
基于VGG16 网络的人脸情绪识别*
2022-04-28 10:36蔡靖杜佳辰王庆周泓任
电子技术应用 2022年1期
蔡靖,杜佳辰,王庆,周泓任
(吉林大学 仪器科学与电气工程学院,吉林 长春 130026)
0 引言
Hinton 等人在研究深度卷积神经网络中通过引入ReLU 函数以及采用多GPU 训练等方式加快了网络的训练速度并提高了网络模型的准确率[1]。LeCun 等人表明深度学习通过使用反向传播算法来发现大型数据集中的复杂结构,以指示机器应如何更改用于从前一层的表示计算每一层的表示的内部参数。深度卷积网络在处理图像、视频、语音和音频方面取得了突破性进展,而递归网络则为文本和语音等顺序数据带来了光明[2]。随着科学技术,尤其是计算机技术方面的不断进步,人们对卷积神经网络的研究也不断深入,面部表情识别技术也随之得到了发展。同时,一些问题也随之而来,例如:如何提高面部表情分类的准确率,如何能够在保证准确率的前提下减少计算的参数量等。
Tang 等人[3]提出将卷积神经网络(Convolutional Neural Networks,CNN)中融入支持向量机(SVM),同时修改了全连接层中的计算损失值的方法,在表情数据集上的测试结果为71.2%,斩获了当年Kaggle 比赛的一等奖。崔凤焦[4]将卷积神经网络、Adaboost 和支持向量机3 种模型算法结构进行相互比较和设计优化,在Cohn-Kanade表情库中实现了对人脸情绪的智能识别,平均识别率最高达到了74.92%。谢鑫等人[5]采用了耗时加长的杜鹃算法(CuckooSearch,CS)对ResNet50 模型进行了变更改进,提高了准确率并使算法不会在调参时陷入梯度消失或爆炸的问题,准确率达到了74.3%。陈佳等人[6]提出一种基于卷积神经网络集成的表情识别方法,子网结构在第一阶段训练3 个子网络,采用Batch Normalization 方法和Dropout 层来加速网络的收敛。接着去掉3 个子网络的输出层,使用SVM 进行第二阶段的训练,完成最终表情的预测,其准确率达到了70.84%。
针对以上人脸表情识别准确率较低的问题,本研究提出了一种基于VGG16 模型算法的人脸表情识别方法来对人脸进行识别,并达到较好的准确率。
1 卷积神经网络
卷积神经网络[7]是近些年发展起来,并引起人们广泛重视研究的一种高效的识别算法,主要用于图像目标的识别,它的结构和生物大脑的神经网络比较相似,其是由一系列功能不相同的层级所构成的。卷积神经网络的结构一般主要包括其特有的卷积层、池化层这两部分及全连接层这第三部分。在卷积神经网络中,卷积层与池化层一般情况下都会呈多次交替地出现,因此不同的模型具有不同的层级结构。
1.1 卷积层
卷积层是卷积神经网络的核心,主要功能就是对卷积进行运算,实现特征提取操作。卷积核(Convolutional Kernel)的功能就是对输入矩阵进行加权平均的一种权值定义函数,卷积核在一个特征图上不断地移动,与输入矩阵根据一定的规则相乘及求和便可直接得到其特征[8],可以直接通过一个卷积核实现对一个输入矩阵进行特征提取,这种特征提取方法是由低层次向高级提取[9],这样做可以促使提取得到的特征更真实有效。卷积层可以满足下列公式:

式中,yab为卷积核中的值,zab为输入矩阵的值,xij为经过卷积计算后得到的特征矩阵的值。
通过卷积运算的到的特征值,可以判断输入区域内是否含有所需要的特征。
1.2 池化层
池化层主要处理卷积层输出的维度较大的特征,可以大大减小矩阵的尺寸,方便进行后续处理。池化层可以在减少数据量的同时,避免发生过拟合。池化层将特征分为几个较小的区域,取其最大值或平均值[9],得到的特征维度更小。目前常见的池化方法有:平均池化、最大池化、随机池化、谱池化。
1.3 全连接层
全连接层的作用是将上一层的各个局部特征综合起来,其每个节点都与上一层的节点有连接,它通过权值矩阵组成一个全新的图[9],变成全局特征。全连接层可以将特征矩阵转换为单个的值,因此可以在减小数据量的同时,减小特征位置对分类带来的影响。通过全连接层得到的向量,其中每个值代表样本属于每个类的可能性的大小[8],因此可以通过最后的输出向量,判断样本的类别。
2 基于VGG16 网络的情绪识别系统
2.1 数据集
FER2013 数据集由Pierre Luc carrier 和Aaron Courville通过搜索相关的情感关键词在网络上爬取,这些图像都是经过人工标注的。它分为三部分,其中测试集共有28 708 张表情图片,公有验证集和私有验证集各3 589张,共35 886 张表情图片。每张图片是由大小为48×48像素的灰度图组成,分为7 个类别,分别为快乐、惊讶、悲伤、愤怒、厌恶、恐惧、中性。
原始的数据集并没有直接以图片的形式给出,而是以保存在csv 格式文件中,使用pandas 解析csv 文件,得到jpg 文件并储存到对应文件夹下,然后将数据集分为训练集和测试集。
通过对FER2013 数据集进行重新标签产生的FER-2013PLUS 数据集在模型训练中会有更高的准确率。图1展示了数据集中的几个样本。

图1 解析后的jpg 格式数据集
2.2 VGG16 神经网络模型
VGG16 网络结构[10-12]如图2 和表1 所示,输入分辨率为224×224 的3 通道图像进入卷积层。在结束卷积操作后,由于数据经过非线性函数的映射之后,存在着取值区间向极限饱和区逐渐靠拢的输入分布,通过对所有输入数据的归一化处理,可以使得数据被强制地拉回至方差为1、平均值为0 的标准正态分布。最后再次进入池化层,逐渐忽略局部特征信息。循环4 轮以上操作,在卷积操作全部完成后,人脸特征信息即可进入全连接层,将包含有局部信息的特征图(包括特征图的高、宽、通道数)全部映射到4 096 维度。VGG16 网络结构的卷积层的kernel 大小均为3×3,效果较好,其步长为1,填充方式为“same”填充,与其他填充方式相比,这种填充方法可以使每一次卷积以后得到的卷积结果的尺寸大小不会发生变化。池化层使用的是2×2 大小的池化核,填充方式与卷积层一样也为“same”填充,激励函数为ReLU。
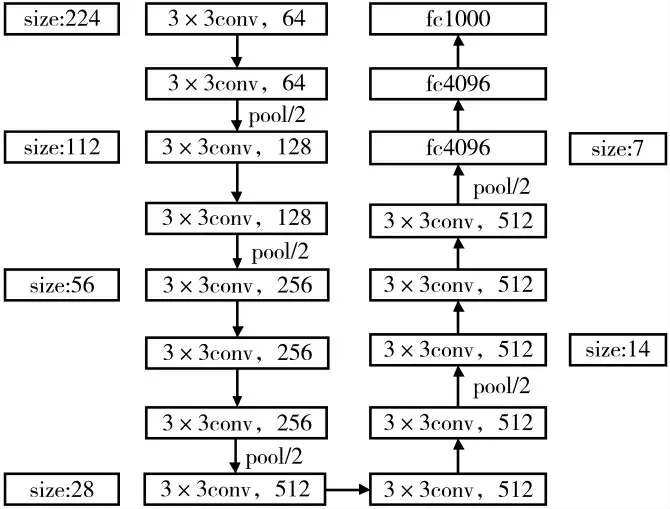
图2 VGG16 网络
2.3 VGG16 神经网络训练过程
输入大小为224×224×3 的图片,经过Conv1_1 和Conv1_2两个卷积层,filter 为3×3,卷积结束后得到222×222×1的矩阵,再经过矩阵填充得到224×224×1 的矩阵。由于第一层有64 个卷积核,原来的224×224×1 就变成了224×224×64。
池化层使用的卷积核是2×2×64,步长为2,第一层卷积结果经过池化后到达第二层,得到的矩阵维数为原来的一半,变成了112×112×128;第二层经过池化层,矩阵维数减半,进入到第三层,由于第三层有256 个卷积核,那么得到56×56×256 的矩阵;同理,第四层有512 个卷积核,得到28×28×512 的矩阵;而第五层也只有512个卷积核,所以得到14×14×512 的矩阵。经过第五次池化最终得到7×7×512 的矩阵,进入到全连接层。
VGG16 的全连接层有3 层。其每一个节点都与上一层每个节点相连接,它可以把前一层的输出特征都整体综合起来。在VGG16 模型结构中,第一层有4 096 个节点,第二层也有4 096 个,第三层只有1 000 个节点,最后再进行softmax 成类别的数目。
如图3 所示,图中显示了图片经过VGG16 各层卷积层和池化层后所提取出的结果,依箭头方向分别为原始图片、第一次卷积后的图片、第一次池化后的图片、第二次卷积后的图片、第二次池化后的图片、第三次卷积后的图片、第三次池化后的图片、第四次卷积后的图片、第四次池化后的图片、第五次卷积后的图片、第五次池化后的图片。

图3 VGG16 训练图
3 实验结果
实验环境为Windows 10 操作系统,采用Python3.7编程语言。实验过程依次是数据预处理、搭建神经网络模型、训练、测试、评估模型。
ResNet50、InceptionResNetV2、InceptionV3、VGG16 模型训练结果分别如表2~表5 所示。表6 为4 种模型的准确率对比,可以看到准确率分别为73%、78%、78%、79%。

表2 ResNet50 模型训练结果

表3 InceptionResNetV2 模型训练结果

表4 InceptionV3 模型训练结果

表5 VGG16 模型训练结果

表6 模型准确率对比
另外,利用VGG16 模型搭建出用于识别人脸情绪的UI 界面,如图4 所示。

图4 UI 结果显示
4 结论
本文采用改进后的FER2013 数据集分别对4 种网络模型进行训练,用于寻找进行人脸表情识别的最佳模型。通过实验结果对比得知,VGG16 模型的准确率相比于其他3 种模型准确率更高。在网络的搭建与训练过程中,发现不同的数据集和网络结构都会对模型的准确率造成影响,后续可以在数据集的预处理以及损失函数的选择等方向上进行研究,以进一步提高人脸识别模型的准确率。
猜你喜欢
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
科技创新与应用(2021年23期)2021-08-30
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
无线互联科技(2020年15期)2020-11-10
科技传播(2020年6期)2020-05-25
计算机技术与发展(2019年1期)2019-01-21
中国交通信息化(2018年5期)2018-08-21
