
基于分类难度的过采样度优化方法
2022-10-12 08:05祝团飞罗成曾一夫张维
长沙大学学报 2022年5期
祝团飞,罗成,曾一夫,张维
(1.长沙学院计算机科学与工程学院,湖南 长沙 410022;2.江西工业贸易职业技术学院信息工程系,江西 南昌 330038)
不平衡数据的分类是指分类的数据中一些类(大数类)的样本数目显著多于另外一些类(少数类)的样本数目,该问题广泛地存在于现实世界的应用中,例如疾病诊断、软件缺陷预测、故障侦测等。样本数目的不平衡分布给传统的分类学习算法带来了巨大挑战,主要表现在两方面:分类算法通常以最小化训练错误为目标,样本数量绝对占优的大数类会使其分类器的预测偏置[1-2];类重叠、类内不平衡、噪声等数据困难因子与类不平衡在学习困难度上有超叠加效应[3-4]。此两项挑战使标准的分类学习算法在少数类上的预测表现出低泛化性能。然而,稀有的少数类对象往往能体现出问题的本质,对少数类样本错误地分类可能会付出相比错误预测大数类样本更高的代价。例如,在疾病诊断中误将一个健康人诊断为患某种疾病固然会给人带来精神负担,但将一个实际病患漏诊为健康人会让其错过最佳的治疗时机,导致灾难性的后果。
过去的二十年,研究人员提出了多种类型的不平衡学习方法[5-6]。其中,人工合成少数类样本的过采样技术是热门的方法之一。过采样技术需要解决两个基本问题:如何生成人工的少数类合成样本,以及为每一个少数类样本生成多少合成样本。这两个问题分别涉及合成样本的生成和过采样度的寻优。现有研究中,几乎所有的过采样算法都侧重于合成样本的生成方法创新,而忽略过采样度的寻优策略设计。然而,过采样度能显著影响算法的性能,过高的过采样度会严重损害大数类的分类性能,过低的过采样度将不能有效纠正分类器偏向大数类的预测偏置。
在过采样度寻优策略中,一个关键的问题是如何解决过采样权重分布,即在总的合成样本一定的情况下,如何完成合成样本在各个少数类样本上量的分配。现有的方法基于样本分布的局部特征,为少数类样本测量若干反映学习重要性的数据因子,然后整合这些数据因子作为过采样权重[7-11]。然而,学习的重要性依赖于具体的分类学习方法,且出于强化难于分类的样本学习的目的,少数类样本的过采样度应由其本身的分类难度决定。
基于以上动机,我们提出一种依赖分类困难度的过采样权重分配方法CD-W(Classification Difficulty-based Weighting)。通过将CD-W与目前流行的SMOTE插值生成技术相结合,得到新的过采样算法CD-SM。CD-SM中每一个少数类样本的过采样权重由分类器对其预测的软损失决定,以确保分类损失越高的少数类样本分配到越多的合成样本。为了评估CD-SM的有效性,我们以神经网络为分类器,以F1、G-mean和AUC[12]为性能评价指标,在18个UCI标准数据集上进行实验,结果表明,CD-SM是具有高度竞争力的加权过采样算法。
1 相关工作
现有文献中,只有非常少量的过采样方法涉及估计过采样权重的分布,我们对有限的过采样权重估计方法进行了总结。
自2002年合成少数过采样技术SMOTE被提出以来,学术界和工业界的研究人员设计了大量的过采样算法去处理不平衡的分类问题[6-9,13-18]。绝大部分的算法致力于合成样本生成方法的创新,而忽视过采样度寻优策略的设计,其中代表性的算法有SMOTE[17]、SMOM[13]、PAIO[14]和SMOR[15]。这些方法简单地假设过采样权重分布是一个均匀的分布,为每一个少数类样本生成等量的合成样本。然而,不同的少数类样本具有不同的重要性,一些样本可为数据的分类学习提供更多有用的信息。
Borderline-SMOTE[9]和ADASYN[7]是被最早提出加权过采样的两个算法,且都基于少数类样本的k最近邻居分布确定过采样的权重。前者只对k最近邻居中存在一半以上大数类样本的少数类样本赋权重(不包括k最近邻居全为大数类的少数类“噪声”样本),后者少数类样本的过采样权重与其k最近邻居中大数类样本数目成正比。此种加权过采样策略的动机是边界的样本往往具有更高的重要性,需为其分配更多的合成样本。后续的INOS[10]和RAMOBoost[11]过采样沿用了ADASYN的过采样权重计算方法。然而,找到一个合适的邻居参数k去捕捉所有的边界样本和充分反映学习的重要性是非常困难甚至不可行的[18]。
为避免设置参数k,MWMOTE[18]引入边界大数类样本和少数类样本间的亲密因子与密度因子来计算少数类样本的过采样度,其中亲密因子衡量每一个边界大数类样本与其k最近的少数类样本的邻近程度(即距离远近),而密度因子反映每一个边界大数类样本周围分布少数类样本的稀疏程度。一个少数类样本的过采样权重是累加所有边界大数类样本提供的亲密因子与密度因子的乘积。MWMOTE分配过采样权重的主要出发点是为越靠近大数类样本(更高的亲密因子)和位于越稀疏聚类(倾向更高的密度因子)的少数类样本分配越高的权重。
最近,基于高斯分布的过采样方法GDO[8]采用了与MWMOTE相似的权重计算方法,其使用密度因子和距离因子来衡量少数类样本所具有的信息量差异。在GDO中,密度因子被定义为少数类样本的k最近邻居中大数类样本的比率,距离因子衡量k最近邻居中大数类样本邻居相对于少数类样本邻居与当前考虑的少数类样本的平均距离比。GDO将一个少数类样本的密度因子与距离因子之和作为此样本的过采样权重,其背后的动机是为远离大数类样本的边界少数类样本分配更高的权重。然而,类似于ADASYN,如果少数类样本的k最近邻居不存在任何的大数类样本,GDO将为这些样本的权重赋值为零。显然,这可能导致大部分的过采样权重只集中在个别的少数类样本上。
2 基于分类难度的算法
我们提出的过采样算法的主要思想是依据少数类的分类难度来分配少数类样本的过采样权重,然后与目前流行的合成样本生成方法SMOTE相结合,得到一种基于分类难度的加权过采样方法CD-SM。在CD-SM中,一个少数类样本的分类难度是分类模型对其多次预测的分类损失平均。CD-SM首先将样本的分类难度转化为过采样的权重分布,然后据此分布,在更难分类的少数类样本附近插值生成更多的合成样本,以强化这些样本的学习。
CD-SM的算法过程如下。
输入:原始不平衡数据集D,少数类样本集S,分类学习算法L,估计分类难度的次数nc,生成的合成样本总量ns;
输出:合成的少数样本集Syn;
步骤1:对原始不平衡数据集D的每一类,应用SMOTE方法生成相同数量的合成样本,以得到一个与D相同类分布的合成数据集Dsyn;
步骤2:基于Dsyn,使用分类学习算法L训练得到分类模型M;
步骤3:使用M对D中的少数类样本集S分类,得到少数类样本的分类难度;
步骤4:重复以上步骤nc次,将少数类样本的nc次分类难度的平均值作为其最终的分类难度CD;
步骤5:将获得的难度CD转换为过采样权重分布W;
步骤6:执行下面过程,为少数类生成合成样本数据集Syn。
(1)从S中根据过采样权重分布W,抽样出一个少数类样本xi作为主种子样本;
(2)从xi的k最近同类邻居中随机选择一个少数类样本xj作为辅助种子样本;
(3)基于xi和xj,插值得到一个合成样本,其中δ是一个元素处在[0,1]之间的随机向量,“.*”代表元素级的乘法;
(4)将xs加入;
(5)重复(1)至(4)ns次,返回Syn。
步骤1与步骤2的目的是生成D的一个副本数据集Dsyn以训练得到分类模型M,然后使用M去对少数类样本集S分类。步骤3中,一个少数类样本xi的分类难度可表示为:

其中yi是xi的真实标签。即为预测xi时产生的软损失。损失越高代表xi越难被M正确分类。由于Dsyn是使用SMOTE生成的原始数据集D的副本,其样本受SMOTE中随机因素的影响而具有一定的随机性。步骤4的目的是为D生成多次的副本Dsyn,通过反复训练与预测S,从而得到S中每一个样本的可靠分类难度估计CD(一个少数样本的最终分类难度是nc次估计的平均值)。
得到少数类样本的分类困难度后,在步骤5中利用下面两式将其转换为一个过采样权重分布W:
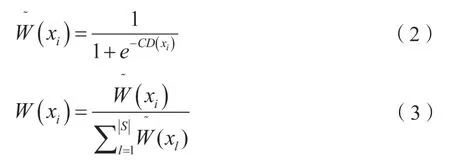
最后,基于W和S,在步骤6中为少数类生成合成样本集Syn。步骤6中,每一个主种子样本xi是据分布W从S中抽样得到,越高分类难度的少数类样本有越高的概率被选择作为主种子样本,从而有越大可能在其附近生成较多的合成样本。
3 仿真实验
3.1 实验设置
3.1.1 数据集
我们从UCI数据库[19]中选择了18个现实的数据集作为实验数据。这些数据集的特征总结如表1所示。从表1中可以看出,选择的实验数据集具有不同的特征数目、样本数目和类不平衡度。
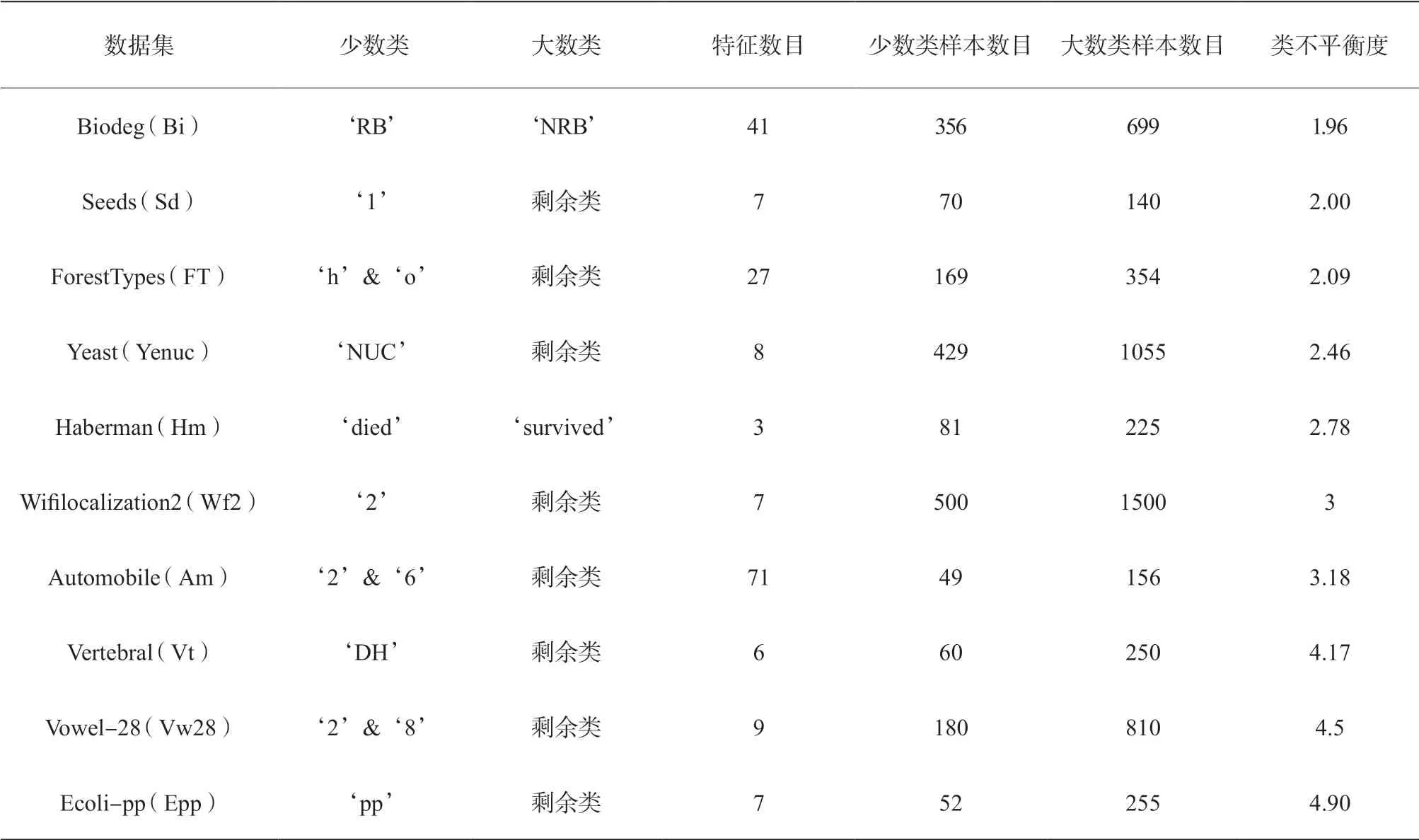
表1 实验的18个UCI不平衡数据集的特征总结

续表
3.1.2 方法比较
在已有的文献中,过采样算法ADASYN、MWMOTE和GDO采用的权重计算方法分别是三种代表性的过采样度权重分配方法。我们重点与此三种方法进行比较。为了剔除合成样本生成方式的不同所造成的实验干扰,将ADASYN、MWMOTE和GDO中的过采样度权重方式分别与SMOTE的合成样本生成方法相结合,简写为ADSM,MW-SM和GD-SM。此外,我们将被普遍采用的均匀权重分配方式也纳入实验比较中,即原始的SMOTE(简写为SM)过采样。所有比较的方法的参数分别使用相应论文中的推荐值。实验提出的CD-SM中,估计分类难度的次数nc设置为5。
3.1.3 性能指标
由于类分布的不平衡,评估分类模型在不平衡数据上的学习性能需要采用专门的类不平衡评价指标。在现有的研究中,F1、G-mean和AUC[12]是三个最为常用的面向类不平衡的性能指标。对F1、G-mean的定义如下:

其中,召回率Recall和精确度Precision分别是少数类样本被正确预测的比率(即少数类的预测精度)和预测为少数类的样本中实际为少数类的比率。不同于F1和G-mean,AUC不依赖于具体的决策阈值。实验中每一个作为比较的方法在每一个数据集取得的实验结果都基于10次独立运行的5分层交叉验证,然后将其平均值作为最后的性能。
3.1.4 统计性检验
Wilcoxon符号秩检验[20]是最受欢迎的非参数显著性检验方法。我们使用此方法去验证提出的方法与其他比较的方法间是否存在显著性差异。
3.1.5 基分类器
我们使用一个三层的神经网络作为基分类器,其输入层和输出层的神经元个数分别为训练集的特征数目和类别数目,中间层采用固定的10个神经元。神经网络以0.01的学习率训练500代以收敛分类模型。
3.2 实验结果与分析
表2和表3分别总结了当过采样倍率为100%和300%时,NONE、SM、AD-SM、MW-SM、GD-SM和我们提出的CD-SM在每一个数据集上的F1、G-mean和AUC性能值(NONE表示未结合任何过采样算法的性能结果)。基于表2和表3的结果,CD-SM在两种过采样倍率和每一种评价指标下都获得了最好的平均性能值。为更好地演示各种比较的方法的竞争力,图1给出了所有用于比较的方法在18个实验数据集上的平均性能排名。从图1可以看出,CD-SM以明显的优势在每一个评价指标上获得最低的平均排名,表明基于分类难度的过采样权重分配方法具有最高的竞争力和稳健性。

图1 a与b分别表示当过采样倍率100%和300%时,各方法在F1、G-mean和AUC上的平均排名

表2 过采样倍率100%时,比较的方法在18个实验数据集上的F1、G-mean和AUC性能结果

表3 过采样倍率300%时,比较的方法在18个实验数据集上的F1、G-mean和AUC性能结果
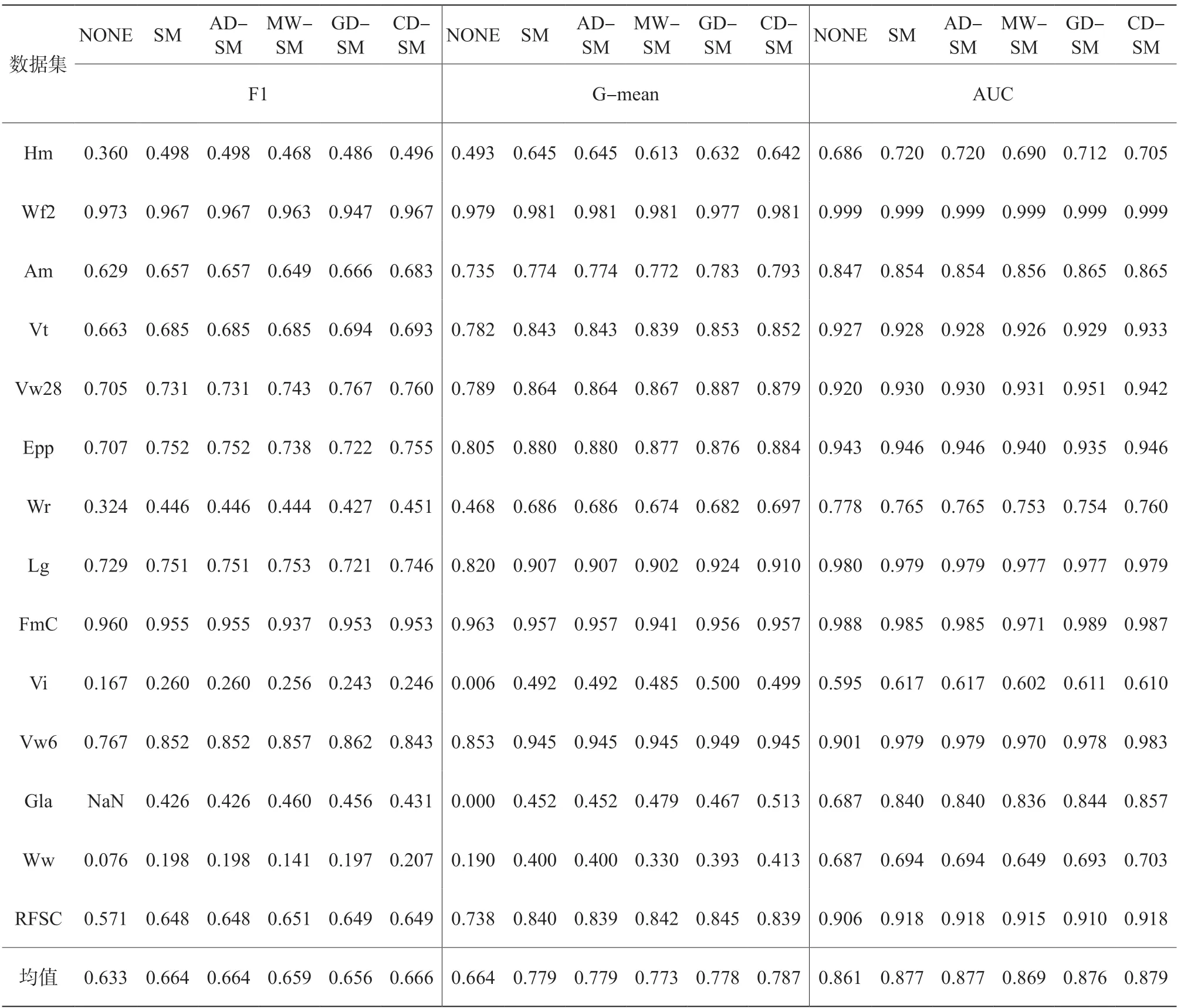
续表
为了测试比较的方法间是否存在显著性差异,表4列出了CD-SM与其他每一个方法的Wilcoxon符号秩检验结果(“++”“+*”分别表示CD-SM以0.05和0.1的显著性水平好于其他比较的方法,“+”表示CD-SM只定量地好于其他比较的方法)。表4的结果说明在绝大部分情况下,CD-SM显著性地好于其他比较的方法,从而验证了提出的方法的有效性。
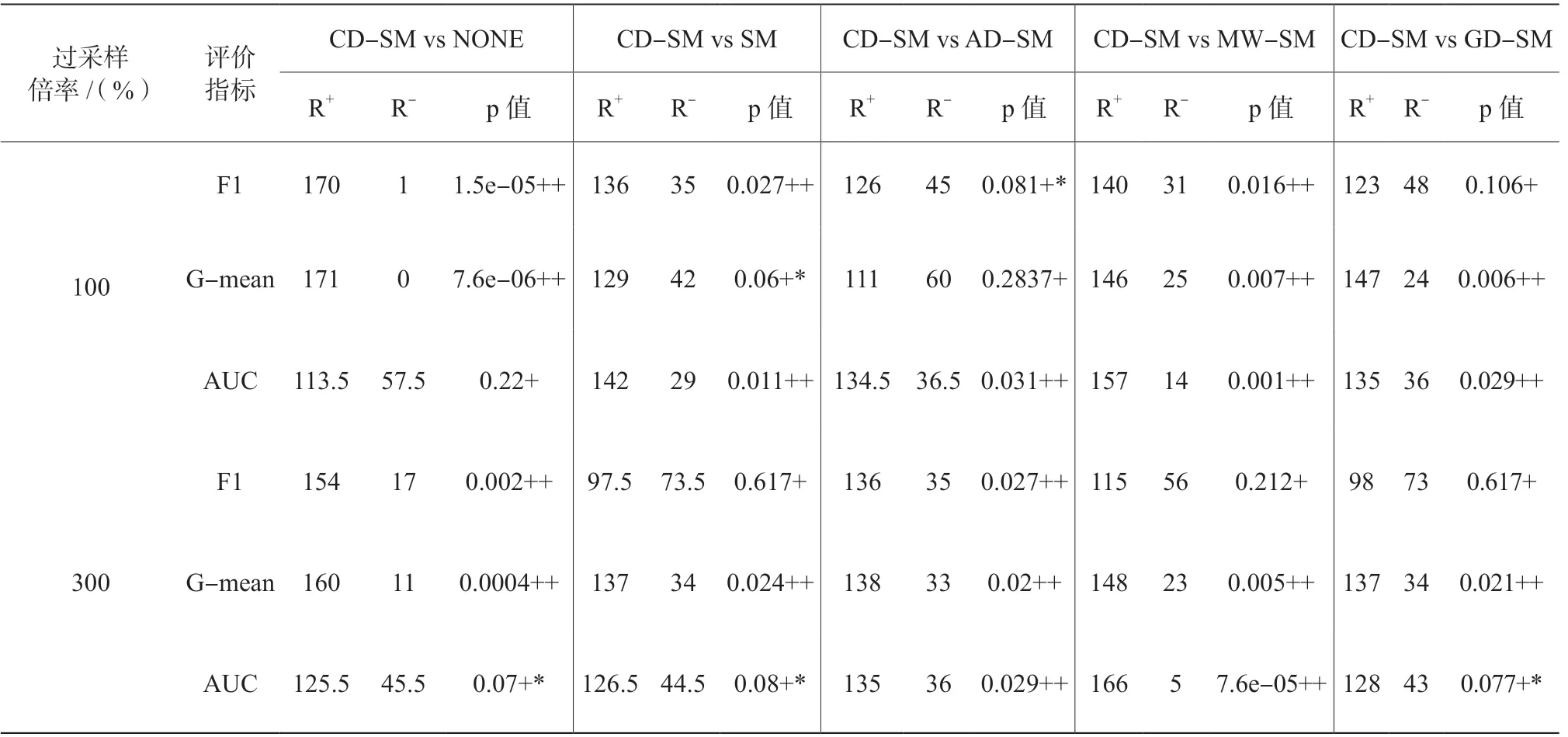
表4 CD-SM与每一个其他比较的方法间的Wilcoxon符号秩显著性检验结果
4 结论
我们提出了一种基于分类难度的加权过采样方法,将分类学习算法在少数类样本上的分类损失作为过采样权重,以强化那些难于正确分类的少数类样本的学习。不同于已有的加权过采样方法,我们提出的方法分配过采样权重不再基于数据特征所反映的样本重要性,而是直接考虑当前的分类学习算法对少数类样本的分类难度。为了评价提出的方法的有效性,我们以18个UCI现实数据集为实验数据,以神经网络为基分类器进行实验,结果表明,此方法在常用的评价指标F1、G-mean和AUC上都优于现有的加权过采样方法。
最后,需要指出的是,我们提出的方法需要额外训练nc次的模型和预测nc次的少数类样本集去获得准确的分类难度分布。在实验仿真中,CD-SM的nc只需设置为一个较小的常数5,即可取得相比已有方法显著更好的性能。因此,我们认为其产生的额外时间代价是值得的。
猜你喜欢
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
数学学习与研究(2019年17期)2019-10-18
决策(2018年8期)2018-12-10
领导决策信息(2018年16期)2018-09-27
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
数学学习与研究(2017年3期)2017-03-09
数学大王·低年级(2016年9期)2016-05-14
西南学林(2011年0期)2011-11-12
