
基于数据架构的结构化数据注册引擎设计
2022-06-02 06:35黄安琪杨文晖倪雅婷
计算机与现代化 2022年5期
黄安琪,苗 放,杨文晖,倪雅婷,蒋 媛
(1.成都理工大学计算机与网络安全学院,四川 成都 610059; 2.成都大学大数据研究院,四川 成都 610106)
0 引 言
伴随着互联网、大数据的不断发展与进步,数据的重要地位得到逐步体现。2015年,十八届五中全会首次提出“国家大数据战略”,国务院发布《促进大数据发展行动纲要》,发展大数据已然成为国家的首要战略之一;2016年,《政务信息资源共享管理暂行办法》出台,要求加快推动政务信息系统互联和公共数据共享,跨部门数据资源共享共用格局基本形成;2017年,《大数据产业发展规划(2016—2020年)》开始实施,全国各地将按照规划发展大数据产业;2018年12月,中共中央政治局就实施国家大数据战略进行第二次集体学习,习近平总书记强调推动实施国家大数据战略,加快完善数字基础设施,推进数据资源整合和开放共享,保障数据安全;2020年实现政府数据集的普遍开放,国务院和国务院办公厅又陆续印发了系列文件,推进政务信息资源共享管理和政务信息系统整合共享。
随着国家大数据战略的推进,政府和各行各业所使用的应用系统的规模不断扩大,数据管理、数据共享、信息安全已经成为了政府、企业关注的重点和面临的重大挑战[1-3]。跨层级、跨地域、跨系统、跨部门、跨业务的信息系统的整合、互联、协同以及数据共享的问题仍然存在[4-5]。梅宏院士在关于大数据的发展现状和未来趋势中指出,数据成为核心资产,现在是数据为王的时代,数据共享是应首要解决的问题。目前,政府与企业的信息系统产生的数据大多都是结构化数据,存储在关系型数据库中,由于各个系统自成体系,成为一个个独立的“信息孤岛”,而且问题越来越严重[6-7]。如何管治和利用好结构化数据,是目前众多企业和政府机关所面临的难题[8]。
在数据时代,应该以数据的思维来思考和解决问题。数据架构(Data Architecture, DA),建立在云计算的硬件架构之上,采用“面向数据和以数据为核心”的思想,通过数据注册中心(Data Register Center, DRC)、数据权限中心(Data Authority Center, DAC)和数据异常控制中心(Data-exception Control Center, DEC)来统一定义数据、管理数据和提供数据服务[9]。同时为了解决数据的安全问题,DOSA(Data-Oriented Security Architecture)是基于DA的基础上,专门对安全方面的研究,其数据是天生注册的[10]。DOSA是一种利用数字证书认证和公钥基础设施进行数据保护和应用的架构[11],在数字版权作品管理系统中已得到应用。DRC是数据架构中的核心组件,主要的功能是对数据的注册信息进行存储与管理,由DRC将应用层和数据资源池连接起来,通过实时数据注册机制,对应用提供服务[12]。数据资源统一注册是实现数据资源统一调度和共享应用的有效途径,是分散存储的多源、异构、异地数据和资源目录间的纽带。
大部分现有“数据管理平台”或“数据交换平台”普遍认为结构化数据已经是结构化的了。对于结构化数据的管理和应用,通常采用最直接的拷贝方式,将分散各地的结构化数据直接集成到一个庞大的数据存储库中,最常用的技术架构就是数据湖与数据中台。数据湖通过从各类结构化数据源引接汇聚[13-14],数据中台通过数据采集层,原始异构结构化数据源的获取汇集[15-16]。2种技术架构对于结构化数据的处理方式存在以下几种问题:
1)海量多源异构的结构化数据的存储需要耗费大量的硬件资源,建设成本高。
2)汇集后的结构化数据与源数据存在版本差异,进行实时同步更新十分困难,运营维护难。
3)对于复杂、综合应用和协同应用场景,增加了数据管理的难度和负担。
针对现有技术架构对结构化数据的管理和应用的缺陷,数据架构根据统一注册标准将结构化数据提取出数据注册信息,通过注册信息与结构化数据源建立紧耦合关系,就能通过注册信息来管理结构化数据本身,从而在使结构化数据在物理上分散,在逻辑上集中,实现跨层级、跨地域、跨系统、跨部门、跨业务的结构化数据资源统一调度管理。同时结构化数据是数据资源池中重要的组成成分,结构化数据的注册也是数据架构至关重要的一环,但是,对于结构化数据注册仍然缺乏有效的注册手段。
国外对于结构化数据注册在各领域以不同形式展开研究与应用。在特定领域方面,元数据标准注册系统(IEMSR)是由JISC资助的共享服务计划,只针对教育这一特点领域,解决教育系统的元数据信息注册问题[17]。在跨域方面,UKOLN的信息社会技术计划(IST)下辖的CORES Registry,是一种跨域的元数据注册系统,解决不同领域的数据注册问题[18]。在元数据标准方面,都柏林核心元数据创始组织(DCMI)主办的DCMI Metadata Registry元数据注册系统,其目的是促进DC元数据注册标准的迭代与更新[19]。但在目前,国外仍没有哪个元数据注册系统能够提供对所有现存的、可获取的结构化数据的元数据注册,尽管部分注册系统涵盖的领域已经相当广泛。
在国内,文献[20]研究了元数据标准,分析了不同类型数据的特征,提出了通用的数据注册标准,但对注册方式未作进一步阐述。文献[21]提出了手动注册与自动注册方式,但对结构化数据的注册,未作深入的研究。文献[22]分析了结构化数据的特征,提出了结构化数据的注册标准,研究针对结构化数据的注册方法,但只针对MySQL数据库进行了注册,未解决国产数据库以及其他常用数据库的注册。
为了解决各类结构化数据的注册问题,本文基于DA的数据注册中心(Data Register Center, DRC),结合现有的研究成果,并深入分析结构化数据的特征,设计出一种针对结构化数据的注册引擎,并提出一种结构化数据的元数据信息注册标准和注册方法,解决了包括国产数据库在内的各类常用数据库的注册问题。通过构建基于数据架构的结构化数据注册实验平台,验证了该注册引擎能够对各类型结构化数据进行自动采集,并且准确、高效地将结构化数据注册信息写入DRC数据注册库中。
1 结构化数据注册引擎
1.1 结构化数据注册引擎的系统结构
结构化数据注册引擎是DRC数据注册中心的主要功能模块,是部署在云服务器上对结构化数据实现自动实时注册和未来智能注册的基本工作单元。注册引擎总体设计基于层次化设计理念,划分为注册信息采集层、注册信息汇集层、注册信息注册层。系统结构如图1所示。
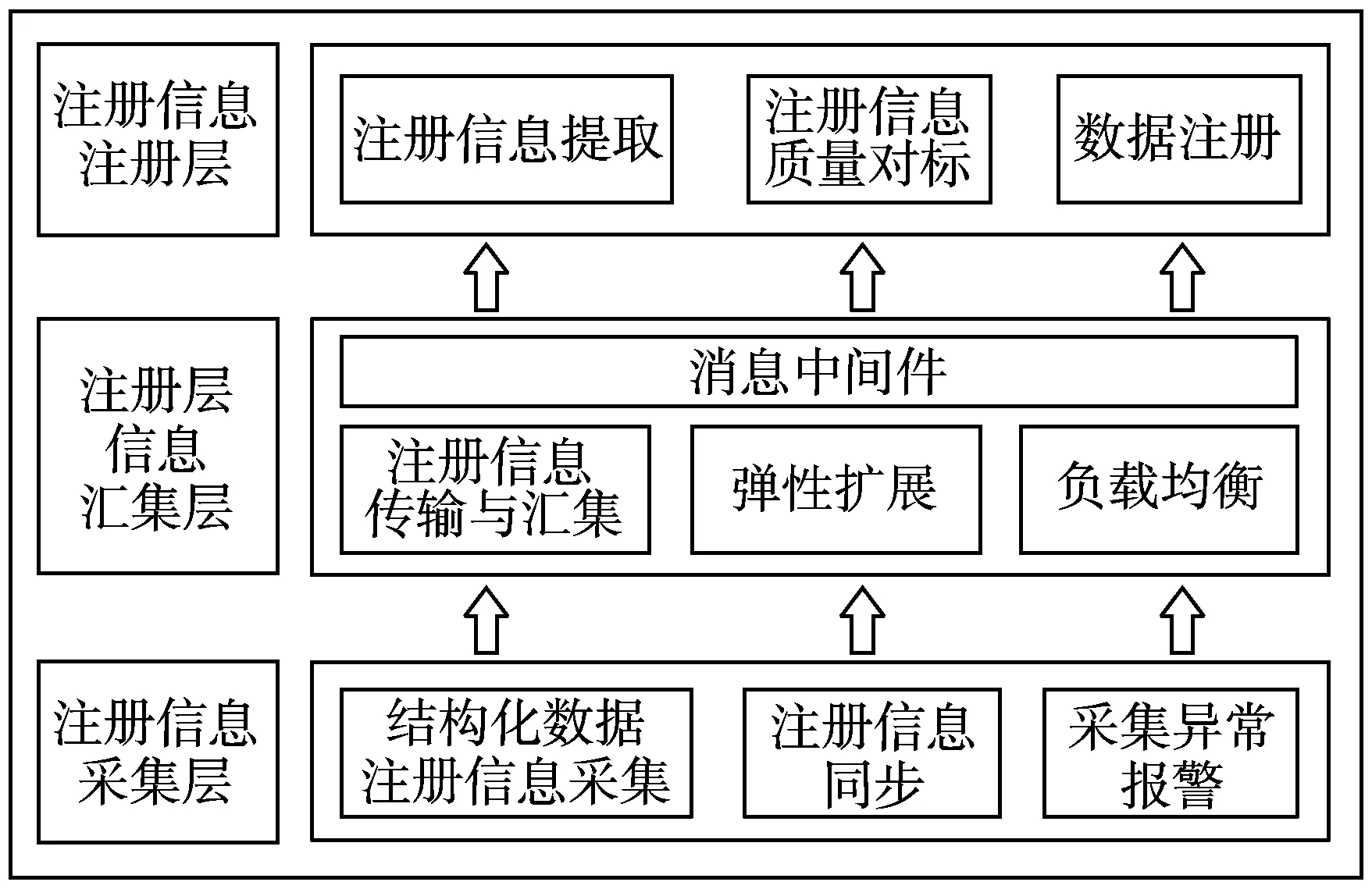
图1 结构化数据注册引擎的系统结构
1.2 注册信息采集层
注册信息采集层的主要功能是根据结构化数据统一注册标准,对分散到不同地点的结构化数据源进行注册信息采集。由于结构化数据目前多存储于关系型数据库中,而数据库类型多样,因此采集层内部集成了多种采集模块,能针对不同的数据库类型进行采集,解决了包括达梦、DB2、MySQL等数据库的注册信息采集。可通过数据架构中DRC数据注册中心配置注册引擎,填写数据源相关参数并设定采集频率,启动任务进行高效率自动化采集。
1.3 注册信息汇集层
注册信息汇集层主要具有以下2个功能:1)通过分布式消息队列Kafka,将注册信息采集层按照结构化数据统一注册标准采集到的结构化数据注册信息传输到Kafka服务器集群,实现注册信息的实时传输;2)在Kafka服务器集群中汇集从不同数据源采集到的结构化数据注册信息,实现多源、海量的结构化数据注册信息汇聚。
1.4 注册信息注册层
注册信息注册层监听汇集层中的消息队列,按照设定的注册策略自动提取结构化数据注册信息。同时内置质量对标模块,对提取的注册信息进行核查,将符合标准的注册信息写入DRC数据注册库中,不符合标准的注册信息将记录于异常日志。
2 关键技术
2.1 结构化数据统一注册标准
结构化数据多存储在关系型数据库中,如达梦、MySQL、Oracle、PostgreSQL等。由于结构化数据的数据库是按照不同业务系统的特定运行需求而建立的,复杂多样的应用系统导致数据规范不统一。为了实现数据的统一管理,就必须提出一种结构化数据统一注册标准,只有在统一的注册标准之下才能做到数据的统一管理和共享,从而打破“数据孤岛”[23]。
结构化数据的数据库千差万别,数据库表结构、数据库字段、字段类型等设计不尽相同,要对其建立统一的数据注册规范或标准,显然不太符合实际。但是,从理论上,可以把结构化数据注册规范的制定归纳为“统一注册标准”。结合对结构化数据的分析,总结发现存储在关系型数据库中的结构化数据具有共性元素,如数据库类型、数据库名称、表名称、表字段结构、数据库访问地址、访问口令、访问权限等。统一数据注册标准后,对接入系统数据的标准要求降低,数据适配性提高。
结构化数据统一注册标准基于上述共性元素,结合个性化特点,并根据DA数据架构理论进行设计[24]。结构化数据注册标准管理中包括数据库注册、数据库表注册、数据库表字段注册,需要的信息项获取情况和具体内容如表1~表3所示。
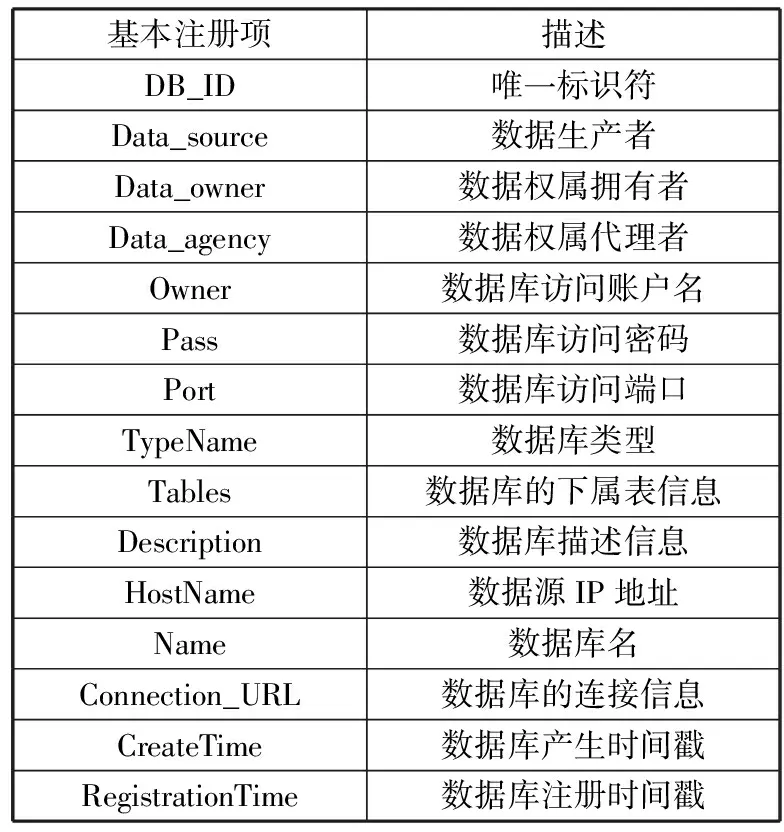
表1 数据库注册标准

表2 数据库表注册标准
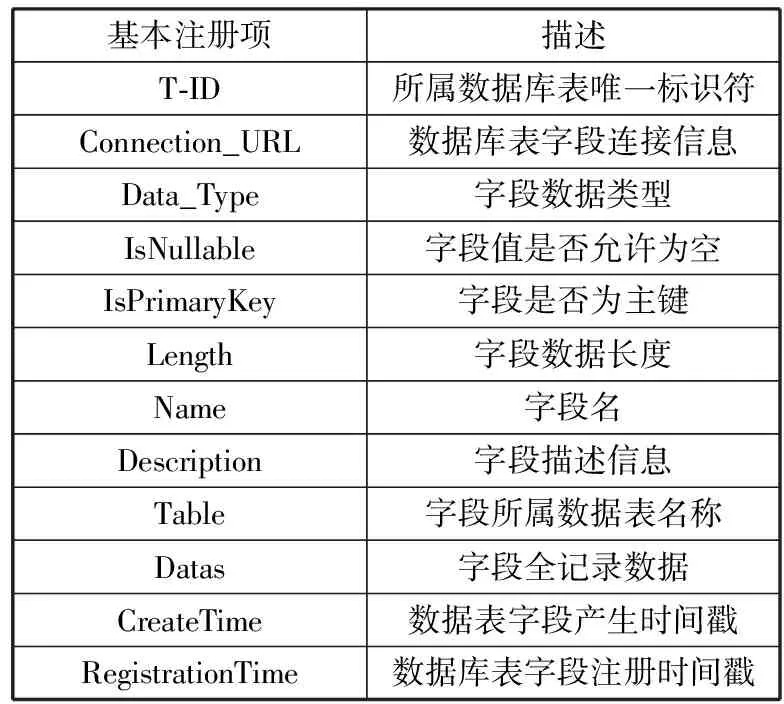
表3 数据库表字段注册标准
2.2 注册信息采集
2.2.1 采集层功能架构
结构化数据注册引擎采用分布式采集技术,针对不同类型的结构化数据源,例如常见的关系型数据库MySQL、Oracle、达梦,非关系型数据库Hive等,采取不同的采集模块引擎实现多源、异构的结构化数据注册信息采集。同时,按照结构化数据统一注册标准对采集到的数据进行数据转换、处理,从而形成符合标准的结构化数据注册信息,最终将注册信息汇集到消息中间件中。注册信息采集层的功能架构如图2所示。

图2 注册信息采集层功能架构图
2.2.2 采集技术
按照结构化数据统一注册标准,需要采集数据库的Schema信息、数据库表与数据表字段的相关数据注册信息,结构化数据注册信息的采集利用JDBC(Java Databases Connectivity standard)技术完成。
在JDBC技术规范中,提供了Connection、Statement、ResultSet这3种经常用到的接口,针对每个接口,JDBC规范提供了相应的接口描述对象[25]。本文结构化数据注册信息采集采用JDBC的相应接口获取结构化数据注册信息。
在获取注册信息之前,需要通过JDBC Driver连接数据库,不同类型的数据库采用不同的JDBC Driver,如表4所示。

表4 不同类型数据库对应JDBC Driver
针对结构化数据源类型多样、复杂的特性,JDBC接口中内置针对不同数据库类型的方法,可以获取到按注册标准设定的结构化数据注册信息项,从而完成数据采集,并且接口也具有高安全性、高性能、高可读性和高可维护性的优点。
2.2.3 数据库与数据库表注册信息采集
首先通过JDBC Driver与对应的数据源建立连接。连接建立成功后,通过JDBC ResultSet接口采集数据库的Schema信息与数据库表相关数据信息。采集完成后根据结构化数据统一注册标准中需要获取的注册信息项,将得到的结构化数据信息进行处理,形成符合标准的结构化数据注册信息。
使用JDBC技术采集数据库的Schema信息与数据库表相关数据信息的部分代码为:
代码1使用JDBC技术获取数据库Schema信息
输入:JDBC与数据库连接参数
输出:数据库Schema信息
1:Connection conn=null;
2:conn=DriverManager.getConnection(url, user, pass);
3:ResultSet rs=null;
4:String Schema=null;
5: try{
6: rs=conn.getMetaData().getCatalogs();
7: while (rs.next())
8: String tableSchem=rs.getString("TABLE_CAT");
9: Schema=tableSchem+Schema+"-";}}
10: catch(SQLException e){
11: e.printStackTrace();}
12: finally{
13: close(rs,conn);}
14:return Schema;
代码2使用JDBC技术获取数据库表注册信息
输入:JDBC与数据库连接参数
输出:数据库表注册信息
1:Connection conn=null;
2:conn=DriverManager.getConnection(url, user, pass)
3:ResultSet rs=null;
4:DatabaseMetaData dbmd=conn.getMetaData();
5:try{
6: rs=dbmd.getTables(null, null, "%", "%");
7: JSONObject tableRegisterInfo=new JSONObject();
8: while(rs.next()){
9: tableRegisterInfo.set("tableType",rs.getString("TABLE_TYPE"));
10: tableRegisterInfo.set("tableSchema",rs.getString("TABLE_SCHEMA"));
11: tableRegisterInfo.set("tableName",rs.getString("TABLE_NAME"));
12: tableRegisterInfo.set("columnName",rs.getString("COLUMN_NAME"));}}
13:catch(SQLException ex){
14: ex.printStackTrace();}
15:finally{
16: close(rs,conn);}
17:return tableRegisterInfo;
2.2.4 数据表字段注册信息采集
根据结构化数据统一注册标准以及DA中DRC数据注册中心对结构化数据的注册与应用需求,需要对数据库内容,即表字段相关信息与表字段的全记录数据进行数据注册。
由于数据表的字段数量较多并且字段全纪录数据的体量庞大,不能对数据表的所有字段的全纪录数据进行采集注册,因此需要选取典型字段进行全纪录数据注册。采集典型表字段的全记录数据进行注册的目的在于:
1)体现结构化数据信息体量。
2)通过数据表字段全记录数据,来掌握源数据表的实时变化情况。
3)典型字段代表着该数据表的主要内容,有些工作不一定要访问源数据库表,只需访问DRC中数据注册中间库就能完成了,例如统计分析、计算数据总量等。
本文对每张数据表选用2个典型字段进行全记录数据注册,典型字段为数据表的主键字段与第一个非空字段。其余数据表字段只进行字段相关信息的注册,不进行全记录数据注册。
确定好采集内容后,表字段注册信息的采集与数据库和数据库表注册信息的采集方式与过程类似,通过JDBC ResultSet接口采集数据表字段相关数据,通过JDBC Statement接口执行SQL语句查询数据表典型字段的全记录数据。最终根据数据表字段的统一注册标准,对采集到的所有数据进行处理,形成符合标准的数据表字段注册信息,传输至注册信息汇集层。
2.3 注册信息汇集
通过注册信息采集层采集到的结构化数据注册信息需要通过消息中间件传输给注册层,由于采集层会频繁地定时采集海量结构化数据注册信息,所以需要具有分布式消息传输、高并发吞吐量、弹性扩展、可恢复性、可靠传输等特性的消息中间件来支持注册信息的传输与汇集[26]。目前,应用比较广泛的主流消息中间件的对比如表5所示。
结合结构化数据注册引擎中各层次之间进行的注册信息传输与汇集对于消息中间件的要求,以及上述几种主流的消息中间件的对比,选择了Kafka作为注册信息汇集与传输的消息中间件。Kafka为分布式而生,具有高吞吐量、持久化数据存储、分布式系统易于扩展、消息延迟低等特性,同时具备负载均衡与弹性部署的特点,使用Kafka能够满足数据采集单元注册信息汇集的需求。
2.4 注册信息质量对标
通过对注册信息进行质量对标检查,将符合结构化数据统一注册标准的注册信息直接写入DRC数据注册库中,并在DRC注册中心记录注册成功日志。不符合标准的注册信息可分为注册标准项缺失和标准项数据缺失2类。对于这2类情况,质量对标模块针对性地采用不同的处理策略。注册标准项缺失指数据采集层封装的结构化注册信息与注册标准不对应,注册层相关模块将该数据丢弃并在本地记录注册异常,同时发送注册失败日志到DRC注册中心;标准项数据缺失指注册信息标准项都一一对应,但标准项数据缺失,注册层对应模块会对缺失项进行自动标注,同时通知数据提供者按照统一注册标准进行补充填写。注册信息质量对标具体流程如图3所示。

图3 注册信息质量对标流程图
2.5 注册信息同步
数据架构的核心部件是数据注册中心,要求对数据进行“天生注册”或“原生注册”。一切数据天生注册包括数据源本地注册与系统产生的新数据的注册。在实际的业务系统中,数据库中的数据是动态变化的,比如数据库表会发生增加或者删除操作;数据库表中记录会发生新增或者减少等情况。数据注册中间库中存储的注册信息与数据源应该是紧耦合关系,注册引擎定时扫描,自动更新数据注册信息,实现DRC数据注册库与数据源同步。
结构化数据注册引擎定时任务调度采用定时任务框架Quartz。Quartz支持根据时间间隔来调度任务,实现了采集注册任务和触发器的多对多的关系,还能把多个采集注册任务与不同的触发器关联。Quartz的工作原理如图4所示。

图4 Quartz的工作原理图
在DRC数据注册中心中填写结构化数据源相关参数后,需要配置定时扫描采集的时间间隔。Quartz中cron时间表达式支持配置秒、分、时、日、月、周、年。由于需要注册的数据库的数据更新频率不同,注册引擎结合cron时间表达式能够完成复杂的定时规则,灵活解决注册信息定时同步的问题。
3 实验与结果分析
3.1 实验环境
本文的实验环境通过搭建服务器集群,将DRC数据注册中心与结构化数据注册引擎,以及需要进行注册测试的各类型数据库安装部署在集群各节点上。structured-01上部署DRC数据注册中心,structured-02上部署结构化数据注册引擎,structured-03上部署各类型测试数据库。DRC核心组件工作正常,注册引擎功能可用。集群及各节点的硬件配置如表6所示。

表6 节点的硬件配置
3.2 测试数据准备
为了有效测试结构化数据注册引擎,设置不同数据库类型的结构化数据源进行采集注册,包括MySQL、Oracle、SQL Server、达梦、PostgreSQL、DB2、Hive共7种类型的结构化数据。通过IntelliJ IDEA开发工具内置的数据库连接模块,测试各类型数据库的连接情况,数据库连接正常。连接详情如图5所示。
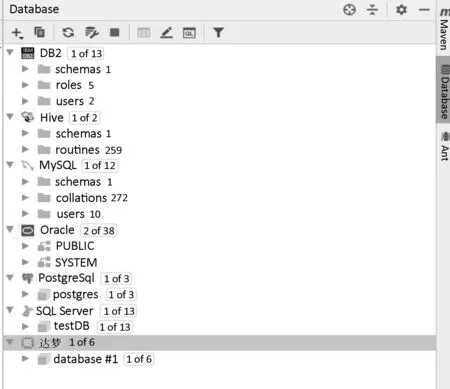
图5 测试数据库连接详情
3.3 测试及结果分析
本次测试对结构化数据注册引擎的注册功能、注册性能进行综合测评。
3.3.1 注册功能测试
启动部署的结构化数据注册引擎,通过DRC数据注册中心来配置结构化数据注册任务,填写数据源的相关参数,选取需要注册的数据库类型,设置定时扫描的时间间隔,如图6所示。
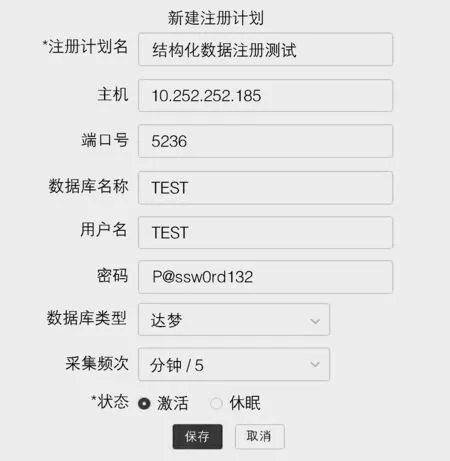
图6 注册任务配置
点击保存后,通过HTTP请求,将注册任务参数传递给注册引擎。注册引擎接收参数后,首先对数据源进行自动测试连接,连接成功后,按照结构化数据统一注册标准进行结构化数据注册信息的采集,若测试连接失败,则将异常信息报告给DRC数据注册中心。注册信息采集完成后,传输到汇集层消息中间件中,结构化数据注册信息采集过程日志部分展示如图7所示。

图7 结构化数据注册信息采集过程日志部分展示
注册信息注册层信息提取模块实时监听消息中间件中指定Topic的偏移量变化,感知到偏移量变化后,注册模块从Topic中修复结构化数据注册信息,通过质量对标流程,核查注册信息是否满足标准。满足标准的注册信息将写入DRC数据注册库中。经过实验测试,7种类型的数据库均采集注册成功,可在DRC数据注册中心可视化界面进行查看,如图8~图10所示。图8展示数据库的注册信息列表,图9展示数据库表的注册信息列表,图10为部分数据表字段注册信息列表。

图8 DRC中数据注册信息列表展示

图9 DRC中数据表注册信息列表展示

图10 DRC中数据表字段注册信息列表展示
由于注册的数据库类型较多,这里选择一种具有代表性的结构化数据作详细注册信息项展示,如图11~图13所示。图11展示达梦数据库的详细注册信息项,图12展示达梦数据库表的详细注册信息项。图13展示达梦数据表的典型字段详细注册信息项。

图11 达梦数据库的详细注册信息项

图12 达梦数据库表的详细注册信息项
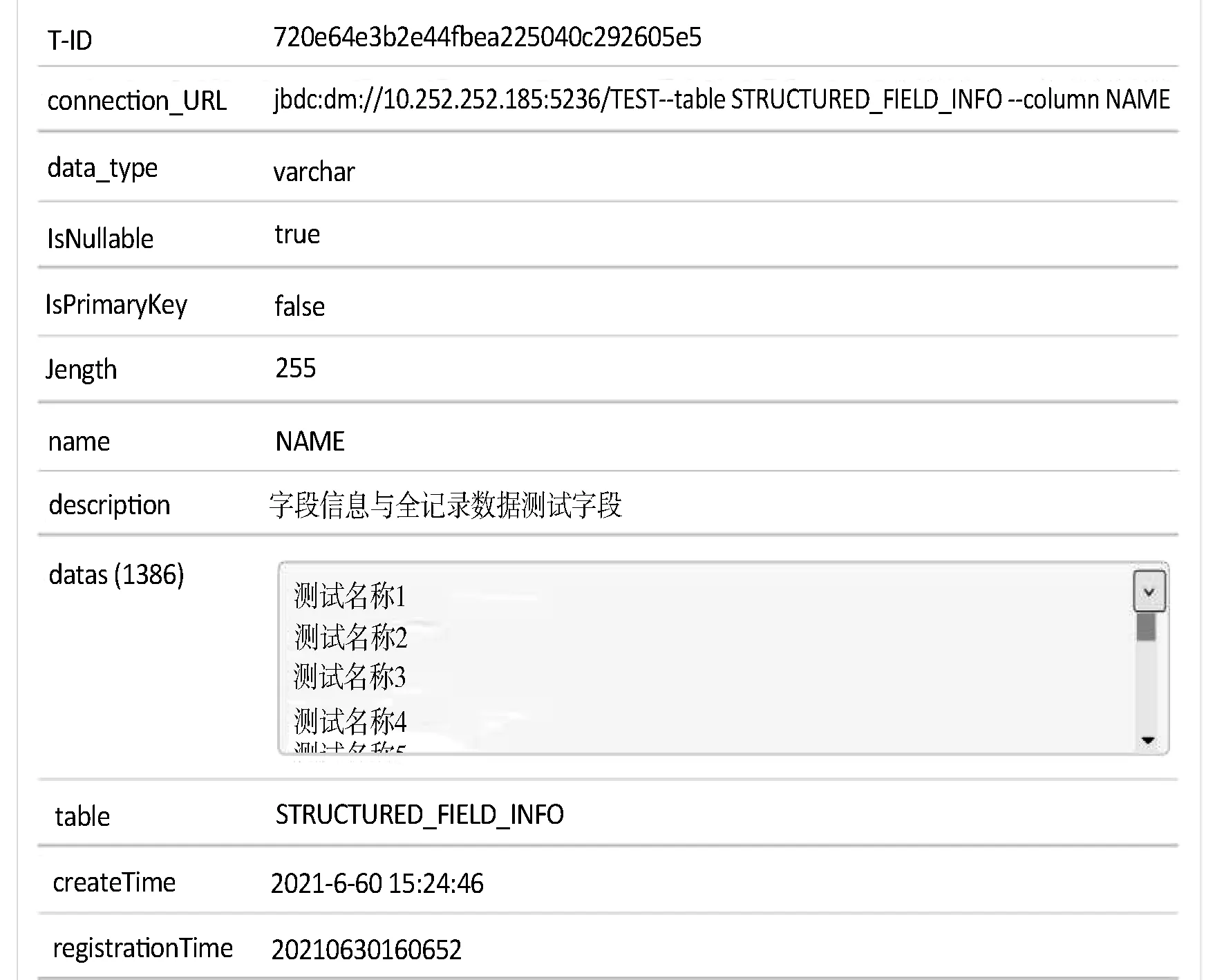
图13 达梦数据表典型字段的详细注册信息项
3.3.2 注册性能测试
结构化数据注册引擎性能测试从2个方面进行,测试内容包括不同类型数据库的平均注册耗时和相同数据库类型不同表数量的平均注册耗时。
表7展示的是对不同类型数据库多次采集注册信息的平均注册耗时。

表7 不同类型数据库的平均注册耗时
由表7可知,除Hive数据库以外,其他6种类型数据库平均注册耗时均在1 s左右。由于Hive的结构较其他类型数据库来说会更复杂,导致平均注册耗时会略长。同时JDBC技术对常用关系型数据库与国产达梦数据库的适配性更好,平均注册耗时会更短。
图14和图15展示相同数据库类型不同表数量的平均注册耗时,选取达梦数据库与MySQL数据库作实验测试。

图15 达梦数据库不同表个数的平均注册耗时
由图14、图15可以看出,在数据库类型相同的情况下,随着数据库中表数量的增加,数据库的平均注册耗时呈现增长趋势,但增长时间幅度不大。一般情况下,数据库中表个数在100个以内,结构化数据注册引擎基本满足注册性能要求。
4 结束语
基于实验结果与分析,本文所设计的结构化数据注册引擎能够按照结构化数据统一注册标准对分布式结构化数据源进行采集注册,针对常用的数据库与国产数据库也能实现自动注册。注册引擎与DRC数据注册中心交互状态稳定,可以实现结构化数据的采集注册任务,满足数据注册的高效性、可靠性,同时通过对结构化数据注册的性能测试,可知注册引擎在性能上能达到用户性能需求,为DRC数据注册中心的结构化数据注册信息管理和应用奠定坚实的基础,为更深一步的理论和实践研究提供支持。
结构化数据注册引擎今后的改进与优化可以从2个方面进行,一方面是采用微服务架构进行总体设计,将注册引擎各层次的功能模块全部拆分为微服务,实现快速部署与可拓展性、可维护性;另一方面,改进注册信息同步模块,需要深入研究各类型数据库的实时同步更新技术,替换定时扫描。
猜你喜欢
军民两用技术与产品(2021年2期)2021-04-13
房地产导刊(2020年12期)2021-01-14
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
中国人民公安大学学报(自然科学版)(2020年1期)2020-05-15
人民交通(2020年4期)2020-04-16
小型微型计算机系统(2019年3期)2019-03-13
计算机与生活(2018年3期)2018-03-12
商周刊(2017年22期)2017-11-09
兵器装备工程学报(2012年6期)2012-09-12
