
BSLA:改进Siamese-LSTM的文本相似模型
2022-12-06 10:32孟金旭单鸿涛万俊杰贾仁祥
计算机工程与应用 2022年23期
孟金旭,单鸿涛,万俊杰,贾仁祥
上海工程技术大学 电子电气工程学院,上海 201620
互联网信息技术的快速发展带来了海量的文本数据,这些海量的文本数据通常包含着有用的相似信息,文本相似算法可以提取里面的相似信息,并将这些相似信息应用在搜索引擎[1]、问答系统[2]、文本摘要[3]等方面上。
文本相似度通常指的是对比两个文本的语义相似程度来判断它们表达的意思是否一致。例如,句子1“手机看漫画用什么软件”和句子2“用手机什么软件能看漫画”都表达了看漫画需要使用什么样的手机软件的意思,是相似文本,而句子3“求《黑虎》这部电影”和句子4“求筷子兄弟微电影《父亲》”,虽然都表达的是寻求一部电影,但是这里面表达的是寻求不同的电影,不是相似文本。文本相似度的计算方法有很多,传统的文本相似度计算方法有余弦值计算[4](cosine similarity)、N-Gram[5]、VSM(vector space model)[6]和Jaccard相似度[7]等计算方法。这些传统的文本相似度计算方法存在着人工耗费量大、模型对语义相似处理能力差和泛化能力差等缺点。后来,随着深度学习的快速发展,国内外很多研究学者将深度学习的方法运用到文本相似度计算中,卷积神经网络(convolutional neural networks,CNN)[8]可以提取文本的局部特征信息,Shen等[9]在DSSM[10]模型中引进了CNN网络,提出了CNN-DSSM文本相似模型。长短时记忆神经网络LSTM(long short-term memory networks)[11]可以提取长序列文本的特征信息,得到文本的全局特征信息,解决了CNN不能提取的全局特征的缺陷,Palangi等[12]基于LSTM网络提出了Siamese-LSTM文本相似模型,Wang等[13]在BiLSTM[14]网络的基础上提出了BiMPM文本相似模型GRU(gated recurrent unit)[15]比LSTM训练参数更少,同时还保持效果不变,受到很多研究学者的喜爱,赵琪等[16]基于BiGRU和胶囊网络(capsule)提出了capsule-BiGRU的文本相似度模型,方炯焜等[17]结合GRU和Glove[18]提出了一种文本分类模型。注意力机制可以提取相似文本的某些重要特征,提高模型对相似文本的判别能力,Yin等[19]综合了CNN和注意力Attention[20]机制提出了ABCNN文本相似模型,Chen等[21]综合BiLSTM和注意力机制提出了ESIM文本相似模型。
传统的文本相似方法采用的是one-hot、TF-IDF等词向量方法,这些词向量存在着不能考虑文本中不同词之间的联系,同时还有词向量特征维度爆炸等缺陷,后来,随着深度学习的预训练词向量得到快速发展,词向量的维度可以被处理成从高维降到低维,避免了高维爆炸,同时也保留了更多的语义信息。2013年Mikolov等[22]提出了word2vec词向量表示模型,实现了词向量由高维到低维的转换,Pennington等[18]通过语料库构建单词的共现矩阵提出了Glove模型,上面这些模型的词向量都为静态词向量,词向量始终是固定的,无法解决一词多义问题。后来Peters等[23]提出了ELMO模型,Radford等[24]提出了GPT模型,Devlin等[25]提出了BERT模型,这些模型生成的词向量是动态的词向量,而且效果越来越好,很好地解决了一词多义问题。
本文改进了Siamese-LSTM文本相似模型,在Siamese-LSTM模型引入注意力机制和BERT模型,提出了一种混合文本匹配模型(BSLA模型),BERT模型作为BSLA模型的最低端,用来对输入的文本词向量编码处理,从而加强文本中不同词之间的交互能力,注意力机制位于整个模型的输出端,对语义相关的词向量特征分配更高的分值,从而对相似文本提高识别能力。
1 相关理论
1.1 自注意力机制
注意力机制是一种查询机制,即通过查询query搜索键值对<key,value>,其计算公式为:

为了防止在计算过程中向量维度过高致使点乘结果过大而形成的梯度过小问题,在自注意力机制中增加了缩放因子其计算公式为:

其中Q、K、V为上述query、key、value向量对应构成的矩阵,key和value的维度分别用dk和dv表示。
1.2 多头注意力
图1所示为多头注意力(multi-headed attention)框架图[26],首先对三个矩阵Q、K、V进行线性变换,然后送入到缩放点积注意力中进行h次运算,最后将运算结果做拼接操作和线性变换操作得到最终结果,计算公式表示如下:

图1 多头注意力框架Fig.1 Multi-head attention architecture

1.3 LSTM网络
长短期记忆神经网络LSTM[11]是循环神经网络(recurrent neural network,RNN)的一种变体,能够提取长间隔的文本序列特征,还可以避免RNN网络出现的梯度消失问题。LSTM单元结构如图2所示,LSTM由遗忘门ft、输入门it和输出门ot三个门组成,通过门结构控制信息的删除与添加。其中ft决定从上一时刻的细胞状态ct-1丢弃哪些信息,it用来更新细胞状态ct,ot用来控制信息的输出,一个LSTM单元的计算过程表示如下:
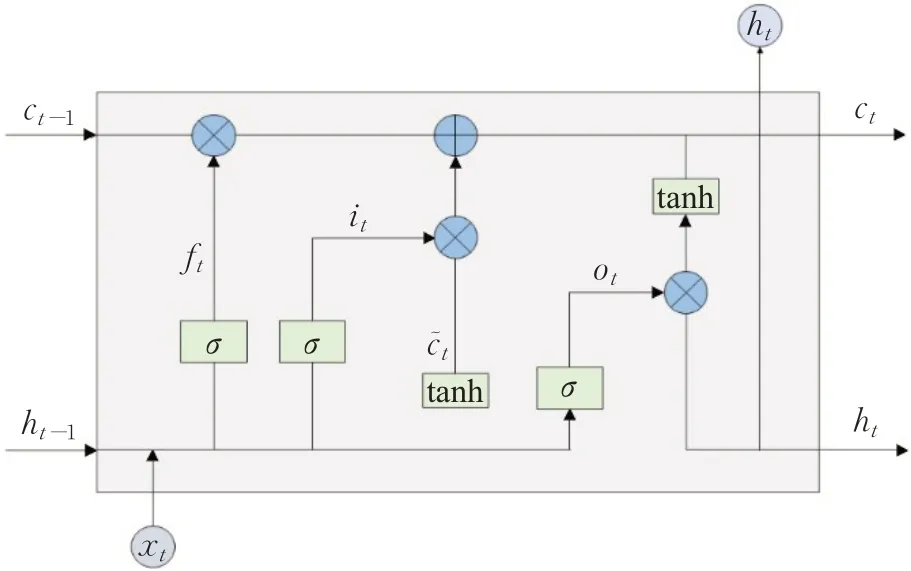
图2 LSTM单元内部结构示意图Fig.2 Schematic diagram of internal structure of LSTM unit
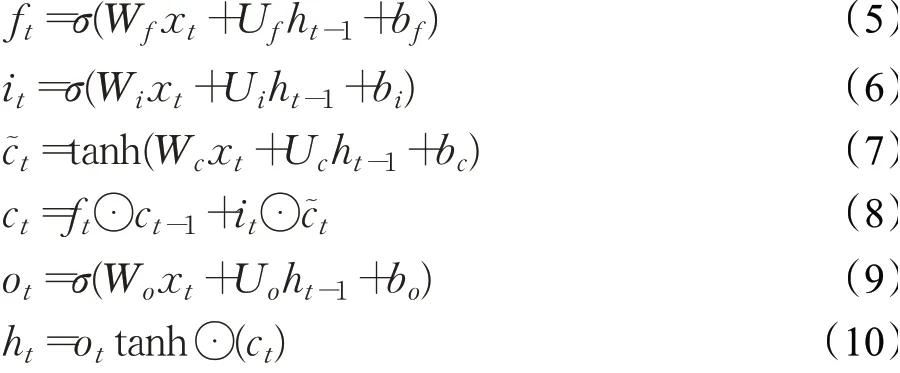
其中,σ表示sigmoid函数,xt表示t时刻的输入,c͂t表示候选更新状态,ft、it、ct、ot分别表示遗忘门、输入门、记忆门、输出门,Wf、Wi、Wc、Wo、Uf、Ui、Uc、Uo分别表示不同门对应的权重,bf、bi、bc、bo分别表示不同门对应的偏置,⊙表示Haddamard积,tanh指激活函数,ht-1、ht分别表示LSTM单元t-1的隐藏层状态和t时刻的隐藏层状态。
2 BSLA模型
BSLA模型如图3所示,该模型主要有输入层、BERT编码层、BiLSTM层、Attention层和输出层组成。

图3 BSLA模型图Fig.3 BSLA model figure
2.1 输入层
输入层有两个句子p和q,根据BERT模型输入的词向量特点,采用WordPiece进行分词,将每个句子的每个词处理成词向量(token embeddings)、段向量(segment embeddings)和位置向量(position embeddings)三个向量,并将这三个向量相加输入到Bert的编码层,如图4所示,句子p“手机看漫画用什么软件”被切分成了若干个字,变成了“手”“机”“看”“漫”“画”“用”“什”“么”“软”“件”,每个字都有其对应位置信息、令牌token信息和所处哪个句子的信息,因为输入到BERT模型中只有一个句子,所以对于句子p或句子q中的每一个字所处的某个句子信息是一样的。BERT编码层输入的句子序列长度为25,其中[CLS]和[SEP]分隔符占用的2个长度,对输入到BERT编码层的句子长度超过23切分掉保留前面的字,句子长度不足的话后面用<padding>进行补充。其中[CLS]表示分类输出的特殊符号,[SEP]表示分隔非连续token序列的特殊符号,标志着一个句子的结束。输入层的计算公式如下:


图4 输入层表示Fig.4 Input layer representation
2.2 BERT编码层
BERT模型如图5所示,它的核心模块是由Transformer组成的。Transformer采用了多头注意力机制,具有很好的并行性,对句子中的所有词的信息编码都不用考虑方向和距离,可以学习到不同语义场景下的信息。BERT采用双向Transformer编码器作为特征提取器,来提取特征信息。输入到BERT模型每个字向量,经过其编码运算后,每个字向量都包含了丰富的语义信息,与其他字向量之间双向交互,字与字之间关联度更高。如“漫”字经过BERT编码层运算输出后,与句子“手机看漫画用什么软件”中的其他字具有动态语义关联关系。BERT模型采用的是12层的Transformer编码器,输出的隐藏层维度为768,编码层的计算公式如下:

图5 BERT模型图Fig.5 BERT model figure

Trm是一个转换块,包括自注意力层,全连接层,和输出层,hi、hi-1分别表示当前层和上一层的输出结果。
2.3 BiLSTM层
BiLSTM采用双向的LSTM提取上下文信息。句子p和句子q经过BERT编码层输出的信息分别为P={p1,p2,…,pm}和Q={q1,q2,…,qn},这些信息分别输入到BiLSTM层,其中矩阵P和矩阵Q对应的维度都为batch_size×seq_len×hidden_size,本文中数值大小为64×25×768,BiLSTM网络中LSTM隐藏层维度为768。

BiLSTM对P和Q的编码后,输出的每个字向量包含了上下文全局特征信息,单向LSTM输出的字向量维度大小为batch_size×seq_len×hidden_size,本文中的数值大小为64×25×768,双向LSTM输出的字向量维度数值大小为64×25×1 536。
2.4 Attention层
在BiLSTM层后面引入注意力机制,目的是对BiLSTM层输出的词向量分配不同的权值,通过自动加权变换后生成具有注意力概率分布的特征向量,以此来突出文本中的关键信息。这里采用注意力机制来使得对相似结果影响高的词向量占比更高,为了方便说明,这里采用一个词向量来解释一下注意力机制的原理,例如句子p“手机看漫画用什么软件”中在某时刻经过注意力机制运算后输出的词向量中,“漫画”向量对文本相似影响权重高于其他词向量,所以输出的词向量中“漫画”向量占的权重更大,在经过本文模型不断训练后,相对应的另一个句子q“用手机什么软件能看漫画”在该时刻输出的词向量“漫画”对文本相似的影响也会高于其他词向量,在输出的词向量中占的权重更大,所以句子p和句子q经过注意力机制在相同时刻输出每个词向量对相似结果的影响存在一定的相互关联。
注意力的计算公式表示如下:

ht表示BiLSTM在t时刻输出的特征向量,wt表示ht的权重矩阵,αt表示通过softmax函数得到的权重,o表示经过加权运算后的特征向量。
2.5 输出层
经过注意力机制层对BiLSTM层输出词向量加权运算后,句子p和q分别得到了不同的特征向量,分别为和oq的维度大小为batch_size×seq_len×2×hidden_size,本文中大小数值为64×25×1 536,采用曼哈顿距离(Manhadun)计算句子p和q的相似度,损失函数为:

计算完相似度之后,得到相似度矩阵,维度为batch_size×1×2×hidden_size,本文中数值大小为64×1×1 536,将相似度矩阵维度进行拉平操作,保留batch_size和2×hidden_size两个维度,然后输入到全连接层,最后通过sigmoid函数进行二分类判断两个文本是否相似。
3 实验设计与分析
3.1 数据集的采集与处理
本文采用的数据集为中文数据集LCQMC语义匹配数据集和英文数据集Quora Question Pairs。数据集由两个问题和一个标签组成,标签为1则表示两个问题语义相同,为0则表示语义不同。LCQMC语义匹配数据集有238 766条训练集,8 802条验证集,12 500条测试集组成。Quora Question Pairs数据集有404 000条句子对组成,本文将其划分成9∶1∶1的训练集、测试集和验证集,其中验证集和测试集中标签为0和标签为1的数据各占一半。本文所使用的数据集的部分样本如表1所示。

表1 部分数据集样本示例Table 1 Examples of partial dataset samples
3.2 实验环境与参数设置
3.2.1 实验环境
本文实验所使用的深度学习框架是pytorch,所有模型的训练、验证和测试都是基于pytorch框架上完成的,具体的实验环境如表2所示。

表2 实验环境配置Table 2 Experimental environment configuration
3.2.2 实验参数设置
本文实验中使用BERT作为编码层构建的模型,其hidden_size为768,其他参数由该模型组建之前的单个模型参数保持一致,其他模型中文数据集使用搜狗新闻的Word+Character预训练词向量,英文数据集采用谷歌的word2vec预训练模型,维度为300d。本文模型及一些对比模型的实验参数如表3所示,表格中模型相同的参数合并在一起,在表格中居中表示,没有某个参数的用“—”表示,每个句子的最大长度为25。

表3 主要模型的重要实验参数Table 3 Important experimental parameters of main model
3.3 评价指标
本文两个句子语义相同为1,语义不同为0,是一个二分类问题,为了公平地评价各种模型的性能,以准确率(accuracy)、精准率(precision)、召回率(recall)和F1值来评价模型,它们的定义如下所示:

其中,TP表示在正类样本里预测也为正类的样本数量,FP表示在负类样本里预测为正类的样本数量,FN表示在正类样本里预测为负类的样本数量,TN表示在负类样本里预测也为负类的样本数量。
3.4 对比模型
为了验证本文混合模型的有效性,进行了如下的对比实验:(1)将本文模型与当前流行的文本匹配模型比较。(2)探究注意力机制对本文模型的影响。(3)探究BERT模型作为编码层对本文模型的影响。(4)对比了不同模型花费的时间成本。
比较的模型如下所示:
(1)ABCNN[20]:基于CNN和attention机制构建的文本匹配模型。
(2)Siamese-LSTM[12]:基于BiLSTM的文本匹配模型。
(3)Siamese-LSTM+Attention(SLA):在Siamese-LSTM模型中引入Attention机制的文本匹配模型。
(4)ESIM[21]:基于BiLSTM和treeLSTM的混合神经推理模型。
(5)BIMPM[13]:基于BiLSTM的双边多角度匹配模型。
(6)BERT+Siamese-LSTM(BSL):BERT模型为编码层,其隐藏层的输出结果输入到Siamese-LSTM模型中的混合文本匹配模型。
(7)capsule-BiGRU[16]:结合capsule和BiGRU网络,同时引入互注意力机制的文本匹配模型。
3.5 实验结果及分析
本文选取ABCNN、Siamese-LSTM、SLA、ESIM、BIMPM、BSL和BSLA等模型在两个数据集上做了训练、验证和测试,各个模型在两个数据集训练的loss值变化图和accuracy值变化图分别如图6~图9所示,验证的accuracy值变化图如图10和图11所示,测试结果如表4所示,其中capsule-BiGRU的测试结果来自文献[16]。

表4 不同模型的测试结果Table 4 Test results of different models单位:%

图6 LCQMC数据集上训练的loss值变化图Fig.6 Variation diagram of loss values trained on LCQMC dataset

图9 Quora Question Pairs数据集上训练的accuracy值变化图Fig.9 Variation diagram of accuracy values trained on Quora Question Pairs dataset

图10 LCQMC数据集上验证的accuracy值变化图Fig.10 Variation diagram of accuracy values validated on LCQMC dataset

图11 Quora Question Pairs数据集上验证的accuracy值变化图Fig.11 Variation diagram of accuracy values validated on Quora Question Pairs dataset
3.5.1 与当前流行的文本匹配模型对比

图7 Quora Question Pairs数据集上训练的loss值变化图Fig.7 Variation diagram of loss values trained on Quora Question Pairs dataset

图8 LCQMC数据集上训练的accuracy值变化图Fig.8 Variation diagram of accuracy values trained on LCQMC dataset
从图6~图11中可以看出,虽然由于本文使用的中英文数据集存在差异,导致BSLA模型在训练和验证过程中数值变化存在不同,但是无论是在中文LCQMC数据集对应的训练和验证图,还是在英文Quora Question Pairs数据集对应的训练和验证图,BSLA模型相对当前流行的ABCNN、Siamese-LSTM、ESIM和BIMPM等网络模型进行对比,在训练过程中loss初始值更小,收敛速度更快,变化浮动更小,同样在训练和验证过程中的accuracy值初始值更大,收敛速度更快,值变化浮动更小。从表4的测试结果中可以看出,在LCQMC数据集上,BSLA模型相对当前流行的ABCNN、Siamese-LSTM、ESIM和BIMPM中表现最好的BIMPM模型相比,BSLA模型在precision、recall和F1值上分别高出BIMPM模型1.32、1.45和1.39个百分点,同样在Quora Question Pairs数据集上也高出了BIMPM模型2.40、2.42和2.41个百分点。与capsule-BiGRU模型的测试结果相比,虽然BSLA模型在recall值低于capsule-BiGRU模型2.03个百分点,但是precision和F1值分别高出2.52和0.31个百分点,BSLA模型与capsule-BiGRU模型在recall值上存在差异的原因可能是文献[16]中采用的Quora Question Pairs数据集的测试集标签0和标签1的数量不一致的原因。综合上面的对比结果,可以看出本文BSLA模型在precision、recall和F1值基本上都优于当前流行的文本匹配模型。
3.5.2 注意力机制对本文模型的影响
在表4的测试结果中,本文从Siamese-LSTM模型中引入注意力机制形成的SLA模型测试结果中看出,SLA模型在LCQMC和Quora Question Pairs数据集上precision、recall和F1值都高于没有加入注意力机制的Siamese-LSTM模型,所以本文考虑在本文模型中引入注意力机制。本文模型在加入注意力机制后,与没有引入注意力机制的BSL模型相比,BSLA模型在训练和验证过程loss、accuracy值收敛速度更快,BSLA模型相对于BSL模型测试结果中,在LCQMC数据集上precision、recall和F1值分别高出0.31、0.27和0.29个百分点,在Quora Question Pairs数据集上precision、recall和F1值分别高出0.25、0.26和0.26个百分点。综上,可以看出本文模型引入注意力机制后,本文模型可以关注对相似识别做出贡献较大的词向量,可以在一定程度上增加对相似文本的识别能力。
3.5.3 BERT模型对本文模型的影响
从图6~图11中可以看出本文BSLA模型在引入BERT动态词向量作为本文模型的编码层后,训练过程中模型的loss值明显降低,训练过程和测试过程的accuracy值都明显升高了不少。同样,从表4的测试结果中可以看出,BSLA模型相对于没有引入BERT模型的SLA模型,在LCQMC数据集上precision、recall和F1值分别高出1.59、1.46和1.53个百分点,在Quora Question Pairs数据集上precision、recall和F1值分别高出3.78、7.78和3.78个百分点。综上,可以看出BERT模型作为BSLA模型的编码层,对输入的上下文中词向量编码运算后再输入到后面的BiLSTM-Attention后进行相似度计算效果更好。
3.5.4 不同模型花费的时间成本
不同模型在20个epoch总的训练时间结果如表5,变化图如图12所示,从表5和图12中可以看出,本文模型在引入注意力机制后,总的模型训练时间有所增加,在LCQMC和Quora Question Pairs数据集上分别增加了235 s和1 198 s,但是在引入BERT模型作为本文模型的编码层后,本文BSLA模型总的训练时间呈大幅度增长,总的训练时间在LCQMC和Quora Question Pairs数据集上分别增加了32 473 s和95 397 s。所以,总的来说本文BSLA模型存在训练时间过长的缺陷。

表5 不同模型总的训练时间Table 5 Total training time of different models单位:s

图12 不同模型总的训练时间Fig.12 Total training time of different models
4 结束语
针对Siamese-LSTM模型对相似文本特征提取能力差,准确率偏低,本文对其进行了改进,加入了注意力机制和BERT编码模型,有效地增强了模型的性能。本文通过将不同模型在LCQMC数据集和Quora Question Pairs数据集进行了训练、验证和测试,证明了Siamese-LSTM和BSL模型在引入注意力机制后提升了模型的效果,同样也证明了SLA模型引入BERT模型后有效地提升了模型的效果,最终证明融合了注意力机制和BERT编码模型的本文模型在精确率、召回率和F1值三个评价指标上表现出效果基本上都是最佳的,但是针对本文模型的训练时间来说,存在着训练耗费时间长的缺陷。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
计算机研究与发展(2022年1期)2022-01-19
小学生学习指导(中年级)(2021年12期)2021-12-30
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机应用(2020年12期)2020-12-31
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
