
基于深度残差网络的多人姿态估计
2021-05-17 02:36秦晓飞郭海洋陈浩胜何致远
光学仪器 2021年2期
秦晓飞,郭海洋,陈浩胜,李 夏,何致远
(1.上海理工大学 光电信息与计算机工程学院,上海 200093;2.上海理工大学 机械工程学院,上海 200093)
引 言
人体姿态估计就是在给定的一幅图像或一段视频中去进行人体关键点位置定位的过程,基于给定RGB图像的关键点定位在多个领域都有着很好的应用前景,具有很高的研究价值。但由于存在光照变化、运动模糊、自身遮挡和视角不同等问题,所以现实生活中,多人姿态估计非常具有挑战性。早期的人体姿态估计经典著作将人类关键点估计问题表述为树形结构或图形模型问题,并基于手工制作的特征来预测关键点位置。随着深度卷积神经网络(CNN)的发展,其在人体姿态估计领域的应用极大地提高了关键点预测的性能。
基于卷积神经网络的人体姿态估计经历了坐标回归到预测热力图的发展趋势。Toshev等[1]提出的DeepPose首次使用CNN强大的拟合能力去强制性地回归人体骨骼关键点的坐标,并用级联的形式不断地调整结果。然而使用坐标回归的方法非常容易造成过拟合问题,随后出现的预测热力图的方法优势明显。2016年,单人姿态估计领域以Hourglass[2]和卷积姿态机(CPM)[3]为代表的模型均使用了这一方法。前者重复使用降采样和上采样的沙漏状网络来推断人体的关键点位置,后者使用排列有序的网络架构来实现空间信息和纹理信息的建模。这两个网络中的每一个阶段都会单独地去监督某一部分的学习,同时使用级联的网络结构将空间信息和纹理信息有效融合在一起。2017年,卡内基梅隆大学提出的OpenPose[4]使用部分亲和场来表示人的肢体,并采用树结构结合匈牙利算法求解线性整数,在多人姿态估计自底而上流派中具有里程碑意义。2018年提出的MultiPoseNet[5]使用ResNet作为主干网络,再加两个特征金字塔网络头分别输出人体检测框和人体关键点,最后使用姿态残差网络将检测到的所有关键点依据人体检测结果进行聚类,得到每个人的人体关键点集合。2019年提出的HR-Net[6]模型极力追求检测精度而忽视了模型参数量,与此同时也涌现出LPN[7]、FPD[8]等一批以简单、快速和较高精度为特点的小模型。
本文提出了一种基于深度残差网络(ResNet)的多人姿态估计算法,该算法采用现有的人体检测器,以Simple Baseline[9]为单人姿态估计网络的主干网络,通过改进残差块,引入多尺度监督模块和多尺度回归模块,结合丰富的多尺度特征,通过对各尺度特征的匹配,提高了关键点定位的鲁棒性。另外,新颖的坐标提取方法也有效提升了模型的性能。该算法参数量少,检测速度快,检测精度也极具竞争力。
1 网络结构
1.1 整体算法网络结构
本文提出的算法属于自顶而下方案,即先将图片输入到人体检测网络中,检测图片中的所有人体,给每个人体实例一个边界框,随后将边界框裁减调整为适当尺寸输入到单人姿态估计网络(SPPE)内作关键点检测。由于YOLOv3[10]很好地权衡了人体检测速度和精度,是当下最先进的目标检测算法之一,因此本文算法直接取其作为人体检测器。整体算法网络结构如图1所示。
1.2 单人姿态估计模型
单人关键点检测网络往往会采用一个编解码架构,通过特征提取网络反复提取原始图片的信息,随着网络的加深提取到的信息越来越抽象,特征图的空间尺寸也会越来越小,这对关键点的最终预测有负面影响。本文受Simple Baseline[9]启发,采用ResNet50作为特征提取的主干网络,在C5层后面接3个反卷积模块,每个模块为:反卷积层+BN+ReLU+ 1 ×1 卷积,每个反卷积层输出的特征图均为128个通道,经过 1 ×1 卷积后生成的热力图的大小依次为 1 6×12 ,32×24, 6 4×48 。在每个模块上增加一个损失项,以允许对每一层输出的特定尺度的热力图进行明确的监督。多尺度监督能够有效地学习多尺度特征,从而更好地捕捉到身体关键点的局部上下文特征。将D1,D2,D3输出的热力图分别上采样至同一尺度后堆叠起来,再经过一个 1 ×1 的卷积输出最终预测的热力图,对各尺度热力图的整合充分利用了全局上下文信息,提高了关键点定位的鲁棒性。图2详细展示了单人姿态估计网络结构。

图1 整体算法网络结构示意图Fig.1 Overall algorithm network structure diagram

图2 单人姿态估计网络结构Fig.2 Network structure of single person pose estimation
1.2.1 残差块的改进
深度残差网络(ResNet)的基础构造块是残差块,分别由 1 ×1 , 3 ×3 , 1 ×1 的卷积以及1×1的旁路跳级连接组成。这一结构对特征图的输出通道数能进行非常灵活的设置,不过本文对这一基础模块进行了更为细致的改进,将普通卷积改成了深度可分离卷积,降低了参数量。将经过1×1卷积输出的特征图平均分成s个特征图子集,然后分别再经过 3 ×3 的深度可分离卷积,各特征图子集间加入跳级连接,这样残差块的特征提取能力将大幅度提升。本文还对ResNet-50的C2~C5各层输入输出的通道数都进行了减半处理,降低了计算量。原始残差块的参数量为 N um1 ,引入深度可分离卷积并降低通道数后的参数量为 N um2 ,N、M分别是输入和输出通道数,且满足M=2N,N≥32 ,N为 32 的整数倍:
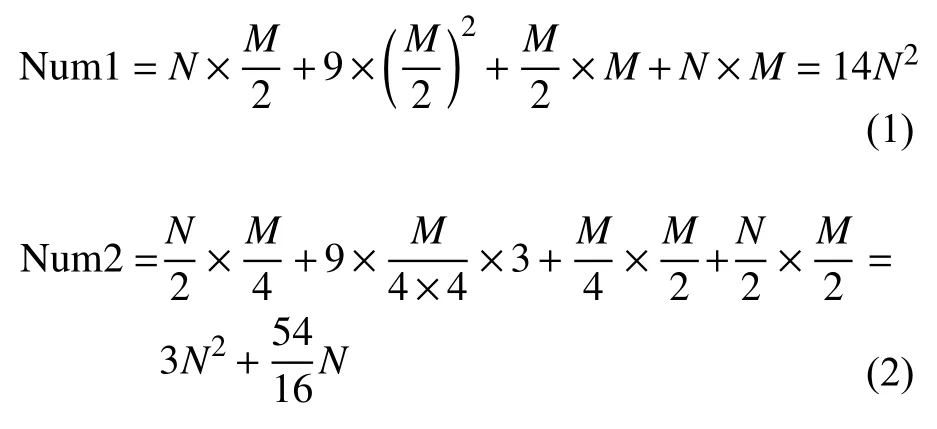
故 N um2/Num1 ≤ 0.222 , 即 改 造 后 的 残 差块参数量降低到原来的 1 /4 以下。改进过程见图3。
1.2.2 多尺度监督
Simple Baseline模型仅仅对最终的热力图进行监督,忽视了对解码阶段各尺度信息的融合,对全局信息利用不够全面。多尺度监督模块(MSSModel)就是要弥补这一不足,该模块主要是对反卷积层进行监督。反卷积层的每一层都有不同尺度,各个尺度的预测热力图都有其对应的真实热力图,多尺度监督模块就是通过计算真实热力图与这些预测热力图之间的残差来实现监督目的。为了使预测热力图的通道数相等以便计算对应的残差,使用 1 ×1 的卷积进行降维,将高维特征映射转化为所需数量的特征,其中,降维之后得到的热力图数量(即通道数)与身体关键点的数量相同。另一方面,对真实关键点热力图进行下采样,以匹配每个尺度下的关键点的预测热力图,方便计算残差。具体结构见图2。

图3 残差块的改进过程Fig.3 Improvement process of residual block
为了训练多尺度监督网络,本文定义了损失函数LMSE 。LMSE 定义为所有尺度上关键点的预测热力图与真实热力图的均方误差( M SE )的均值。首先,

式中: (x,y) 表示热力图上任意像素点坐标;(xn,yn)是第k个关键点的真实坐标; σ 是高斯峰的标准差;(x,y) 是第d(d=1,2,3) 个尺度下的真实热力图,它是以每个关键点真实坐标为中心生成的二维高斯分布。损失函数LMSE定义为

式中:K表示人体关键点总数;表示第d个尺度下第k个关键点的预测热力图,(x,y) 尺度与(x,y) 、(x,y) 一致。需要注意反卷积层预测的热力图与最终预测热力图的损失权重是不一样的。
1.2.3 多尺度回归
使用一个多尺度回归模块(MSR-Model)对多尺度关键点热力图进行全局优化,以提高估计姿态的结构一致性。通过考虑所有尺度上的热力图进行姿势优化,可以从回归网络中学习这些先验知识。该模块以多尺度热力图作为输入,通过 1 ×1 卷积后可以有效地将所有尺度上的热力图进行融合,以细化估计的姿态。多尺度回归模块根据多尺度特征确定人体关键点之间的连通性,共同优化整体结构形态。具体结构见图2。
1.3 坐标提取
推理时,大多数现有方法使用函数argmax来获取热力图中的关键点位置并转换为全分辨率,argmax的结果是离散的,只能是整数,这限制了最终预测坐标的精度。Luvizon等[11]尝试使用soft-argmax技术来回归最终坐标,使整个过程可微。
将真实热力图归一化到 [0,1]区间内,这意味着会有大量接近零的值,可能会影响soft-argmax的精度。
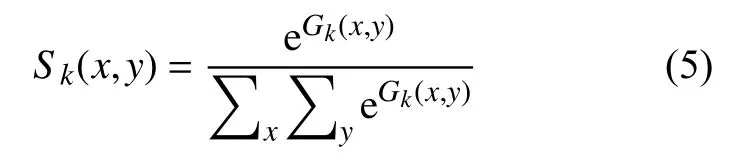
由于 e0=1 , e1=e ,热力图中大量的零会降低产生最大值的概率,进而影响结果的准确性。本文在Gk(x,y) 之前引入系数 β 来抑制接近于零的值的影响。可以用下式来表示:

经过大量实验,最终将 β 值设定为160,此时性能是最优异的。将改良过的soft-argmax用于从单人姿态估计网络输出的热力图中提取关键点坐标,进一步提高了最终预测的准确性。
2 实 验
2.1 数据集
MPII数据集由大约25 000幅多人图片组成,提供大约40 000个带注释的人体样本,其中约25 000用于训练,约3 000作为验证集进行评估,约11 000用于测试,每个人体样本由16个关键点表示。COCO 2017训练集有57 000幅图像包含150 000个人体实例,COCO 2017验证集包含5 000幅图像,test-dev集包含20 000张图像,关键点个数为17。
2.2 评价指标
主要评价指标有mAP和PCKh。mAP(平均精度均值)是基于对象关键点相似度(OKS)的评价指标,例如AP50代表目标关键点相似度(OKS)为0.50,mAP表示OKS分别为0.50,0.55,...,0.95时对应的AP的平均值。PCKh是另一种评价指标,代表以真实头部边界框对角线长度为归一化参考的关键点正确估计的比例,如PCKh@0.5表示预测关键点与对应的真实关键点位置距离小于真实头部边界框对角线长度的50%则被认为是正确预测的。OKS的具体定义为

式中:p为真实的人的ID;i表示关键点的ID;dpi表示预测关键点与真实关键点的欧氏距离;Sp表示当前人的尺度因子,即人在真实情况中所占面积的平方根; σi代表第i个关键点的归一化因子;vpi代表第p个人的第i个关键点是否可见; δ 是用于将可见点选出来进行计算的函数。
2.3 实施细节
首先在MPII数据集上对单人姿态估计网络进行训练。MPII多人图片中每个人体实例都有一个中心点标签和一个尺度因子,根据这两个数据将人体附近的区域进行裁剪并将其大小调整为256×192像素,在此基础上,本文使用了-30°~30°的随机旋转,0.7~1.30的随机尺度水平翻转进行数据扩增,将扩增后的图片块送入SPPE训练。本文程序使用PyTorch框架来实现,随机初始化模型参数,使用Adam算法,初始学习率设为10-4。对MPII训练集子集的25 000个人体实例进行100个epoch的训练,即在训练batch设为30的情况下训练60个epoch,没有给学习率设置权重衰减,之后手动加载训练好的模型,更改学习率为10-5,又训练40个epoch。在2块NVIDIA GTX1080Ti显卡上共训练了4天。在包含3 000个人体实例的验证集上进行评估,确保单人姿态估计网络性能有提升后再进行下一步训练。
将预训练好的单人姿态估计网络用COCO数据集继续进行多人姿态估计训练。由于COCO 2017训练集的图片自带人体边界框的标签数据,因此可直接按人体边界框进行裁剪,后续操作和在MPII上训练时一致。不过本文是将训练集和验证集放在一起进行训练的。最后将YOLOv3与SPPE相结合,在COCO 2017 test-dev集和MPII测试集分别进行测试。
2.4 结果分析
2.4.1 改进措施的有效性分析
在MPII验证集上对改进的模块进行消融实验,直接使用Simple Baseline基准模型进行测试时,模型参数量约为3.4×107,对检测速度影响很大,而且平均PCKh@0.5只有87.8%。本文先对残差块进行改进,缩减残差块的输入输出通道数、引入深度可分离卷积并将特征图分组处理后,参数量大幅度下降,约为8.4×106,而同时PCKh@0.5得分却有0.8%的提升,说明改进后的残差块特征提取能力确实得到提升。随着多尺度监督模块和多尺度回归模块以及β-Soft-Argmax的引进与改良,总体参数量仅有约2×105的微小提升,却分别带来0.6%、0.3%和0.2%的性能提升,最终平均PCKh@0.5达到了89.7%,性价比很高。具体实验过程见表1,√代表使用或者引进某模块,×代表未使用。可以清晰地看出各改进措施带来的变化,在参数量大幅降低的同时,也意味着检测速度的提升,与此同时模型检测精度也不断提升,充分证明了本文算法的有效性。
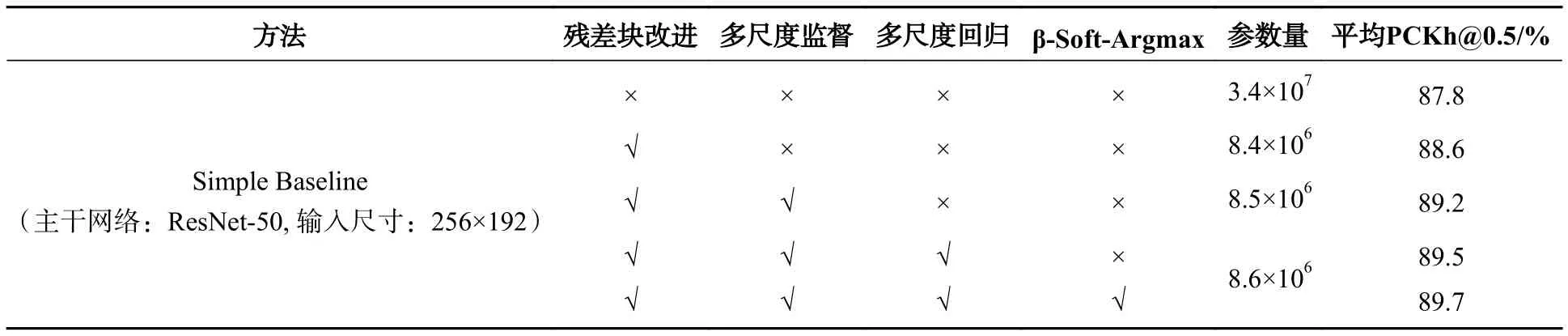
表1 MPII验证集上 PCKh@0.5 性能对比Tab.1 Performance comparison of PCKh@0.5 on the MPII validation dataset
2.4.2 MPII数据集结果
表2是本文提出的算法与一些流行算法在MPII测试集上的性能对比。可以清楚地看到,本文提出的算法是非常高效的,PCKh@0.5得分达到了92.1%,虽然和最先进的算法相比较还有一定差距,但在个别关键点例如腕关节和踝关节处,本文提出的算法识别精度超过了现有最优秀的算法,具体比较见图4。图5是本文算法在MPII数据集上对单人进行姿态估计的推理结果,可见检测的精度相当高。图6是本文算法在MPII数据集上对多人进行姿态估计的推理结果,由于采用YOLOv3作为人体检测器,因此对于较小的人体实例也有很好的检测效果。

表2 MPII测试集上 PCKh@0.5 性能对比Tab.2 Performance comparison of PCKh@0.5 on the MPII testing dataset
2.4.3 COCO数据集结果
图7所示为本文算法在COCO数据集上的一些单人推理结果。对于常见的身体姿态,检测结果优异。表3是本文提出的方法与一些流行方法在COCO数据集上的性能对比。需要注意的是,在以ResNet为主干网络的各类算法中,本文算法采用较小的输入就能获得相当高的mAP得分,mAP达到了72.4。尽管本文算法检测精度性能不是最先进的,但模型的参数量较小,因此推理速度优势明显。图8所示为本文算法在COCO数据集上的一些多人骨架推理结果,可以看出在人群密集情况下,对于部分遮挡的人体,本文算法依旧可以较准确地预测出人体关键点,但若人体肢体出现严重的缺失或者是遮挡时依旧会出现混乱的预测。这是由于经YOLOv3检测并裁剪的人体边界框内存在部分不可见的人体肢体,因此SPPE检测关键点失败,这是可以理解的。

图4 MPII测试集上腕关节、踝关节处 PCKh 比较Fig.4 Comparison of PCKh at wrist and ankle on the MPII testing dataset

图5 MPII数据集上单人推理结果Fig.5 Inference results of a single person on the MPII dataset

图6 MPII数据集上多人推理结果Fig.6 Multi-person pose inference results on the MPII dataset

图7 COCO 数据集上单人推理结果Fig.7 Inference results of a single person on the COCO dataset

表3 COCO 2017 test-dev 集上 AP 性能对比Tab.3 Comparison of AP performance on COCO 2017 test-dev dataset

图8 COCO 数据集上多人推理结果Fig.8 Multi-person pose inference results on the COCO dataset
3 结 论
本文遵循自顶而下的方案,提出了一种用于图片输入的多人姿态估计算法,采用YOLOv3作为人体检测器;基于深度残差网络(ResNet),通过改进基础残差块大幅度降低了参数量并提高了特征提取能力,另外通过多尺度监督模块和多尺度回归模块进一步融合了不同尺度热力图之间的信息,有效加强了中间过程的监督;改良过的坐标提取方式使得模型的梯度流可以从坐标点流动到高斯热力图上,使得模型端到端可训练,缩短了模型推理时间,同时提升了人体关键点预测的精度。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
英语文摘(2021年4期)2021-07-22
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
现代临床医学(2019年4期)2019-09-10
中学历史教学(2017年12期)2018-01-19
数学物理学报(2017年5期)2017-11-23
现代检验医学杂志(2015年6期)2015-02-06
中国卫生(2014年2期)2014-11-12
