
基于融合聚类预处理和主元分析的传感器故障检测与诊断优化策略
2021-03-31 09:02张弘韬陈焕新郭亚宾李冠男申利梅
制冷技术 2021年1期
张弘韬,陈焕新*,郭亚宾,李冠男,申利梅
(1-华中科技大学能源与动力工程学院,湖北武汉 430074;2-郑州大学土木工程学院,河南郑州 450001;3-武汉科技大学城市建设学院,湖北武汉 430081)
0 引言
传感器是工业自动控制系统实施各种优化的控制策略和实现运行目标所必须的基本组件[1-2]。在常规的工业控制循环中,传感器持续输出的测量信号是循环正常工作的第一个环节,也是重要的前提,其测量信号及时反映系统当前运行状态的信息,并通过反馈作用传递至控制中心,由控制中心经过适当计算发出相应指令给执行部件,以维持运行参数的相对稳定并实现各种控制优化策略。所以当传感器发生故障,导致其读数不准确时,控制中心错误的指令可能会影响各种优化的控制策略和运行目标的实现,这就很可能显著增加能耗与运行费用,甚至由于系统长期处于高负荷高能耗状态而降低系统部件的使用寿命。
传感器的软故障表现形式主要为偏移、漂移和精度下降,其结果均为出现不同程度的测量偏差,偏差通常在初期不易检测到,而随着时间的推移和故障信号在控制循环中的传递[3],有可能发展为较严重的程度。尤其是对于大型空调系统,其具有复杂且耦合的控制关联,故障经过累积或传递后可能使各设备或部件无法高效运行,增加额外能耗。此外,为了满足某些空调系统传感器持续高精度输出以完成如性能检测及能耗计量的要求,一套能够及时地自动检测出传感器故障并隔离故障源的故障检测及诊断(Fault Detection and Diagnosis,FDD)系统显得尤为必要。
近年来,学者们在制冷空调传感器故障诊断方面有较为广泛的研究,主要有3 类典型的诊断方法,分别是基于知识、模型与数据驱动的方法。基于知识的诊断方法[4-6]的基本原理是首先对系统的各种运行状况进行学习训练(不管是否有故障),然后针对某一实际的运行状况,应用各种启发式的推理推断故障是否存在;基于模型的方法[7-8]是先获得由数学模型计算而来的参数预测值,然后得到实际过程的输出值和预测值之间的某种关系并将其作为用于故障诊断的指标。而数据驱动即依据数据处理的方法[9-10],不用构建物理模型,仅仅是借助大量的各种运行工况下的历史数据,包括正常数据和故障数据,来掌握变量和参量之间的固有联系,通过这样的机器语言学习过程建立的数学模型可以用于判别新数据中的故障情况并隔离故障源。
近来,数据挖掘技术被广泛应用于检测和诊断空调系统的传感器故障,这些应用通常是通过采集数据、机器学习、归纳演绎、识别故障或能耗模式来提取变量数据间的关联或系统的隐藏特征[11-15]。其中,主元分析[16-17](Principal Component Analysis,PCA)作为一种典型的在多种制冷空调系统[11,18-21]中成功得以用于建立纯数学模型的故障检测方法,在其理论研究取得较大进展的背后,是许多研究者在其应用于故障诊断领域做出的积极贡献:WANG等[18]利用主元分析方法进行了冷水机组的传感器故障检测和诊断工作;DU 等[3,10]则利用Fisher 判别分析法(Fisher Discrimination Analysis,FDA)和联合角度法(Joint Angel Analysis,JAA)优化了变风量(Variable Air Volume,VAV)空调系统中传感器故障检测与诊断( Fault Detection and Diagnosis,FDD)过程的PCA 模型,改进了PCA法应用于传感器故障的诊断水平;XU 等[22]和DU等[23]采用小波分析(Wavelet Analysis)方法对于PCA 建模数据质量问题进行了探究,从而进一步改善了传统PCA 应用于制冷空调故障诊断的性能。此外,DU 等[24]利用神经网络(Neural Network)、聚类分析(Clustering Analysis)等数据挖掘技术来诊断空调系统中的常见故障。这些方法都在一定程度上提高了基于PCA 的传感器FDD 过程的性能,但实际的传感器监测数据往往体现了大型空调系统中的高度复杂非线性的控制关联和随着环境状态多变的运行工况特征,而基于传统PCA 的故障检测方法适用于动态系统的稳态过程[25],利用某一稳定工况下的运行数据建立起来的主元模型并不能直接应用到另外的工况条件。在实际应用时,必须考虑PCA 模型的工况适应性问题。
本文以一个实际的水源热泵空调系统为研究对象,针对传感器常见的小幅值偏移和漂移故障,提出一种基于融合聚类和改进PCA 方法的传感器FDD 策略。考虑到传统PCA 模型的工况适应性问题,采用将减法聚类及K-Means 聚类结合的聚类方法对各种运行工况的建模数据进行识别与分类。主元分析主要用于提取特征变量间的固有关联并按照不同运行工况建立统计学模型。选择T2和平方预测误差(Square Prediction Error,SPE)统计量作为FDD 检测指标,向温度和其他类型传感器引入典型的传感器故障如固定和漂移故障,此外,还采用交叉运行工况的模型来研究运行工况的变化对统计量指标变化敏感度的影响。
1 故障检测与诊断优化策略
1.1 主元分析
设原始数据集为矩阵X0,X0∈Rm×n(m为样本数,n为变量数)。
首先得到X0的标准化矩阵X。根据矩阵论原理,标准化矩阵X的协方差矩阵R可以作为主元分析的对象。协方差矩阵定义为:

对协方差矩阵R进行特征值分解,分别得到特征值和对应的特征向量。特征值按λ1>λ2>…>λn>0的形式排列,而其所对应的特征向量也对应组成特征值矩阵U,U是一个n维方阵,[p1,p2,… ,pn]。
本研究采用累计贡献率法[26]选取主元个数l。因此,根据特征值分解和主元数的确定,可将测量空间划分为两个正交子空间:产生正常数据变化的主元子空间(Principal Component Subspace,PCS)和产生不正常变化或者噪音的残差子空间(Residual Subspace,RS)。任意一个采样数据x,都可分别投影在两个子空间,得到其投影为主元向量和残差向量e,如图1所示。

图1 采样数据x 在PCA 模型下的投影关系

式中,p为载荷矩阵,是主元分析的投影矩阵,p的列是协方差矩阵R的前l个最大特征值对应的特征向量,即p=[p1,p2,…pn],p∈Rn×l。
1.1.1 故障检测指标
通常用平方预测误差和Hotelling′sT2(简称T2统计量)来检测传感器数据是否发生异常。Q统计量表征样本点到主元子空间的距离,其数值等于残差向量e在残差空间上的欧氏距离的平方。

当有传感器发生故障导致测量数据间相关关系的变化,残差可能显著增加,导致其Q统计量大于一个固定范围。
当存在故障工况时,会出现:

式中,Qα为SPE 的阈值,可根据后n-l个特征值计算得到[26]。
T2统计量分析的是原始样本点在主元空间中投影的分布情况,其数值等于样本点在主元子空间的投影点到样本点的均值点的距离,可表示为:

式中,Λ1,l= diag(λ1,λ2,...,λl)表示前l个特征值组成的对角矩阵。
T2统计量服从F分析,其检测阈值为:

式中,m为样本数;l为所保留的主元数;Fl,m-l,α为自由度为l和m-l、置信度为α的F分布的临界值。
1.1.2 故障诊断指标
Q贡献率[27]被广泛用于采用Q统计量作为判断依据的故障源诊断分析中。从计算原理上分析,Q统计量表征了残差向量e的各个分量在残差空间各维度上投影的平方。

残差向量e所在的n维残差空间中,每个维度对Q统计量的贡献率定义为:

当采样数据的第i个分量出现故障变化,导致该数据的残差向量e在第i维的维度上出现偏差。该偏差会导致所在维度的贡献率增大。因此,通过确定最大贡献率所在的维度i,可以确定第i个传感器为故障源所在。
1.2 聚类方法
考虑到PCA 模型的工况适应性问题,本文将提出一种结合减法聚类和K-means 聚类方法的数据预处理策略,减法聚类方法可快速确定较准确的初始聚类中心,并可自动确定具有较好聚类效果的最大聚类数目,这两点弥补了K-means 聚类方法的两点不足:聚类数目的事先给定很难估计;初始聚类中心的选择对聚类结果有较大的影响。
1.2.1 减法聚类
减法聚类是一种爬山法[28],是将所有的样本点作为聚类中心的候选点。它是一种快速而独立的近似的聚类方法,其计算量与样本点的数目成简单的线性关系,而且与所考虑问题的维数无关。
减法聚类首先计算每个样本点的密度指标[29],如果该样本点周围的点多,则密度指标就大,然后将密度指标最大的样本点选为第一个聚类中心;选定第一个聚类中心后,其它样本点的密度指标根据样本点距离第一个聚类中心的距离做相应的调整,离第一个聚类中心越近的样本点,其密度指标减小得越多,下一个聚类中心选在调整后的密度指标最大的样本点上;然后再对所有样本点的密度指标进行调整,不断寻找下一个聚类中心,直到最后一个聚类中心的密度指标值和第一个聚类中心的密度指标值之比小于一个参数δ值,δ≥0.5 时有较好的聚类效果,且当δ=0.5 时所获得的聚类数目最多,因此,在自动设定聚类数时,以δ=0.5 时所获得的聚类数为最大上限Cmax。
1.2.2 K-Means 聚类
K-Means 聚类算法[30]是一种以平均值作为聚类中心的分割聚类方法,简单易操作而且快速是其最大的优点,在处理大数据集时,也能表现较高的效率和相对可伸缩性。因此它成为数据挖掘算法中一类基础且重要的聚类方法。
K-Means 算法首先需要选取初始聚类中心,然后对所有数据点进行分类,最后计算每个聚类的平均值调整聚类中心,不断的迭代循环。最终使同一聚类内数据间的距离最小,不同聚类数据间的距离最大[31]。
1.3 融合聚类预处理的PCA 故障检测方法
图2所示为基于数据驱动方法的传感器故障检测流程。

图2 基于数据驱动方法的传感器故障检测流程
主要分为3 个部分:模型适应性预处理(训练和测试数据)、模型训练(训练数据)和模型检测(测试数据)。
1)模型适应性预处理
此部分主要是考虑到前文提出的PCA 模型的工况适应性问题,对训练数据和测试数据进行聚类分析,以得到适用于PCA 建模的各子训练数据库和匹配于相应子训练数据库的子测试数据集。
2)模型训练
通过对各子训练数据集的学习,可以得到多个子PCA 模型。
3)模型测试
对新的测试数据矩阵进行标准化处理后,再计算相应的Q统计量和T2统计量,并分别与训练模型的阈值Qα和T2α作比较,以判断是否产生故障或发生工况变化。
2 研究对象及方法
2.1 研究对象
2.1.1 系统及数据对象
图3所示为某办公大楼水源热泵系统结构简图。该水源热泵系统包含3 个子系统:室外的水源换热系统、机房冷水机组系统和室内末端的空调系统。机组的启停及压缩机的频率均为人为控制,一般运行时间为周一至周五08:00—17:30。机组运行监测过程中,以10 min 的采集频率采集各种实际运行数据。监测时间覆盖整个夏季工况和冬季工况。冬夏季工况由管路中阀门切换控制,夏季冷水供回水温度设计为7 ℃/12 ℃,冬季热水供回水温度为45 ℃/40 ℃,空调末端设备均采用风机盘管。

图3 测试的水源热泵系统结构简图
该系统中主要采用温度和流量传感器来监测各种工况下的性能及能耗情况,其中主要包括直接测量得到的室内环境温度Tin、冷冻水供水温度Tsw、冷冻水回水温度Trw、冷冻水瞬时流量Fi、冷水机运行数量N、室外空气温度Tout等传感器,还有间接计算得到的可反映系统性能和能耗情况的制冷/供暖量Qi、机组功率P等。本研究选取该系统2016年7月和8月的实测运行数据作为实验数据,并将7月数据集作为训练数据集,8月数据集作为原始测试数据集,其中7月的数据量为1,856,8月的数据量为1,161。
2.1.2 传感器故障
常见的传感器故障[25],包括偏移、漂移、精度下降和失效故障。其中,偏移故障是指测量值和真值的差值是一个定值,故障测量值与无故障测量值是平行的;漂移故障是指差值是时变的,比如线性变化的,有故障测量值与无故障测量值之间的差距随时间的推移而不断加大;精度下降故障指差值是随机变化产生的随机噪声,故障测量值与无故障测量值混杂在一起;而失效故障指测量值趋于一定常数,通常这一恒定值是0 或者最大读数。
2.1.3 故障分析模型
基于PCA 模型的传感器的FDD 分析,本质上来说,是采用监测空调系统过程中采集的多个数据信号进行数据分析的过程。这些数据信号之间相关性高,该相关性被能量守恒定律、热平衡原理等基本规律所制约[26]。因此必须建立相关测量数据的关系模型,再运用基于数据的方法来分析其相关性。
根据所研究系统的能量守恒关系以及相关的控制关联,可以建立如下包含8 个变量的PCA 统计模型。
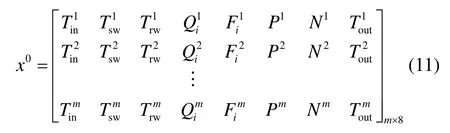
2.2 研究方法
本研究拟采用Q统计量和T2统计量的双重检测标准实现对传感器测试数据的故障检测,对应可能出现的4 种故障检测结果:SPE 和T2统计量均没有超过阈值;SPE 超过,T2没有超过;SPE 和T2均超过,通常认为这4 种结果和传感器故障和工况扰动有关[32]。本研究将着重于这4 种检测结果下的异常行为变化分析,为此需要对原始测试数据集分别进行适当处理。因此,为了探究将SPE 和T2统计量对传感器故障和工况变化两种异常数据状态的指标变化,可以采用以下研究方法:
1)向划分工况的原始测试集引入故障,如表1所示,其中漂移程度设定为测试样本集的最后一个样本漂移至最大的偏差程度;此时主要是检验传感器故障对Q统计量检验标准的影响;

表1 引入的传感器故障类型及大小
2)不向原始测试集引入故障,将属于B 工况的测试集来测试利用A 工况建立的PCA 模型,此时主要是模拟工况的变化对T2统计量检验标准分布的影响。
本文分别采用故障检测率和故障诊断率[22]来量化基于PCA 的传感器多测量样本的FDD 的能力。故障检测率是指Q统计量超过阈值的样本数与测试数据的总样本数之比。当检测率高于20%时,认为故障检测才是成功的。此外,故障诊断率是正确诊断故障(Q统计量最大贡献率所在的维度与引入故障的维度相同)的样本数与Q统计量超过阈值的样本数之比。当诊断率低于50%时,认为故障诊断是错误的,即发生了故障误报。“Q诊断率”的故障诊断结果的表示方式是Q贡献率图[33]的数字直观表示,不仅定量分析故障诊断的效果,而且还较好地结合了故障检测率的概念,即认为只有检测到故障的产生(Q统计量超过阈值),才有可能实施故障诊断,即识别故障传感器,此时故障诊断的正确性判断更具有科学性。
3 结果和分析
根据聚类原理关系,考虑到本实验对象非稳态运行工况的存在,指定减法聚类参数δ=0.5,得到最大聚类数目Cmax=10,对训练集和原始测试集利用减法聚类和K-means 聚类方法同时进行分类预处理,由此得到的子训练集和子测试集的分类情况如表2所示。

表2 训练集和原始测试集中每一聚类中的样本数
由于聚类3 只有一个数据,故不予讨论其验证结果。以下对聚类2、聚类4 和聚类9 子测试数据集进行处理,得到多种传感器故障或交叉工况的数据基于Q统计量和T2统计量检测标准的FDD结果。
3.1 引入故障的FDD 结果及分析
3.1.1 温度类传感器的FDD 结果汇总
表3所示为聚类4 子测试数据集和没有进行聚类处理的原始测试集的供水温度传感器的故障诊断率。表4所示为聚类2、聚类4 和聚类9 子测试数据集和未进行聚类处理的原始总测试集的温度类传感器引入表3所示故障的基于Q统计量和T2双重检测标准的故障检测效率。

表3 引入故障的各子测试集的故障诊断率汇总表(%)

表4 引入故障的各测试集的基于Q 和T2 统计量的故障检测率汇总表(%)
3.1.2 其他类传感器的FDD 结果汇总
表5所示为聚类2、聚类4 和聚类9 子测试数据集和未进行聚类处理的原始测试集的其他类传感器(除温度传感器外)的基于Q统计量和T2双重检测标准的故障检测效率。表6所示为聚类2 子测试数据集和未进行聚类处理的原始测试集的机组功率传感器的故障诊断率。

表5 引入故障的各测试集的基于Q 和T2 统计量的故障检测率汇总表(%)

表6 引入故障的各测试集的故障诊断率汇总表(%)
3.1.3 引入故障的FDD 结果分析
为了研究聚类2 的原始测试集验证,利用聚类4 的训练集建立的PCA 模型的FDD 特性,用以作为交叉模型的FDD 分析的例子。
由此计算可得基于Q统计量的故障检测效率为100%。此时各变量的Q贡献率如图4所示,图中各区域从上至下分别代表的变量为:室外空气温度、冷水机运行数量、机组功率、瞬时热量、冷冻水瞬时流量、冷冻水回水温度、冷冻水供水温度和室内环境温度。

图4 交叉工况验证的Q 贡献率
由图4可知,各变量对Q统计量的贡献率相当。说明此时各传感器未发生明显故障使某一个变量的Q统计量贡献率偏大,这是符合预计的结果。
基于T2统计量的检测效率达到100%,和3.1节的验证内容相比,这是最明显的区别,此时交叉工况模型的统计量验证的目的达成,但同时,基于Q统计量检测标准的故障检测效率也较高,这可能是和数据质量问题有关。
4 结论
本文以水源热泵系统的传感器为对象,在建立该对象的变量故障分析统计模型的基础上,利用将减法聚类及K-Means 结合的聚类分析方法,对历史正常运行数据进行分类预处理,从而建立分类的历史正常运行数据的数据库,分别训练各个分类下的正常数据以建立PCA 模型;对新的测试数据进行归类,分别向实测传感器数据的各类传感器采取引入故障或交叉工况的数据处理手段,再利用对应的PCA 模型分析测试数据的基于Q统计量和T2统计量的FDD 性能,得到如下结论:
1)融合减法聚类及K-Means 聚类的综合聚类方法弥补了单一K-Means 聚类方法的不足,实现了对建模及测试数据的分类预处理过程,由此建立的多个PCA 模型改善了传统PCA 对多样工况传感器故障的检测性能,表现为对传感器漂移故障的检测效率约提升50%,在其他故障条件下也能显著提高测试数据的故障检测率和故障诊断率;
2)SPE 统计量和T2统计量故障检测指标对于同一传感器变量的同一故障过程的故障检测能力表现出不同的敏感度,相对而言,基于SPE 统计量的故障检测指标对引入偏移、漂移等传感器故障的测试过程的检测能力更强,而基于T2统计量的故障检测指标对发生工况扰动或变化的测试过程的检测能力更强;
3)基于SPE 统计量和T2统计量的故障检测结果体现了将PCA 应用于FDD 流程的特点:基于PCA 的FDD 能力高低很大程度上取决于数据质量的好坏,能够获取大量无故障历史运行数据是PCA进行优化建模的前提;同一传感器变量在不同处理条件下,检测效率差异较大,体现在工况变化较偏移和漂移等传感器故障的检测效率高,可达到完全检测(100%);而对于不同大小程度的传感器故障,一般来说,其故障检测率随着偏差的增大而提高,且对同一大小的正负偏差的检测能力相近。
猜你喜欢
一重技术(2021年5期)2022-01-18
铁道通信信号(2019年6期)2019-10-08
科学与财富(2018年30期)2018-12-28
雷达学报(2017年6期)2017-03-26
计算机应用(2016年9期)2016-11-01
体育科技(2016年2期)2016-02-28
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
电子设计工程(2015年6期)2015-02-27
振动、测试与诊断(2014年5期)2014-03-01
河南科技(2014年3期)2014-02-27
