
基于大数据挖掘的配电网计划停电影响因素建模分析
2021-12-23 12:50刘江东吴志坚黄振勇吴予乐
测试技术学报 2021年6期
刘江东,吴志坚,黄振勇,濮 实,吴予乐,高 洁
(国网江苏省电力有限公司 扬州供电分公司,江苏 扬州 225009)
0 引 言
电网断电一般分为计划断电和故障断电.在这种情况下,为了减少供电系统和电力设备故障对用户用电的影响,电网企业可以根据线路和设备的实际运行情况,对线路或设备进行定期的维修和保养.此外,电网在升级改造、配合城市建设施工等情况下,还需要提前统筹安排停电作业.其中,少数检修工作需要相应的线路停电.但是,不合理的计划停电会给日常生活造成过大干扰.因此,计划停电是衡量电网运行状况的重要指标,对计划停电影响因素的分析具有重要意义.
国外电网计划停电研究较为成熟,利用大数据技术,构建配电网可靠性数据信息库,分析电网规律性信息,同时根据配电网实际情况,以停电电量最小为目标,建立优化数学模型,对配电网内在进行各种约束,进而预测电网停电时间.国内电网计划停电研究同样取得较大发展,通过分布函数中的对数正态分布,描述电网复杂的运行状况,数据挖掘停电时间参数、设备故障率等,绘制电网的负荷变化曲线,根据实际数据算例,评估电网运行风险,得到总停电持续时间[1,2].
在以上理论的基础上,本文提出基于大数据挖掘的配电网计划停电影响因素建模分析方法,对电网供电、停电进行调度管理.
1 配电网计划停电影响因素提取
利用大数据挖掘技术,获取配电网计划停电影响因素.统计配电网历史数据,挖掘与电网计划停电关联度较高的信息数据,具体流程如图 1 所示.
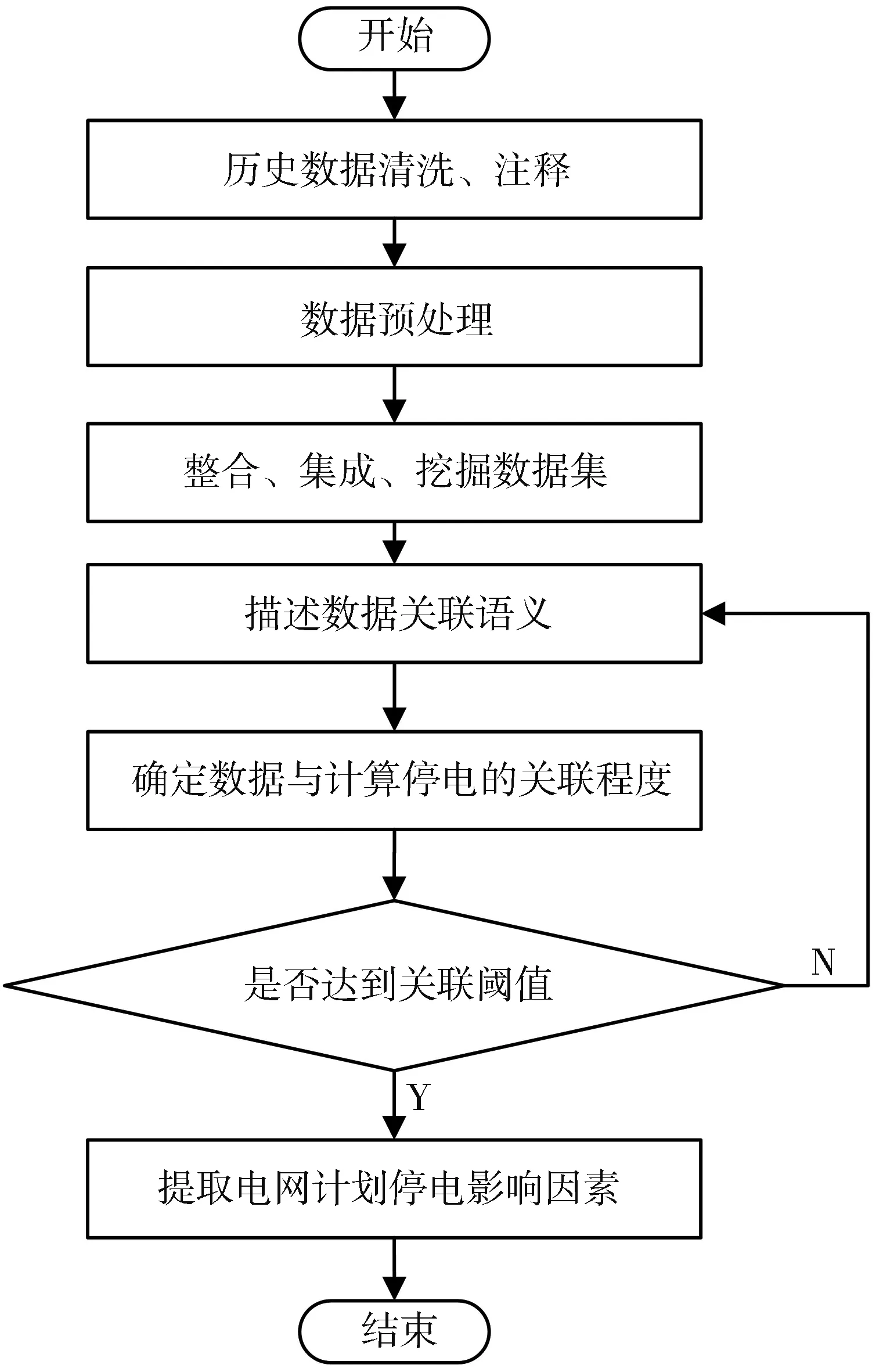
图 1 影响因素的大数据挖掘流程
如图 1 所示,导出配电网停电相关的日志记录、传感器数据,包括设备台账、投运试验等静态参数、在线监测、运行记录、带电检测、巡视记录等动态参数,以及缺陷故障、检修试验等准动态参数、对历史数据进行预处理,设采集样本数据为ti(i=1,2,…,n),则原始数据的样本平均值
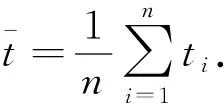
(1)
原始数据剩余误差

(2)
根据贝赛尔公式,得到数据均方根偏差

(3)

2 建立配电网计划停电影响因素评价模型
对提取影响因素进行建模,判定各因素与电网计划停电的关联程度.提取的计划停电各影响因素如表 1 所示.

表 1 配电网计划停电影响因素
采用熵权法,计算各影响因素权重,首先建立评价矩阵
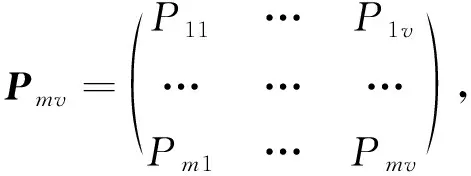
(4)
式中:m为影响因素的个数;v为配电网供电区域的个数[5].对影响因素进行无量纲化处理,将其分为正向和反向两种,其中正向与计划停电增量方向一致,反向则相反[6].其标幺值具体定义如表 2 所示.

表 2 影响因素的标幺值判断标准
根据各影响因素的标幺值,对其进行规范处理,计算公式为
Cjr=(Pjr-Pmin)/(Pmax-Pmin)j=
(1,…,m)r=(1,…,v),
(5)
式中:Cjr为评价矩阵中第j行、第r列影响因素标准化后的值;Pmax、Pmin分别为影响因素标幺值的最大值、最小值[7-9].各因素信息熵
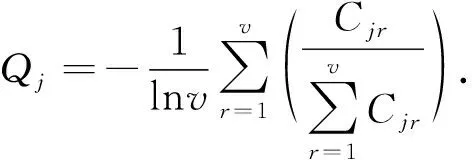
(6)
则第j个影响因素的熵权值

(7)
将熵权值wj作为影响因素权重,判断各因素与配电网计划停电的关联程度[10-11].至此完成配电网计划停电影响因素评价模型的建立.
3 分析影响因素计划停电敏感程度
计算模型评价值划分各影响因素作用下配电网的可靠等级,确定是否进行计划停电[12].建立影响因素评语集F={F1,F2,F3,F4,F5},分别表示供电可靠性好、较好、一般、较差、差,共5个等级,采用专家打分方式,定义评语集分值为{10,20,30,40,50}[13].然后定义评语集中各等级隶属度的判定依据,采用模糊多值评估法,对影响因素在各等级的属于程度,进行多值描述,得到影响因素的评价结果集,实现各因素的模糊评判[14].则评价结果集中,第j个影响因素的评分值
Ej=10I1+20I2+30I3+40I4+50I5,
(8)
式中:I1~I5分别为F1~F5的隶属度.汇总评价结果集和权重集,得到评价模型的最终评价结果[15]

(9)
根据最终评价结果,划分配电网可靠程度,进而确定计划停电敏感程度.将敏感程度划分为1~5个等级,具体如表 3 所示.

表 3 配电网计划停电敏感程度
根据表 3 内容,确定各因素对配电网计划停电的影响程度,判断电网是否需要停电及停电时间,至此完成影响因素计划停电敏感程度的分析以及基于大数据挖掘的配电网计划停电影响因素建模分析方法设计.
4 实验设计与分析
进行对比实验,将本文设计方法记为实验A组,两种传统配电网计划停电影响因素建模分析方法分别记为实验B组和实验C组.
4.1 实验准备
选取某城市电网,将某供电局10 kV配电结构作为实验对象,区域内共有10 kV线25条,线路长793.728 km,总用户数为1 652,所辖变电站20座,总容量为226.9 MVA,配电变压器为24台,主变20台,配电网接线如图 2 所示.

图 2 10 kV配电网结构图
该配电网P11~P61为所接负荷,P71~P91为负荷点,M1~M9为主干线,K1~K10为分支线,区域内平均622 km2有一变电站,均有一台~两台变压器,多主变率为14.1%,平均供电半径为 45 km.配电网可挖掘的历史数据如表 4 所示.

表 4 配电网可挖掘历史数据
由表 4 可知,该区域电网的供电可靠性要高于全国平均水平,计划停电呈逐年下降趋势,3组分析方法分别对该电网计划停电影响因素进行分析.实验A组为本文方法,实验B组为文献[1] 方法,实验C组为文献[2]方法.
4.2 实验结果
4.2.1 第1组实验结果
首先比较3组分析方法作用下的供电可靠率,供电可靠率

(10)
式中:α为配电网每次停电持续时间;β为每次停电用户数;C为总用户数;B为分析方法作用后的统计时间.A值越大,电网持续供电能力就越高.将供电区域分为多个区域,各区域电网计划停电影响因素的权重值如表5所示.

表 5 各区域影响因素权重值
计算各区域的供电可靠率,实验对比结果如图 3 所示.

图 3 供电可靠率对比结果
由图 3 可知,实验A组平均供电可靠率为99.235%;实验B组和实验C组的供电可靠率,分别为96.436%和95.102%,相比实验B组和实验C组,A组电网供电可靠率分别提高了2.799%,4.133%.
4.2.2 第2组实验结果
3组方法对配电网负荷进行预测,得到各周的最大负荷预测值,将预测值与实际值相比较,计算负荷预测误差,比较3组方法分析结果的可靠性.实验A组根据历史负荷数据,输出预测值,记录配电网周实际的最大负荷值,分别为121.625 kW,128.097 kW,119.289 kW,135.902 kW,128.021 kW,132.092 kW,121.872 kW,实验对比结果如图 4 所示.

图 4 负荷预测误差对比结果
由图 4 可知,实验A组负荷预测误差的平均值为0.346%;实验B组和实验C组的负荷预测误差,分别为1.982%和1.379%,相比实验B组和实验C组,A组电网负荷预测误差分别降低了1.636%,1.033%.
4.2.3 第3组实验结果
比较各供电区域内3组分析方法提取的影响因素与配电网计划停电的关联度,关联度表示影响因素对计划停电的贡献程度,关联度越高,影响因素与计划停电的关联水平就越高,关联度

(11)


图 5 影响因素关联度对比结果
由图5可知,实验A组负荷影响因素的平均关联度为0.897 1,实验B组和实验C组的平均关联度,分别为0.643 6和0.537 2,相比实验B组和实验C组,A组影响因素关联度分别提高了0.2535和 0.359 9.综上所述,本文分析方法相比于传统分析方法,提高了影响因素与计划停电的关联水平,对电网负荷预测更为准确,保证了电网对用户的持续供电能力.
5 结束语
本文分析方法充分发挥了大数据挖掘技术的优势,保证了电网负荷预测值的准确性.但研究仍存在一定不足,在今后的研究中,应该进一步改变配电网结构与冗余度,深入分析配电网计划停电的分布规律、时间特点,保证停电时间的判断精度.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
电子制作(2018年8期)2018-06-26
中成药(2018年1期)2018-02-02
电力与能源(2017年6期)2017-05-14
电测与仪表(2016年5期)2016-04-22
河南电力(2016年5期)2016-02-06
信息通信技术(2015年6期)2015-12-26
电源技术(2015年11期)2015-08-22
