
基于BP神经网络的污染场地土壤重金属和PAHs含量预测
2021-09-24 11:49任加国马福俊谷庆宝武倩倩
环境科学研究 2021年9期
任加国, 龚 克,, 马福俊, 谷庆宝, 武倩倩
1.山东科技大学地球科学与工程学院, 山东 青岛 266590 2.中国环境科学研究院, 环境基准与风险评估国家重点实验室, 北京 100012
工业活动产生的废气、废液和废渣排放及泄漏[1]导致大量重金属和多环芳烃(polycyclic aromatic hydrocarbons,PAHs)进入土壤环境,造成土壤污染,其中以焦化厂、炼钢厂、金属加工厂及其周边地区土壤污染尤为显著[2-3]. 重金属和PAHs具有性质稳定、难降解和毒性强的特点,容易被土壤吸附并不断累积[4],进而威胁人类健康[5-6]. 从保障人类生产生活安全角度出发,实现土壤环境质量评价和安全管理需要对土壤中重金属和PAHs含量进行系统、全面地检测. 然而,受土壤检测成本和项目周期等因素制约,污染场地土壤经常存在检测数据缺失的现象,如何利用有限的检测数据获得更全面的信息成为当前研究热点.
人工神经网络是模仿人脑结构和功能的运算模型,具有联想记忆、分类识别、优化计算以及非线性映射等近似人脑的基本功能[7]. BP神经网络是一种按照误差逆传播的人工神经网络[8],能够处理已知条件与结果之间无明确关系的数据,通过在条件与结果之间建立一定的映射关系,而不需要在构建网络之前确定映射的数学方程[9],从不完整的样本中提取信息特征对问题进行预测评估[10]. 目前,BP神经网络对土壤污染物含量预测主要是针对空间尺度大区域的表层土壤[11-13],而对小区域土壤污染物垂向空间分布预测的相关研究较少. 与大区域相比,小区域土壤污染受到其他因素(自然、生产因素)的影响较小,但土壤自身理化性质及其与污染物间的相互作用对污染物空间分布具有显著影响,且土壤污染物空间分布的检测能力及成本要求较高. 因此,通过BP神经网络实现小区域场地土壤污染物的空间分布预测具有重要的现实意义.
某金属加工厂是新中国成立后的一个重点综合性有色金属加工、科研、生产基地. 由于该厂对环保工作重视度不够,设施落后,生产过程中产生大量的粉尘、酸洗废液等,导致地块内土壤受到重金属和PAHs不同程度的污染. 以该场地为研究对象,对场地不同点位及深度的土壤样品进行重金属和PAHs含量检测,分析不同污染物之间的关联性,建立以监测点空间参数和已知土壤污染物含量数据为输入值、土壤重金属和PAHs含量数据为输出值的映射关系,通过构建BP神经网络模型,预测缺失的重金属和PAHs含量数据,并对BP神经网络预测效果进行评价,以期为土壤污染的空间分析和评价方法提供参考.
1 材料与方法
1.1 研究区概况及采样点布置
研究区为某有色金属加工厂生产区域,占地面积约6.5×105m2,自20世纪50年代开始,厂区一直从事有色金属加工生产,主要产品包括铜、镍、钛合金和其他冶金制品等. 常年生产活动对地块土壤造成了一定污染. 场地金属加工车间(熔铸、板带、管棒车间等)主要沿南北方向分布在厂区中部,辅助系统和供暖车间分布在厂区西侧. 场地地层自上而下主要为杂填土、粉质黏土、砂土和砾砂土,含水层埋藏较深. 按照HJ 25.2—2019《建设用地土壤污染风险管控和修复监测技术导则》相关要求,采用系统网格布点法,不超过 1 600 m2布设1个采样点,对于存在污染区域进行加密布点,不超过400 m2布设1个采样点. 场地总共设置379个采样点,分别采集0.5~11.0 m不同深度的土壤样品,其中表层土壤采样深度为0~0.5 m,其他层位每1 m采集1个土壤样品,共采集 1 832 个土壤样品. 采样点布设见图1.
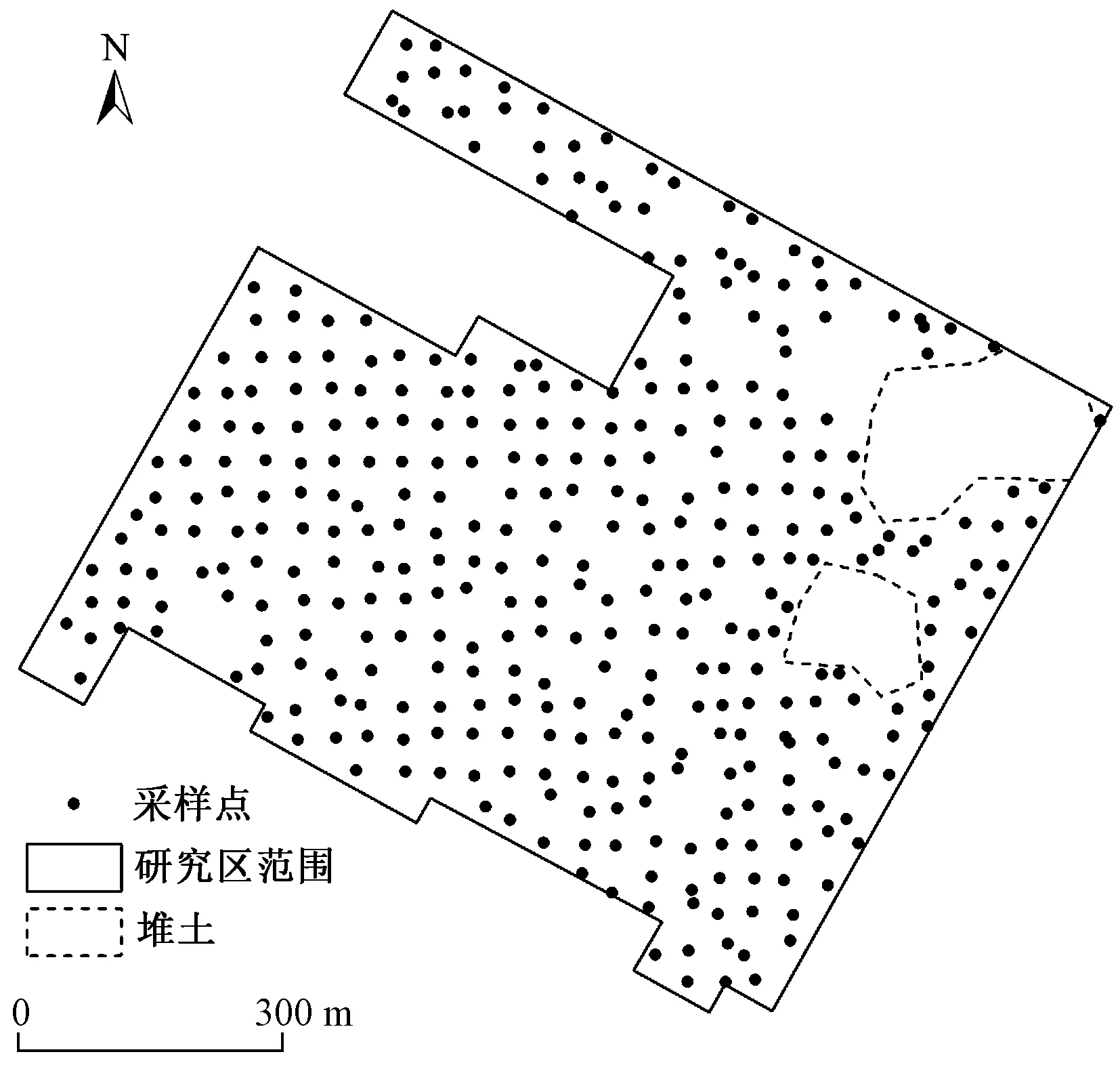
图1 采样点位置示意Fig.1 The location of sampling sites
1.2 土壤样品测定
采集的土壤样品剔除树枝石块等杂质,经冷冻干燥、混匀风干后研磨破碎过100目(0.15 mm)钢筛后保存. 土壤pH和含水率分别利用pH计和含水率测定仪进行测定[14-15];采用HCl-HNO3-HF微波密闭消解技术进行土壤样品消解,使用电感耦合等离子体原子发射光谱法(ICAP RQ,Thermo Fisher Scientific,美国)测定土壤中w(Zn)、w(Cu)、w(Ni)、w(Cd)、w(Hg)、w(Cr)[16],使用原子荧光法(AFS 2100,北京海光仪器有限公司)测定土壤中w(As)[17].
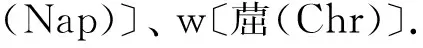
为保证分析样品的准确性,采用现场平行样、空白样品、实验室平行样和加标样品进行质量控制,国家土壤标准物质测试结果均在土壤成分的认定值范围内,重金属的加标回收率范围为81%~130%,相对偏差控制在0~12%之间;PAHs的加标回收率范围为55%~104%,相对偏差范围控制在1%~14%之间. 测试结果均符合相应标准方法质量控制与保证要求.
1.3 土壤污染物关联性分析
土壤污染物含量是多种因素共同影响的结果,其作用机理较为复杂,利用神经网络进行污染物含量预测之前,需要考虑不同污染物之间的交互作用[19],对模型的输入参数进行选取,因此该文通过多元统计方法〔相关性分析、主成分分析(principal component analysis, PCA)和聚类分析〕分析土壤中重金属和PAHs污染物间的关联性,为神经网络输入参数的选取提供依据.
关联性分析中重金属污染物输入参数为w(As)、w(Cr)、w(Zn)、w(Cu)、w(Pb)、w(Ni)、w(Cd),PAHs污染物输入参数为w(BaP)、w(DBA)、w(BkF)、w(BbF)、w(BaA)、w(Nap)、w(Chr). 相关性分析选择双变量Pearson法,显著性检验选择双尾检验[20];主成分分析选择KMO和Bartlett法进行球形度检验,利用最大方差法获得旋转因子,旋转方法为Kaiser标准化的正交旋转法,旋转在迭代5次后收敛[21-22];聚类分析选择按照组间连接系统聚类,选择Pearson相关性作为度量标准.
关联性显著的元素可能具有同源性,能够提高预测精度[23-24],但是即使部分污染物关联性较弱,二者之间可能存在非线性相关性,仍可能对预测精度有积极影响. 因此,该文中关联性较弱的污染物数据仍作为神经网络预测模型的输入因子进行训练,并设置将关联性较弱因子去除后的输入因子预测模型作为对照样本,探究关联性弱的因子对BP神经网络模型预测精度的影响.
1.4 BP神经网络模型构建及污染物含量预测
BP神经网络是一种典型的多层前馈网络[25],其函数逼近、回归计算等能力已被广泛应用于环境科学研究领域,在预测土壤污染物的空间分布方面均取得了较好的效果[26-28].
该研究所选场地范围较大,分析样品数量多,受成本限制,个别采样点的某些污染物指标未检测,导致数据缺失. 为保证检测数据的完整性,通过构建BP神经网络对缺失数据进行预测:将样本中不含缺失数据的因子作为模型的输入条件,含有缺失数据的因子作为输出条件,利用样本中的已知数据训练神经网络,在训练达到要求后,将缺失样本的已知数据输入模型,输出值即为缺失数据的预测值[29]. 研究区共获得1 691组土壤样本数据,随机抽取30组作为验证样本,在其余样本中随机选取50、200、800和1 661组(剩余全部样本)作为训练样本,其中,w(Cu)、w(Pb)和w(DBA)、w(BkF)、w(BbF)、w(BaA)、w(Nap)、w(Chr)作为缺失数据,通过构建的神经网络对缺失数据进行预测,并与验证样本的实测数据进行对比,评价模型的预测精度.
重金属含量预测选取采样点空间坐标参数、土壤pH、含水率(ω)、w(As)、w(Cr)、w(Zn)、w(Ni)、w(Cd)作为输入参数,w(Pb)和w(Cd)作为输出参数;PAHs含量预测选取采样点空间坐标参数、土壤pH、含水率(ω)和w(BaP)作为输入参数,w(DBA)、w(BkF)、w(BbF)、w(BaA)、w(Nap)、w(Chr)作为输出参数.
构建的BP神经网络拓扑结构见图2,神经网络每个节点代表一种特定的输出函数,称为激活函数[30],每两个节点的连接代表权重,通过不断学习来调整权重值[31],该文采用的学习速率为0.05. 构建的双层隐含层单元数分别为20和15个. 选取正切函数tansig作为隐含层的传递函数,线性函数purelin作为输出层的传递函数,共轭梯度函数trainscg作为训练函数对样本进行训练[32]. 重金属和PAHs指标最大迭代次数分别设置为20 000和 10 000 次,通过反复迭代,最终确定权值和阈值,建立预测模型.
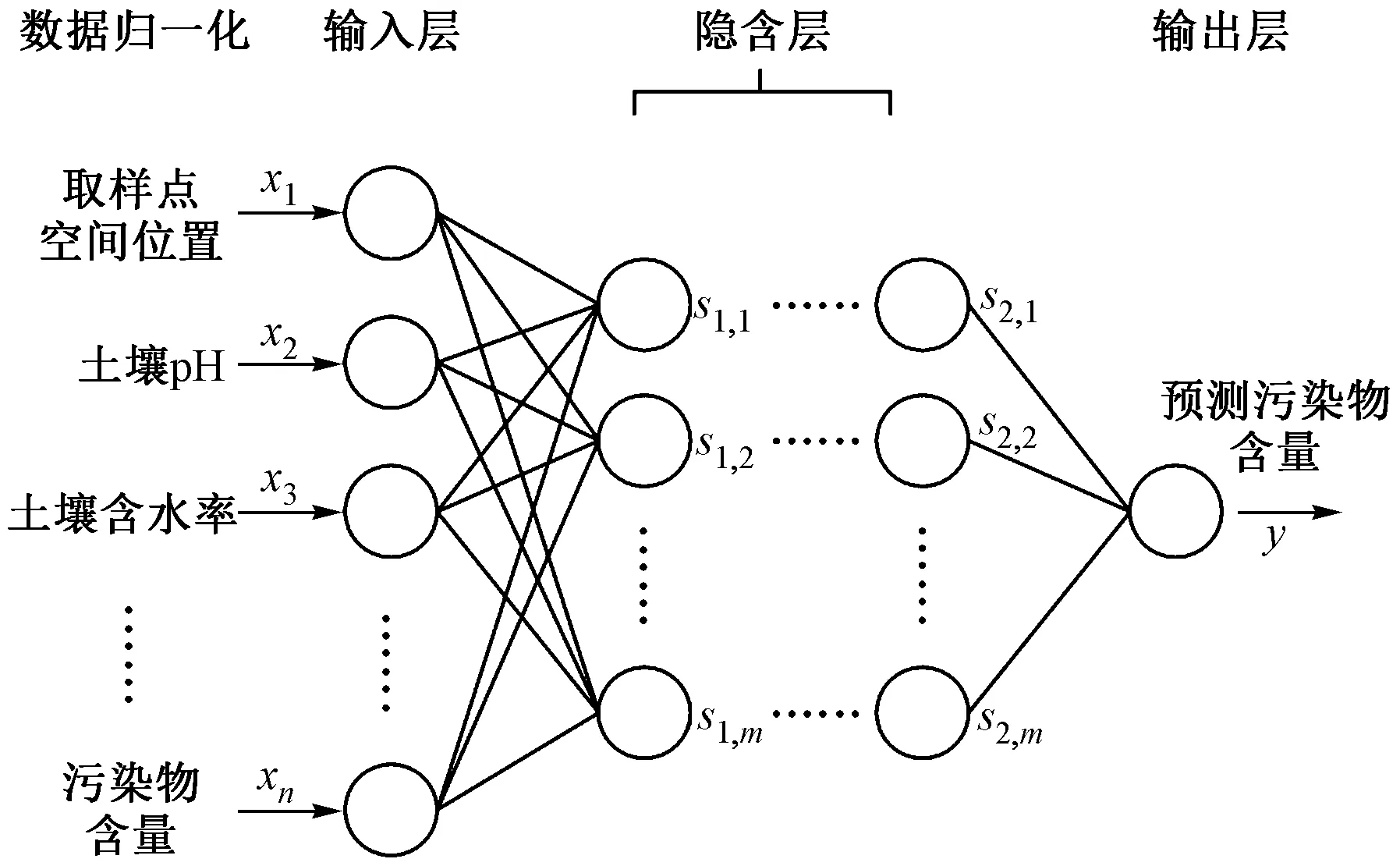
图2 BP神经网络拓扑结构Fig.2 Topological of BP neural network
BP神经网络根据梯度下降法调节连接权值,使训练误差达到最小,为使输入数据能够适应传递函数,提高计算过程的收敛速度,需要对训练数据进行归一化处理[33],处理后的变量取值范围在[-1,1]之间,计算方法如式(1)所示:
(1)
式中,xi为输入变量ti归一化后的值,tmax和tmin分别为输入变量X的最大值和最小值.
1.5 数据分析
所有试验数据使用Microsoft Excel 2013进行处理,并采用SPSS 22软件进行多元统计分析;利用Matlab 2014软件编写程序构建BP神经网络的预测模型,采用OriginPro 9.0软件进行模型精度分析.
2 结果与讨论
2.1 土壤重金属和PAHs含量特征
研究区土壤污染物含量统计结果见表1[34]. 结果显示,除w(Chr)外,土壤中重金属和PAHs均存在不同程度的超标现象. 土壤重金属污染物中,除w(Cr)外,其他6种重金属平均含量均高于当地土壤背景值,与GB 36600—2018《土壤环境质量 建设用地土壤污染风险管控标准》[35]中的风险筛选值对比,7种重金属含量超标率表现为w(Ni)>w(Cu)>w(As)>w(Pb)>w(Zn)=w(Cd)>w(Cr),最大超标倍数分别为43.93、8.45、5.80、8.05、5.03、17.70和2.98倍;土壤PAHs污染物中,w(BaP)的超标情况较为严重,局部超标倍数较高,与GB 36600—2018中土壤PAHs风险筛选值对比,除w(Chr)未超标外,其他6种PAHs含量超标率表现为w(BaP)>w(Chr)>w(DBA)>w(BbF)=w(BaA)>w(Nap)>w(BkF),最大超标倍数分别为120.00、28.00、30.55、30.36、3.02和1.22倍.
变异系数(CV)可以反映土壤污染物的变异程度,该值越大,表明该污染物受人为活动的影响越强[36]. 研究区土壤重金属和PAHs的变异系数见表1[34],其中重金属Zn、Cu、Pb、Ni和Cd的变异系数范围为2.75~8.12,属于强变异(CV≥1.0);As和Cr的变异系数分别为0.43和0.82,属于中等变异(0.1≤CV<1.0);PAHs变异系数为3.49~6.84,属于强变异[37]. 由此可见,场地重金属和PAHs污染物受到较强的人为污染源影响.
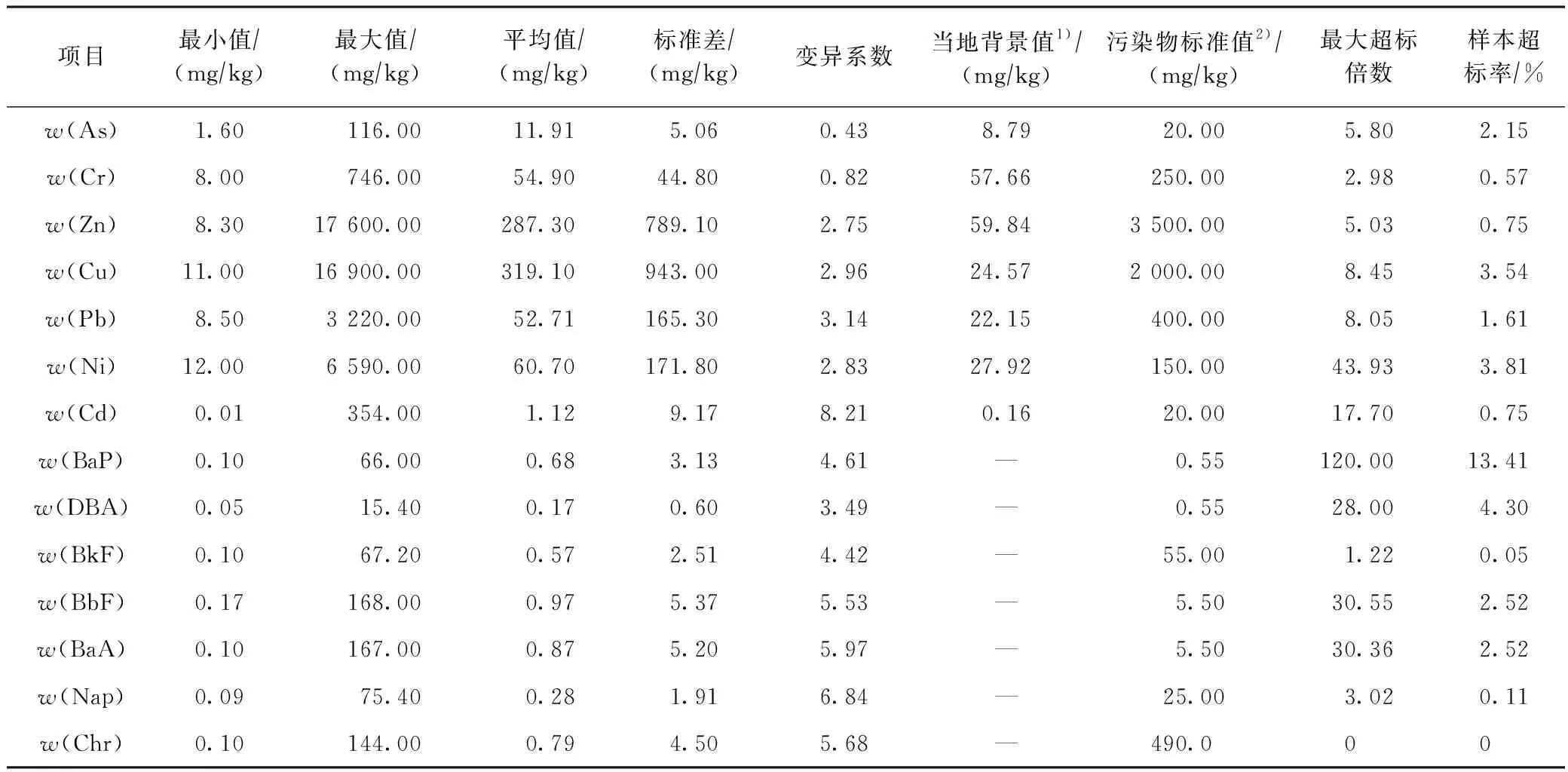
表1 研究区土壤重金属和PAHs的含量统计值[34]
2.2 土壤污染物关联性分析
2.2.1重金属污染物
相关性分析通常作为污染物同源鉴别的依据[38-39]. 从表2可以得出,Zn与Cu、Pb、Cd均具有较强相关性(R为0.579~0.673,P<0.01),Cu与Ni相关性较好(R=0.519),Cr与其他6种重金属相关性均较差,其他重金属间彼此相关性较弱,表明Cr与其他重金属的来源均不同. 由于研究场地不同类型的生产车间较多,因此不同区域土壤重金属污染来源差异性较大.
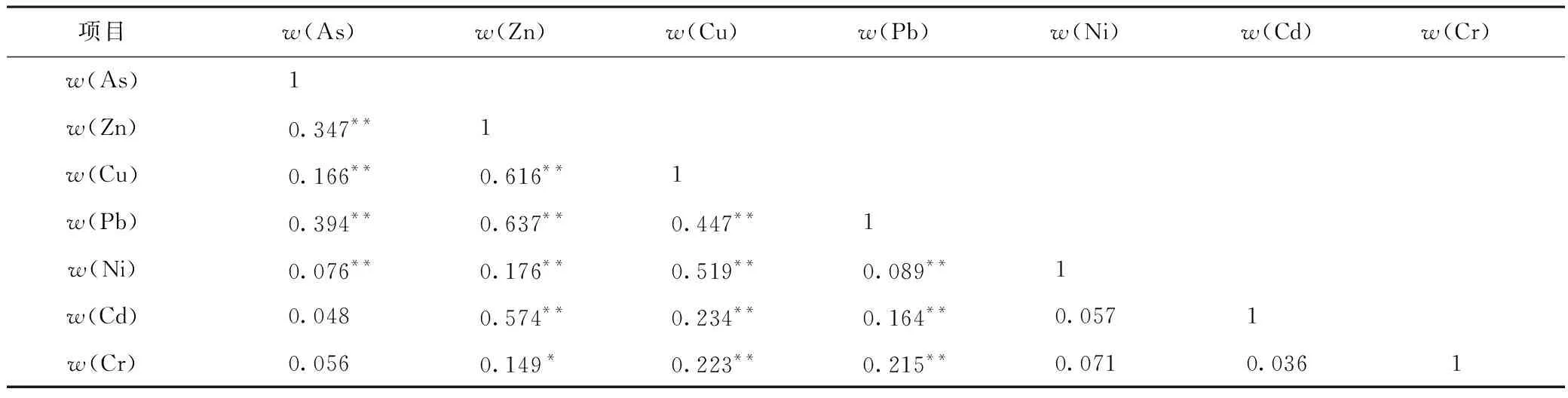
表2 研究区土壤7种重金属含量的相关性
KMO检验值(0.607)和Bartlett球形度(ξ=4 045,P<0.05)分析结果表明,该研究中重金属污染物含量数据适用主成分分析. 7种重金属经PCA解析后〔见图3(a)〕,获得PC1、PC2、PC3和PC4共4个主成分,累计方差贡献率为84.01%,各主成分方差贡献率分别为23.54%、23.08%、21.82%和15.57%. 从因子载荷(F)来看,PC1以As(F=0.876)、Pb(F=0.735)和Zn(F=0.510)为主导,PC2以Cd(F=0.930)和Zn(F=0.734)为主导,PC3以Ni(F=0.935)和Cu(F=0.747)为主导,PC4以Cr(F=0.97)为主导. 值得注意的是,前2个主成分中,Zn的正载荷均较高,表明Zn污染来源较广,且Zn与As、Pb、Cd具有同源性;Cr与其他6种重金属来源均不同.
聚类分析将7种重金属分为三簇〔见图3(b)〕,第一簇为Zn、Pb、As和Cd;第二簇为Cu和Ni;第三簇为单独Cr,簇距离越低,表示因子间关联越显著[40-41]. 由图3(b)可见,第一簇中Zn与Pb、As、Cd的簇距离较小,表明Zn与这3种重金属具有相似污染源;Cr与其他簇的距离均较大,表明Cr与其他6种重金属的来源差异性较大.
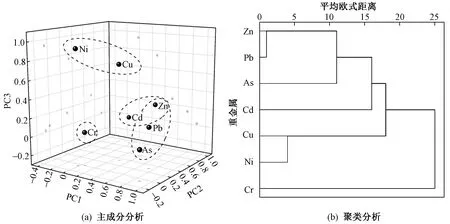
图3 研究区土壤中7种重金属主成分和聚类分析Fig.3 Principal component diagram and dendrogram of seven heavy metals contents in soils of the study area
上述3种多元统计分析方法所得结果相近,综合分析结果并结合场地生产历史可以得出:不同生产车间的特征污染物不同,Zn、Pb、As和Cd是熔铸车间的主要产品或原料,关联性较好;Cu和Ni主要是管棒车间的主要产物,关联性较好,这些重金属污染主要源自不同生产线的原材料和产品;Cr仅在盘管车间涉及污染,且w(Cr)(平均值为54.9 mg/kg)与当地土壤背景值(57.7 mg/kg)接近,相关研究表明,Cr污染主要源于成土母质[42-43],研究区Cr判断为受少量工业影响的自然源,因此与其他6种重金属关联性较弱.
2.2.2PAHs污染物
研究区土壤中7种PAHs相关性分析结果见表3,除Nap外,BaP、DBA、BkF、BbF、BaA和Chr彼此间均呈显著相关(P<0.01),表明这6种PAHs具有相同或相似的来源;Nap与其他PAHs相关性较弱.
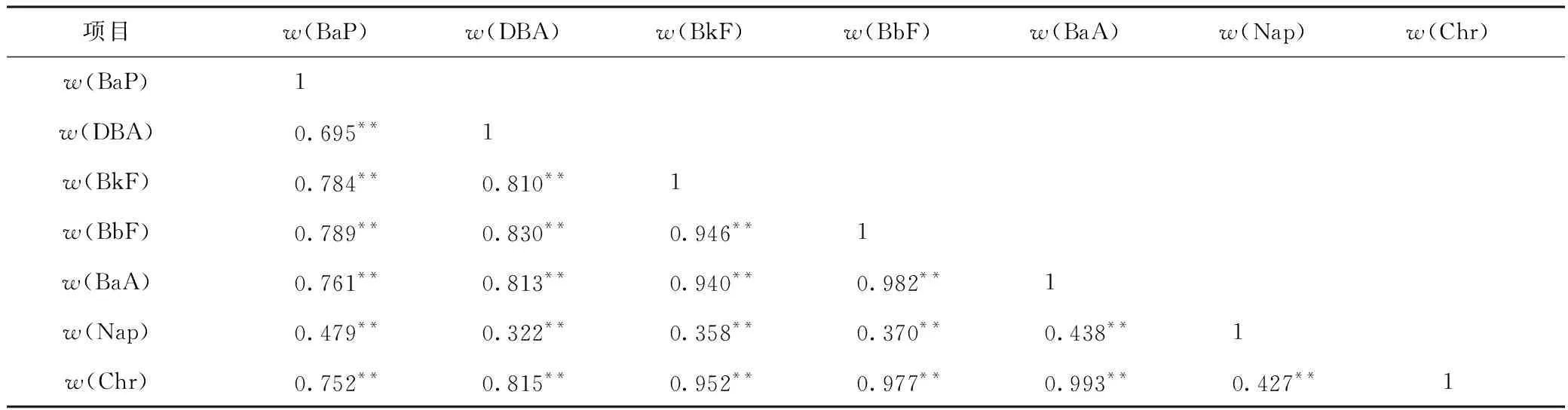
表3 研究区土壤中7种PAHs的相关性
KMO检验值(0.854)和Bartlett球形度(ξ=23 761,P<0.05)分析表明,PAHs含量数据适用主成分分析. 通过分析获得2个主成分〔见图4(a)〕,累计方差贡献率为90.53%,PC1、PC2的方差贡献率分别为71.73%和18.80%. 从因子载荷(F)来看,PC1以BaP(F=0.762)、DBA(F=0.874)、BkF(F=0.953)、BbF(F=0.968)、BaA(F=0.946)和Chr(F=0.950)为主导,PC2以Nap(F=0.973)为主导,这与PAHs相关性分析结果一致.
聚类分析也将7种PAHs分为两簇〔见图4(b)〕,第一簇为BaP、DBA、BkF、BbF、BaA、Chr,簇距离均小于10;第二簇为单独Nap,进一步表明除Nap外的其他6种PAHs具有相同或相似污染源.
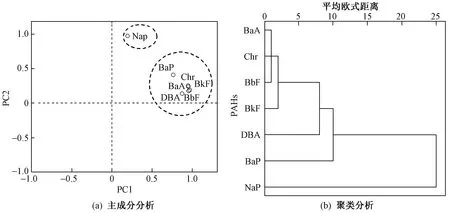
图4 研究区土壤中7种PAHs主成分和聚类分析Fig.4 Principal component diagram and dendrogram of seven PAHs in soils of the study area
结合厂区生产历史并综合3种分析方法结果表明,除Nap外,BaP、DBA、BkF、BbF、BaA和Chr彼此关联性较好,其中BaP、BaA和Chr是燃煤型排放的标志污染物,BkF、BbF和DBA主要来自汽油或柴油的燃烧[44],因此推断这6种PAHs主要来自燃煤和交通混合源[45];而Nap的产生可能与生物质不完全燃烧有关[46],因此与其他6种PAHs关联性较弱.
2.3 BP神经网络训练及检验
2.3.1不同训练样本数对神经网络精度影响
按照1.4节建立的BP神经网络模型进行训练,得到不同训练样本数量对训练精度的影响如图5所示. 由图5可以看出,随着训练样本数量的增加,神经网络训练误差(mean squared error,MSE)逐渐减小,并且训练结束时MSE更接近设置的目标误差,表明随着样本数量的增加,训练精度逐步提高;而当训练样本数据减至50个时,重金属和PAHs相应BP模型在未达到迭代次数(20 000 和 10 000 次)时提前终止训练,表明随着迭代次数的增加,训练误差不再降低,训练精度无法提高,停止训练. 因此,适当增加训练样本数量能够有效提高模型预测精度.
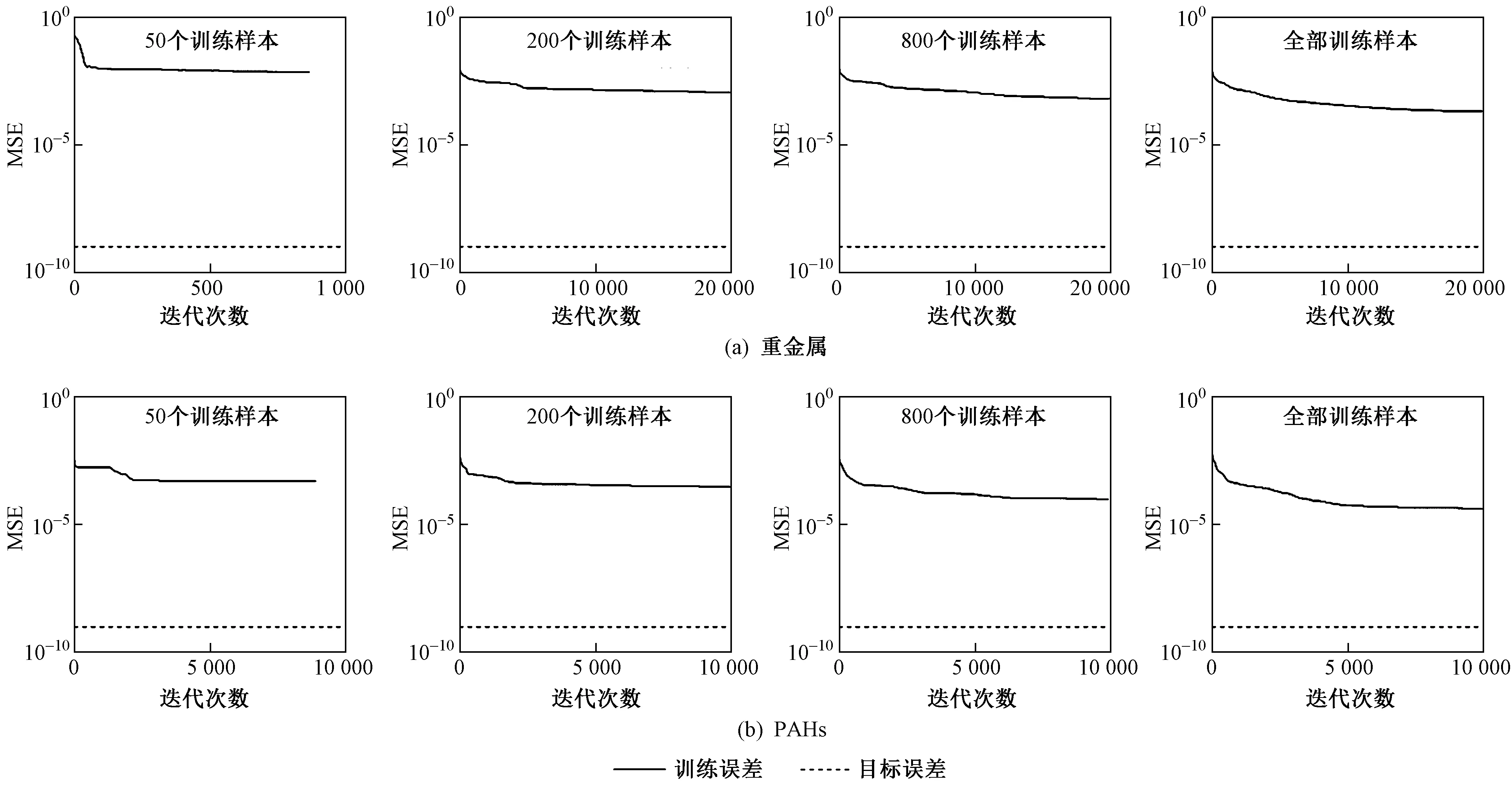
图5 不同训练样本数量对BP神经网络精度的影响Fig.5 The effect of different training sample size on the accuracy of BP neural network
2.3.2神经网络训练精度和误差分析
选择全部1 661个训练样本建立BP神经网络模型,结果如图6所示. 重金属及PAHs样本在训练次数分别为 20 000 和 10 000 次时达到最佳效果,训练样本MSE分别为1.9×10-4和4.3×10-5,表明训练收敛效果较好;同时,训练样本输出值和目标值之间的相关系数(R)分别达到 0.990 11 和 0.995 19,R接近1,表明重金属和PAHs样本神经网络训练效果较好.
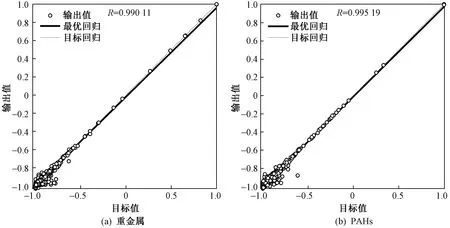
图6 BP神经网络训练误差曲线和线性回归结果Fig.6 The error curve diagram and linear regression diagram of BP neural network training
利用训练完成后的BP神经网络模型对30组验证样本的缺失数据〔w(Cu)、w(Pb)和w(DBA)、w(BkF)、w(BbF)、w(BaA)、w(Nap)、w(Chr)〕进行预测,结果如图7所示. 缺失数据预测结果与实测结果的R范围为0.901~0.996,预测曲线与实测曲线重合度较好. 将BP神经网络模型预测结果与实测结果进行对比分析,结果(见表4)显示,验证样本的决定系数(R2)范围为0.812~0.993,表明该模型预测拟合度效果较高. 模拟效率系数(Nash-Sutcliffe efficiency coefficient,NSE)通常是衡量模拟结果可靠性的重要指标[29],取值范围为(-∞,1],当NSE为正值时,表明模拟结果可信,且该值越接近1,表示模型匹配程度越好. 由表4可见:该研究中NSE范围为0.779~0.959,除w(DBA)外,其他验证样本的NSE均大于0.8,模拟效果较好,这与其他相关研究结果[47]相似;同时,验证样本的均方根误差(RMSE)和平均绝对误差(MAE)均较小. 综上,BP神经网络模型可靠性高,能够较好地预测研究区土壤重金属和PAHs含量.
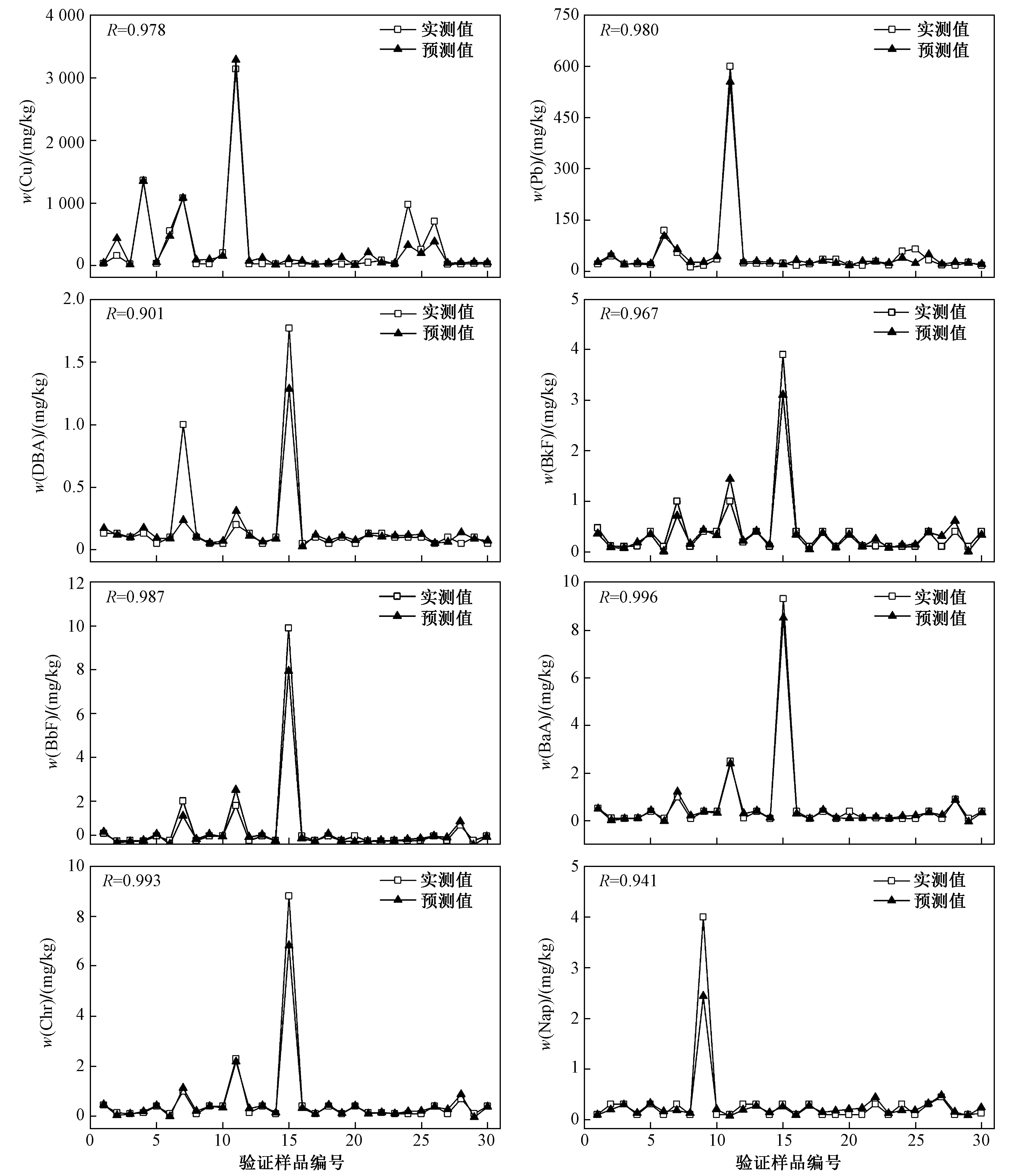
图7 BP神经网络预测值与实测值结果散点图Fig.7 The scatter diagram of predicted values and measured values of BP neural network
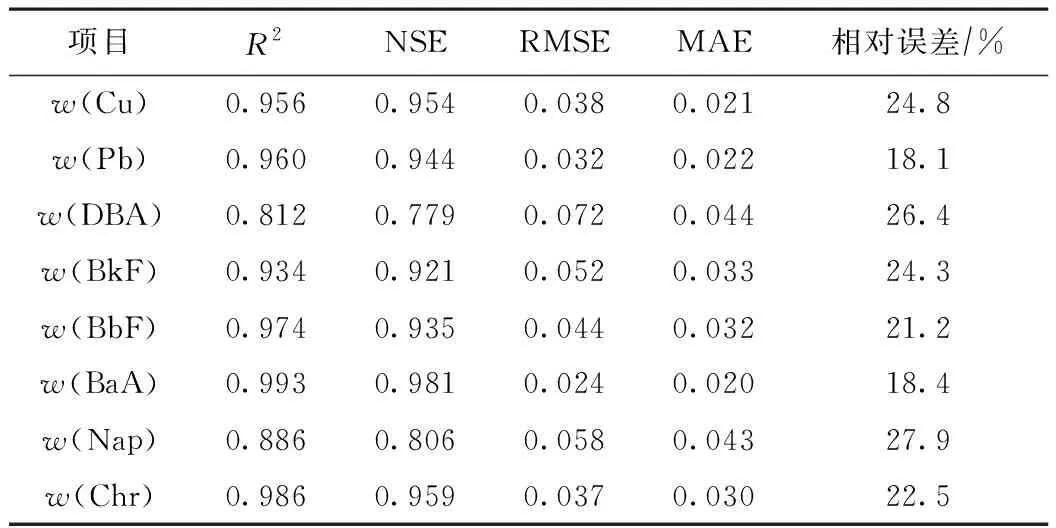
表4 BP神经网络预测精度和误差分析
为了探究污染物关联性对BP神经网络模型预测精度的影响,根据污染物的关联性分析结果,该研究去除了关联性较弱的因子〔w(Cd)、w(Cr)〕,选取重金属中关联性较强的因子〔(w(As)、w(Cr)、w(Zn)、w(Ni)〕和采样点空间参数以及理化性质作为输入变量,w(Cu)、w(Pb)作为输出变量,在其他参数不变的条件下构建对照模型,该对照模型的预测结果与选取全部因子作为输入变量构建的模型预测结果对比见表5. 由表5可以看出,与去除关联性较弱的因子相比,选取全部因子作为输入变量建立的预测模型整体拟合度更好,其精度分析指标(R2)相比于对照模型提高了0.129,NSE提高了0.134,误差分析指标RMSE和MAE分别降低了0.036和0.031. 由此可见,相比于仅使用关联性强的因子作为输入参数,考虑不同影响因子构建的BP神经网络模型预测更加准确可靠. 推测原因可能是,关联性较弱因子之间仍有非线性相关性,但这种关联难以通过具体数学方程计算,而神经网络不需要确定具体的映射方程,因此将这些因子作为输入变量构建神经网络,能够和输出端建立较好的映射关系,从而进一步提高预测模型的精度.

表5 不同输入变量的预测模型精度对比
3 结论
a) 通过分析某金属加工厂生产区内土壤污染特性,结果表明,除PAHs的Chr外,重金属和PAHs均存在不同程度的超标现象,其中重金属Ni、As、Cu及PAHs中BaP超标较为严重;重金属和PAHs变异系数较高,该区域土壤受到较强的人为污染源影响.
b) 多元统计分析结果显示,污染土壤中重金属Zn与Pb、As、Cd关联性均较好,Cu与Ni关联性较好,而Cr与其他6种重金属关联性较弱,Zn、Pb、As、Cd、Cu和Ni污染主要源于不同生产线的原材料和产品,Cr为受少量工业影响的自然源;PAHs中除Nap外,BaP、DBA、BkF、BbF、BaA和Chr彼此关联性较好,6种关联性好的PAHs主要来自燃煤和交通混合源,Nap则源于生物质不完全燃烧.
c) 构建的BP神经网络模型训练效果较好;验证样本的预测值与实测值之间的误差分析显示,各污染物含量的决定系数(R2)范围为0.812~0.993,模拟效率系数(NSE)范围为0.779~0.959,均方根误差(RMSE)和平均绝对误差(MAE)均较小;构建的BP神经网络模型准确可靠,能够较好地预测研究区内土壤污染物含量,且关联性较弱因子的输入能进一步提高预测模型的精度.
猜你喜欢
农业灾害研究(2022年2期)2022-05-31
小学教学参考(语文)(2022年3期)2022-05-26
石油沥青(2022年2期)2022-05-23
老年医学研究(2021年5期)2022-01-19
汽车工程师(2021年12期)2022-01-17
今日农业(2021年11期)2021-11-27
少儿科学周刊·儿童版(2021年23期)2021-03-24
云南医药(2020年5期)2020-10-27
饮食与健康·下旬刊(2019年9期)2019-03-08
科学中国人(2018年8期)2018-07-23
