
情景感知的服务需求动态预测方法研究
2021-08-24 06:53刘志中
小型微型计算机系统 2021年8期
丰 凯,刘志中,宋 成,张 丽
1(河南理工大学 计算机科学与技术学院,河南 焦作 454003)
2(烟台大学 计算机与控制工程学院,山东 烟台 264005)
1 引 言
近年来,随着服务计算、物联网、智能终端以及5G网络的快速发展与普及,越来越多的用户可以随时随地访问来自于不同领域、功能丰富的服务,完成工作与日常生活事务.随着网络上可用服务数量的激增,用户难以快速及时地发现满足其需求的服务,严重影响了用户的满意度,降低了服务资源的利用率.主动服务推荐逐渐成为实现智能服务的关键技术,而服务需求动态预测是实现主动服务推荐的基础.如何实现服务需求的动态预测已经成为智能服务领域亟需解决的关键问题之一.近年来,国内外学者针对这一问题开展了研究,并取得了一定的研究成果[1-5].已有的研究工作大都基于协同过滤[6,7]、支持向量机[8,9]、矩阵分解[10]以及机器学习[10]方法来实现用户服务需求的预测.然而,已有的研究工作没有充分考虑用户所处的场景对其服务需求的影响,导致服务需求预测精度不高.事实上,用户的服务需求与其所处的场景具有密切的关联关系.用户所处的场景是触发用户提出服务需求的重要因素,因此,在进行用户服务需求预测时,需要充分考虑用户所处的场景.
在实际应用中,用户在不同的场景下常常会提出相同的服务需求,不同的场景对服务需求的影响也是不同的.因此,在进行服务需求预测时,需要考虑多个不同场景对服务需求的影响权重,从而提高服务需求预测的准确性.为了简化描述,后文用“服务需求”替代“同一个服务需求”.为了实现高精度的服务需求预测,本文构建了一种注意力机制增强的深度交互神经网络模型AMEDIN,并基于AMEDIN提出了一种情景感知的服务需求动态预测方法.该方法捕获不同场景与服务需求之间的交互关系,并获取不同场景对服务需求的影响权重,使得与服务需求关联性较强的场景获得更高的影响权重,从而对情景感知的服务需求预测起到主导作用.本文的创新点主要包括:
1)引入了交互单元.通过交互单元可以显式地建模多个场景与服务需求之间的交互关系,充分捕获不同场景与服务需求之间的非线性关系,有助于提高服务需求预测的准确性.
2)通过交互单元与注意力机制相结合,动态地获取不同场景对服务需求的影响权重,挖掘对用户服务需求影响较大的场景特征,从而提高了服务需求预测的可解释性与精度.
本文组织结构如下:第2节介绍相关工作;第3节介绍情景感知的服务需求动态预测方法;第4节是本文的实验部分;第5节对本文工作进行了总结与展望.
2 相关工作
随着近年来个性化服务需求信息的增长,国内外一些学者对用户服务需求预测进行了研究.Yao等[11]针对现有的出租车需求预测只考虑空间或时间关系的不足,提出了一种深度多视角时空网络模型,对空间和时间关系进行建模并预测用户服务需求.为了为IaaS提供商选择长期服务请求并使其利润最大化,Mistry等[12]提出了一种基于多变量隐马尔可夫模型和自回归综合移动平均模型的资源利用模式预测方法,能够预测服务请求的高频度和季节性的长期行为.考虑到许多客户的不同行为,Koshiba等[13]提出了一种基于客户分类模型的服务需求预测方法.
为了帮助公司为未来市场生产产品,Song等[14]开发了一种预测客户需求转变趋势的综合方法.为了降低在快速变化的市场中开发新产品的风险,Chong等[15]提出了一种基于人工免疫和神经系统的用户需求分析和预测系统.对于面向服务的制造,Cao等[16]提出了一种考虑客户满意度的客户需求预测方法,利用结构方程模型定量描述客户满意度指标与影响因素之间的关系,并采用最小二乘支持向量机制进行客户需求预测.Garg等[17]提出了一种基于时态数据挖掘的即时服务需求自适应预测系统.
虽然上述研究工作取得了较好的成果,然而,已有的研究工作通常将不同的场景对用户服务需求的影响视为同样重要的,导致模型无法充分学习不同场景对服务需求的影响,从而降低了服务需求预测的精度.针对当前研究工作存在的不足,本文构建了一种注意力机制增强的深度交互神经网络模型AMEDIN,并基于AMEDIN提出了一种情景感知的服务需求动态预测方法.AMEDIN通过交互单元和注意力机制自适应的学习多个场景特征对用户服务需求特征的影响权重,解决了上述问题并提高了模型的表达能力,在一定程度上弥补了当前研究工作存在的不足.
3 情景感知的服务需求动态预测方法
在服务使用中,可以通过智能终端、物联网以及智能穿戴设备,获取用户的特征信息、所处的场景信息以及提出的服务需求信息等,从而能够形成用户提出服务需求时的相关数据,为实现情景感知的服务需求预测提供数据支持.针对情景感知的服务需求动态预测问题,定义服务使用数据模型如公式(1)所示:
SAR=
(1)
其中,UF=
为了提高情景感知的服务需求动态预测的精度,本文设计了一种注意力机制增强的深度交互神经网络模型AMEDIN,来获取不同场景与服务需求之间的交互关系,进而获取不同场景对服务需求的影响权重.下面分别介绍AMEDIN模型及其主要运行机制.
3.1 注意力机制增强的深度交互神经网络模型(AMEDIN)
AMEDIN模型由交互单元、影响权重学习模块以及服务需求预测模块组成,其结构如图1所示.其中,交互单元与服务需求预测模块由全连接网络构成.交互单元用于捕获不同场景与服务需求之间的交互关系;影响权重学习模块基于注意力机制学习不同场景对于服务需求的影响权重;服务需求预测模块基于影响权重学习模块的学习结果,实现情景感知的服务需求预测.下面分别介绍交互关系的获取与基于注意力机制的影响权重学习过程.

图1 AMEDIN模型结构图
3.1.1 基于交互单元的交互关系获取


(2)


(3)

3.1.2 基于注意力机制的影响权重学习

(4)
(5)
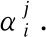
(6)
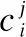
3.2 服务需求的动态预测
在获取对用户发起服务需求具有较大影响的场景特征之后,基于AMEDIN模型的预测模块实现服务需求的预测.在对服务需求预测模块进行训练时,定义模型的输入数据为Ii=
(7)
其中,σ表示ReLU激活函数,W表示权重矩阵,Ii表示输入的数据,b表示偏置向量.
在AMEDIN模型中,选择交叉熵损失函数(CrossEntro-pyLoss)来优化所构建的模型,交叉熵损失函数如公式(8)所示:
(8)
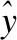
(9)
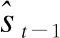
算法1.基于AMEDIN的服务需求动态预测
阶段1.AMEDIN模型的训练
输入:D//用于模型训练的数据集
1.初始化模型的参数;
2.repeat
3.fori to ndo//n为批量数据的数量
5.for(j=1 to m)//m为输入样本Xi中场景特征的数量
7.endfor
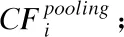
12.依据公式(6)计算注意力机制的输出;
14.依据公式(8)计算AMEDIN模型的损失值;
15.依据Adam算法更新AMEDIN模型中的参数;
16.endfor
17.until{满足模型训练结束条件;}
阶段2.服务需求的预测
18.输入:fori to kdo//k为服务需求特征的数量
19.endfor
20.执行AMEDIN模型;
21.依据预测值为1时的概率,提取概率值较大的那条数据中的服务需求特征作为预测的用户服务需求;
22.输出:预测的服务需求
4 实验结果与分析
4.1 实验数据准备
目前,还不存在用于验证情景感知的服务需求动态预测的数据集.为了验证本文所提出方法的有效性,本文采用MovieLens数据集(1)https://grouplens.org/datasets/movielens/1m/和天池网站提供的Alibaba数据集(2)https://tianchi.aliyun.com/dataset/dataDetail dataId=56.其中,Movielens数据包含来自6000名用户对18个类别4000部电影打分的100万个样本数据;Alibaba数据集是阿里巴巴公司提供的大量用户广告点击率的数据.针对MovieLens数据,将用户特征看成服务需求预测中的用户特征,将情景特征映射为服务需求预测中的场景特征,将电影特征映射为服务需求预测中服务需求特征,将用户对电影的评价值映射为用户服务需求的标签;针对Alibaba数据,将用户特征看成服务需求预测中的用户特征,将情景特征映射为服务需求预测中的场景特征,将广告特征映射为服务需求预测中的服务需求特征,将用户是否会点击广告的值映射为用户服务需求预测中的标签.实验中,本文将Movielens数据中的评分类别转换为二分类,电影的原始用户评分是从1到5的连续值,本文将评分为4和5的样本标记为正,其余的标记为负.由于Alibaba数据量比较大,本文从该数据中随机采样100万条数据作为实验数据.在实验中,重点考虑了每个数据集中的5种场景特征,Movielens数据中的信息如表1所示,Alibaba数据中的信息如表2所示.
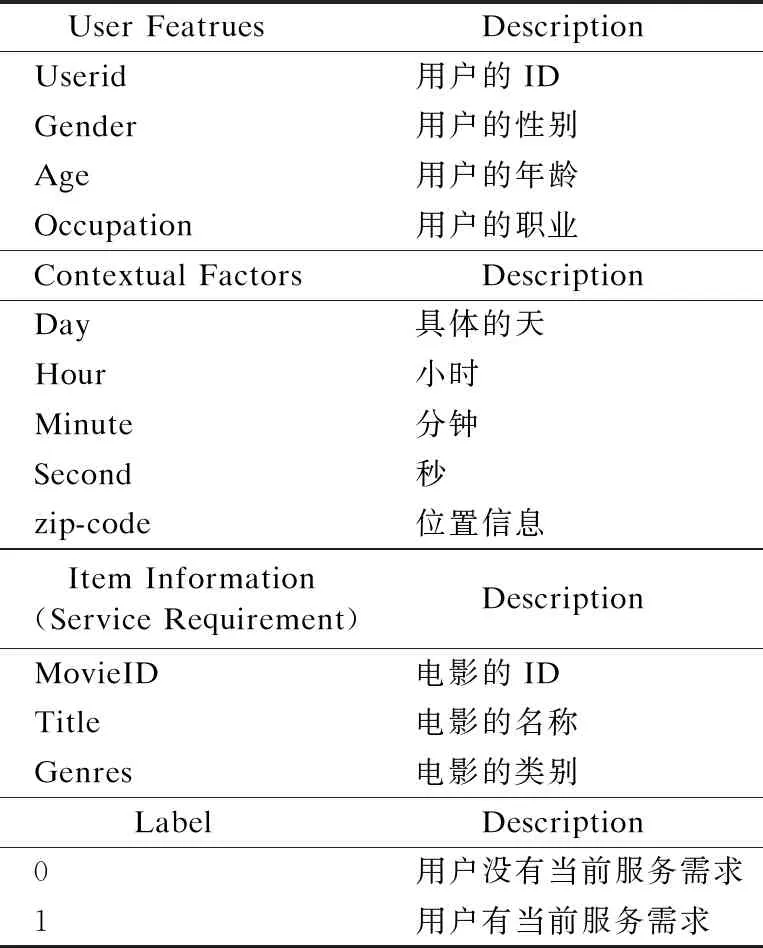
表1 Movielens数据中的信息
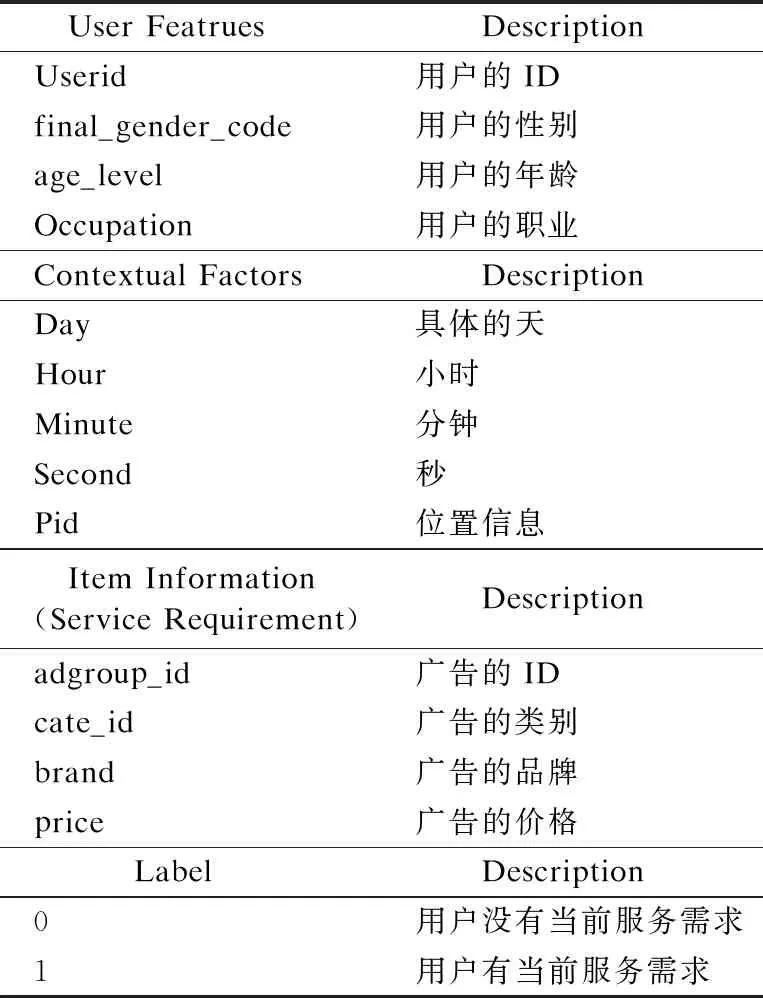
表2 Alibaba数据中的信息
实验环境为个人电脑,操作系统:Windows 10专业版64位,CPU:Intel i7 8750H,RAM:8GB.该实验选择开源的TensorFlow 2.0 GPU为预测模型的实现框架,采用Python 3.6编程实现预测模型.
4.2 评估指标
本文采用均方根误差RMSE与平均绝对误差MAE和准确率Acc来计算服务需求的预测值与真实值的偏差,从而衡量本文所提出的预测方法的有效性.其中,RMSE与MAE的计算公式如公式(10)与公式(11)所示.
(10)
(11)
其中,RMSE与MAE的值越小,表示模型的预测精度越高;Acc的值越大表明模型的预测精度越高.
4.3 AMEDIN模型参数设置
在AMEDIN模型中,交互单元用于学习多个场景和服务需求之间的交互关系,交互单元的网络层数对模型的性能具有重要影响,为了使得AMEDIN模型具有较好的性能,这里通过实验的方法来确定层数的最优取值.在实验中,采用Adam为优化算法,初始化学习率为0.00001.通过设置不同的层数来观察AMEDIN模型的性能表现,进而来确定交互单元中网络层数的最优取值.实验结果如表3所示.
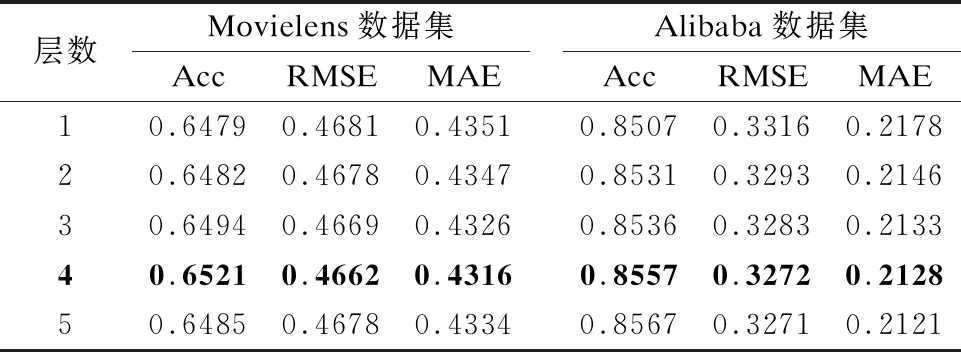
表3 交互单元网络层数对AMEDIN模型性能的影响
从表3可以看出,增加交互单元的层数有助于提高模型预测准确度.但是,随着层数的增加,模型性能的提升度有限.同时,交互单元层数的增加,会给模型带来更多的参数学习开销,从而增加模型训练的复杂度以及过拟合风险.基于上述实验结果,综合考虑模型的性能与训练消耗,本文确定交互单元的网络层数为4.
此外,在用户服务需求预测模型中,交互单元中每层网络的神经元节点数目对模型的性能也有较大的影响,为了使模型具有较好的预测能力,该实验在AMEDIN模型中,分别设置每层网络的神经元节点数为16、32、64、128与256,执行模型并记录实验结果,实验结果如表4所示.
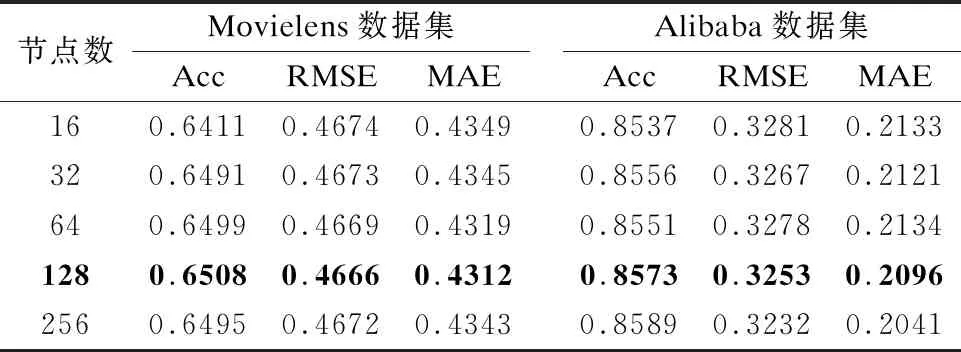
表4 交互单元节点数对AMEDIN模型性能的影响
从表4可以看出,随着神经元节点数目的增加,模型的性能逐渐得到提升;而当节点数达到128时,模型的性能达到最优;之后,随着节点数量的增加,模型的性能所有下降.同时,增加神经元的节点数量,会增加模型训练的开销以及过拟合的风险.基于实验结果,本文将AMEDIN模型交互单元中每层网络神经元的节点数设置为128.
4.4 对比模型参数的设置
为了验证所提出方法的有效性,该实验选取了5种典型的深度神经网络与本文所构建的AMEDIN模型进行比较.5种典型的深度神经网络分别为:深度神经网络(Deep Neural Network,DNN)、DeepFM[22]、注意力交互网络(Attentive Interaction Network,AIN)[23]、注意力因子分解机(Attentional Factorization Machine,AFM)[24]与神经因子分解机(Neural Factorization Machine,NFM)[25].
对于深度神经网络DNN,分别将用户特征、场景特征和服务需求特征经过嵌入层(Embedding)之后,输入到全连接网络,预测用户的服务需求.在实验中设置其隐含层数为3,隐含层节点数为32,采用交叉熵损失函数,并且采用Adam优化算法,初始化学习率设置为0.001.对于DeepFM,在用户特征、场景特征和服务需求特征经过嵌入层处理之后,使用因子分解机(Factorization Machines,FM)提取低阶特征,然后使用DNN进行高阶特征提取之后,输入到全连接网络,预测用户的服务需求.在该实验中,DeepFM的参数设置与原论文保持一致,设置Dropout为0.5,选择Adam作为优化算法,设置初始化学习率为0.001.对于AIN,与原论文保持一致,设置隐含层数为2,隐含层节点数为128,并且采用Adam为优化算法,设置初始学习率为0.001.
对于AFM模型,依据原论文设置Dropout为0.5,使用大小为512的批量训练策略,选择Adam为优化算法,设置学习率的初始值为0.001.NFM是一种用于稀疏数据预测的神经网络模型,它在神经网络模型下增强因子分解机来学习高阶交互特征,设置使用大小为512的批量训练策略,并且采用Adam为优化算法,初始化学习率为0.01.对于本文提出的AMEDIN模型,交互单元的层数设为4,隐含层节点数设置为128,采用Adam为优化算法,初始化学习率为0.00001.对于每一个网络模型,都采用Alibaba数据集和Movielens数据集作为实验数据,设置最大迭代次数为300.
4.5 不同模型的性能比较
为了验证本文所提出方法的有效性,该实验采用数据集的80%作为训练数据,数据集的20%为测试数据,对多个模型进行训练与测试.采用4.2节中给出的评估指标来度量每一个模型的性能.实验结果如表5所示.

表5 不同模型在两套数据集上的性能评估
从表5可以看出,在进行服务需求预测时,本文提出的AMEDIN模型在评估指标Acc、RMSE和MAE上均优于其他方法.在Movielens数据集中,AMEDIN模型在评估指标Acc上,分别优于其他方法中最优结果1.14%;在指标RMSE和MAE上,分别领先于次优结果0.51%和0.5%.在Alibaba数据集中,AMEDIN模型在评估指标Acc上分别优于其它方法中最优结果1.48%,在指标RMSE和MAE上分别领先次优结果1.06%和1.6%.通过上述实验结果可以得出,本文所提出的AMEDIN模型通过交互单元和注意力机制,能够有效捕捉多个场景对服务需求的不同影响;同时,通过提取多个场景和服务需求的交互特征,能够有效降低多个场景和服务需求之间非线性关系的损失;另一方面,通过注意力机制得到对用户服务需求影响权重最大的场景特征,提高了模型的预测精度.
4.6 不同模型的收敛性验证
为了验证本文所提出方法的收敛性,分别对多个模型进行训练与测试,多个模型的参数设置与4.3节中的设置一致.实验结果如图2和图3所示.其中,纵坐标表示预测准确度,横坐标表示模型的迭代次数.
从图2和图3可以看出,随着迭代次数的增加,多个深度神经网络的预测准确率不断得到提升.从图2可以看出,在Movielens数据集中,NFM模型的性能表现最弱.从图3可以看出,在Alibaba数据集中,DNN模型的性能表现最弱.本文所提出的AMEDIN模型在两个数据集上都具有较好的预测准确度.通过上述实验结果可以得出,AMEDIN模型具有良好的学习能力,迭代较少的次数就能够获得较高预测准确率.
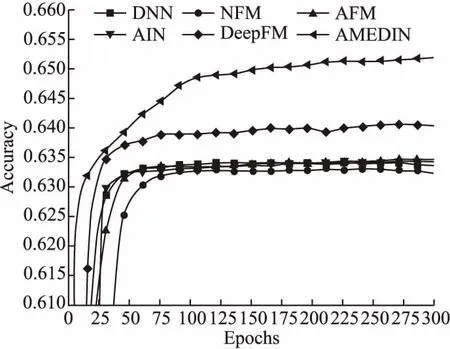
图2 不同模型在Movielens数据集上的准确率
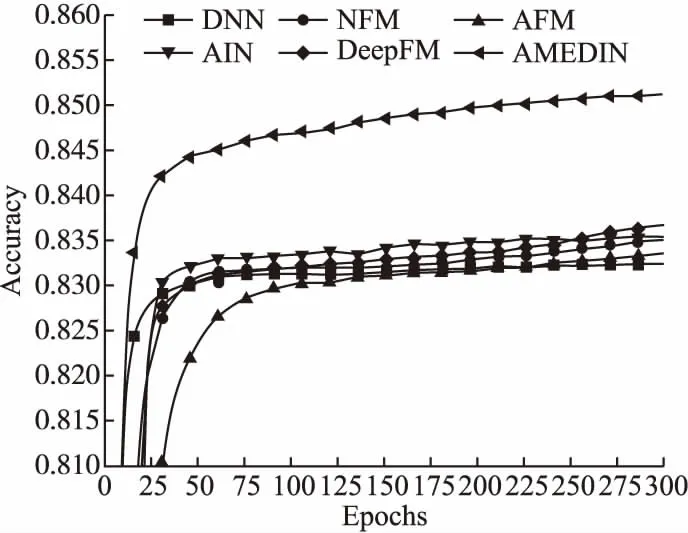
图3 不同模型在Alibaba数据集上的准确率
4.7 不同模块对AMEDIN模型性能的影响分析
为了验证获取交互关系、获取影响权重对于提高服务需求预测准确度的有效性,该实验通过去掉相关的操作得到AMEDIN模型不同的变体,通过AMEDIN模型的变体与AMEDIN模型的比较来验证不同模块对AMEDIN模型性能的影响.其中,AMEDINNoIta表示不考虑不同场景和服务需求之间的交互关系,AMEDINNoPooling表示不考虑池化场景特征与服务需求之间的交互关系,AMEDINNoAtt表示不使用注意力机制.AMEDIN模型与其它变体模型的参数设置一致,基于相同数据集与实验平台对4种模型进行训练和测试,
实验结果如图4至图7所示,其中纵坐标分别表示RMSE和MAE,横坐标表示算法的迭代次数.

图4 不同模型在Movielens数据集上的RMSE
从图4到图7可以看出,当AMEDIN模型不考虑交互关系与AMEDIN模型不使用注意力机制时,AMEDIN的变体模型在RMSE和MAE评估指标数值有所上升,而AMEDIN模型在RMSE和MAE指标上优于其他3种变体模型.基述实验结果可以得出,考虑不同场景和服务需求的交互关系以及考虑不同场景对服务需求的影响权重,有助于提升AMEDIN模型的性能,也即说明,考虑场景和服务需求之间的交互关系以及不同场景对服务需求的影响权重,有助于提高服务需求预测的准确度.
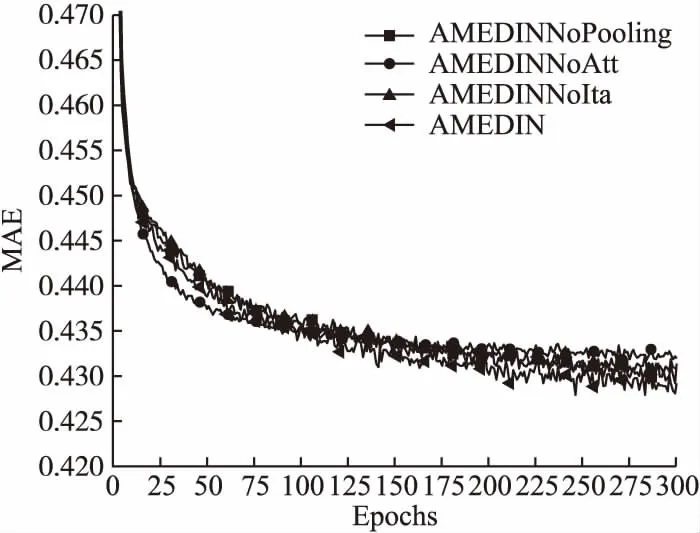
图5 不同模型在Movielens数据集上的MAE

图6 不同模型在Alibaba数据集上的RMSE

图7 不同模型在Alibaba数据集上的MAE
5 总结与展望
为了实现情景感知的服务需求动态预测,进而提高服务推荐的主动性与智能性,本文提出了一种情景感知的服务需求动态预测方法.该研究工作构建了一种注意力机制增强的深度交互神经网络模型AMEDIN,首先通过AMEDIN模型中的交互单元,捕获多个不同场景和服务需求之间的交互关系;之后,通过注意力机制,获取多个场景对服务需求的影响权重;最后,基于注意力机制的输出构建训练数据,通过全连接网络对服务需求进行动态预测.基于真实的数据集进行了大量的实验,验证了本文所提出方法的有效性;同时还通过实验验证了交互单元和注意力机制对于提升模型预测精度的有效性.在后续的研究工作中,将进一步分析影响服务需求预测精度的主要因素,挖掘这些因素对服务需求预测的影响规律,基于这些规律开展服务需求预测的研究,从而提高服务需求预测的灵活性与准确度.
猜你喜欢
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
国企管理(2022年3期)2022-05-17
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
商场现代化(2016年4期)2016-04-08
物联网技术(2015年5期)2015-07-18
