
基于DVMD降噪的旋转机械故障诊断
2022-09-17 07:32尹逊龙牟宗磊王友清
控制理论与应用 2022年7期
尹逊龙牟宗磊王友清
(1.山东科技大学电气与自动化工程学院,山东青岛 266590;2.北京化工大学信息科学与技术学院,北京 100029)
1 引言
旋转机械作为现代机械设备的重要组成部分,在工业中有着重要作用.由于机械设备的自动化、智能化水平不断提高,旋转机械的内部结构也更加复杂,并且此类设备长期工作在恶劣环境中,齿轮、轴承等旋转机械的核心零件极易发生损坏,若未能及时诊断出故障,可能导致设备无法正常运转,甚至引发重大事故[1].因此,人们对设备故障的监测和诊断技术的可靠性提出了更高的要求.
通过实时采集和分析机械设备的振动信号,可以监测设备的健康状况.但是当设备工作在恶劣的工业环境中,能够反映故障信息的特征分量往往被噪声所淹没[2],并且旋转机械结构复杂,产生的振动信号具有多分量和调幅调频特性[3],故障分量通常混杂在无关分量中,因此,在设备运转过程中,包含在振动信号中的无关分量和噪声难以剔除.为了解决上述问题,不少学者改进信号分解方法,对故障信号进行了降噪处理,例如:小波分解(wavelet decomposition,WD)、经验模态分解(empirical mode decomposition,EMD)和局部均值分解(local mean decomposition,LMD)[4-5]等.相较于WD,EMD和LMD,变分模态分解[6](variational mode decomposition,VMD)在分解信号的过程中能够抑制噪声的干扰,并且分量之间能够有效避免模态混叠[7].通过VMD分解,噪声被分配到每个分量中,如果直接对每个分量进行降噪处理,可能会剔除有效的故障分量[8].因此,将VMD算法改进为深度VMD(depth VMD,DVMD)降噪方法,首先将VMD分解得到的分量进行相关分析,对相关度较低的分量进行降噪处理,再与其余分量重构,然后对重构的信号进行多次VMD分解、分量降噪与重构,实现故障分量的噪声转移至相关度低的分量.噪声在分量中剔除后,能够提高故障特征的敏感性,从而提高故障诊断的精度.
故障诊断是根据不同故障特征之间的差异,实现对故障的区分.理论上如果信号通过降噪处理,增强信号表达特征的能力,再基于机器学习提取有效的故障特征,选取合适的分类器,就能从本质上提升故障诊断的性能[9].在传统的机器学习中,人工提取多尺度排列熵[10](multi-scale permutation entropy,MPE)特征不仅能够反映信号的复杂性,并且将单一维度的故障信息扩展至多维,从而增强分类器对故障特征的敏感度.相较于传统机器学习的特征提取方法,深度学习方法则是通过训练大量的数据,自动建立故障特征到故障类型的非线性映射[11],进而提高诊断模型的泛化能力.从2015年提出的Resnet模型[12],到2019年提出的Efficientnet模型[13],再到2020年提出的Regnet模型[14],深度学习在故障诊断中的作用也越来越重要[15].将故障信号与深度学习模型有机结合,提高强噪声、非平稳信号的诊断精度已成为当前研究的热点[16].轻量级梯度提升机(light grandient boosting machine,LightGBM)使用集成学习的方式[17],该分类器通过直方图方式对连续特征值进行分段,以节省运行内存[18],并且具有高效的运行速度和准确的分类效果.因此,将提取的故障特征放入LightGBM中进行训练,能够以高效的运行速度得到准确的诊断模型.
综上,本文提出DVMD降噪方法有效剔除振动信号的噪声.在不同的降噪深度下,对信号进行分解、分量降噪和重构,实现了噪声在分量之间的转移与剔除,进而增强了信号表达特征的能力.使用风力涡轮传动系统的齿轮箱数据集进行验证,结果表明,无论是采用传统的人工特征提取方式,还是通过训练深度学习模型自动提取特征,诊断效果均有提升.
2 基于深度变分模态分解的降噪方法
2.1 DVMD的降噪原理
VMD是一种自适应、非递归的模态变分信号处理方法[19],将该算法改进为DVMD降噪方法的步骤如下: 假设长度为N输入信号x(t)经过VMD处理后得到了K个IMF分量,将每个模态分量uk(t)经过Hilbert变换后得到解析信号,解析信号与对应的中心频率ejωkt项相乘,将各模态分量的频谱转移至基频带

式中:δ(t)为狄拉克分布,“*”为卷积运算.
约束变分问题表达式如下:

式中:uk(t)为输入信号经VMD分解得到的第k个模态分量,ωk为第k个模态分量的中心频率.
为得到最优的uk(t)和ωk,引入了增广拉格朗日函数ζ[6],如式(3)所示.用交替方向乘子法进行迭代优化得到ζ的极小值点,从而解决式(2)的最小化问题.

式中:α表示带宽参数,λ(t)表示拉格朗日乘子.DVMD降噪方法具体实施过程如下:
步骤1,←0.
步骤2迭代次数nn+1.
步骤3ForkK+1
对所有的ω≥0,更新泛函

对所有的ω≥0,更新
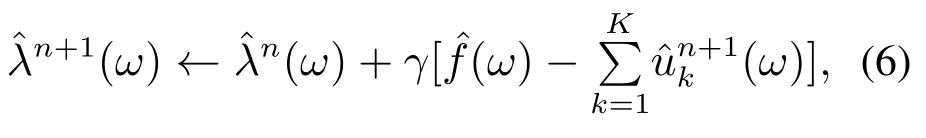
式中γ表示噪音容限参数.当信号存在强噪声时,可设定γ0,能实现良好的去噪.
步骤4重复执行步骤2到步骤4,直到满足迭代约束条件

步骤5计算模态分量uk(t)与输入信号x(t)的皮尔逊相关系数

步骤6设置相关系数阈值,对于阈值以下的uk(t)进行空间重构,得到Hankel矩阵H

步骤7对H矩阵进行奇异值分解[20](SVD),令mN-n+1,则H ∈Rm×n,存在矩阵U ∈Rm×m与矩阵V ∈Rn×n,使得HUΣVT,其中Σ ∈Rm×n,并且Σdiag{σ1,σ2,···,σk,σk+1,···,σn},选取前k个奇异值σi较大的SVD分量进行重构,得到经过降噪处理的分量uk(t).
步骤8将所有分量重构,重复执行步骤1到步骤8,直到满足预设的降噪深度L,输出经过DVMD降噪处理的信号

DVMD降噪原理如图1所示.在VMD的分解过程中,K和α对VMD分解效果影响较大.若采用经验法预设参数,参数值设置不合适,可能会导致模态混叠或者过度分解.所以,本文采用SSA算法优化VMD参数,实现自适应分解.

图1 DVMD 降噪原理图Fig.1 The principle diagram of DVMD
2.2 基于麻雀算法优化VMD参数
麻雀算法(sparrow search algorithm,SSA)是一种以麻雀的觅食和躲避天敌的社会行为作为背景提出的群智能优化算法,第2.2节主要参考文献[21].SSAVMD算法原理如下.
设置麻雀优化VMD参数的搜索空间如下:

式中:n为麻雀的数量,[z1,1z2,1···zn,1]T为参数K的搜索空间,[z1,2z2,2···zn,2]T为参数α的搜索空间,在2 维搜索空间中有n只麻雀,则第i只麻雀在搜索VMD参数空间的位置为
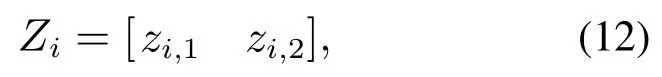
式中zi,j为搜索空间中第i只麻雀的第j个参数位置,i1,2,···,n,j≤2.VMD参数以整数形式在麻雀种群中进行搜寻,参数将以发现者、加入者和预警者角色随机更新.
发现者的数量一般占麻雀总数量的10%~20%,其位置更新公式为
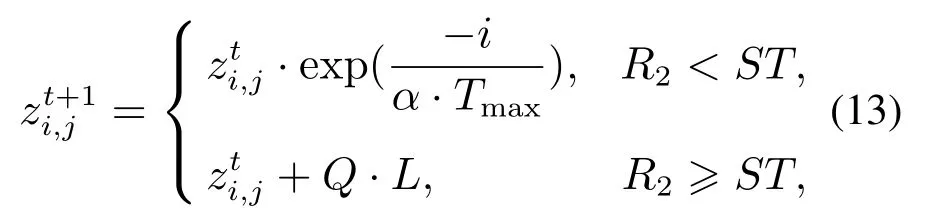
式中:t为当前迭代次数,Tmax为最大的迭代次数,α为(0,1]之间的均匀随机数,Q为服从标准正态分布的随机数;L是维度为1×d,元素均为1的向量,R2∈[0,1]和ST ∈[0.5,1]分别为预警值和安全值.
加入者的数量一般占麻雀总数量的80%~90%,其位置更新公式为

预警者的数量一般占麻雀总数量的10%~20%,其位置更新公式为
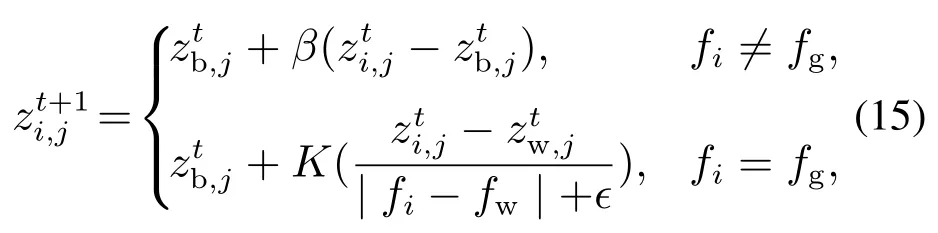
式中:β为位置更新的步长,K ∈[-1,1],表示麻雀位置更新的方向,ϵ为一个极小的参数值,防止分母为0,fi为第i只麻雀的适应度值,fg和fw分别为当前麻雀种群的最优和最劣适应度值.为提高SSA的搜索性能,避免麻雀长时间停留边界导致陷入局部最优解,将边界进行改进,即

式中:zmin为最小边界值,zmax为最大边界值,λ为[0,1]之间的一个随机数.
SSA优化VMD参数需要确定一个适应度函数,依据适应函数的值寻找最优的K和α.本文考虑了原始信号与重构信号的误差,VMD只有分解出原信号所包含的有效分量,才能避免模态混叠和虚假分量,使用原始信号能量与分量能量差的绝对值作为适应度函数.函数值代表原始信号与重构信号的能量差,适应度值越小,误差越小,即

式中:E0和Ev分别为原信号的总能量与各模态分量的总能量,x(t)为输入信号,uk(t)为经过VMD分解得到的模态分量,K模态分量个数,F为适应度函数,在麻雀搜寻最优的参数过程中,通过比较个体与群体的适应度值,更新麻雀位置,最终找到最优的K和α.SSA-VMD流程如图2所示.
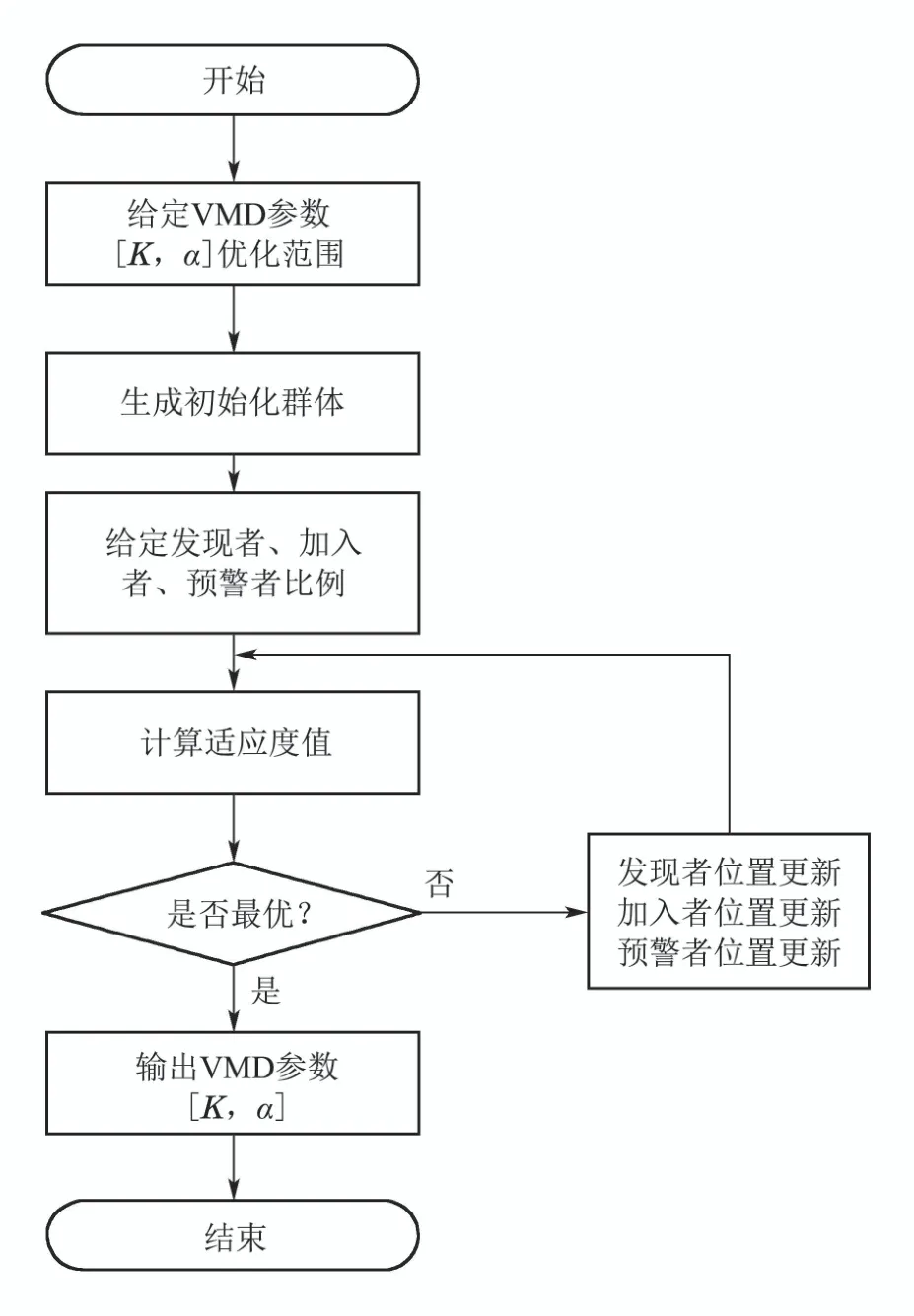
图2 SSA-VMD流程图Fig.2 The flow chart of SSA-VMD
3 算法有效性分析
首先构造应用验证所使用的仿真测试信号,验证SSA-VMD分解效果与DVMD降噪效果,仿真测试信号如下式:
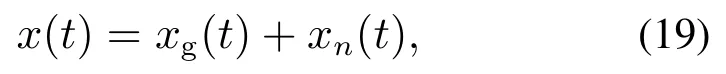
各部分信号为
式中:x(t)为仿真测试信号,xg(t)为具有多分量特性的有效信号,r(t)为高斯噪声.fk为各有效分量的频率,Ak和β分别为xg(t)和xn(t)的幅值.将频率预设为1 Hz,100 Hz,200 Hz,300 Hz,仿真测试信号的时域和频域如图3所示.

图3 仿真测试信号Fig.3 The signal for simulation tests
3.1 基于优化算法的VMD自适应分解
将SSA算法的麻雀数量设置为10,经过30次迭代更新后,得到的最优参数组合为K5,α644,SSAVMD分解仿真测试信号的效果,如图4所示.

图4 信号自适应分解频谱图Fig.4 Spectrum of signal adaptive decomposition
图4为各模态分量的幅频分布,从图中可以看出,分量分别在集中在1 Hz,100 Hz,200 Hz,300Hz的预设频率附近,并且随频率的增加,模态分量所包含的噪声随之增加,处在最高频段的无关分量包含大量的高频噪声.所以通过SSA算法优化VMD参数,得到了较为理想的模态分量,将具有多分量特性的信号分解成多个有效分量,可以对分量做进一步分析与降噪处理.
3.2 DVMD降噪性能分析
使用DVMD降噪方法对无关分量进行降噪和剔除,根据式(21)反映在不同深度下的降噪效果,即

式中:P为信号的功率,Ps为原始信号功率,PD为DVMD降噪信号的功率,Pn为噪声功率.若nr值越接近1,则说明剔除噪声的效果越好;若nr值小于1,则未能完全剔除噪声;若nr值大于1,则说明在降噪过程中,剔除了输入信号的有效分量.nr值随降噪深度的变化曲线如图5所示.
从图5可以看出,降噪效果的nr值随深度的增大而增大,并且逐渐趋向1,在降噪深度为15时,nr值超过0.9,值随深度的变化也趋于平缓,说明DVMD降噪方法在不同深度下,不仅有效地剔除了噪声,而且保留了信号的有效分量.

图5 不同深度下的降噪效果Fig.5 Noise reduction effect in different depths
DVMD降噪方法的原则是根据皮尔逊相关系数判断出无关分量,将处在无关分量的噪声剔除,再经过重构,再次分解后将有效分量的噪声转移至无关分量,实现噪声的转移.DVMD降噪前后分量的幅频分布,如图6所示.
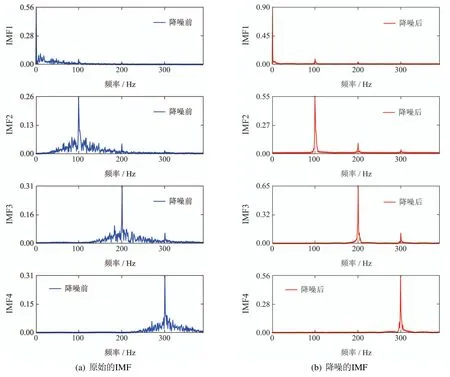
图6 各分量降噪前后对比Fig.6 Comparison of each component before and after denoising
对比图6(a)(b)各模态的幅频分布,从图6(a)中可以看出,首次SSA-VMD分解得到的模态分量由于未经过SVD降噪,因此噪声混杂在各分量中,但是,经过深度降噪后,图6(b)各分量的幅频分布更加明显,因此信号表达特征的能力也得到增强.
4 诊断试验
通过DVMD降噪方法对故障信号进行预处理,提高信号表达自身故障信息的能力,从而提升故障诊断的精度.试验数据来自Spectra Quest公司生产的风力涡轮传动系统诊断试验平台,所使用的振动信号分别为正常信号、缺齿信号、断齿信号和裂齿信号.为验证所提降噪方法能否提升信号在不同维度下表达特征信息的能力,通过传统的特征提取方式和训练深度模型的特征提取方式,分别对所提方法的有益性进行验证.故障诊断流程如图7所示.

图7 故障诊断流程Fig.7 The process of fault diagnosis
故障诊断过程如下: 首先,分别提取信号的多尺度排列熵特征或者时频图特征;然后按照一定比例将特征数据分为训练数据集和测试数据集,再把训练集放入LightGBM分类器中进行训练,得到用于故障诊断的模型,将测试集放入诊断模型,预测各测试集数据的故障类别;最后将测试集预测类别与真实类别进行比对,得到模型的诊断精度.
4.1 DVMD降噪预处理
由于工业环境复杂,采集的工业信号包含大量噪声,但是试验平台采集的信号较为干净,仅包含少量的噪声,为了模拟更切合实际的工业环境,检验本文DVMD降噪方法的效果,加入了信噪比为1的噪声.考虑到降噪的效果与效率,降噪深度设置为20.降噪前后,4种试验信号的幅频分布如图8(a)和(b)所示.
从图8可以看出,正常信号的幅频在50 Hz附近较为明显,当齿轮发生单点局部损坏时,即缺齿、断齿、裂齿等不同类型的损坏,其幅频分布产生了不同程度的变化,例如,缺齿故障产生了周期性冲击信号,冲击幅频分布在90 Hz附近.
通过图8(a)不难看出,部分故障幅频信息被噪声所淹没,进而难以区分故障之间的差别,但是通过图8(b)可以看出,经过DVMD降噪后,不仅剔除了包含在信号中的噪声,并且表达此类故障的幅频信息变得更加明显.

图8 降噪前后频谱Fig.8 Spectrum before and after denoising
4.2 基于MPE与LightGBM故障诊断
在本节诊断试验中,人工提取4种信号的多尺度排列熵特征,每种信号的样本数量为100,特征尺度为21,降噪前后特征值随尺度的变化如图9(a)(b)所示.
降噪前MPE特征值变化如图9(a)所示,4种信号的特征值变化整体呈下降趋势,并且每一尺度下的不同特征值之间的距离较近,说明在噪声的影响下,不同故障信号的差异被噪声淹没,导致故障特征的敏感性不高.但是经过DVMD降噪后,MPE特征的变化如图9(b)所示,从图中可以看出,在不同尺度下,降噪后各故障特征值之间的距离变大.说明不同故障之间的差异更加明显,进而提高了特征的敏感程度.
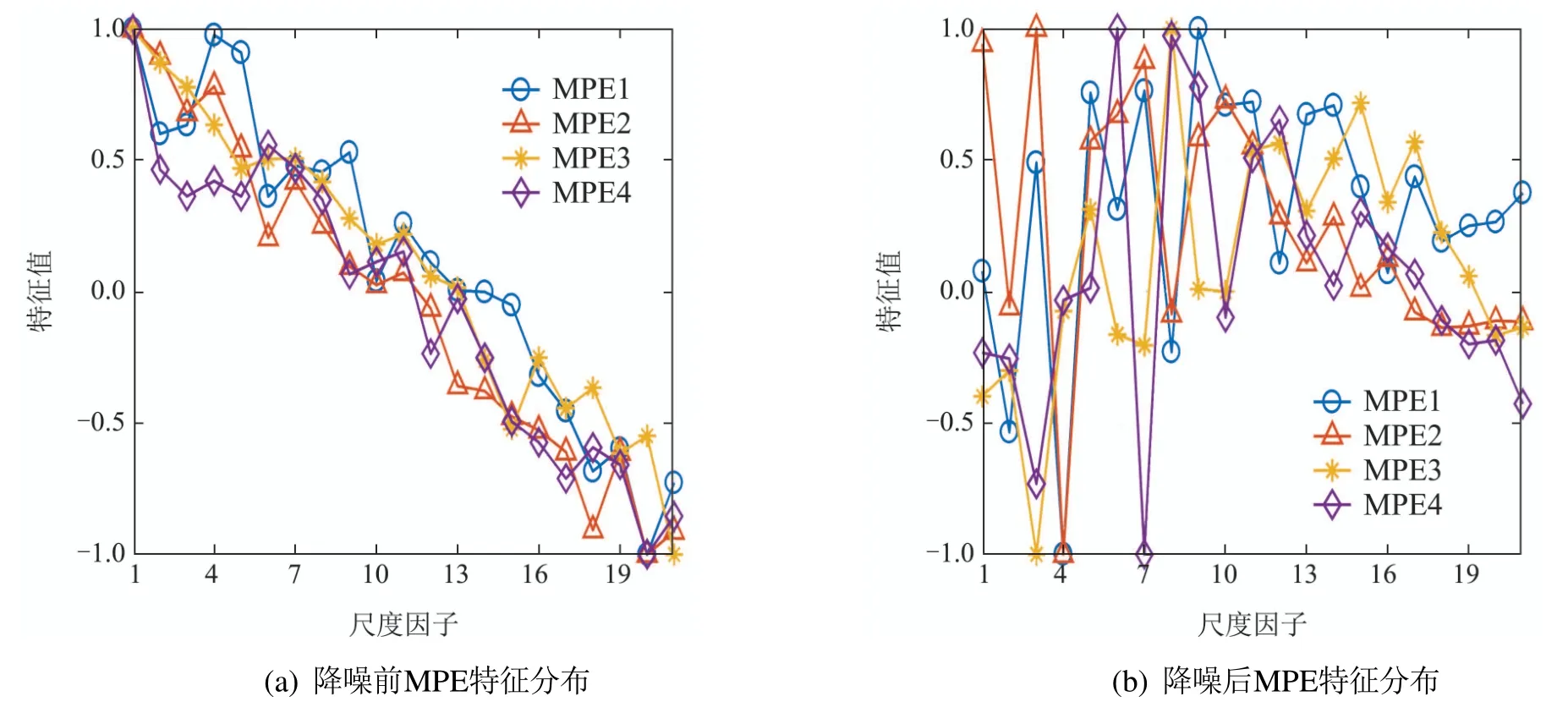
图9 MPE特征分布Fig.9 Distribution of MPE feature
本节取280组样本作为训练数据集,取120组样本作为测试数据集.由于MPE特征前10尺度的差异较大,对诊断效果的影响也较大,所以将前10个尺度下的训练集特征放入LightGBM分类器中进行训练,诊断结果如图10所示.
图10(a)中,提取未降噪信号的MPE 特征,通过LightGBM 训练得到的诊断模型,诊断精度只有64.17%.图10(b)中,信号经过DVMD降噪后,分类器训练出的模型的诊断精度达到100%.通过试验结果可以得出,DVMD降噪方法对信号进行预处理,显著提升了模型的诊断精度,该方法应用在基于传统机器学习的故障诊断领域,具有一定的应用潜力.

图10 基于MPE的故障诊断结果Fig.10 The results of fault diagnosis based on MPE
4.3 基于深度学习模型与LightGBM的故障诊断
与传统的特征提取方式不同,深度学习是根据大量信号样本建立故障特征与类别的映射,实现对异常信号的诊断[22].因此,本节试验选取4000组信号样本,其中2800组作为训练数据集,1200组作为测试数据集.深度学习模型通常是提取图像的二维特征图,通过“cmor”小波基[23]将降噪前后的信号转换成时频图,如图11所示.
受噪声的影响,图11(a)的时频分布较为混乱,该图能够表达的故障时频信息也较为模糊.经过DVMD降噪处理后得到图11(b),图11(b)的时频信息分布有序,并且能够较为清晰地表达故障的时频信息.
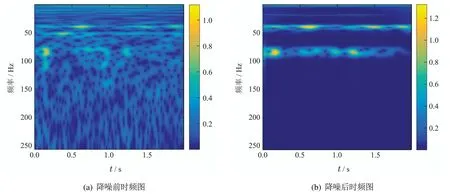
图11 信号的时频图Fig.11 The time-frequency diagrams of signal
使用Resnet,Efficientnet和Regnet深度学习模型分别提取时频特征,通过LightGBM训练和预测得到各模型的诊断结果与精度,如图12 和表1 所示.Resnet-LightGBM诊断模型的精度由90.75%提升至96.00%,Efficientnet-LightGBM 诊断模型的精度由95.25%提升至95.50%,Regnet-LightGBM 诊断模型的精度由83.58%提升至89.17%,通过试验结果可以得出,DVMD降噪方法提高了信号表达故障时频信息的能力,所以所提降噪方法应用在基于深度学习的故障诊断方面具有一定的实用价值.

表1 不同深度学习模型诊断结果对比Table 1 Comparison of diagnosis results of different deep learning models


图12 基于深度学习模型的故障诊断结果Fig.12 The results of fault diagnosis based on deep learning model
通过上述试验可以看出,无论是通过传统的人工特征提取方法,还是以“黑盒”的形式训练深度学习模型,振动信号经过DVMD降噪方法处理后,其表达自身故障信息的能力得到加强,该方法提升了故障诊断模型的泛化能力.
5 结论
本文基于深度变分模态分解DVMD降噪方法,实现了对振动信号的深度降噪.通过对不同深度下的信号进行降噪,验证了DVMD降噪方法能有效剔除混杂在信号中的噪声,并且在降噪过程中具有良好的鲁棒性.为验证所提降噪方法对故障诊断模型的影响,本文将所提方法应用于传统的机器学习方法和深度学习方法中,并在诊断效果方面进行试验验证,验证结果表明,经过DVMD降噪处理后,提取的样本特征能够提高诊断模型的泛化能力.因此,本文所提DVMD降噪方法作为一种信号处理方式,提高了信号表达自身信息的能力,故障诊断的效果进一步提升,将该方法应用于旋转机械的故障诊断具有一定的潜力和价值.
猜你喜欢
一重技术(2021年5期)2022-01-18
当代陕西(2019年19期)2019-11-23
作文小学中年级(2019年10期)2019-11-04
智族GQ(2019年9期)2019-10-28
英美文学研究论丛(2018年1期)2018-08-16
电子制作(2018年10期)2018-08-04
文理导航·科普童话(2016年7期)2017-02-04
北京航空航天大学学报(2016年6期)2016-11-16
山东青年(2016年1期)2016-02-28
汽车电器(2014年5期)2014-02-28
