
变分推理的概率高斯/非高斯过程监测
2021-07-30 07:57任珈仪任世锦潘剑寒杨茂云李新玉
电子设计工程 2021年14期
任珈仪,任世锦,潘剑寒,杨茂云,李新玉
(1.南京邮电大学理学院,江苏南京 210023;2.江苏师范大学计算机学院,江苏徐州 221116;3.中国矿业大学机电工程学院,江苏徐州 221116)
随着现代流程工业不断朝着复杂化方向发展,稳定的工业产品质量和安全高效的生产成为科研技术人员和企业管理者主要关注的问题。近年来,基于数据驱动的过程监测理论和技术能够通过生产和工艺数据分析快速帮助操作人员和工程师了解生产过程相关知识,及时处理异常现象,在实际应用中取得了较好的效果,受到人们的普遍关注[1-4]。典型的过程监测方法主要有主元分析、偏最小二乘、高斯混合模型等统计分析方法。另外,流形学习具有描述数据几何结构的强大能力,在非线性维数约简、描述数据局部特性的方面具有出色表现,也是提高故障诊断的准确性和可理解性的可行方法[5-6]。另外,流形学习与其他统计分析技术进行结合,可以提高统计分析方法描述数据几何结构的能力,能够更好地刻画数据总体分布,这也成为流形学习研究的重要方向,极大扩宽了流形学习的应用范围[7]。
高维过程数据的本质特性往往可以由隐藏低维空间的数据描述,另外,过程工况切换、外部环境干扰等因素会导致测量数据具有明显的随机不确定性。近年来,隐变量模型技术在高维数据信息提取方面的优势以及概率图理论对随机数据建模的强大能力已经成为过程故障检测和软测量建模的重要方法,已在实际应用中取得满意的效果[8]。一般来说,过程变量集往往由高斯分布变量与非高斯分布变量组成,不同过程变量的噪声水平可能有所差异。即使在过程平稳运行状态,仍然有部分过程变量服从非高斯分布。然而,一些过程监测算法仍然假设过程(隐)变量服从高斯分布,这种假设会影响过程监测精度[9-10。]独立成分分析(Independent Component Analysis,ICA)与主元分析(Principal Component Analysis,PCA)分别用于描述非高斯数据和高斯数据,文献[11]提出KICA-PCA 的两阶段非线性过程在线监测算法,利用学生t-分布能够近似高斯/非高斯分布。文献[3]提出了基于t-分布的PICA 算法,并在此基础上提出了两阶段概率ICA(Probabilistic ICA,PICA)与概率PCA(Probabilistic PCA,PPCA)方法,分别提取数据中高斯和非高斯成分,有利于理解运行模式。上述抽取高斯/非高斯成分方法均通过两阶段方法抽取不同类型成分,并且假定各个变量噪声水平相同,无法同时抽取高斯和非高斯成分。
基于上述讨论,考虑到隐变量模型在数据降维和信息提取的优势以及概率图理论描述随机数据的有效性[12-14],设计一种基于学生t-分布高斯/非高斯成分提取框架,并用于过程故障诊断。该方法使用变分推理(Variational Inference,VI)自动确定模型参数和模型选择,保证了模型性能的提高。该方法还能够同时提取过程的高斯/非高斯成分,实现两种成分的折中平衡,提高了混杂过程的信息提取能力。文中建立了高斯/非高斯以及残差空间的故障监测统计量,有利于提高工业过程的安全性和认识水平。最后,使用TE 模型对提出算法进行仿真验证,结果表明,所提出的模型能够有效运用于高斯/非高斯分布过程监测,且具有良好的鲁棒性。
1 高斯/非高斯成分概率模型
假设隐变量和观测变量x之间具有如下线性关系:

其中,P∈ℝD×d为类似PCA 负荷矩阵的权重矩阵,且满足PTP=Id∈ℝd×d;t∈ℝd×1为服从正态分布N(0,Id)的隐变量;Id为单位矩阵且d<D;观测噪声ε服从高斯分布N(0,Λ-1),Λ=diag(β,β2,β1) ;s∈ℝr为相互独立的非高斯信号源,满足。由式(1)可以看出,观测数据的变化能够由隐空间中非高斯和高斯成分表示,由此可以更好地理解过程机理。值得注意的是,非高斯信号和高斯信号是相互独立的,定义如下隐变量先验和观测变量条件分布形式:

其中,Λ为对角矩阵。传统方法假定多个高斯混合可以近似非高斯信号,但是混合信号的数量难以确定。由于t-分布可以看作无限多个不同高斯分布信号的混合形式,因此可以使用t-分布表示非高斯信号[9]。在实际中,通过调节自由度值使得t-分布近似非高斯分布。非高斯源信号的每个维度变量sk的分布形式为:

在介绍推理方法前,先给出文中模型概率结构图,如图1 所示。定义隐变量集合Δ={T,S,U},其余模型参数记为Θ,由图1 可以看出变量之间的依赖关系,对数完全似然函数形式为:


图1 高斯/非高斯混合概率模型结构图
无法直接求取似然函数最大优化问题的闭解,MCMC 和贝叶斯变分推理方法是关于学习参数后验分布的常用方法。由于MCMC 存在计算效率以及收敛性问题,因此文中使用贝叶斯变分推理方法(VI)学习参数的后验分布。
2 变分推理的模型参数学习
基于变分理论[15],对数完全似然函数具有如下关系:


在实际中,将隐空间的方差约束为单位方差进行分析,每个隐空间的方差与自由度关系一般满足。实际中定义自由度的最小取值为vk=2.5。ICA 维度采用交叉验证方法确定,即首先使用范数进行维度范围的初选,然后使用交叉验证并结合模型的复杂度来进行进一步选取。使用PPCA 对矩阵P进行初始化,其他参数可以通过随机初始化获取,这样可以大大提高算法的收敛速度。
3 故障检测统计量的构建

其中,a为置信度,dt为高斯隐变量的维数,D为观测数据维数。使用核密度估计方法计算非高斯成分监测统计量I2的控制限,控制置信度同样设置为a。
4 仿 真
为了评价所提出方法的有效性,仿真实验使用Tennessee Eastman(TE)测试仿真平台。该平台是一个典型的化工模型仿真平台,系统由连续搅拌式反应釜、分凝器、气液分离塔、汽提塔、再沸器和离心式压缩机等操作单元组成,常用故障监测仿真见文献[3]。TE 过程的流程示意图如图2 所示。

图2 TE过程流程示意图
TE 过程共有41 个测量变量和12 个操控变量,选取与文献[11]相同的22 个变量作为故障监测变量。训练样本和检测样本的采样间隔均设定为3 s,采集960 个过程平稳状态样本作为正常训练样本。过程平稳运行8 h 之后加入故障,整个采集过程中系统共运行48 h,共采集960 个样本点。在建模阶段,对所有样本均归一化预处理。根据模型训练结果,采用交叉验证方法确定了27 个维度的隐空间。考虑到几个隐变量自由度相差较小的情况,文中选取自由度大于40 的隐变量作为高斯分布变量,非高斯成分数量为8,高斯成分数量为19,置信度取99%。对于难以准确检测的故障3 和故障9,利用文中方法进行检测。从图3 可以看到,文中方法的3 个统计量均能够检测到过程的变化,并能够准确指示过程故障。同样,由图4 可知,文中模型能够检测到故障9。上述故障检测结果表明,3 种监测统计量可以相互补充,从而有效提高系统的故障检测性能。
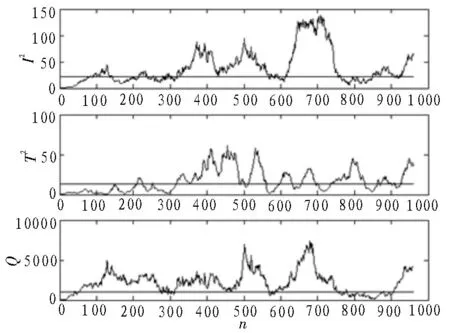
图3 文中方法故障3仿真结果

图4 文中方法故障9仿真结果
为了进一步说明文中方法的有效性,表1 中列出了使用文中方法与ICA-PCA、PICA-PPCA 方法检测故障3 和故障9 时各个统计量检测结果。从表1可以看出,文中方法的Q统计量获得了最好的检测效果,对于检测过程中的微小、潜在故障的效果是明显的,漏检率低于其他监测方法,也在一定程度上提高了过程运行的安全性。

表1 故障3和9的检测结果
5 结论
针对高斯/非高斯混杂过程鲁棒建模问题,提出了高斯/非高斯成分抽取统一框架,克服了现有两阶段高斯/非高斯信息抽取算法存在的计算量大及忽略了两类信息的关联性等缺点。文中详细给出了变分推理算法学习模型参数方法,自适应确定独立成分数量和高斯成分数量,克服了现有方法忽略两类信息的关联性问题。最后在TE 平台对难以检测的故障3 和故障9 进行了仿真实验,并与其他方法进行对比。仿真表明,所提算法能够准确抽取高斯/非高斯信息,故障检测统计量之间具有一定的互补性,表现出很好的建模和监测效果,具有很好的鲁棒性能。
需要注意的是,文中方法为线性特征抽取方法,对于动态非线性系统还需要对该方法进行进一步改进,比如利用核技巧、混合建模方法改进文中方法,拓宽算法的适用场合。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
数字通信世界(2021年3期)2021-04-09
河北理科教学研究(2020年2期)2020-09-11
湖北理工学院学报(2020年4期)2020-08-22
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
计算机应用与软件(2017年4期)2017-04-24
电影故事(2015年16期)2015-07-14
新高考·高二数学(2014年7期)2014-09-18
网络安全与数据管理(2011年11期)2011-02-28
