
融合时间序列与卷积神经网络的网络谣言检测
2022-05-10 08:45汪建梅余晨钰
小型微型计算机系统 2022年5期
汪建梅,彭 云,余晨钰
(江西师范大学 计算机信息工程学院,南昌 330022)
1 引 言
截至2020年6月,我国网民规模达到9.40亿,互联网普及率达67.0%(1)http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/202009/P020200929546215182514.pdf.随着互联网的普及,大多数用户不断从社交媒体获取信息,同时通过社交媒体表达和传播信息.随着在线社交媒体的迅速发展,大量不可靠的谣言信息可能会大量涌现.社交媒体上的谣言信息泛滥,可能使人们难以将可信信息与众多复杂信息区分开,从而影响人们的正常生活秩序,尤其是在突发公共事件(自然灾害,意外事故)下,公共卫生事件,社会保障事件,经济危机等),谣言广泛传播可能极具破坏性.因此,在谣言的早期阶段自动有效地识别网络中的谣言具有重要意义.
谣言检测的主要任务是检测微博帖子的相关事件是否为谣言,不是判断某一条具体微博是否为谣言.现有的谣言检测模型可以大致分为两类:基于传统机器学习的谣言检测和基于深度学习的谣言检测.
基于传统机器学习的谣言识别模型主要是利用了微博文本的符号特征、含有的链接特征、关键词分布特征和时间差等手工制作的特征,在综合用户特征和传播特征,利用SVM分类学习方法对微博进行分类[1-3],然后在此基础提出不同的系统识别框架.V.Qazvinian等[4]通过分析Twitter文本的浅层文本特征、行为特征和元素特征,构建多个贝叶斯分类研究来识别谣言.早期Mendoza等[5]通过分析Twitter谣言传播的结构,得出在出现重大事件时,Twitter更容易传播谣言,并且通过图传播分析传播源的可信性来判断事件的可信度.还有学者通过分析Twitter文本特征、转发率、传播时间点特征计算可信度分数[6,7]与基尼系数(Gini)[8]来识别谣言.Vasu等[9]分别讨论了词袋、n_grams、计数矢量器、TF-IDF这四个基本分类器对谣言识别的效果.也有学者另辟蹊径,提出基于话题[10,11]的谣言检测框架,可以降低谣言在没有转发或人群反应的情况下的互动缺失影响.李明彩等[12]提出最大熵模型,将信息中的词汇作为特征,计算文本的最大熵,得出谣言与非谣言的概率,并将该模型与传统的SVM、BP、Bayes[13]方法比较,得到较好结果.罗嗣卿等[14]、蔡国永等[15]、曾子明等[16]都加入了谣言微博文本的情感特征,并利用LDA主题模型深入挖掘微博文本的主题分布特征,再采用分别采用随机森林、决策树、组合决策树算法进行谣言识别.传统的机器学习方法从单纯的手工制作特征到利用器和集成分类器,虽然所有降低劳动强度,但是仍然不能形成重要特性之间的高层交互.
为了挖掘动态复杂的社交媒体场景中的关键特征,深度神经网络是一个很好的选择.采用循环神经网络GRU[17,18]、LSTM[19]、RNN[20,21]等以及这些基础网络的变体来深层挖掘谣言微博文本以及谣言传播的特征,结果证明基于神经网络的谣言检测方法优于人工构造特征的谣言检测模型.Ma J等[22]同样利用RNN来捕捉帖子的上下文信息随时间的变化.Zhihong Wang等[23]在GRU的基础上添加了情绪词典和动态时间序列特征来优化GRU算法.循环神经网络更加关注时间序列带来的特征影响,并且对卷积神经网络的内部特征关系没有深入的研究.刘政等[24]提出卷积神经网络模型,将微博中的谣言事件向量化,通过卷积神经网络隐含层的学习训练来挖掘表示文本深层的特征,Santhoshkumar等[25]提出一种基于特定因素的卷积神经网络(CNN)方法.采用两个并行的CNN进行谣言事件分类,然后再利用决策树将这两个CNN的输出组合在一起,并提供分类输出.在卷积神经网络的基础上衍生出了基于图卷积神经网络模型[26]的谣言识别方法,将微博谣言数据转换为图数据,再利用卷积神经网络进行训练有标注数据,通过更新图中节点权重,将该信息传递给无标注数据,大大降低了谣言数据标注的工作量.
CNN在谣言识别中取得了很好的结果,但没有考虑到谣言各个生命周期之间的时间序列特征,对现有的卷积神经网络模型进行了改进.
主要贡献如下:
1)提出卷积神经网络(CNN)与时间序列算法进行微博谣言识别;
2)改进卷积神经网络(CNN)与时间序列算法的全连接层分类函数,增强模型泛化能力.
2 相关工作
在自然语言处理方面,卷积神经网络在语句分类[27]、语义分析[28]、实体关系分类[29]、注意力机制[30]等中都取得了很好的效果.在谣言识别方面,刘政提出基于卷积神经网络的模型,利用Doc2Vec[31]将微博帖子向量化,并且将卷积核的大小设为帖子向量的长度,可以有效地提取帖子与帖子之间、帖子内部之间的特征.刘政等的模型大大降低了人工构造特征的劳动强度,并且学习到微博帖子之间的深层特征,但是并没有考虑谣言不同生命周期之间帖子的时间序列特征.Adel等[30]对卷积神经网络识别谣言进行改进,添加不确定检测因素的注意力机制,该模型利用文本的单词向量序列、外部网络环境变化来检测事件的真假.Feng Yu等[32]提出一个用于错误信息和早期发现任务的CAMI模型,收集事件数据集的数据分布,观察假信息和真信息的长尾分布,将微博帖子分组,再利用Doc2Vec得到文本向量表示,作为卷积神经网络的输入.Feng Yu等该模型检测帖子中的真假信息,虽考虑到帖子之间的时间序列特征,但是参数过于庞大,占据太多资源.Dazhen等[33]在考虑内容特征和社交特征的基础上,还考虑了文本单词序列上下文特征,采用LSTM获取内容的双向序列上下文信息,然后将深层序列上下文信息与社会特征结合,用CNN学习内容与社会特征之间的联系.Jing MA等[34]提出DSTS算法,使用时间序列来考虑社会语境特征在谣言传播过程中随时间变化的特征,在利用SVM算法进行谣言识别,但是并没有考虑到微博文本上下文之间或微博文本之间的深层特征.
综合分析,现有的利用卷积神经网络检测网络谣言的模型存在以下问题:
1)卷积神经网络训练模型,模型过于复杂,参数过于庞大,占据过大资源;
2)卷积神经网络并未很好处理谣言生命周期之间的时间序列特征;
3 CNN-TS谣言检测模型
3.1 基本定义
实验的研究对象是微博谣言事件,关注的是微博发布的相关事件是否是谣言,而不是关心与该事件相关的微博帖子是否为谣言.微博事件一旦被检测为谣言,那么传播与该事件相关的帖子也应该被视为谣言.例如,“中美不同的教育方式的结果是:教育进展国际评估组织的调查显示,在21个被调查国家中,中国孩子的计算能力排名第一,想象力排名倒数第一,创造力排名倒数第五.此外,在中国的中小学生中,认为自己有好奇心和想象力的只占4.7%,而希望培养想象力和创造力的只占14.9%.”(2)https://www.sohu.com/a/74593586_101403这条谣言以及相关微博帖子“这种发展趋势很可怕…”“[给力]”“家长、社会、教育专家和行政官员是推手,值得反思,但目前看不到希望,因为大家都跟着感觉走,没有彻底改革的勇气.”等就构成了一个谣言事件,而本文判断的仅是“中美不同的教育方式的结果是:教育进展国际评估组织的调查显示,在21个被调查国家中,中国孩子的计算能力排名第一,想象力排名倒数第一,创造力排名倒数第五.此外,在中国的中小学生中,认为自己有好奇心和想象力的只占4.7%,而希望培养想象力和创造力的只占14.9%.”(3)https://www.sohu.com/a/74593586_101403这个微博事件是否是谣言,而其相关微博帖子是否是谣言并不关心.因此,针对融合时间序列与卷积神经网络模型给出相关的符号解释和定义.
定义1.谣言事件[34].定义所有微博事件集合E={Ei},其中Ei={mi,j},Ei是指第i个事件,包含与其相关的所有微博帖子,mi,j是指第i个事的第j条微博帖子.要达到的目标就是判断Ei,j是否是谣言事件.
3.2 理论基础
3.2.1 Doc2Vec段落向量的构建
一个谣言事件有Ei,j若干条微博帖子mi,j,将每一条微博帖子的文本视为谣言事件的一个段落文本.根据Doc2Vec[31]中对段落文本向量的处理如式(1)所示.
(1)
其中,N是段落文本的词个数,一个单词表示成的单词向量为Wn,单词向量组成的集合是W,gj是一个段落向量,D是所有段落向量组成的集合.
利用Softmax函数对段落中的单词进行概率预测的公式如公式(2)、公式(3)所示.
(2)
xn=h(gj,wn-k,…,wn+k;D,W)
(3)
其中,θ是Softmax函数的参数,h代表着连接函数或者平均函数.
3.2.2 卷积神经网络结构原理
党建武等[35]中描述了卷积神经网络的结构,如图1所示.深度学习能够实现数据的逐层转换,深入提取隐藏特征.

图1 卷积神经网络结构图
CNN对输入数据进行一系列的卷积与池化操作.其中,卷积层是卷积神经网络的核心,卷积层对输入层数据中的每个特征进行局部感知,然后在更高层次上对局部特征进行综合运算,从而得到全局信息.卷积层的计算公式如(4)所示.
F=f(X⊗W+b)
(4)
其中,F为卷积层中多个卷积核的输出特征矩阵,X为输入数据向量,f为非线性激活函数,⊗为卷积操作,W为各个卷积核的权重矩阵,b为各个卷积核的偏置项.非线性激活函数是对卷积层的输出进行非线性映射操作,以增强函数的特定数值性质,ReLU函数通常用于中间层的非线性激活,因为其迭代速度快,Softmax函数一般用于最后一层的激活功能.
池化层是池化卷积层的输出,保留主要特征,压缩数据和参数的数量,减少过度拟合,提高模型的容错性,计算如公式(5)所示.
P=pool(F)
(5)
其中,P表示池化层的特征输出结果,pool表示池化函数,一般分为Max Pooling和Average Pooling.
全连接层是以平滑化后的特征矩阵作为全连通层的输入矩阵,然后以激活函数作为分类函数,输出每个分类标签的概率.
3.2.3 K折交叉验证法
K折交叉验证法是减少过拟合,解决数据量不够多,导致检测效果差的常用操作方法.K折交叉验证就是将给定的数据集均分为K份,经过若干次迭代,第K次迭代取第K折数据作为测试集,另外K-1份数据作为训练集,直到K折中的每折数据都用作测试集.然后将总迭代的测试结果与训练结果的平均值作为最后的测试与训练结果.K折交叉验证法的结构原理图如图2所示.

图2 K折交叉验证法原理图
3.3 CNN-TS模型结构
3.3.1 CNN-TS模型流程图
提出的谣言检测的流程图如图3所示.首先获取微博中的事件数据,其中包含谣言数据与非谣言数据,将其随机打乱,保证训练集、验证集和测试集的数据分布都是相同的;其次,将每个事件数据作为一个整体,并对与之相关的每个微博帖子进行文本向量化.然后将该事件数据的文本向量按对应的时间序列进行排序,均分为20组;最后将这20组向量作为输入矩阵,进行卷积神经网络模型的训练.
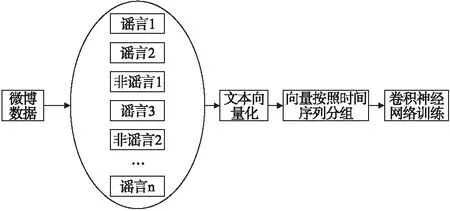
图3 微博谣言检测流程图
3.3.2 微博帖子的时间序列分组
一个有影响力的微博事件的帖子数量至少有几百条,甚至达到几万条,不同事件的帖子数量差异大.但是谣言事件的生存周期分为潜伏期、滋生期、蔓延期、消退期,在这4个时间段内和4个时间段之间的微博帖子文本特征具有相似的特征及变化趋势.因此将这些按照时间序列排好的相邻帖子视为一个组,代表事件的一个特定生命周期.这样做的考虑是:更多关注各个时间段内的微博帖子内容的特征关系,并且可以提取出各个时间段之间的微博文本的特征,而不是单独一条微博帖子之间的特征关系.一个微博谣言事件的发展在各个时间段内的帖子内容会有差异,而且这样做能够大大减少模型输入数据的复杂度.帖子的时间序列分割参考MA等[34]中的操作.
对于一个事件Ei,其帖子的起始时间为time_Begini,帖子的结束时间为time_Endi,将每条微博mi,j的时间ti,j转换为0到N之间内的时间戳,N是时间间隔数,在本文中N取20.那么对于事件Ei的帖子时间间隔time_Intervali和每一条帖子的时间戳数的time_Stampmi,j计算公式如公式(6)和公式(7)所示.
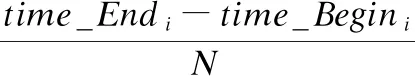
(6)

(7)
然后收集所有相关微博帖子的时间戳,并从每个事件的所有时间戳中减去相应事件的开始时间戳.然后将这些时间戳规范化为0-1尺度.最后将整个时间戳按时间顺序平均分割为20个份额,每个时间窗口内的帖子表示为如式(8)所示.
Ti=[time_Stampmi,j-1,time_Stampmi,j),j=1,2,3,…,20
(8)
然后将分组后的帖子Ti利用Doc2Vect文本向量化,作为输入矩阵传入卷积神经网络训练.第i个微博谣言事件的相关帖子分组后,得到的向量矩阵的表示如式(9)所示.
V(Ei)=(Fi,1,Fi,2,…,Fi,20)
(9)
其中,Ei是第i个谣言事件,Fi,20是分组后的20个特征向量.
向量按时间序列分组的模型结构如图4所示.

图4 时间序列分组的模型结构图
3.3.3 CNN-TS的卷积神经网络模型
用于卷积神经网络的模型结构如图5所示.

图5 微博谣言的卷积神经网络模型图
其中Fi,j∈Rk,表示谣言事件Ei的第j条微博的文本向量,其维度为k.一个包含n条相关微博的谣言事件的文本向量可以表示为如式(10)所示.
Ei=Fi1⊕Fi2⊕Fi3⊕…⊕Fin
(10)
其中⊕表示串联操作.
卷积层:利用卷积核filterw∈Rh*k对输入向量进行卷积操作得到新的特征向量.例如,第1层隐含层的3个卷积核的操作计算公式如式(11).
(11)

池化层:对卷积后的特征矩阵进行压缩,一方面使特征矩阵变小,一另一方面提取主要特征.本实验采用的是maxpooling,将特征矩阵切成几个区域,取其最大值,保持原有的矩阵特征得出池化后的特征值.
全连接层:将经过多个卷积层与池化层后的特征矩阵作为全连接层的输入矩阵,一般采用Softmax函数作为分类函数进行操作,其输出为每一个分类标签的概率.
卷积核filter的设置是采用刘政等[24]文献中的操作:将filter的宽度等于输入矩阵的宽度.每一行是微博事件的按时间序列分组后的微博帖子向量,这样设置,能够更加关注微博帖子文本之间的特征关系,而不是微博帖子文本内部的词语之间的特征关系.
3.4 模型结构的改进
卷积神经网络对标签的分类方法主要由两部分组成:一个是分数函数,它将原始数据映射到类别分数;另一个是损失函数,它量化了预测分数和实际分数之间的一致性,主要用来表示一个标签的概率.神经网络模型可以通过更新评分函数的参数使损失函数值最小化,达到模型最优的目的.分类函数softmax与SVM的损失函数是不同的,它们的区别如下:
1)softmax函数的损失函数是cross-entropyloss,如式(12)、式(13)所示.
(12)
(13)
其中,fyi是把标签i预测为yi的分数,j是分类结果中的一个,Li是在[0,1]之间的损失.Pyi是数据分类的Softmax值,即分类正确的概率,Softmax值越大,该模型的损失也就越小.
2)SVM函数的损失函数是hinge-loss.分类器输入样本xi后,第j个类别的评分是:
sj=f(xi,W)j
(14)
则对第i个样本的损失为:
(15)
该计算公式只关注正确分数比不正确大Δ的值,在用hinge-loss训练时,需考虑预期的损失函数该有多大.
因此,先用Softmax函数对输入数据进行预训练,得到预期的损失函数值大小,然后再次输入模型,将分类函数Softmax改为SVM,解决模型泛化能力不足的问题.
CNN-TS模型采用的分类函数是Softmax,针对此问题,修改模型中的分类函数Softmax,采用SVM对池化后的特征向量进行最终分类,模型结构图如图6所示.

图6 SVM作为分类函数的CNN-TS改进模型结构图
4 实验与分析
4.1 实验数据
采用的实验数据是Ma等[22]文献中的公开数据集.该数据集中的微博数据是从新浪社区管理中心获得的谣言与非谣言事件,该中心报道了各种不实信息.并通过爬虫捕获了这些事件的原始帖子以及所有相关的转发/回复消息.该数据集的统计情况如表1所示.
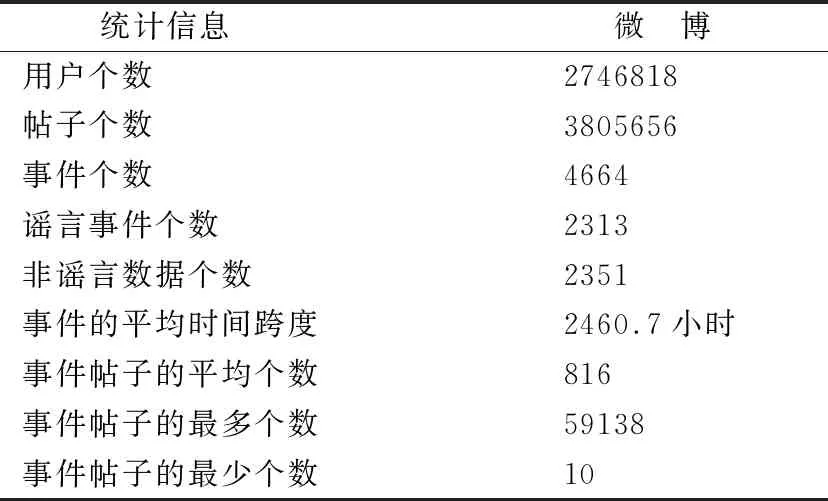
表1 微博数据的详情统计情况表
4.2 数据预处理
收集到的实验数据包含大量噪声,会严重影响谣言识别效果,因此有必要在实验前进行数据噪声处理.
1)去除标点符号.在本实验中,只考虑帖子的文本特征,但某些标点符号,如“!”也可作为一种特征,因此按照“!”“?”优先级保留,其余则需移除.
2)去除表情符号.本实验中只考虑文本的特征,不考虑文本所展现出来的情感特征,因此需要移除表情符号,例如[开心].
3)去除特殊符号.微博帖子包含无关信息,例如超链接和@某某,可以通过正则表达式匹配将其从数据集中删除.
4)分词.微博帖子为短文本,在进行文本处理时,其最小粒度应为词或词语,因此需要进行分词操作.采用的是Python中的jieba分词处理.
5)去停用词.停用词是指不对文本特征有任何贡献的词.它不仅包含标点符号,还包含语气词,人称词和地点词之类的词.但语气词也代表了文本的一种隐含特征,因此本实验不去除语气词.本实验采用的是哈工大停用词表hit_stopwords.
微博文本数据进行噪声处理,可以大大降低文本无关信息的噪声影响,大大增强模型检测效果.
4.3 实验评价指标
准确率(accuracy),精确率(precision),召回率(recall),F1值常被用于评判实验效果,本文同样选取这4个指标.具体的计算方式如下:

(16)
预测正确的样本数是样本数中真谣言的样本预测为真和假谣言的样本预测为假的个数;预测正确的正样本数是预测正确的样本数中预测为真的个数;预测为正的样本数为不论真实标签为真还是为假,都将其预测为真的个数;总样本中的正样本数为总样本中真实标签为真的个数.准确率反映的是检测方法的准确性,召回率反映的是检测方法的覆盖率,这两个指标的数值越大,表明检测方法的整体效果越好.
4.4 实验设置
将提出的模型与刘政等[24],Abhishek等[36]的模型进行了对比.
刘政等[24]的模型:刘政等提出采用卷积神经网络模型进行微博谣言的检测,取得了良好的效果,本文的模型就是卷积神经网络模型的一种改进.
Abhishek等[36]的模型:Abhishek等的模型是利用朴素贝叶斯、随机森林和支持向量机这3种基本的机器学习模型对文本特征、用户特征以及文本与用户组合的特征进行训练、识别.本实验采用Abhishek中的基于RBF核模型的SVM方法,对组合特征进行训练.本文模型对分类函数的改进是利用了RBF核模型的SVM方法.
提出的模型(CNN-TS):时间序列和卷积神经网络模型的融合由卷积层,池化层和两个完全连接层组成.卷积层的宽度与输入数据矩阵的宽度相同.输入矩阵是使用Doc2Vec训练的文本向量矩阵.
超参数设置:超参数的设置是参考刘政等[24]的参数,filter的高度为3,dropout rate为0.5.每一条微博的维度k设为50.
数据集的划分:K折交叉验证方法用于评估模型的预测性能.经过训练的模型对新数据的性能可以在一定程度上减少过度拟合的情况,并可以从有限的数据中获得尽可能多的有效信息,将K设置为10,并多次计算每个评估指标的K折交叉验证平均值.
4.5 实验结果
模型CNN-TS与CNN,SVM-RBF的实验结果比较如表2所示.

表2 模型的实验结果比较图
从表2中可以看出,融合时间序列与卷积神经网络的模型优于基于支持向量机的RBF核模型和普通的卷积神经网络模型,比支持向量机模型准确率提高0.082,精确率提高0.061,F1值提高0.089;比普通的卷积神经网络模型准确率提高0.056,recall提高0.16,F1值提高0.081.因此融合了时间序列的卷积神经网络模型是优于刘政等[24]提出的基本卷积神经网络模型以及Abhishek等[36]运用的支持向量机模型的.
同时对CNN-TS的模型进行改进,将最终的分类函数改为SVM得到改进后的模型,最终的实验结果比支持向量机模型准确率提高0.097,精确率提高0.09,recall值提高0.112,F1值提高0.1;比普通的卷积神经网络模型准确率提高0.071,精确率提高0.016,recall提高0.154,F1值提高0.092;比CNN-TS准确率提高0.015,精确率提高0.029,F1值提高0.013.CNN-TS-SVM模型除了recall略低0.006外,其他准确率、精确率、F1值都高于CNN-TS模型,因此在CNN-TS模型的基础上,修改分类函数,改进后的CNN-TS(SVM)模型是优于CNN-TS模型的.
模型的输入数据矩阵与刘政等[24]的卷积神经网络的输入矩阵的规模对比如表3所示.

表3 模型的输入数据矩阵规模对比表
模型融合了时间序列后,输入矩阵的规模大大减小,大大减少了占用系统内存,减少了训练时间,同时准确率,召回率,F1值都优于刘政等[24]提出的CNN模型.而且迭代步数在100步内就可以收敛,同时不出现过拟合的情况.
5 结 语
提出了融合时间序列与卷积神经网络的谣言检测算法模型,可以大大降低模型的复杂度,减小数据集的规模,又考虑到时间序列上的特征变化.提出的方法是通过将与某一个事件相关的所有微博帖子按时间序列分成若干组,再通过Doc2Vec处理成文本向量,最后作为卷积神经网络的输入进行训练预测.结果显示,它们优于卷积神经网络模型.为了进一步改进,用Softmax分类函数的神经网络模型训练好后,再一次用SVM模型进行最后的分类,结果显示,这种改进优于未改进之前的状态.如何进一步优化神经网络模型,添加谣言文本和图片的特征进行更彻底的实验将是下一个进一步的研究工作.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
环球时报(2022-04-13)2022-04-13
小雪花·小学生快乐作文(2020年4期)2020-10-12
上海师范大学学报·自然科学版(2019年5期)2019-12-13
民生周刊(2017年22期)2017-12-12
新高考·高一数学(2016年10期)2017-07-06
中国新通信(2017年9期)2017-05-27
小雪花·成长指南(2016年11期)2016-12-07
小品文选刊(2009年7期)2009-05-25
