
基于多分类监督学习的驾驶风格特征指标筛选*
2022-03-20 14:42廖小棱蒋佩玉
交通信息与安全 2022年1期
王 旭 马 菲 廖小棱 蒋佩玉 张 伟 王 芳
(1.山东大学齐鲁交通学院 济南 250001;2.山东高速集团有限公司 济南 250001;3.山东省智慧交通重点实验室 济南 250001;4.山东高速信息集团有限公司 济南 250001)
0 引 言
道路交通安全问题是近年来全球交通领域关注的热点问题。据统计,2019年我国总计发生机动车交通事故21.5万起,事故造成死亡6.27万人,受伤25.6万人,直接财产损失13.46亿元[1]。大量道路交通事故致因分析表明:超过80%的事故与驾驶员行为操作有关[2],其中驾驶风格与事故发生率之间存在较强的相关性。美国国家公路交通安全管理局发现,攻击性驾驶行为约占所有致命交通事故的2 3[3]。驾驶员激进程度越高,驾驶过程中越容易出现急变速、频繁换道、超速行驶等不良驾驶行为[4]。这些不良驾驶行为导致恶性交通事故的频繁发生,促使研究人员开始重视驾驶风格相关研究[5-6]。
驾驶风格是指驾驶员操纵车辆所表现出的相对稳定的行为特性,是1种具有个体性、差异性的倾向性行为[7]。早期对驾驶风格的研究集中利用问卷调查的方式[8-10],从文化、性别、地域等角度出发,设计驾驶行为问卷[11]以及多维度驾驶风格量表[12]。问卷调查方法虽简便可行,但易受驾驶员的主观情绪影响,调查结果的准确性、可靠性难以保证。此外,事后对驾驶员进行问卷调查,难以深入挖掘真实驾驶行为状态,调查结果可能会偏离其实际驾驶表现,驾驶风格分类的实时性、精确度较差。车联网以及大数据技术的发展促使许多学者开始利用自然驾驶实验数据建立驾驶风格分类及识别模型,并尝试在驾驶辅助系统中进行实时驾驶风格识别,如Bellemd等[11],Castignani等[12]将加速度、速度或踏板位置等作为特征参数,利用主成分分析(principal component analysis,PCA)对上述特征进行降维处理,并结合k-means聚类划分驾驶风格,搭建支持向量机和神经网络模型实现驾驶风格识别。Karginova等[13]则利用聚类结果,在不同时间窗口下对K近邻、神经网络、决策树和随机森林等方法的识别能力进行了比较,在仿真环境中发现神经网络识别正确率最高。相较于问卷调查方式,利用自然驾驶数据可从微观驾驶行为特征出发,有效识别驾驶风格。识别驾驶风格并为驾驶员提供预警可及时干预危险驾驶行为,降低交通事故风险,改善交通安全状况[14]。
然而,现有研究驾驶风格评价指标种类繁多,选取过多的指标在增加数据采集及处理难度、识别系统通信带宽度要求的同时,也会降低驾驶风格识别精度,无法及时给予驾驶员正确的预警提醒。驾驶辅助系统识别驾驶风格时,过多数据指标要求也会对系统用户的隐私造成威胁,降低系统用户信任度,因此需要经过特征工程筛选特征子集。但以往的研究仅关注驾驶风格与特征指标之间的相关性,忽略考虑利用特征指标识别驾驶风格的有效性与精度。例如,吕能超等[15]开展实车驾驶试验,用Near-crash事件代替真实碰撞事件研究驾驶员行为特征,通过方差分析发现驾驶风格与最大、平均减速度有显著影响关系;Ma等[16]采用网约车辆驾驶行为数据,发现驾驶员在巡航、乘车请求和下车3项驾驶任务时,驾驶风格在转弯、加速和减速操作中存在显著差异;杨曼等[17]引入行车安全事件表征驾驶风险,建立Logit模型分析主要因素与风险关系,得出驾驶风险与行车安全事件类型、原因、平均减速度、天气、年龄和驾龄等6个因素有显著关联性。
综上,本文基于车联网自然驾驶数据,利用无监督学习算法实现驾驶风格分类,构建特征筛选模型,分析各特征指标对驾驶风格的影响程度,并搭建神经网络驾驶风格识别模型验证指标的有效性。
1 驾驶行为数据处理
1.1 驾驶风格量化指标集
本文选择美国安全试验模型部署计划中的主数据集——基本安全信息(BSM)观察研究驾驶员微观驾驶行为。BSMs数据集包含车辆运动状态和位置数据,其主文件BsmP1是以10 Hz频率测量得到的高分辨率微观驾驶数据。研究按照连续行程及车辆ID分割每辆车的数据,合并同一驾驶员的不同行程,并将速度、加速度、偏航率等时序数据进行统计学处理,得到242名驾驶员的驾驶风格量化指标集。此外,考虑到驾驶员对加速变化比加速本身更敏感[18],本研究还引入加速度冲击度即加速度变化率作为驾驶风格量化指标。本文所选择的指标具体见表1。

表1 驾驶风格量化指标集Tab.1 Driving style quantitative index set
1.2 主成分分析
考虑到上述18个驾驶风格指标的相关性以及后续驾驶风格聚类所需的工作量,本文利用PCA实现驾驶风格指标集的降维处理,结果见图1和表2。图1为18个主成分的贡献率,贡献率越大,包含的数据信息则越多。前6个主成分的累积贡献率达到85%,故可用其代表原有18个评价指标[19]。进一步计算各驾驶员的前6个主成分得分见表3,作为后续驾驶风格分类模型的输入。
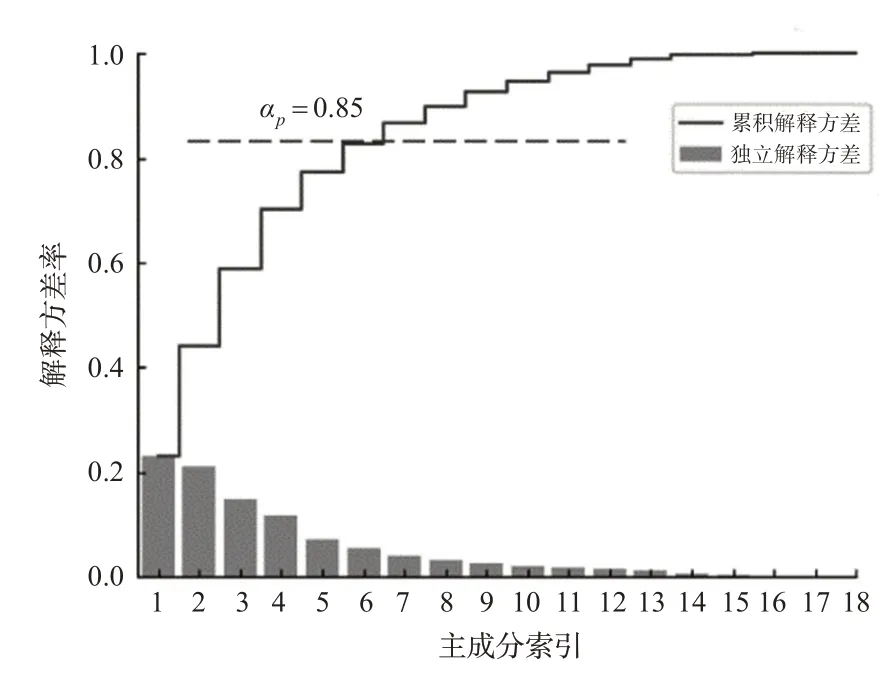
图1 主成分贡献率图Fig.1 Principal Component Contribution Rate

表2 各主成分的信息贡献率与累积贡献率Tab.2 Information Contribution Rate and Cumulative Contribution Rate of Each Principal Component
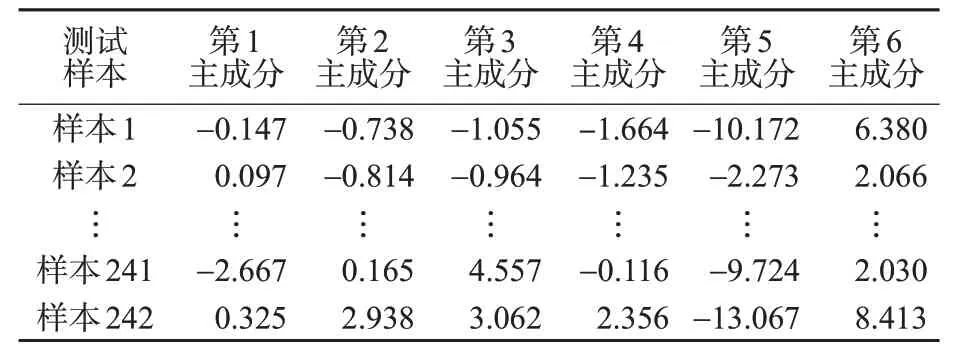
表3 驾驶员主成分得分Tab.3 Driver principal component score
此外,为了评价各指标在所选前6个主成分中的重要性,本文计算了各指标的因子载荷量,其绝对值大小反映了指标与主成分的关联程度。由表2和表4可以看出:第1主成分包含的最大信息量为24.2%,且与最小横向加速度、平均横向加速度关联性最强,可见第1主成分极大程度上反映了驾驶员的横向加速度信息;第2主成分包含的信息量次之,为21.9%,且与速度标准差、最大横向加速度关联性最强,可见第2主成分综合反映了车辆的运动状态信息;第3主成分包含的最大信息量为15%,且与纵向冲击度平均值、垂向冲击度平均值关联性最强,因而第3主成分可代表加速变化。综上,虽然降维后的各大主成分都包含了表1中驾驶风格指标信息,但主成分对每个指标的反映程度不同。

表4 各指标的因子载荷量Tab.4 Factor load of each index
2 驾驶风格分类
2.1 聚类算法
K-means算法是基于划分的无监督聚类学习算法,以欧式距离作为样本相似性度量准则,距离越小,样本相似性越高。然而K-means算法聚类结果易受初始聚类中心影响,不当的初值选择可能导致算法收敛于局部最优解[20]。因此,相关研究对初始聚类中心的选取进行改进提出K-means++算法[21],具体聚类过程如下。
步骤1。从样本数据集中随机选择1个样本作为第1个聚类中心C1。
步骤2。对于数据集中每个点Xi,计算与已知聚类中心的距离D(x),其被选为新的聚类中心的概率为,按照轮盘法选出新的聚类中心。
步骤3。重复步骤2,直到k个初始聚类中心全部确定。
步骤4。提取数据集中其余样本Xi,分别计算与k个聚类中心的距离,并将其划分到距离最小的聚类中心所对应的簇中。
步骤5。针对每个簇,重新计算聚类中心。
步骤6。重复步骤2和步骤3,直到类内误差平方和达到最小,聚类中心不再改变,算法收敛。
步骤7。输出K-means++算法聚类结果。
2.2 聚类效果评价
为了客观评价K-means和K-means++的聚类效果,本文选取轮廓系数法作为评价指标。轮廓系数法从内聚度a(i)和分离度b(i)这2个角度评价了聚类结果的集中程度。轮廓系数的值介于[-1,1]之间,越趋近于1代表内聚度和分离度越好,即聚类效果越好。对于第i个驾驶样本而言,其轮廓系数值S i计算见式(1)。
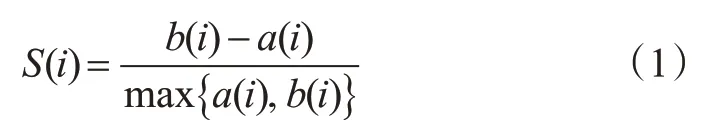
式中:a(i)为簇内不相似度,表示驾驶样本i到同簇内其他样本不相似程度的平均值;b(i)为簇间不相似度,表示驾驶样本i到其他簇的平均不相似程度的最小值。
本文将驾驶风格分为3类:平静型、一般型和激进型[22]。K-means与K-means++的聚类效果见表5。

表5 K-means与K-means++聚类效果Tab.5 Clustering effect of K-means and K-means++
对比2种方法的聚类结果,发现在二者迭代次数相同的情况下,K-means++的轮廓系数值大于K-means,这说明K-means++的聚类效果更优,故本文选择K-means++的聚类结果作为下一步递归特征消元算法(RFE)的输入,完成驾驶风格样本标记工作。
3 驾驶风格识别
3.1 特征筛选
简洁明了的驾驶风格评价体系与最大程度表征驾驶风格的特征指标,对研究驾驶行为及优化驾驶辅助系统尤为重要。主成分在不同程度上反映了不同指标,但可能会削弱某些因素的重要性从而影响到后续的驾驶行为分析。因此,本文选取支持向量机(SVC)与随机森林(RF)作为递归特征消元(RFE)的底层迭代模型,构建SVC-RFE与RF-RFE模型进行驾驶风格指标筛选。
RFE是1种性能良好的后向搜索特征筛选方法[23-24]。SVC是1种二分类模型,基本模型是在特征空间上的间隔最大的线性分类器,在N维样本空间里找到分类超平面,将空间上的训练样本进行分类。RF是1种利用多棵树训练样本的分类器,可随机选择决策树节点划分特征,在训练样本特征维度高时,仍能高效地训练模型。SVC-RFE与RF-RFE能够通过SVC与RF进行指标重要性排序,进一步利用RFE筛选重要指标。本文使用三折交叉验证确定重要指标个数,2种集成算法的最佳特征个数与交叉验证正确分类分值见图2。在n=6时,2种方法的分类正确率均在85%以上。计算前6个特征的重要度发现,2种方法的筛选结果均包括最大速度、速度标准差、最小垂向加速度、最小纵向加速度,重合率66.7%。不同的是,SVC-RFE中平均纵向加速度排名最高,分值为4.979,RF-RFE最大速度排名最高,分值为0.086 7,见表6。结合图2,本文选择排序正确分值较高的RF-RFE排序结果作为最终结果。最大速度作为驾驶过程中速度的极限值,较加速度等瞬时指标而言,更能反映驾驶员驾驶过程中的心理状态,利用最大速度划分不同风格的驾驶人群更为合理。
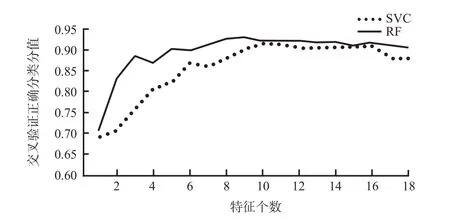
图2 特征个数与交叉验证正确分类分值Fig.2 The Number of Features and The Correct Classification Score of Cross Validation
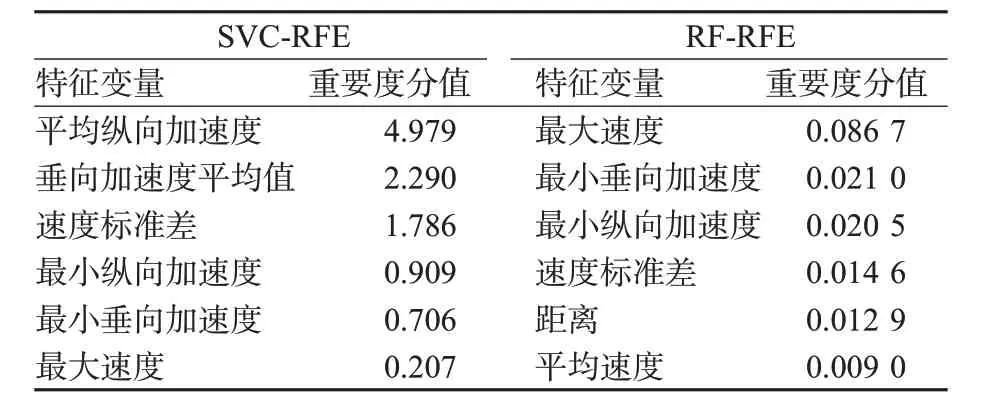
表6 SVC-RFE与RF-RFE排名前6的特征及重要性分值Tab.6 Top 6 characteristics and importance scores of SVC-RFE and RF-RFE
随后,研究分别选取RF-RFE中排名最高的最大速度和排名最低的平均速度,进一步验证不同驾驶风格驾驶员的差异。由图3可知,58名激进型驾驶员的最大速度平均可达29.40 m/s,与平静型、一般型驾驶员的平均最大速度差值可达10 m/s;由图4可知,58名激进驾驶员的平均速度约16.82 m/s,与平静、一般型驾驶风格的驾驶员相差较小。结合表6和图3的观察结果,本文使用最大速度作为神经网络驾驶风格识别模型的输入变量。同时,综合分析表2、表4与图3、表6可知,作为驾驶样本划分输入的6个主成分主要反映了加速度等指标,而忽视了最大速度,因此无监督学习算法的驾驶样本划分结果会存在一定误差。

图3 最大速度区间Fig.3 Maximum speed interval diagram
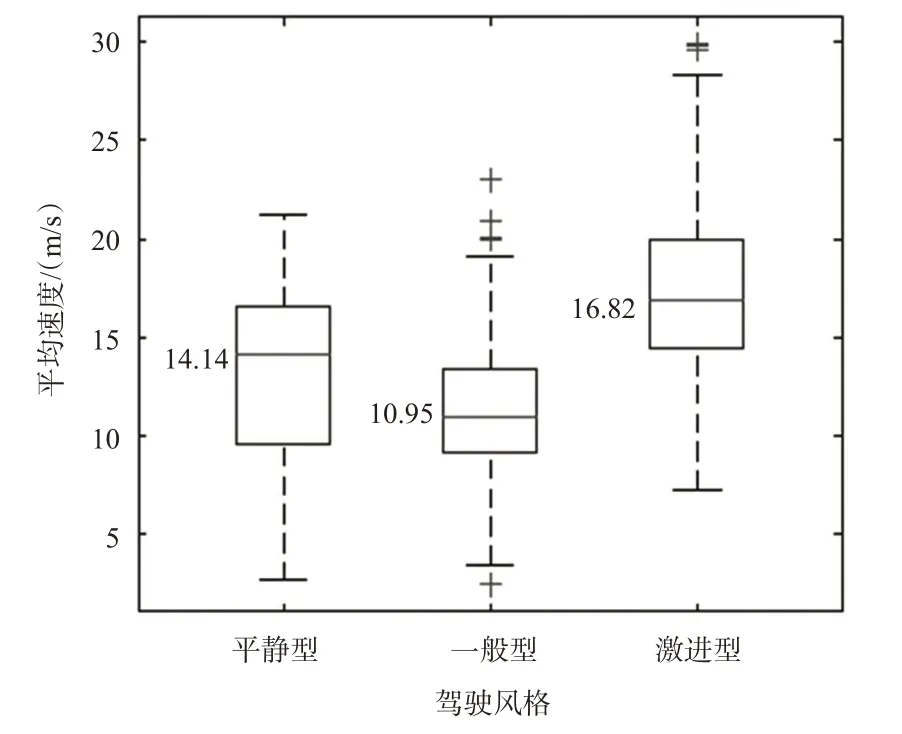
图4 平均速度区间Fig.4 Average speed interval diagram
3.2 驾驶风格识别模型
基于上述结果,本文利用神经网络搭建驾驶风格识别模型验证所选指标的合理性。神经网络识别具有客观性强,处理大数据大样本能力强、可自学习的特点,被广泛用于驾驶风格识别[20]。随机选取242个驾驶样本中的170个样本进行神经网络训练,剩余72个样本(平静型样本30个,一般型样本33个,激进型样本9个)用来验证模型识别精度。将242个样本的最大速度作为神经网络输入,以242个样本的分类结果Y(平静型[1,0,0],一般型[0,1,0],激进型[0,0,1])作为神经网络模型的输出,隐含层层数设置为10,训练函数为trainscg。该模型的权重为W,偏移量为b,隐含层传递函数为sigmoid,输出层传递函数为softmax。图5为72组测试样本的分类结果,如目标分类为1的样本中有25个被正确识别为1,有5个被识别为2,正确率为83.3%。整体测试结果表明,仅使用最大速度作为驾驶风格识别模型输入,识别精度可达86.1%。
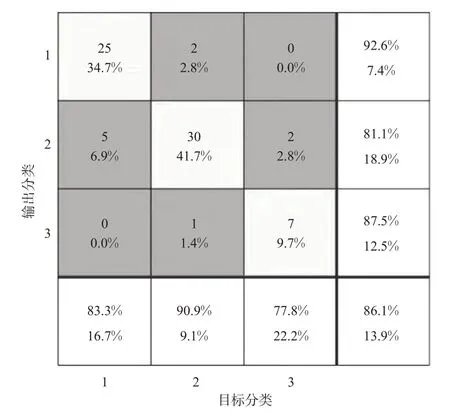
图5 测试样本测试结果Fig.5 Test sample test results
4 结束语
本文基于车联网自然驾驶实验数据,建立驾驶行为量化指标集,结合无监督聚类学习算法完成驾驶风格样本标定,利用特征递归算法得到驾驶风格重要指标,搭建驾驶风格识别模型验证指标有效性。结论如下:①主成分分析与指标筛选结果对比,主成分进行驾驶风格样本划分会忽略最大速度的影响;②利用轮廓系数法评价K-means与K-means++算法聚类效果,K-means++聚类效果更优;③以支持向量机与随机森林为底层迭代模型,构建SVC-RFE与RF-RFE模型筛选驾驶风格指标,当特征个数n=6时,SVC-RFE与RF-RFE的排序正确率均高于85%,RF-RFE的正确率可达90%。最大速度排名最高,在3种驾驶风格群体中差值可达10 m/s;④搭建神经网络模型进一步验证最大速度作为特征指标的有效性,结果显示,仅使用最大速度进行驾驶风格识别精度可达86.1%。综上,在本研究中最大速度更能有效反映驾驶员行驶过程中的过激行为,是区分驾驶风格的最有效指标。
后续研究工作将利用本研究筛选的指标,在驾驶辅助系统中实现危险驾驶行为预警。并且考虑将该驾驶风格识别方法应用于运输企业车辆监管,结合驾驶风格与运输车辆相关多维数据,实现运输车辆风险综合评价,进行差异化、精准和高效监管,提高监管效率和安全水平,降低监管成本。此外,未来的研究将关注道路环境与驾驶风格之间的联系,考虑城市道路、高速公路等不同道路条件下驾驶风格的差异性。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年7期)2022-04-20
汽车实用技术(2022年4期)2022-03-07
中学生数理化·高一版(2021年2期)2021-03-19
活力(2019年22期)2019-03-16
领导决策信息(2018年16期)2018-09-27
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
