
基于对抗学习和知识蒸馏的神经网络压缩算法
2021-11-12 15:11刘金金李清宝李晓楠
计算机工程与应用 2021年21期
刘金金,李清宝,李晓楠
1.战略支援部队信息工程大学,郑州450003
2.数学工程与先进计算国家重点实验室,郑州450003
3.中原工学院 计算机学院,郑州450007
深度神经网络在多种计算机视觉相关的任务中展现出了最优越的性能,例如图像分类[1]、工业视觉检测[2]、姿态估计[3]、行人再识别[4]和人脸识别[5]等。随着配套硬件设备的发展和对卷积神经网络认识的不断加深,研究表明越深的网络能够提取越抽象的语义信息,网络的表示能力越强。然而更深更宽的神经网络将难以收敛,并且会导致反向传播算法中的梯度消失[6-7]。残差网络ResNet[1]和批量归一化(Batch Normalization,BN)[8]能够在一定程度上解决这一问题,但是具有大量参数的深度学习模型需要更大的存储空间和更强的运算单元,无法在移动终端上进行部署和实时推理,从而影响深度学习模型在实际应用中的落地和推广。例如公共区域的视频监控系统多部署在内存有限和计算能力较低的嵌入式设备上,无法实时准确地对视频帧中的多人进行身份识别和行为分析。本研究旨在改善深度学习网络在人脸识别系统中的部署和应用问题。
为了解决这一问题,研究人员采用多种技术压缩网络参数,主要包括量化或二值化、因子分解、网络剪枝和知识蒸馏[9]等。其中知识蒸馏的方法基于教师-学生的策略,旨在训练一个轻量级的学生网络,使学生网络模仿完备的大尺寸的教师网络输出的软目标,达到知识迁移的目的。相较于样本固有的一位有效信息标签,教师网络的输出能够提供“不正确”分类的相对概率,使分类概率具有更大的信息量。学生网络的权重更新是一个最小化知识蒸馏损失的过程,即最小化学生网络输出与教师网络输出、学生网络输出与真实标签间的差异。
虽然通过最小化知识蒸馏损失能够使学生网络模仿教师网络的输出,但是其性能仍有差距。主要有以下几个原因。首先学生网络只学习教师网络输出的分类概率分布,而忽略了包含丰富语义信息和空间相关性的中间特征图。一些现有方法直接对齐学生网络和教师网络的中间层表示,不能有效地转移潜在的空间相关性。其次由于教师网络和学生网络具有不同的拓扑结构,其最优解空间也存在差异。如果只采用蒸馏损失全程监督学生网络的训练过程,学生网络无法找到自己的最优解空间。此外,教师网络的预测不是完全正确的,在训练过程中,如果学生网络完全学习教师网络输出的软目标,会迁移错误的知识。
针对上述问题,本研究提出了一种针对分类概率和特征图两个层面的深度学习模型压缩算法。框架由三部分组成,分别为预训练得到的教师网络、小规模的学生网络和判别器。其中教师网络和学生网络可以为任意结构的卷积神经网络,判别器则为由多个全连接层构成的深度学习网络,并在训练过程中更新权重。为了减轻教师网络错误分类的影响,添加指示函数,优化知识蒸馏损失,使学生网络只学习正确的输出。此外由于人脸特征具有丰富的空间相关性,学生网络模仿教师网络提取的特征图是十分必要的。引入生成对抗网络[10]中的判别器,识别输入的特征图是“真”(教师网络)还是“假”(学生网络),使学生网络能够自动学习类间的相关性。为了使学生网络能够自主探索自己的最优解空间,在训练过程中打破教师网络和学生网络之间的单向转换通路,使其相互学习,交替更新。完整流程如图1所示,其中实线为网络的正向传播过程,虚线为目标函数的计算过程。

图1 对抗学习辅助下的知识蒸馏过程Fig.1 Process of knowledge distillation assisted by adversarial learning
本研究的贡献总结如下:
(1)改进经典的知识蒸馏损失,使其不仅能够学习教师网络输出的正确软目标,而且能够从中间层获取丰富的隐含知识。
(2)引入对抗学习中的判别器,鉴别教师网络和学生网络特征图的差异,进一步缩小大模型和容量有限的小模型最优解空间之间的差异。
(3)在训练过程中采用互学习的策略,使教师网络和学生网络学习对方的特征图,提升泛化能力。
(4)由于本研究针对人脸识别的应用,采用公开的人脸数据集训练模型,并与已有的理想算法进行比较,验证所提算法的有效性和先进性。
1 相关工作
神经网络的中存在很多冗余参数,文献[11]的研究表明,模型中有仅用1%的深度卷积就能达到和原来网络相近的性能。神经网络压缩早在文献[12]的工作中就已为人所知,但最近由于现代深度模型的性能和计算需求的综合增长而受到了广泛关注。
1.1 卷积神经网络压缩算法
神经网络压缩的相关方法主要分为五大类:量化、剪枝、因子分解、精细模型设计和知识蒸馏等。
量化的方法是将网络的权重离散化,逐步将预先训练的全精度卷积网络转换为低精度卷积网络。基于这一思想,Gong等人[13]使用k-means对权值进行聚类,然后进行量化。量化可以简化到二进制级别的−1和1,如XNOR-Net[14]和BinaryConnect[15],但后者不在参数更新期间量化,而是在前向和后向梯度传递的过程中二进制化权重。
剪枝则是根据一定规则剔除网络中链接的过程,根据粒度的粗细又可以分为面向链接的剪枝和面向卷积模板的剪枝。Han等人[16]将量化与剪枝相结合,进一步减少存储需求和网络计算。在HashedNet[17]中,网络连接被随机分组到哈希桶中,相同桶的连接共享权值。然而当使用卷积神经网络时,稀疏连接不一定会加速推理。出于这个原因,Li等人[18]裁剪完整的卷积模板,而不是单个的连接。因此剪枝后的神经网络仍然进行密集矩阵乘法,而不需要稀疏卷积库。
因子分解的方法旨在对卷积模板的矩阵进行低秩分解或找寻近似的低秩矩阵。其中,使用深度可分离卷积和点卷积的组合可以近似深度卷积模板,例如MobileNet[19]和ShuffleNet[20]。
相较于AlexNet[21]和VGG16[22]需要较多的计算资源,残差网络(Residual Network,ResNet)及其变体不仅减少了参数数量,同时保持(甚至提高)了性能。SqueezeNet[23]通过利用1×1卷积模板替换3×3卷积模板并减少3×3卷积模板的通道数量来进一步修剪参数。此外Inception[24]、Xception[25]、CondenseNet[26]和ResNeXt[27]也有效地设计更深更宽的网络,而不引入比AlexNet和VGG16更多的参数。Octave卷积[28]根据不同的频率将特征图进行因式分解,对不同频率的信息进行不同的存储和操作,以实现基于高低频率的轻量化存储方式。Octave卷积可用于ResNet、GoogLeNet等基线网络结构的优化,也可以对如MobileNet-v1&v2,ShuffleNet v1&v2等常规轻量化网络进行进一步地优化,能够有效减少深度神经网络对于存储空间的要求,实现轻量化。
除了人工设计轻量化深度神经网络以外,基于神经架构搜索的自动化模型设计的优势愈加凸显,如MnasNet[29]等。
1.2 知识蒸馏
知识蒸馏(Knowledge Distillation,KD)的目标是通过使用Softmax函数之前(Logits)或者之后的输出(分类概率),将知识从教师网络转移至学生网络。
为了使学生网络能够完成多个计算机视觉任务,文献[30]则是蒸馏多个教师网络,构成多分支的学生网络。文献[31]优化了教师-学生策略,弱化策略中两者的指导与学习关系,两个均从头训练,相互学习,并且采用循环训练策略同时训练多个网络。文献[32]中提出的教师-学生策略中,两种网络采用相同的架构,而使用不同分辨率的人脸图像,能在一定程度上解决实际应用中图像分辨率低的问题。学生网络的训练方法分为知识蒸馏和知识迁移两种,前者随机初始化学生网络参数,采用基于分类的交叉熵损失和特征向量间的欧氏距离更新网路,后者则是用教师网络的参数初始化学生网络,然后只采用交叉熵损失更新网络。
1.3 对抗学习
生成对抗网络通过对抗学习生成图像,使生成器能够模拟特定的特征分布空间。这一本质特性与知识蒸馏的目的存在交叉,可以将小容量的学生网络看作生成器,在给定相同输入图像的情况下,将学生输出映射到教师输出。
Belagiannis等人提出了一种基于对抗学习的网络压缩算法[33],去掉了KD损失中学生网络输出与真实标签的交叉熵损失,而是使用两者Logits间的L2范数,故不需要提前给出训练样本的真实标签。由于学生网络具有较小的容量,很难使其完全精确地模仿教师网络的软目标,增加对抗损失,使学生网络能够能快地收敛于教师网络的最优解空间。由于判别器过早达到平衡会使学生网络无法从教师网络学习到有效的梯度,引入对判别器的正则化,避免判别器支配后续的训练过程。
针对人脸识别任务的特性,本研究优化了现有的知识蒸馏方法,不只简单学习分类概率,同时考虑特征图间的知识迁移。为了使学生网络能够探索自己的最优解空间,加入判别损失这一更加宏观的标准,使学生网络在训练过程中具有更多的自主性。
2 算法分析
在视频监控系统的应用中,为了具有较好的人脸识别性能,多采用具有更深更宽结构的深度学习模型。相反,在一些现实场景中,为了满足资源有限的设备的需求,需要对已有模型进行剪枝或量化。为了解决这两个目标之间的权衡困难,本研究提出了一种对抗学习辅助下的知识蒸馏算法。
本研究主要从知识获取对象和知识蒸馏策略两个方面入手优化了现有算法,从以下三个方面进行详细阐述。
2.1 基于分类概率的知识蒸馏优化
知识蒸馏的基本思想是通过最小化教师网络和学生网络间的预测分布的差异,使学生网络近似于教师网络。神经网络通常通过使用Softmax输出层来产生分类概率,将计算出的每个类别的Logits转换为分类概率,如式(1)所示:

其中,zi为Logits的第i个分量,T为温度参数,越高的温度会产生越软的类间分类概率。
知识蒸馏损失有两部分组成,一是分类概率间的交叉熵,学生网络和教师网络使用相同的温度T,二是学生网络的分类预测与真实标签间的交叉熵损失,温度为1,如式(2)所示:
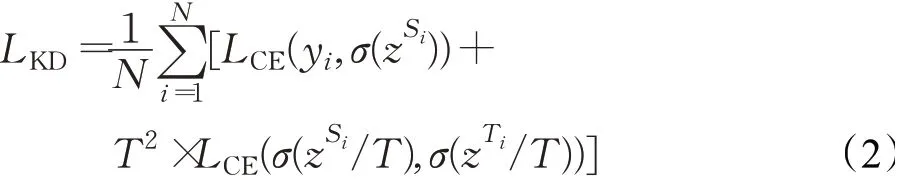
其中,N为小批量的尺寸,LCE代表交叉熵,也可以用相对熵,即Kullback-Leibler散度代替。σ()代表Softmax函数,T为蒸馏温度,yi为样本i的真实标签,zS∈ℝC和zT∈ℝC分别为C类分类任务的学生网络和教师网络输出的Logits。
虽然训练初期教师网络比学生网络更准确,但教师仍然会有一些预测错误。当教师网络预测错误时,知识同样会转移到学生网络身上,这将会影响学生网络的表现。因此改进传统知识蒸馏的方法,忽略教师网络错误的预测分布,只把正确的预测分布传递给学生网络,具体目标函数如式(3)所示:

其中,I()为指示函数,yS为学生网络预测的标签。当教师网络能够正确预测输入样本的分类时,指示函数为1,学生网络同时学习样本标签和教师网络输出的软目标;教师网络无法正确分类时,指示函数为0,仅计算学生网络的分类情况和真实标签间的交叉熵。
2.2 对抗学习辅助下的特征图迁移
研究表明[34],位于较浅层面的卷积层会对边缘、角度、曲线等低级特征做出响应;下一级卷积层则能响应更复杂的特征,如圆和矩形。因此,当卷积操作逐渐加深,卷积层会提取出更复杂、高维的特征。另一方面,深度卷积特征也比浅层卷积特征更能代表网络的泛化能力。因此,选择教师网络Logits前的特征图作为学生网络学习的对象,分别记为f T和f S。
常用相似度计算方法有余弦距离、欧氏距离、马氏距离等。这些方法的目的均是使学生网络最大程度模仿教师网络输出的特征图。由于学生网络的容量小,它可能无法精确地再现某一特定的输出模态,并且实际中学生网络与教师网络具有不同的结构,没有必要精确地模拟一个教师网络的输出来达到良好的表现。因此本研究提出一个面向教师网络和学生网络的对抗学习机制。对抗训练策略缓解了人工设计损失函数的困难,已经在多个计算机视觉任务中显示出了优越性。
特征图学习机制由三部分组成,即教师网络、学生网络和判别器。教师网络和学生网络的输入为相同的人脸图像,将其输出的特征图作为判别器的输入,判别器鉴定其来自哪个网络。采用生成对抗网络中的对抗损失作为目标函数,如式(4)所示:
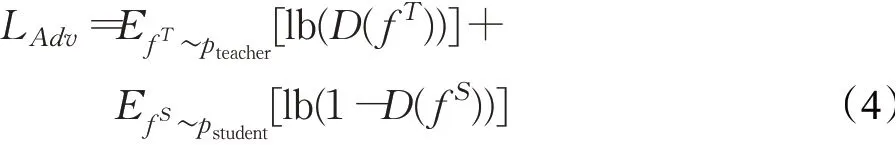
在训练过程中,判别器的目的是最小化对抗损失,确保正确区分两个不同的分布;学生网络的目的则是使判别器无法区分其与教师网络的差异,以此构成对抗训练判别器和学生网络交替更新,直至判别器的识别准确率为1/2,此时网络收敛。
相较分类概率,高维特征图能够保留更多的特征,采用高维的特征图作为判别器的鉴定对象能够使判别器具有更强的鉴别能力,指导学生网络的更新,最小化与教师网络的差异。
2.3 学生网络和教师网络的深度互学习
相关研究表明[35],教师网络的影响不总是积极的。在网络训练的前期,知识蒸馏辅助学生网络的更新,但是随后会抑制学生网络的优化。实验结果表明,在某一时期,交叉熵损失会反向上升。此外模型蒸馏算法需要有提前预训练好的教师网络,且教师网络在学习过程中保持固定,仅对学生网络进行单向的知识传递,难以从学生网络的学习状态中得到反馈信息来对训练过程进行优化调整。
深度互学习[36]指即多个网络相互学习,每个网络在训练过程中不仅接受来自真值标记的监督,还参考同伴网络的学习经验来进一步提升泛化能力。真值标签提供的信息仅包含样本是否属于某一类,但缺少不同类别之间的联系,而网络输出的分类概率则能够在一定程度上恢复该信息,因此网络之间进行分类概率交叉学习可以传递学习到的数据分布特性,从而帮助网络改善泛化性能。其次,网络在训练过程中会参考同伴网络的经验来调整自己的学习过程,最终能够收敛到一个更平缓的极小值点,小的波动不会对网络的预测结果造成剧烈影响,从而具备更好的泛化性能。
本研究中采用学生网络和教师网络特征图间的Jensen-Shannon散度作为互学习的目标函数,如式(5)所示。相较于KL散度,JS散度是对称的,解决了KL散度非对称的问题。

其中,qT和qS分别为教师网络和学生网络的分类概率分布。联合基于对抗学习的特征图迁移和互学习方法,学生网络不仅能够模仿教师网络特征图的分布,同时能够保留自主学习的能力。
综上所述,用以训练学生网络的目标函数的完整形式为:

其中,α,β∈[0,1)为超参数,用以平衡各部分间的权重。
3 实验结果与分析
3.1 实现细节
3.1.1 数据集
本研究中所采用CASIA-WebFace[37]和CelebA[38]数据集作为训练样本集。CASIA-WebFace数据集中的样本来自IMDb网站,有10 575人的494 414张照片。CelebA数据集包含超过200 000的名人图片,每张图片有40个属性标注。该数据集中的图像具有较大的姿态变化和复杂背景。对所有图像进行归一化处理,尺寸统一为256×256。
3.1.2 网络结构
由于残差网络在图像分类应用中具有最优的性能,所以本研究中采用ResNet-101作为教师网络。ResNet-101由两种残差块组成,一是Identity Block,输入和输出的维度相同,二是Conv Block,输入和输出的维度不同,用以改变特征向量的维度。教师网络预先在数据集上训练,在学生网络的训练过程中的互学习阶段微调。学生网络在实验中采用和教师网络同样采用残差结构的ResNet-18,在训练前随机分配链接权重。具体结构如表1所示。

表1 教师网络和学生网络的具体结构Table 1 Detailed structure of teacher and student
判别器是模型中的重要组成部分,必须在简单性和网络容量之间取得平衡。判别器由三个全连接层组成(128fc-256fc-128fc),中间激活为非线性激活单元ReLU。输出则是由Sigmoid函数给出的二元预测,判定输入的特征图来自哪个网络。
3.1.3 相关参数设置
在所有实验中,均采用随机梯度下降的算法。根据文献[39],动量设为0.9,权重衰减为0.000 1,小批量尺寸为128。对于两个训练集,均训练200轮次。初始学习率为0.1,分别在第80轮次和160轮次分别将学习率调整为0.01和0.001。
在前160轮中,只采用知识蒸馏损失和对抗损失指导学生网络的更新,使学生网络的分类错误率迅速下降;在后40轮中加入两个网络的互学习损失,对学生网络微调,具有更好的泛化能力。在多次实验中选取最优的超参数,使学生网络尽快收敛,故在上述两个训练阶段超参数分别取α=0.5,β=0和α=0.5,β=0.05。
3.2 算法流程
网络压缩分为两个阶段:首先,在学生网络训练的前半段,知识蒸馏损失和对抗损失指导学生网络和判别器的更新,在训练的后半段,教师网络和学生网络互学习,对模型进行微调,以提高泛化能力。算法伪码如算法1所示。
算法1基于知识蒸馏和对抗学习的网络压缩算法
输入 预训练的教师网络;随机初始化的学生网络和判别器;训练数据集;学习率、小批量尺寸及α,β
输出 小尺寸的学生网络

3.3 性能对比
本节中从两个方面定量地分析所提方法的有效性,首先比较全监督下训练的学生网络和不同温度下知识蒸馏得到的学生网络,如表2所示;然后在CASIA WEBFACE和CelebA数据集上训练其他知识蒸馏方法,与所提方法比较,如表3所示。将数据集按照4∶4∶2的比例随机划分为训练集、测试集和验证集,表中准确率在验证集上获得,评价指标为Top-1准确率。

表2 全监督训练与知识蒸馏性能对比Table 2 Comparison between fully supervised training and knowledge distillation%

表3 所提方法与其他知识蒸馏方法的性能对比Table 3 Comparison between proposed method and other knowledge distillation methods %
表2 中前两行分别为全监督训练方式下得到的教师网络和学生网络,网络结构分别固定为ResNet-101和ResNet-18。ResNet-101的参数量为44.6×106,浮点运算量为1.8 GFLOPs,而ResNet-18的参数量仅为11.2×106,浮点运算量为7.6 GFLOPs。同时利用本文所提出的知识蒸馏算法训练ResNet-18网络,温度T∈{1,2,5,10}。表2中还可以看出,由于网络深度不同,全监督训练下的学生网络在两种验证集上的准确率均低于教师网络,但是学生网络的参数数量仅为教师网络的1/4,模型尺寸和识别性能间有较好的平衡。采用知识蒸馏算法得到的学生网络在验证集上的性能略低于全监督训练的教师网络,但是随着温度T的增加,其性能超越了全监督训练的学生网络。由此可见,本研究所提出的知识蒸馏算法能够使小尺寸的网络学习到大规模网络的知识,有效地实现知识迁移。同时,温度T越高,输出的分类概率越平缓,得到的识别性能越好;但是随着温度的逐渐增加,性能提高趋于平缓,表明较高的温度会引起错误标签的概率增加,使学生网络更多地关注相关知识。因此在知识蒸馏方法中选择合适的温度T是比较重要的。
本研究中还将所提方法与其他知识蒸馏算法进行了比较,包括经典知识蒸馏算法KD、深度互学习算法DML、FitNet[40]、Channel Distillation[41]和KTAN[42]。FitNet将中间层的表示作为学生网络的学习对象,要求学生网络的中间层模仿老师网络特定的中间层的输出。CD中分别计算教师网络和学生网络每个通道的注意力信息,教师监督学生学习其注意力信息,已达到通道间传递信息的目的。KTAN除了采用分类概率间的交叉熵损失外,采用均方误差损失最小化学生网络和教师网络特征图之间的差异,同时引入判别器鉴定特征图的出处。
表3 中的数据均在CASIA WEBFACE和CelebA数据集上获得,教师网络和学生网络的结构分别为ResNet-101和ResNet-18,训练参数如3.1.3小节所示。由表中数据可知,由于教师网络具有更深的结构,所以展现出最好的性能。五种引自文献的方法,除了CD和KTAN在CelebA数据集上的性能外,其余数据在Top-1性能中均低于全监督的学生网络。本文所提出的知识蒸馏方法相较其他知识蒸馏方法,学生网络不仅学习了教师网络正确的分类概率,同时利用对抗学习的方法使学生网络定性学习教师网络的特征图;在训练的后半段,教师网络和学生网络相互学习,促进学生网络探索自己的最优解空间,具有更好的泛化能力。在CASIA WEBFACE和CelebA两个数据集上,本研究的识别准确率均超过了全监督训练得到的学生网络,证明了所提方法的有效性和先进性。
3.4 消融实验
本节中,通过消融实验分别验证了式(6)中知识蒸馏损失,对抗损失和互学习损失的有效性。实验结果如表4所示。

表4 基于不同损失函数的性能对比Table 3 Performance comparison based on different loss functions %
对比表3和表4中数据可以看出,改进后的知识蒸馏损失剔除了错误估计样本,使识别性能得到了小幅度提升。分别在知识蒸馏损失的基础上添加基于特征图的对抗损失和互学习损失后,性能的提成在1%左右,均超过了互学习DML算法、将中间层作为学习对象的FitNet和CD方法。对比KTAN,本研究方法摒弃了均方误差,使学生网络不必完全模拟教师网络的特征图,能够自主更新,性能得到了进一步的提升。
通过消融实验可知,本研究所采用的三种损失函数能够有效地完成从教师网络到学生网络的知识迁移,不仅包括分类概率知识,同时学习了特征图的分布,并且适度保留自主学习的空间。
4 结束语
深度学习方法越来越多地应用于计算机视觉任务中,并且在人脸识别任务中的准确率已经超越了人眼,但是仍然面对着训练时间长、泛化能力弱、部署困难等落地问题。本研究针对深度学习模型在嵌入式设备难以进行部署和实时性能差的问题,深入研究了现有的模型压缩和加速算法,提出了一种基于知识蒸馏和对抗学习的神经网络压缩算法。算法框架由三部分组成,预训练得到的大规模教师网络,轻量级的学生网络和辅助对抗学习的判别器。学生网络通过知识蒸馏损失学习教师网络的分类概率,同时通过对抗损失模拟教师网络的特征图知识。鉴于教师网络和学生网络具有不同的最优解空间,在训练的后半段利用深度互学习理论,促使学生网络和教师网络相互学习,以促使学生网络探索自己的最优解。
针对人脸识别任务,采用CASIA WEBFACE和CelebA两个数据集作为训练集,通过消融实验验证了所提组合目标函数的有效性,同时与面向特征图知识蒸馏算法和基于对抗学习训练的模型压缩算法对比,实验数据表明,根据所提算法训练得到的学生网络具有较少的链接数,同时保证了较好的识别准确率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
今日农业(2019年15期)2019-01-03
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
初中生世界·七年级(2017年9期)2017-10-13
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
