
基于集成局部费舍尔判别分析的故障分类
2021-04-29 04:06凯徐明星韩
控制理论与应用 2021年4期
钟 凯徐明星韩 敏
(1.大连理工大学 电子信息与电气工程学部,辽宁 大连 116024;2.大连理工大学 工业装备智能控制与优化教育部重点实验室,辽宁 大连 116024;3.安徽大学 物质科学与信息技术研究院,安徽 合肥 230601)
1 引言
现代的工业生产过程趋向于流水化作业,并且具有大型化、智能化、复杂化的特点.随之而来的便是过程间的交互变得更加频繁,设备的结构也变得更加多样.如果其中的某一子系统或者零件发生故障,就像多米诺骨牌效应一样,不仅会造成产品质量的降低,而且也会破坏工业生产的设备,对整个企业的生产造成影响,更严重的是还有可能对环境造成不可逆转的破坏,甚至出现人员伤亡[1–2].因此及时有效的过程监测对工业生产效率的提高和企业自身的发展都具有重要的意义[3–6].
作为过程监测研究领域重要的分支之一,故障诊断(某种意义上等价于故障分类)近年来取得了较大的发展和进步,并取得丰硕的理论研究成果和工程应用实例.故障诊断主要是将过程中已经发生的故障与其他样本划分开来,从而确定故障的位置,故障的原因以及故障的类别等[7],以便采取后续的故障隔离和过程恢复措施.针对故障诊断方法的分类,目前业内比较认可的是由文献 [8]提出的基于解析模型、基于过程知识和基于数据驱动这三大类.由于基于数据驱动的方法只需要一定的过程数据而无需建立复杂的数学模型,实施简单且更为有效,因此获得更广泛的关注和青睐.另一方面计算机技术的发展以及数据分析手段的丰富,也为数据驱动故障分类方法的发展提供了极大的便利.
常见的数据驱动的过程监测方法主要有主成分分析法(principal component analysis,PCA)[9],费舍尔判别分析法 (Fisher discriminant analysis,FDA)[10],前者主要是将高维数据投影到低维空间,同时保留重要的样本信息,因此更适用于故障检测.而FDA模型通过判别投影方向使得属于不同类别的样本间分离性变大,同一类别中的样本间分离性变小,所以常常适用于故障 诊断和分类[11].在过去 的20年,大量的基于FDA 模型的故障分类方法被提出.例如,文献 [12]提出基于核方法建立的核FDA模型,从而可以处理非线性过程的故障诊断问题.文献 [13]将局部费舍尔判别分析(local Fisher discriminant analysis,LFDA)应用于复杂过程的监测,并在分类多个故障时展示了比常规的FDA模型更好的性能.文献 [14]将PCA和FDA原理融合提出半监督的费舍尔判别分析模型,该模型不但能保留各自的优点还克服了自身的局限性,并在化工过程的故障诊断中取得了较高的精度.随后,文献 [15]设计一种半监督的局部费舍尔判别分析模型,并成功应用于旋转机械的微小故障的分类.近期,文献 [16]讨论了不同变量对故障的影响程度,并 设计了稀 疏的LFDA模型,且在真实和仿真的过程中都验证了方法的有效性.
虽然上述的基于FDA模型的故障分类方法能 够解决某一特定的问题,但是很少有方法同时从样本和变量的角度挖掘数据的局部结构特性,也没有考虑不同变量子块对故障分类结果的差异化影响.基 于此,本文提出一种集成的局部费舍尔判别分析模型(integrated local Fisher discriminant analysis,ILFDA).论文的主要创新点包括:
1) 有效利用机理知识将系统进行合理的划分,排除了无关变量的干扰并降低了建模的难度,刻画了变量维度的数据局部特性.
2) 利用分类性能加权策略将局部结果进行有机集成.不但获取了样本维度的数据局部信息,还定量地刻画不同子块(变量)对当前故障的影响程度.
3) 所提的ILFDA模型不但是子分类器的集成和增强,也是过程机理知识和数据驱动方法的融合和互补,为复杂过程故障分类提供了新的研究思路.
2 预备知识
2.1 费舍尔判别分析
FDA是一种有监督的判别分析方法,主要思想是寻找最优的投影方向,使得类间离散度最大的同时类内离散度最小.对于含有n个样本和m个特征的原始数据矩阵X=(x1x2···xn)∈Rn×m.且n个样本被划分为K个类别,其中第k(1 ≤k≤K)个类别Ck中含有nk个样本.则类间离散度矩阵Sb和类内离散度矩阵Sw计算如下:
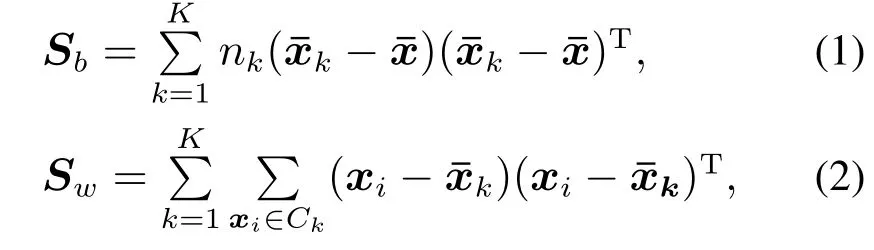
为了更方便介绍LFDA模型,在式(1)和式(2)的基础上给出FDA算法的对等形式:


则FDA的 最优判别方向 可以通过优化下面的目标函数得到

2.2 局部费舍尔判别分析
一般的FDA方法忽视了数据的局部特征,而只关注数据的全局特征.因此,当来自相应类别的数据不服从多元高斯分布,且同一类别间的样本展现出多模态特性时,传统的FDA算法不再适用.为了克服常规FDA方法的上述不足,文献 [17]将FDA和局部保留投影(locality preserving projection,LPP)算法结 合提出了LFDA模型.
LFDA模型的类间散度矩阵与类内散度矩阵可以定义如下:

由于故障数据集内部的数据分布复杂,对故障分类的结果影响也不尽相同,所以不能对所有的类别赋予相同的权重,为了充分考虑局部特性,加权矩阵定义为

与式(7)类似,LFDA模型的投影方向可通过求解下式得到:

上述的优化问题可以转化为以下的广义特征值问题:

其中λ,分别为广义特征值和特征向量.
对于新的测试数据集x,可通过下面的判别函数将其划分为具体的类别中去[18]:

3 集成局部费舍尔判别分析
本小节给出了所提的ILFDA模型的具体介绍,包括过程分块策略,多块分类结果的集成等,最后给出ILFDA算法的主要步骤.
3.1 过程分块策略
在实际的工业过程中,过程数据有时会表现出复杂的特征,变量间也会展现出多种关联性,因此很难依靠单一的数据驱动模型对整个过程进行建模和监测.此外,由于采样设备和采样环境的局限性,可能无法获取完整的过程数据,特别是故障样本,这些都会导致数据驱动方法的效率大打折扣.因此,有必要将数据驱动方法和过程机理进行融合,实现方法之间的优势互补.首先需要根据已知的过程结构或者机理知识将复杂的系统划分为多个子块,并将具有类似特征或者是关联性较强的变量划分到同一子块中,然后对每一子块分别建立数据驱动的故障诊断模型,计算相应的统计指标,提取局部故障特征信息并进行集成.其基本原理如图1所示.

图1 过程分块步骤Fig.1 The procedures of process partition
此类分块方法的优点为:由于按照结构原理将整个复杂系统合理地划分为多个子块,减少了一些无关和冗余变量的影响,降低了直接对整个系统建模的难度,进而提高故障诊断的精度和模型的可解释性.但是根据机理知识进行分块的方法也有其自身的局限性,例如当过程机理和先验知识未知时,就无法对过程进行准确的分块.所以本文所提的ILFDA模型是建立在机理知识和数据驱动方法相结合的基础上,比较适用于机理知识已知的情形,且是单一方法或者局部模型的有效集成和增强.
3.2 多块分类模型集成
根据第3.1小节的过程分块方法,可以将整个系统划分为M个变量子块.分别在每个子块中建立LFDA模 型,并根据 式 (14) 和 式 (15) 求 得M个判别函数,(1 ≤l≤M).由于不同变量子块对故障分类的影响可能不尽相同,为了更好地刻画不同子块对诊断结果的差异化影响,利用加权策略建立如下的集成判别函数:

其中权值矩阵定义如下:

Accl表示第l个子块 中训练 样本的 故障分 类精度(classifcation accuracy,Acc).对于新采集的实时监测数据x,可通过下式将其划分为某一确定的类别:
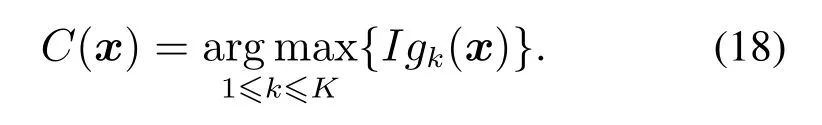
从以上的分析可知,如果某一子块中训练数据的分类精度越高则该子块的加权系数就越大,其在集成的模型中所起的作用就越重要,反之亦然.所以ILFDA模型可以从样本和变量两个维度刻画数据的局部特性,更全面地凸显样本局部信息和变量局部信息在故障分类中的作用,有助于提高故障分类精度.
3.3 ILFDA算法流程
为了更好地理解本文所提的ILFDA算法,图2给出了该算法的流程图.

图2 ILFDA算法流程图Fig.2 The flowchart of the ILFDA algorithm
该算法的详细过程总结如下:
步骤1根据过程机理知识将原始系统划分为M个子块;
步骤2在每个子块中建立LFDA模型,分别计算第l个子块中训练数据集的故障分类精度Accl;
步骤3根据式(17)计算权值系数wl;
步骤4对新的实时测试样本数据x,根据步骤1的分块结果将其分为M个子块;
步骤5根据式(14)和式(15)计算M个子块的判别函数,1≤l≤M;
步骤6将步骤3得到的权值系数wl分别赋予x的M子块;
步骤7根据式(16)计算集成判别函数Igk(x);
步骤8根据式(18)对x进行分类.
4 仿真实验
4.1 TE过程介绍
为了验证所提ILFDA方法的故障分类性能,本文在田纳 西–伊斯曼过程(Tennessee Eastman,TE)中 进行仿真实验.TE过程是 由伊斯 曼化学 品公司 的J.J.Downs和E.F.Vogel于1993年首次提出[19],并成为验证过程控制和监测方法广泛使用的基准平台.TE过程包括5个主要单元:反应器、冷凝器、压缩机、分离器和汽提塔.TE过程中进行的化学反应主要包含4种反应物A,C,D,E和两种生成物G,H以及一种惰性物质B和副产品F.该过程中共有41个测量变量和12个操作变量(如表1所示).测量变量中的前22个是连续型变量(如表2所示),后19个属于成分变量.本文选取22个连续型变量和前11个操作变量,共33个变量用以建模.另外,TE过程含有21种不同的预设故障,每种故障工况数据集的前161个样本为无故障样本,后800个样本为故障样本,并且TE过程还包含960个正常工况的样本,采自过程的平稳状态.更多关于TE过程的介绍可参考文献 [20].

表1 TE过程的操作变量Table 1 The operating variables of TE process

表2 TE过程的测量变量Table 2 The measurement variables of TE process
4.2 实验条件设置
首先根据TE过程结构的原理将其划分为5个子块,即原料块、反应器块、分离器块、汽提塔块、压缩机块.每个子块包含的变量具体如下:
子块1(原料块):V1,V2,V3,V4,;
子块2(反应器块):V6,V7,V8,V21,;
子块3(分离器块):V11,V12,V13,V14,;
子块4(汽提塔块):V9,V15,V16,V17,V18,V19,;
子块5(压缩机块):V5,V10,V20,V22,.
本实验选择TE过程中的故障3和故障5以及故障11用以验证ILFDA方法的有效性,3种故障的具体介绍如表3所示,从表中可以看出这3种故障都为TE过程中的温度异常,所以相互之间的关联性较为密切,此外3种故障发生于不同的子块而且故障的类型也不尽相同,所以比较适合用于验证本文的集成的故障诊断方法.3种故障都包含了训练数据集(每种故障480个样本)、测试数据集(每种故障都选择第161–560个故障工况样本),所有的故障数据在使用前都利用正常工况样本的均值和方差进行了标准化处理.

表3 从TE过程选择的故障Table 3 The selected faults from TE process
首先使用LFDA计算训练样本中各个子块的分类精度,得到各个子块的权值如图3所示.

图3 各个子块的权值Fig.3 The weight of each sub-block
4.3 仿真结果分析
本文以EDA[11],FDA和LFDA模型作为对比实验进行仿真实验.4种方法对不同故障的判别函数如图4所示,对于确定的样本点,如果其在某一故障的判别函数值最大,则该样本即被划分为此类故障.图4的横坐标中共有1200个采样样本,其中样本1–400为故障3,样本401–800为故障5,样本801–1200为故障11.从图4(a)中可以看出EDA模型对故障5有较好的分类结果,但是在区间1–400和801–1200,故障3和故障11的判别函数都有大量的交叉和重叠,说明EDA对故障3和故障11的分类精度都很低,无法有效地将这两种故障划分开来.而图4(b)中故障3和故障11 的误分类现象有了一定的改善,分类精度得到了提高,但是还是存在较多的误分类点.此外,FDA也可以较好的对故障5进行分类.由于LFDA可以克服FDA方法无法描述数据局部特征的缺陷,所以在图4(c)中3种故障的判别函数交叉和重叠现象进一步被消除,也就是说故障的分类精度得到了提升.而在图4(d)中可以较为清楚的看出本文所提的ILFDA模型在较好地将故障5分类的同时,还能够显著提升故障3和故障11的分类精度.


图4 不同方法对3种故障的判别函数Fig.4 Discriminant functions of the three faults by different methods
此外,还将不同方法对3种故障的分类结果绘制如图5所 示.类似地,横坐标中的样本1–400,样本401–800和样本801–1200分别为故障3,故 障5和故障11,纵坐标代表故障的标签.从图5(a)可知大量的故障3和故障11的样本被EDA误分为其他的故障,特别是对故障11.类似的情况也出现在图5(b)中,FDA模型对故障11的分类精度也较低.而在图5(c)中,由于LFDA模型能够考虑数据的局部特性,所以取得了比EDA和FDA都高的故障分类精度.最后在图5(d)中,所提的ILFDA模型能够同时将这3种故障进行有效的划分,取得了最好的故障分类性能.究其原因,主要是由于ILFDA模型不但能够有机融合机理知识和数据驱动模型的优点,同时从样本和变量角度挖掘数据的局部特征,还能将多个局部的故障分类模型进行集成和增强.

图5 不同方法对3种故障的分类结果Fig.5 Classification results of the three faults by different methods
为了定量的分析4种方法的分类精度,将具体分类精度列于表4中,且最高的分类精度用粗体标出,以方便辨识.由表的第1行可知,EDA模型对3种故障的分类精度分别为64.25%,98.75%和34.75%,而平均的分类精度为65.92%,虽然对故障5的分类效果较好,但对于剩余两种故障的分类精度不能满足要求.同样的,虽然FDA比EDA对故障3的分类精度有了一定的提升,但是FDA仍然无法有效提高故障11的分类精度.作为FDA的改进方法,LFDA虽然提升了故障11的分类精度(达到61.5%),但是故障3的分类精度反而出现较大的下降,总体76%的平均分类精度也难以让人满意,因此仍然具有可提升的余地.而ILFDA方法同时对故障3和故障11取得了 最高的 分类精 度(分别为97.5%和92.25%),即便对故障5没有取 得最好的分类效果,但ILFDA也和最优的LFDA模型相 差无几(99.5%和99.75%),此外ILFDA的平均分类精度要远高于对比算法(96.42%对比65.92%,68.83%,76%),也从另一个角度证明所提方法的有效性.
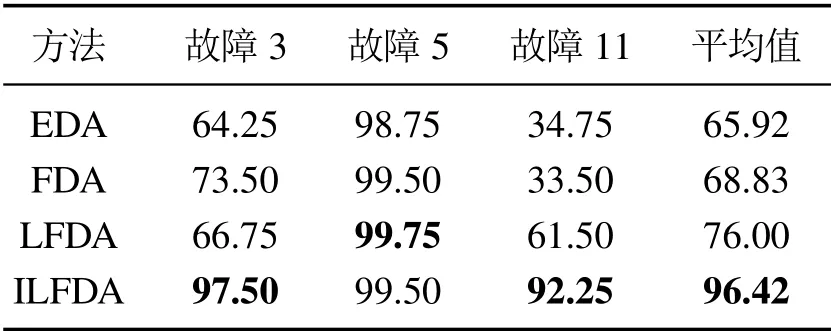
表4 3种故障的分类精度Table 4 Classifcation accuracy of the faults %
5 结论
本文提出的ILFDA是一种基于LFDA模型的集成多子块的判别方法,不但能将机理知识和过程数据进行优势互补,还能将多个局部故障分类模型进行集成和增强,可以从变量和样本两个角度挖掘数据的局部特性.为了充分获取变量之间的局部信息,首先根据机理知识对系统变量进行合理的分块.然后在每个子块中分别建立LFDA模型,并得到相应的局部分类结果.最后利用基于训练样本分类精度的加权集成策略将各个子块的分类结果进行有机的融合.利用TE过程进行方法验证,仿真结果表明所提方法取得了最高的分类精度,降低了故障的误分类情况,具有一定的实际应用价值.
猜你喜欢
智能计算机与应用(2022年10期)2022-11-05
一重技术(2021年5期)2022-01-18
中华书画家(2021年12期)2022-01-06
现代计算机(2021年36期)2021-03-14
南京理工大学学报(2020年4期)2020-09-21
散文诗(2020年1期)2020-07-20
计算机应用(2018年12期)2019-01-07
电子制作(2018年11期)2018-08-04
东方艺术·国画(2016年3期)2017-02-08
发明与创新(2016年38期)2016-08-22
