
课程资源的融合知识图谱多任务特征推荐算法
2021-11-12 15:03徐行健孟繁军
计算机工程与应用 2021年21期
吴 昊,徐行健,孟繁军
内蒙古师范大学 计算机科学技术学院,呼和浩特011500
2020年4月28号中国互联网信息中心(CNNIC)发布的第45次《中国互联网络发展状况统计报告》显示,截止2020年3月,我国在线教育的用户规模已经达到4.23亿,较2018年底增长约110.2%,占整体网民人数的46.8%,尤其是在2020年初的新冠肺炎疫情期间,在各种在线教育应用平台的日活跃用户更是达到千万以上[1]。
在线教育爆发式增长改变了传统的教学模式,使人们随时随地学习成为现实。但是,伴随着大数据时代的到来,在线教育平台的课程数量庞大,学习方向繁多,课程类型应有尽有,对学习者也产生了很多弊端。一是学习者很难短时间内找到适合自己的课程;二是学习者个人所感兴趣的学习路线复杂,而学校的培养方案里的课程又趋于单一化和重复化,学习者满意度低,无法达到预期的教学效果[2];三是大多数在线教育平台不像传统教育那样对学习者提供有效的学习指导、课程规划,学习者自身缺少对总体知识结构的深入理解互联网学习资源数量冗杂,导致学习者陷入大量的课程选择中,从而造成了信息过载,甚至出现了课程的通过率较低的状况[3],最后,传统教育模式难以及时有效地发现学习者的学习目标。针对上述问题,一些在线教育平台通过课程搜索和热门课程推荐等方法也未能较好的解决。然而,由于知识图谱作为辅助信息的推荐算法得到充分的关注和研究,使得基于知识图谱的课程推荐算法进一步地提升推荐效果成为可能[4]。
个性化推荐技术现在已经广泛运用到各大领域,如电子商务、在线视频、新闻头条、自媒体短视频等领域,有效地解决了各大领域的信息过载问题。对于教育领域方面存在的问题,国内外诸多在线教育团队也纷纷在探讨和研究,近年来取得的研究成果往往都是通过学生选择课程的历史和热门课程大数据分析进行推荐,虽然推荐结果也较为实用,但缺乏对学习者整个学习过程的支持和结合学校的培养方案进行推荐,并且现有算法对课程推荐方面的数据稀疏和冷启动问题也没有很好的方法。
本文基于edX公开的课程数据集构建现有课程结构关系的知识图谱[5],利用多任务特征学习方法模型,提出一个多任务课程推荐算法(Multi-Layer Knowledge graph Recommendation,MLKR),并且与基于内容的协同过滤推荐算法对比,以表征算法性能。
1 课程推荐算法概述
1.1 课程推荐算法
课程个性化推荐技术是在线教育与教育大数据领域的研究热点之一,国内外众多研究团队纷纷提出个性化网络教育的概念、研究个性化课程推荐算法,目的是降低在线学习的辍学率,激发和调动学习者主动学习的积极性,充分发挥不同学习者的学习个性。
国内学者在心理学层面研究得出[6]:每个学习个体客观存在的个体差异使得个性化课程规划对于学习有积极的意义。虽然我国在个性化课程推荐算法起步较晚,但在推荐算法的优化和改进方面有许多成果。王忠华等通过学习资源的协同预测方法,基本缓解协同推荐算法中的扩展性计算和松散型计算等问题[7]。李星雨等利用师生之间的交流,改进基于物品的协同过滤算法,对学生的特征进行分析,提出适合学生的个性化推荐算法,进而缓解推荐结果与学习者贴合度低的问题[8]。檀晓红等对在线学习者在学习的过程中的动态数据获取并分析,提取了学习者个性化学习的需求,再通过专业教师对课程进行整体规划,最后使用遗传分层推荐算法为学习者推荐课程,显著提高课程推荐精准度[9]。
国外学者在2008年开始对课程推荐算法进行研究,Jose等通过分析选课系统和电商平台的差异性和相似性,通过生物启发算法改进知识和发现关联规则[10],而近年来的研究大多利用在探讨学习者的行为特点来表示学习者的特征,从而产生推荐结果。Pang等把每个学习者行为特征提取并转换成相同维度的向量,将其分散放在包含相似用户之中,这些学习者具有更多共同的课程,提出了多层存储推荐算法(Multi-Layer Bucketing Recommendation,MLBR)和MapReduce技术扩展,使传统的协同推荐算法性能得到提升[11]。郭清菊等根据学习者的行为和偏好进行学习者浏览日志的挖掘,采用AprioriAll算法提出的混合推荐策略,实现了对学习者个性化推荐[12]。
目前,现有应用研究主要集中在采用协同推荐或数据挖掘方法,提高课程推荐准确率,但上述方法常涉及到推荐算法冷启动的问题,无法建立性能较好的推荐模型以及在没有初始数据时,无法精准推荐[13]。
1.2 传统课程推荐算法存在问题
(1)推荐课程准确度问题。使用精确程度高的推荐算法可以为学习者提供更加适合自己的课程,增强满意度。推荐结果的准确性是一个推荐算法的重要指标。假如一个推荐算法产生的推荐结果不会产生良好的推荐结果,推荐结果将不会有存在意义[14]。
(2)数据稀疏问题。利用传统协同过滤方法时的相似度计算主要依靠学习者对课程的评分矩阵,实际过程中对课程的评分很少,有些情况仅仅为2%[15]。使得课程评分矩阵过于稀疏,课程与学习者找到相似的邻居成为困难,造成了课程推荐的质量变低。
(3)冷启动问题。现在课程平台会随着新的学习者和课程需求不断更新内容,但是在更新之前没有任何新加入的学习者或者新的课程内容的记录,造成了推荐算法无法进行及时有效的推荐。
2 知识图谱辅助的多任务特征学习方法
2.1 课程知识图谱的构成
对于现有数据集中学习者和课程之间交互的信息稀疏甚至缺少的问题而导致的冷启动问题,可以通过在推荐算法中引入其他的信息,即辅助信息(Side Information)来缓解。在电影、商品等常见的推荐中引入的辅助信息有:社交网络(Social networks)、用户或者商品属性特征(User/Item attributes)、多媒体信息(Multimedia)、上下文信息(Contexts)等[16]。在本文采用的辅助信息是知识图谱,用三元组(c1,r,c2)来表示,课程的知识图谱为G:
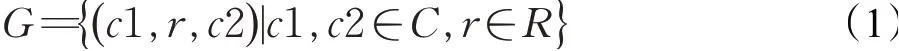
其中,c1和c2∈C,C为edX数据集的所有课程,r∈R,R中构造了5个关系:same.instructor(拥有同一个教师)、same.subject(属于同一种学科)、hour.low(课程交互时间≤30 h)、hour.mid(30 h<课程交互时间≤100 h)、hour.high(课程交互时间>100 h),如图1所示。当一个学习者与四门课程有过交互:Java程序设计、数据结构、计算机网络、操作系统,在知识图谱中就可以将三门课程关联到其他的事件中,并连接到其他众多non-item实体上,再从这些non-item实体又连接到课程实体上,如最右边的无线网络技术、网络信息安全、J2EE架构与应用、编译原理。
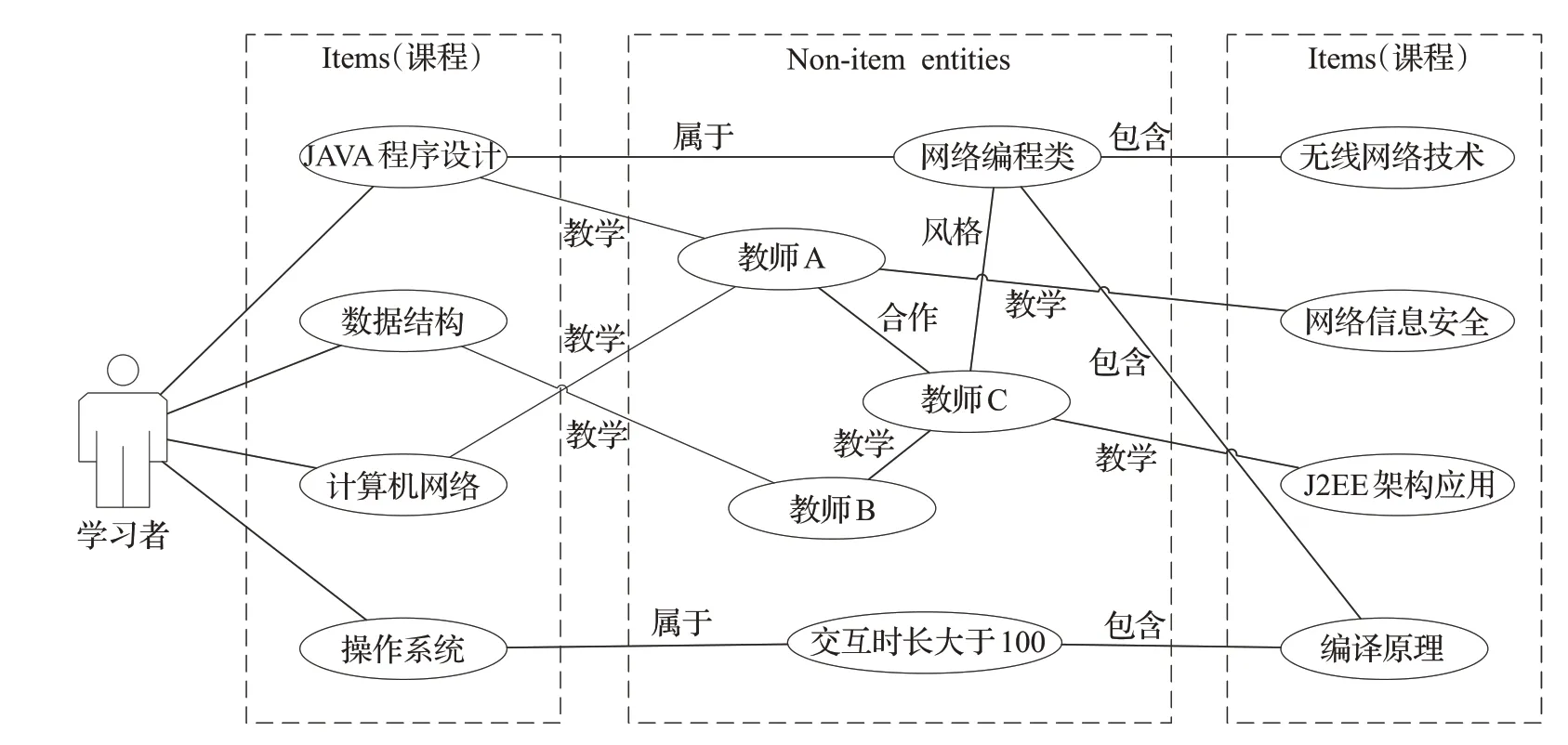
图1 课程知识图谱三元组Fig.1 Three tuples of curriculum knowledge map
传统协同过滤算法就是将中间non-item实体部分替换为其他学习者,其他学习者通过历史学习记录等交互过程得到连接,构造的知识图谱实质是建立一个从学习者已经交互过的课程到未交互过的课程的连接,这些连接不是由其他学习者的交互历史记录得来,而是通过non-item实体进行连接。构造知识图谱的方法提供额外的在课程之间连接的信息来源以及算法中item相似度更准确的计算方式,从而提高推荐课程的精确度[15]。
2.2 MLKR算法
为了缓解传统课程推荐算法的局限性,提出了基于端对端通用深度推荐框架的MLKR算法,其采用知识图谱嵌入任务作为辅助推荐任务,其中两个任务不是相互独立的,具有较高相关性。主要是由于在推荐算法中的单个课程(item)可能与知识图谱中单个或者多个实体(entity)相互关联,所以单个item和其所对应的实体在推荐算法以及知识图谱中可能存在相似结构,在初始阶段非任务特征的潜在空间中也存在相似特征。为了对item和entity之间的共享特征进行建模,在MLKR算法中加入交叉压缩单元(Cross&Compress)[17],交叉压缩单元确定了item和entity特征之间的高阶交互,并自动控制两个任务的交叉知识转移。使用交叉压缩单元后,item和entity的表征可以相互补充,避免两个任务产生过拟合和噪声,并提高泛化能力[18]。整体框架通过交替优化两个任务的不同频率进行训练,以提高MLKR算法在真实环境中的灵活性和适应性。
MLKR算法框架如图2所示,主要包括三个模块:推荐模块、知识图谱嵌入模块与交叉压缩单元。

图2 MLKR推荐算法框架Fig.2 MLKR algorithm framework
推荐模块的输入为学习者向量U与课程向量Cr,输出为学习者对于课程的选课率p。
模块分为low-level(低阶)和high-level(高阶)两部分,其中low-level部分使用多层感知器MLP(Multi-Lay Perceptron)处理学习者的特征UL,课程部分使用交叉压缩单元来进行处理,返回一门课程的特征CrL,最后将UL与CrL拼接,通过推荐算法中的函数fRS,输出选课预测值。对于给定学习者的初始特征向量U,使用L阶的MLP提取其特征:

知识图谱嵌入模块就是将实体和关系嵌入到一个向量空间中,同时保留结构,对于知识图谱嵌入模型,现有的研究提出了一个深度语义匹配架构[18],与推荐模块类似,给定知识图谱G以及三元组(h,r,t),其中分别通过交叉压缩单元与非线性层处理三元组头部h和关系r的初始特征向量[19]。之后将潜在特征关联在一起,最后用K阶MLP预测尾部t:
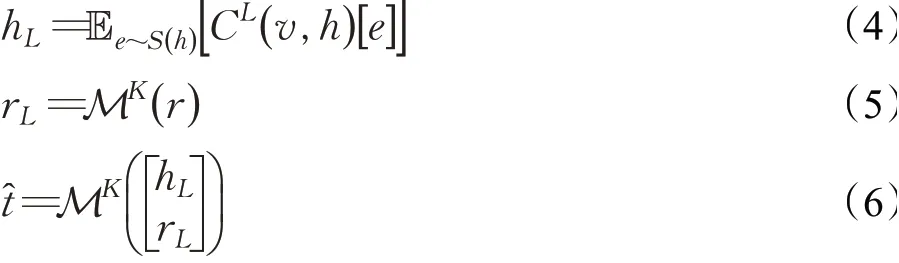
其中,S(h)为h的关联项集合,t̂为根据尾部t得出的预测向量。
最后加入交叉单元是为了模拟item和entity之间的特征交互,其只存在于MLKR算法的初始阶层中,由于课程推荐算法中的课程和知识图谱嵌入模块的中的实体有着对应关系,并且有着对同一item的描述,其中的embedding(嵌入)是相似度极高的,即可以被连接,于是中间每一层都使用交叉压缩单元作为连接的结合。如图3所示,L层的输入为课程item的embeddingCrL和实体的embeddingeL,下一层的输出为embedding,交叉压缩单元模块分为两部分:Cross(交叉)和Compress(压缩),其中Cross将CrLCrL,eL进行一次交叉,CrL为d×1的向量,eL为1×d的向量,矩阵计算后获得d×d的矩阵CL。Compress将交叉后的矩阵CL重新压缩回Embeddingspace(嵌入空间),并通过参数WL压缩输出CrL+1、eL+1[20]。

图3 交叉压缩单元Fig.3 Cross and Compress unit
MLKR算法主要的训练过程如下:构建打分文件和知识图谱,通过MLKR模型对数据进行学习,得出预测模型,能够有效地预测学习者U对课程Cr感兴趣的概率,由于在打分中的item和知识图谱中的实体实质上指向相同的内容,其具有高度的重合性和相关性,采用多任务学习的框架将推荐算法和知识图谱分别视作两个分离任务,同时两者可以通过item和entity进行相关,从而对两个模块进行交替学习。
在推荐算法部分中,输入的是学习者和课程的特征表示,输出为学习者对课程的感兴趣的概率。
在知识图谱的模块中,输入为三元组的头结点和关系,输出为预测的尾结点。利用项目和实体的相似性,设计交叉压缩单元连接两个模块。
通过交叉压缩单元,两个模块间可以共享信息,弥补自身的信息不足。在交替学习的过程中,分别固定推荐算法模块的参数和知识图谱的参数,同时训练另一个模块的参数,通过来回交替训练的方式,使损失不断减小。
MLKR算法具体实现步骤如图4所示。利用模型进行学习的过程包括多次迭代,为了将推荐算法的性能尽可能达到最优,在每次迭代过程中,交替对课程推荐模块和知识图谱模块进行训练。对于每次的迭代中两个模块的训练而言,均是通过以下的几个步骤:首先从输入的数据中提取小部分,然后对课程item和课程head提取特征值,利用梯度下降(Gradient Descent)算法更新最终预测函数的值,即模型收敛,获得MLKR算法训练模型。

图4 MLKR算法训练步骤Fig.4 MLKR algorithm training steps
3 实验结果与分析
3.1 实验环境与数据集处理
实验环境为Inteli5-10210U CPU@1.60 GHz,8 GB内存,Window10操作系统。利用Pycharm中Anaconda3与TensorFlow框架。
实验采用Kaggle上Online Courses from Harvard and MIT作为数据集。其中edX是MITx和HarvardX创建的大规模开放在线课堂平台,类似于国内的网易公开课、腾讯课堂。该数据集的数据字段包含23个,数据信息290个,文件大小64 KB左右。实验中,随机选取60%作为训练集,20%作为验证集,20%作为测试集。根据推荐算法需求,抽取实验所使用到数据集中的7个属性:课程名、教师、学科、总交互时长、播放视频时间占比、发帖占比、高于零分占比。抽取后数据集部分片段如表1所示。
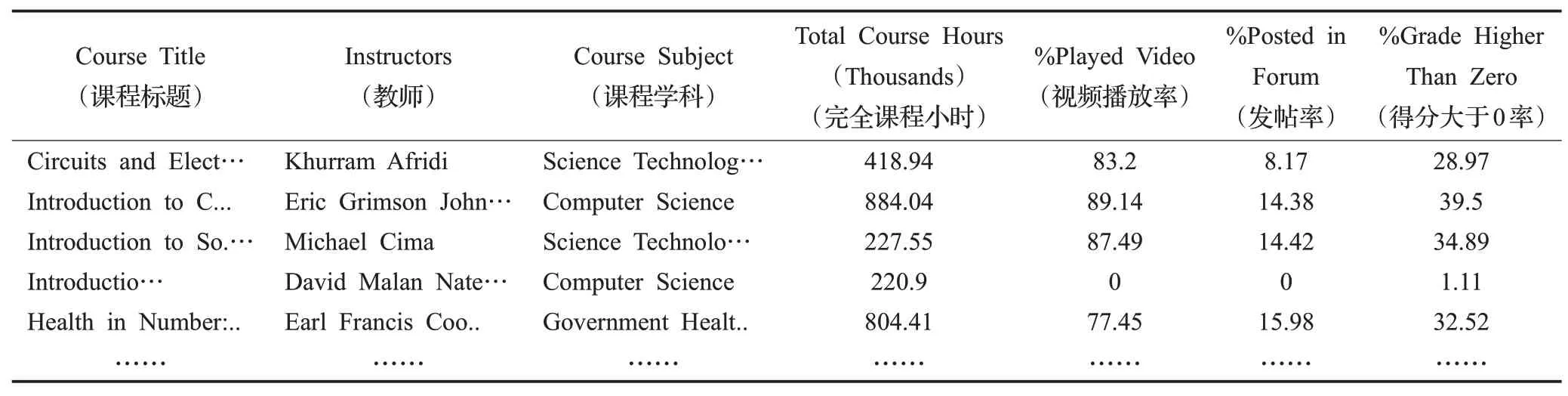
表1 课程推荐所需edX数据集片段Table 1 Recommended edX dataset fragments for course
最后利用neo4j构建知识图谱,并做链路预测的任务,通过头部实体、关系来预测尾实体,使用有监督训练来得到更好的item向量表示。
3.2 评价指标
使用准确率(ACC)、精确率(Presicion)、召回率(Recall)、F1值(F1-Score)作为评价指标,用以衡量各个算法的性能,实现MKLR算法数值表征,具体计算见式(7)~(10)。在固定训练集情况下,模型ACC、Presicion、Recall和F1计算越高,表明推荐模型更加高效[21]。

其中,TP(True Positive)表示真阳性,即课程的样本被正确推荐给学习者的数量;TN(True Negative)表示真阴性,即不属于正确推荐课程的样本被正确推荐给学习者以外的其他课程的数量;FP(False Positive)表示假阳性,即不属于正确推荐课程的样本被错误推荐给学习者的数量;FN(False Negative)表示假阴性,即属于正确推荐课程的样本被错误推荐给学习者以外的其他课程的数量[22]。
3.3 实验过程与结果分析
首先,系统运行数据处理模块preprocess.py,将知识图谱文件kg.txt和构造的学习者打分文件user_mooc.dat转化成数值文件,构造打分文件的部分数据如表2所示,UserID为构造的学习者ID,ArtistID为课程ID。然后,根据对应权重得到和构造学习者模型打分权重Wg,计算如下:

表2 根据edX数据集构造的打分数据片段Table 2 Scoring data fragment constructed from edX dataset
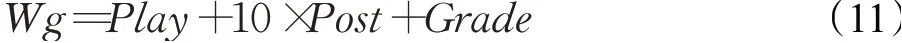
其中,Play为播放视频时间占比取整,Post为发帖占比取整、Grade则为高于零分占比的取整。
得到构造打分文件后生成ratings_final.npy以及kg_final.txt,接着将上述文件作为模型的输入,main.py文件作为模型训练和超参数调整文件,对课程数据集超参数进行调整[23]。由于打分预测的实现存在困难,为了保证实验结果的可信程度,同时也为了降低模型训练耗时、增加模型参数调整精度,本实验中超参数学习率Ir_rs选取0.001、Ir_kge选取0.002。由图5可以看出,当超参数Batchsize为2 048、AUC、ACC、Presicion、Recall和F1评价指标表现较好。当Batchsize大于2 048时,Presicion、Recall和F1降低,是由于模型训练出现过拟合。当大于4 096时,尽管由于评价指标Presicion、Recall和F1数值提高,但是会造成训练时间过长。结合数据集中word出现次数和图6可以看出,embedding维度选取32时,模型评价指标表现较好。最后设置Batchsize为2 048,embedding维度为32,图7结果也验证了Ir_rs选取0.001、Ir_kge选取0.002时,模型性能表现较好。
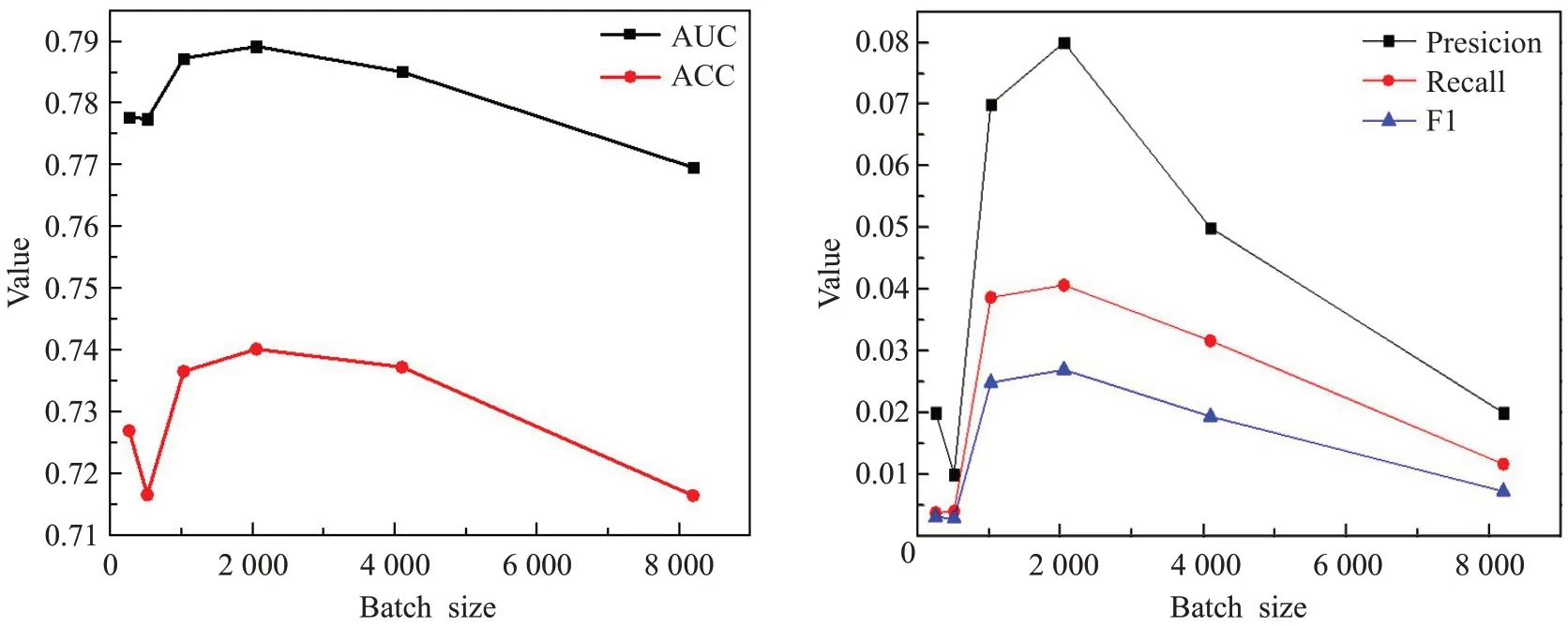
图5 调整超参数BatchsizeFig.5 Adjust hyperparameter Batchsize

图6 调整embedding维度Fig.6 Adjusting embedding dimension

图7 当固定Batchsize=2 048,Dim=32时调整IrFig.7 When fixed batchsize=2 048,dim=32,adjust Ir
在固定模型超参数条件下对比不同算法之间的性能表现,表3为MLKR推荐算法与协同过滤算法以及排序学习算法代价对比,包括训练和预测时间对比,结果表明,在训练速度方面,ItemCF速度最快,训练时间最短,由于MLKR算法采用深度学习的多任务处理,时间复杂度O(n)较高,与协同过滤算法相比训练时间较长。但比排序学习推荐算法(LR)速度快。对比不同算法性能,实验结果如表4所示,MLKR算法对于UserCF算法和LR排序学习模型相比有着更好的准确性。

表3 MLKR推荐算法与协同过滤算法代价比较Table 3 Cost comparison of MLKR algorithm and collaborative filtering algorithm
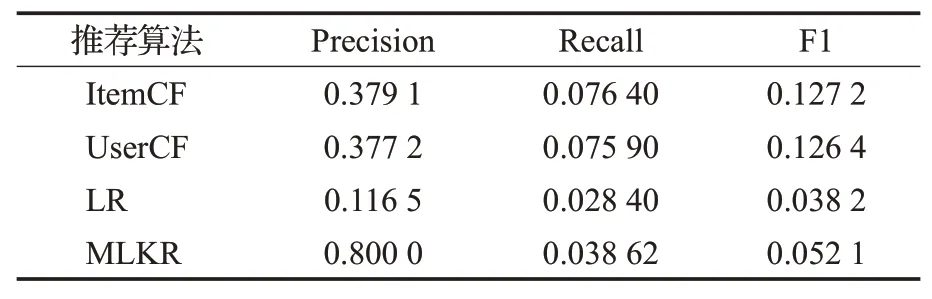
表4 MLKR推荐算法与协同过滤算法比较Table 4 Comparison of MLKR algorithm and collaborative filtering algorithm
由于构建的辅助信息是根据高校的学生培养方向所定制学习的课程学习路线,有些必修的课程无法满足所有学习者的兴趣,所以与ItemCF算法相比Recall值较低,并且相比与传统协同过滤推荐算法,MLKR算法需要通过相应本体构建知识图谱进行推荐,需要相应的构建过程代价,而协同过滤算法更适用于数据量多、偏向于多数用户喜爱的推荐环境[23]。最终实验结果表明MLKR算法更符合实际课程推荐的环境,且性能优于传统推荐算法。
4 结束语
面向课程资源的融合知识图谱与多任务特征推荐算法MLKR通过推荐模块和知识图谱嵌入模块提取课程资源的相关特征,使用交叉压缩单元学习实体之间的高阶交互,并在两个任务之间传递,解决了推荐算法中数据稀疏和冷启动的问题。与传统基于用户的协同过滤算法和多层存储推荐算法相比,提出的MLKR算法可以更加精准、高效地实现课程资源推荐。
猜你喜欢
少先队活动(2020年12期)2021-01-14
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
初中生世界·八年级(2019年6期)2019-08-13
中成药(2017年3期)2017-05-17
海外华文教育(2016年4期)2017-01-20
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
领导科学论坛(2016年9期)2016-06-05
成人教育(2015年7期)2015-12-21
