
基于自注意力序列模型的唇语识别研究
2021-07-16 14:05王媛媛吴开存
电子器件 2021年3期
王媛媛,王 沛,吴开存
(1.盐城工学院信息工程学院,江苏 盐城 224051;2.东南大学网络空间安全学院,江苏 南京 210096;3.东南大学信息科学与工程学院,江苏 南京 210096)
唇语识别是一项通过唇部视觉信息来推断视频中语音内容的任务。其在实践中具有许多关键应用,例如辅助提升语音识别性能[1],活体检测[2],改进助听器等。唇语识别任务的关键在于如何有效地捕捉唇部运动信息,同时减小由光照条件、头部姿态、说话人外表等因素而产生的噪声。
唇语识别任务存在很多难点和挑战。首先,不同语句的唇部运动差异极其微小,细粒度特征难以捕捉;其次,不同说话人的语速不同,同一段语句的时长也可能不同,需要解决长短时依赖问题;此外,上下文的冗余信息会不可避免地带入到当前语句中,影响最终的识别结果。传统的方法分为多个阶段,包括嘴唇检测,特征提取和分类器分类。其技术核心主要包括用HOG 等特征提取算法捕捉嘴唇的几何特征,利用隐藏马尔科夫模型(HMM)识别特征序列。这类方法在特征提取和时序建模方面的效果都极其有限,不具备实用性。近年来的研究中[3],卷积神经网络(CNN)可以很好地学习到与视频序列的空间特征,配合LSTM 等循环网络在时序上的建模,在唇语识别任务上取得了一定的成果,但是仍然存在一些缺点,比如不能抵抗明暗光线、皱纹、胡须等因素带来的视觉噪声,以及语速和词语边界冗余信息带来的时序建模困难的问题。
为了解决这些问题,本文设计的STCNN +Bi-GRU+Self-Attention 模型,充分考虑了唇语识别任务的复杂性和多样性。一方面,STCNN 可以有效抑制视觉噪声,提取图像序列的高维特征;另一方面,以Bi-GRU 作为时序模型,搭配Self-Attention 辅助训练,可以增强关键帧的语义表示,避免时域全局平均带来的语义损失。最终,本文在LRW 数据集[4]和LRW-1000 数据集上[5]评估了所提出的方法,结果表明,在不使用额外数据和额外预训练的情况下,与先前的方法相比,本文所提出的方法在上述两个基准数据集上达到了最先进的水平。
1 基于STCNN-GRU 的唇语识别基础框架
唇语识别模型的基础框架包含两个阶段。第一阶段是检测人脸,根据人脸特征点得到嘴唇区域,使用CNN 提取嘴唇图像序列中每帧图像的时空特征向量;第二阶段使用循环神经网络对各帧图像特征的时序关系建模,并使用全连接层作为分类器进行分类[6]。如图1 所示,输入张量的维度是B×T×H×W,每个维度分别对应批次、帧、高度和宽度。令X=(x1,x2,…,xT)表示T帧输入图像序列,其中xi为第i帧的特征向量。该模型的任务是将输入序列X分为N类之一,其中N为类别总数。令Y=(0,0,1,…,0)表示序列的带注释单词标签。经过端到端训练,得到时序特征序列对应的音素,字符或词语。

图1 唇语识别模型的基本框架
1.1 前端模块
前端模块的主要任务是提取图像序列特征,该部分由时空卷积[7]网络(STCNN)、ResNet18[8]和全局平均池化(GAP)[9]构成。与传统卷积神经网络相比,STCNN 可以同时跨时间以及空间维度进行卷积来处理视频数据。令输入为x,权重为w∈,则STCNN 可以表示为:

STCNN 将直接作用于原始图像序列,以执行序列中的时间空间对齐。然后进行空间池化以压缩空间域中的特征,在此过程中不执行时间下采样,以避免进一步丢失序列的运动信息。这是因为每一类别单词的持续时间总是很短。接下来将特征按照时长T分为T个部分,并且对每个时间步长t=1,2,…,T分别使用ResNet18 提取判别特征,在提升通道数的同时,捕获图像的语义信息。最后在卷积层末端使用GAP,得到B×C×T的特征输出,其中C是最后一层卷积的通道维度。
1.2 后端模块
后端模块的主要任务是对时序关系建模,由双向门控循环单元[10](Bi-GRU)和全连接层构成。从前端模块得到的特征序列以正常顺序输入一个GRU,并以相反顺序输入另一个GRU,两组输出在每一个对应的时间位置连接在一起,以表示整个序列。Bi-GRU 的输出是整个输入序列的全局表示,可以表示为H=[h1,h2,…,hT],其中H∈Rd×T,d是GRU 的隐藏层数量,ht表示第t时刻的输出。最后使用全连接层线性变换将特征向量H映射为维度为N的特征向量O,N表示类别总数。通过Softmax激活函数得到每一类别的概率作为模型最终输出,并使用交叉熵损失函数计算神经网络的损失Loss,如式(2)所示,其中表示第i个类别的预测概率,Yi表示真实的one-hot 标签值。

2 时域自注意力机制
在每个序列中,不同帧提供的有价值的信息量是不等的。受到说话人语速的影响,一段唇语视频中,仅有少数几帧是关键帧,对最终识别结果有极大影响,而其余的特征序列则对最终结果的贡献较小。除此以外,在实际情况中,输入的字词片段也难免会带来邻近词语的冗余信息,这给时序建模带来了极大的困难。如图2 中的一个完整视频样本所示,该样本的18 帧图像中,只有中间的9 帧代表了样本标签“国际”这个词语,而前5 帧和后4 帧分别是来自上下文词语的冗余信息。

图2 标记为“国际”的一个样本视频
对于单个单词、短语或句子,获取完全精确的起始和终止边界位置是极其困难的。一个好的唇语识别模型应该能够学习到来自不同视频的关键信息。现有的方法,通常是对每个序列的所有时间步长上的特征赋予相同的权重[3,11-12],这在实践中将会在一定程度上损失精度。一个单词的关键信息往往隐含在某一段或几段连续帧中,因此有必要让模型能够辨识重要的关键信息,采用不同的权重进行时序建模。在Seq2seq 模型中,Transformer[13]被广泛应用并取得了良好的成绩。这主要得益于Transformer中的自注意力机制(Self-Attention)。为了更好地解决上述问题,本文将改进的自注意力机制与GRU 结合,将其引入到唇语识别任务中。本文所使用的Self-Attention 结构如图3 所示。

图3 时域自注意力机制的结构
其中Q(Query)、K(Key)和V(Value)均由前端模块的输出向量线性变换生成,接着通过点积和Softmax 运算得到时域特征的权重,再反馈到后端网络中,点积自注意力机制的公式如下:

F这个权重表示每一时刻唇部的特征和当前模型输出结果的相关性,通过时域自注意力机制可以保证一些更重要时刻的唇部特征能够更好地被关注,提升有用的特征,抑制对当前任务无用的特征。
综上所述,本文提出的基于自注意力序列模型的唇语识别方法如图4 所示,由以下几个步骤构成:

图4 基于自注意力序列模型的唇语识别方法
(1)从原始视频中提取多帧图像,检测视频中的人脸特征点位置,并裁剪出嘴唇及周边区域,组成多帧分辨率为88×88 的唇部图像序列,作为模型的输入;
(2)将唇部图像序列输入前端模块,经过STCNN、ResNet18 和GAP,提取出维度为512 的时序特征序列;
(3)使用时域自注意力机制,对上一步骤中的特征序列进行相关性计算和特征加权;
(4)将加权后的特征序列输入后端模块,经过双向GRU 和全连接层分类,得到代表样本类别的one-hot 向量。
3 实验分析
3.1 数据集
实验使用了领域内两个大规模单词级唇语数据集LRW 和LRW1000 作为评判基准。LRW 是一个单词级英文唇语识别数据集,包含BBC 电视节目中的音视频数据共500 类单词,每个分类有1 000 个实例。LRW 是一个具有挑战性的数据集,并已被大多数现有的唇读方法广泛使用。LRW1000 是目前最大规模的中文词语级别的唇读数据集,共有1 000类中文词语,70 000 多条样本实例。其数据采集于CCTV 电视节目,涵盖了各类的说话条件,包括照明条件、分辨率、姿势、性别、化妆等。
3.2 实验设置
将两个数据集样本的各帧以嘴唇为中心裁切或调整到96×96 作为输入,接着随机选择位置裁切到88×88 作为数据增强。STCNN 层的卷积核大小和步长分别设置为(5,7,7)和(1,2,2)。ResNet18 模块的卷积核大小为(3,3,3),一共18 层,包含5 次下采样和1 次GAP,各层之间都使用了Batch Normalization[14]。每个GRU 的隐藏层有1 024 个单元,一共3 层Bi-GRU。Self-Attention 模块使用了Multi-Head,head 的数量通过多次实验对比确定。使用Adam 优化器,学习率初始化为0.001,每轮衰减为0.5 倍。所有的GRU 层和全连接层都使用dropout来减轻过拟合。
3.3 结果分析
为了评价模型的性能,本实验以模型在LRW和LRW1000 数据集上的测试集准确率作为评价指标。在模型所有的预测结果中,如果最大概率值的类别与样本实际类别相同,则认为预测正确,Top1准确率为预测正确的样本数量与总样本数的比值。
如表1 所示,在两个主流数据集上,本文提出的基线模型准确率分别为82.04%和38.31%。在使用了Multi-Head Self-Attention 之后,准确率相比基线模型分别提升了2.75%和2.27%。实验结果表明,本文提出的STCNN+Bi-GRU+Self-Attention 模型优于先前最先进的其他方法。

表1 不同模型在LRW 和LRW1000 的Top1 准确率
3.4 时域自注意力机制效果评估
为了验证时域自注意力机制对唇语识别任务的贡献,本文计算了head =0(不使用Attention)到5 的情况下,模型在LRW1000 数据集上的准确率。结果如图5 所示,引入了Self-Attention 相比原来的基线模型,准确率大幅提升,且随着Attention head 数量的提升,准确率也不断提升。但是当head≥4 时,模型的准确率提升幅度有限,且带来了更多的训练参数,因此本文的最终模型使用了head 为4 的自注意力机制。
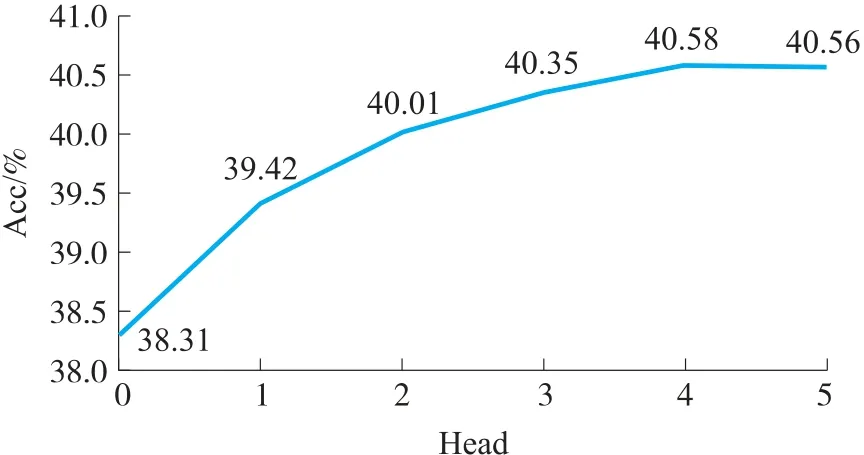
图5 Attention head 值对模型准确率的影响
4 总结
本文具体分析了目前唇语识别任务面临的挑战和难点,提出了基于自注意力序列模型的唇语识别方法。经过详细的实验以及与先前模型的对比,验证了本文提出的模型在唇语识别任务上优越性,同时也证明了时域自注意力机制在时序建模方面的有效性。
猜你喜欢
中国农业信息(2021年3期)2021-11-22
作文通讯·高中版(2019年11期)2019-09-10
文学港(2019年5期)2019-05-24
下一代英才(酷炫少年)(2018年12期)2018-12-29
测控技术(2018年11期)2018-12-07
中国信息化周报(2018年3期)2018-01-31
电子制作(2017年13期)2017-12-15
电子制作(2016年15期)2017-01-15
系统工程与电子技术(2016年7期)2016-08-21
西北工业大学学报(2015年4期)2016-01-19
