
基于混合语料的无监督双语词典抽取
2021-12-01 05:26韩梦凡曹海龙
智能计算机与应用 2021年8期
韩梦凡,曹海龙
(哈尔滨工业大学 计算学部 机器智能与翻译实验室,哈尔滨 150001)
0 引言
双语词典抽取能够抽取出不同语言中含义相同的单词。作为机器翻译的基础,双语词典也被应用到跨语言自然语言处理任务中。在跨语言任务中,双语词典作为共享的跨语言特征将在一个语言上训练得到的模型应用到其它语言上。跨语言命名实体识别、跨语言信息检索以及跨语言文档分类等都利用该思想进行跨语言任务学习。
双语词典的抽取需要大规模高质量的平行语料,例如Mikolov 和Xing 等人的工作都采用了规模较大的词典作为监督方式学习跨语言词向量,进而抽取双语词典。由于高质量大规模的平行语料难以获取,不需要任何监督信息的无监督方法逐步成为研究热点[1-2];Barone 等人首次提出采用生成对抗训练进行无监督学习[3];zhang 等人在此基础上提升生成对抗训练方法的性能[4];Artetxe 等人利用无监督初始化和迭代自学习进行无监督跨语言词向量表示学习来抽取词典[5];Lample 等人将生成对抗训练与迭代学习过程进行结合,利用对抗训练获取初始化词典之后进行迭代增强[6]。尽管无监督方法在部分语言上(如英语-西班牙语)的性能与有监督方法不相上下,但是无监督方法隐含了不同语言的词向量是同构的假设。Søgaard 等人的研究表明词向量之间的同构性受到多种因素的影响,不同语言的同构程度是不同的[7]。基于以上原因,本文提出了一种同构性增强的方法,来提升无监督方法在双语词典抽取上的性能,该方法首先利用基线模型抽取双语词典,根据双语词典替换且合并单语语料,对混合语料进行训练,提升不同语言词向量的同构性,进而提升双语词典性能。在维基百科语料英文-中文实验上,本文提出的方法有明显的提升。
1 基于混合语料的无监督双语词典构建模型
本文在Artetxe 等人提出的无监督双语词典抽取模型(vecmap)的基础上,提出了一个基于混合语料的无监督双语词典构建模型,模型的示意图如图1 所示。
基于混合语料的无监督双语词典构建模型包含3 部分,第一部分利用基线模型将单语词向量映射至同一个空间并抽取词典;第二部分利用抽取的词典将源语言及目标语言单语语料中的单词替换并合并为混合语料,训练混合语料得到新的单语词向量XN与YN;第三部分利用基线模型映射词向量XN与YN至同一空间并抽取词典。
训练混合语料过程中被词典替换后的单词能够影响上下文单词,使对应上下文单词更加接近,从而可以增强不同语言之间单语词向量的同构性。
2 基于混合语料的无监督双语词典模型细节
本文提出的模型结构中,基线模型vemcap 采用了无监督初始化词典以及迭代自学习,不断更新词典和映射矩阵,最终利用映射矩阵W把源语言词向量映射到同一个空间。本文采用Lample 等人提出的跨域相似性局部缩放方法(cross-domain similarity local scaling,CSLS)[6]替代最近邻方法抽取词典。
在抽取词典时采用CSLS 方法寻找源语言到目标语言的翻译,得到对应的翻译对,根据翻译对抽取词典。本文提出了两种抽取词典方式:
(1)基于频率进行词典抽取。在抽取词典的过程中,根据源语言单词出现的频率作为选取准则,源语言单词出现的频率越高,该源语言单词对应的翻译对越优先被抽取;源语言单词出现的频率越低,该源语言单词对应的翻译对越靠后被抽取;
(2)基于CSLS值进行词典抽取。该方式在抽取词典的过程中,根据已有翻译对对应的CSLS值进行词典抽取,翻译对对应的CSLS值越大,对应翻译对越容易被抽取;翻译对对应的CSLS值越小,对应翻译对越难以被抽取。
利用抽取得到词典替换合并语料:首先将词典中的词对联结成为一个特殊的联结对,接下来将单语语料中出现在词典中的单词替换成对应的联结对,具体例子见表1。

表1 替换合并语料例子Tab.1 Example of replacing and merging corpus
在训练混合语料过程中,本文采用了word2vec方法进行混词向量的训练。混合语料训练词向量中,根据上下文预测中心词的过程如图2 所示。

图2 混合语料预测中心词Fig.2 Example of predicting center word from Mixed Corpus
根据图2 可以发现,数学∗∗∗math 的翻译联结对能够影响“学习”和“learning”,根据单词的语义是由上下文决定的分布假设,经过词向量训练后的“学习”和“learning”会更加接近彼此。采用混合语料训练词向量的方式能够提升单语词向量的同构性。
在得到混合词向量后,将混合词向量分离为源语言单语词向量与目标语言单语词向量,具体见表2。
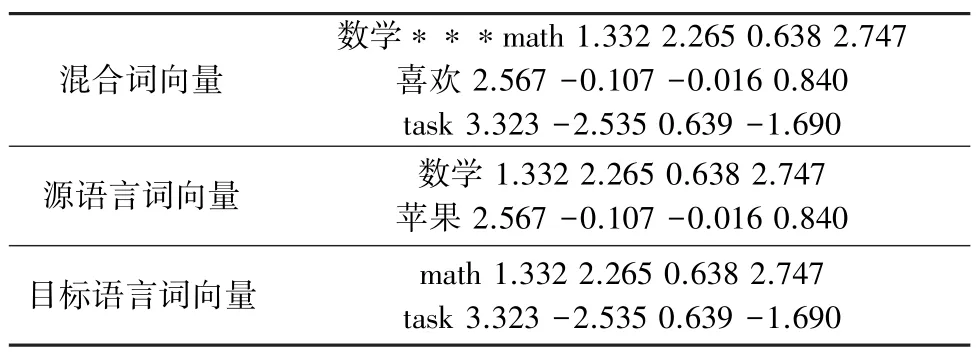
表2 分离混合词向量Tab.2 Example of separating mixed word embedding
3 实 验
本文的实验在维基百科中文和英文单语语料进行,评价指标包括抽取双语词典的准确率以及词向量同构性的程度。词向量同构性程度的衡量采用了Søgaard 等人提出的奇异向量相似度(Eigenvector Similarity,EVS)[7]。EVS值越低,同构性越好;EVS值越高,同构性越差。
本文提出的方法在双语词典抽取任务上的结果见表3,其中CSLS、frequency 分别表示基于CSLS值抽取词典以及基于频率抽取词典,参数dict 表示抽取词典的规模。

表3 基于混合语料的词典抽取结果Tab.3 Dictionary induction accuracy based on mixed corpus
可以发现不论是基于频率方法还是基于CSLS值方法,在词典规模合适的情况下,本方法面向词典抽取任务上的结果有明显的提升。在基于CSLS值替换的方法中最高能够达到51.14%,在基于频率替换的方法中最高能够达到51.97%,远远超过基线模型的46.44%。验证了本文提出的方法在双语词典抽取任务上的有效性。
根据表3 可以发现,随着抽取词典规模的增大,双语词典的性能并没有随着提升。一个可能的原因是由于随着抽取词典规模的增大,词典对应的质量随之降低。词典中错误翻译对上下文也产生了影响,最终导致双语词典抽取任务性能下降。
本文基于混合语料训练得到单语词向量在同构性评价指标上的结果见表4,其中10 k、20 k 表示抽取最常用10 k 或者20 k 单词衡量对应词向量之间的同构性。

表4 词向量同构性结果Tab.4 Isomorphism results of word embedding
通过表4 可以发现,本文提出方法词向量同构性相对于原始方法有明显的提升,验证了本文提出方法能够提升不同语言词向量之间的同构性。对比在10k 与20k 的结果可以发现,频率越高的单词对应的同构性越好。
4 结束语
本文提出了一种基于混合语料训练的无监督双语词典构建方法。该方法根据单语词向量训练方法,采用分布假设的特性,提出了将单语语料中的单词替换成抽取词典翻译联结对,并将原始单语语料合并的混合语料的方法。该方法增强了单语词向量之间的同构性,同时在双语词典抽取任务上有明显的提升。无监督双语词典抽取的同构性假设制约了无监督算法的性能,除了增强不同语言词向量之间的同构性,未来还可以探索其它不需要同构性假设的方法。
猜你喜欢
语数外学习·高中版上旬(2021年7期)2021-11-11
江苏广播电视报·新教育(2021年34期)2021-01-03
学苑创造·A版(2020年10期)2020-11-06
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
科学与财富(2016年30期)2017-03-31
考试周刊(2017年1期)2017-01-20
考试周刊(2016年83期)2016-10-31
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
西南学林(2014年0期)2014-11-12
