
基于残差网络和注意力机制的红外与可见光图像融合算法
2022-05-18 02:12李国梁向文豪张顺利张博勋
无人系统技术 2022年2期
李国梁,向文豪,张顺利,张博勋
(1.北京交通大学软件学院,北京 100044;2.中国船舶工业系统工程研究院,北京 100036)
1 引 言
无人机因其具有造价低、安全风险系数小和机动性强等优点,在军民领域有着广泛的应用[1-5]。以无人机为载体对目标进行航拍获取目标信息一直是无人系统领域的研究热点和应用热点。无人机航拍可以获得包含目标和复杂背景的红外图像、可见光图像、灰度图像、多光谱图像等。然而在复杂的背景条件下,单一类型的图像成像存在局限。例如,虽然红外图像具有很好的抗干扰能力,能很好地捕获发热目标信息,但其图像缺乏丰富的细节纹理信息,对比度也较差;可见光图像的空间分辨率较高,且具有清晰的细节纹理信息,更易被人眼视觉系统所理解,但其成像过程对外部环境依赖较大,如光照条件差、目标信息被遮挡等都容易造成可见光成像效果变差。对此,研究人员提出了红外与可见光图像融合技术,将两种图像的优点全部呈现在融合图像上[6-8]。深入研究红外与可见光图像融合算法能够用于军事、航空、资源勘探、安防监控等众多领域,具有非常重要的应用与研究价值。
目前,红外与可见光图像融合算法包括基于多尺度变换的方法、基于稀疏表示的方法、基于神经网络的方法等。Toet 等[9]提出了基于对比度金字塔的图像融合算法。Burt 等[10]为解决对比度金字塔融合算法的噪声问题而提出了基于梯度金字塔分解的图像融合算法。此后,还出现了高斯金字塔变换[11]、比例低通金字塔[12]等图像融合方法。然而,金字塔分解不具有方向性,一般融合图像的质量不尽如人意。基于小波变换的融合方法在金字塔变化的基础上进一步继承和发展了多尺度融合的思想。在金字塔变换的基础上,Yan等[13]提出了小波变换。小波变换在频域上对图像进行分解,且具有方向性。在不同的频域上对图像分量进行融合,有助于提升融合图像的视觉效果。不同尺度的方向分量具有的图像特征明显,针对性地进行融合操作能更好地保留图像的结构信息,有助于融合效果的提升。此外,离散小波变换[14]、提升小波变换[15]、多小波变换[16]等都是常见的基于小波变换的图像融合方法。
稀疏表示是一种非常有效的图像表示理论,目前已经成功应用于计算机视觉、模式识别等领域,并取得了良好的效果。与基于多尺度的融合方法不同,基于稀疏表示的融合算法利用图像数据字典对源图像进行稀疏表示,进而实现图像的融合。该类融合算法一般首先将源图像通过滑动窗口策略划分为许多带重叠的图像块,然后基于学习到的完备字典对每个图像块进行系数编码,得到图像的稀疏表示系数;之后根据融合规则融合图像系数,最后利用完备字典对系数进行重构,得到融合图像。近年来,一些学者基于图像表示理论进行图像融合,并取得了一定的研究成果。Yang 等[17]提出了基于稀疏表示的图像融合算法。Li 等[18]提出了基于联合稀疏表示模型的图像融合算法。除此之外,还有基于非负稀疏表示模型[19]、基于自适应稀疏表示模型[20]的图像融合算法等,也取得了较好的融合效果。
近年来,随着深度学习技术的发展,深度学习在图像融合领域得到了广泛的应用。例如,李辉等[21]提出一种深度学习框架,用于图像融合。该算法将源图像分解为基础部分和细节部分,基础部分用加权平均法融合,细节部分内容使用深度学习网络进行多层特征的提取,并以此生成多个候选融合细节内容,然后使用最大选择策略来生成融合的细节内容。最后,将融合后的基础部分与细节内容相结合,重建融合后的图像。Li 等[22]还提出了一种基于稠密网络和自编码器结构的新型融合框架,整个框架分为编码器、融合策略、解码器三部分,编码器部分使用了稠密网络提取并保留图像的深层特征,从而确保使用融合策略融合后图像的显著特征不会丢失,然后基于制定的融合规则对红外和可见光图像的深层特征进行融合,再使用一个包含卷积层的解码器对融合后的图像特征信息进行解码,得到融合图像。Ma等[23]将生成式对抗网络(Generative Adversarial Networks, GAN)用于红外和可见光图像融合任务,生成器的目标是提取源图像中的重要信息,并将这些信息融入到一张图像中,鉴别器判别融合的图像是否具有更多的可见信息,通过二者的对抗训练提升图像融合效果。与现有的融合方法相比,这些基于卷积神经网络或GAN 的融合框架都具有良好的融合性能。
鉴于深度学习技术的优点,本文提出了一种基于残差网络和注意力机制的红外与可见光图像融合算法,分别对源图像的高频细节信息和低频背景信息进行特征提取,然后再使用解码器网络对图像特征信息进行恢复重建,得到融合图像。
2 基于残差网络与注意力机制的图像融合方法
随着深度学习的不断发展,目前已经有部分学者和研究人员尝试使用卷积神经网络进行红外与可见光图像的图像融合,并且取得了较好的效果。采用卷积神经网络进行图像融合的方法大多采用了自编码器结构进行模型训练,在测试阶段再结合设定的融合规则进行图像融合。这类基于自编码网络的图像融合方法能很好地利用现有的大量图像数据集,但网络中的融合规则往往需要人工制定和选择,模型训练时的学习目标也不够直观。因此,本文提出了一种基于残差网络和注意力机制的图像融合算法。
2.1 融合算法网络结构
融合算法的整体框架示意图如图1所示。主要分为图像预处理、图像编码网络、特征融合、图像解码网络几部分。首先利用引导滤波将红外与可见光图像分解为背景层和细节层,之后使用编码网络分别提取背景层和细节层图像的特征信息,使得编码网络可以只专注于提取源图像中高频细节信息或低频背景信息的图像特征,降低了网络提取图像特征的难度,有助于提取更为全面的特征信息。在编码网络中,使用上下文特征提取模块来提取图像的上下文特征信息,提升图像特征提取的效果。之后,将两种图像特征信息进行融合,利用解码网络对图像进行恢复重建。在解码网络中,本文设计了一种注意力特征融合模块,对残差网络单元进行加强,提升了残差单元对特征信息的选择效果。该模块有利于保留重要的图像特征信息,提升图像的恢复重建效果。另外,考虑到红外和可见光图像含有的信息量不同,两者对融合图像产生的影响也不同,因此在损失函数中设计了一种基于梯度信息的自适应权重计算方法,将此权重作为红外和可见光图像的信息保留度,以此来调节不同源图像对融合图像的影响程度。
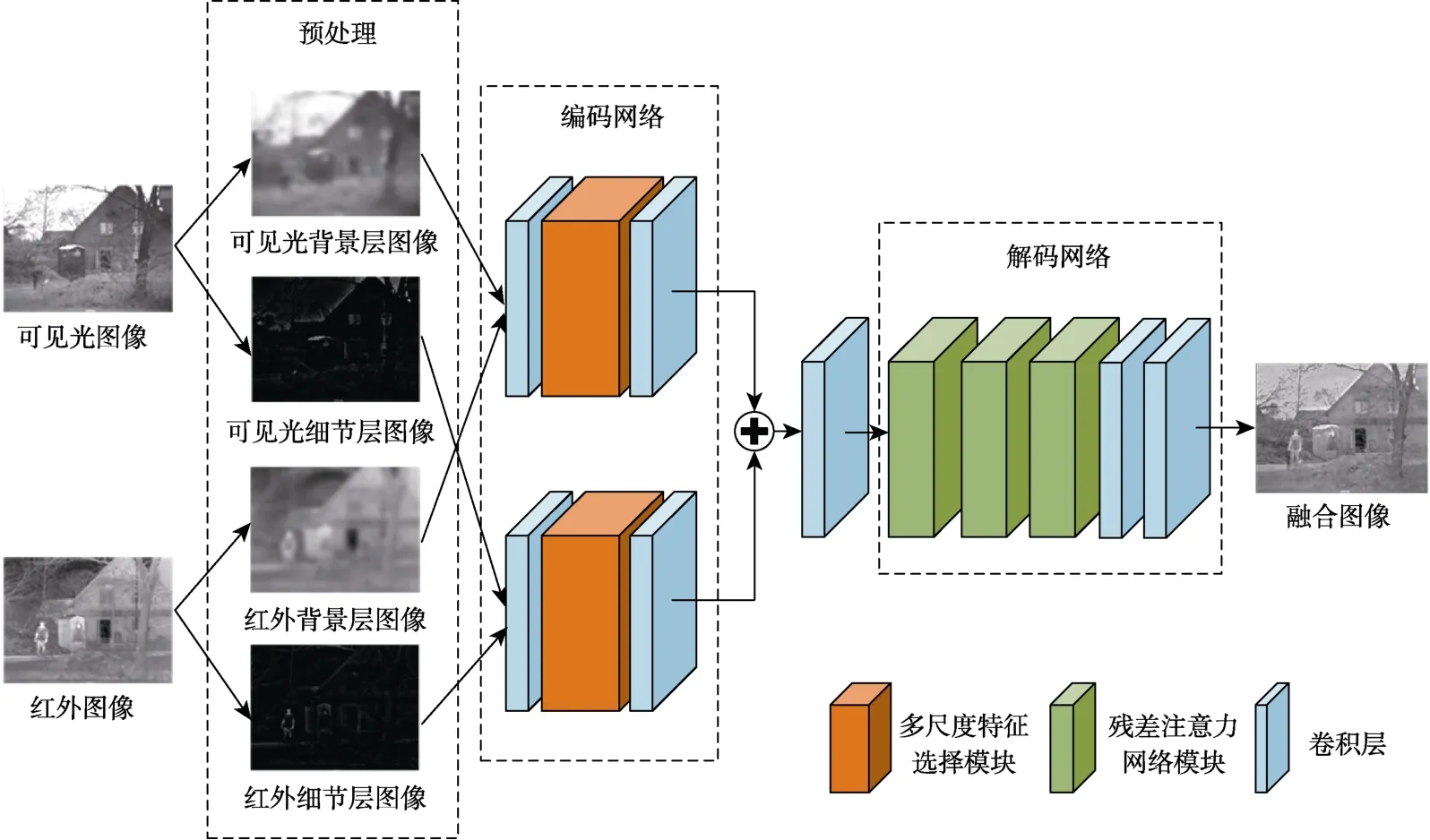
图1 融合算法框架图Fig.1 Image fusion algorithm framework
在网络结构中,使用卷积层后一般紧跟着批归一化操作和激活层。在算法模型中,输出层采用TanH激活函数,并将值映射到[0,1]范围内,从而将图像从特征空间转化为灰度空间;其余卷积层后的激活函数采用ReLU函数,该函数计算复杂度低,可以有效抑制模型训练中的梯度消失问题。
2.2 图像预处理
图像的频域信息反映了图像中像素值的变化,其隐藏着丰富的图像信息。一般认为,图像频域中的高频分量对应图像的细节信息,低频分量对应图像的轮廓信息。因此,不同于其他基于深度学习的图像融合方法将红外图像与可见光图像直接拼接,进行特征提取或者分别进行特征信息提取。本文方法在图像预处理环节使用引导滤波[24]将红外与可见光图像分解为背景层和细节层,背景层对应图像的低频分量,含有图像的背景轮廓信息,细节层中对应图像的高频分量,含有图像的细节纹理信息。引导滤波是一种自适应权重的滤波器,能够在平滑图像的同时起到保持边界的作用。图像I与其背景层Ibase、细节层Idetail之间的关系为:

图像的背景层和细节层包含了图像的全部信息,故在图像分解的过程中不存在图像信息的缺失。通过对图像进行分解,编码网络可以更专注于提取图像的高频特征信息或低频特征信息,减小编码网络提取图像特征的难度,从而提取到更为全面的图像特征信息。
2.3 上下文特征提取模块
为了更好地提取图像的特征信息,设计了一种上下文特征提取模块(Context Feature Refine Block,CFR Block)。该模块可以提取输入信息的上下文特征信息,其结构如图2所示。该模块将神经网络分为三个分支,每个分支中都包括两个卷积层,三个分支分别使用大小为3×3、5×5 和7×7 的卷积核,对应三个分支网络的感受野分别可以达到5、9、13,从而提取到图像的上下文特征信息。同时,为了减少参数个数,该模块将5×5和7×7 卷积核替换为卷积核大小为3×3、扩张尺寸分别为2 和3 的空洞卷积。最后,将三个分支的特征信息进入相加融合,即可得到图像的上下文特征信息。CFR Block 的网络参数如表1所示。
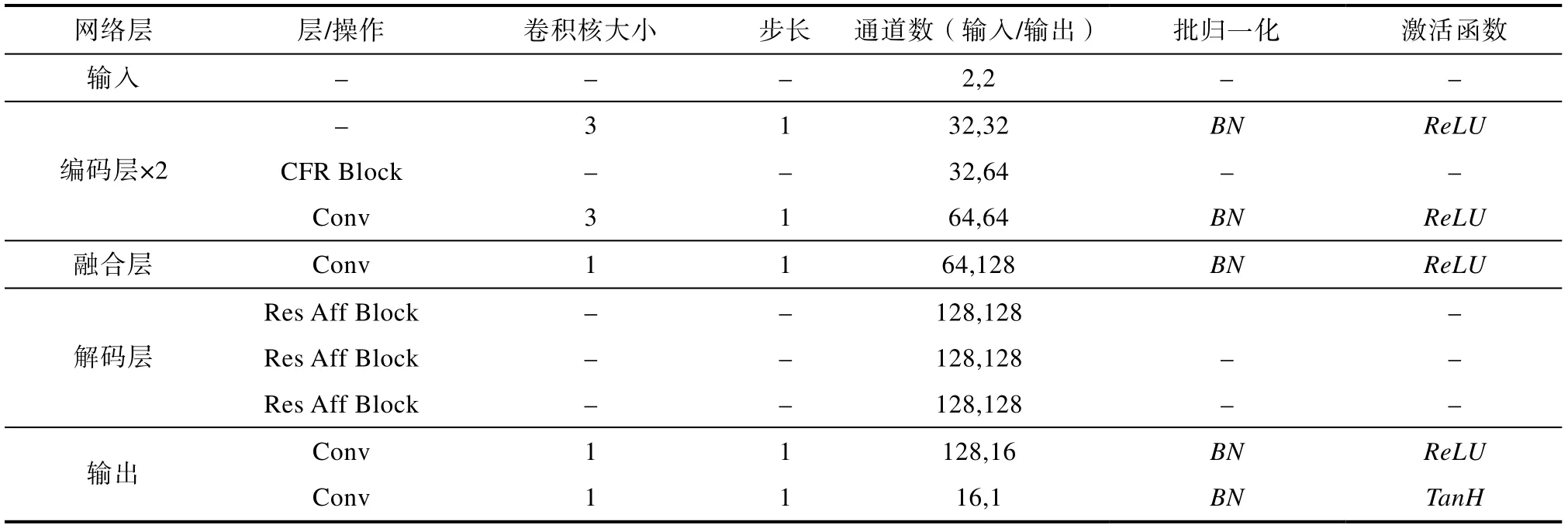
表1 图像融合网络参数信息Table 1 Parameters of image fusion network
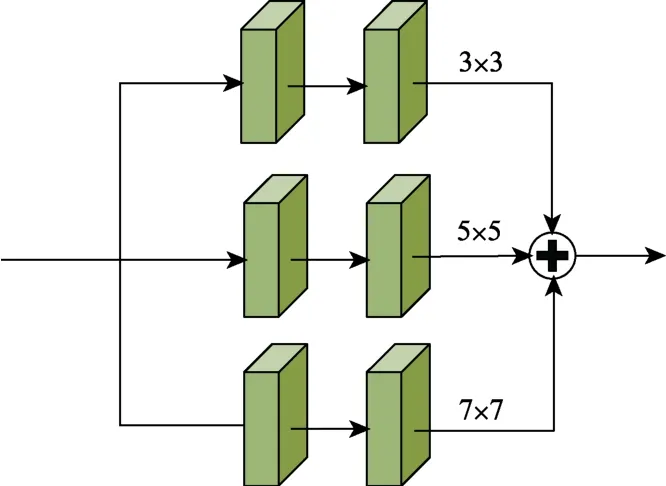
图2 上下文特征提取模块结构Fig.2 Structure of context feature refine block
2.4 注意力特征融合模块
本文设计了一种注意力特征融合模块(Attention Feature Fusion Block, AFF Block)来对残差网络单元进行加强,以提升其保留重要特征信息的能力。
该特征融合模块包括空间注意力融合模块和通道注意力融合模块。注意力特征融合模块的框架图如图3所示,其中,f1、f2为待融合的特征图信息,二者经空间注意力融合模块可得到空间区域信息加强后的融合特征图fspatial,经通道注意力融合模块可对特征图的通道信息通过注意力进行加强,得到融合特征图fchannel。最后,将两种融合的特征图进行融合,即得到融合特征ffuse,三者关系可表示为:
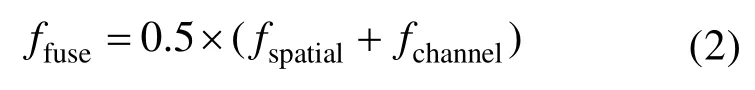

图3 注意力特征融合模块框架Fig.3 Frame of attention feature fusion block
如图4所示,本文将此注意力特征融合模块用于残差网络单元中,得到残差注意力网络模块( Residual Attention Feature Fusion Block,Res-Aff-Block),使得残差网络单元在特征融合过程中能保留更多重要的图像特征信息。本文方法选择采用图4(b)中所示的Res-Aff-Block 用于红外与可见光图像的融合算法中,模块内卷积层的通道数为64、64、128。Res-Aff-Block 的网络参数如表1所示。
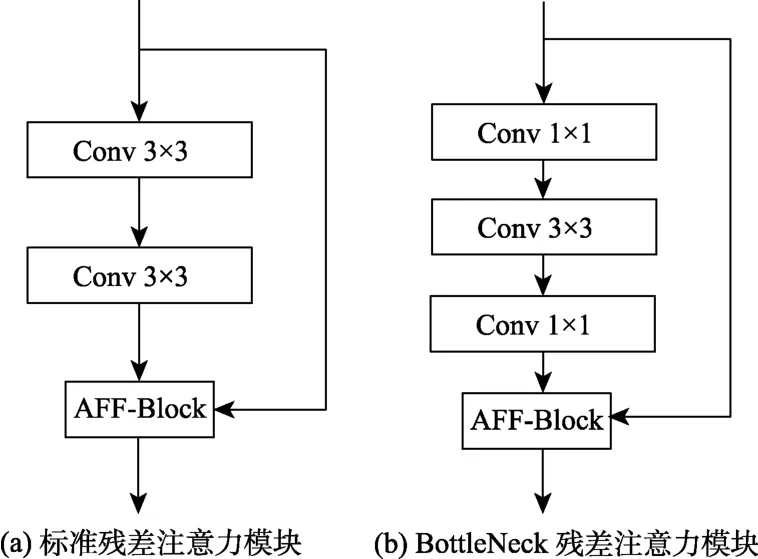
图4 残差注意力模块示意图Fig.4 Diagram of Res-Aff-Block
2.4.1 空间注意力特征融合模块
空间注意力特征融合模块示意图如图5所示。f1、f2为待融合的特征图信息,其维度为H×W×C,H、W、C分别表示图像的高度、宽度和通道维数。首先提取特征图的空间统计信息,其通过在通道维度上对f1、f2分别进行全局平均池化和全局最大池化,并将池化结果在通道维度上进行拼接,得到维度为H×W×2的池化特征图。之后,基于f1、f2的空间统计信息进行空间权重的计算。该模块利用一个输出通道为1、卷积核大小为1、步长为1 的卷积层对池化特征图进行空间特征信息的提取,之后将提取的特征信息经sigmoid激活函数后,将其作为特征图f1、f2的空间权重信息v1、v2。这里,对f1、f2的池化特征图进行特征提取时卷积层权重共享。最后,根据空间权重对特征f1、f2进行空间区域信息的增强,再将增强后的特征图进行相加,即可得到融合特征图fspatial:

图5 空间注意力特征融合模块Fig.5 Spatial attention feature fusion block
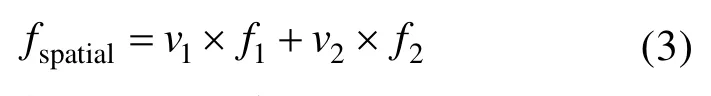
2.4.2 通道注意力特征融合模块
通道注意力特征融合模块示意图如图6所示。f1、f2为待融合的特征图信息,其维度为H×W×C。首先,对f1、f2进行平均池化操作对通道信息进行统计,具体计算形式如下所示:
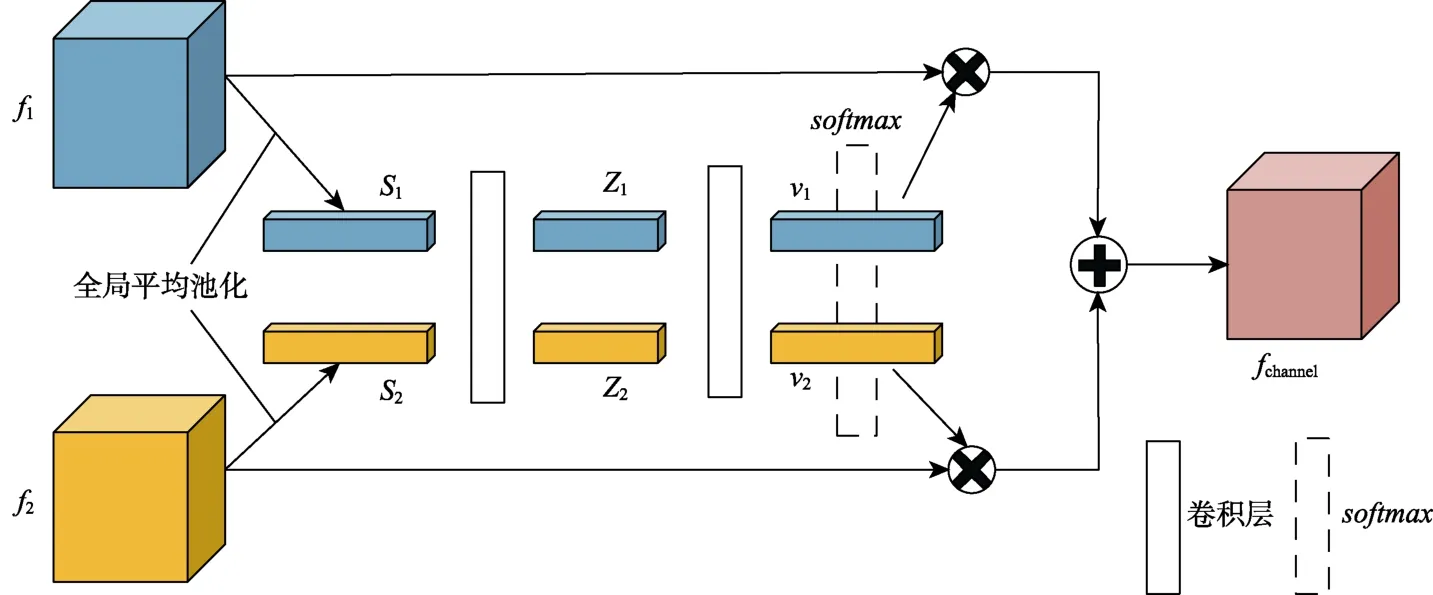
图6 通道注意力特征融合模块Fig.6 Channel attention feature fusion block

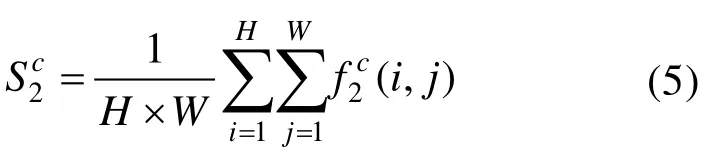
其中,S1、S2分别为特征图f1、f2的通道统计信息,且S1∈Rc,S2∈Rc;c为特征通道维数的下标。之后,利用输出通道为d、卷积核大小为1、步长为1 的卷积层对特征S1、S2进行卷积操作,以获得更紧凑的特征Z1、Z2。特征Z1、Z2的维数d可以通过比率r和最小值l来控制,其表示为:
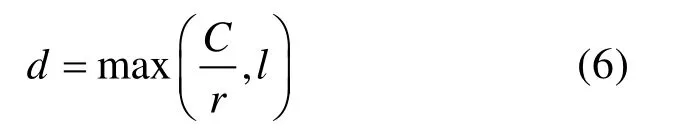
然后,通过输出通道为C、卷积核大小为1、步长为1 的卷积层对特征Z1、Z2进行卷积操作,并将输出结果进行softmax运算,得到不同特征的通道权重v1、v2。与空间注意力模块相同,此处对f1、f2的通道统计信息进行特征提取转化的卷积层权重共享。
最后,根据通道权重信息对特征f1、f2进行加权计算,得到通道注意力特征融合结果fchannel:

2.5 损失函数设计
不同类型的图像所具有的信息差别很大,图像融合的目的是尽可能多地保留源图像中的互补信息,去除其中的冗余信息。具体到红外与可见光图像融合领域,即融合图像能从红外图像中获得更多的热辐射信息,从可见光中获得更多的背景细节纹理信息。红外图像的热辐射信息一般主要表现在图像的像素强度信息中,其与背景信息的差异较大,因而高亮目标信息的边缘处也会存在较丰富的梯度信息。可见光图像的细节纹理信息较多表现在图像的梯度信息中,一般梯度信息较丰富的地方往往便是图像细节纹理较多的区域。
如果一幅源图像中的信息量更加丰富,则其对融合图像产生的影响可能更大,融合图像也应与该源图像保持更大的相似度。而不同的图像具有的信息量也不尽相同,因而本文希望利用一种信息度量的方法来确定红外图像与可见光图像中含有重要信息的比重,使得在模型学习的过程中可以自适应地调整不同源图像对网络融合结果的影响,从而得到更好的融合效果。
本文通过源图像的梯度信息来度量红外与可见光图像的信息量。与其他度量方法相比,图像梯度是一种具有较小接受域的基于局部空间结构的度量方法。在深度学习框架中,梯度信息在计算和存储方面也非常方便和有效,非常适合在卷积神经网络中用于信息衡量。该度量方法可表示为:
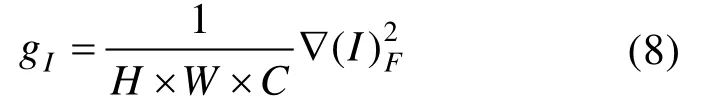
其中,gI表示图像I的信息量,H、W、C分别表示图像的高度、宽度、通道维数,在图像为灰度图时,C即为1。||*||F表示F范数,∇表示使用拉普拉斯算子计算得到的图像的二阶梯度信息。
基于以上信息度量方法,可以计算出可见光图像V和红外图像I所具有的信息量gV和gI。进一步地,本文将其转化为自适应权重,并将其作为红外与可见光图像在融合结果中的信息保留度,其计算方式如下:
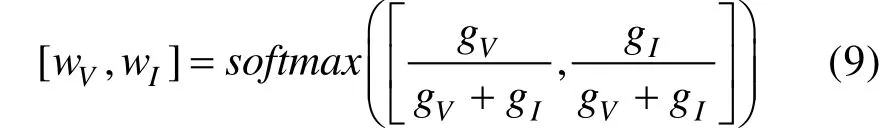
在计算红外图像与可见光图像的信息量占总信息量的比重之后,使用softmax函数对其进行处理。wV和wI可以用来调整融合图像与可见光、红外图像之间的相似度。权重越大,表明对应源图像与融合图像间的相似度越高,对应源图像的信息保存程度越高。
损失函数用于在模型训练时引导模型进行误差修正,促使模型能保留更多的源图像信息,使得融合图像与源图像之间具有很高的相似度。在损失函数设计中,本文从图像结构相似性和像素强度分布两个方面来实现融合图像和可见光、红外图像间的相似性约束。
结构相似性度量方法(Structural Similarity Index Measure, SSIM)是在图像领域使用最广泛的指标之一,该方法基于图像的亮度、对比度、结构三部分来衡量图像之间的相似性。在深度学习中,SSIM 也被广泛应用于图像处理相关模型的损失函数中。本文使用SSIM 约束红外图像I、可见光图像V与融合图像F之间的相似性,并结合权重wV和wI来调整源图像的信息保留度,其计算公式表示为:
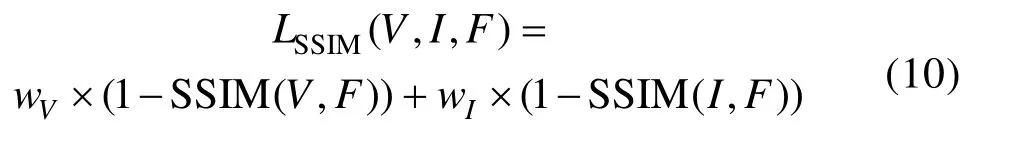
然而SSIM 更多关注的是图像在结构和对比度上的变化,对图像强度分布差异的约束较弱。因此,本文使用均方误差损失来对其进行补充。在计算均方误差MSE 时,同样使用权重wV和wI来调节源图像对融合图像的影响程度,MSE 损失计算公式如下:
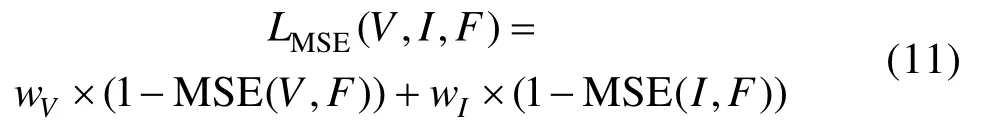
均方误差损失对图像强度分布差异的约束较强,在单独作为损失函数时,容易导致图像模糊等现象。可见,SSIM 和MSE 具有很强的互补作用,在使用时,本文通过常数α来控制二者的比重,最终本文设计的损失函数定义为
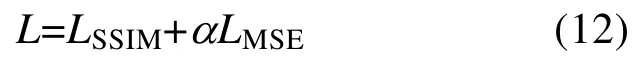
3 实验结果及分析
为了验证提出的图像融合算法的有效性,本文在公开数据集上进行实验,并对实验结果进行分析。
3.1 实验设置
TNO 数据集[25]是红外与可见光图像融合领域使用广泛的数据集之一,其中包含很多图像内容丰富且经过矫正配准的红外与可见光的图像数据。本文将TNO 数据集中42 对常用的不同场景下的红外与可见光图像作为训练和测试数据。实验中对图像进行了裁剪,裁剪过程中步长设为20,裁剪图像尺寸为186×186,最终得到16958对红外与可见光图像。同时,对图像的像素值进行缩放映射到[0,1]范围内。本文提出的融合算法基于Tensoflow 2 深度学习框架进行模型的搭建和训练,模型训练的硬件环境为GTX 1080Ti 和Intel i7-8700K。融合结果的客观质量评价指标结果在Matlab 2019b 上计算得到。
将图像融合算法与12 个方法进行比较,其中包括6 个传统图像融合算法:基于交叉双边滤波(Cross Bilateral Filter,CBF)的[26]、基于曲波变换(Curvelet Transform,CVT)的[27]、基于双树复小波变换( Dual-tree Complex Wavelet Transform, DTCWT)的[28]、基于梯度转移融合(Gradient Transfer Fusion,GTF)的[16]、基于多分辨率奇异值分解(Multi-Resolution Singular Value Decomposition,MSVD)的[29]、基于比率低通金字塔(Ratio of Low-Pass Pyramid,RP)[12]的图像融合算法。6 个基于深度学习的图像融合算法:Fusion GAN[23]、IFCNN[30]、DenseFuse[22]、NestFuse[31]、U2Fusion[32]、RFN-Nest[33]融合算法。其中,DenseFuse 融合算法中采用L1 融合规则,NestFuse 融合算法的注意力融合模块中采用平均融合策略,其他对比方法的参数设置根据其对应的参考文献进行设置。本文所提出的图像融合算法在模型训练过程中,使用Adam 优化器对模型进行训练,损失函数中参数α设置为20。
3.2 主观评价分析
如图7所示为不同图像融合算法对“街道”图像进行融合后的结果,其中(a)和(b)分别为红外图像和可见光图像,(c)~(n)为各种对比融合算法的融合图像,(o)为本文提出的图像融合算法的实验结果。为了方便实验结果的观察对比,将融合图像中的行人和广告牌区域用红色方框进行了标记。
通过观察融合结果可以发现,CBF 和RP 算法的融合图像中具有大量噪声,导致许多图像细节信息丢失,很多图像区域也因此变得模糊。例如,CBF 融合图像中的广告牌和RP 融合图像中的行人区域,图像的细节信息被噪声所干扰,其中CBF 融合图像中的噪声甚至造成了图像背景的模糊。CVT、DTCWH 算法的融合图像中也含有少量噪音,但图像的纹理细节信息基本得到了保留。GTF、MSVD、Fusion GAN、RFN-Nest 融合算法的融合图像中产生的噪声很少,关键目标信息也呈现出了高亮轮廓,但是图像中的很多细节区域模糊不清,丢失了很多细节纹理信息。如GTF 融合图像中丢失了广告牌区域光照渐变的细节纹理信息,MSVD 和Fusion GAN 在此处的融合效果相比于GTF 较好,但光照细节信息也有些模糊,不够清晰;RFN-Nest 融合图像中的细节信息丢失严重,对广告牌上的文字信息都未能保留。NestFuse 算法的融合图像很好地保留了图像的细节信息,但图像的对比度稍弱,U2Fusion 算法的融合图像整体色调偏暗,二者的视觉体验略差。相比之下,IFCNN、DenseFuse 和本文提出的图像融合算法的融合图像对比度较高,图像中的广告牌区域字迹清晰,光照渐变纹理信息保留较好,行人区域的高亮目标轮廓清晰,易于辨识,融合效果自然。通过对融合图像的观察比较,可以发现提出的融合算法不仅很好地保留了图像中的细节纹理信息,而且图像的背景区域信息也融合得较好,图像整体的视觉效果很好。可见,本文提出的图像融合算法将可见光和红外图像中的信息进行了很好的融合,融合图像对比度高,视觉效果好。
3.3 客观评价分析
为了客观验证融合结果的效果,选取了信息熵(Entropy, EN)、交叉熵(Cross Entropy, CE)、SCD、SSIM、多尺度结构相似性(Multi-Scale Structural Similarity Index Measure, MSSSIM)、视觉信息保真度(Visual Information Fiedity, VIF)作为融合图像质量的评价指标。其中,EN 可以反映图像中含有信息量的大小,值越大表明融合图像质量越好,但是其容易受到噪声的干扰,可作为参考指标。CE 可以用来衡量信息量之间的距离,其值越小,表明融合图像的信息与源图像越相近,融合图像的质量越好。SCD 可以衡量融合图像含有的源图像的信息量,其值越大,表明融合图像从源图像中获取了更多的细节信息,图像的融合效果更好。SSIM 可以从图像的结构、亮度、对比度三方面衡量图像间的相似度,MSSSIM 则是在SSIM 的基础上引入了多尺度机制,其与人眼视觉系统的视觉感知更加一致。二者的值越大,表明融合图像与源图像越相似,图像融合质量越好。VIF 可以衡量融合图像相对于原始图像的VIF,值越大,则图像融合的效果越好。
表2展示了本文方法和12 个对比融合算法在TNO 数据集的42 对图像上所取得的客观质量评价指标的平均值。为方便观察,将每项指标中取得前三的结果分别用粗体、红色、绿色进行了标注。从表中结果可以看出,本文所提出的图像融合算法在CE、SCD、SSIM、MSSSIM 指标上都取得了最优的结果,VIF 的结果也仅次于U2Fusion。其中,SSIM 和MSSSIM 指标上的结果最优,表明本算法的融合结果在图像的结构相似度上与源图像最接近,融合图像很好地继承了源图像的亮度、对比度和结构信息。SCD 指标取得最优结果也说明了融合图像含有的源图像信息量较多,获取到的源图像的细节较多。本文的融合算法在VIF 指标上取得了仅次于U2Fusion 的结果,表明融合图像的VIF 较高,视觉观感很好。NestFuse 算法融合结果的EN 指标最高,但观察融合结果,其图像对比度略差于本文算法。在其他指标上,本文算法也优于NestFuse。另外,EN 的计算容易受到噪点的干扰,图像中的噪点较多会导致EN 的计算偏高,如CBF 算法的EN 指标较高,但其融合图像中噪点较多。本文算法虽未能在EN指标上取得较好的成绩,但图像中噪点较少,而且本文算法的融合结果在CE 上取得了最优结果,说明融合图像与源图像的信息相似程度最高,融合图像从源图像中获取的信息保留程度较好。
3.4 图像预处理作用分析
为验证本文所提出的红外与可见光图像融合算法中图像预处理步骤的作用,设计了以下对比实验:
(A)将红外图像与可见光图像分别从两路编码网络输入进行特征提取,网络其余部分保持不变;
(B)两路编码网络合并,将红外图像与可见光图像进行拼接后输入网络进行特征提取和图像融合。为保证模型规模相当,合并后的编码网络各层间的顺序保持不变,但层数变为原先的两倍。
实验结果如表3所示。从表中可以看出,对源图像进行分解预处理后再进行特征提取的方法在除CE 外的客观评级指标上都取得了最好的结果,而且融合结果虽然未能在CE 上取得最好结果,但其结果与实验A 的差距也很小。这表明该图像预处理步骤有助于提取到红外和可见光图像更为全面的特征信息,有利于提升源图像的融合效果。

表3 图像预处理分析实验结果Table 3 Ablation study of different image preprocessing operations
3.5 CFR Block 作用分析
为验证本文所提出的图像融合算法中 CFR Block 的作用,设计了以下对比实验:
(A)为验证上下文特征的作用,将该模块中的卷积核大小统一设为3×3,其余部分保持不变;
(B)为验证多个分支进行特征提取的作用,将该模块中的卷积层合并为1 路,加深网络深度;
(C)将该模块合成为1 路网络,并使用三个标准残差单元如图4(a)中所示替代CFR Block 中的卷积层,三个残差单元的输入输出通道数分别设为32、64、64,另外将原先该模块后的卷积层移至第一个和第二个残差单元之间,用来提升特征的维度。
实验结果如表4所示。从表中可以看出,使用CFR Block 进行特征提取,融合图像在EN、SCD、SSIM、MSSSIM 等客观质量评级指标上都呈现出了更好的结果,虽然未能在CE 和VIF 指标上保持最好结果,但差异较小。同实验A 的对比结果来看,CFR Block 可以有效提取到图像的上下文特征,有助于提升图像的融合效果。同实验B 和C 的结果来分析,该模块虽然网络深度较浅,但其提取的图像特征更加丰富全面,融合结果中源图像的结构信息和细节信息保留更好。

表4 上下文特征分析实验结果Table 4 Ablation study of context feature refine block
3.6 注意力特征融合模块作用分析
为验证本文图像融合算法中注意力特征融合模块的作用,设计了以下对比实验:
(A)将解码网络中残差注意力单元的注意力特征融合模块去除,替换为标准的残差单元结构。
(B)将注意力特征融合模块中的通道注意力特征融合模块去除,仅使用空间注意力特征融合模块融合残差单元中的特征信息。
(C)将注意力特征融合模块中的空间注意力特征融合模块去除,仅使用通道注意力特征融合模块融合残差单元中的特征信息。
实验结果如表5所示。将实验B 与A 相对比发现,使用空间注意力特征融合模块会导致融合图像在除VIF 以外的指标上都有所下降,这说明对特征的空间信息进行增强可能会导致图像特征信息的丢失,但是这有利于提升图像的视觉保真程度。将实验C 与A 相对比发现,通道注意力特征融合模块有效地提升了融合图像对源图像中信息的保留程度。将以上实验结果和本文融合算法相比较可以发现,将空间注意力和通道注意力相结合后,融合图像的EN、MSSSIM、SCD 等指标都得到了增强,融合图像从源图像获取的信息量更多,同时融合图像的视觉保真度也较好,说明本文提出的注意力特征融合模块有效地结合了空间注意力和通道注意力模块的优势,取得了一个相对更加平衡且有效的成绩。

表5 注意力特征融合模块分析实验结果Table 5 Ablation study of attention feature fusion block
4 结 论
本文提出了基于残差网络和注意力机制的红外与可见光图像融合算法。该算法通过引导滤波实现对红外图像与可见光图像的分解,通过编码器网络分别对分解后的图像进行特征提取,然后进行融合,并通过构建解码器实现对融合图像的重建。其中,利用残差网络作为模型的主干网络,引入注意力机制提高感兴趣区域的权重。实验证明,本文方法可以取得良好的融合效果,改善了单一类型图像信息量不足的问题,可用于无人机的航拍图像处理,提升无人机航拍图像捕捉目标信息的能力。然而,本文方法的融合效率还有待提高,在未来的研究工作中,可以采用更轻量化的网络进行特征提取和特征融合,在保证融合效果的同时提高运行效率,以满足实际场景的需要。
猜你喜欢
环球时报(2022-05-23)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
金桥(2021年4期)2021-05-21
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
北京航空航天大学学报(2018年1期)2018-04-20
