
基于混合特征提取的判决预测模型
2021-12-01 05:26刘璐瑶
智能计算机与应用 2021年8期
刘璐瑶,李 实
(东北林业大学 信息与计算机工程学院,哈尔滨 150006)
0 引言
在传统的司法领域中,案件判决依赖于法官、律师等法律相关人士的专业解答和辩论流程。对于普通人而言,复杂的法律条文构成了专业壁垒,对于案件结果的预判也与专业人士存在较大差距[1]。对于专业人士而言,大部分案件都属于常见案件,预测过程较为简单。如果能用技术手段学习到这些案件的共性,让量刑过程实现自动化或者半自动化,辅助法官的决策过程,一方面能将司法工作者从琐碎的事务中解放出来,另一方面也有利于消除人的主观因素的影响[2],实现同案同判。
当今时代,随着法律的不断完善,人民的法律意识也不断提高,与此同时历史案件在不断累积,新案件也在不断的增加[3],司法领域的各种公开案件量已足够满足深度学习需求,使得用深度学习技术进行司法领域相关问题的研究成为可能。
国外的研究者已经开展了大量的关于人工智能在司法领域各个方向的研究。Vlek 等通过贝叶斯网络对案件的现有证据进行建模、分析与推理,在刑事案件的审判中,能够更好的通过模型从文本中提取出当前案件的场景描述,并能够直接的向法官或者陪审团提供对于现有证据的分析与结果展示[4];Ashley 等人通过建立案件数据库,从已判决案件的文本描述中提取信息,并应用这些信息使用决策树算法完成自动预测新案件的结果[5]。
英美司法智能研究与中国在许多方面有所不同。首先,英美量刑模式为普通法体系,又称为判例法,而中国的量刑模式是基于成文法;其次,英语与汉字的差异导致文本处理方法的不同;另外,汉语法律词汇与非法律词汇的差异很大,一些流行的文本分类方法难以直接应用。基于此,在关于机器学习的研究中,高菲等在研究和借鉴英美法系的量刑模式后,提出了改进中国量刑模式的新思路[6]。通过对盗窃案件中年龄、主共犯、认罪态度等的量刑情节进行统计和数值化后,使用支持向量机技术预测刑期,使刑期结果精确到月份。本文是基于深度学习技术实现中文司法智能领域的罪名预测和刑期预测,拟利用抽取式文本摘要,对案情描述文本进行预处理,同时提出基于BiGRU-Attention-CapsNet 的文本分类模型进行罪名预测和28 类刑期预测。
本研究的主要贡献如下:
(1)提出了一种基于注意力机制的混合特征提取网络的文本分类模型,解决全局和局部特征的不完全特征提取问题。
(2)由于硬件和模型的限制,每条案情描述文本长度有限,通过对案情描述文本进行压缩,在文本长度和文本信息量中找到平衡,在指定长度中保留尽可能多的信息。
(3)在刑期分类中,实现了较小的分类粒度,有更高的实际应用和参考价值。
1 相关工作
近年来判决预测的研究越来越受到人们的关注。目前在智能司法领域的研究方法主要分为3类:数学统计方法、机器学习方法和深度学习方法。
早期的判决自动预测主张使用统计学方法,试图分析大量历史案例找出共性规律并使用统计学模型模拟判决流程。典型工作如文献[7]中提出的量化分析法和如文献[8]提出的关联分析法。但此类方法仅在特定领域的数据上有效,较难推广到一般性案件中。
随着机器学习的发展,一些研究者开始从案件文书中提取特征,利用机器学习模型来解决智能司法领域的问题。代表性工作如文献[9]中基于文书浅层文本特征的K 近邻算法分类预测模型;文献[10]中将3 层神经网络与退火算法相结合,通过定义和量化28 种监禁情况的特征,预测有期徒刑、死刑和无期徒刑;文献[11]中利用多元伯努利模型进行分类的不均匀分布,然后采用朴素贝叶斯算法进行分类。该方法大大提高了分类的精度,但提取出的浅文本特征只能针对特定案例,泛化能力不强。虽然机器学习模型极大地自动化了学习,并且总是随着经验而改进,但其需要手动对大量的特性进行标记,这需要大量的时间和专业知识。
由于深度学习模型具有不需要标注大量特征的优点,研究者们开始基于文本分类框架构建预测模型,即以大量历史法律文书作为训练文本,以罪名为类别标签,训练深度学习分类模型[12-15]。Ye 等人从事实描述中生成法院视图来解释判决预测[16]。代表性工作如文献[17]和文献[18]中提出的基于深度神经网络罪名分类模型;文献[19]在2018 年使用“中国法研杯”司法人工智能挑战赛(CAIL-2018)的数据集,提出了一种长文本分类的混合深度神经网络模型HAC(hybrid attention and CNN model),利用残差网络,融合了改进的层次注意力网络和深度金字塔卷积神经网络,使用分类方法将刑期分为18 类对刑期进行预测;文献[20]中,在CAIL-2018small 数据集上,针对单人多罪名多法条的刑事案件对比了3 种平均词向量模型,并在多核CNN模型中加入不同层次的Attention 机制,融合BERT句向量特征,提出了BERT-ACNN 模型。
此类方法在预测效果上取得了一定的进步,但对特征提取不够完整,没有考虑局部特征和全局特征的融合。因此,本文使用胶囊网络提取局部语义特征信息后,再使用加入注意力机制的BiGRU 提取全局语义特征信息,最后将两个网络合并,提取更加完整的信息来提升罪名预测和刑期预测的性能。
2 基于BiGRU-Attention-CapsNet 的预测模型
2.1 数据预处理
数据预处理包括案情描述预处理和标签预处理。在案情描述预处理部分,考虑到法律文本的关键句经常在句子结尾才出现,而部分文本的长度超过了允许读入的最大长度,本文先对数据进行抽取式摘要处理以确保关键句被读入。抽取式摘要采用TextRank 算法抽取重要度最高的10 个句子作为摘要,之后主要是加入自定义词典对摘要进行分词去停、构建事实词典、将分词去停后的文本序列化、将序列处理为同一长度等预处理。在标签预处理部分:对于罪名标签,将202 种罪名放到一个文本文件中,再将其转化为数字编号;而对于刑期标签,考虑到以月为单位进行分类效果不佳,所以以年为单位将0~25 年的刑期分为26 类,无期徒刑和死刑各为一类,刑期一共分为28 类。
2.2 BiGRU-Attention-CapsNet 模型研究
2.2.1 BiGRU-Attention-CapsNet 模型
本文搭建的基于BiGRU-Attention-CapsNet 的文本分类模型结构如图1 所示。文本分类模型主要包含输入层、Embedding 嵌入层、BiGRU-Attention-CapsNet 层、全连接层、输出层几个部分。

图1 BiGRU-Attention-CapsNet 模型Fig.1 BiGRU-Attention-CapsNet model
其中,BiGRU-Attention-CapsNet 层合并了BiGRU-Attention 层提取的全局特征向量和CapsNet模块提取的局部特征向量。
2.2.2 BiGRU 层
门控循环单元GRU 是对长短期记忆网络的一种改进,保留长期序列信息的同时通过门控机制优化了参数的规模[21]。在GRU 网络中信息只能单向传递,但词语可能与上下文的词语都有依赖关系,使用BiGRU 融合上下文的语义信息,实现信息的双向传递,模型效果会更好。本文BiGRU 层的目的是对输入文本词向量进行文本深层次特征的提取。式(1)、式(2)表示对输入词向量xi正向、反向编码。式(3)表示对、进行向量拼接操作。
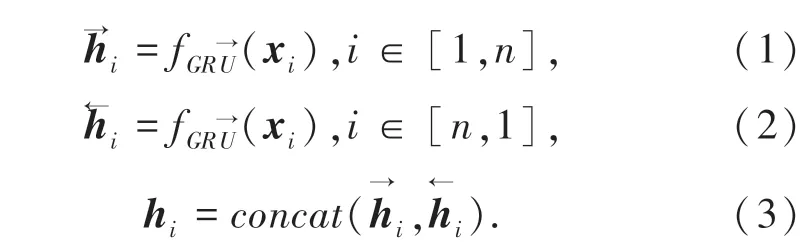
2.2.3 词级别注意力层
为捕获更准确的语义表达,本文在BiGRU 层后引入注意力机制,对案情描述语句进行编码。不同的词对句子意思的表达所起的作用也有所不同,因此采用词级别Attention 机制来提取对句子含义重要的词语。
词级别Attention 机制可通过以下3 个步骤实现:
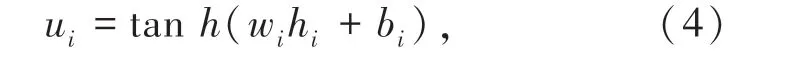
式中,wi为模型权重,bi为偏置。
(2)计算ui和上下文向量uc的相似性,并归一化得到度量词语重要性指标,如式(5)所示。

其中,上下文向量uc是对输入的一种语义表示,是在训练过程中随机初始化和共同学习的,ε是一个很小的正数,是为了避免出现除零异常而添加的。
(3)计算词语的加权向量得到句子向量,如式(6)所示。

2.2.4 胶囊网络模块
网络使用了CapsNet 算法的最后一层DigitCaps层,将池化层用动态路由代替。该胶囊网络模块包括以下4 层:
第一层:卷积层
要在最严格水资源管理制度试点工作带动下,全面推进最严格水资源管理各项工作,确保各项制度有措施、能落地。一是按照“节水优先、空间均衡、系统治理、两手发力”的治水思路,以水定需,量水而行,因水制宜,严格水资源论证、取水许可管理和水资源有偿使用制度。二是把节约用水贯穿于经济社会发展和群众生活全过程,优化用水结构,切实转变用水方式,全面实行计划用水管理,加快推进节水技术改造。三是全面落实 《全国重要江河湖泊水功能区划》,从严核定水域纳污容量,切实加强水污染防控,加强饮用水水源保护,推进水生态文明建设。四是按照最严格水资源管理制度考核工作要求,积极有序开展辖区内考核工作,切实落实水资源管理责任制。
通过不同的卷积核在句子的不同位置提取Ngram 特征。其输入是文本词向量,卷积操作就是卷积核矩阵Ma和对应输入层中一小块矩阵的点积相乘。卷积核通过权重共享的方式,按照步幅上下左右的在输入层滑动,提取特征,以此将输入层做特征映射作为输出层。具体形式如下:
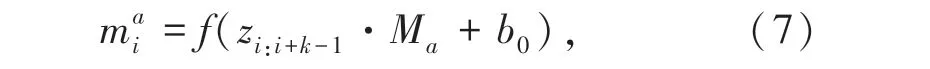
其中,b0是偏置项,f是非线性激活函数ReLU。
第二层:主胶囊层(第一个胶囊层)
胶囊将卷积操作的标量输出替换为矢量输出,从而保留实例化参数。每一个胶囊pi可由式(8)得到:

其中:g()表示非线性压缩函数;b1为胶囊的偏置项;W是不同滑动窗口的共享滤波器;Mi是Ma中第i行向量。
第三层:卷积胶囊层
在这一层中,每个胶囊仅与下面层中的一个局部区域相连。这些胶囊与转换矩阵相乘来计算子胶囊(低层胶囊)与父胶囊(高层胶囊)之间的关系,然后根据协议路由计算出上层的父胶囊。
第四层:全连接胶囊层
上一层的胶囊被展平成一个胶囊列表,并送入全连接胶囊层。在全连接胶囊层中,胶囊乘以变换矩阵,然后按协议路由生成最终的胶囊及其对每个类别的概率。
3 实验
3.1 数据集
本文使用的数据集为“中国法研杯”司法人工智能挑战赛(CAIL-2018)的数据集[22],数据集是来自中国裁判文书网公开的刑事法律文书。其中每份数据由法律文书中的案情描述和事实部分组成,同时也包括每个案件所涉及的法条、被告人被判的罪名和刑期长短内容。数据集共包括268 万条刑法法律文书,共涉及202 条罪名、183 条法条,刑期长短包括0~25 年,无期徒刑和死刑。数据格式如图2所示。

图2 数据示例Fig.2 Sample data
其中,fact 表示案情描述;meta 表示标签信息;punish_of_money 表示罚金(单位:元);accusation 表示罪名;relevant_articles 为相关法条;term_of_imprisonment 为刑期。刑期分为:是否死刑(death_penalty)、是否无期(life_imprisonment)、有期徒刑刑期(imprisonment)等。
3.2 实验参数设置
参数设置上,使用word2vec 模型训练词向量,维度为100。由于本文训练样本的字符长度为1 000时,样本覆盖全部语料集的90%以上,故设定读取的序列长度为1 000。对于长度不符的样例进行padding 或cut 处理。训练时部分参数见表1。
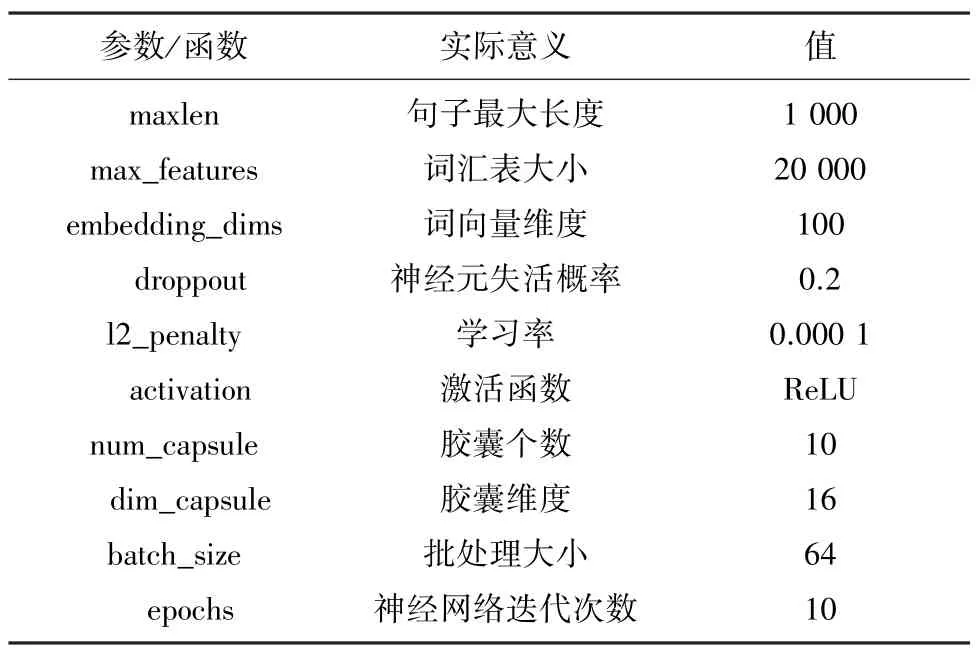
表1 部分参数设置Tab.1 Some parameters settings
3.3 结果与分析
表2 列出了CAIL2018 数据集在TextCNN,BiGRUAttention,CapsNet 和BiGRU-Attention-CapsNet4 个模型上的罪名和刑期的预测结果。评估指标为测试集的准确率和损失值。

表2 比较实验Tab.2 Model comparison experiments
TextCNN 是2014 年由Yoon Kim 提出的经典文本分类模型;BiGRU-Attention 融合上下文的语义信息,实现信息双向传递,注意力机制能对文本重要部分赋予更高的权重,起到优化特征向量的目的;CapsNet 与TextCNN 相比,具有空间同变性,将数个连续的神经元封装为一个胶囊输出,保留了文本中词的本地顺序和词的语义表示。由表2 可知,在罪名预测和28 类刑期预测上,两模型的分类准确率均优于TextCNN,而融合了全局特征和局部特征的BiGRUAttention-CapsNet 是一种双向门循环单元注意机制混合胶囊神经网络模型,其全局特征由BiGRUAttention 提取,局部特征由CapsNet 提取。由此表明,由于合并特征提取,提高了模型学习的语义信息,该模型的分类精度高于两个独立模型的分类精度。
本研究使用了与文献[1]相同的数据集和评价指标。由表3 中数据表明,结合全局和局部特征的模型BiGRU-Attention-CapsNet 具有最佳的精度。

表3 不同模型实验结果Tab.3 Prediction results for different models
对于刑期预测,文献[19]与本文数据集相同,把预测刑期与真实刑期的差异作为评估指标。假设第i起案件的真实刑期是ti,而预测的结果是¯ti。其定义差异di如下:

然后,将得分函数f(v)定义如下:

最终得分如下:

文献[19]将刑期分为18 类。为了便于比较,本研究也将刑期分为18 类。表3 显示,BiGRU-Attention-CapsNet 的得分为82.76 分,比HAC 的得分高5.62 分。
4 结束语
本文在预处理部分对长文本采用TextRank 算法抽取关键句作为模型输入,提出BiGRU-Attention-CapsNet 模型,将全局特征和局部特征进行融合,在罪名预测和28 类刑期预测的准确率上都有所提升。在未来的工作中,可以考虑引入外部法律知识库或融合更多知识模型。实际司法过程中,刑期还受到许多因素的影响,如被告和受害者的年龄,是否存在自首行为等。因此,在刑期预测中还可以添加命名实体识别和实体关系提取等技术,以提高预测的准确率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
重庆行政(2019年5期)2019-11-18
妇女之友(2018年8期)2018-09-17
环球时报(2018-05-19)2018-05-19
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
杂文选刊(2014年11期)2014-10-22
小学阅读指南·高年级版(2009年3期)2009-03-27
家庭医药(2009年1期)2009-02-05
