
基于Class Balanced Loss修正交叉熵的非均衡样本信用风险评价模型
2022-04-07 01:24石宝峰董轶哲
系统管理学报 2022年2期
杨 莲 ,石宝峰 ,董轶哲
(1.西北农林科技大学 经济管理学院,陕西 杨凌 712100;2.西北农林科技大学 信用大数据应用研究中心,陕西 杨凌 712100;3.爱丁堡大学商学院,英国 爱丁堡EH8 9JS)
信用评价是金融机构划分客户信用等级、贷款决策和风险管理的重要依据。对贷款客户信用风险的准确度量,不仅可以最大限度降低金融机构的违约风险和贷款损失,还可有效缓解客户“贷款难”的现状[1-3]。评价模型作为风险测度的一种有效工具,对金融机构识别信用风险,避免因信息不对称导致的信用风险误判、信贷资金错贷意义重大[4]。为此,已有学者利用数理统计[5-8]、机器学习模型[9-11]对客户信用风险识别问题展开研究。但在实践中,由于信贷数据大部分非违约、少部分违约的不均衡分布特性,致使传统以分类准确率为优化目标的信用评价模型,存在对“多类”非违约样本识别过度、“少类”违约样本识别不足的现状。
为缓解这一问题,学者们试图从非均衡数据采样和非均衡分类算法两方面进行优化处理。在数据采样方面,现有文献主要通过欠采样[12-13]和过采样[14-15]两种方法实现。金旭等[16]将有监督学习和无监督学习相结合,提出了一种基于质心的ICIKMDS欠采样方法,用于解决数据不均衡问题,实证表明,ICIKMDS 有效提升了分类器在测试集中的分类准确率。肖连杰等[13]利用模糊C-均值算法对多类样本进行聚类欠采样,将所有聚类中心样本与少类样本结合、形成均衡数据集,然后利用集成学习算法对均衡数据集进行分类,取得了较好的分类效果。欠采样通过去除一些“多类”非违约样本,使剩余的“多类”非违约和“少类”违约样本数目达到均衡,但容易丢失原始样本中的有价值信息[16]。为弥补这一缺陷,有学者提出利用过采样方法来解决这一问题。衣柏衡等[17]通过对传统的SMOTE 算法进行改进,使SMOTE 聚焦于被评价模型错分的样本、利用错分样本合成新违约样本,实证结果表明,与传统SMOTE 算法相比,改进的SMOTE 算法降低了样本不均衡对评价模型分类性能的影响。张忠良等[18]采用基于高斯过程的SMOTE 过采样技术来增加训练样本的多样性,提高分类器的分类性能。上述基于数据采样的样本均衡方法虽然提高了数据集的均衡性,但在一定程度上改变了原始数据的分布特征[19]。因此,一些学者试图在不改变原始数据分布特征的前提下,采用非均衡分类算法来解决信用评价中的数据不均衡问题。
在非均衡分类算法方面,现有文献主要通过成本敏感学习[20-22]和集成学习[23-25]两类方法实现。张卫国等[26]将双边误差测量方法引入模糊近似支持向量机,通过对正负两类样本的训练误差赋予不同权重,以此减缓因数据不均衡造成的分类误差,实证表明了所提出的模型比Logit回归、BP神经网络和支持向量机有更好的分类效果,能有效提高违约样本分类的准确率。Zhang等[27]将变量离散化和成本敏感Logit模型相结合,以降低评价模型在不均衡数据集中的偏差,实证结果表明,相比传统Logit模型,成本敏感Logit模型在提升信用评价准确度、降低第二类错误方面都有所改善。与单一分类模型相比,多个分类模型的组合可以产生更好的分类效果,因此,有学者通过集成模型来解决非均衡数据中的样本分类问题[28]。夏利宇等[29]利用迭代欠采样方法提升模型对违约客户的关注度,并采用集成方法将弱分类模型转变为强分类模型,以降低样本不均衡对评价结果的影响。此外,也有学者将成本敏感学习与集成学习相结合,以提升对非均衡数据的预测精度。Xiao等[30]通过将集成学习与成本敏感学习进行结合,提出了一种非均衡数据的动态分类器集成方法(DCEID)。对于每个测试客户,DCEID 可以自适应地从动态分类选择方法(DCS)和动态集成选择方法(DES)中选择更合适的方法,实证结果表明,DCEID 的分类性能不仅优于加权随机森林和改进的平衡随机森林等静态集成方法,而且优于现有的DCS和DES策略。上述基于传统机器学习的分类模型,通常由冗余指标剔除、显著性指标筛选、分类模型建立等多个模块组成,每个模块都是一个独立的任务,其结果的好坏会直接影响下一模块,进而影响整个分类模型的预测效果。与传统机器学习不同,深度学习模型通过将冗余指标剔除、显著性指标筛选、分类模型建立等模块进行统一,构建端到端的学习算法,有效缓解了传统机器学习模型因模块之间相互独立而对最终分类结果造成的不利影响[31]。因此,基于深度学习模型的上述优势,一些学者将深度学习用于信用评价模型的构建。赵雪峰等[32]通过将自然语言处理技术与卷积神经网络(CNN)相结合,构建了个人贷款信用评价WVCNN 深度学习模型,实证结果表明,相比较传统的BP神经网络和SVM,WV-CNN 的预测精度更高、鲁棒性更好。
上述解决信用评价样本非均衡问题方法的不足主要体现在两个方面:一方面,现实中由于违约(或非违约)样本之间的内在相似性,使得评价模型从这些样本中学到的信息重复,而重复学习对评价模型违约预测性能的提升有限。由于不均衡数据中“多类”非违约样本在数量上的绝对优势,样本相似问题在非违约样本中发生的概率更大,因而提升模型对不均衡样本预测性能的关键是利用违约、非违约样本中的有效样本对模型进行训练[33]。然而,现有基于深度学习的信用评价模型并未充分考虑到这一点。另一方面,现有深度学习信用评价模型的目标函数通常为交叉熵,而交叉熵没有将违约、非违约样本对目标损失的贡献度进行区分。在实践中,由于非违约客户在样本总数上占有绝对优势,如果不对两类样本损失的贡献度进行区分,会导致非违约样本造成的损失在目标损失中占比过高、主导模型优化方向,从而不利于违约样本有效识别的问题出现。
针对上述问题,本文将图像识别领域中的类平衡损失Class Balanced Loss函数引入信用风险评价,通过测算违约、非违约样本的有效样本数,进而在交叉熵函数中引入与有效样本数成反比的权重项来调整违约、非违约样本损失对目标损失的贡献度,构建Class Balanced Loss修正交叉熵的非均衡样本信用风险评价模型。利用中国某微型金融机构1 534个农户小额贷款数据和UCI公开的1 000个德国信贷数据进行实证,结果表明,本文所建模型具有良好的违约预测性能。
1 信用风险评价建模原理
1.1 信用风险评价相关概念界定
全样本空间。设X违约={xi|yi=1,i=1,2,…,n}(或X非违约={xi|yi=0,i=1,2,…,m})表示由贷款数据中所有违约(或非违约)客户构成的集合,则称X违约(或X非违约)为违约(或非违约)样本的全样本空间。
本文假定任意违约(或非违约)样本都与其全样本空间中某个邻域相关联,而不是以点的形式孤立存在于全样本空间中;每个违约(或非违约)样本是其全样本空间的一个子集,每个违约(或非违约)样本体积为1,并且可能与其他违约(或非违约)样本重叠。需要说明的是,本文关注的是同类样本的重叠,未考虑违约样本和非违约样本之间的重叠。
违约客户有效样本数量。由于违约客户之间的内在相似性,任何一个违约样本都有可能与其他违约样本重叠,故对所有违约样本进行不放回采样,以对违约样本的全样本空间X违约实现无重叠覆盖,采样结果记为S违约,则S违约中样本的期望体积即为违约客户的有效样本数量。
非违约客户有效样本数量。由于非违约客户之间的内在相似性,任何一个非违约样本都有可能与其他非违约样本重叠,故对所有非违约样本进行不放回采样,以对非违约样本的全样本空间X非违约实现无重叠覆盖,采样结果记为S非违约,则S非违约中样本的期望体积即为非违约客户的有效样本数量。
1.2 科学问题的难点
难点1贷款数据中违约样本远少于非违约样本,致使非违约样本主导模型优化方向、评价模型难以识别违约样本,然而,对违约样本的准确判别才是商业银行风险管控的焦点。如何在不改变样本原有数据结构的情形下,降低不均衡样本对评价模型性能的影响,提升模型对违约样本的识别力是本文需要解决的第1个难点。
难点2贷款数据违约、非违约样本中的有效样本对评价模型构建及模型预测性能起着关键作用,如何测度违约、非违约样本的有效样本数,并在此基础上构建信用评价模型,提升评价模型对违约样本的学习能力,是本文面临的第2个难点。
1.3 突破难点的思路
(1)通过在交叉熵函数中引入平衡因子ω,对违约、非违约样本造成的损失进行重新加权,增大违约样本损失在目标损失中的权重、减小非违约样本损失在目标损失中的权重,使评价模型侧重于对违约样本的学习,提升模型对违约样本的识别能力,缓解评价模型因非违约样本在数量上的占比优势而主导模型优化方向、不利于违约样本识别的问题。解决难点1。
(2)受随机覆盖思想[34]启发,对所有违约(或非违约)样本进行不放回采样,利用采样样本对违约(或非违约)样本的全样本空间X违约(或X非违约)进行无重叠覆盖,则采样结果中样本的期望体积即为违约(或非违约)贷款客户的有效样本数。解决难点2。下面以违约客户为例,说明其有效样本的测算过程。
设贷款数据中违约样本集为A,先前采样的违约样本集为PA。为简化问题,假设新采样的违约样本xi以两种方式与PA进行交互:一是出现在PA中,二是出现在PA外部,不考虑部分重叠的情况。
首先,任取集合A中未经采样的违约样本xi。其次,判断xi是否与先前采样的违约样本集PA中已有样本重叠。若未重叠,则将xi添加到样本集PA中,并更新PA的期望体积为:E(PA)=E(PA)+1;若重叠,则PA与E(PA)保持不变。最后,对违约样本集A中其余未经采样的样本重复上述步骤。此时,更新后的样本集PA的期望体积E(PA),即为贷款数据违约样本集A的有效样本数。违约客户有效样本测算原理如图1所示。
2 信用风险评价模型构建
2.1 指标数据标准化处理
由于不同类型信用评价指标单位量纲的差异,为避免人为打分的主观误差影响,需要对原始指标数据进行标准化处理[35]。常见的定量指标有正向指标、负向指标和区间指标3类。
(1)正向指标数据标准化。正向指标数值越大,表明样本的信用状况越好,如“总资产、月可支配收入”等指标。设为第i个客户第j个指标标准化后的值是第i个客户第j个指标的原始数据,则
(2)负向指标数据标准化。负向指标数值越小,表明样本的信用状况越好,如“总负债、资产负债率”等指标,则
(3)区间指标标准化。区间指标是取值在某一个特定区间内,信用情况是最佳的指标。例如,客户信用风险评价“年龄”的最佳区间为[31,45],它表示年龄位于该区间的借贷客户还款能力和还款意愿最强。设q1为最佳区间的左端点,q2为最佳区间的右端点,则
式(3)中其余字母含义同式(1)。
2.2 基于BPNN-Class Balanced Cross Entropy的非均衡样本信用风险评价模型构建
与传统机器学习算法不同,深度学习是一种将冗余指标剔除、显著性指标筛选和分类预测等模块进行统一的端到端的学习算法,因此具有更优异的指标提取能力[31]。深度学习采用的模型主要是神经网络,该方法通过使用误差反向传播算法,较好地解决了评价指标的贡献度分配问题,在复杂系统评价和金融风险预测中得到了广泛应用[36-38]。本文将反向传播神经网络(Back Propagation Neural Network,BPNN)应用于信用风险评价,通过在BPNN 交叉熵函数中引入平衡因子ω,利用平衡因子ω客观调节正负样本损失在目标损失中的权重,实现BPNN 模型对不均衡样本中违约样本的深度学习,提升模型对违约样本的预测能力,缓解传统评价模型对不均衡样本适用性不强的缺陷。
基于BPNN 的信用风险评价模型构建可以分为两个阶段,第1阶段为信用风险评价信息的正向传播,贷款数据由输入层进入到BPNN,经隐藏层激活函数逐层处理之后,再由输出层对贷款客户的违约状态进行预测。第2阶段为违约判别误差信息的反向传播,通过计算违约状态预测值与真实值之间的差距,判断该差距是否在模型的预设精度以内。若不在,则将误差反向逐层向前传递,利用梯度下降法调整各网络层权重与偏置以减小误差,直至模型输出的违约预测误差满足模型的精度要求。BPNN信用风险评价示意如图2所示。
2.2.1 信用风险评价信息的正向传播 以图2中3层BPNN 为例,说明信用风险评价信息正向传播过程。设S1为第1层隐藏层的输出,S2为第2层隐藏层的输出,f1为第1层隐藏层的激活函数,f2为第2层隐藏层的激活函数,W1为输入层至第1层隐藏层的权重矩阵,W2为第1层至第2层隐藏层的权重矩阵,xi=为客户i评价指标向量,θ1为输入层至第1层隐藏层的偏置,θ2为第1层至第2层隐藏层的偏置,W1xi+θ1为第1层隐藏层的输入,W2S1+θ2为第2层隐藏层的输入,则第i个贷款客户的信用评价信息正向传播过程可由第1、2层隐藏层神经元的输入输出关系表示:
设为客户i的违约状态预测值∈[0,1],h为输出层违约状态判别函数,W3为第2层隐藏层至输出层的权重矩阵,θ3为第2层隐藏层至输出层的偏置,则违约状态预测值为
式(6)的经济学含义:式(6)刻画了3层BPNN对贷款客户i的违约预测结果。预测值表示评价模型预测客户i属于违约样本的概率,取违约判别阈值为0.5[38],若违约状态预测值<0.5,则将客户i判别为非违约客户;反之,则判别为违约客户。
2.2.2 违约预测误差反向传播测算 利用式(6)求得的客户违约状态预测值与违约状态真实值yi,求解模型预测误差值G(yi)。若G(yi)>模型预设精度,则进入反向传播过程。误差反向传播的核心是对各层网络权重和偏置进行不断修正,若修正后的权重和偏置可以使模型的违约预测误差值G(yi,)≤模型预设精度,则修正完成。不失一般性,本文以第l层隐藏层为例,说明误差反向传播修正权重和偏置的过程。
设dl=Wl Sl-1+θl为第l层隐藏层的输入,(dl)为第l层隐藏层输入对该层输出的影响程度,Wl为第l-1层至第l层隐藏层的权重矩阵,则G(yi,)对第l层隐藏层权重Wl与偏置θl的偏导数为:
式中,tl=(dl)·((Wl+1)Ttl+1)为第l层隐藏层输入dl对误差值G(yi,)的影响程度,也反映了G(yi,)对第l层隐藏层输入dl的敏感程度。
式(7)~(8)的统计学含义:两式分别为预测误差G(yi,)对网络权重Wl和偏置θl的一阶偏导,用于表示权重矩阵Wl和偏置θl对误差值G(yi,)的影响程度,也反映了G(yi,)对权重矩阵Wl和偏置θl变化的敏感性。∂G(yi,)/∂Wl越大,说明G(yi,)对Wl的变化越敏感,Wl的微小变动即可引起误差值G(yi,)的较大波动,此时的Wl不利于客户i违约状态判别;反之,则Wl有利于客户i违约状态判别。因此,可以通过调整Wl来降低Wl对G(yi,)影响,从而使得评价模型的违约预测误差G(yi,)满足预设精度要求。式(8)同理,不再赘述。
式(7)~(8)的经济学意义:利用梯度下降调节隐藏层神经元的网络权重Wl和偏置θl,降低贷款客户i的违约预测误差G(yi,),实现对BPNN 信用评级信息正向传播违约预测性能的反向调优。
2.2.3 Class Balanced Loss修正交叉熵的非均衡样本信用风险评价模型构建 由于实际中的信贷数据存在大部分非违约、少部分违约的数据不均衡现象,致使传统以交叉熵为目标损失函数G(yi,)的BPNN 模型在面对不均衡样本时,极易出现对“多类”非违约样本识别过度、对“少类”违约样本识别不足的问题。为此,本文将交叉熵替换为引入平衡因子ω的类平衡交叉熵(Class Balanced Cross Entropy,CBCE)函数,以提升BPNN 模型对不均衡样本中违约样本的识别力、改善BPNN 模型对不均衡样本的适用性。
(1)交叉熵函数。设yi为真实违约状态为其预测值,交叉熵函数为[39]
式(9)的经济学意义:该式表示评价模型对贷款客户i违约预测的损失值(也称为误差值)。评价模型会根据样本的预测损失值进行参数反向调优,以提升模型违约预测性能。以一个违约客户和一个非违约客户为例:①当客户为违约客户(yi=1)时,不妨取0.2。由于预测值0.2小于阈值0.5,模型将违约客户判别为非违约客户、判别错误,此时Cross Entropy=-log0.2=0.699,即评价模型对违约客户i进行预测产生的损失为0.699。②当客户为非违约客户(yi=0)时,不妨取0.8。由于0.8大于阈值0.5,模型将非违约客户i误判为违约客户、判别错误,此时Cross Entropy=-log(1-0.8)=0.699,即评价模型对非违约客户i进行预测产生的损失为0.699。进一步,可求得上述两个样本(1个违约样本、1个非违约样本)的交叉熵权重(违约样本权重=×100=50%,非违约样本权重=×100=50%),如表1第2、3行最后1列所示。
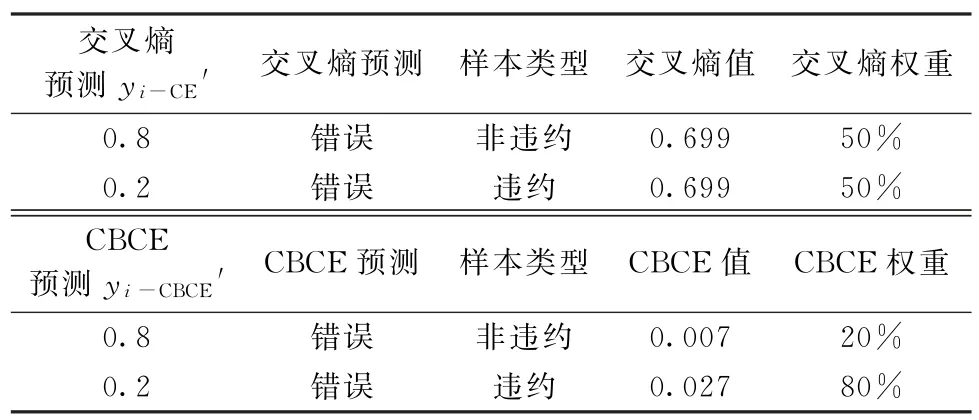
表1 交叉熵(CE)与Class Balanced交叉熵(CBCE)对违约客户识别对比
需要说明的是:①对评价模型优化起主导作用的是预测错误的样本,故本文主要以误判样本为例解释公式的经济学意义。②对于预测错误的违约、非违约样本,评价模型会重点学习在目标损失中占比较大的一类样本,为此,本文通过计算样本损失权重来反映这一点。
不难发现,利用式(9)计算出的2个样本的损失占总目标损失的比例是一致的(50%=50%),即式(9)所示的交叉熵函数并没有将违约、非违约样本对目标损失交叉熵函数的贡献度进行区分。实践中由于非违约客户在样本总数上占有绝对优势,如果不对两类样本损失的贡献度进行区分,会导致非违约样本造成的损失在目标损失中占比过高,从而主导BPNN 模型优化方向、不利于违约样本有效判别的问题出现。为此,下文将探讨如何修正交叉熵函数,提升模型对违约样本的识别力。
(2)引入平衡因子ω的CBCE函数。为了弥补上述不足,本文引入含有平衡因子项ω的CBCE 函数。与交叉熵相比,CBCE函数通过测算违约、非违约样本有效样本数En和Em,构造平衡因子项ωn和ωm,进而利用ωn和ωm对违约、非违约样本损失进行重新加权,增大违约样本损失在目标损失中的权重、减少非违约样本损失在目标损失中的权重,使评价模型侧重于对违约样本的学习。改善BPNN 模型因样本不均衡导致的对非违约样本学习过度、对违约样本学习不足的现状。为方便理解,首先介绍违约、非违约客户有效样本数En和Em的测算原理,然后介绍违约、非违约客户平衡因子ωn和ωm的构造过程,最后给出CBCE的实现原理。
①测算违约、非违约客户有效样本数En和Em。以违约客户为例,通过命题形式给出违约客户有效样本数En的测算及证明过程。
命题1设n为贷款数据中违约客户总数,En为n个违约客户对应的有效样本的期望体积,N为违约样本全样本空间X违约的期望体积(N为En的上限),β=(N-1)/N∈[0,1)为超参数,用于刻画样本的重叠程度(β越趋向于0,表示样本之间重叠程度越大,其中,β=0表示所有样本全部重叠;反之,β越趋向于1,表示样本之间重叠程度越小),则n个违约客户的有效样本数为
证明通过数学归纳法对命题1进行证明。
(i)当n=1时,表示贷款数据中只有一个违约样本,此时1个客户的有效样本数为1,故E1=(1-β1)/(1-β)=1成立。
(ii)假设当n=n-1时,
成立。式(11)表示已经采样了n-1个违约样本,且n-1个样本的有效样本数为
(iii)当n=n时,求解n个违约客户的有效样本数En。对第n个违约样本xn进行采样,为简化问题,假设新采样的数据xn以两种方式与前n-1个样本进行交互:一是以概率p出现在前n-1个样本中,此时n个违约样本的期望体积En=En-1;二是以概率1-p出现在前n-1个样本外部,此时n个违约样本的期望体积En=En-1+1,不考虑部分重叠的情况[33]。由假设条件N为En的上限可知p=En-1/N,因此,n个违约客户的有效样本数为
进一步,将式(11)代入式(12),可得
由命题1不难看出,可以通过调整参数β的取值来调整违约(或非违约)贷款客户之间的重叠程度,进而实现对不同重叠程度下贷款客户有效样本数的测算。具体地:(a)违约客户有效样本数En随着β的增大而增大,即β越大、违约样本之间重叠程度越小、有效样本数En越大。例如,当β=0.99,0.999[33],n=40时,由式(10)计算可得:
比较可知E40(β=0.999)-E40(β=0.99)=5.9>0,故En随着参数β的增大而增大。(b)随着违约客户数量n的增加,β越大、有效样本数En增长越快。例如,当n=40,50,β=0.999时,
当n=40,50,β=0.99时,
比较可知
从而β越大,随着违约客户数量n的增加,En增长越快。
需要说明的是:(a)实践中,贷款数据通常呈现高维特性,致使无法事先确定其重叠程度。本文利用参数β对现实中贷款客户之间的重叠程度进行刻画,通过改变参数β的取值来调整样本的重叠程度、找到适合贷款数据的最佳β,进而实现在最佳参数β下有效样本数的测算。(b)本文与Cui等[33]的区别在于,Cui等的研究对象为图像数据,而本文的研究对象为客户贷款数据。虽然Cui等较好地解决了图像识别中的样本不均衡问题,但是贷款数据与图像数据具有本质上的区别(例如,图像数据是三维而贷款数据是二维),无法直接将其应用于不均衡贷款客户的信用风险预测中。从而研究如何将适用于非均衡图像数据分类模型的使用边界进行拓展,可为解决不均衡信用风险评价客户分类提供新的思路。
②构造违约、非违约客户平衡因子ωn、ωm。利用①中测算出的违约、非违约客户有效样本数En和Em,构造违约、非违约样本平衡因子分别为:
式(14)~(15)的统计学含义:式(14)中平衡因子ωn用于调整违约样本造成的损失对目标损失的贡献度。由于β∈[0,1),式(14)中ωn与违约客户数n成反比,即违约客户数n越少、违约样本平衡因子ωn越大,从而违约样本对目标损失的贡献度越大。式(15)同理,不再赘述。
式(14)~(15)的经济学含义:违约样本数n远小于非违约样本数m,因此,违约样本平衡因子ωn要远大于非违约样本平衡因子ωm,从而可以分别通过ωn、ωm来增大违约样本损失占目标损失的权重、减小非违约样本损失占目标损失的权重,以提升评价模型对违约样本的学习力度与识别能力。
③CBCE函数。利用②中得到的违约、非违约客户平衡因子ωn和ωm,构造CBCE函数:
式(16)的经济学意义:该式表示评价模型对贷款客户i违约预测的损失值,利用平衡因子ωn和ωm修正后的CBCE 可以提升评价模型对违约样本学习力度与识别能力。以一个违约客户和一个非违约客户为例:(i)对于违约客户i(yi=1),不妨取违约客户数n=30,β=0.99=0.2。由于0.2小于阈值0.5,模型将客户i误判为非违约客户,此时,
即将违约客户i误判所造成的损失为0.027。(ii)对于非违约客户i(yi=0),不妨取非违约客户数m=300,β=0.99=0.8。由于0.8大于阈值0.5,模型将非违约客户i误判为违约客户,此时,
即将非违约客户i误判所造成的损失为0.007。进一步,可得上述两个样本的CBCE 权重(违约样本权重=×100=80%,非违约样本权重=×100=20%),见表1第5、6行最后1列所示。
不难发现,对于示例两个样本中的非违约样本,而对于违约样本,
由此可见,引入平衡因子后的CBCE 函数,可以通过增大违约样本损失占目标损失的权重(80%>50%)来提升模型对违约样本的关注度、学习力度与识别能力。
2.3 信用风险评价模型实现流程
2.3.1 建模步骤
步骤1原始数据预处理。
依据2.1节指标数据标准化处理方法对原始数据进行指标标准化处理,以避免不同指标的量纲差异对评价模型违约判别性能造成影响。
步骤2标准化数据训练集和测试集的划分。
将标准化数据按9∶1比例分为训练集和测试集,训练集用于评价模型的构建,测试集用于评价模型违约预测性能的检验。
步骤3模型参数预设。
参考相关文献[33,40-41],结合商业银行信用风险实务专家建议,从增强模型学习能力、避免过拟合等方面,选取模型的预设参数。参数定义、作用及取值范围如表2所示。
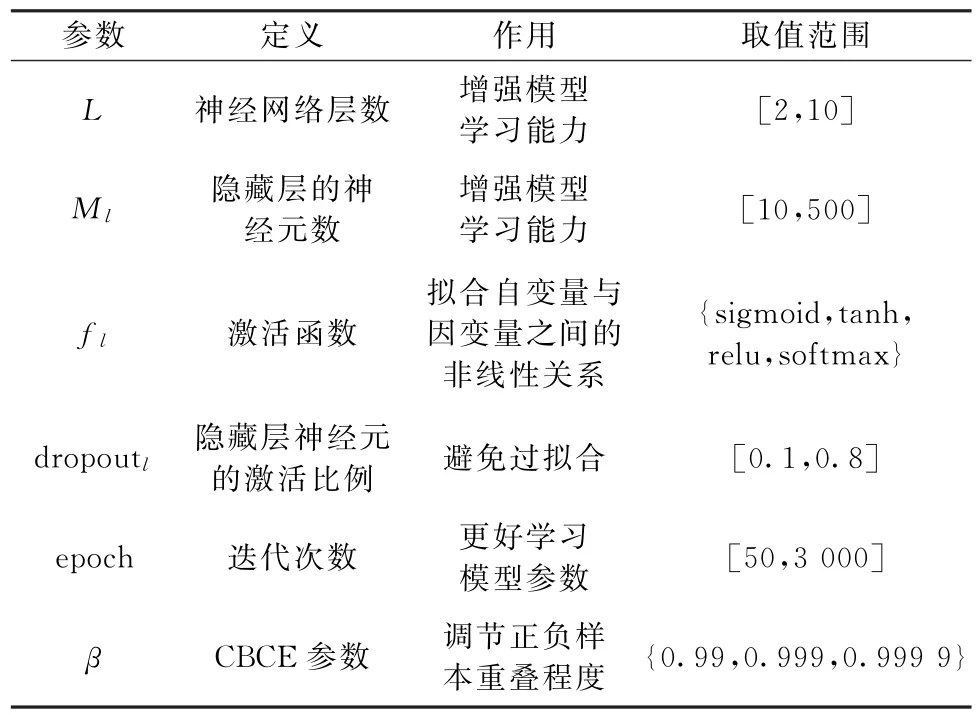
表2 预设参数设置
步骤4构建评价模型。
利用训练样本对BPNN-CBCE模型的网络参数进行学习,得到使模型结构化风险最小的网络参数,在此基础上构建BPNN-CBCE信用风险评价模型。
步骤5计算评价指标。
将测试样本代入步骤4 构建的BPNN-CBCE信用风险评价模型,可得测试集客户的违约状态预测结果。将违约状态预测结果同客户真实违约状态进行对比,得到模型的预测精度。BPNN-CBCE 信用风险评价建模流程如图3所示。
2.3.2 模型评价标准 对模型判别精度的评价是为了检验模型的有效性,基于贷款数据的非均衡特点,使用准确率Accuracy、AUC 和违约召回率Default recall等3个标准进行综合判定。
设TP为客户的真实状态为非违约,且被判别为非违约;FN为客户的真实状态为非违约,且被判别为违约;TN为客户的真实状态为违约,且被判别为违约;FP为客户的真实状态为违约,且被判别为非违约。则
当样本不均衡时,评价模型通过将大多数样本划分为非违约样本,提升模型判别的准确率,但这会导致模型无法有效识别违约客户。因此,当样本不均衡时,准确率对模型预测性能的判别可能失效[1]。与准确率不同的是,AUC 同时考虑了模型对于违约客户和非违约客户的判别能力,避免了样本不均衡带来的模型评价准则失效的问题。AUC被定义为ROC 曲线下的面积,因此,可以通过制作模型的ROC曲线图得到AUC值。首先,计算模型的TPR(True Positive Rate)和FPR(False Positive Rate),分别为:
其次,以TPR为横坐标、FPR为纵坐标,绘制模型的ROC曲线图,AUC就是曲线下的面积。AUC值越大,模型违约判别能力越强[42],即
式(20)的经济学含义:式(20)可用于衡量评价模型对违约样本的识别力。等式右边分子TN表示违约客户被正确判别为违约的个数,分母TN+FP表示样本中包含的违约客户总数。因此,违约召回率Default recall是指将违约客户正确判别为违约的比例,该值越大,说明模型对违约客户的判别精度越高。
3 实证分析
3.1 信用评价指标的海选
以农户小额贷款信用风险评价为例,说明海选指标集的构建过程。通过参考标普、穆迪、惠誉、中国农业银行[43]、中国邮政储蓄银行[44]、中和农信[45]等国内外典型机构信用评价指标体系,结合国内外经典文献,以及通过调研访谈等方式,建立了贷款人基本情况、贷款人家庭特征、贷款人财务信息和外部宏观条件4个农户信用评价准则层,如表3第(b)列所示。海选出教育程度、贷款目的、劳动力占比和人均地区生产总值等33个农户信用风险评价指标,如表3第(c)列所示。
3.2 样本选取和数据来源
本文研究数据源自中国某微型金融机构农户小额贷款数据[44],该金融机构是一家专注服务农村小微客户的助农机构,致力于打通普惠金融最后100 m、将服务送达末端用户。截至到2020 年底,该金融机构已在全国设立了370 余家分支机构,覆盖了10万多个村庄。选取农户贷款数据进行实证分析的原因是:农户贷款具有业务量大、额度小、风险分散、财务数据不健全以及样本非均衡等特点与难点,使得商业银行等金融机构对农户的信用风险评估更具难度与挑战性。合理评价农户的信用风险,不仅有利于改善农户融资难、贷款难的现状,还可以促进农村金融发展和增加就业。因此,选取农户贷款数据进行实证研究具有较强实际意义。
数据集包含1 416个非违约农户和118个违约农户,样本不均衡比为12∶1。指标原始数据如表3第(1)~(1 534)列前33行所示,农户违约状态标识如表3第34行所示,其中0表示非违约,1表示违约。表4第(1)~(1 534)列前33行是指标的标准化数据,标准化过程见3.3节。
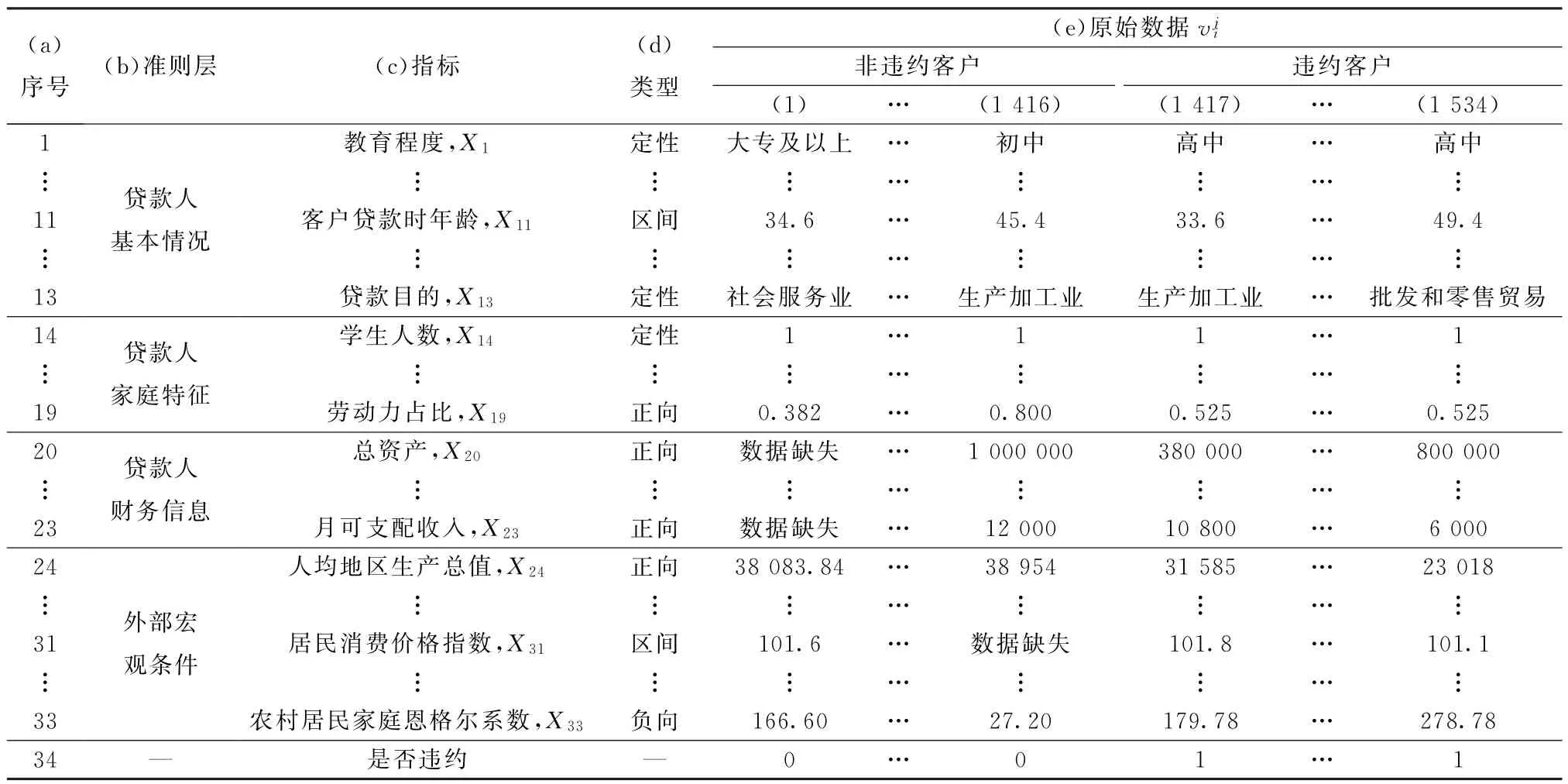
表3 农户信用评价指标及原始数据

表4 农户信用评价标准化数据
3.3 指标数据标准化
3.3.1 定量指标标准化
(1)正向指标数据标准化。根据2.1节正向指标数据标准化原理,计算表3正向指标每一行原始数据的最大值、最小值,并将原始数据、最大值及最小值代入式(1),得到正向指标的标准化值,结果列入表4第(1)~(1 534)列对应行。
(2)负向指标数据标准化。根据2.1节负向指标数据标准化原理,计算表3负向指标每一行原始数据的最大值、最小值,并将原始数据、最大值及最小值代入式(2),得到负向指标的标准化值,结果列入表4第(1)~(1 534)列对应行。
(3)区间指标数据标准化。本文共涉及“客户贷款时年龄”和“居民消费价格指数”两个区间指标。“客户贷款时年龄”的最佳区间为[31,45],“居民消费价格指数”的最佳区间为[101,105][46]。根据2.1节区间指标数据标准化原理,计算“客户贷款时年龄”指标原始数据的最大值、最小值,并将原始数据,q1=31,q2=45,最大值及最小值代入式(3),得到“客户贷款时年龄”指标的标准化值,结果列入表4第(1)~(1 534)列对应行。
同理,计算“居民消费价格指数”指标原始数据的最大值、最小值,并将原始数据,q1=101,q2=105,最大值及最小值代入式(3),得到“居民消费价格指数”指标的标准化值,结果列入表4第(1)~(1 534)列对应行。
3.3.2 定性指标标准化 通过对中国某全国性大型商业银行信贷业务的总行副行长、风险管理部总经理、授信审批部总经理、信贷部总经理等银行实务专家以及业务骨干进行访谈调研,结合大连理工大学、西北农林科技大学、西南财经大学以及东北财经大学11名专家学者,并参考某商业银行农户非财务数据信贷字典,制定出适合农户信用评价的定性指标打分标准,如表5所示。根据表3第(d)列,找到定性指标所在行的农户数据,按照表5打分标准对这些定性指标进行打分,结果列入表4 第(1)~(1 534)列对应行。
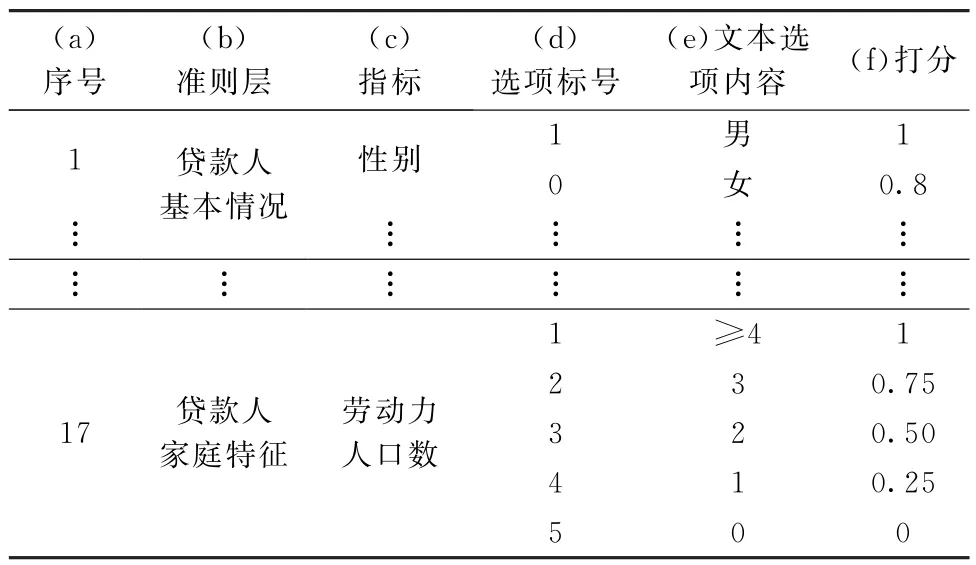
表5 农户定性指标打分标准
3.4 模型参数设置及信用评价结果求解
通过实验调参,选出BPNN-CBCE 的参数设置结果,如表6所示。其中,神经网络层数L=5,第l层隐藏层神经元个数Ml=256,隐藏层激活函数为relu,输出层分类函数为softmax,第l层隐藏层dropoutl为0.2,迭代次数epoch=500,CBCE参数β=0.999。将训练集农户标准化数据、违约状态yi以及表6所示参数代入2.2节BPNN-CBCE模型构建过程,对神经网络各层权重Wl和偏置θl进行估计,可得到基于BPNN-CBCE 的信用评价模型。为验证模型的有效性,需要用测试集样本进行检验。将测试集农户标准化数据、违约状态yi代入构建好的BPNN-CBCE 模型,得到测试集样本的违约概率。以概率值0.5为临界点,当概率值大于0.5时,判定为违约;否则,判定为非违约,如此可以得到测试集样本的违约状态预测值。根据违约状态预测值和违约状态真实值,最终可以得到测试集样本的Accuracy、AUC 和违约召回率Default recall,结果分别列入表7第1行第(4)~(6)列。实验在Windows 10下进行,采用Python 3.7.0进行编程,利用Pytorch 1.5.1深度学习框架搭建模型,使用Intel(R)Core(TM)i5-5200U CPU 运行模型。

表6 BPNN-CBCE模型参数设置结果
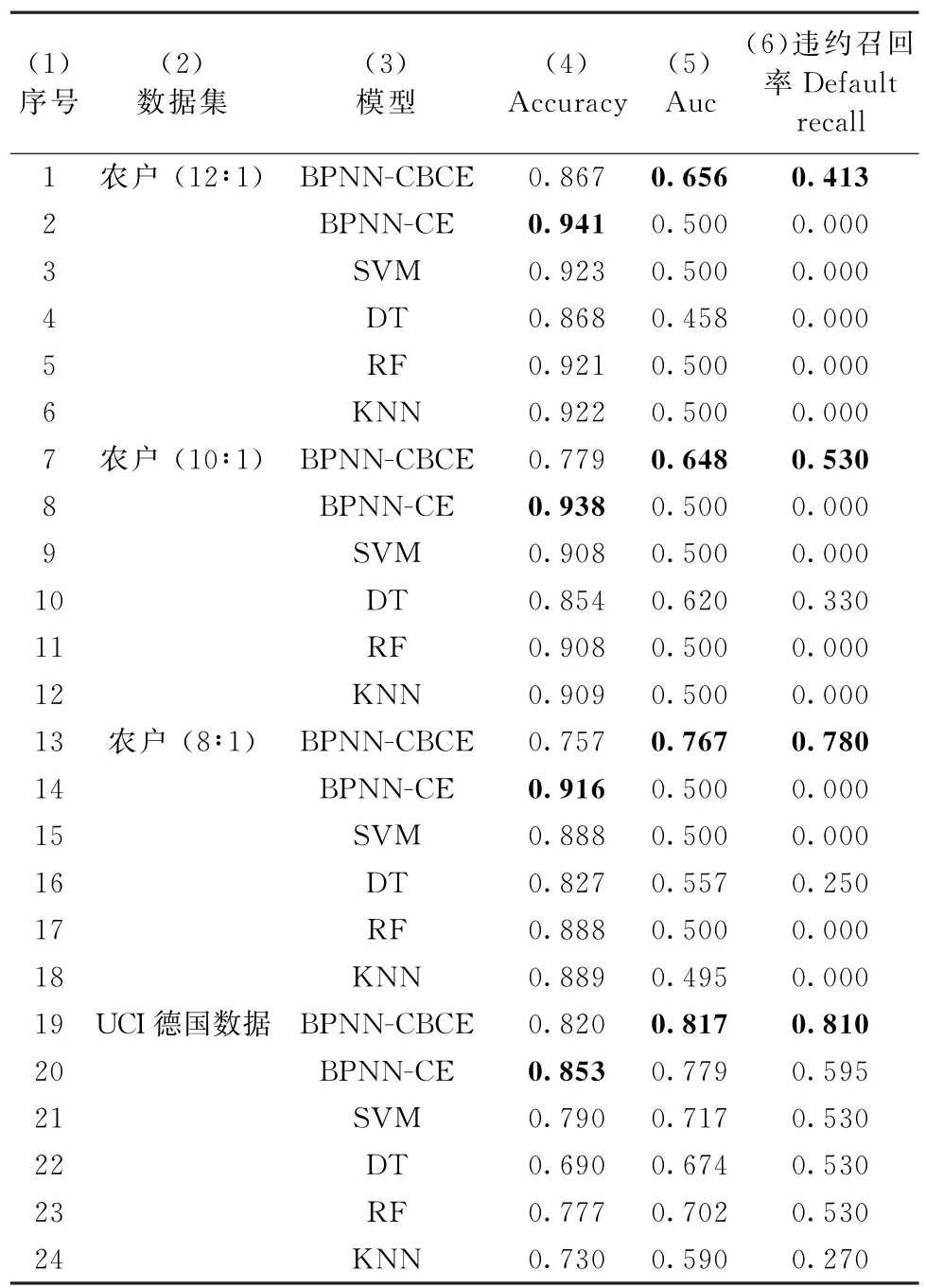
表7 BPNN-CBCE与BPNN-CE、SVM、DT、RF、KNN 方法预测性能对比
3.5 评价结果分析与模型稳健性检验
为评价信用风险测度模型BPNN-CBCE 的判别性能,从如下3个方面进行分析:①利用表4中不均衡比为12∶1的1 534个农户贷款数据,将所建模型与交叉熵神经网络(BPNN-Cross Entropy,BPNN-CE)、支持向量机(Support Vector Machine,SVM)、决策树(Decision Tree,DT)、随机森林(Random Forest,RF)和K最近邻(K-Nearest Neighbor,KNN)5种分类模型进行对比,测算模型的判别性能;②利用简单随机抽样法,从农户数据随机抽取一定数量的非违约客户,分别与118个违约客户组成不均衡比例为10∶1和8∶1的农户数据集,验证BPNN-CBCE对不同不均衡比例数据集的适用性;③将农户数据替换为UCI公开的德国信贷数据集,比较上述6种方法在公开数据集中的分类表现,进一步验证模型的稳健性。德国信贷数据集来自美国加州大学欧文分校(University of California Irvine)提出的用于机器学习的UCI数据库,该数据库所提供的数据均可免费下载与使用。近年来,该数据集被广泛应用于信用风险领域中评价模型的稳健性检验[1,47-48]。选取德国信贷数据集进行稳健性检验,既可方便与现有文献进行对比,同时也可验证本文构建模型对其他非均衡样本的适用性。另外,本文还给出了当CBCE 核心参数β取集合{0.99,0.999,0.999 9}中不同值时,上述数据集对应的BPNN-CBCE 分类结果。用于比较不同β取值对评价模型分类性能的影响,从而找出适合每个数据集的参数β最佳取值。
(1)基于6种方法的1 534个农户贷款数据信用风险评价结果对比。利用训练集农户标准化数据、违约状态yi分别对BPNN-CE、SVM、DT、RF和KNN 等5种分类模型进行训练,并将测试集和yi代入训练好的5种模型,从而得到5种分类模型的Accuracy、AUC 与Default recall,结果列入表7第(2)~(6)行、第(4)~(6)列。
①BPNN-CBCE 模型对农户不均衡数据具有更好的判别能力。由表7第(1)~(6)行及第(4)列可见,BPNN-CE、SVM、DT、RF 和KNN 这5种模型的准确率Accuracy 均高于BPNN-CBCE 模型,进一步分析发现,5种模型通过将大多数样本划分为非违约样本,提升了模型判别的准确率Accuracy;但这5 类模型无法有效识别违约客户。因此,当样本不均衡时,准确率Accuracy对模型的判别失效。与准确率不同的是,AUC同时考虑了模型对于违约客户和非违约客户的判别能力,避免了样本不均衡带来的模型评价准则失效的问题。由表7第(1)~(6)行及第(5)列可见,本文所建立的BPNN-CBCE模型的AUC 值0.656位居6种模型第1,并且相比较其余5种模型中AUC最高的提升了15.6个百分点。因此,BPNN-CBCE对农户数据具有更好的判别能力。
②BPNN-CBCE 模型对农户不均衡数据中违约样本具有更好的识别能力。由式(20)违约召回率Default recall定义可知,分子TN为违约客户被正确判别为违约的个数,分母TN +FP为样本中包含的违约客户总数,违约召回率Default recall是将违约客户正确判别为违约的比例。因此,Default recall值越大,说明模型对违约客户的判别精度越高。由表7第(1)~(6)行及第(6)列Default recall结果可见,BPNN-CBCE 的Default recall 0.413 为6种模型中最高,并且相较于其他5种模型提升了41.3%,从而BPNN-CBCE对农户不均衡数据中违约样本识别更有效。进一步,以BPNN-CE 为例说明其余模型违约召回率Default recall值为0的原因。BPNN-CE评价模型主要是通过对模型参数进行不断修正以减小模型预测误差来达到对模型进行优化的目的,因此,评价模型为了快速达到优化目标,往往会优先对造成误差较大的样本进行学习。由于非违约样本数量在总样本中占有绝对优势,会使非违约样本的误差占据总误差中大部分,从而评价模型会优先对非违约样本进行学习。而对数量较多的非违约样本的充分学习会使评价模型的准确率得到快速提升,提前实现优化目标。这会导致评价模型几乎没有从违约样本中学到有价值的信息。由于学到的有用信息少,也就不难解释评价模型违约召回率Default recall值为0的原因。
需要说明的是,针对传统信用风险预测模型存在对非违约样本识别过度、对违约样本识别不足的问题,CBCE函数通过对违约、非违约样本损失对总损失贡献度进行调整,提升了对违约样本的召回率Default recall。但同时也会因非违约样本损失占总损失权重的降低而使评价模型从非违约样本中学到的信息没有原来那么多,从而对非违约样本的识别造成一定的影响。然而,对于金融机构而言,将违约样本误判为非违约样本要远比将非违约样本误判为违约样本造成的损失大,所以金融机构更加关注对违约样本的准确识别[49]。因此,相对于BPNNCBCE 在非违约样本识别力的轻微降低,其对违约样本的识别力的提升对于金融机构而言更有价值。
(2)基于不同不均衡比例数据(10∶1,8∶1)的模型稳健性检验。表8展示了10∶1,8∶1农户数据集的基本信息,其中10∶1数据集1 298个贷款农户中包含1 180个非违约客户、118个违约客户;8∶1数据集1 062个贷款农户中包含944个非违约客户、118个违约客户。分别将1 298和1 062个农户标准化数据按9∶1比例分为训练集和测试集,并参考3.4、3.5 节(1)部分得到两个数据集对应的BPNNCBCE、BPNN-CE、SVM、DT、RF和KNN 等6种分类模型的Accuracy、AUC 与Default recall,结果列入表7第(7)~(18)行以及第(4)~(6)列。
对于10∶1农户数据集:①BPNN-CBCE模型的AUC值为0.648,均高于BPNN-CE、SVM、DT、RF和KNN 模型对应的AUC 值;②BPNN-CBCE 的违约召回率Default recall为0.530,均高于其余5种模型,并且相较于其他5种模型中违约召回率最高的DT 提升了20%。对于8∶1农户数据集:①BPNN-CBCE 模型的AUC 值为0.767,相比较其余5 种模型中AUC 最高的DT 提升了21%;②BPNN-CBCE的Default recall为0.780,相比较其他5 种模型中违约召回率最高的DT 提升了53%。综上所述,对于不同不均衡比例农户数据集,BPNN-CBCE模型的违约判别性能均优于其余5种对比模型。
(3)基于UCI德国公开数据的模型稳健性检验。表8最后一行为UCI德国数据集的基本信息,1 000个贷款客户包含700个非违约、300个违约客户,样本不均衡比为2.3∶1。将德国信贷数据按9∶1比例分为训练集和测试集,利用训练集分别对BPNN-CBCE、BPNN-CE、SVM、DT、RF 和KNN等6种分类模型进行训练,并将测试集代入训练好的6种模型,从而得到6种模型的Accuracy、AUC与Default recall,结果列入表7第(19)~(24)行以及第(4)~(6)列。不难看出,BPNN-CBCE 模型的AUC 值(0.817)和违约召回率Default recall(0.810)均优于其余5 种方法。为进一步验证BPNN-CBCE模型的稳健性,将表7德国数据集对应的BPNN-CBCE 实证结果同现有文献进行了比较,发现:①与Kuppili等[47]德国数据集的评价结果相比,本文所提出的模型在Accuracy(0.820>0.759)上得到了提升;②与Sen等[48]德国数据集的评价结果相比,本文所提出的模型在Accuracy(0.820>0.807)方面得到了改进。
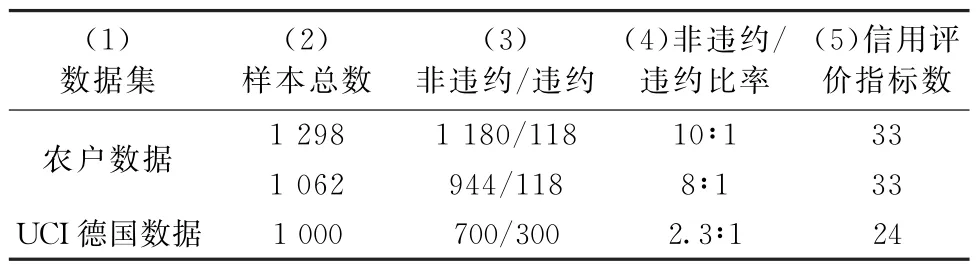
表8 数据基本信息
(4)参数β不同取值下的模型分类结果分析。为验证参数β的不同取值对BPNN-CBCE评价模型性能的影响,从而选取每个数据集适用的参数β取值,将表6 中的参数β替换为集合{0.99,0.999,0.999 9}中的值,分别进行实证分析。参考3.4、3.5节(1)部分,得到不同参数β取值下4个数据集对应的6 种分类模型的Accuracy、AUC 与Default recall,结果列入表9 第(1)~(12)行以及第(4)~(6)列。
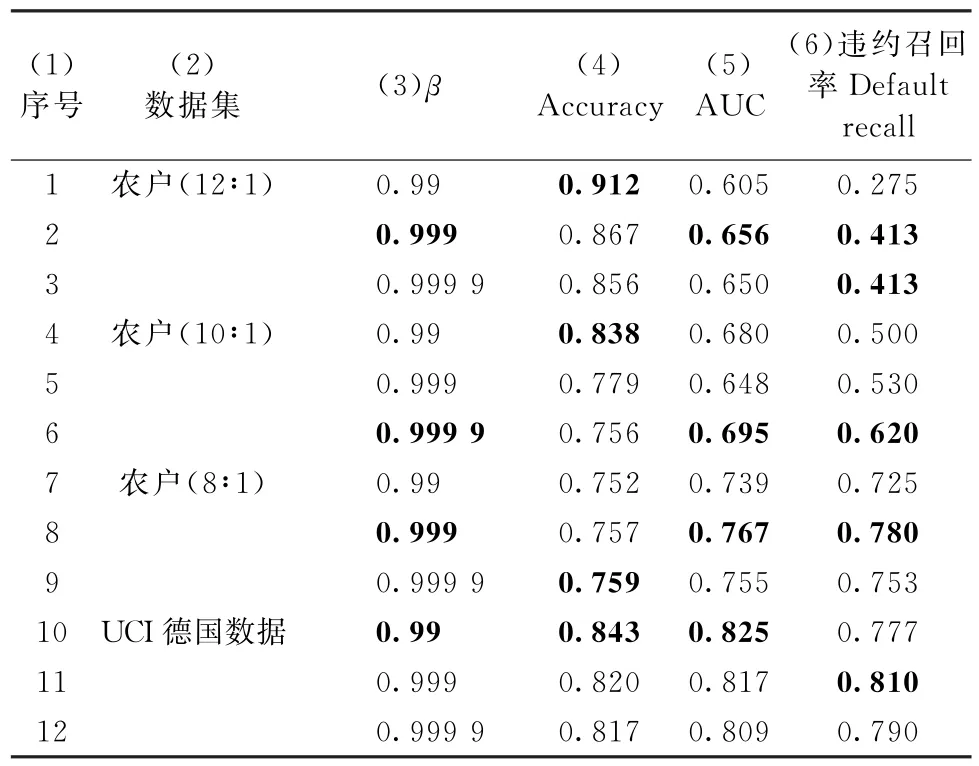
表9 参数β 不同取值下BPNN-CBCE模型的敏感性分析
由表9可以看出:不同数据集对应的最优参数β取值不同。对于12∶1农户数据,当β=0.999时,BPNN-CBCE 对应的AUC、违约召回率Default recall(0.656、0.413)分别为3种β取值对应结果中最高;对于10∶1农户数据,当β=0.999 9时,模型判别效果最佳;对于8∶1农户数据,当β=0.999时,判别效果最优;对于德国数据集,当β=0.99 时,BPNN-CBCE 对应的 Accuracy、AUC (0.843、0.825)分别为3种β取值下最高。因此,数据集不同,参数β的最佳取值也不同。实证中需根据不同数据集特点,选取适用的参数取值。
4 结论
由于将违约客户误判为非违约客户给金融机构造成的损失要远大于将非违约客户误判为违约客户造成的损失,故对违约客户的准确识别一直是金融机构风险管控的焦点。然而,在实践中,由于信用评价违约客户少、非违约客户多的非均衡样本特征,使得金融机构信用评估中极易出现对非违约客户识别过度、对违约客户识别不足的情况。通过测算信贷数据中违约、非违约客户的有效样本数En和Em,构造能调节违约、非违约样本损失在目标损失中权重的平衡因子ωn和ωm,构建BPNN-CBCE 信用风险评价模型。利用中国某金融机构1 534笔农户小额贷款数据和UCI公开的德国信贷数据,实证表明:
(1)BPNN-CBCE对不均衡数据中违约样本具有更好的识别力。对于农户数据,BPNN-CBCE 模型在AUC、违约召回率Default recall方面普遍优于BPNN-CE、SVM、DT、RF 和KNN 等5 种对比模型,其中BPNN-CBCE的Default recall相比较其余5种模型提升了41.3个百分点、AUC 相比较其余5种对比模型提升了15.6个百分点。因此,引入平衡因子ω后的BPNN-CBCE 通过增大违约样本在目标损失中的权重、降低非违约样本在目标损失中的权重,实现了对违约样本的充分学习、提升了对违约样本的识别能力,从而降低了金融机构将违约客户误判造成的损失。
(2)BPNN-CBCE评价模型表现出较好的稳健性。对于不同不均衡比例的农户数据(10∶1、8∶1),BPNN-CBCE评价模型的AUC 值(0.648,0.767)、违约召回率Default recall(0.530,0.780)均高于其余5 种对比模型;对于UCI公开的德国数据集,BPNN-CBCE模型的AUC 值(0.817)、违约召回率Default recall(0.810)也均优于其余5种对比模型。因此,对于不同不均衡比例的信贷数据,BPNNCBCE 模型均表现出了较好的稳健性,可在金融机构信用风险测评中实践应用。
本文主要创新与特色:①利用平衡因子ω,增大违约样本在目标损失中的权重、降低非违约样本在目标损失中的权重,客观调节违约、非违约样本损失在目标损失中权重,克服了由样本不均衡带来的评价模型对非违约样本识别过度、对违约样本的识别不足,弥补了现有评价模型在挖掘贷款客户尤其是违约贷款客户信用评价指标与违约状态之间规律性联系方面的不足,完善了现有信用评价理论体系。②通过考虑数据重叠,利用随机覆盖方法,分别对贷款数据中违约、非违约样本进行不放回采样,以对全样本空间X违约、X非违约进行不重叠覆盖,计算两类贷款客户的有效样本数量。既反映了由于真实数据之间的内在相似性,随着样本数量的增加,新添加的样本很可能是现有样本近似重复的客观事实,也保证了基于有效样本对两类样本损失进行重新加权的客观性。③将图像识别领域中的Class Balanced Loss函数引入信用评价领域,既拓展了Class Balanced Loss的使用边界,也为解决不均衡样本的信用风险评价提供了新的研究思路。
猜你喜欢
化工管理(2022年13期)2022-12-02
电子科技大学学报(2022年4期)2022-07-15
湖南林业科技(2021年3期)2021-12-02
甘蔗糖业(2021年5期)2021-11-21
甘蔗糖业(2021年4期)2021-09-26
现代电子技术(2021年3期)2021-02-02
小天使·二年级语数英综合(2019年10期)2019-11-08
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
