
基于ANN 的加工零件表面粗糙度和能耗预测方法
2021-12-15 02:38肖小平李晶晶张超周光辉杨雄军
应用科技 2021年6期
肖小平,李晶晶,张超,周光辉,杨雄军
1.湖南省计量检测研究院,湖南 长沙 410014 2.西安交通大学 机械工程学院,陕西 西安 710049
随着制造业自动化和智能化的快速发展,提高制造效率、降低成本和减少资源浪费成为各企业的共同目标。精准预测零件加工能耗与表面粗糙度(常用Ra表示)已成为当前智能车间绿色制造的主要研究热点。目前对零件粗糙度和能耗的预测方法众多,如正交试验[1]、遗传算法[2]、BP 神经网络[3]、回归模型[4-5]、支持向量机[6]等。上述关于粗糙度、能耗的预测模型大多将切削参数作为自变量,其他因素以系数方式影响计算结果。但在实际加工过程中,同一规格的刀具仍存在着因磨损状况不同而导致的切削参数差异,其磨损状况对粗糙度和能耗等有着不可忽视的影响。
ANN 因其在处理随机数据、非线性数据等方面的自学习、自适应优势而被广泛应用于预测、分类等研究。Paturi 等[7]以切削参数为自变量,利用回归模型和ANN 预测AISI 52 100 钢硬车削过程中的表面粗糙度。Kant 等[8]结合实际加工实验,研究了ANN 对能耗的预测能力。Gupta 等[9]提出了用ANN 和支持向量回归相结合的车削参数优化方法。Sangwan[10]和Kumar 等[11]提出了一种将ANN 和遗传算法相结合的方法对车削加工参数进行优化。从上述研究可以看出,使用ANN 模型考虑加工参数和加工性能之间的非线性关系,对预测实际加工过程中表面加工质量和切削能耗时,比传统经验模型更具优势。基于以上分析与思考,本文从切削过程出发,考虑实际切削过程中影响刀具磨损与切削条件的因素,以刀具后刀面磨损量和切削三要素为自变量,采用ANN 模型对能耗和表面粗糙度进行预测,通过与回归模型进行实验对比,分析ANN 模型的优越性,据此扩展切削能耗的预测方法,为研究和践行智能车间低碳制造提供理论和方法指导。
1 基于ANN 的粗糙度和能耗预测
1.1 粗糙度和能耗预测模型
本文以刀具后刀面磨损量和切削三要素为输入,采用ANN 构建了零件加工能耗和表面粗糙度在线预测模型,如图1 所示。

图1 粗糙度和切削比能预测的ANN 结构
ANN 为该模型的核心,其结构主要包括输入层、输出层、隐含层及各层的神经元。输入层和输出层主要依据样本数据来设定。其中,自变量为刀具切削速度、进给量、切削深度和后刀面磨损量,故输入层应包含4 个神经元。同理,因变量为粗糙度和切削比能,因此输出层包含2 个神经元。由于输入变量和预测变量较少,且样本数据量也较少,为避免由于网络结构过于简单而造成较大的误差,在ANN 中设置2 层隐含层。
1.2 ANN 的参数设计
由ANN 结构可知,输入层包含4 个神经元即M=4,输出层包含2 个神经元即N=2,隐含层数为2。隐含层中神经元的数目会对网络的收敛速度和稳定性产生巨大影响:神经元数目过少,则导致网络对切削比能和粗糙度的预测准确率低,达不到预定的目标;而较多的神经元则会增加ANN 复杂度和降低其稳定性。当前常用试凑法或经验法来确定中间隐含层中所包含的神经元数目,广泛使用的经验公式[12]如下:

式中:Li为隐含层所包含的神经元数,m为输入层中所包含的神经元数,n为预测层中所包含的神经元数,a为0~10的正整数。
通过式(1)只能确定隐含层神经元数目的大致范围,要想得到精确的神经元数还需通过实际数据对网络进行训练,进一步比较选出最优的隐含层神经元数目。选取不同数量的神经元在相同环境下对ANN 进行训练并比较其输出误差值,进而选出最优的ANN 结构,如图2 所示。
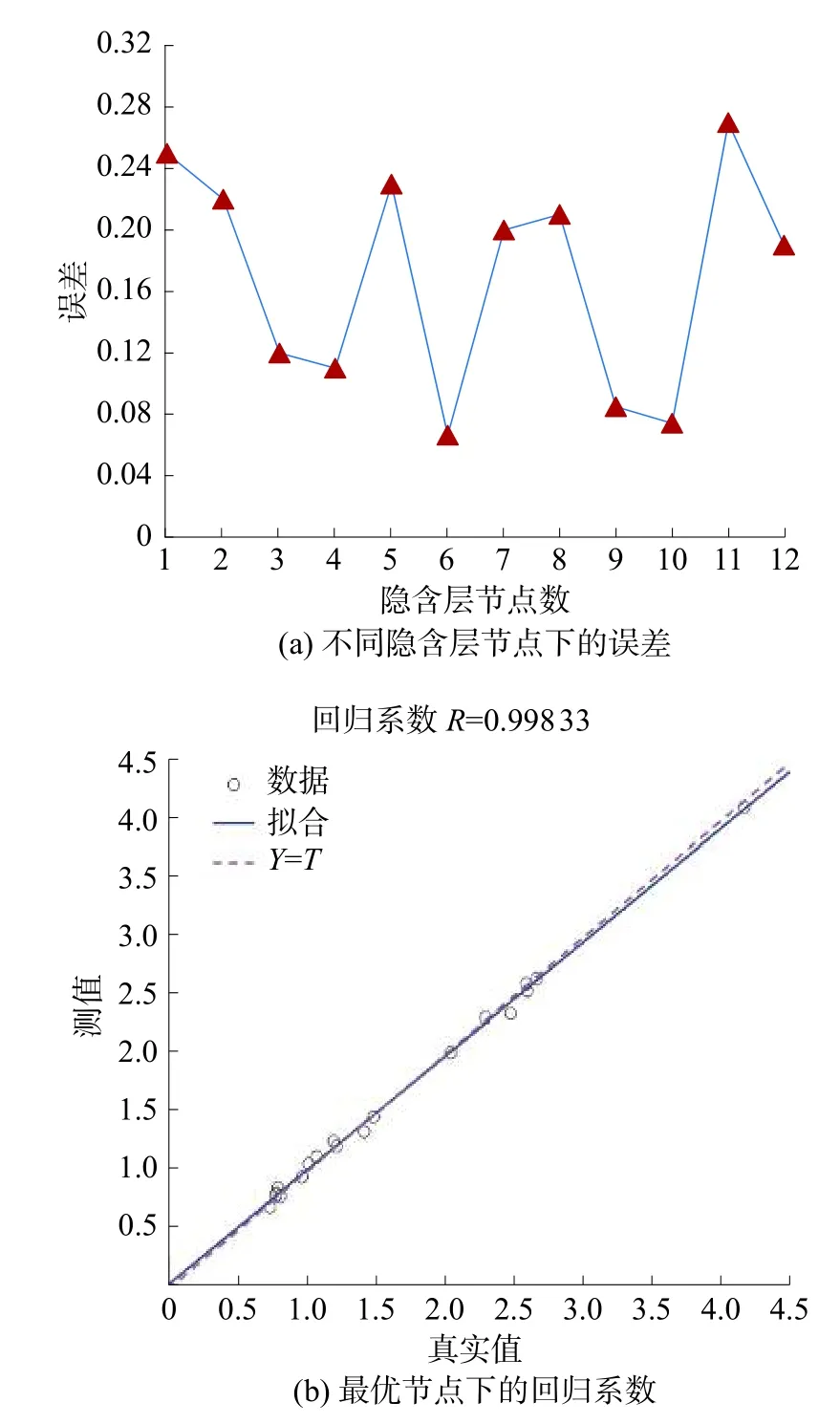
图2 隐含层节点的选择
由图2 可知,当2 个隐含层皆由6 个神经元组成时,验证集数据的平均绝对误差最小,训练数据集的回归系数为0.99833,接近1,说明实验结果与预测结果具有很强的相关性。因此,确定4-6-6-2 结构为最优的ANN 模型。
学习率是影响ANN 预测结果的一个关键变量。学习率过小会致使网络的收敛速度降低;相反,较大的学习率可能会造成ANN 很难收敛。因此,训练过程中需要不断调整学习率以使网络的准确率最高,经过多次试验,最终学习率取0.002,动量系数取0.8,网络中的学习算法如下:

式中:xk为权值参数矩阵,α为网络的学习率,β为动量变量的系数,gk为ANN 中的学习函数梯度。
1.3 ANN 函数的选择
1.3.1 传递函数
ANN 层与层之间通过传递函数进行联系,经过多次对ANN 进行训练发现,输入层到第一个隐含层、第一个隐含层到第二个隐含层以及第二个隐含层到最终预测层的传递函数分别选择线性函数、对数函数和线性函数。
1.3.2 优化函数
ANN 的训练过程包括正向传递过程和反馈传递过程,传递过程中根据训练误差的大小通过优化函数不断调整网络各个节点的权值,以使网络的精度最高。常用的优化函数有梯度下降法、牛顿法、变学习率反向传播(back propagation,BP)算法和动量BP 算法[13-14](traingdm 函数)等。在本文中采用动量BP 算法traingdm 作为优化函数。
2 样本数据集构建
2.1 样本集构建及归一化方法
本文以刀具后刀面磨损量和切削三要素为实验变量,以粗糙度和切削比能为因变量的车削实验数据作为训练样本。
由于训练样本的数量级和量纲不同,相互之间的差异较大,如若直接用于ANN 的训练,将会导致较大的误差,甚至可能无法获得收敛的模型。因此,为了消除输入样本的数量级差异,将其无量纲化。在训练样本数据之前需对其执行归一化操作,计算公式为
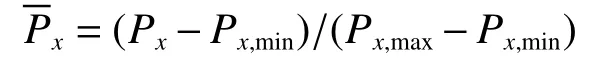
式中:Px为训练样本中的一组数据,Px,min为该组数据中的最小值,Px,max为该组数据中的最大值,为归一化处理后的数据。
当对实验数据进行预测后,需要对数据执行反归一化操作才能够使预测结果有实际的物理意义,计算公式为
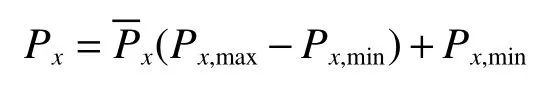
2.2 基于车削实验的样本数据集构建
1)车削实验环境
为验证提出的粗糙度和切削比能预测模型,在数控车床FTC20 进行车削实验。车削实验的刀片选用不同磨损程度的U6RW3862-R2-R1-P0,材料选用长度100 mm、直径100 mm 的铸铁棒料。刀片的后刀面磨损量由激光共聚焦显微镜OLS4000 进行测量,表面粗糙度由高性能粗糙度仪TIME3221 进行测量,功率测量采用钳式功率计PW3360 完成,如图3 所示。

图3 实验使用机床、刀具及后刀面磨损测量图
2)样本数据集
在数控车床FTC20 上进行车削实验。车削一共包含24 组实验,随机抽取第2、7、9、14 和21 组共5 组实验数据作为验证组,其余19 组作为拟合组,正交实验水平如表1 所示。

表1 FTC20 车削实验切削实验水平表
切削比能(specific cutting energy,SCE)通常被定义为去除工件特定体积材料所消耗的切削能量,其值用ESC表示。SCE 可用于描述机床的能耗情况,能耗通过测量机床的功率来进行监测。为保证实验的准确性,在同一组实验下每测量5 次表面粗糙度值求一次平均值,每测量10 次功率值求一次平均值,获得的实验数据如表2 所示。
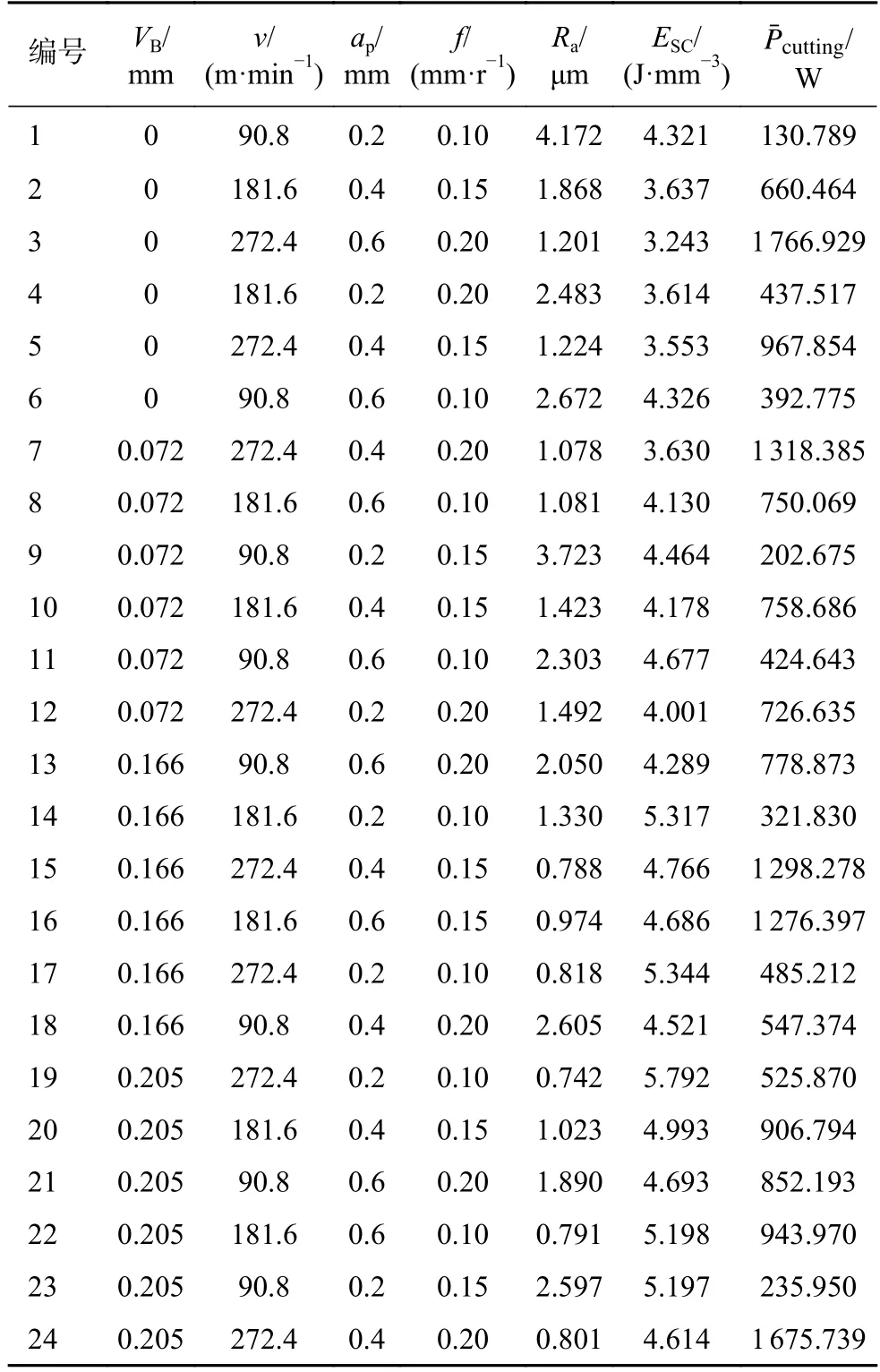
表2 实验结果
3 案例研究
基于构建的样本数据集,本节训练得到了考虑刀具磨损的粗糙度和能耗预测模型,并通过与回归模型预测方法进行对比,验证了所提模型与方法的正确性和有效性。
3.1 基于ANN 的粗糙度和能耗预测模型训练与应用
为了方便与回归模型进行对比分析,同样以样本数据中的19 组实验数据作为训练集,另外5 组数据作为验证集。
ANN 对Ra预测结果与实测值的比较如图4所示。图4(a)是在训练组上ANN 预测值与实测值的比较情况,最大百分比误差(maximum percentage error,MPE)值eMP为6.24%,平均绝对百分比误差(mean absolute percentage error,MAPE)值eMAP为2.48%;在验证组图4(b)中,eMP为6.44%,eMAP为5.12%。采用ANN 的预测误差值均在7%以内,说明了采用本文提出的ANN 结构能够准确且有效地预测机床实际加工中的特征表面粗糙度,证明了本文提出的ANN 结构的合理性。

图4 Ra 的ANN 预测结果与实测值对比
ANN 对切削比能的预测结果与实测值比较如图5 所示。

图5 ESC 的ANN 预测结果与实测值对比
图5(a)是在训练组上ANN 预测值与实测值的比较情况,eMP为6.38%,eMAP为2.65%;在验证组图5(b)中,eMP为3.31%,eMAP为1.66%。采用ANN 的预测误差值均在7%以内,说明了采用本文提出的ANN 结构也能够准确且有效地预测机床实际加工中的切削比能,进而实现能耗的有效预测,同样证明本文提出的ANN 结构的合理性。
3.2 基于回归模型的刀具磨损的粗糙度和能耗预测
基于刀具磨损建立表面粗糙度和切削功率的回归模型(regression model,RM)[15-16]为
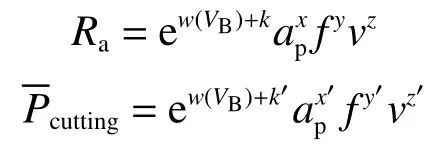
式中:Ra为表面粗糙度,mm;VB为后刀面磨损量,mm;k、k′为待定系数;ap为切削深度,mm;f为进给量,mm/r;v为切削速度,m/min;为切削功率,W;w、x、y、z、x′、y′和z′为待拟合系数。
根据文献[17-18]得Esc的计算公式为

式中:Ecutting为切削过程消耗的能量,J;Q为材料去除体积,mm3;MRR为材料去除率,mm3/s;ESC为切削比能,J/mm3。
整理后得:

表面粗糙度和切削比能的回归模型皆与刀具切削参数及后刀面磨损量等存在复杂的幂函数关系,因此,为方便进行实验验证,整理得:
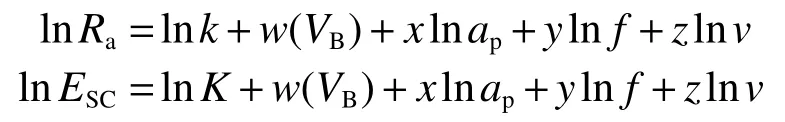
采用IBM SPSS Statistics 进行回归处理得到回归模型中的各个系数,获得Ra的多元线性拟合分析结果如表3 所示。根据线性回归分析,R2=0.99 >0.85,表明模型拟合情况良好。

表3 多元非线性拟合分析结果
因而得到的模型拟合公式如下:

通过对拟合数据的进一步分析判断模型拟合的效果,给出FTC20 车削实验中表面粗糙度的拟合效果及验证组误差百分比图,如图6 所示。

图6 Ra 的拟合效果及验证组误差
图6(a)给出的是回归拟合粗糙度与实际实验结果的比较情况,拟合组的eMP为6.47%,eMAP为2.98%;在图6(b)验证组中,eMP为6.70%,eMAP为3.43%。由此说明拟合误差较小,效果理想。
同理,对切削比能也进行回归和数据分析,R2=0.96 >0.85表明模型拟合情况良好。得到模型的拟合公式为
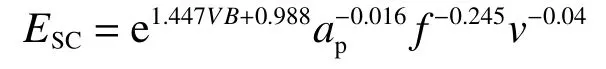
同样通过对切削比能的拟合数据进一步分析来判断模型拟合的效果,给出FTC20 车削实验中切削比能的拟合效果及验证组的误差对比如图7所示。


图7 ESC 的拟合效果及验证组误差
图7(a)给出的是回归拟合切削比能与实际实验结果的比较情况,拟合组中的eMP为6.62%,eMAP为2.25%;在图7(b)验证组中,eMP为4.50%,eMAP为1.92%。由此说明拟合误差较小,效果理想。
3.3 模型验证和性能分析
为了充分评价回归模型(regression model,RM)和ANN 分别对表面粗糙度和切削比能的预测能力,将ANN 和回归模型的预测结果与实测值进行对比,并计算了模型预测结果与实测值之间的绝对误差百分比值。表面粗糙度实测值与模型预测结果对比如图8 所示,详细数据如表4所示。

图8 Ra 的实测值与不同方法预测值对比
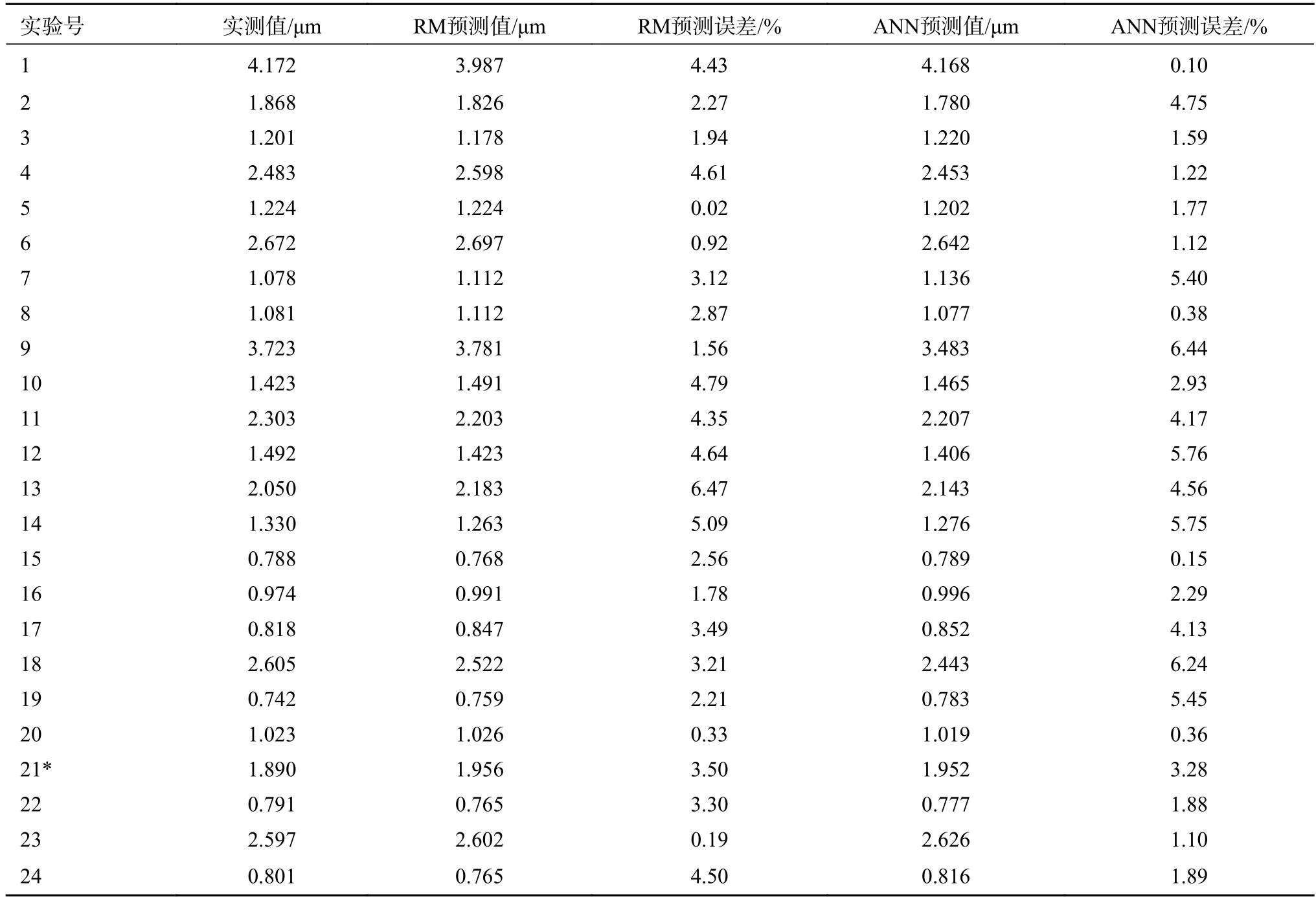
表4 Ra 的模型预测值与实验实测值之间的绝对百分误差
同理,对切削比能的实验数据也进行了对比分析,如图9 所示。

图9 ESC 的实测值与不同方法预测值对比
在Ra验证集上,RM 和ANN 的eMP分别为6.70%和6.44%。在ESC验证集上,RM 和ANN 的eMP分别为3.50%和3.31%,eMAP分别为1.92%和1.66%。由此可以看出,2 种预测方法的预测结果都在可接受的误差范围内,均适用于对Ra和ESC进行预测。但是与RM 相比,ANN 的预测结果更接近实测值,预测效率更高。因此,选用ANN 进行Ra和ESC预测更准确。
4 结论
本文考虑了刀具后刀面磨损对切削比能和表面加工质量的影响,基于ANN 模型进行工件表面粗糙度和能耗预测,并通过与回归模型对比,验证了ANN 方法的优越性。
1)本文以刀具磨损对能耗和粗糙度预测的影响为考虑因素,从实际切削过程出发,以刀具后刀面磨损量和切削三要素为自变量,设计了基于ANN 的粗糙度和能耗预测模型,相较于传统的预测模型更符合切削实际过程。
2)采用RM 和ANN 对能耗和表面粗糙度进行评估,通过实验比较分析,在Ra和ESC验证集上,ANN 的预测结果最大百分比误差更接近实测值,相较于RM,ANN 对表面粗糙度和能耗的预测精度分别提升了5.4%和13.5%,验证了ANN 模型在预测效率和预测精度上的优越性。
猜你喜欢
环境保护与循环经济(2021年7期)2021-11-02
哈尔滨轴承(2020年1期)2020-11-03
甘肃科技(2020年20期)2020-04-13
制造技术与机床(2019年11期)2019-12-04
中国奶牛(2019年10期)2019-10-28
模具制造(2019年4期)2019-06-24
电子制作(2018年23期)2018-12-26
制造技术与机床(2017年7期)2018-01-19
制造技术与机床(2017年12期)2017-02-02
材料科学与工程学报(2016年2期)2017-01-15
