
XSSD-P:改进的SSD行人检测算法
2022-12-06 10:29鲍文斌张冬泉
计算机工程与应用 2022年23期
鲍文斌,张冬泉
北京交通大学 机械与电子控制工程学院,北京 100044
近年来,行人检测技术作为自动驾驶和机器人技术等领域的重要组成部分引起了研究学者的极大关注,该技术分为基于特征的行人检测[1]和基于深度学习的行人检测[2]两大类。其中,常用的手工特征描述符包括HOG特征[3]、Haar-like特征[4]、DPM特征[5]等。与基于特征的行人检测方法相比,基于深度学习的行人检测方法能够通过学习的方式获取更有利于分类的最佳特征[6]。因此,基于深度学习的行人检测方法在行人检测技术中占据了主导地位。其中,RCNN[7]充分结合了卷积神经网络和选择性搜索算法[8],是卷积神经网络应用于通用目标检测的开山之作。但是,对输入图片重复进行特征提取使得RCNN算法不满足实时性要求。在RCNN的基础上,Fast RCNN[9]借鉴空间金字塔池化算法[10]实现了单次特征提取即可完成检测的跨越,提高了检测速度。Faster RCNN采用区域建议网络替代选择性搜索算法进行候选框选择[11],再次提高了检测速度和检测精度。SSD算法[12]和YOLO系列算法[13-16]实现了真正意义上的端到端的行人检测,大幅提高了行人检测的速度。
SSD算法通过骨干网络进行特征提取并构造多尺度特征图,在每个特征图上预测固定数量的框和框内是否存在行人,然后通过非极大值抑制算法产生最终检测[17]。在对SSD算法的改进中,DSSD算法和FSSD算法分别采取反卷积和双线性插值变换的方法产生新的特征图并通过将新特征图与原特征图进行融合提高了检测精度[18-19];M2Det算法改进了特征融合的方式将检测精度再次提高[20];RfbNet算法提出感受野模块并将其应用于特征图的头部[21],起到了提高检测精度的作用;Pelee算法通过设计轻量化的网络提高了检测速度[22]。虽然改进算法对检测精度或检测速度有不同程度的提高,但某一性能提高的同时也不同程度地牺牲了其对立性能。因此如何同时提高检测速度和检测精度或在不降低其中一个性能的情况下提高另一个性能成为研究行人检测的关键问题之一。
基于以上对SSD算法及其改进算法的研究分析,本文将在进一步分析锚框和特征图映射到输入图像上的感受野对检测性能的影响的基础上,通过改造SSD算法的骨干网络和重新设计基础锚框与多尺度卷积核,并将卷积核与基础锚框进行耦合,同时提高行人检测的检测精度及检测速度。
1 XSSD-P算法
XSSD-P算法以修改后的Xception网络作为骨干网络,输入图片的大小为299×299像素。与SSD算法相比,XSSD-P算法使用多尺度卷积核在被选择用于检测的特征图上滑窗进行预测,且在该过程中使用深度可分离卷积替代常规卷积完成预测运算。在进行位置回归时,XSSD-P算法根据行人外形尺寸特点设计了基础锚框,基础锚框与用于预测的卷积核耦合且其可以通过调整自身大小得到用于位置回归的锚框(1.3节详细说明)。XSSD-P算法与SSD算法的结构对比如图1所示。

图1 XSSD-P算法与SSD算法的结构对比图Fig.1 Structure comparison of XSSD-P and SSD
1.1 Xception网络
在卷积神经网络的特征图中跨通道相关性和空间相关性的映射可以完全解耦的前提下,Chollet[23]提出了Xception网络。Xception网络由输入流(entry flow)、中间流(middle flow)和输出流(exit flow)三部分组成,共包含了14个模块(block),网络结构如图2所示。由图可知,Xception网络是一个由深度可分离卷积层和残差结构组成的线性堆栈,除第一个和最后一个模块以外,其余模块均与浅层特征存在线性连接。
残差结构首先复制一个浅层网络的输出,然后将其与深层网络的输出通过元素相加得到下一层的输出,如图2所示(使用虚线框标出),在通过增加网络深度提高网络的特征表达能力时,该结构能够有效地缓解梯度消失、梯度爆炸和网络退化问题[24]。深度可分离卷积将常规卷积运算一分为二,其在减少参数的同时拥有与常规卷积相当的特征提取能力。本文对常用的骨干网络进行了性能比较,包括Xception网络、VGG16网络、ResNet-152网络和Darknet53网络,网络的相关参数如表1所示,在ImageNet数据集的分类性能比较如表2所示。表1中的参数为各网络去掉全连接层后得到的参数,其中,网络的计算量(FLOPs)在输入图像尺寸相同和输入图像尺寸为常用尺寸两种条件下分别获得。表2给出了各网络在ImageNet数据集中的Top-1 accuracy(排名第一的类别与实际结果相符的准确率)和Top-5 accuracy(排名前五的类别包含实际结果的准确率)[15,23]。

表1 常用骨干网络参数对比Table 1 Comparison of commonly used backbone network

表2 ImageNet数据集中的分类性能比较Table 2 Classification performance comparison on ImageNet 单位:%

图2 Xception网络结构Fig.2 Structure of Xception network
由表1可知,除VGG16网络以外,其余网络的感受野均大于700,远超过输入图像的大小,且拥有较深的网络深度,感受野和网络深度的增加在一定程度上可以增强网络的特征提取能力;由表2可知,在ImageNet数据集上的分类性能比较中,Xception网络的分类精度均高于其他三个网络。基于以上两点可知,Xception网络拥有更强的特征提取能力。在参数量和计算量方面,由表1可知,Xception网络拥有最少的计算量,参数量仅超过VGG16网络,较少的参数量可以降低网络的训练难度和提高网络的训练速度,较少的计算量可以提高网络提取特征的速度。综合Xception网络在特征提取能力和速度上的优势,XSSD-P算法选择Xception网络作为骨干网络。
XSSD-P算法在使用Xception网络进行特征提取时,将网络最后一个模块中全局平均池化层及以后的结构去除(图2虚线框标出),然后分别使用block10、block12和block14输出的特征图对小尺寸、中等尺寸和大尺寸的行人进行预测。
1.2 深度可分离卷积运算
深度可分离卷积的核心思想是将一个完整的卷积运算分解为逐深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)两步进行[25]。在Xception网络中,大量的深度可分离卷积被运用,图3为深度可分离卷积运算和常规卷积运算对比。如图所示,深度可分离卷积先使用1×1的卷积核进行逐点卷积,然后再使用3×3的卷积核在每个通道上进行卷积。

图3 深度可分离卷积运算和常规卷积运算对比Fig.3 Comparison of depthwise separable convolution and conventional convolution
当输入通道为m1,输出通道为m2时,
常规卷积参数量:

深度可分离卷积参数量:

由参数量计算结果可知,常规卷积运算的参数量约为深度可分离卷积运算的参数量的9倍。因此,在特征图上进行预测时,XSSD-P算法采用深度可分离卷积运算代替SSD算法中使用的常规卷积运算达到减少网络参数的目的。
1.3 锚框与多尺度卷积核的设计及耦合
在SSD算法中,输入图片经过各层卷积计算得到多尺度特征图,卷积核在特征图上进行特征提取并完成预测,如图4所示。由图可知,最终用于分类的特征是结果特征图映射到输入图像上的实际感受野内的特征,且研究表明,实际感受野内的像素点对输出特征向量的影响分布成高斯分布,即中心的像素点产生的影响最大[26]。如果待检测行人的关键特征没能够被负责该行人检测的实际有效感受野[26]所覆盖,那么将导致卷积核无法提取到最有效的特征用于检测,即实际有效感受野的位置和尺寸与锚框的位置和尺寸的不匹配以及锚框尺寸与待检测行人尺寸的不匹配将直接影响SSD算法的精度。

图4 特征提取及预测示意Fig.4 Feature extraction and prediction diagram
针对SSD算法的不足,本文首先在INRIA数据集、VOC数据集和COCO数据集中选择出存在小部分遮挡和未遮挡的行人并使用K-means聚类算法对其宽度和高度进行了聚类分析,共聚成9类,K-means聚类算法如式(3)所示:

式中,μi是k个聚类中心的类别,x()j是第j个样本,代价函数T是不同类别之间的距离之和,聚类结果如图5所示。

图5 K-means聚类分析结果Fig.5 Results of K-means cluster analysis
在聚类分析结果的基础上,使用如式(4)所示的最小二乘法对聚类中心坐标进行线性拟合:

式中,(xi,yi)是聚类中心坐标,a和b分别为线性方程的斜率和截距,当φ取最小值时为最优解,通过计算,获得的回归直线方程为y=1.7x+33。K-means聚类分析和最小二乘法的计算结果表明行人的宽高比约为1∶2。
通过对行人外形尺寸进行分析,并根据输入图像的尺寸(299×299),本文将图片中高度小于75、介于75和150之间和大于150的行人分别认定为小尺寸行人、中等尺寸行人和大尺寸行人。综合特征图的尺寸特点、行人宽高比和行人的尺寸划分,XSSD-P算法选择使用多尺度卷积核,将block10、block12和block14输出的预测特征图上用于预测的卷积核尺寸分别设定为2×4、4×8和4×8。然后将输入图片分别均分为19×19和10×10与预测特征图相对应,类比3个预测特征图,在均分后的输入图片上设置2×4、4×8和4×8的框跟随多尺度卷积核在输入图片上滑动,称之为基础锚框。当多尺度卷积核在预测特征图上滑窗进行检测时,输入图片上与卷积核相对应的基础锚框滑动至对应位置并进行同心缩放,得到的新框即为用于位置回归的锚框,缩放比例分别为0.8、1和1.25。表3对预测特征图、卷积核和锚框进行了汇总。

表3 特征图、卷积核和锚框汇总Table 3 Summary table of feature map,convolution kernel and anchors
网络输出的位置偏差预测值为预测位置坐标与基础锚框坐标之间的偏差,可用式(5)表示:

式中,(tx,ty,tw,th)为网络的位置偏差预测值,(Px,Py,Pw,Ph)为预测框的中心坐标和宽高,(Rx,Ry,Rw,Rh)为基础锚框的中心坐标和宽高,α为比例系数。
简言之,本文借助实际有效感受野和实际感受野之间的关系提出基础锚框,其与实际有效感受野和行人外形尺寸高度匹配,实现了卷积核与锚框的耦合并增强了卷积核提取有效特征的能力。如图6所示,展示了上述使用多尺度卷积核及卷积核与锚框之间的耦合关系进行行人检测的过程,首先,输入图片经特征提取获得预测特征图,然后,多尺度卷积核在对应预测特征图上滑动进行预测,每个位置进行3组预测,输出得分预测值和位置偏差预测值,在此过程中,与卷积核对应的基础锚框在输入图片上随卷积核滑动并在每个位置产生3个锚框,最后,在位置偏差预测值和锚框坐标值的基础上进行位置回归完成检测。

图6 行人检测示意图Fig.6 Schematic diagram of pedestrian detection process
2 实验
为了验证方法的有效性和合理性,本文使用相同的数据集分别对XSSD-P算法和SSD算法以及其他主流算法进行训练和测试,比较了XSSD-P与各算法的检测精度性能;在同一台计算机上对XSSD-P算法和SSD算法进行检测速度测试,比较两算法的检测速度性能。
2.1 实验数据集
本文使用INRIA、COCO、VOC2007、VOC2012、Caltech和MIT数据集进行训练和测试,在COCO、VOC2007和VOC2012数据集中只对行人进行检测,在Caltech行人数据集中共包括249 884帧图像,有122 187帧图像包含行人,在122 187帧图像中每隔10帧进行一次截取,共得到12 218张图像,由于Caltech数据集图像清晰度较低,因此选择使用测试集的合理子集(reasonable,行人高度H>50像素)作为本实验的测试集,最终共选择7 610张图像用于实验,在MIT数据集中,由于部分图片并非只包含一个行人,因此本文对其进行补充标注后作为测试集使用。本文使用的数据集汇总如表4所示。

表4 实验数据集汇总Table 4 Summary table of datasets used for experiments
2.2 实验环境与参数
本实验在TensorFlow2.3.1框架下进行,操作系统为Windows10。训练时,本文将加载的训练集中90%的图片用于网络训练,剩下10%作为训练过程中的验证集,初始学习率设定为0.000 5,学习率的衰减方式为,当验证集的损失在3个批次内不发生明显下降时,学习率缩小为原来的一半。训练停止的条件为,训练批次达到100次或者验证集的损失不再发生明显下降。
XSSD-P算法用到的损失函数与SSD算法一致,均为定位损失和置信度损失的加权和[27],公式如下所示:
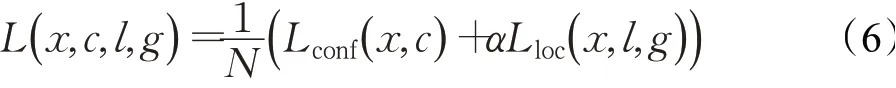
式中,N为匹配的框数,Lconf(x,c)为置信度损失,Lloc(x,l,g)为定位损失,α为权重系数。
2.3 实验结果与分析
2.3.1 评估指标
本文使用精确率(precision,P)、召回率(recall,r)和平均精度均值(mean average precision,mAP)作为检测精度性能的评估指标[28],使用每秒帧数(frames per second)和平均用时作为检测速度性能的评估指标。
精确率计算公式如式(7)所示:

式中,TP(true positive)是被检测为正样本,实际也是正样本;FP(false positive)是被检测为正样本,实际是负样本。
召回率计算公式如式(8)所示:

式中,FN(false negative)是被检测为负样本,实际是正样本。
平均精度均值计算公式如式(9)所示:

式中,C为类别,AP(average precision)的计算公式如式(10)所示:

式中,P为准确率,r为召回率。
2.3.2 预测特征图的选择试验
XSSD-P算法共使用3个特征图用于行人检测。由于深层特征拥有更大的感受野和更强的特征表达能力,因此选择block14输出的特征图用于大尺寸行人的检测。在block8、block9、block10、block11和block12输出的特征图中选择剩余两个特征图,且输出用于小尺度行人检测的特征图的特征层在网络中的位置更靠前一些。本文使用VOC2007训练集和VOC2007测试集进行实验,实验结果如表5所示。

表5 预测特征图的选择实验结果Table 5 Experimental results of feature map selection for pedestrian detection
由表中结果可以得出,当使用block10和block12输出的特征图作为小尺寸行人检测和中等尺寸行人检测的预测特征图时,行人检测器获得了最高的召回率和平均精度均值,且精确率与最大值相差不到1%,综合考虑,XSSD-P算法选择block10、block12和block14输出的特征图用于小尺度、中等尺度和大尺度行人检测。
2.3.3 与SSD的检测精度对比实验
在INRIA数据集中,使用INRIA训练集对网络进行训练,使用INRIA测试集进行测试,实验结果如表6所示。

表6 INRIA数据集实验结果Table 6 Experimental results of XSSD-P and SSD using INRIA dataset
在该实验中,与SSD算法相比,XSSD-P算法的精确率、召回率和平均精度均值分别提高了1.07、18.68和4.9个百分点。
在VOC数据集中,本文共进行两次实验:(1)使用VOC2007训练集对网络进行训练,使用VOC2007测试集进行测试;(2)使用VOC2007训练集和VOC2012训练集对网络进行训练,使用VOC2007测试集进行测试。实验结果如表7所示。

表7 VOC数据集实验结果Table 7 Experimental results of XSSD-P and SSD using VOC dataset
在该实验中,与SSD算法相比,使用VOC2007训练集进行训练时,XSSD-P算法的精确率、召回率和平均精度均值分别提高了0.69、7.11和1.39个百分点;使用VOC2007训练集和VOC2012训练集进行训练时,XSSD-P算法的精确率、召回率和平均精度均值分别提高了1.04、3.98和2.42个百分点。
在COCO数据集中,先使用COCO训练集分别对XSSD-P算法和SSD算法进行预训练,然后使用VOC2007训练集、VOC2012训练集和INRIA训练集对网络参数进行微调,并在对应测试集上进行测试,实验结果如表8所示。

表8 COCO数据集实验结果Table 8 Experimental results of XSSD-P and SSD using COCO dataset
在该实验中,使用VOC2007训练集和VOC2012训练集进行网络参数微调时,XSSD-P算法比SSD算法在精确率、召回率和平均精度均值三个指标上分别高出2.60、3.71和3.78个百分点;使用INRIA训练集进行网络参数微调时,改进算法比原算法在精确率、召回率和平均精度均值三个指标上分别高出1.66、11.2和2.61个百分点。
XSSD-P算法通过分析INRIA、VOC和COCO数据集获取了行人外形特征,并以此重新定义了锚框以及锚框的产生方式,为了验证算法的泛化性能,本文在Caltech行人数据集和MIT行人数据集中比较了XSSD-P算法与SSD算法的检测精度。
在Caltech行人数据集中,使用Caltech训练集对网络进行训练,使用Caltech测试集进行测试,在MIT行人数据集中,使用在COCO数据集和VOC数据集中获得的网络参数进行测试,测试结果如表9所示。

表9 Caltech和MIT数据集实验结果Table 9 Experimental results of XSSD-P and SSD using Caltech and MIT datasets
由实验结果可知,与SSD算法相比,在Caltech数据集中XSSD-P算法的召回率和平均精度均值分别提高了12.68和3.17个百分点,精确率降低了9.24个百分点,在MIT数据集中XSSD-P算法的精确率、召回率和平均精度均值分别提高了0.04、10.83和7.72个百分点。
在以上四组实验中,除Caltech测试集中的精确率比较以外,XSSD-P算法在精确率、召回率和平均精度均值三个指标上全面领先SSD算法,结果表明XSSD-P算法的检测精度性能优于SSD算法。XSSD-P算法在Caltech和MIT数据集中的检测精度依然优于SSD算法,且领先幅度接近其在INRIA和VOC数据集中的领先幅度,表明XSSD-P算法拥有与SSD算法相当的泛化能力。第三组实验中在VOC2007测试集中的部分行人检测结果对比如图7所示。

图7 行人检测结果对比Fig.7 Comparison of pedestrian detection results between XSSD-P and SSD
2.3.4 与其他主流算法的检测精度对比
除了与SSD算法进行检测精度比较,本文还将XSSD-P与Faster RCNN、YOLO和YOLOv2在VOC数据集中进行了比较,使用VOC2007训练集和VOC2012训练集分别对各网络进训练,使用VOC2007测试集进行测试,实验结果如表10所示。

表10 检测精度对比结果Table 10 Comparison result of detection accuracy
由表中结果可以看出,在行人检测方面,XSSD-P算法的平均精度均值高于当前主流的Faster RCNN、YOLO和YOLOv2算法。
2.3.5 检测速度对比实验
本文在检测速度对比实验中所使用的计算机的配置如表11所示,在测速过程中不包括图片前处理和检测完成后的绘图部分,包括的内容有:网络推理、得分门限筛选和非极大值抑制,即图片被输入网络得到输出后使用非极大值抑制算法进行筛选的全过程。

表11 计算机配置信息Table 11 Computer configuration information
在VOC2007测试集中随机选择1 000张图片对SSD算法和XSSD-P算法进行检测速度测试,测试结果如表12所示。

表12 检测速度测试结果Table 12 Experimental results of pedestrian detection speed
测试结果表明,XSSD-P算法的平均耗时比SSD算法减少了0.004 14 s,单张图片的检测时间缩短了29.32%;在使用每秒帧数(FPS)作为评估指标时,XSSD-P算法比SSD算法高30 FPS,单位时间内检测的图片数目增加了42.86%。与SSD算法相比,XSSD-P算法在检测速度性能方面大幅提高。
3 结束语
为了提高SSD算法的检测精度和检测速度,本文分析了其不足之处并做出改进,提出了XSSD-P算法用于行人检测。首先,该方法充分考虑了锚框尺寸和感受野对检测性能的影响,根据行人外形尺寸重新设计了锚框和多尺度卷积核并将二者进行耦合。其次,XSSD-P算法以Xception网络作为骨干网络并通过实验选择了检测效果最佳的特征层用于预测,且预测过程采用深度可分离卷积代替常规卷积完成。
使用INRIA数据集、VOC数据集和COCO数据集比较了XSSD-P算法与SSD算法以及其他主流算法的检测精度。在与SSD算法的比较中,XSSD-P算法的精确率、召回率和平均精度均值全面领先SSD算法;在与Faster RCNN、YOLO和YOLOv2算法的比较中,XSSD-P算法的平均精度均值均高于其他算法。除此以外,还在Caltech行人数据集和MIT行人数据集中对XSS-P算法的泛化能力进行了验证。在搭载型号为GeForce RTX 2070 SUPER的GPU的计算机上分别测试了XSSD-P算法和SSD算法的检测速度,XSSD-P算法的检测速度比SSD算法高30 FPS,提高了42.86%。实验结果表明,XSSD-P算法的检测精度和检测速度均优于SSD算法,具有一定的应用价值。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
