
基于深度学习的道路语义分割新方法
2021-08-03 02:58薛振彦程晋炳
南阳师范学院学报 2021年4期
薛振彦,惠 明,程晋炳,董 昊
(1.南阳师范学院 物理与电子工程学院,河南省MXene材料微结构国际联合实验室,河南 南阳 473061;2.南阳师范学院 美术与艺术设计学院,河南 南阳 473061)
0 引 言
具有自动驾驶技术的智能汽车是当下科学技术发展的热门研究内容,其中,对车载自带图像采集系统所得到的道路图像进行精准的语义分割,是智能汽车自动驾驶中的关键技术之一.
针对图像语义像素级的分割问题,J.Long等人提出FCN神经网络结构,即全卷积神经网络(Fully Convolutional Networks).FCN模型成为当前语义分割领域中最常用的网络模型之一.FCN是由CNN网络改进得来的.CNN网络一般在卷积层后加上几层全连接层,将图像信息压缩成一个固定尺度的特征矢量,并最终输出一个图像级别分类结果的一维长度的值.而FCN模型将CNN末端的全连接层去掉,利用反卷积方式对最后一层卷积层进行上采样,进而使模型的输出维度恢复到与输入图像尺寸相同的程度,从而实现对像素进行预测分类.本文在FCN网络的基础上提出一种先验概率层的后处理方法,并与传统的全卷积神经网络模型(FCN)相结合实现道路图像的语义分割.先验概率层利用道路图像的先验知识,在所有道路图像训练标签的基础上表示各像素点分类概率的二维数组,并将它与传统全卷积神经网络模型相结合对道路图像进行语义分割.实验结果表明本文提出的先验概率层的后处理算法能够优化传统全卷积神经网络模型的分割效果.
本文的主要工作包括以下几个方面:
(1)针对传统FCN模型算法分割精度较低的缺陷,提出一种新的思路:根据道路图像的特殊性(道路总处于图中央下方的特定位置),对图像中的每个像素值附上一个特殊值表示其分类先验概率,以此来提高FCN模型对道路图像的语义分割结果.
(2)基于KITTI数据集,利用tensorflow开源神经网络框架对本文的神经网络框架进行训练学习,确定参数.
(3)将本文方法应用于真实道路图像识别实验,对实验结果进行分析,验证后处理概率层模型的优化性能.
1 相关工作
图像分割主要是通过提取图片的低级特征进行简单的图像分割,常用的方法有:基于目标函数的模糊C-均值算法(Bezdek,1981)[1],“Normalized cut”分割方法(Jianbo Shi等,2000)[2].虽然这些方法能够考虑全局信息进行图像划分,但分割的结果不准确且不能对图像进行语义标注[3].
随着深度学习(Deep Learning)技术快速提升,卷积神经网络(Convolutional Neural Networks)[4]被提出并应用在图像分类与语义分割中.为了使卷积网络更好地应用于图像语义分割,许多研究人员对其进行改进和优化,提出多种用于语义分割的神经网络.全卷积神经网络(Jonathan Long等)[5]的提出解决了像素级别的图像分类,SegNet神经网络(Vijay Badrinarayanan等)[6]使用编码器与解码器的对称结构,并在解码器中应用最大池化指数,使该网络对分割分辨率有了些许改善.为解决池化操作所带来的图像信息丢失问题,DeepLab神经网络(Liang-Chieh Chen等)[7]被提出,该网络利用空洞卷积,并将其结合全连接条件随机场,提出金字塔形的空洞池化结构.然而空洞卷积结构拥有计算成本高、占用内存大的缺点.因此RefineNet神经网络(Guosheng Lin等)[8]被提出来以解决空洞卷积结构的缺点,该网络分割精度高,但是其网络比较复杂.
以上算法都是用于解决普通图像的语义分割问题,并不是专门针对某一类特殊图像的问题而设计的.因此,为使神经网络模型更好地用于解决道路图像语义分割问题,并且针对道路图像特有的性质,本文对全卷积神经网络模型进行改进,提出一种加入先验概率层的后处理方法,并将该模型用于道路图像语义分割,与传统全卷积神经网络算法对比分析,本文提出的模型提高道路图像的语义分割精度.
2 先验概率层的后处理算法
2.1 先验概率层的定义
实际的驾驶过程中,可行驶的道路一般都位于智能车摄像头所拍摄视野的中下位置.因此道路图像语义训练模型的道路图像中的道路都是处于图像的中下位置,本文利用道路图像的这个特点,构建先验概率层的二维数组,表示图像像素点的先验分类概率.
先验概率层的具体定义过程如下:
(1)先将训练集中每一张真实标签的每个RGB值转换成能表示分类结果的one-hot编码二维数组h*w,其中h、w为输入标签图像的高和宽,数组的每个值的结果为1或0,如图1所示,值为1代表该像素点分类为道路,值为0代表该像素点分类为非道路(背景).

图1 转换后的数据标签示意图
(2)接着将转换后的所有标签数组进行求和取平均(归一化),得到一个h*w的概率层(如图2、3所示),其每一个值的取值范围为0到1之间(包括0和1),值越接近1表示该像素点越可能为道路,值越接近0表示该像素点越可能为非道路(背景).

图2 概率层概念图
为了让概率层更加准确地分类每个像素的语义分割结果,需要对概率层进行一定的转换,使原概率层的每个数值减去0.5,得到最终的概率层,如图4所示.

图3 原概率层示意图

图4 转换后的概率层示意图
2.2 先验概率层的后处理算法
在模型预测测试集图像时,在模型的最后一层添加此概率层,并为此层分配一个影响因子,作为预测结果的后处理方法,以此来矫正原FCN模型预测的部分错误分类的像素.
当道路图像经过已训练好的神经网络模型后,会生成一个二维数组标签矩阵,如图5所示,其每个像素点取值为0到1.因此将每个像素点取值与0.5值相比,大于0.5则表示该像素点分类为道路,小于0.5表示该像素点分类为背景.而从图5可以看到,其中有两个像素点值分类错误,将背景预测成了道路,将道路预测成了背景.而在这种情况下,增加后处理概率层可以对预测结果进行影响干预.通过将预测结果中每个像素的预测值与概率层对应像素的数值相加,如图6所示,进一步增加道路区域的概率,减少背景区域的概率,从而实现对预测结果的纠正,在一定程度上提高道路图像语义分割的分割精度.从图6可看出,原本错误分类的两个像素点经概率层处理后,最终分类正确,且其他像素点分类结果也没有被改变.

图5 预测错误的标签矩阵
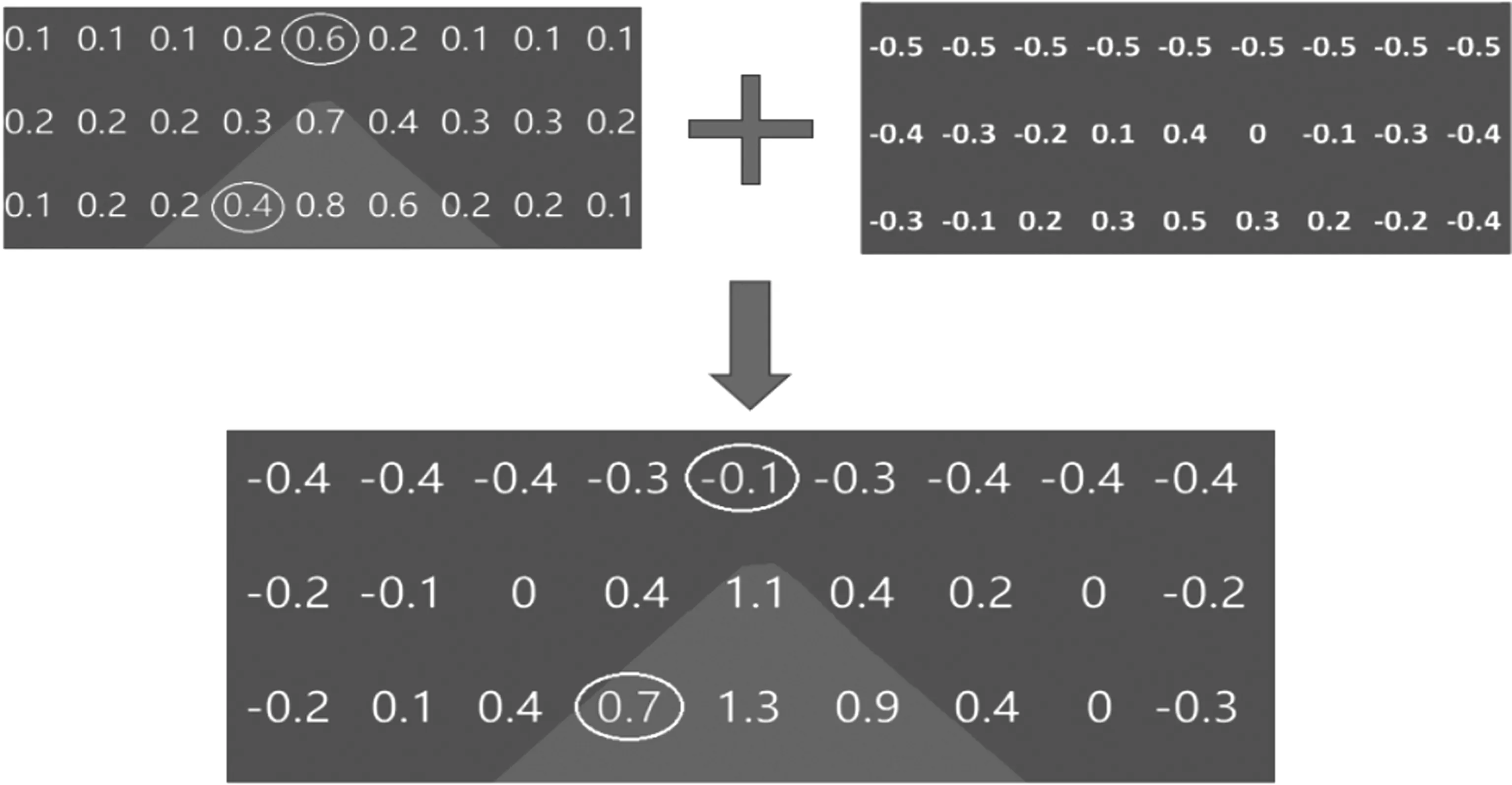
图6 概率层后处理过程示意图
3 实验与分析
本文的所有实验都是基于数据集KITTI[9]中的道路图像进行模型训练.数据集KITTI是由丰田公司美国芝加哥技术研究院和德国Karlsruhe理工学院于2012年合作采集创建的.KITTI数据集主要包括了高速公路、农村和都市等日常生活场景的图像数据,而该图像数据主要是通过搭载在一辆汽车上的彩色摄像头进行拍摄采集.在该数据集中,道路被标记成紫色(RGB值为[255,0,255]),而背景则被标记为红色(RGB值为[255,0,0]).本文一共使用289张图片,并将其大小裁剪为576*160,其中214张图片用作训练模型,75张图片用作测试验证.
3.1 实验过程设置
3.1.1 预处理:在实验开始时,首先需要对训练的图像和标签进行预处理操作.先对图片和标签进行裁剪;接着把标签图片转换成one-hot编码的向量数组,以此来表示对应像素所属分类;最后将训练图片与对应的标签划分成一个一个batch_size大小的batch,作为输入的训练数据.
3.1.2 搭建FCN网络模型.
3.1.3 训练模型:将神经网络的输出通过softmax函数进行归一化处理,并将处理结果和标签结果一同通过交叉熵函数并求平均,形成模型训练的代价函数;然后使用AdamOptimizer优化器朝代价函数下降方向对模型进行优化,并计算每次迭代的训练准确率,学习率设置为0.00001.
3.1.4 生成概率层:根据概率层原理,利用所有训练图片的标签生成一个能表示各像素点分类概率的二维数组.
3.1.5 模型预测:在模型训练完成后,将模型参数保存,然后输入测试图片到已训练好的模型中,并且利用概率层使其生成预测标签,再将预测的标签与真实标签进行对比,并求出其像素精度(PA)、平均像素精度(MPA)和平均交并比值(MIoU).
3.2 度量标准
为了深入分析实验结果,本文采用PA、MPA、MIoU[10]三种度量标准对结果进行定量分析.接下来会简单介绍每一种度量标准的计算方式,假设有k+1种类别需要分类,其中Pij代表第i个类别被预测为第j个类别的像素个数,Pii就意味着第i个类别被正确预测为该类类别的像素个数.
像素精度计算公式如下所示.
(1)
像素精度为图像语义分割中最简单的度量标准,从公式中可以清楚看出该度量标准即是所有被正确分类的像素数量占输入图像总像素的比例.
平均像素精度计算公式如下所示.
(2)
平均像素精度是像素精度的优化版本,其主要做法是先对每个类内部作像素精度的计算,接着对所有结果进行平均求值.
MIoU平均交并比值的计算公式如下所示.
(3)
平均交并比值是图像语义分割中最主要的度量标准,其做法是求解两个集合间并集与交集的比例,这两个集合即为预测标签集合和真实标签集合.该度量指标往往低于以上两者.
3.3 实验结果分析
为了验证本文算法在道路图像分割中的效果,主要用FCN模型和本文提出的基于先验概率层的后处理算法FCN模型进行对比,定性对比效果如图7所示.

图7 不同算法道路分割的结果对比
从图7可以看出,本文提出的基于先验概率层的后处理算法图7(d)对道路图像的分割效果,要比传统FCN模型算法图7(c)效果好一些.FCN模型在添加概率层后,分割出来的道路轮廓更加光滑,道路边界更加连贯完整.同时,在添加概率层后,可以去除一些不合理的离散点,使预测区域尽可能地连通,更加符合真实道路的情景.
接着,对这两种模型的预测结果进行定量分析,比较像素精确度、平均像素精度和平均交并比值,其结果表1所示.

表1 不同模型对道路图像的分割结果对比
从表1显示的结果可以清楚地证明本文提出的算法与传统的FCN模型算法相比,在分割精度上有一定的提高.后处理概率层可将像素精确度由88.8%提高到91.3%,提高了2.5个百分点;平均像素精确度由82.9%提高到85.7%,提高了2.8个百分点;平均交并比值由72.5%提高到77.9%,提高了5.4个百分点.
实验结果证明,概率层的运用可以提高模型对道路图像的语义分割效果.概率层记录道路图像中像素的分割类别先验概率,对图像中的每个像素值进行后期干预,以此来提高对道路图像的语义分割结果.
4 结束语
针对当前国际上FCN模型在道路图像语义分割算法领域的最新研究成果,本文根据道路图像的特殊性,通过添加道路图像先验概率层的思路开展了道路图像语义分割方法的研究.实验结果表明:相对于传统全卷积神经网络算法,本文提出的算法能较好地分割道路图像,精度更高,且可靠性较好,可用于道路图像语义分割.由于现有开源的道路图像数据集较少,本文算法没能在大量的道路图像中开展图像分割实验,后续将继续开展道路图像样本库和标签数据集收集建立工作,进一步验证本文算法在大量不同场景道路图像分割中的效果.同时,在概率层生成方法上,可以尝试进行tanh函数、sigmoid函数等非线性变化,探究线性变化与非线性变化间的差别与各自优缺点,使其能够适合更加复杂多变的道路图像.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
合肥工业大学学报(自然科学版)(2021年11期)2021-12-10
北京航空航天大学学报(2021年9期)2021-11-02
现代电子技术(2021年1期)2021-01-17
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
微型电脑应用(2019年1期)2019-01-23
北京航空航天大学学报(2018年1期)2018-04-20
电脑知识与技术(2018年35期)2018-02-27
长江学术(2016年4期)2016-03-11
