
利用同质区特性的高光谱图像迁移学习分类
2021-11-12 15:16周绍光赵婵娟陈仁喜
计算机工程与应用 2021年21期
周绍光,吴 昊,赵婵娟,陈仁喜
河海大学 地球科学与工程学院,南京211100
高光谱成像是一项重要的遥感技术,它可以收集从可见光到近红外波长范围的电磁光谱。由于具有丰富的光谱信息,高光谱遥感影像可以区分细微的光谱差异,已广泛应用于许多领域。
成功应用高光谱影像的关键是精确的分类。已发表论文的统计结果表明,HSI分类(即根据其光谱特征将每个像素分配给一个特定的类别)是高光谱研究领域最活跃的一个方向。在HSI分类任务中,有限的可用训练样本始终是一个主要挑战。及时地标记大量训练样本具有很大难度,迁移学习的基本思想便成为应对这一挑战的潜在希望。
就遥感影像分类而言,迁移学习的目的是利用相似影像中丰富的标记样本提高缺少标记样本的新影像的分类精度。具有大量标记样本的影像称为源域,而缺少标记样本的待分类影像称为目标域。严格地讲,利用相似影像实现新影像分类的任务属于迁移学习的一个分支——领域自适应。源域影像和目标域影像具有一定的相似性,同时又有所不同,这是领域自适应方法存在的原因。
减小目标域和源域影像在特征空间的差异是达成迁移学习目的的最重要途径。这一任务与分类所采用的特征息息相关。最早的高光谱分类主要限于使用光谱信息。随着对空间信息重要性认识的不断提高,高光谱影像分类开始同时利用光谱信息和空间信息。近年来,深度学习技术得以迅速发展,基于深度学习技术的高光谱影像分类已取得了令人鼓舞的效果。因此,在深度学习基础上实现源域到目标域的信息迁移已成为众多研究者的共同目标。
事实上,伴随着著名的卷积神经网络(CNN)[1]的提出,很快即出现了相应的迁移学习思想:利用具体需要分类的数据集(目标域)中少量样本精调在庞大数据集(源域)上训练而得的分类模型,通过精调后的分类模型预测目标域其他样本的类别。这一方案简单有效,多次被研究者用于高光谱数据的分类[2-4]。也有观点认为这种简单的精调无法减小源域和目标域间较大的数据偏移(Data Shift),因而,引入领域自适应中的最大平均差异(MMD)技术来解决问题[5-6]。MMD立足于减小无标签样本间特征分布的差异,选择和训练样本需要一定的经验,而且需要大量的目标域样本以保证结果有效。
文献[7]利用少量目标域标记样本来克服无监督领域自适应的缺点。该方法利用经典的卷积孪生网巧妙地设计了深度领域自适应网络结构,利用源域样本和极少的目标域有标记样本对其进行训练,减少了源域和目标域同类样本间的距离,同时增加不同样本间的距离,实现两个域间特征的语义对齐。此方法采用的损失函数简称为CCSA(Classification and Contrastive Semantic Alignment)。
目标域每类只有一个标记样本的情况称为oneshot,这是有监督迁移的极端情况,近期广受关注[8-10]。实验已经证明CCSA在one-shot条件下也能取得良好的效果,而且,目标域标记样本每增加1个,分类精度都会显著提高。从这一研究成果可以推断:如果能够有效地扩增目标域每类1个实际标记样本,一定可以提高迁移学习的效果。本文研究重点是对one-shot情况进行样本扩增,以探索目标域每类1个真实标记样本情况下所能获取的最高分类精度。样本扩增是训练CNN场景分类模型时出现的概念,通过对已有的标记图像进行旋转、变形及平移等形式的变换来增加训练样本数量。传统方法无法用于处理像素分类的光谱特征数据,所以,本文提出了基于同质区的扩增方法,新方法的样本扩增效果与获取同质区的图像分割方法密切相关。
在图像处理领域,图像分割是一个重要的经典课题,已提出了大量的图像分割算法[11-14]。本文同质区生成过程牵涉到在两种不同特点的区域上进行图像分割,一个是原始的遥感影像本身;二是地物边缘附近不规则区域。第一类区域适合使用普通图像分割算法;第二类区域则适合使用可以形成小斑块的超像素分割法。本文在第一类区域使用Meanshift算法[11],因为其稳定性和鲁棒性较好,原理简单,需要设置的参数较少。扩增样本需要同质区斑块具有高纯度。通常认为Meanshift算法生成的斑块紧凑度不好、斑块所包含语义信息较少、包含阴影区容易产生欠分割。但紧凑度和语义信息不影响样本的扩增,阴影区与光照区分开可以避免妨碍样本扩增的过分割现象出现。对比研究[15]表明:SEEDS算法[12]可以保持影像中主要边缘,运行效率较高,其斑块不规则的特点并不影响训练样本扩增。因此选择SEEDS算法对第二类区域进行超像素分割。
经过广泛地分析和比较,发现CCSA具有原理简单,网络结构清晰,容易训练且效果良好的特点。本研究提出基于同质区的样本扩增方案对CCSA进行改进,以达到在目标域每类仅有1个实际标记点时提高分类精度的目的。
1 同质区获取及训练样本扩增
1.1 基于均值漂移和SEEDS超像素分割的同质区生成
根据Mean Shift和SEEDS各自的优缺点,本文将这两种分割方法结合,实现对目标图像不同尺度的分割,并对分割结果进行提纯操作,从而最终获取高质量的同质区。下面对分割操作的具体步骤进行详细阐述。
(1)高光谱遥感影像波段数众多,不宜直接应用分割算法。首先采用Du提出的基于波段相似性度量的非监督波段选择方法[16]对目标图像进行特征选择,分别选取目标图像的三个信息量最丰富但各自最不相似的波段,作为新的颜色特征向量并进行归一化处理。
(2)利用均值漂移算法对图像进行初始分割:均值漂移技术能够估计相似像素的局部密度梯度,这一估计环节被反复执行,相似像素会收敛于同一极大值,将收敛于同一极大值且满足邻近条件的像素点合并为同一超像素,完成整个分割过程。
(3)对初始分割结果进行提纯:均值漂移算法得到的初始分割斑块的面积较大,常常出现欠分割现象,与此同时,同质区会含有杂质像素点。位于地物边域缘区的同质区斑块会跨越多个类别。本文借助mean shift的思想设计了一种斑块提纯方案,该方案可以筛选出初始分割块中比较纯净的区域,同时剔除不够准确的部分,获取高纯度的同质区。下面的同质区提纯算法给出了具体的实现步骤。其中迭代次数T取值范围[3,7],q取值范围[0.5,0.8],本文实验中T取5;q取0.6。
同质区提纯算法
步骤2
步骤4重新计算高纯度点集的特征均值xˉc
步骤5重复步骤2~步骤4迭代计算T次
输出:P1
(4)对剩余的影像部分进行小尺度超像素分割:上述的均值漂移分割和提纯方案可以有效获取高光谱图像中纯度较高的同质区斑块,但同时会产生不属于高纯度同质区的细碎斑块,这些剩余部分多处在地物的边缘附近或者多类地物混合区。这类区域复杂多变,本文采用SEEDS超像素分割算法对提纯后的剩余部分进行分割处理。超像素斑块面积较小,极少会混入噪声点,因此,每一超像素都可视作为提纯后的斑块。本步骤结束后,每一斑块都是高纯度同质区。本文的同质区获取总体流程图如图1所示。

图1 本文分割方法的总体流程图Fig.1 Flow chart of segmentation method in this paper
1.2 分割结果评价指标
本文选用两种广泛使用的评价指标对分割结果进行质量评价,分别是可获得分割准确率(Achievable Segmentation Accuracy,ASA)[17]和欠分割错误率(Under segmentation Error,UE)[18]。其中,ASA表示超像素分割斑块能够达到的最大分割准确率,是一种从最终分割结果反面评价超像素的方法,也可以称其为纯度。而UE则是从正面直接评价超像素分割好坏的方法,它可以根据分割斑块“溢出”真实区域边界的比例来衡量超像素块的边缘贴合度。两种评价指标从不同角度出发,可以更全面地对最终的分割结果进行质量评价和精度评定。两种指标的具体计算方法分别如公式(1)和(2)所示:

其中,G表示真实的地物分布,S为分割算法得到的超像素块,|⋅|则表示这些超像素块中包含的所有像素点个数。有些超像素块中没有真实标记点,有些超像素块中只有部分像素点有真实标记,上述两个指标只针对有标记样本进行统计和结果评价。
1.3 基于同质区的训练样本扩增原理
提纯后的初始分割板块和超像素斑块均为纯度很高的同质区,可以用于扩增训练样本。利用同质区扩增训练样本的最简单方案是:选择同质区内一点,获取其类别信息,然后将同区内所有像点赋以同样的类别。
图2 展示了初始分割斑块提纯的情况。图2(a)是一个分割所得的斑块,其中的“+”表示此同质区斑块中主体类别像素,占据同质区的绝大部分;“x”及“o”则表示不同于主体类别的错分入斑块的噪声点。图2(b)是提纯后的斑块,其中的噪声点多数被剔除,但仍有少量残留。

图2 分割斑块提纯Fig.2 Segmentation patches purification
利用随机手段选定的有真实标记的样本点必然处于某一高纯度同质区内,如图3(a)中红色圆圈包围的点。此点属于斑块内的主体类别,按照简单扩增方案,同质区内所有点都会被赋予主体类别(如图3(b)所示),都会被作为具有伪标签的扩增样本点。由于斑块内绝大部分点被标记的类别与其真实类别一致,所以,这样的扩增样本点用于监督训练有益无害。图3(c)中随机选中了高纯度同质区内的噪声点,按照简单扩增原则,此时的扩增结果应该如图3(d)所示,绝大部分像点均被赋以与实际情况不同的错误标签。这样的伪标签样本用于训练模型无疑会破坏分类模型的质量,这样的扩增还不如没有扩增。

图3 简单准则扩增效果Fig.3 Simple guidelines augmentation results
尽管高纯度同质区斑块内噪声点极少,但还是存在选中噪声点的可能。为了尽量减少错误扩增发生的可能性,利用源域和目标域有实际标记的样本训练一个分类模型,并预测目标域所有像素的类别。将同质区斑块内拥有最多像素的预测类别称为斑块预测类别,如图4所示。假如随机选择的真实样本点的类别与其所在斑块的预测类别一致,则进行简单方案扩增;否则,不进行样本扩增。图5给出的是选中样本点类别与斑块预测类别一致的情况,最后给出了扩增的结果。

图4 斑块预测类别Fig.4 Predict classes of patches

图5 具有斑块预测类别制约的训练样本扩增Fig.5 Augmentation of training samples with constraints of predict class of patch
在以上每一幅示意图中的高纯度同质区内,都绘制了所有像点的实际类别,但除了选中标记点外,这些类别信息不可以使用,只能将其当作未标记点。绘出实际类别的目的是为了理解算法原理的方便。
2 基于同质区和孪生卷积神经网络的半监督迁移学习
2.1 孪生卷积神经网络模型构建
具有双重分支且权重共享的网络结构称为孪生神经网络(Siamese Neutral Network,SNN)[19],当孪生神经网络的分支为卷积神经网络时,便称之为孪生卷积神经网络(Siamese Convolutional Neutral Network,SCNN)。与传统的卷积神经网络相比,孪生卷积神经网络最大的特点是将原来的单一串联网络改成了具有两个结构相同、权值共享的并行子分枝的新网络,如图6所示。

图6 孪生卷积神经网络示意图Fig.6 SCNN model
X1和X2是网络模型的输入数据,亦被称为配对数据(Paired Data)。GW(X1)和GW(X2)分别表示X1和X2的映射函数表示两个输入数据经过孪生网络输出之后的相似性度量,例如欧式距离。该网络一般使用对比损失函数作为其训练过程中的损失函数[20],使原本相近的同类样本在新的目标特征空间中保持其原本的特性;而使得原本差异较大的样本可以分离更远。这一特点适合于特征降维,但改进后也适合于迁移学习。
建立在孪生卷积神经网络基础上的模型需要的训练样本数量较少,因为输入网络的数据是同类或异类的样本对,数量不多的标记样本也可以组合出数量庞大的训练用样本对。
2.2 网络模型构建
为达成迁移学习的目的,使用图7所示的孪生卷积神经网络模型架构。

图7 本文使用的孪生卷积神经网络模型架构Fig.7 SCNN model used in this paper
嵌入函数g通过卷积神经网络(CNN)建模,该网络主要由初始卷积层和全连接层组成。其中,孪生网的两个分支,一个用于训练源域,另一个则用于目标域。由于gs=gt=g,CNN的参数将在两个分支中共享。此外,源域分支使用额外的全连接层来建模h,构建分类损失函数。模型中主要有两类损失函数:分类损失函数和对比损失函数,对比损失函数又分为同类样本间的对齐损失函数和不同类样本间的分离损失函数。最终的总体损失函数分为以下三部分。
(1)分类损失函数:

(2)同类样本间的对齐损失函数:

(3)不同类样本间的分离损失函数:

最终,总体损失函数可表示为:

其中,E[]⋅表示统计期望,ℓ可以是任何适当的损失函数(例如多分类问题中使用的交叉熵函数),当Xs和Xt的分布不同时,仅使用源域数据训练得到的深度模型fs会降低目标域的性能。d为两个域的嵌入空间中的距离度量(如欧式距离),一旦对齐,模型便具有模糊样本域属性的特点。k则为Xs和Xt在嵌入空间分布的相似度度量,当相似时,会导致分类精度降低,故k起到一个惩罚的作用。γ为权衡系数,用来控制分类损失函数和对比损失函数各自所占的权重。
针对本研究的具体情况,具体化后的网络结构如图8所示。主要分为特征提取、分类识别和相似度计算三个部分。在特征提取部分,孪生卷积神经网络左右两个分支的结构完全一致,由一系列卷积层、池化层及全连接层组成。

图8 本文使用的孪生卷积神经网络结构示意图Fig.8 Specific SCNN model used in this paper
通过上述的网络结构,输入的源域图像和目标域图像被映射到相应的特征空间。使用欧式距离(Euclidean Distance)作为两个领域的图像输出特征相似度指标,并通过对齐损失函数拉近两个领域中同类样本间距离,通过分离损失函数扩大不同类样本间距离。
为了保证训练后源域分支能够实现准确分类,在源域分支之后又添加了额外的网络层来建立分类模型。
这种基于孪生卷积神经网的迁移思想具有两个优点:首先是原理直观易懂,通过源域和目标域样本的配对训练使得两个域的同类样本在特征空间内彼此接近,而异类样本间距离则尽可能加大,从而使得特征空间内以源域信息分类目标域数据变得简单易行;其次是这种迁移思想的普遍实用性。许多现有的迁移学习方法应用于遥感影像时往往没有明显的效果,而基于孪生网的方法则对几乎所有实验影像的分类效果都有一定程度的提升。因此,本文以这种网络结构作为基础,研究目标域训练样本扩增及训练样本配对措施变化对迁移学习分类效果的提升力度。
2.3 配对样本的生成
训练孪生网络需要足够数量的训练样本对,包括同类样本对和异类样本对。为了方便,将源域及目标域样本标记集合分别记为假设两个域共有C类地物。
首先讲述经典样本对构建方法。同类样本对的构建相对简单。从源域和目标域样本集的每个类别中随机抽取Nperclass1个样本构建总共Nsame个同类样本对,其中。经典构建过程的伪代码如下:

其中函数randomly_draw_Nperclass_samples(ind)表示从集合ind中随机抽取Nperclass个样本,下同。
简而言之,就是从源域和目标域每类样本中分别抽取Nperclass1个样本,配成Nperclass1个样本对,随后将C个类别的样本对集取并得到最终的同类样本对集SamPair。
异类样本对的构建过程与上述步骤有所不同。先从源域样本集的某个类别中随机抽取Nperclass2个样本,再从目标域不包含此类的样本子集内随机抽取Nperclass2个样本,配成Nperclass2个样本对。最后将C次配对所得的样本对集并到一起,得到总共Ndiff个异类样本对,其中具体配对过程的伪代码如下:

上述经典的孪生网训练方案中,Nsame=Ndiff,也即同类与异类样本对的比例为1∶1。CCSA方法中,目标域每类只有一个样本。构建同类样本时,源域每一有标记样本均与目标域的那个同类样本配对,就是说CCSA方法的同类样本对数Nsame就等于源域有标记样本总数。这样才能保证生成足够数量的训练样本对。与此同时,CCSA方法将源域每一样本与目标域所有异类样本配对,并从中随机抽取3对,所以Ndiff=3Nsame。
经典方案涉及到的每个域均提供了较多数量的标记点,需要通过随机抽样才能限制配对数量的爆炸;而CCSA方法的目标域每类仅有一点,只有通过遍历配对才能凑够训练网络所需的样本对数。由于基于同质区的扩增措施增加了目标域有标记样本的数量,本研究更接近经典方案的情况。但是CCSA方法生成异类样本对的做法给了人们一点启发:让每一源域样本与多个异类目标域样本配对有益于扩大不同类样本间的特征差异,提高总体分类精度。本文构建异类样本对时,任一随机选中的源域样本都与目标域的每一异类进行一次随机配对,配对过程的伪代码为:

3 实验结果与分析
3.1 实验数据与环境
为了合理评价本文方法的有效性以及对不同数据和区域的适应性,本文采用了两组具有不同相似程度(不同数据偏移程度)的高光谱测试数据集进行相关实验。分别为同一场景图像中的两块不相交的子区域:Source和Target,以及两幅跨场景图像:PC和PU。
第一组数据集是来自ROSIS-3传感器在帕维亚城市上空采集的高光谱遥感影像[17],图9为该数据的完整影像。选取两块不相交的子区域作为参与迁移实验,分别命名为Source图像和Target图像。

图9 第一组数据集的全图假彩色影像图Fig.9 False color image of first data set
它们各自的大小分别为172×123像素和350×350像素,光谱范围为0.43 μm到0.86 μm,空 间 分辨率为1.3 m。该数据包含115个光谱波段,实际分类时为避免噪声波段产生影响,去除了12个噪声波段,保留其中103个波段进行分类。图10为Source及Target假彩色影像图及相应的实际地面参考数据。这两幅图像共享四类地物,分别为:道路、植被、阴影和建筑。
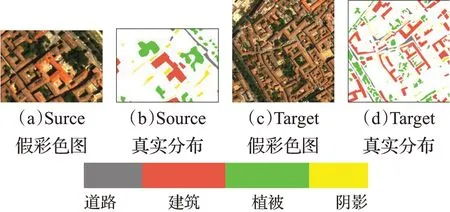
图10 Source和Target的假彩色图像与真实地物分布Fig.10 False-color image and ground truth of Source and Target
表1 统计了这两幅图像的各类样本数量,Target图像中包含的标记样本数量远多于Source。实验中将Source作为源域图像,Target作为目标域图像。

表1 第一组数据集的各类样本数量统计Table 1 Number of samples in each class of first dataset
第二组数据集是同一传感器拍摄的两块不同地区的高光谱影像图,分别来自意大利帕维亚城市中心(Pavia Center)和帕维亚大学(Pavia University),均由成像光谱仪ROSIS-3拍摄所得,简称PC和PU图像。该数据集的光谱范围、空间分辨率、光谱波段与第一组数据一样。两幅影像尺寸分别为1 096×492和610×340个像素,有七种公共地物类别。
为了表述方便将两组数据的地物类别重新统一定义,将标签1至7对应的实际地物分别定义为树、沥青路、自封砖、沥青建筑、草地、裸土和阴影,具体情况如图11所示。表2为第二组数据集的各类样本统计。

表2 第二组数据集的训练与测试样本Table 2 Training and test samples of second dataset

图11 PC和PU的假彩色图像与真实地物分布Fig.11 False-color image and ground truth of PC and PU
本文实验在Windows10系统下基于Python3和MATLAB实现。在Python3环境中,利用Keras库(以TensorFlow为后端)进行孪生卷积神经网络的训练和分类,其余部分均在MATLAB环境下完成。下文分类实验结果均为10次独立实验的平均值。
3.2 目标图像的分割结果展示和质量评价
本节实验对本文的分割提纯过程以及基于多尺度分割方法获取得的三幅影像同质区进行效果展示。超像素分割时,斑块数目设置准则是使斑块平均面积约为40个像素。图12、13和14分别为Target、PC和PU三幅图像的分割提纯过程以及最终分割结果。从图中可以看出,三幅图像经提纯后均获取了较多大面积同质区块,剔除了许多地物边缘处的过分割区域,在剩余残留影像区域进行SEEDS超像素分割,可以精准细致地划分这部分复杂多变的区域。

图12 Target图像分割结果Fig.12 Segmentation result of Target

图13 PC图像分割结果Fig.13 Segmentation result of PC

图14 PU图像分割结果Fig.14 Segmentation result of PU
表3 为三幅影像分割结果的同质区斑块数和两种分割评价指标数值。可以看出:三幅影像的欠分割错误率均低于0.05%;可达分割准确率均在99.7%以上,证明了本文提出的分割-提纯方案的有效性。
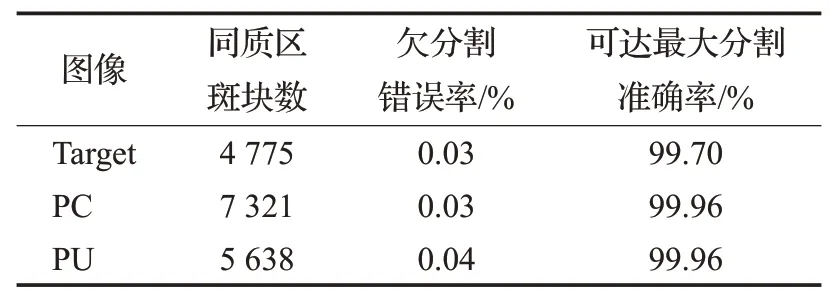
表3 三幅实验影像分割结果评价Table 3 Evaluation of segmentation results of three experimental images
3.3 目标图像分类的实验结果与分析
分类实验中,源域图像每类地物随机选取300个标记样本,目标域图像每类随机选取1个标记样本作为原始训练数据;目标域图像所有剩余标记样本用作测试。训练样本用于训练本文方法和几种参照方法,训练模型用于预测测试样本类别,通过分析对比各项指标来评定各种方法性能的优劣。
除了本文提出的同质区和孪生卷积神经网络的半监督迁移学习(SCNN-HR),实验中的对比方法包括基于线性支持向量机的SRC、SVM1、SVM2和CCSA。其中,SRC仅利用源域图像中的训练样本,未使用目标域的标记样本,基于样本光谱特征训练支持向量机模型,在未进行迁移学习的情况下,直接对目标图像进行分类。SVM1的训练样本中加入了目标域的标记单样本;SVM2则是在源域训练样本中加入了目标域单样本及基于同质区的扩增样本;CCSA为最新的半监督迁移学习方法,利用源域训练样本和目标域标记单样本,基于样本的空谱联合特征训练孪生神经网,并对目标图像进行分类。CCSA与本文方法最为接近,但其在目标域只用了每类一个标记样本,源域、目标域样本配对策略也不一样。
本文方法与CCSA使用的均是空谱联合特征,即将一个像素的所有波段的邻域子图像全部作为其特征(见图15)。邻域窗口尺寸取5×5,这一尺寸几乎可用于所有影像,能够达到利用空间信息的目的,又不会造成分类结果的边缘模糊。邻域的每一波段展开为一列向量,5×5邻域展开成25×1的向量。用于迁移学习实验的数据为102个波段,所以,每一像素的特征数据均为25×102的矩阵,孪生网每一分支的输入层尺寸均为25×102×1。

图15 空谱联合特征的提取Fig.15 Extraction of spatial-spectral feature
表4 和图16分别给出了本文方法SCNN-HR与对比方法对第一组数据的实验结果和分类效果图。
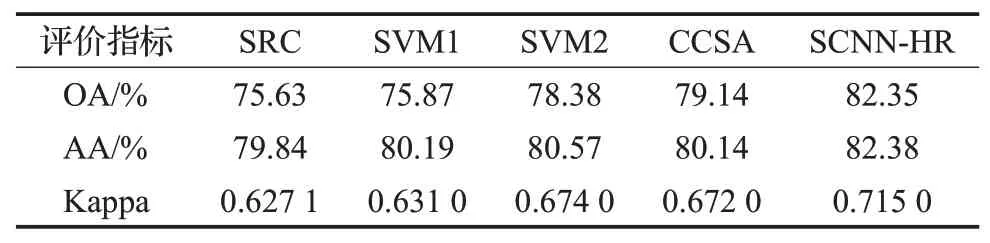
表4 第一组数据集分类结果评价(Source→Target)Table 4 Evaluation of classification results of first dataset(Source→Target)

图16 第一组数据集的分类效果图对比(Source→Target)Fig.16 Classification results of first dataset(Source→Target)
SRC方法直接使用源域的标记样本进行训练,不采取任何迁移学习的手段,分类精度最低。而如果只有目标域每类一个标记样本,即SVM1方法,也无法获得分类精度提升,因为训练样本中源域的数据信息占主导位置,少量的目标域地物信息无法影响模型的训练,且源域和目标域之间存在一定的差异,故无法取得理想的分类结果。SVM2由于加入了较多扩增而得的目标域标记样本信息,虽然未进行两个领域之间的迁移,其分类精度也能提升3%左右。半监督迁移学习方法CCSA的分类结果与SVM2大致相当。本文方法利用同质区对目标域单样本进行扩增,并利用孪生卷积神经网络拉近源域数据和目标域数据间的距离,在三种分类评价指标中均取得了最好结果,其总体精度和平均精度分别为82.35%和82.38%,比CCSA方法高出了约2%~3%,Kappa系数则高出0.04。
表5 和图17为第二组数据集PC→PU时各方法得到的分类结果和相应的分类效果图。在该组实验中,本文方法的分类精度最高,总体分类精度达到了70.10%;相比于直接利用源域数据进行分类的SRC高出约11个百分点;对比未使用迁移方法的SVM2来说,有了4个百分点的精度提升。与半监督分类方法CCSA相比,总体分类精度和平均精度高出了5~6个百分点,具有明显的优势。分类效果图显示:相比于其他方法,本文方法对于裸土和草地这两种地物的区分性更好,包含的噪声点也更少。

表5 第二组数据集分类结果评价(PC→PU)Table 5 Evaluation of classification results of second dataset(PC→PU)
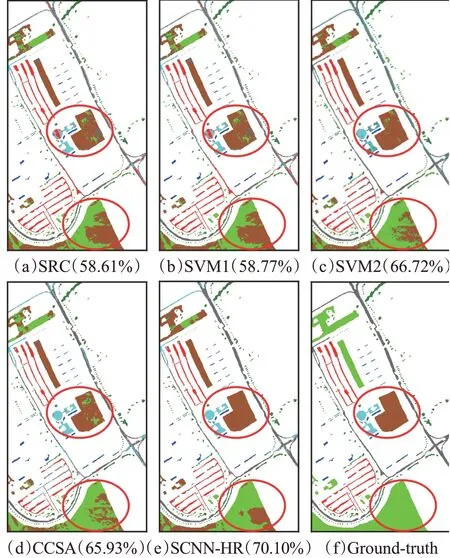
图17 第二组数据集的分类效果图对比(PC→PU)Fig.17 Classification results of second dataset(PC→PU)
表6 和图18为不同方法在PU→PC时得到的分类结果和分类效果图。本文方法的总体精度达到了87.58%;比基准方法SRC高出了约13个百分点;比未使用迁移方法的SVM2高出了4个百分点;同时,相比半监督分类方法CCSA来说,也有2个百分点的精度提升。分类效果图显示:本文方法分出的沥青浇筑完整性最高,基本接近真实地物分布。

图18 第二组数据集的分类效果图对比(PU→PC)Fig.18 Classification results of second dataset(PU→PC)

表6 第二组数据集分类结果评价(PU→PC)Table 6 Evaluation of classification results of second dataset(PU→PC)
4 结束语
孪生神经网络的结构适合目标域标记点极少情况下的迁移学习,但迁移分类效果不甚理想。本文研究了一种基于同质区和孪生神经网络结构的半监督迁移分类方法,借助分割所得的目标域同质区扩增标记样本,结合空谱联合特征实现网络模型训练。实验结果表明:改进措施明显提升了高光谱数据的分类效果,基本满足地物识别和信息提取的需求。两组数据的实验结果同时证明本文探索的方法针对源域和目标域间偏移程度不同的高光谱图像均具有适应性。
猜你喜欢
自我保健(2021年2期)2021-11-30
妇女之友(2021年9期)2021-09-26
昆明医科大学学报(2020年11期)2020-12-28
计算机技术与发展(2020年11期)2020-12-04
百姓生活(2019年2期)2019-03-20
理科考试研究·高中(2017年7期)2017-11-04
中国塑料(2016年11期)2016-04-16
汽车零部件(2015年1期)2015-12-05
电子与信息学报(2015年12期)2015-08-17
汽车维修与保养(2015年7期)2015-04-17
