
改进SRGAN 的图像超分辨率算法
2022-09-18 04:36刘嵩山王华军李特李光志万军马瑜
西华大学学报(自然科学版) 2022年5期
刘嵩山,王华军,李特,李光志,万军,马瑜
(成都理工大学计算机与网络安全学院,四川 成都 610059)
在大数据时代下,图像数据被人们广泛使用,但是图像在采集的过程中,受设备性能、成本、图像压缩等一系列因素的影响导致图像的成像效果并不理想;因此,无法满足在一定特殊场景下的需求,如卫星遥感[1]、医学[2]、生物特征识别[3]等。
图像的超分辨率重建(super-resolution,SR)就是用低分辨率图像生成对应的高分辨率图像的过程。传统的SR 算法大多是基于插值的超分辨率重建算法,这类算法的优点是原理简单,速度较快。但是其高度依赖于邻域信息,且重建后的图像较为模糊,甚至出现振铃现象。传统的机器学习算法通过对一组包括HR 图像和LR 图像的样本集合进行训练,学习得到一个联合系统模型。但是这类方法高度依赖于字典设计,且计算复杂、实时性不高。近年来,随着深度学习技术的发展,特别是卷积神经网络(CNN)重新被人们重视,越来越多的深度学习算法被用于SR 算法中。首次将CNN 用于SR 算法的是SRCNN[4],这种方法比传统方法效果更好,但是计算量大,进而导致训练速度慢。2015年,随着何凯明团队的ResNet[5]问世,很好地解决了深度学习算法训练中梯度消失的问题。2016 年Kim等[6-7]首次将残差网络运用于SR 算法中,这一举措解决了收敛速度慢的问题,优化了模型,图像重建后的质量进一步提升。2017 年,Ledig等[8]首次将GAN 应用于图像超分辨率领域,提出了SRGAN。SRGAN 的网络模型由生成器和鉴别器两个部分构成。生成器部分将LR 图像重建成对应的SR 图像,鉴别器部分将生成器生成的高分辨率图像SR 与真实的高分辨率图像HR 进行比较然后给出图像质量分数,当生成器生成的SR 图像能够使鉴别器分辨不出真的HR 图像和生成器重建的SR 图像时,表明网络模型的重建效果很好。
基于深度学习图像超分辨率的重建算法取得了很好的效果,但是依然存在以下几个问题:(1)SRGAN网络模型结构本身参数数量庞大,包含生成器和鉴别器两个部分;(2)SRGAN 的生成器网络模型中没有注意力机制,导致图像特征表达能力不足;(3)以LeakyReLU 函数作为激活函数的激活层对小于等于0 的图像信息数据泛化能力不够,甚至可能出现梯度爆炸。
针对以上问题,本文提出一种基于SRGAN 的图像超分辨率重建算法SRGAN-E。该算法通过添加轻量级注意力机制,在不大幅度增加模型复杂程度的情况下提升模型中生成器的部分性能,并优化鉴别器中激活函数,以获得更好的准确性和泛化能力。改进后的算法在DIV2K 数据集进行训练,将Set5、Set14、BSDS100、Urban100作为测试集,实验结果表明,与SRGAN 相比SRGAN-E的PSNR和SSIM 值均有提高。
1 SRGAN 算法结构
SRGAN 网络模型由两部分构成。第一部分是生成器,生成器的网络模型为SRResNet,网络结构图如图1所示,输入为低分辨率图像LR,LR∈RM×N×3,低分辨率图像通过卷积层、激活层后,得到多张特征图,特征图依次经过B 个残差块,残差块由卷积层、BN 层、PReLu 激活层组成。残差块将前面得到的特征图进行深层次提取得到新的特征图,然后进行上采样放大图像,最后通过卷积层将特征图维度转换为 3,输出成高分辨率图像SR。
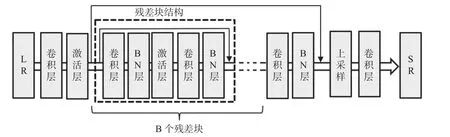
图1 生成器模型
SRGAN 算法的第二部分是鉴别器。鉴别器的网络模型结构图如图2所示,分别将重建后的高分辨率图像SR和真实高分辨率图像HR 输入鉴别器,高分辨率图像通过卷积层后,进入激活层,然后经过若干个卷积层、BN 层、激活层后,将特征图进行平均池化,然后经过两次卷积层,激活层后输出高分辨率图像的质量分数。
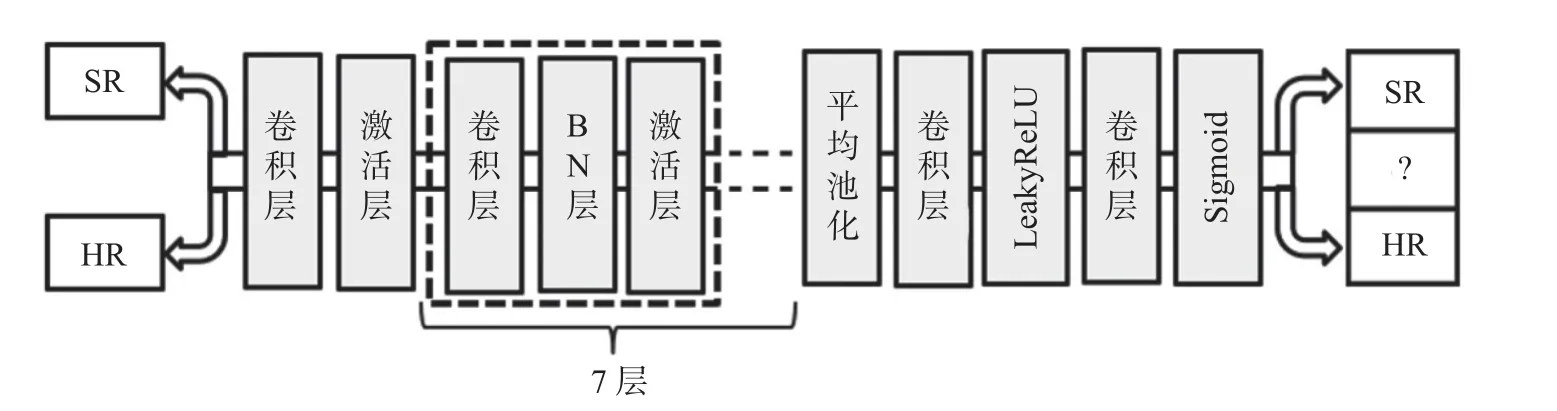
图2 鉴别器模型
SRGAN 算法很好地将GAN 运用于图像的超分辨率重建,在Set5 等测试集上有很好的表现,但是也存在参数数量巨大且缺乏注意力机制等问题。本文在SRGAN 的基础上进行改进,提出了一种图像超分辨率重建算法SRGAN-E。
2 改进的SRGAN 图像超分辨率重建算法
2.1 基础网络的改进
2.1.1 删除BN 层,提高图形的重建效果
BN 层在卷积神经网络中起着重要作用,不但可以加快训练速度,还具有正则化的效果。BN 层的存在使得卷积神经网络可以去掉使用频繁的dropout 层,L1 正则化或L2 正则后,也同样具备防止过拟合的效果,进而提高模型的训练精度。但是在图像超分辨率重建过程中,BN 层的存在会降低图形的重建效果。陈文文[9]详细阐述了BN 层降低图形的重建效果的具体原因:BN 层会对输入到网络的每个批次的图像块做归一化处理,归一化操作会破坏图像的色彩、亮度等信息;BN 层会使网络在每次迭代时都去学习适应不同的分布,导致网络的训练速度大大降低。Lim等[10]的论文中也证明了BN 会增加时间复杂度,减缓训练速度。因此,本文在改进SRGAN 算法时为了提高图形的重建效果将删除BN 层。
2.1.2 引入一维卷积注意力机制,降低参数数量
自从神经网络重新进入人们的视野以来,基于卷积神经网络的算法不断创新也推动着计算机视觉技术的高速发展,如AlexNet[11]、ResNet[5]、ResNeXt[12]等。近年来,越来越多的科学家将注意力机制融入卷积神经网络,实践证明注意力机制在提升算法性能方面有着非常显著的效果。计算机视觉中的注意力机制可以分为3 种:一是通道域注意力,只关注图的空间位置关系,不关注通道,如SENet[13];二是空间域注意力,不关注通道中每个像素点的差异,对特征的所有通道进行加权,如STN[14];三是混合域注意力,既包含通道注意力,又包含空间域注意力,这样的注意力机制在实际应用中应用较为广泛,但是也因为其结构更加复杂导致模型的参数量增大进而导致网络训练困难,如CBAM[15]。
2020 年,WANG等[16]通过引入一维卷积提出了轻量级注意力模型ECA-Net,因为SRGAN 中参数个数太过庞大,本文将参考ECA-Net 的通道注意力进行模型的优化。CBAM 注意力机制虽然使得网络关注了上下文信息,但是CBAM 在过程中进行了通道压缩,使得网络在运算过程中舍弃了部分特征图信息,最终使得注意力机制的特征表达能力下降;因此,本文参考ECA-Net 设计的注意力机制直接对全局池化后的通道特征图进行一维卷积,并没有压缩特征图,使得特征图信息完全保留了下来,而且,在个过程中,也因为一维卷积而没有对整个特征图进行二维卷积运算使得参数数量不增反降。
2.1.3 改进残差块
加入注意力机制后的残差块如图3所示。首先使用全局平均池化和全局最大池化来聚合特征图F 的空间信息,生成的通道描述符分别为和,然后用卷积核长度为k的一维卷积来聚合该通道k个邻域内的信息,将卷积后的两个特征元素求和,然后通过Sigmoid 函数运算得到Mc(F)∈ Rc×1×1,计算过程如式(1)所示。
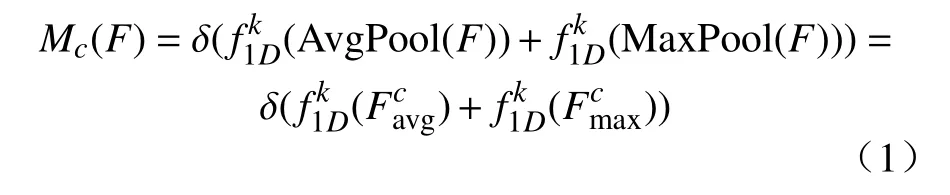
其中:δ是Sigmoid 函数;表示卷积核大小为k的一维卷积操作。Wang等[16]指出一维卷积核的大小k和通道数c 成正比,那么k和c之间的映射关系表示为

其中:最简单的映射是线性函数 φ(k)=γ·k-b;而通道数c 通常设置成2 的幂。根据线性函数扩展到非线性,因此将映射函数表示为
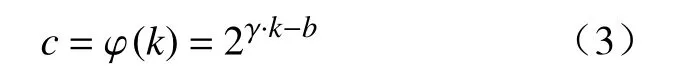
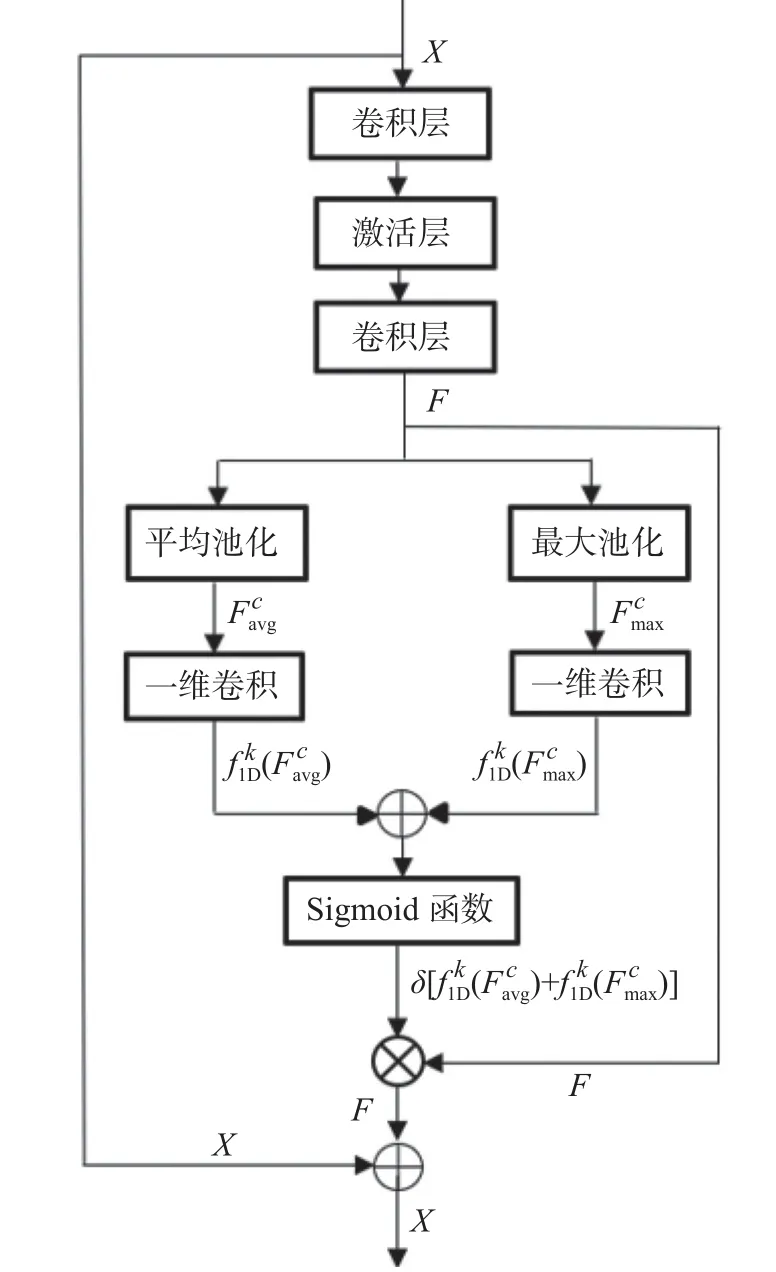
图3 改进后的残差块结构模型
根据上述函数推导出:
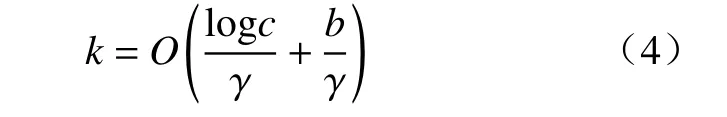
式中:c是特征图的通道数;O(x)表示与x最接近的奇数。通常γ取2,b取1,因此得到k的计算方式为
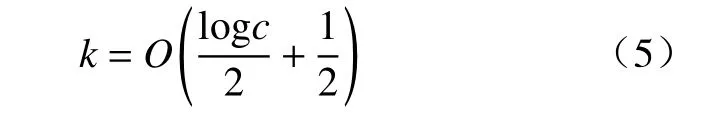
然后将式(1)中Mc(F)的结果乘到池化前的特征图上,这样的注意力机制便可以让模型自发地去注意图像的重点区域。最后为了防止出现梯度在深层网络中消失的问题,将进入残差块的特征图加到主干网络中,计算过程如式(6)、式(7)所示:
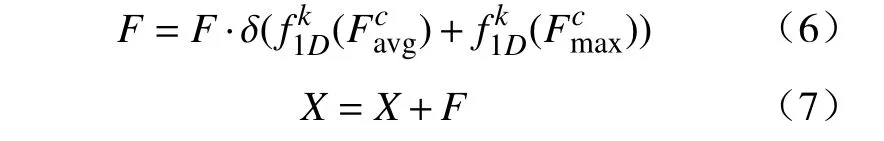
X为输入残差块前的特征图。
2.2 优选鉴别器中的激活函数
在SRGAN 中,鉴别器起着对重建后的图像进行鉴别的作用,其性能的好坏关系着最后重建后的图像的质量的好坏,在原SRGAN 中,使用LeakyReLU函数作为激活函数,其函数的形式如下:
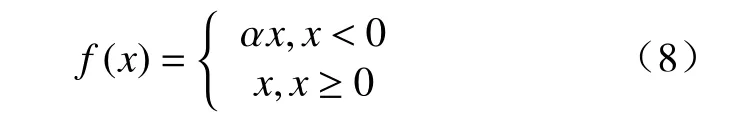
LeakyReLU 函数从ReLU 函数的基础上优化而来,相比较ReLU 函数而言,函数值在大于等于0的部分是一样的,在小于0 的部分,也存在斜率,而不是像ReLU 函数那样等于0,这样就解决了神经网络在反向传播过程中的梯度消失的问题。
且LeakyReLU 函数没有上限,这样,在大于0的部分也不会出现梯度消失。
但是,LeakyReLU 函数没有下限,且函数是单调递增,函数在0 点处的左导数和右导数不相等导致函数不光滑。针对以上缺点,本文选择将Mish[17]函数作为鉴别器的激活函数,Mish 函数的形式为
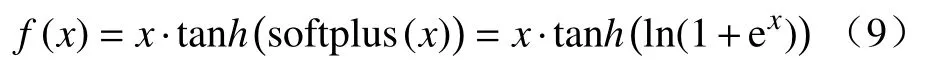
则根据函数计算出对应的导数为
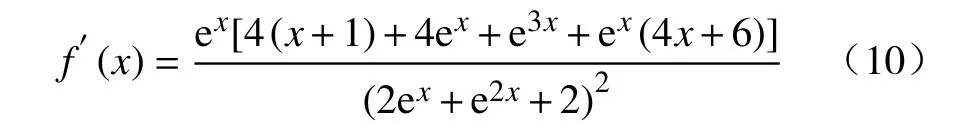
由式(10)可知,f′(-1.2)≈0,f′(x)在小于-1.2 的区间小于0,在大于-1.2 的区间大于0,则函数在0点附近会先递减再递增,函数在0 点附近的图像如图4所示,函数没有上限,最小值大约在-1.2 左右取得,约为-0.31。
首先,相比较LeakyReLU 函数,Mish 函数有下界,这一特点可以帮助模型实现强正则化效果。因为正则化的目的是防止过拟合,而如果激活函数没有下界,则在特征图中代表像素信息的数字在输入激活函数后可能会越来越小,从而导致网络权重在负方向上一直增大,最后导致网络中的神经元走向极端。
其次,Mish 函数并不像LeakyReLU 函数那样一直递增,而是先减小后增大。且在0 点的左半边小于0,这样使得输入的信息为较小的负数时,通过激活函数将信息适当放大;而当输入信息为较大的负数时,通过激活函数将信息适当缩小,这样就能很好地防止梯度爆炸。
最后,Mish 函数在0 点处连续,且左导数和右导数相等,使得函数在0 点处光滑,这一特性使函数避免了奇异性,神经网络在反向传播时,函数在0 点处依然可以求导,这样就使得模型具有很好的泛化能力。
综上所述,在鉴别器中我们选择将Mish 函数作为激活函数,且与生成器一样,去掉BN 层,鉴别器网络模型结构图如图5所示。
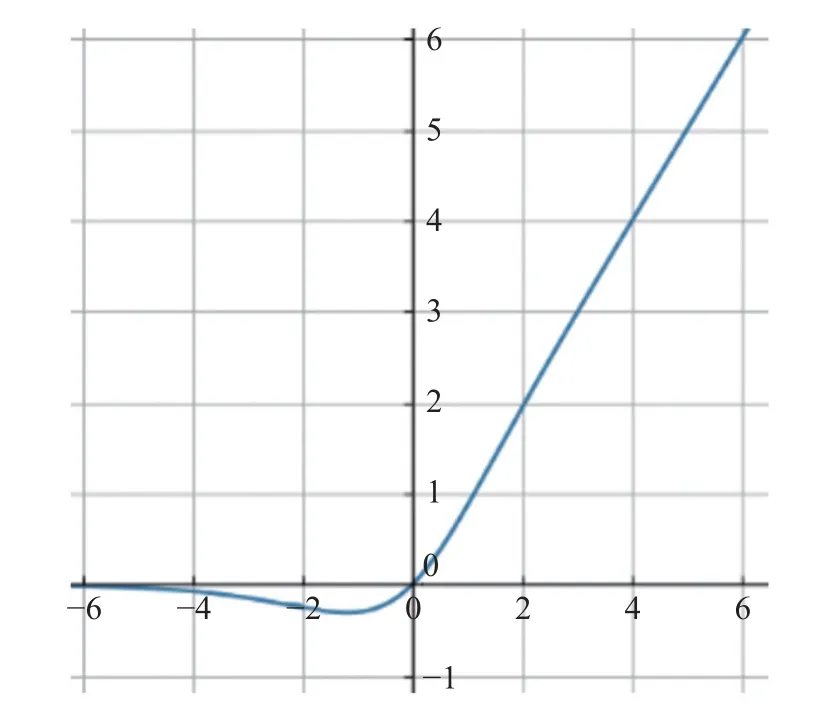
图4 Mish 函数图像
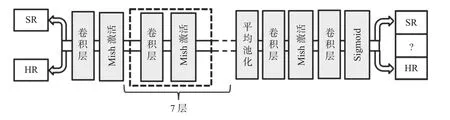
图5 改进后的鉴别器模型
3 实验结果和分析
3.1 实验环境
本文所使用的硬件环境的处理器是Intel(R)Xeon(R) Gold 5218 CPU @ 2.30 GHz,运行内存为125 G,显卡版本为NVIDIA GEFORCE RTX 2080Ti,操作系统为Ubantu20.04。整个实验基于深度学习框架pytorch 1.9 进行,实验环境是python 3.8,GPU加速软件为 CUDA 10.2.89和 CUDNN7.6.5。在训练阶段,使用Adam 优化器,学习率为1e-3,一共训练100 轮。损失函数为对抗损失和内容损失。
3.2 数据集
3.2.1 训练集
本文采用训练集是图像超分辨率领域的经典数据集DIV2K,数据集包含800 张训练图像,100张验证图像和100 张测试图像。训练集中包含低分辨率图像和对应的高分辨率图像。
3.2.2 测试集
本文采用的测试集是个标准基准数据集:Set5,Set14,BSDS100,Urban100。Set5 数据集是由5 张图片组成,应用广泛。Set14 数据集共有 14 张图片。与 Set5 相比,Set14 所包含的图像更多,分辨率也更高。BSDS100 数据集共有 100 张图片,相比较Set5和Set14,BSDS100 图像所包含的内容更加丰富。Urban100 数据集共有 100 张图片,与BSDS100 数据集相比较,分辨率更高。
3.3 评测指标
为验证改进算法的性能,本文使用峰值信噪比(PSNR)和结构相似性(SSIM)两种客观评价标准作为图像超分辨率重建评价标准。
峰值信噪比(PSNR)经常用作图像压缩等领域中信号重建质量的测量,它非常简单地通过均方差(MSE)进行定义。两个m×n单色图像S和H,峰值信噪比(PSNR)定义为:
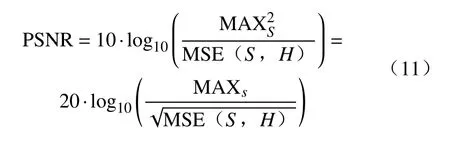
结构相似性(SSIM),也是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。
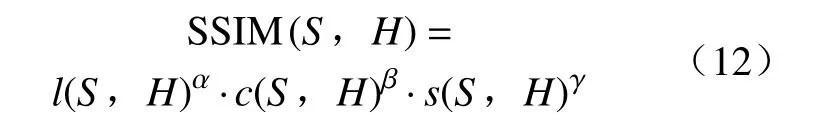
式中:l(S,H)表示亮度比较函数;α为调节亮度的参数;c(S,H)表示对比度函数;β为调节对比度的参数,β> 0;s(S,H)表示结构函数;γ为调节结构函数的参数,γ> 0。
根据重建后的图像和原始高分辨率图像得到每个测试集上所有图像的PSNR 值和SSIM 值,然后在每个测试集上求得平均值,得到最终的PSNR值和SSIM 值。
3.4 实验结果及分析
3.4.1 消融实验
在改进算法的过程中,本文将鉴别器中的激活函数从LeakyReLU 函数改为Mish 函数,为了验证这一选择是合理的,我们改变前文中的生成器部分,鉴别器部分在去掉BN 层以后,还是使用LeakyReLU函数作为激活函数,然后进行训练,得到权重文件后在测试集上进行测试,然后和鉴别器中的激活函数改变后的效果进行比较,得到表1和表2。
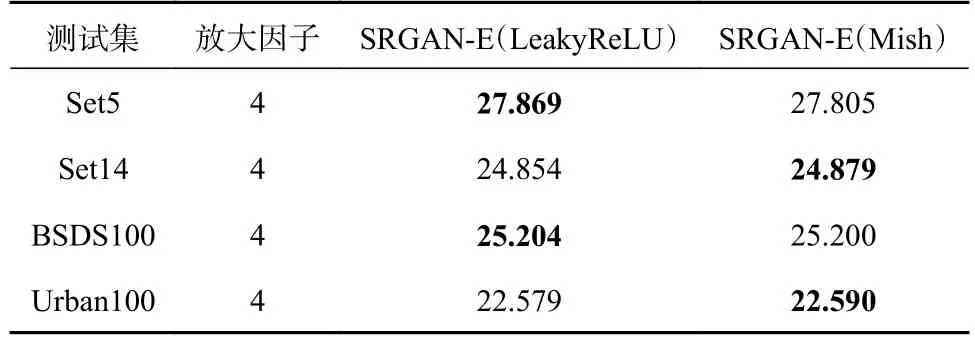
表1 改进后的算法鉴别器中分别为LeakyReLU 函数和Mish 函数的PSNR 对比结果
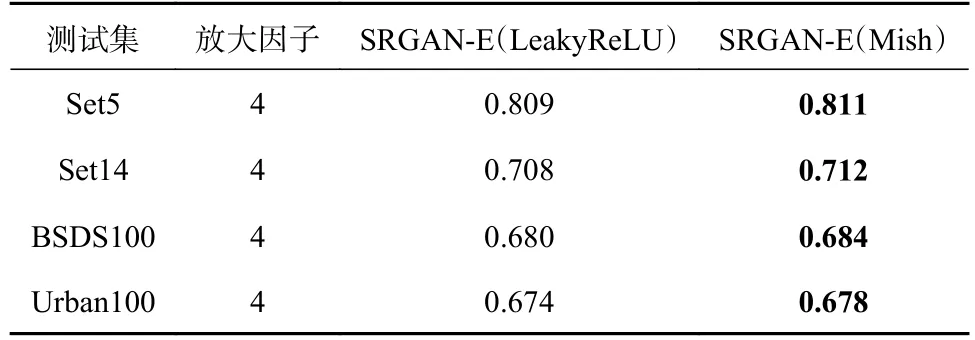
表2 改进后的算法鉴别器中分别为LeakyReLU 函数和Mish 函数的SSIM 对比结果
由表1和表2可知,在测试指标PSNR 中,Set5和BSDS100 两个数据集上,LeakyReLU 函数的表现更好,在另外两个数据集上Mish 函数表现更好,但是在测试指标SSIM 中,4 个测试集上,Mish 函数的表现都更好。Set5和BSDS100 两个数据集与Set14和Urban100 数据集相比,Set14和Urban100两个数据集内容更加丰富,分辨率也更高,Mish 函数对于分辨率更高的图像的效果更好,而LeakyReLU函数对于低分辨率的图像的效果更好。所以尽管出现了LeakyReLU 函数表现更好的特殊的情况,本文还是认为Mish 函数作为激活函数更好,特别是对高分辨率的图像更是如此。
3.4.2 对比实验
为了验证本文优化算法的效果,本文选取了一些经典算法进行实验,先将每个算法训练100 轮,得到相应的权重文件,然后在4 个测试集上进行测试得到在放大因子4 倍的情况下的4 个测试集的PSNR和 SSIM 值,具体如表3和表4所示。
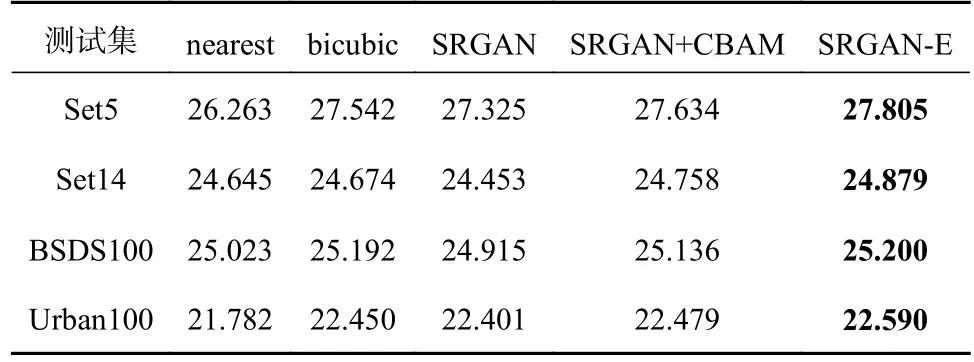
表3 每个算法在4 个测试集上的PSNR值
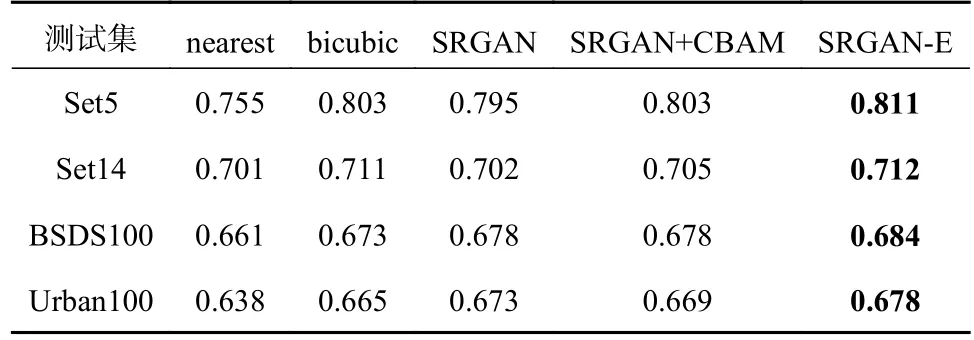
表4 每个算法在4 个测试集上的SSIM值
由表3和表4可知,改进后的SRGAN-E 算法与原始的SRGAN 算法相比,在4 个测试集上PSNR的平均值增加了0.345,SSIM 的平均值增加了0.009,进而证实了改进的SRGAN-E 算法是有效的。
为验证前文阐述的参数数量减少的真实性,本文在实验时通过pytorch 提供的parameters()函数获取网络的参数数量(如表5所示),由于鉴别器的优化不涉及参数数量的改变,所以表5中只是生成器的参数。

表5 生成器参数数量
由表5可知,SRGAN-E 算法的生成器参数数量与SRGAN 算法相比,不增反降,减少了1 388 个。图像的重建效果却有所提升。SRGAN+CBAM 的方法虽然提升了重建效果;但是基于CBAM 的注意力机制中存在两次二维卷积,使得参数数量在原模型上进一步增加,而且,也因为卷积运算时压缩了特征图的通道数,使得图像信息损失进而导致重建效果无法进一步提高。本文所提出的算法通过一维卷积的方式保留了图像的信息,也因为一维卷积的卷积核规模更小,使得参数有所下降,且模型的性能无论与较原始的SRGAN 算法相比,还是与SRGAN+CBAM 算法相比,算法的性能都得到了提升。
3.5 超分辨率重建改进算法的效果
为了展示改进算法的重建效果,我们从测试集中随机选取了一张低分辨率图片分别进行原始SRGAN 算法测试和本文改进后的SRGAN-E 算法测试,然后得到的效果如图6所示。
由图6可以看出,无论是客观测试指标上还是从视觉效果上,都可以看出本文提出的SRGANE 算法都比原始SRGAN 算法在提升图像重建效果的性能上更加优异。

图6 放大因子为 4 倍的重建图像结果
4 结论
为了解决SRGAN 算法中存在的问题,本文通过添加一维卷积注意力机制,优选激活函数等措施,提出了一种改进的图像超分辨率重建算法SRGAN-E。与原始的SRGAN 算法相比,改进后的SRGAN-E 算法在4 个测试集上的PSNR和SSIM两个评价指标上都有所提升,且减少了SRGAN 中的生成器参数数量。在本文中,仅仅是对生成器和鉴别器的性能进行了优化,虽然参数数量有所减少,但是数量依旧还是庞大,还需要进行更加深层次的优化以到达在不降低重建图像质量的情况下提高模型训练速度的目的。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
小雪花·成长指南(2022年1期)2022-04-09
河南科技(2021年35期)2021-04-25
上海师范大学学报·自然科学版(2019年5期)2019-12-13
第二课堂(课外活动版)(2016年2期)2016-10-21
CHIP新电脑(2016年3期)2016-03-10
微型计算机(2009年4期)2009-12-23
数码摄影(2009年12期)2009-12-07
