
一种使用注意力双向异构LSTM的治疗引擎
2021-08-24 06:53黄兆孟张立言
小型微型计算机系统 2021年8期
黄兆孟,徐 旭,张立言
(南京航空航天大学 计算机科学与技术学院,南京 210016)
1 引 言
近年来,电子病历系统在全国迅速普及应用,已经在患者信息归档和计费统计等医院行政任务方面发挥了巨大的积极的作用.与此同时,这些电子病历系统中记录了各种临床信息,这为进一步开发利用临床医疗数据提供了数据支撑,医疗数据挖掘与分析[1]这一新兴领域因此快速发展.
1.1 动 机
医疗数据挖掘与分析涉及多个领域,事实上,电子病历系统中的数据已经成功应用于疾病检测与分类、表型分析、信息提取、数据增强、数据隐私保护、临床事件顺序预测等多个临床应用类型的任务[2].在这分析任务中,临床事件的顺序预测[3]是一项重要的任务,该任务基于过去的纵向医疗事件序列来预测未来的临床事件,例如药物处方的预测等.
本文旨在开发一种治疗引擎,它可以对病患的多种历史住院信息建模,以自动预测病人下一个疗程的治疗药物处方.该想法是通过学习隐藏在大规模数据中的知识来预测下一期处方,包括人口统计学,疾病状况,实验室结果,诊断和患者的历史治疗记录.该引擎利用资深医生提供的治疗记录和满意治疗结果患者的EMRs提供的知识,不仅可以提高医疗效率,还可以通过引导所有医生避免意外故障,做出明智的临床决策,从而提高医疗质量 .
1.2 挑 战
然而,建立这样一个治疗引擎并不容易,临床的电子系统数据具有时间性和多模态特征,这为治疗引擎的有效预测带来了挑战.如图1所示,EMRs包含丰富的数据信息,包括患者人口统计信息、住院疾病类型诊断、每个疗程的药物处方和身体检测数据等[4].不同模态的医疗信息可能存在内在联系,如何提取多模态数据的关系是一个具有挑战性的问题.另外,如何正确地对这些时间性的高维的EMR数据进行建模,从而显著地提高预测性能,也是一个具有挑战性的问题.
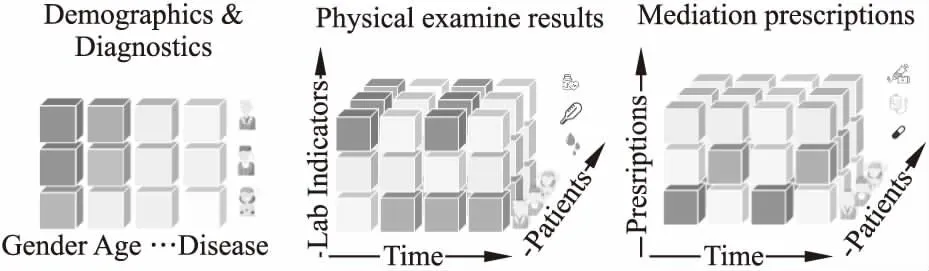
图1 EMRs数据
Retain[5]、Dipole[6]、LSTM-DE[7]是目前预测药物处方的先进模型.LSTM-DE在LSTM的基础上将实验室检测序列作为额外的序列输入通过稀疏连接加入到药物处方预测序列中,取得了较好的预测效果.Retain使用一个具有反向时间顺序的EMR序列的RNN,具有较好的预测精度.然而它们仍然受到RNN[8]和LSTM[9]的健忘性的限制,当时间序列长度较大时,这些模型的预测能力明显下降.Dipole使用双向神经网络(BRNN)利用了过去的和未来的所以可用的输入信息进行训练,缓解了长序列问题的影响.然而,Retain和Dipole均没有考虑到多模态数据对结果预测性能的影响.
注意力模型(AM)[10]在序列建模方面是一种有效的方法,不同阶段的治疗对未来的治疗方案有着不同的影响,基于注意力的神经网络可以学习数据样本与任务的相关性.例如,Retain使用基于位置的反向注意力进行预测,Dipole以时间顺序和反向时间顺序的方式对病人的就诊信息进行建模 .我们认为,对全局的前向的时间信息和后向的时间信息给予不同的时间关注度可以帮助预测模型提高预测性能.
1.3 解决方案
为了解决上述问题和挑战,文中提出了一种基于注意力的双向异构LSTM的治疗引擎(ATBH-LSTM),模型同时关注到了数据的时间性和多模态性.该方法提出一个端到端的神经网络,通过引入异构LSTM结构(H-LSTM)对多模态数据信息进行建模,在此基础上,使用双向结构(Bidirectional Structure)保留了全局的时间信息并通过Attention机制加强时间信息建模,有效提升了模型的预测性能.特别的是,双向递归神经网络可以利用过去和未来所有可用的输入信息进行训练,用于缓解长序列问题的影响,并且该模型对时间顺序和反向时间顺序使用分开的Attention机制,有效保留了双向LSTM结构的前向和后向的信息.在一个大型的真实的重症医疗数据集MIMIC-III[11]上进行了测试,实验结果表明,与最先进的方法相比,该方法具有优越性.
本文的其余部分组织如下:我们在第2节中介绍了与治疗引擎相关的工作进展,并在第3节中给出了所提出的主要模型框架.第4节对提出的方法进行了实证评价.最后,我们总结了我们工作的要点、不足和对未来工作的展望.
2 相关工作
2.1 医疗数据挖掘
电子病历系统中沉淀了大量的数据和医疗知识,然而直到最近今年,分析丰富的EMR数据的技术大多数是基于传统的机器学习和统计技术,如逻辑回归(LR)、支持向量机(SVM)、随机森林(RF)等[12].近年来,循环神经网络(RNN)[8,12-14]、长-短期记忆单元(LSTM)[7,9,15]、卷积神经网络(CNN)和图卷积神经网络(GCN)等深度学习技术通过构建数据的深度层次特征,有效捕获数据的长期依赖关系,在许多领域取得了巨大的成功,如图像处理、自然语言处理等领域.
在医疗数据挖掘和数据分析领域中,由于有丰富的海量的数据支撑,深度学习方法越来越多地应用于各种分析任务,已经成功应用于疾病检测与分类、表型分析、临床事件顺序预测等多个临床应用类型的任务.据Shickel B等人[2]的统计,该领域的出版物数量呈指数式增长,并预计今后每年都会出现大幅度的增长.医疗数据挖掘和数据分析已然成为医疗信息技术领域的研究热点.
2.2 序列建模
RNN及其变体包括长短时记忆(LSTM)和门控递归单元(GRU)模型等门控RNNs是序列建模的常见模型[7-9,12-15].除了RNN外,许多非序列模型被引入序列建模问题.Fang S.等人[16]提出了一个完全基于卷积神经网络的架构用于场景文本识别,其编码器为二维残差CNN,解码器为深度一维CNN.Vaswani等人[17]则将具有注意机制的卷积神经网络应用于序列建模任务.虽然当输入数据具有清晰的空间结构时,卷积神经网络是合乎逻辑的选择,然而,对于序列化数据这种方式学习到的只是浅层的数据特征[18].RNNs旨在处理序列数据长时间依赖性.
2.3 临床事件序列预测与治疗引擎
在医疗数据挖掘的众多应用领域中,临床事件序列预测[3]是的一个重要领域.EMR数据已被用于对多个医学临床事件的序列预测任务建模,包括辅助诊断[6,19]、疾病进展[15]、预后预测[13]、治疗过程分析[20].然而,电子病案数据挖掘也面临着许多挑战,如时间性、不规则性、多模态性等.
治疗引擎对病患的多种历史住院信息建模,以自动预测病人下一个疗程的治疗药物处方.Retain[5]使用一个具有两层反向时间顺序的EMR序列的RNN预测药物处方.LSTM-DE[7]改造基础的LSTM的内部结构,将实验室检测序列作为额外的序列输入通过稀疏连接加入到药物处方预测序列中,取得了较好的预测效果.LSTM-DE的结构如图2所示,LSTM-DE纳入了多种模态的EMR数据.然而,LSTM-DE没有充分考虑EHRs中的时间信息,单向的神经网络结构无法全面捕捉全局的时态数据特征.Dipole[6]使用双向神经网络(BRNN)利用了过去的和未来的所以可用的输入信息进行训练,缓解了长序列问题的影响.Retain和Dipole和之前的大多数研究都只关注EMR记录的部分信息,均没有考虑到多模态数据对结果预测性能的影响.临床医疗数据的异质性和时间性仍然是临床事件序列预测以及治疗引擎成功建模的难点和关键.我们同时关注了数据的时间性和多模态性.
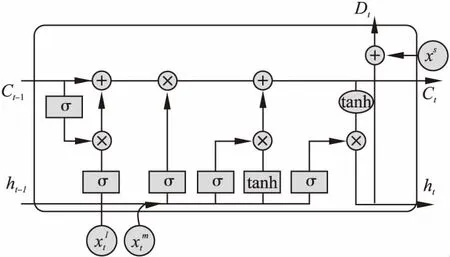
图2 LSTM-DE的结构
2.4 注意力模型
注意力机制能够使神经网络从复杂的数据中识别和聚焦于和任务相关的信息,在图像处理[21]和自然语言处理[22]等多个领域都有很多的应用.在医疗数据挖掘领域,注意力机制也得到了广泛的应用[5,6,15,17,23].与这些注意机制不同的是,我们对全局的前向的时间信息和后向的时间信息给予不同的时间关注度,这样可以充分学习到EMR的时间信息特征,从而提高预测性能.
2.5 EMRs数据
EMRs数据通常包含多种数据模式,包括数值型数据(如实验室指标检测值)、自由文本临床笔记、连续监测数据(如心电图(ECG))、用于诊断的、用药的离散代码等. 图1显示了我们研究中使用的4类EMRs数据,包括静态的人口统计信息和诊断信息、时态性的实验室指标和纵向药物治疗记录.
人口统计信息 记录在患者访问医院时,包括患者的年龄、性别、体重、保险、语言、宗教、婚姻状况、种族和其他信息.这些信息在临床决策中起着重要的作用,如治疗方案的设计和剂量的选择.患者的人口统计信息可以形式化为xde.
诊断信息 由医生提供.它包括疾病名称和疾病的严重程度.对于不同的诊断会有完全不同的治疗方案.诊断信息可以形式化为xdi.一般一次访视诊断信息是固定不变的.我们使用xs=[xde,xdi]为住院期间静态信息.
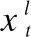
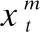
本文的任务就是对这4种数据进行统一建模,以便更准确地预测患者下一步的药物处方.即:
(1)

3 方 法
3.1 治疗引擎的整体性描述
我们首先根据MIMIC-Ⅲ的结构特点,从重症医疗数据库中筛选出病人的人口统计学信息、疾病状况、实验室结果、诊断和患者的历史治疗记录.将这些数据处理成两组时态数据和一组静态数据,分别馈送到双向的异构LSTM中,异构LSTM能够有效处理多模态的数据,从而学习到病人每个时刻的实际隐藏状态.通过注意力机制可以学习到每个时刻对当前状态的影响程度,从而挑选出对治疗有用的状态信息.模型的本质是一个多标签分类器,我们使用每个医学记录的多模序列来端到端地训练多标签分类模型,通过学习隐藏在大规模数据中的知识来预测下一疗程的治疗处方.

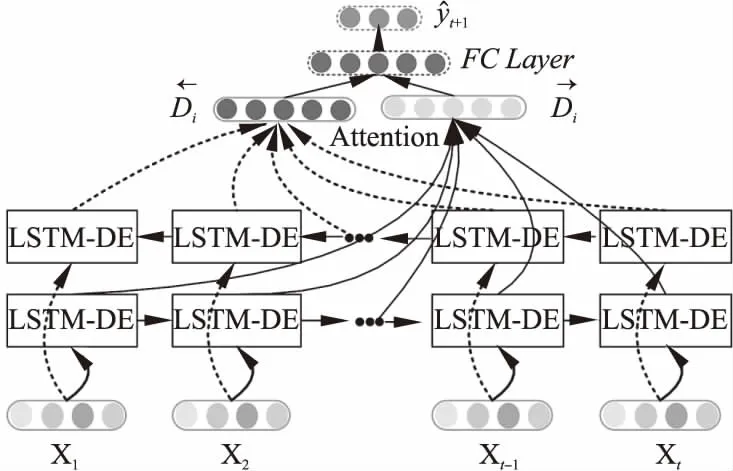
图3 基于注意力的双向异构LSTM的治疗引擎的网络结构
3.2 双向异构LSTM


(2)

3.3 注意机制
当给病人开药时,医生检查病人住院期间的所有医院记录.医生回顾病人的生理变化和用药历史,并基于他的广泛知识和经验,为病人开出合适的药物.我们模拟了医生给病人开药的过程,并利用双向注意力机制反复考查纵向信息.
我们选择了基于位置的注意力方法[6]结合多层感知机(MLP)来计算注意力权重,我们将每个时刻的实隐藏状态和权重矩阵W相乘获得每个时刻的潜在矢量,tanh为激活函数,vα为输入权重.计算得到每个时刻的注意力得分:
(3)
其中,v,W,b是需要学习的参数,根据公式(3),我们可以使用softmax函数获得注意力权重向量 ,如下所示:
α=Softmax([α1,α2,…,αt)]
β=Softmax([β1,β2,…,βt)]
(4)
(5)
3.4 药物处方预测
我们使用两个具有不同激活功能的全连接层和上下文向量c来预测下一个治疗处方.
(6)
4 实 验
4.1 实验数据
为了验证该治疗引擎的有效性,文中方法在一个大型的真实的重症医疗数据集MIMIC-III上进行了测试.MIMIC-III[11]是由麻省理工学院维护的开源数据集.它详细记录了53423名患者的实际住院健康状况,这些患者在2001年-2012年的10年间入住医院的重症监护室.表1显示了数据库所创建和提供的26个原始数据表.尽管医疗数据丰富,但公开的真实数据集却很少.MIMIC-III重症医疗数据集为所有的医疗数据挖掘研究提供了坚实的数据支持,有利于方法的复现和比较.

表1 数据类型
我们从数据集中提取实验室检测值和治疗药物处方两个时间序列、人口统计数据静态表.对于患有不同疾病的患者,治疗过程是完全不同的.因此在本文中,我们只考虑被诊断为同一种疾病的患者的子集.我们选取了出现频率最高的5个ICU诊断数据子集来进行实验,包括充血性心力衰竭、冠心病、冠状动脉旁路移植、上消化道出血、胸痛5种诊断,如表2、表3所示.在本研究中,我们将每个ICU住院日作为一个治疗疗程,这与现实是相符的,ICU病人每天的治疗药物处方都需要重新审定.
我们在按一天为单位重新采样,建立了体检序列和药物处方序列.这些异构序列的记录时间可以是可变的.即使是一个病人,不同来源的临床事件也可能有不同的记录时间.例如,患者一天进行一些实验室检查,但结果在第2天测量,然后患者获得有效的处方.虽然这些临床事件记录在不同的日子,但它们紧密相连.为了使这些序列同时同步,我们选择一个序列作为基序列,而将其他序列作为协同序列.基序列与协同序列之间采用时间对齐,即时间对齐后所有序列的时间步长都与基序列保持一致.考虑到这些异构序列的记录时间不同,我们使用相同长度的序列生成训练和测试批次,而不是将原始序列填充到一个固定的长度.为了获得更好的泛化能力,将过短或过长的序列剔除.
4.2 实验设置
4.2.1 基线方法
将我们的方法与以下基线进行比较:
1)LSTM,基础的LSTM模型.我们使用历史药物序列(历史治疗)作为输入预测药物处方.
2)LSTM-FC,将所有异构序列简单串联作为输入的模型.
3)LSTM-DE,Jin,B.等人[7]改进的LSTM模型,使用稀疏连接将附加序列添加到主序列中,有效的对多模态数据进行了建模.
4)Retain,Choi等人[5]提出的反向注意力模型用于临床序列预测.
5)Dipole,Ma,F.等人[6]提出的双向RNN模型对全局时间信息进行了有效建模.
4.2.2 本文的方法
1)ATH-LSTM在异构LSTM上添加注意力机制.
2)BiH-LSTM为双向异构LSTM.
3)ATBH-LSTM:本文提出的基于注意力的双向异构LSTM的治疗引擎.
4.2.3 参数设置
所有这些模型都是用在Tensorflow中的mini-batch stochastic Adam optimizer实现的.我们将相同诊断的患者数据随机分为训练数据(80%)和测试数据(20%).所有的模型使用相同的网络设置和参数进行比较.具体来说,学习率设置为0.01.对所有模型进行100个epoch的训练,并对结果进行5个倍数的交叉验证.为了避免梯度爆炸,我们将L2范数添加到损失函数中,参数为10-5.时间序列长度均大于3.由于将全连接层添加到了所有模型中,所以我们将其设定为固定值512维.
4.3 结果分析
为了确定最佳的隐藏状态的维度,如图4、图5所示,我们比较了在诊断为胸痛的数据子集下每个维度的ROC曲线下面积(AUROC)和P-R曲线下面积(AUPR)的值.在各个维度上的比较,我们所提出的方法ATBH-LSTM均在其他基线方法之上.并且LSTM单元的维度没有影响所提方法的预测性能,这说明我们的方法具有更高的鲁棒性.
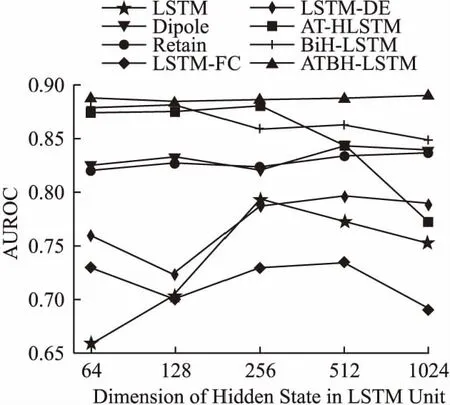
图4 隐藏状态为每个维度时各个模型的AUROC的值

图5 隐藏状态为每个维度时各个模型的AUPR的值
为了便于进行对比实验,在接下来的实验,我们选择512维的隐藏状态维度.我们在5个数据子集上所有方法的AUROC和AUPR的平均性能.结果如表2、表3所示.
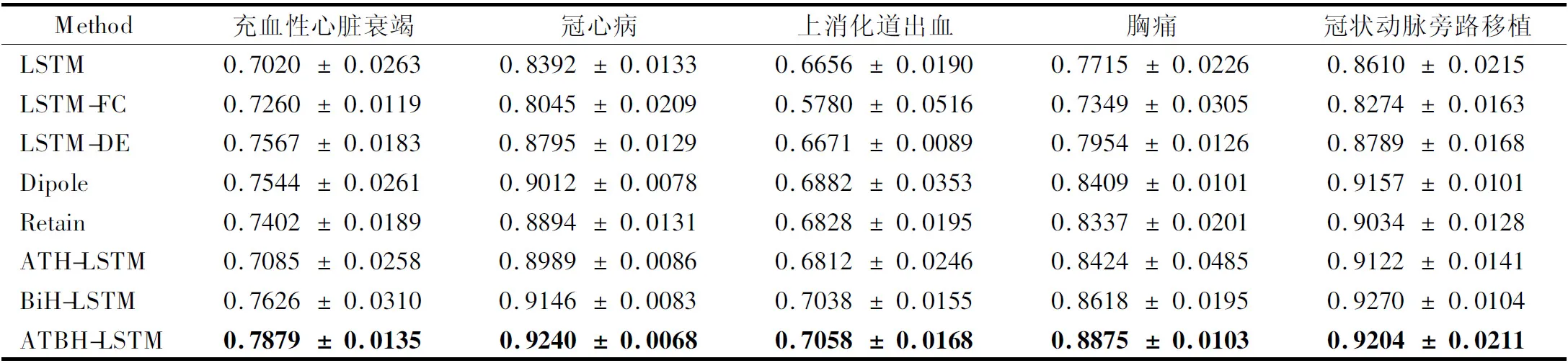
表2 使用AUROC比较LSTM、、LSTM- FC、LSTM-DE、Dipole、Retain、ATB-LSTM、BH-LSTM、ATBH-LSTM的性能
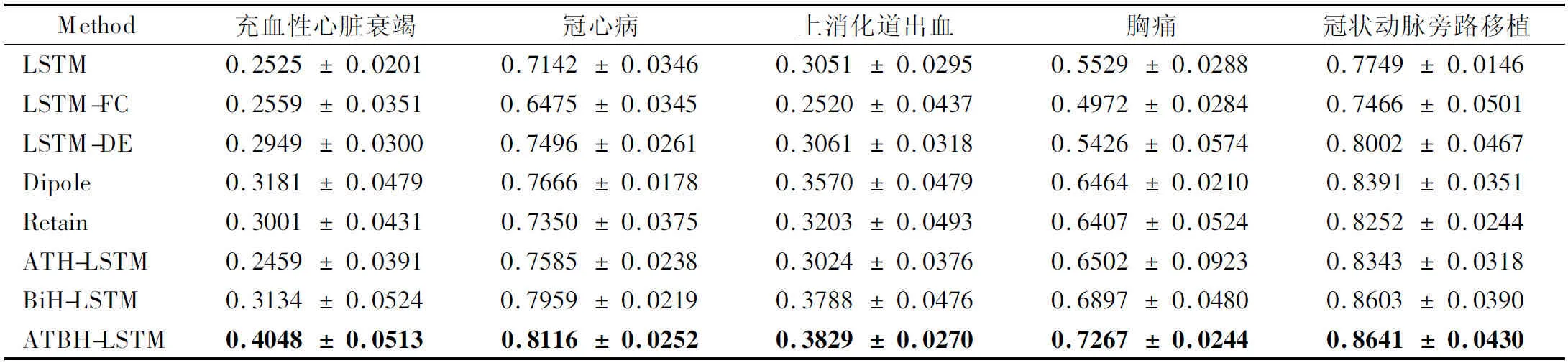
表3 使用AUPR比较LSTM、、LSTM- FC、LSTM-DE、Dipole、Retain、ATB-LSTM、BH-LSTM、ATBH-LSTM的性能
首先,通过对LSTM、LSTM-FC和LSTM-DE的比较,验证了异构LSTM能有效处理多模态数据.LSTM-FC在大多数疾病上的性能均低于LSTM,说明将数据的简单混合反而混淆了数据隐藏的信息,LSTM-DE的异构组织有效的处理了多模态信息,然而在上消化道出血诊断集上的LSTM-DE的效果并不好,这可能是数据的时间长度过长,单向LSTM结构遗忘了部分信息.
其次,LSTM-DE和拟议的BiH-LSTM均未使用任何注意机制,但在所有疾病数据集上,BiH-LSTM的性能均高于LSTM-DE. 结果表明,从两个方向对访问信息进行建模可以提高预测性能. 因此,将双向递归神经网络用于诊断预测任务是合理的.
另外,ATH-LSTM、Retain、Dipole使用注意力机制,3个方法的AUROC和AUROC均高于没有使用注意力的基线模型LSTM、LSTM-FC和LSTM-DE.这说明,注意力模型的使用有效提升了预测性能.ATH-LSTM的表现明显优于Retain、Dipole方法,这可能是对前向信息和后向信息的分别处理使得模型学习到了更加全面的隐藏信息.
通过消融实验,可以发现ATH-LSTM、BiH-LSTM在所有数据集上均优于LSTM-DE说明双向结构和注意力机制起到了预期效果.方法ATBH-LSTM在这些数据子集上的表现都优于其他方法,这说明基于注意力的双向异构LSTM的治疗引擎能有效预测下一疗程的治疗药物处方.
与AUROC相比,AUPR评分越高,说明预测所用的处方越有可能被采用,因为阳性结果少于阴性结果.特别的是,从表3中可以发现,本文所提出的方法在AUPR性能指标上提升很大,远优于其他方法.这说明,本治疗引擎的推荐的治疗处方更加有效,这对提升医疗决策质量有重要意义.
综上,我们的模型相比基线模型具有更高的鲁棒性和预测性能,同时我们预测的结果更加有可能在临床决策中被医生采用,这表明本文提出的治疗引擎的可行性和有效性.
5 总 结
为了准确预测病患下一疗程的治疗药物处方,必须对丰富的患者住院信息进行建模.本文提出了一种基于注意力的双向异构LSTM的治疗引擎,通过引入异构LSTM和双向注意力机制来解决多模态EMR数据带来的挑战.在真实EMR数据集上的实验表明,我们提出的方法在预测治疗处方任务方面取得了很好的效果,提升了预测精度和药物处方的可用性.这项工作的一个局限性是我们简化了预测任务,即只预测了治疗药物的类型而忽略了药物的剂量.此外,推荐药物的安全性也是未来值得研究的问题.
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
计算技术与自动化(2022年2期)2022-07-04
汽车实用技术(2022年10期)2022-06-09
小学教学研究(2022年5期)2022-04-28
汽车工程师(2021年12期)2022-01-17
文苑(2020年6期)2020-06-22
福建基础教育研究(2019年11期)2019-05-28
恋爱婚姻家庭·养生版(2018年10期)2018-10-26
成长·读写月刊(2018年8期)2018-08-30
电影新作(2014年1期)2014-02-27
