
基于深度学习的智能广告牌的设计与实现
2021-12-15 02:38樊雪倩陈春雨
应用科技 2021年6期
樊雪倩,陈春雨
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
在大型商场中,经常可以看到带有液晶显示器的广告牌,但是这些广告牌大多只能按照预设内容进行循环播放,无法针对特定群体进行有针对性的定向广告投放。因此,要在广告费用不变的情况下,让广告的宣传效果达到最好,是一个很有研究意义的问题。人工神经网络是对动物神经网络的简单模仿,依靠系统的复杂程度,通过调节内部节点之间的相互连接关系,从而达到处理信息的目的,被广泛应用于图像识别、计算机视觉等领域,取得了许多突出的成果[1]。近年来,深度学习技术的蓬勃发展使计算机视觉技术取得了极大的突破,运用深度学习技术,计算机可以从图像以及视频中识别各种物体,并给出相应的位置、置信度等信息。本文为改善传统液晶广告牌针对不同人群推送相同广告的问题,设计并实现了一种与深度学习目标检测算法相结合的智能广告牌。根据正在观看广告牌的行人的性别年龄和服饰信息,返回针对不同特点人群的广告,提升广告推送的效果,以更少的广告费完成更好的宣传效果。
基于深度学习的智能广告牌的核心是目标检测技术[2]。随着深度学习的迅速发展,硬件计算能力不断增强,相应的数据集不断构建,深度神经网络在不同的视觉任务中取得了巨大的成功,深度网络模型也在目标检测领域得到了广泛的应用[3]。经过数年的研究,Girshick 等[4-5]在2013 年提出了将深度学习应用到目标检测上的RCNN 检测算法,成为后续目标检测技术发展的基础,也为从事深度学习研究的科研人员提供了新思路。2016 年,R-CNN 系列的最高代表作Faster R-CNN 实现了端到端的检测,达到了最优的检测精度[6]。同样是在2016 年,YOLO 目标检测算法和SSD 目标检测算法相继被提出,YOLO 和SSD转向回归问题的研究,一步实现分类和目标定位,达到了端到端的实时检测,速度上较RCNN系列有非常大的提升[7-8]。YOLO 算法中使用由维度聚类得到的先验框,对边界框预测[9]。2017 年到2018 年间,YOLO 的升级算法YOLOv2 和YOLOv3相继被提出,YOLOv2 解决了YOLO 存在的主要问题,包括定位不准和召回率不高的问题;而后面提出的YOLOv3 则在小目标的识别方面进行了改善[10-11]。由于移动端的运行内存小,不适合部署参数量大的模型,本文采用改进后的SSD 目标检测算法,将原始VGG16 网络替换为轻量级的mobilenet 网络,大大加快了模型推理时间,确保目标检测与广告推送的实时性。
1 系统设计
1.1 系统总体设计
总体的设计思路为:首先制作基于深度学习的目标检测模型,然后通过Android 平台将模型部署到嵌入式端,最后通过编写服务器端与嵌入式端程序实现针对性广告的返回[12]。目标检测模型基于tensorflow 框架,选取SSD_MobileNet 目标检测模型,通过训练自己制作的数据集制作模型,实现实时检测行人的性别、年龄以及特定服饰的功能。模型部署采用TensorFlow Lite,将模型文件转为tflite 文件,然后在Android 平台上使用;服务器端与嵌入式端的通信采用Socket 通信,完成服务器端与嵌入式端检测结果、广告图片以及商品店铺网址的稳定传送。将训练好的模型部署到RK3399,RK3399 启动摄像头拍摄实时画面,获取一帧实时画面照片后送往目标检测模型进行实时检测;检测到目标后,将检测结果发送到服务器;服务器收到检测结果后将相应的广告图片与广告链接发送到嵌入式端;最终,在显示屏上显示实时检测结果和返回的广告图片,总体设计框图如图1 所示。

图1 总体设计框图
1.2 通信流程设计
客户端与服务器端采用socket 进行通信,通信的过程如图2 所示[13]。客户端将实时检测到的结果发送至服务器端;服务器端收到检测结果对应的数字(共17 个类别,分别对应数字0~16)后,根据检测结果发送对应商品的商家网址到客户端;客户端收到网址后,向服务器端发送确认信息表示已经收到商家网址;服务器端收到客户端发送的确认信息后,将要发送的图片大小发送至客户端;客户端收到图片大小后,向服务器端发送确认信息表示已经收到了将要接收的图片的大小;服务器端收到确认信息后,向客户端发送针对性的广告图片。

图2 通信过程
1.2.1 服务器端
服务器首先会创建套接字,然后绑定端口号,监听客户端的请求。当客户端与服务器端建立连接后,会开启新的线程进行通信;如果没有建立连接,则继续监听客户端的请求。服务器会通过输入流获得检测结果和确认信息;通过输出流写入将要发送的网址和广告图片,判断是否抛出异常,如果没有抛出异常就继续监听,如果抛出异常则结束程序。服务器端的程序流程如图3 所示。

图3 服务器端流程
1.2.2 客户端
客户端的程序流程与服务器端大致相同,如图4 所示。

图4 客户端流程
2 目标检测原理
2.1 SSD 网络
SSD 模型以VGG16 为基础网络,但是将VGG16的全连接层fc6 和fc7 转换成卷积层conv6 和conv7,conv6 层和conv7 层的卷积核大小分别为3*3 和1*1,并添加特征提取层[14]。 SSD 的网络结构利用了多尺度的特征图做检测。模型的输入图片大小是300×300 或512×512,其与前者网络结构没有差别,只是最后新增一个卷积层。
2.2 轻量级卷积神经网络模型Mobilenet
当对图像进行分类、分割以及目标检测时,会涉及到大量的数据运算。而卷积神经网络以它特有的结构,在速度上远远快于传统的图像处理方法。虽然卷积神经网络在时间上有明显的优越性,但是其在精度方面却不如传统算法。如果想提高模型的精度,那么网络中参数的计算量会大大增加,占用的空间将会很大。使用嵌入式系统部署检测模型经济实惠且易于实现,但是常见的嵌入式系统内存有限,为了将检测模型部署至嵌入式系统,需要对模型进行压缩以减少内存的占用,提升模型检测速度。压缩模型的方法有很多,列出几种常用的方法:1)将N×N的卷积核分解成1×N和N×1 的卷积核;2)使用输入维度大而输出维度小的网络结构;3)将高精度的浮点数参数转化为低精度参数;4)对图像进行去冗余操作,包括对图像进行编码等。
深度可分离卷积的原理是对图像进行去冗余操作,控制图像冗余信息大小的参数分别为宽度因子和分辨率因子。但是模型的衡量指标有多个,在确保模型精度和模型运行速度对实际应用不会产生影响的情况下,尽量减少冗余和模型占用空间,是最终想要达到的目的。最终经过多年研究,Google 团队设计出了适合部署到移动端的网络模型MobileNet。MobileNet 是轻量级的卷积神经网络,如果将其作为目标检测中的基础网络,则会大大减小目标检测模型的体积和模型的运行时间。
2.3 改进后的SSD 网络
SSD 目标检测算法使用VGG16 作为基础网络进行特征提取,但是VGG16 卷积神经网络多次使用3×3 卷积核和2×2 最大池化层,因此内部参数数量多,运算量也十分大,导致模型占用的内存会非常大,模型预测时间也比较长,不适合将训练后的模型部署到内存空间小、实时性要求高的嵌入式端或移动端。如果要将模型应用到移动平台,减少模型大小、提高模型运算速度,则需要结合模型参数少、占用空间小的MobileNet 卷积神经网络。因此,用MobileNet[15]卷积神经网络替换VGG16 卷积神经网络,然后再由后续的卷积层生成4 个特征图,总计6 个特征图,进行后续的回归运算,最终检测出目标。经过上述步骤改进后的SSD-MobileNet 目标检测算法,具有权重参数少、运算速度快和占用空间小等优点[15]。
3 系统测试与分析
为了便于部署到嵌入式端,提高模型检测准确率,本文对SSD 目标检测算法进行如下改进:1)将原始特征提取网络修改为MobileNet 卷积神经网络,修改后的网络命名为SSD-MobileNet;2)将原始特征提取网络修改为MobileNet 卷积神经网络,并加入特征金字塔网络(feature pyramid network,FPN),修改后的网络命名为SSDMobileNet-FPN;3)将原始特征提取网络修改为Inception2 卷积神经网络,通过增加网络的宽度来提高网络性能,修改后的网络命名为SSD-Inception2;4)将原始特征提取网络修改为Resnet50 卷积神经网络,通过增加网络的深度来提高网络性能,修改后的网络命名为SSDResnet50。
3.1 各网络性能对比
使用改进后的SSD 网络SSD-MobileNet、SSD-MobileNet-FPN、SSD-Inception2、SSD-Resnet50分别进行测试,测试图片共633 张。表1 所示为改进后的各网络对应每个类别的召回率。

表1 改进后各网络召回率
表2 所示为改进后各网络对应每个类别的平均精度(average precision, AP)。

表2 改进后各网络平均精度
SSD-MobileNet 模型均值平均精度(mean average precision, mAP)为0.8150,速度为21.46 f/s。SSD-MobileNet-FPN 模型mAP 为0.8550,速度为20.57 f/s。SSD-Inception2 模型mAP 为0.8069,速度为18.14 f/s。SSD-Resnet50 模型mAP 为0.8910,速度为16.37 f/s。通过对比修改网络结构后的模型的mAp 值和速度,发现SSD-Resnet50 模型准确率最高,但是同时考虑精度和速度后,SSDMobileNet-FPN 效果最好,在保证精度的同时速度较快,可以保证部署到嵌入式设备后检测的实时性。最终选择SSD-MobileNet-FPN 训练模型,并部署到嵌入式设备来模拟检测和广告推送。
3.2 模型测试结果
本次设计训练的目标检测模型共有17 个分类,包括特定服饰、性别和年龄等,训练总步数为500000 步,batch_size 最初设置为16,但是由于电脑内存不足,训练中断,于是将batch_size 修改为12。学习率起始为0.0001,最初每经过2000 步,学习率下降为原来的0.95 倍,训练了20000 步左右后发现损失函数(loss function)值下降十分缓慢。于是调整训练步数为20000 步,每经过20000步,学习率下降为原来的0.95 倍。
部分测试结果如图5 和图6 所示,展示了男女青年、连衣裙、西装、帽子和风衣的检测结果。通过结果可以看出,模型检测效果较好,检测框与真实框位置基本一致,分类准确,分类置信度较高。

图5 男女青年服装测试结果

图6 帽子及风衣测试结果
3.3 系统检测速度
在RK3399 上进行实际速度测试。图7 为RK3399 实物,在实际部署到RK3399 后,Android程序加载目标检测模型,检测一帧图片的时长为200 ms 左右。所以,在嵌入式开发板RK3399 上运行目标检测,加载检测模型后,在正常运行的情况下,检测帧率可以达到5 f/s[16]。

图7 RK3399 实物
3.4 推送准确率评价
本文智能广告牌设计思路是根据识别到的服饰和不同性别年龄段推荐广告。当识别到服饰,会推送对应服饰的广告内容;当识别到性别年龄时,会推送符合该性别年龄常用的商品。屏幕识别到多目标情况时,会优先推送检测置信度最高物体所对应的广告。由于智能广告牌是根据检测结果推送对应广告,当检测结果准确时,推送的广告内容准确。因此推送准确率可由目标检测模型的AP 值和召回率来代替。
3.5 结果分析
本次设计制作的目标检测模型共包含17 个类别:服饰包括针织帽、墨镜、羽绒服、连衣裙、西服、风衣和牛仔裤;性别年龄包括男婴儿、男儿童、男青年、男中年、男老年、女婴儿、女儿童、女青年、女中年和女老年。具体实现的功能为用RK3399 外接摄像头拍摄实时画面,当检测到目标时,将检测结果发送给服务器端,服务器端根据检测结果推送针对性的广告图片。广告图片共170 张,针对每个类别推送的广告图片共10 张,当检测到该类别时,会随机返回10 张图片中的1 张,广告每2 s 返回1 次,当行人对广告图片中的内容感兴趣时,可通过点击屏幕上方的“打开店铺”按钮查看店铺和商品详情。部分类别的结果展示和广告返回情况如图8 所示。
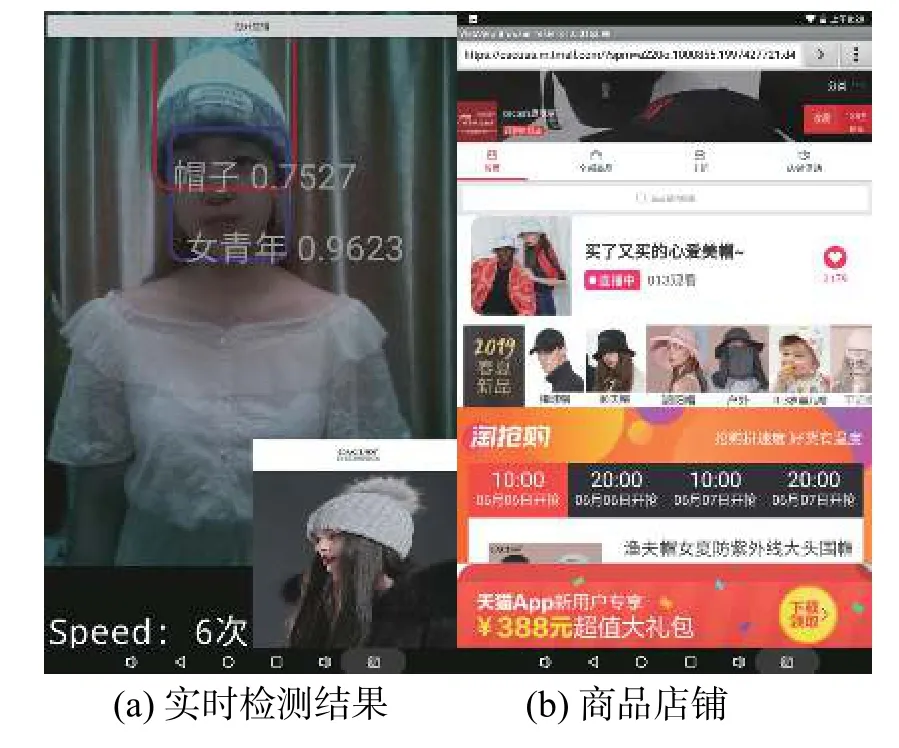
图8 针织帽测试结果
图8 为将目标检测模型部署到RK3399 端后,实际的检测效果图。图8(a)图蓝色框标注的是当前画面置信度较高的类别,红色框标注的类别置信度比蓝色框低,设置一张图片中最多可以检测10 个目标。图8(a)中帽子的置信度为0.7527,女青年的置信度为0.9623,检测帧率为每秒6 次。图8(a)为实时检测和广告返回结果,图8(b)为点击按钮后显示的画面。可以看到,模型对帽子的检测效果基本符合要求,检测框与真实框之间没有大幅度偏移,检测类别也没有出现错误,广告推送内容合适。广告图片每2 s 更新一次,每个类别对应的广告图片为10 张,大小为300 pixel×300 pixel。
图9、图10 为将目标检测模型部署到RK3399端后的实际检测效果。图9(a)为实时检测和广告返回结果,图9(b)为点击按钮后显示的画面。男老年的置信度为0.9971,检测帧率为每秒5 次。可以看到,模型对男老年的检测效果基本符合要求,检测框没有大幅度偏移,检测类别也没有出现错误,广告推送内容合适。

图9 男老年测试结果
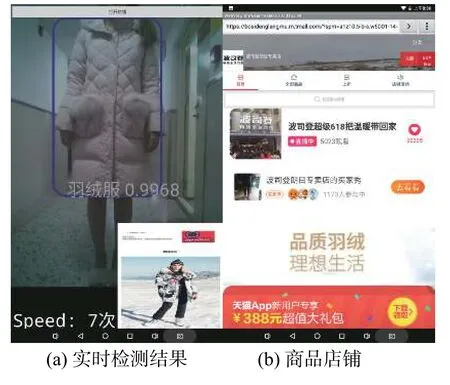
图10 羽绒服测试结果
图10 中羽绒服的置信度为0.996 8,检测帧率为每秒7 次,图10(a)为实时检测和广告返回结果,图10(b)为点击按钮后显示的画面。可以看到,模型对羽绒服的检测效果基本符合要求,检测框没有大幅度偏移,检测类别也没有出现错误,广告推送内容合适。广告图片每2 s 更新一次,每个类别对应的广告图片为10 张,大小为300×300。
4 结论
本文基于深度学习设计并实现了智能广告牌。将深度学习、计算机视觉技术、目标检测技术与液晶显示广告牌相结合,实现了智能识别广告牌前行人的特征信息,包括性别年龄和特定服饰,并根据识别结果有针对性的推送广告图片,从而改善广告宣传效果。
1)制作了包括羽绒服、风衣等7 个服饰类别,男女婴儿、男女青年等10 个性别年龄组合类别的数据集,使用SSD-MobileNet-FPN 训练便于部署到移动设备的轻量级目标检测模型。模型最终的mAp 值达到了0.855 0,系统检测速度达到了5 f/s。
2)设计模拟服务器端和广告牌的通信收发流程,模拟智能广告牌识别特定类别后广告推送流程,并借助RK3399 开发板完成演示。
3)本文根据识别结果有针对性地推送广告,从而达到改善广告宣传效果的目的,以尽量少的广告费用达到理想的宣传效果。同时,可以为行人减少无用广告信息的推送,节省了行人的时间。本文使用RK3399 开发板模拟广告牌,利用改进后的目标检测算法SSD,训练出一个可以检测特定服饰和性别年龄的目标检测模型,实时检测摄像头前行人特征,并根据检测到的行人的不同特征返回不同广告信息,解决了传统液晶广告牌只能按照预设内容循环播放广告的问题,使得广告推送更具针对性,宣传效果更好。
通过分析研究发现该设计可以在以下方面进行改进和提升:
1)数据的采集方面。由于图像来源有限,均从百度、淘宝和影视剧剧照中获得,数据集小。如果有途径获得各个类别的大量图片,可以对模型的检测效果有很大改善,模型的泛化能力也会相应增强。
2)采集的服装类别有限。文中服饰类别只包括了针织帽、墨镜、羽绒服、连衣裙、西装、风衣和牛仔裤。如果想要扩大广告牌的识别目标的类型范围,则需要新增加更多常见的服装类别。
3)服装类别划分宽泛。如果对服装类别再进行细致划分,加上领型、颜色、衣长、版型、花纹、袖长等属性,根据检测结果可以更具针对性地返回广告信息。
猜你喜欢
数码世界(2020年11期)2020-11-23
科学大众(2020年17期)2020-10-27
新世纪智能(英语备考)(2019年3期)2019-06-12
成功(2018年10期)2018-03-26
网络空间安全(2016年11期)2017-02-13
中国房地产业(2016年8期)2016-03-01
新校长(2016年8期)2016-01-10
武夷学院学报(2014年5期)2014-07-19
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
