
变系数空间自回归模型的Bootstrap检验
2021-08-08 01:20李体政
工程数学学报 2021年4期
杜 颖, 李体政
(1-西安外国语大学经济金融学院,西安 7 10128;2-西安建筑科技大学理学院,西安 7 10055)
1 引言
近年来在对经济等领域问题的研究分析过程中,发现如犯罪率、社会互动、经济增长、溢出效应、同伴效应、价格竞争、税收竞争、房价、地价等重要的经济指标中普遍存在着空间相关性,而线性空间自回归模型是描述空间相关性的最经典和最流行的模型之一.有关模型的估计、统计推断及应用等方面的问题得到了深入研究[1-3].一方面由于线性空间自回归模型对回归函数的假设过于严格,当回归函数的设定不准确时就会产生很大的估计偏差,甚至可能会得到错误的结论.另一方面线性空间自回归模型忽略了空间数据中可能存在的动态特征,即响应变量与协变量之间的关系会随着某个变量(比如年龄、受教育程度、收入水平等)的变化而变化,因而不能有效处理具有动态特征的空间数据.针对上述问题,李坤明和陈建宝[4]通过假定线性空间自回归模型中的回归系数是某个协变量的未知函数,提出了变系数空间自回归模型,其形式如下

变系数空间自回归模型假定经典线性空间自回归模型中的常数回归系数为其他解释变量的未知函数,增加了模型的灵活性和适应性,同时由于系数函数通常被看作是某个自变量的一元函数而有效避免了拟合中因自变量维数增加而造成的维数灾难问题.更重要的是由于模型中的系数函数随着某个协变量的变化而变化,从而使得该模型能够有效挖掘空间数据中的动态特征.在实践中,模型(1)中的一些系数函数可能是常数,而其他系数与解释变量u有关.在这种情况下,模型(1)可以进一步简化为空间计量经济学中的半变系数空间自回归模型.从估计的角度看,半变系数空间自回归模型不能简单认为是变系数空间自回归模型的特殊情况,因为将常系数视为变系数会导致估计效率的损失.对于半变系数空间自回归模型,Wei等[5]提出了一种轮廓拟最大似然方法,该方法利用局部线性平滑法估计变系数,利用拟最大似然法估计常系数.Sun[6]也建立了一个基于半参数序列的最小二乘法估计方法分别估计变系数和常系数.尽管半变系数空间自回归模型的建立能更全面真实地描述响应变量与协变量之间的关系,但在实际应用中,我们首先应明确哪些回归系数可以假定为常数,仅凭对实际问题背景的了解做出符合实际的假设在很多情况下是困难的,甚至是不可能的,这就需要系统地检验变系数空间自回归模型中哪些系数函数是常数,解决这个问题将为半变系数空间自回归模型的确定提供理论依据.本文建立了一种确定变系数空间自回归模型中部分系数函数是否为常数的Bootstrap检验方法,利用在备择假设和零假设下关于系数拟合值的轮廓拟对数似然函数的差值构造了检验统计量,并且通过模拟实验考察了Bootstrap方法逼近其零分布的有效性以及统计量的检验功效.
2 变系数空间自回归模型及其轮廓拟最大似然估计方法
由于估计方法是检验的基础,在讨论参数的统计推断问题之前,我们先简单回顾一下变系数空间自回归模型的轮廓拟最大似然估计方法.


对于模型(2),文献[4]给出一种两步估计方法.
第1步 固定ρ,并整理模型(2),可得

其中Y(ρ)=T(ρ)Y.设β1(·),β2(·),···,βq(·)具有连续的二阶导数,则对任一给定的u0∈U,变系数模型的局部线性拟合为选择β(u0),使

这里Yi(ρ)是Y(ρ)的第i个分量,Kh(·)=K(·/h)/h,其中K(·)为给定的核函数,h为窗宽.
因此,求上述局部加权最小二乘问题的解可得到系数函数向量β(u)在u0处的局部线性估计

其中0q×q表示q×q零矩阵,
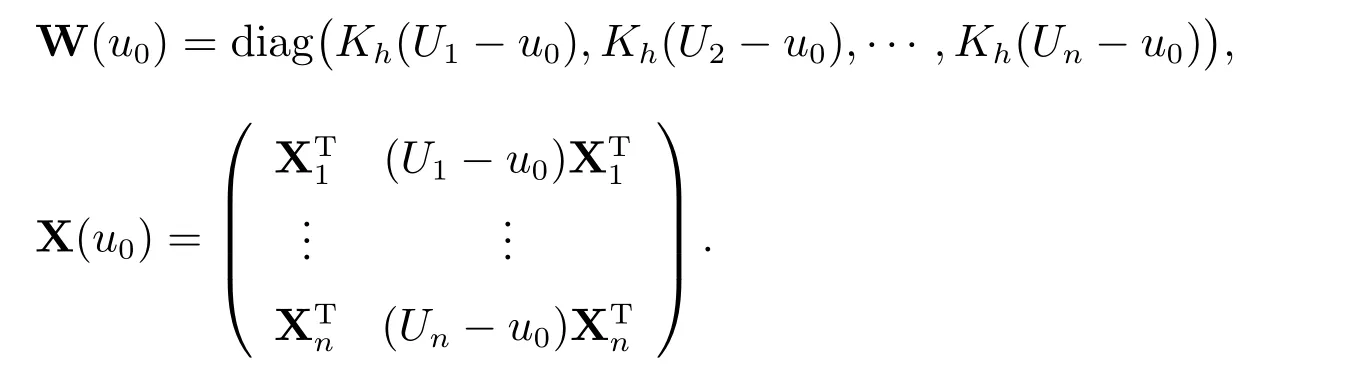
特别地,分别取u0=U1,U2,···,Un,对于给定的ρ,可得

其中

第2步 最大化下面的轮廓拟对数似然函数

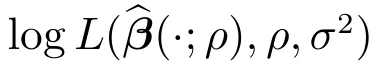

其中M1=(In−S)T(In−S).进而将结果带入式(7)中得到

3 基于残差项的Bootstrap检验
如前所述,对于变系数空间自回归模型,通常人们感兴趣的问题为,是否其中的某些系数可视为常数,因而有如下的假设

其中{i1,i2,···,ir}是{1,2,···,q}的一个非空子集,βi1,βi2,···,βir为未知常数.
3.1 检验统计量的构造
本小节中,针对上述假设,我们给出由在备择假设和零假设下关于系数拟合值的轮廓拟对数似然函数的差值所构造的似然比检验统计量.
在假设H1下,按照第2节介绍的方法拟合变系数空间自回归模型,可得到轮廓拟对数似然函数在此估计下的值

在假设H0下,模型(1)变成如下的半变系数空间自回归模型

其中
Ic={i1,i2,···,ir},Ic∪Iv={1,2,···,q},Ic∩Iv=φ.


下面通过简单介绍文献[5]的轮廓拟最大似然估计过程与结果来计算相应的半变系数空间自回归模型的对数似然函数值.首先,固定βc和ρ,并将模型(14)写成如下形式

根据文献[7]的局部线性光滑方法可以得到模型(15)中的系数函数的估计值,因而,对于给定的βc和ρ,可以得到Mv的估计值

其中
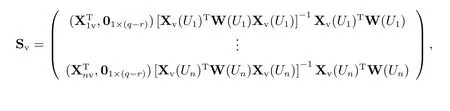

然后,对于任一给定的ρ,找到βc和σ2,使得
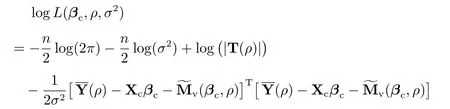
的值最大.求解上述问题可得βc和σ2的轮廓拟最大似然估计值如下

其中


则假设(11)下的似然比检验统计量为

其中当T过分偏大时,应拒绝H0.设t为T的观测值,则检验的p值为

上述统计量经常被用来比较两个相关模型之间的拟合优度问题[5,8,9].如果不考虑空间相关性取ρ=0,则检验统计量即为经典的广义似然比检验[10],并被广泛用于各种非参数和半参数回归模型的推断问题[11].Fan和Huang[12]指出用广义似然比检验方法进行假设检验时,除了原假设中模型的参数估计过程不需要选择窗宽的情形,其它情形在对零模型和备择模型的估计过程中应该选择相同的窗宽,否则窗宽的变动可能会使得零模型和备择模型的对数似然函数之间无法比较,从而导致检验成效的损失.此外,Fan和Jiang[11]以及Cai[13]提出,对于给定的数据集,由于原假设中的模型设定不确定是否正确,应该使用备择假设中拟合的结果来生成Bootstrap取样所需要的残差值.基于这两点考虑,本文在构造检验统计量(21)时,使用变系数空间自回归模型选出的窗宽对半变系数空间自回归模型进行拟合.
3.2 计算p值的Bootstrap方法
在计算统计推断的p值时,寻求检验统计量的零分布是首先要解决的重要问题.然而,由于模型中存在空间滞后项,使得检验统计量零分布很难精确得到.即使这个渐近分布能够得到,Fan和Jiang[11]指出在有限样本容量下有可能会导致错误的推断结果.众所周知,Bootstrap方法是一种非常有效的模拟统计量分布的再抽样方法,已被广泛应用于各种统计推断问题中[14,15],也是本文用以逼近检验统计量零分布的方法.
因而,关于p值的计算,由如下的Bootstrap方法实现:

其中



其中#A表示集合A中元素的个数.
3.3 有关Bootstrap检验方法的讨论
1) 此方法可用于全局回归关系平稳性检验,可以检验所有的系数函数均为常数的假设,即验证经典的线性空间自回归模型是否适用于所给的样本数据.此时原假设变为
H0:模型(1)中所有系数均为常数,
对应的是经典的线性空间自回归模型
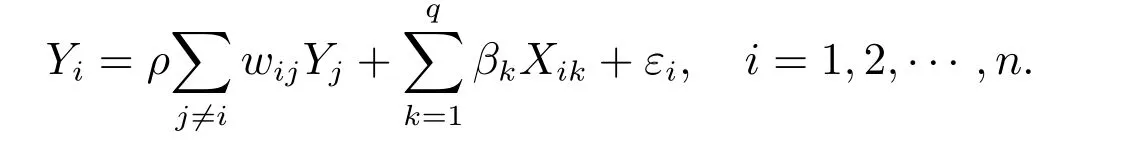
在此情形下,上述的零模型很容易由拟最大似然估计法来拟合.
2) 此检验方法可以进一步推广.尽管我们所构造的Bootstrap方法是用来确定变系数空间自回归模型中的常系数的,它还可以用于检验系数函数更复杂的结构.其中一个自然推广为检验一些系数是否为自变量u的一些已知函数的线性组合.对应的原假设为

这里对每个k∈{i1,i2,···,ir},θkl(l=1,2,···,Ik)为未知参数,fkl(u)(l=1,2,···,Ik)为已知的相互独立的,自变量u的线性函数,则原假设中假定部分系数是线性的或者是u的广义多项式函数均可以看作是(25)的特殊情形.在原假设下对应的模型为

若令
Zikl=fkl(Ui)Xik,l=1,2,···,Ik,k=i1,i2,···,ir,i=1,2,···,n,
则零模型可以进一步表示为

由于Zikl(l=1,2,···,Ik,k=i1,i2,···,ir,i=1,2,···,n)是已知的,故上述模型也是半变系数空间自回归模型.因而,所构造的检验方法可用于检验原假设(25).
检测方法的另一个推广是对一个半变系数空间自回归模型与另一个半变系数空间自回归模型之间的假设进行检验.在这种情况下,备择模型是一个半变系数空间自回归模型,原假设对应的模型可以有多种选择.例如,为了评估备择模型的常系数部分中的一些解释变量是否确实影响了响应变量,可以相对应的设置一个假定这些解释变量对应的系数均为零的原模型.
4 模拟试验
本节通过模拟试验考察Bootstrap方法的有效性,在观测值来自正态和非正态总体时分别考察检验方法逼近检验统计量零分布的精确性以及检验的功效.由于解释变量存在共线性会影响系数估计的结果,我们也考察了解释变量间共线性的存在对检验性能的影响.
4.1 试验设计
在试验中,在由l×l个方块组成的格点处选取观测值,这样样本容量为n=l2.空间权重矩阵W设为Queen矩阵.用以产生数据的变系数空间自回归模型为

这里wij表示W的(i,j)分量,Xi1≡1,Ui为产生于均匀分布U(0,1)的随机变量,(Xi2,Xi3,Xi4)T(i=1,2,···,n)为产生于N(0,Σ)的随机变量(其中Σ的主对角线元素为1,其它元素取值为γ).为了全面考察解释变量X2,X3以及X4之间的共线性程度对检验方法的检验效果带来的影响,我们分别选取γ为常数0,0.5和0.8以及

四种情形.同时为了考察空间相关性对检验的影响,空间滞后相关系数ρ取值为−0.9,−0.6,−0.3,0,0.3,0.6以及0.9.系数函数β1(u),β2(u),β3(u)以及β4(u)的选取如下
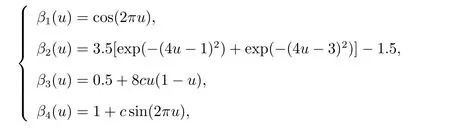
这里c是一个常数,通过对c的不同取值来评价检验的功效.注意,当c=0时,表示H0为真,而c̸=0时,表示H1为真,且H1与H0之间的偏差会随着c的绝对值的增加而增加.
为了考察误差项对检验方法有效性的影响,我们同时给出了下面四种常见的误差分布情况下的模拟结果:
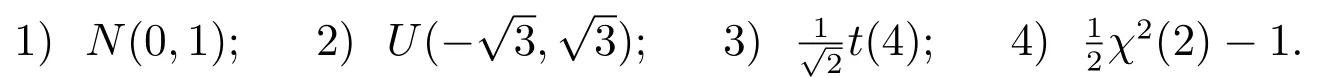
模拟中采用Gaussian核函数
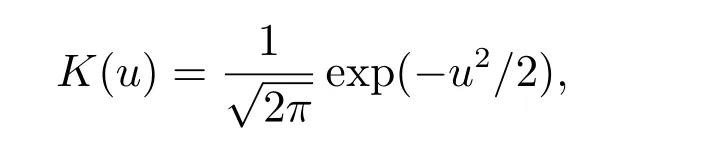
窗宽选择根据文献[5]采取ROT方法.
4.2 模拟结果分析
针对样本数n=102和n=132,ρ的七种不同取值,γ的四种不同取值以及四种不同的误差分布组合的每一种设定情形,重复试验N=500次,且每一次试验都将进行500次Bootstrap抽样模拟来计算统计量的p值.
1) Bootstrap方法逼近零分布的有效性
令系数函数β3(u)和β4(u)中的c=0,此时H0为真且β3(u)=0.5,β4(u)=1,则在原假设条件和每一种设定情况下,我们计算500次重复下的p值分别小于给定的不同显著性水平(即拒绝H0)的频率,其中p值是基于500次Bootstrap模拟计算得到的.拟合的结果展示在表1中.

表1 在Bootstrap检验拒绝H 0的频率

续表1 在Bootstrap检验拒绝H0的频率
由表1的结果可知,当H0为真时在所有的试验设定下,拒绝H0的频率非常接近于给定的显著性水平α的值.也就是说,即使在较小样本n=100时,Bootstrap方法都可以精确地逼近统计量T的零分布.我们发现不管是在正态的误差分布还是非正态的误差分布下,模拟结果没有明显差别,这表明对统计量T的零分布的Bootstrap逼近的表现对误差项的分布是稳定.同样,空间自相关参数ρ和解释变量之间共线性也没有表现出明显影响拒绝H0的频率的结果的情况.这些都说明了Bootstrap方法逼近零分布的有效性.
2) 统计量的检验功效
当c̸=0,则假定所有系数都是变系数的备择假设为真.在这种情形下,我们将β3(u)和β4(u)中的c分别取值为0.1,0.2和0.3.在显著性水平α=0.05下,分别计算N=500次重复下拒绝H0的频率,并以此模拟检验功效.拟合的结果展示在表2中.
由表2可以看出,随着样本容量的增加或者c的增加即备择假设与原假设模型之间的偏差加大,检验功效是逐渐增大趋近于1的,这表示所用的检验方法具有良好的检验功效性质.由表2,我们发现检验方法的表现对于我们所考察的四种正态和非正态情形下的误差分布,以及七个不同取值的空间滞后相关系数ρ,并没有出现太大的差异,说明检验功效对于误差项分布以及空间自相关程度的变化具有一定的稳健性.然而,相对于相互独立的解释变量所得到的结果,共线性在一定程度上会减弱检验的功效.这主要是由于自变量间的共线性的增强会导致各个自变量的系数不太容易识别,降低了检验功效.但是,这个不利的影响会随着n或者c的增加而逐渐改善.
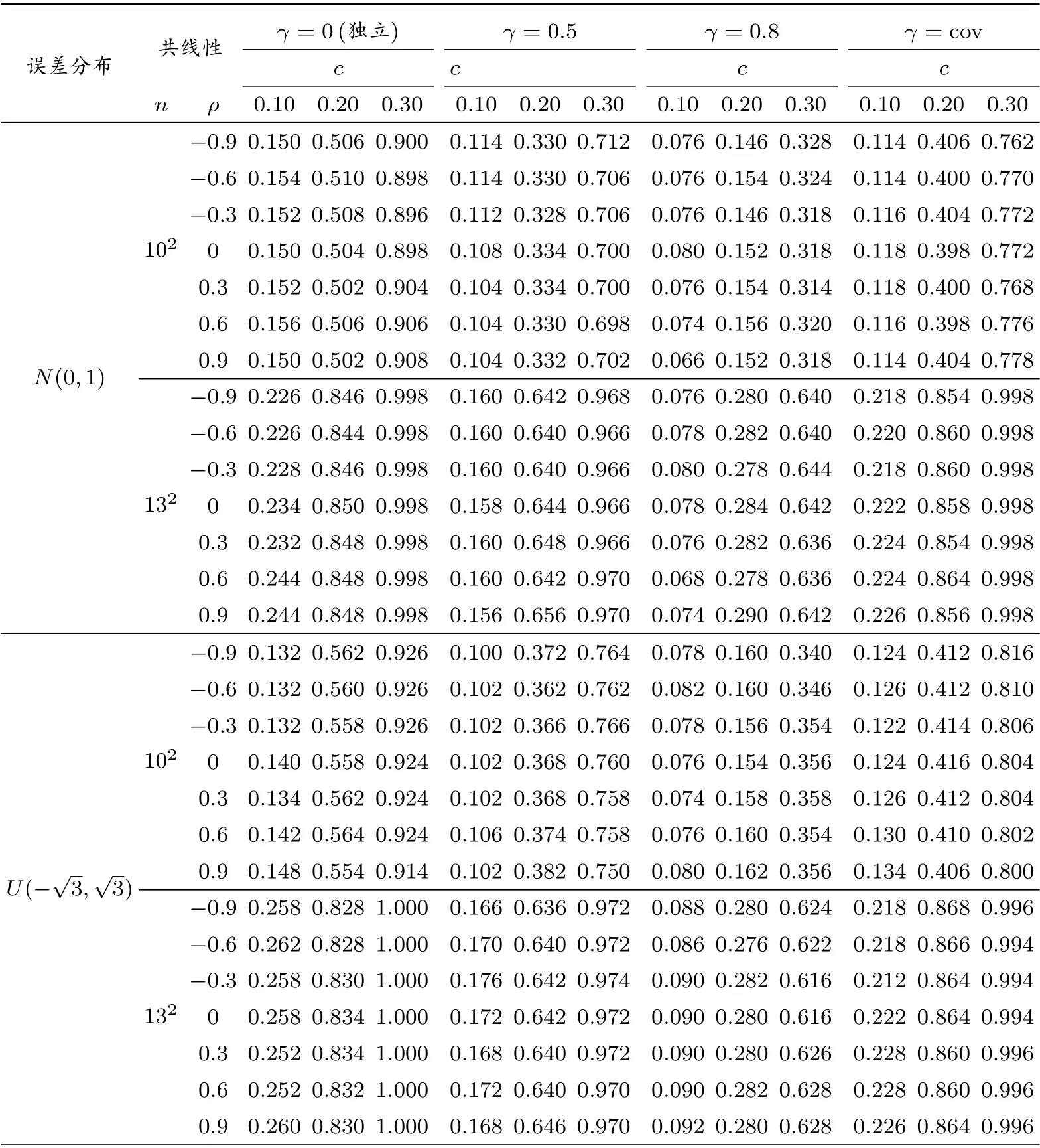
表2 当α=0.05时的检验功效

续表2 当α=0.05时的检验功效
5 小结
通过基于残差的Bootstrap方法来逼近检验统计量的零分布,本文建立了确定变系数空间自回归模型中的常系数项的检验方法.通过模拟试验验证了这种方法的准确性和可靠性.同时,本文还分别给出了在不同的误差分布、空间相关性参数以及解释变量的共线性程度这些情形下的模拟结果,进一步反映出该检验方法的稳健性.
对比变系数模型,半变系数模型反映了回归函数的更为精细的结构,从而为分析和了解自变量对因变量的影响提供了更详细的信息.但从实际应用角度来看,分析者事先往往并不知道哪些系数是常数,哪些是随u而变化的.对于给定的数据集,我们可利用本文所给出的检验部分系数为常数的检验方法来识别变系数空间自回归模型中的常值系数,从而为建立半变系数空间自回归模型提供依据.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学年刊A辑(中文版)(2021年1期)2021-06-09
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化·高一版(2021年2期)2021-03-19
河北理科教学研究(2020年2期)2020-09-11
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
山西大同大学学报(自然科学版)(2016年4期)2016-11-27
新高考·高一物理(2016年3期)2016-05-18
数学年刊A辑(中文版)(2015年2期)2015-10-30
新高考·高二数学(2014年7期)2014-09-18
