
融合时空特征的光伏气象因子预测模型
2022-12-06 10:38李金中王小明谢毓广汪勋婷
计算机工程与应用 2022年23期
李金中,王小明,谢毓广,高 博,汪勋婷
国网安徽省电力有限公司 电力科学研究院,合肥 230601
由于光伏电力系统容易受到天气变化随机性的影响[1],其输出功率具有明显的波动性,从而导致光伏电站供电具有很强的不确定性。这种高不确定性容易引发电力调度的混乱,降低其可靠性和安全性[2]。因此,对光伏电力系统短期内的气象因子准确预报,可以直接影响到太阳能电池组的最佳小时计划及并网调度策略,是光伏发电系统非常重要的运维保障基础。
通常天气预报只有区县级的粗粒度数据,不够精细。而分布式光伏电站的地理分布相对分散,一般天气预报无法准确预测光伏电站所在区域的天气。另一方面,一些早期建成的光伏电站由于硬件条件的限制,并未配置气象采集器,无法准确获取所在位置的太阳辐照度、温度和湿度等信息。然而临近区域的气象数据通常具有相关性,可在临近区域内将若干带有采集器的电站设为标杆电站,利用其气象数据对周边电站气象因子进行预测,甚至可以实现对整个区域的气象因子进行精细预测,从而可以为分布式光伏电站选址、系统发电计划评估和电站运行状态监测提供更加科学、全面的决策依据。
影响光伏发电的气象因子有很多,如太阳辐照度、温度和湿度等。其中太阳辐照度对光伏发电的影响最大,但其变化具有明显的周期性。在晴天的环境下,太阳辐照度从日出开始增长,至正午左右达到最高,再慢慢减少直到日落变为零,此外日最高气温与太阳辐射强度具有一定的正相关性[3]。温度和湿度对光伏发电也有影响:在一定程度上随着温度的增加发电功率呈上升趋势,但温度过高将影响光电转换效率;湿度变化规律则一般与温度相反,且随着相对湿度的增加发电功率一般呈减小趋势。因此,需要针对光伏气象因子在时空两个维度开展精细预测,从而优化电网运行,提高系统可靠性,保证电能质量,并且对光伏未来选址具有重大意义。
基于上述问题,本文提出了一种时空特征融合的光伏气象因子预测模型(spatial-temporal features model,STF),在时间和空间两个维度对光伏发电进行预测。在时间维度上,本文设计了一种改进的长短期记忆网络(long short-term memory,LSTM)模型,它在传统的LSTM单元之上增加了注意力机制和遗传算法以有效学习光伏电站历史数据的时间特征,并对光伏电站气象因子进行时间序列预测。在空间维度上,利用张量分解(tensor decomposition,TD)的方法提取区域间的空间依赖,并对周边区域天气因子数据进行预测。本模型可以实现对光伏电站周围区域太阳辐照度及其他气象因子的精准预测,同时对稀疏数据具有较强的鲁棒性,本文的主要贡献包括以下三点:
(1)提出了融合注意力机制和遗传算法的时间预测模块,给模型的输入分配基于重要性的权重来捕获数据中的时间依赖性。
(2)结合历史数据和预测数值,利用张量分解的方法预测光伏电站周围区域的气象因子数值,融合时空特征。
(3)在实验部分,使用中国东南部某光伏系统的真实数据评估本文模型,结果表明本文模型优于传统预测模型,预测精度有明显提升。
1 相关工作
对于气象因子的预测问题,国内外学者已经做了大量研究。数值天气预报(numerical weather prediction,NWP)[4]模型作为一种典型的天气预报模型,常用来预测太阳辐照度和其他气象因子。这种模型的分析基于描述天气演变的流体力学和热力学的方程组,而这些复杂的非线性方程需要强大的计算能力来求解。数值天气预报分为全球数值天气预报和区域数值天气预报。全球数值天气预报模型通常具有粗略的分辨率,不能对小尺度特征进行详细测绘。区域数值天气预报模型则可以通过缩小全球数值天气预报模型来获得,它可以解释局部效应,并产生改进的特定地点预测[5]。但NWP并不总是有效的,基于NWP的气象因子不同预测实验之间的误差差异很大,取决于实验地不同的气候和大气动力学[6],且夏季和晴天的预测准确率通常高于其他时间。
随着光伏发电的广泛应用,对气象因子预测精度和适用性的要求越来越高,由此产生了新的气象预测模型。现有的预测模型包括统计模型和基于卫星云图的模型[7-10]。基于卫星云图的模型利用运动矢量场来检测云层的运动,依靠之前记录的时间步长来确定云结构再进行预测,但由于云预报的误差存在,预测结果也会受到影响。
统计学习模型包括时间序列[11]、小波分析[12-13]、人工神经网络(artificial neural network,ANN)[14-16]、支持向量机(support vector machines,SVM)[17]、卷积神经网络(convolutional neural networks,CNN)[18]。基于统计学习方法的预测模型通常优于其他预测技术。文献[13]利用经验模态分解和向量机相结合构建的模型进行逐时预测。结果表明,其提出的预测系统在预测精度方面表现出优越性。文献[16]利用ANN模型对我国东南部山区月度平均太阳辐射量进行估算,估算值与实测值有较好的吻合度。但使用ANN模型的一个缺点是,在模型结构复杂或数据有大量噪声的情况下,模型训练过程可能导致性能不佳。而且ANN等方法需要较多的参数,无法很好适用于稀疏数据集。
长短期记忆神经网络[19]适用于时间序列预测,可以提取时序数据的长短期特征。张量分解法在气象因子的预测中尚未得到广泛应用,但它简单易用,在空间预测中表现良好。基于张量分解的方法目前较多应用于城市计算领域,通常结合多种数据集进行不同类型的预测,如对城市噪声[20]的推测和分析,针对难以直接获取的数据或稀疏数据,能有效分析数据分布变化规律,预测空缺位置数值。
2 时空特征融合预测模型
2.1 总体结构
STF模型训练的基本思想是:首先将训练集的多种气象因子相关数据分别进行归一化操作并输入时间预测模块进行训练。随后获取预测结果,并把得到的预测数值和历史数据拼接在一起构建张量,最后利用张量分解方法进行空间预测。构建张量的方法是根据经纬度数据进行网格划分,再按照光伏电站所在位置对数据建模。由于电站所处地理位置相近,因此其他电站的气象因子数据也可作为预测依据。此外,对于分布位置分散的光伏电站,建模后张量变得极为稀疏,但模型仍可从占比较小的数据中学习规律,预测周边未设置采集器区域的气象数据并进行评估。模型训练过程如图1所示。

图1 模型训练流程图Fig.1 Flow chart of model training
具体的模型训练流程主要为:
(1)对历史气象数据进行归一化处理,将其映射到[0,1]区间,再送入融合遗传算法的改进LSTM模型训练。
(2)根据历史数据和时间维度预测结果构建张量X。
(3)在X中划分训练集和测试集,进行张量分解操作,得到空间预测结果。
(4)将训练集进行迭代训练,根据目标函数计算损失。
(5)判断误差是否收敛,若不满足则重新进行训练,满足则得到最终的气象因子预测结果。
STF预测模型结构如图2所示。其结构主要由时间预测模块和空间预测模块组成,时间预测模块从历史气象数据中提取时间依赖性,进行训练后对光伏电站数据进行时间维度上的预测并输出。然后将数据建模,利用空间预测模块进行空间维度上的预测,最终得到周围未设置采集器区域的气象预测值。接下来将详细说明时间预测模块以及空间预测模块的结构和作用。

图2 模型结构图Fig.2 Model structure diagram
2.2 时间预测模块
时间预测模块的作用是学习历史气象数据的时间依赖性,对光伏电站未来历史数据进行预测。传统的LSTM可以解决长期依赖的问题,但它也存在一些不足,如对随机权重值敏感和容易陷入局部最优。因此本文在传统LSTM网络中增加注意力机制和遗传算法来提高预测精度,构建出一种改进LSTM模块用于时间维度预测,它主要由传统LSTM层、注意力层和遗传选择操作构成。
2.2.1 LSTM层和注意力层
注意力机制(attention mechanism)的基本思想是关注重要部分,同时忽略无关部分的影响。因此本文在传统的LSTM模型中增加一个注意力层,它可以给对预测结果贡献度高的输入分配更大的权重,同时给其他输入分配较小的权重以避免注意力分散,从而提升预测结果准确度。
首先,针对滑动窗口内的各光伏电站历史数据,在注意力层中生成N×N个随机气象权重序列,如下所示:

式中,Wi代表第i个气象权重序列,M表示权重集合数量,等于N×N。
基于生成的注意力权重,对输入的历史气象数据进行采样并送入LSTM,输入的计算如下所示:

LSTM通过输入门it,遗忘门ft和输出门ot得到输出yt,计算过程如下:

式中,σ(·)表示sigmoid激活函数,Ct表示单元格状态,ht表示隐藏状态。
2.2.2 遗传选择
同时,为了获得最优气象权重序列,还利用遗传算法训练注意力层。遗传算法[21](genetic algorithm)通过模拟生物进化的过程寻找全局最优解,具有更强的全局搜索能力,可以进一步提高LSTM的预测精度。
在得到初步预测结果后,利用预测的气象因子数值和真值得到训练误差,找到最小训练误差对应的N个气象权重集合作为最优子集W͂,对其进行0-1编码转化为,再利用遗传算法中的变异和交叉操作生成新的权重集合,作为新的优化空间进行下一轮的训练。遗传选择的流程如图3所示。

图3 遗传选择示意图Fig.3 Graphical illustration of genetic selection operation
在生成新的气象权重集合时,每个气象权重序列由于经过0-1编码,全部由二进制字符组成,它们会被均匀地分割为L个片段,则相应地可以被表示为,其中的一个片段。
在最优子集中的每一个气象权重序列随机选取若干个片段,每一次训练中被选中的片段数量并不固定。假设来自不同序列的片段SM j和SM i为最优子集中的两个权重序列中被选中的片段,以此为例说明变异和交叉操作:
交叉操作:交换SM j和SM i中的随机位置编码,生成新的片段SM k作为新权重序列的一部分。
变异操作:将选中片段的随机位置取反,如将1变为0或将0变为1,形成新的片段,取代原先的片段。
在生成新的优化空间时,最优子集会被重复遍历,直到新的气象权重集合达到原先的大小。
2.3 空间预测模块
空间预测模块的主要作用是将光伏电站气象因子数据进行张量建模,再由张量分解方法学习数据间的空间关联性,利用标杆电站数据在空间维度预测为设置气象采集器区域的气象因子数值。
2.3.1 张量构建
此算法将每个光伏电站的气象因子数据建模为张量X∈ℝN×M×L。其中它的三个维度分别表示共有N个实验点、M个时间间隔和L天的数据。在给定的时间区间内(如一个月),张量的每一个条目X(i,j,k)存储着第si个实验点在第dk天的第tj个时间间隔内的气象因子数据。对于未设置采集器的实验点所在条目,在实验中将用模型预测出的值填充。由于所有电站都处于一个区域,所处地理位置相近,电站本身地理位置及周边电站的天气数据也可作为预测的依据。其中,将所有光伏电站分布的区域按照经纬度划分若干相同大小的网格,每一个网格被视为一个实验点,实验点被表示为s={s1,s2,…,si,…,sN},时间间隔被表示为t={t1,t2,…,tj,…,tM}。本文将每一天划分到相等的时间间隔中,每个时间间隔为一小时。同时由于太阳辐照度只在白天收集,所以在太阳辐照度的预测中,只取8:00—18:00的区间。天数则被表示为d={d1,d2,…,di,…,dL}。
2.3.2 张量分解
张量分解模块的主要作用是利用光伏电站的气象数据预测未设置采集器区域的气象因子数据。张量分解的一种常用方式为Tucker分解[22],它可以看成是高阶主成分分析(principal component analysis,PCA)分解的一种形式。如图2右半部分所示,对于一个n维张量,Tucker分解的基本做法是将原张量分解为一个核心张量和多个因子矩阵的乘积。其中,核心张量表示不同元素如何以及在哪些维度相互影响,而因子矩阵对应着原张量每个维度不同比例的缩放,因子矩阵也被称为其各自对应维度的主要组成成分。
在三维张量情况下,Tucker分解可以表示为:

其中,S∈ℝI×P,T∈ℝJ×Q,D∈ℝK×R表示因子矩阵;G∈ℝP×G×R表示核心张量。×I表示张量矩阵乘法,而I表示张量的指定维度,如H=G×IS即为⊙表示矢量外积,即张量的每一个元素都为相应矢量元素相乘的结果。同时,当P<I,Q<J,R<K时,G可以被视为X的压缩状态。
此时,需解决的优化张量分解的目标函数即为:

使用逐元素优化算法来单独更新张量的每个元素,并利用梯度下降的方法寻找局部最优解,当目标函数开始收敛时,即两次迭代的损失小于ε时,则停止迭代。
最终,STF模型训练的目标函数为:

式中,L(·)表示损失函数,F(·)表示STF模型,θ表示模型参数空间。
3 实验结果与分析
3.1 数据集
本文使用了2019年7月来自中国东南地区某光伏系统114座光伏电站(纬度范围为30.25°N~31.33°N,经度范围为110.11°E~110.5°E)的气象因子数据,气象因子为温度、湿度和太阳辐照度,采样周期为1 h,基本信息如表1所示。图4描述了在不同天气状况(晴天、阴天和雨天)下,夏季光伏电站发电功率在8:00—18:00(5 min为一个节点)的变化曲线。由图中可以看到,晴天不同时刻的发电功率变化呈现先增加后减少的趋势,且基本和太阳辐照度变化周期符合,而阴天和雨天不同时刻发电功率则波动较大,且雨天总体发电功率相对较小。而随着天气状态的变化,影响光伏发电的气象因子也会随之变化,因此预测气象因子可为接下来光伏系统的功率预测和性能评估提供参考。
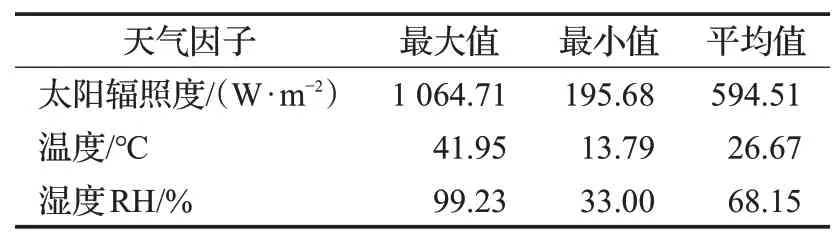
表1 实验数据集基本信息Table 1 Basic information of dataset
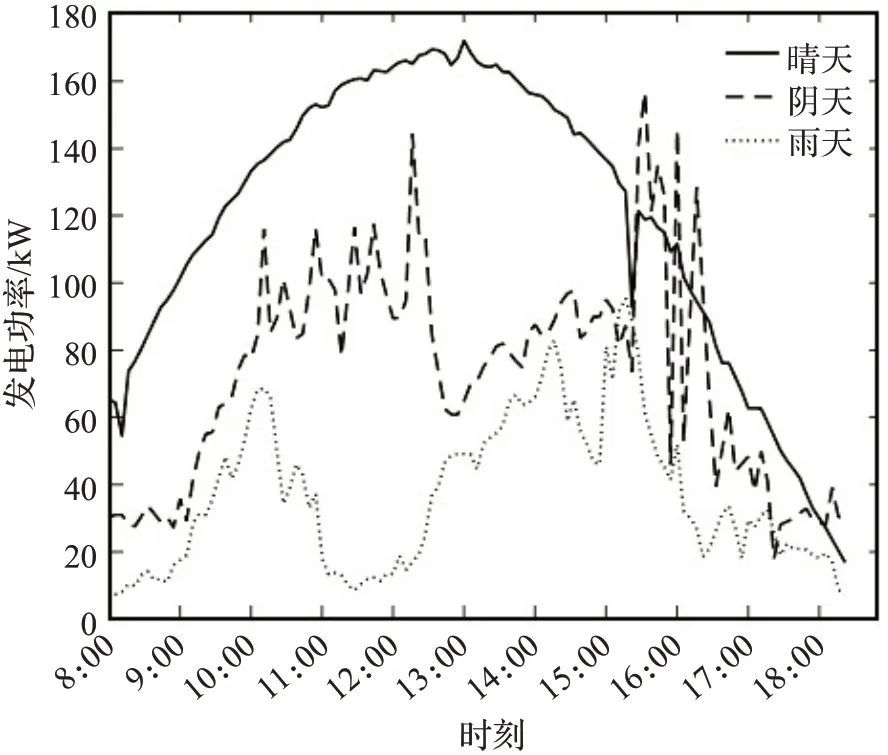
图4 夏季不同天气状况下光伏发电功率曲线图Fig.4 PV power curves in different weather conditions
每一个光伏电站都装有气象采集装置以记录气象因子相关数据。实验中,各光伏电站的三种气象因子数据一起输入模型中学习,进行温度和湿度的预测实验时,共有68 058条数据记录;进行太阳辐照度预测实验时,由于夜晚太阳辐照度为0,故只留下每日8:00—17:00的条目,则共有28 620条数据记录。
在时间序列预测中,针对不同预测维度进行实验:短期预测实验中将数据集30天的数据作为训练集拟合模型,数据最后1天的数据作为测试集进行预测;长期预测实验则将前27天数据作为训练集,对最后4天的数据进行预测,以测试模型性能。
对于空间预测实验,则根据经度和纬度将光伏系统所在区域划分为不同大小的网格,若网格对应经纬度有光伏电站分布,则该网格中将存储这些光伏电站相关数据的平均值,如果没有光伏电站分布,网格中数据则为零。按纬度和经度划分后,由于大多数网格中都没有数据,因此数据集变得非常稀疏。
3.2 评估指标
本文使用两个度量评估预测准确性,分别是平均绝对误差(MAE)和均方根误差(RMSE)。误差指标的值越小,表示预测精度越高。

其中,n表示预测值的总数,yi表示第i个条目的实际值,ŷi表示第i个条目的预测值。
3.3 实验参数设置
实验采用Tensorflow框架实现工程代码,权重序列集合大小被设置为6×6,即共有6个权重集合,每个集合内有6个权重,每个权重序列的被划分的片段总数也为6。
同时,由于不同气象因子数值差异较大,最终实验结果均为归一化后的结果,且都通过2.1节训练流程计算得出,并且对应以下参数:P=Q=R=10,ε=0.001,λ=0.001。
为了提高模型收敛速度,减少训练过程中学习率的手动调节,预测模型采用Adam优化器,batch_size为128,激活函数为Relu。每个对比实验都被重复训练5次,取平均值作为最终结果。
3.4 模型评估
3.4.1 时间序列预测
为验证本文模型的有效性,本文选取DLWP-CNN[18]模型、4-LSTM[19]模型和FA-DRNN[23]模型进行对比,来对STF模型进行评估。
短期预测实验中,每种气象因子预测实验MAE和RMSE结果如表2所示。实验结果表明本文提出的模型具有最高的预测精度。通过比较STF模型与DLWPCNN、FA-DRNN和4-LSTM模型对太阳辐照度预测的性能指标表明,STF模型的MAE分别降低了93.10%、78.89%、37.41%,RMSE分别降低了95.80%、86.57%、60.46%,各项预测误差均有明显改善,大幅度提高了预测精度。

表2 短期气象因子预测实验结果Table 2 Short-term meteorological factor prediction results
光伏电站的短期预测误差如图5所示,可以看出,实验结果表明,DLWP-CNN具有较大的预测误差且波动较大,FA-DRNN变化趋势与真值一致但预测精度不高,而4-LSTM预测精度也弱于本文提出的STF模型。STF模型的预测曲线和真值曲线相差很小,说明该模型有较强的短期预测能力。在长期预测的实验中,每个气象因子的MAE和RMSE结果如表3所示。实验结果表明,STF模型对三个气象因子长期预测误差较短期都有所增加,但都优于其他对比模型,说明本文提出的STF模型具有较强学习能力,能从历史数据中发掘联系,并利用数据中规律进行准确预测,因此对于不同预测尺度都具有较高鲁棒性。

表3 长期气象因子预测实验结果Table 3 Long-term meteorological factor prediction results

图5 光伏电站短期预测误差Fig.5 Short-term prediction error of PV power station
太阳辐照度长期预测的结果如图6所示。由图可知,DLWP-CNN的变化趋势与真值相差较大;FA-DRNN和4-LSTM的变化趋势在前半部分与真值相差不大,但在后半部分太阳辐照度出现波动时无法准确捕捉其变化趋势从而出现偏差;而STF的变化趋势则始终和真值一致。
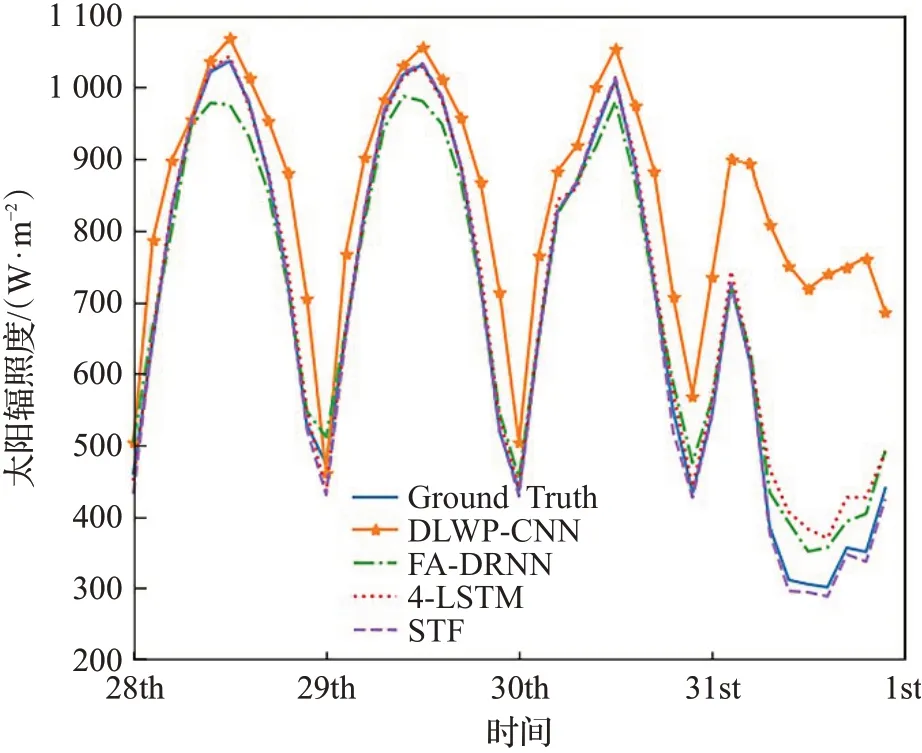
图6 光伏电站长期预测误差Fig.6 Long-term forecast error of PV power station.
3.4.2 空间预测
同一区域的温度和湿度在一定时间范围内变化幅度不大,但每个小区域的地形差异导致其太阳辐照度变化趋势不尽相同,且每天的太阳辐照度由于天气变化而呈现不同变化趋势,因此仅针对太阳辐照度进行空间预测评估。
实验中通过设置不同的网格大小探究模型对稀疏数据的学习能力,同时本文将所有网格的总数作为张量的第一维,因此网格大小分别为0.008°×0.008°、0.01°×0.01°、0.03°×0.03°、0.05°×0.05°和0.1°×0.1°,因此对应的张量大小分别为6 850×10×31、4 360×10×31、518×10×31、207×10×31和60×10×31。其中当网格大小为0.01°×0.01°时,构建完的张量中非零条目占比只有2.1%。
实验中,将短期时间序列预测的值和训练样本组合构建张量,再从张量中随机删除30%的非零条目作为测试集,由模型预测无光伏电站分布网格的数值,再将预测值与真值计算得到误差。
空间预测的实验结果如表4所示,STF-08、STF-1、STF-3、STF-5和STF-10分别表示划分网格大小为0.008°×0.008°、0.01°×0.01°、0.03°×0.03°、0.05°×0.05°和0.1°×0.1°的模型。由表中可得各网格大小的STF空间预测结果远好于线性插值(linear interpolation,LI),并且虽然STF-1所代表的网格最小,即建模后张量最稀疏,但其空间预测结果精度最高,说明本文提出的STF模型对稀疏数据有较强的鲁棒性。STF-08的预测精度较低,这或许是由于划分粒度太小使得未包含光伏电站网格的所占比例过小且网格数量过大,为空间预测增加了难度。STF-3、STF-5和STF-10的预测精度低于STF-1,或许是因为这些划分网格方案中,部分网格包含多个光伏电站,网格中存储的是这些光伏电站气象数据的平均值,降低了光伏电站间的空间关联性从而影响了预测结果。同时STF-10的预测误差小于STF-5,这说明虽然划分网格的粒度降低了光伏电站的空间关联性,但是网格数量的大幅减少也降低了空间预测的难度,从而使得预测精度有所上升。因此根据实验结果,最后的网格划分方案为0.01°×0.01°,下文中的STF均指代STF-1。
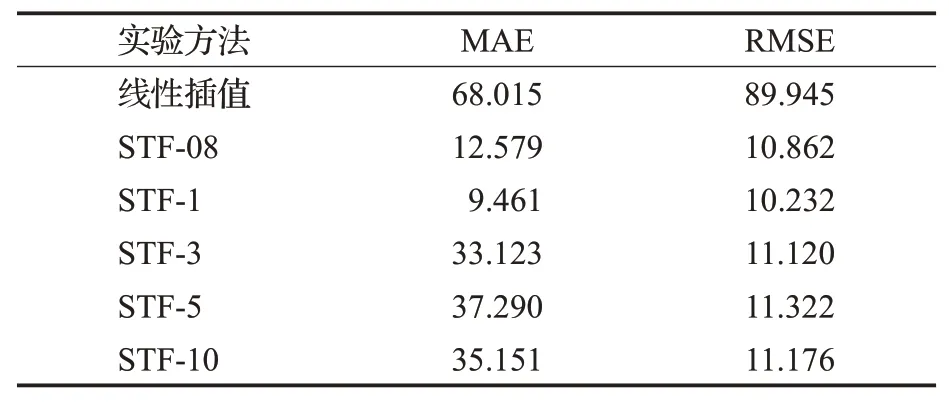
表4 空间预测实验结果Table 4 Performance on spatial prediction experiment
空间预测实验结果可视化结果如图7所示。图中为预测日16:00的数据,图(a)为光伏电站分布位置,图(b)中网格颜色越深代表其数值越大。由图7可知,预测的无光伏电站分布网格中的太阳辐照度受到各自所在行列已知数据影响,呈现较均匀分布状态,较少出现极大数据。光伏电站密集分布区域如图(b)右侧中间部分,预测的太阳辐照度数据相对靠近已知数据。实验结果证明该模型对于空间预测是有效的,且对于稀疏样本有较强鲁棒性。

图7 空间预测结果Fig.7 Result of spatial prediction
4 结束语
本文针对太阳辐照度及其他气象因子预测问题,提出了一种基于改进长短时记忆网络和张量分解的时空融合光伏气象因子预测模型。在LSTM模型的基础上增加注意力机制和遗传算法进行时间序列预测,克服了传统LSTM对随机权重敏感和易陷入局部最优的问题;根据经纬度划分光伏电站所在的区域,并拼接时间序列预测结果构建三维张量,再通过张量分解进行空间预测,克服了在稀疏数据集上预测结果不佳的问题。实验表明,本模型对时间维度和空间维度的精准预测气象因子行之有效,且面对稀疏数据较为鲁棒。该模型具有良好的工业和商业价值,可以为光伏电站性能评估和运维提供数据基础。
猜你喜欢
西南师范大学学报(自然科学版)(2022年1期)2022-03-02
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
宁夏师范学院学报(2021年1期)2021-03-18
五邑大学学报(自然科学版)(2020年4期)2020-12-09
汽车维修与保养(2020年11期)2020-11-23
建材发展导向(2019年5期)2019-09-09
山东工业技术(2017年17期)2017-09-13
中国建筑科学(2017年6期)2017-07-20
风能(2016年8期)2016-12-12
中国建筑科学(2014年7期)2014-09-29
