
基于参考图像的原子模型渲染方法
2023-01-13 06:10吴苗苗顾兆光
图学学报 2022年6期
吴 晨,曹 力,秦 宇,吴苗苗,顾兆光
基于参考图像的原子模型渲染方法
吴 晨1,曹 力1,秦 宇1,吴苗苗1,顾兆光2
(1. 合肥工业大学计算机与信息学院,安徽 合肥 230601; 2. 香港量子人工智能实验室有限公司,香港 999077)
伴随着生物学的发展与纳米电子器件仿真技术的进步,原子结构在现代化科技领域发挥至关重要的作用。原子结构的复杂细节使得渲染效果受光源位置影响较大,导致了原子模型渲染工作的困难。基于此,提出了一种基于参考图像的原子模型渲染方法,计算出参考图像的光照参数用于原子模型的渲染。首先,通过改变光源位置,利用POV-Ray脚本实现不同光源角度下的批量模型渲染,采集光源位置参数及渲染图像得到对应光源位置的渲染图像数据集;接着,以残差神经网络为主干设计光源估计网络,并在网络中嵌入注意力机制提升网络准确性,使用优化后的光源估计网络对数据集进行训练,回归光源位置参数;最后将训练好的卷积神经网络应用于参考图像的渲染参数估计中,利用渲染参数渲染目标模型。实验结果显示。通过网络预测的参数与真实照明参数误差极小,具有高度可靠性。
原子结构;模型渲染; 光源位置; 参考图像; 光源估计网络
原子结构依赖其化学特性存在细节多、结构复杂等特点,在渲染过程中若不经考虑地施加光照会对渲染效果造成一定影响,如图1所示。
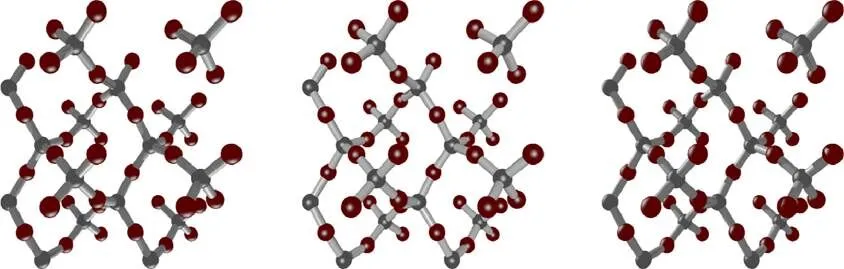
图1 不同光源位置的原子模型渲染图像
目前原子模型的渲染主要依靠通用三维模型渲染软件和专业化学可视化软件实现。然而在模型渲染过程中,往往需要专业人员经过多次交互调整材质、光照、相机等环境参数,对非计算机专业使用者操作和渲染工作存在一定难度。
在混合现实光照研究中,JACOBS和LOSCOS[1]针对真实场景下的几何模型的渲染技术做了详细介绍与分类。在对渲染参数估计的研究中,刘万奎和刘越[2]总结了目前的最新研究进展,其中,图像分析法不需要借助多余的硬件设备,运用神经网络、图像处理等技术分析光照,是近年来光照估计领域的重要发展方向。FU等[3]提出了一种基于形态闭合的光照估计算法。估计的光照参数代表了自然度和亮度,适用于单幅图像。与传统光照参数估计不同,GUO等[4]只估计了一个光照参数,首先通过找到RGB通道中每个像素的最大亮度来构造光照图,然后利用光照的结构来细化光照贴图。此举虽然降低了计算成本,但仅适用于一个小求解空间。SHI等[5]将一种新的深度专门网络用于估计局部光源,使用假设网络和选择网络构成一个新的卷积网络架构,假设网络生成多个以其独特的双分支结构捕获不同模式光源的假设,然后选择网络自适应地从这些假设中选择有信心的估计。LORE等[6]提出了一种训练数据生成方法,使用伽马校正并添加高斯噪声来模拟低光环境,证明了用合成数据训练的模型的有效性。提供的关于模型学习到特征的见解,使网络权值可视化。MARQUES等[7]提出了对混合现实场景的光源位置估计,用于估计位于HMD设备中的单个RGB相机的照明特性,有效地减少了在混合现实应用中照明不匹配的影响。KÁN和KAUFMANN[8]提出了一种基于RGB-D图像的光照估计方法。其训练数据集来源于5个简单的场景用随机的光源位置和摄像机位置进行渲染得到,训练神经网络从RGB-D图像中估计光的方向。CUI等[9]基于残差学习对光源颜色进行了估计,在精度与稳健性水平上有较大提升。在对非均匀光照图像进行光照估计中,传统的光照估计算法往往不能在保持自然的同时有效地估计光照。基于此,GAO等[10]提出了一种基于联合边缘保持滤波器的自然保持光照估计算法,综合考虑空间光滑性、光照边界边缘尖锐、光照范围有限等约束条件。LI等[11]采用了整体逆渲染框架,提出了新的方法来映射复杂的材料到现有的室内场景,使用基于物理的GPU渲染器创建的真实室内数据集来训练深度卷积神经网络,从单个图像中估计出分离的形状、非郎伯表面反射率和光照,但在真实数据集上训练的效果并不突出。
针对不同类型的模型,采用特定的渲染方法[12-14]通常能达到更好的效果。原子模型渲染图像主要应用于量子物理与材料化学领域的书籍杂志附图,撰稿人与编辑往往对计算机渲染技术掌握了解甚少。目前现有原子模型渲染工具如POV-Ray和Pymol等虽然能产生较好的渲染效果,但对于非专业用户来说,想根据已有原子模型得到预期的渲染效果相当困难。因此,本文提出了一种基于参考图像的原子模型渲染方法,根据需求者提供的参考图像学习其光源参数,对目标原子模型进行渲染。首先对原子模型渲染进行分析,提出采用残差神经网络对参考图像的光源渲染参数进行预测。其次对所采用的神经网络进行分析与优化,接着对数据集、损失函数和其他训练细节展开详细介绍,最后从各个方面对该方法进行评估。
1 相关工作
1.1 原子模型生成
原子模型是物体内部构成的原子结构的模型化表达。由于物体内部各个粒子的分布排列遵循一定的化学规律,因此能够建立三维模型清晰地展现出物体内部粒子结构与排布状态。原子结构的渲染效果有多种表现形式,其中球棍模型与空间填充模型是最具代表性的2种分布形式,如图2所示。球棍模型中用球模型代表原子,棍模型则代表原子之间的化学键;与球棍模型相对,空间填充模型不依赖化学键作用,且由许多重复的结构单元组成,根据其不同特性呈线状结构或枝状结构。
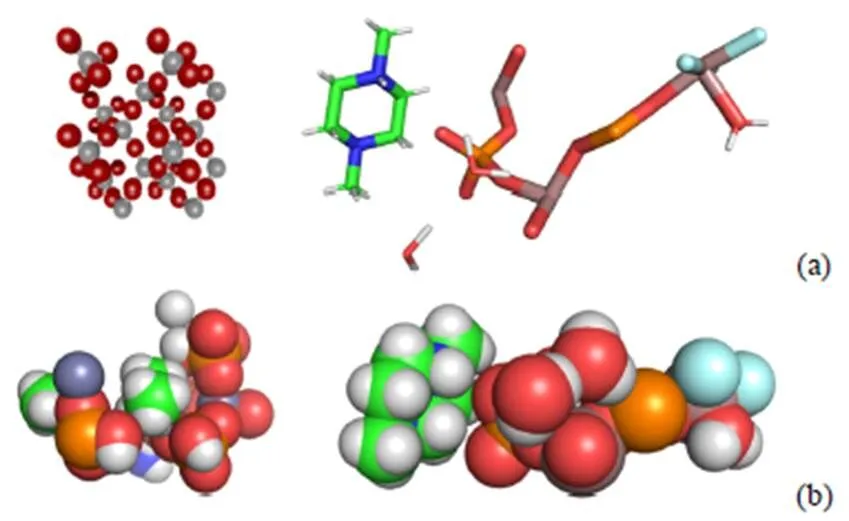
图2 原子结构模型((a)球棍模型;(b)空间填充模型)
现有的原子模型仿真技术更多将功能聚焦于原子处理,如HASEM[15]和Atomsk[16],在原子模型生成与编辑上效率较低。曹力等[17]利用高效生成原子模型的方法,预先将各种材料和不同粒子间的相互关系设计成预制结构;创建模型前,只需创建若干基本的图元,再选择各图元相应材料并将其组合成一个复合图元;依据复合图元的材料信息选择合适的界面预制结构,最终生成设计器件的原子模型。在调研过程中发现硅原子结构因其化学特性,拥有周期性排列风格。同时,作为复杂的晶体模型结构,硅原子结构在半导体研究中广泛使用。本文利用该方法以硅原子结构为基准制作了5个球棍模型,如图3(a)所示。美国矿物学家晶体结构数据库收录了发表在包括Chemistry of Minerals等期刊文献上的每个原子结构,本文根据排列形态、元素包含的异同在其中选择涵盖了构成生物大分子的基本元素的5个空间填充模型,如图3(b)所示。以此5个模型制作的图像数据集按照2.1节的数据集制作方法制作图像数据集作为训练数据,分别对非同类型的空间填充模型进行测试,测试结果均达90%以上,实验结果显示,本文所选空间填充模型具有一定的泛化能力。
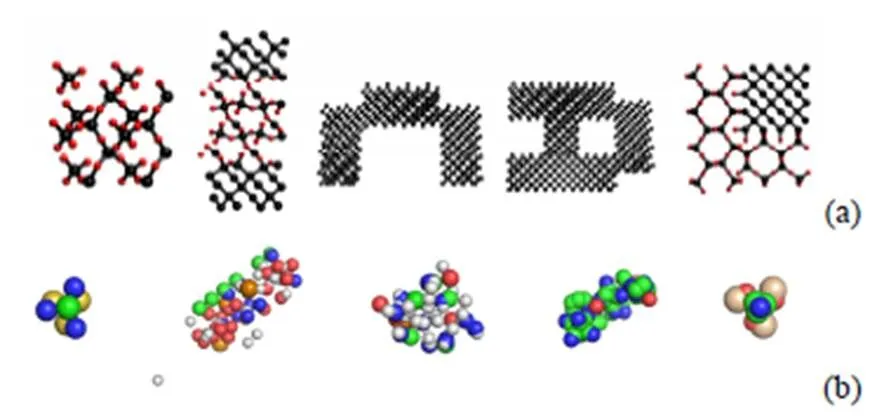
图3 原始原子模型((a)球棍模型;(b)空间填充模型)
1.2 残差神经网络
残差神经网络(residual neural network,ResNet)[18]作为最经典的卷积神经网络模型之一,发现并解决了卷积神经网络中的退化现象。ResNet以残差块为基本结构,将学习目标转为对网络残差的学习,网络依旧可以通过端到端的反向传播训练。由于其简单高效的特性,极大程度上减少了深度过大时神经网络训练困难的问题。
ResNet18 网络结构如图4所示,首先经过一个卷积模块,然后依次连接2个stage,每个stage由2个常规残模块组成,最后是平均池化和全连接层。其中,跳层连接中的实线表示网络输入和经前向神经网络映射后的输入通道相同,可以直接相加,虚线箭头表示将网络输入的维度调整之后再相加。相较于其他卷积神经网络层次较深时无法训练的情况,ResNet18网络从本质上解决了此问题,保证了训练的正常进行。

图4 ResNet18网络结构
2 本文方法
在原子模型的渲染过程中,光源位置异同对渲染效果有显著影响。在深度学习日渐成熟的同时,卷积神经网络在计算机视觉与图像图形领域中的应用较为广泛[19-22]。通过训练一个卷积神经网络,从大量数据集中学习图像特征,典型的有深度图预测[19]、放射率图预测[20]等。但针对原子模型的渲染方法尚未被提出。传统方法聚焦于真实图像的光照估计研究,侧重于光照强度与颜色估计。然而真实场景中的光照信息只能根据预测后的渲染效果进行主观评价,无法定量评估。目前,想要得到渲染效果优秀的原子模型图像,仍需要用户与渲染工具间持续交互与迭代,效率低下。
基于此,本文提出了一种基于参考图像的原子模型渲染参数估计方法。选择已渲染好的原子模型渲染图像作为参考图像,估计其光照参数信息并应用于目标模型的渲染,在提升了原子模型渲染效率的同时还简化了模型渲染的交互过程。具体方法为:选取理想的光源渲染图像作为参考,分析预测参考图像中的光源特征,估计其渲染参数,用该参数信息对原子模型进行渲染。具体地,通过改变光源位置,利用POV-Ray脚本实现原子模型的批量渲染,收集原子模型渲染图像,得到对应光源位置的渲染图像数据集。以ResNet18网络为主干网络设计光源估计网络,并在网络中嵌入注意力机制提升网络性能。使用优化后的光源估计网络对数据集进行训练。将训练好的卷积神经网络应用于参考图像的渲染参数估计中,利用渲染参数渲染目标模型。渲染流程如图5所示。

图5 基于参考图像的原子模型渲染流程示意图
2.1 数据集设置
POV-Ray[23]是一个使用光线跟踪绘制三维图像的开放源代码免费软件,其根据文本的场景描述语言生成渲染图像。图像格式支持纹理渲染和输出,功能简单、使用方便。首先编写脚本生成 POV-Ray软件可执行的场景描述文件;接着使用 POV-Ray批量执行文件,生成渲染图像。
在三维坐标系中,可以用一对二元组(,)来表示点光源相对于待渲染模型的位置[8]。其中,和分别表示偏角和倾角,取值范围分别为0~360°与0~180°之间。将原子模型中心固定在三维坐标系原点,摄像机位置置于轴负向,朝向为轴正向。光源初始位置固定于轴正向,通过改变偏角与倾角的大小改变光源位置。在实验中发现,光照位置参数差值在10°以内的对渲染效果影响较小,如图6所示。故本文实验中以5°为间隔设置采样区间,在保证实验精度的同时减少训练时间。采样位置示意图如图7所示,其中曲线的交点为光源位置的采样点,通过均匀改变偏角与倾角的大小,对点光源位置参数进行采集,得到2 592组参数对{(0,0),(0,5),···,(α,β),···,(355,175)},并以此对原子模型进行渲染得到图像库。对1.1节中提到的10个原始原子模型按照上述方式进行渲染,得到共25 920幅原子模型光照渲染图像,各个渲染图像对应特定光照位置参数,得到三维光照模型渲染数据集。

图6 光照参数相差5˚渲染效果对比图

图7 光源采样位置示意图
2.2 光源估计网络
光源估计网络选取ResNet18作为主干卷积神经网络来提取图像特征,学习参考图像与渲染参数之间的联系。如图8所示,网络架构包含1个卷积层、4个残差网络块和2个全连接层。网络输入为224×224×3的渲染参考图像,输出为光源位置参数。卷积核大小为7×7,步长设为2。卷积层后连接1个使用最大池化方法的池化层,能显著减少参数误差引起的估计均值的偏移。残差网络部分由4 组残差网络结构组成,每组包含2个残差块。其中,第一组残差网络的输入通道和输出通道相同,不需要下采样层,其他3组由于经过跳层连接,均需要连接下采样层调整网络输入维度。经过残差模块之后连接1个平均池化进行特征选择和信息过滤。然后经过2层全连接层,提高网络模型的非线性表达能力。
本文选取Relu函数[24]作为激活函数,对除全连接层以外的每一个卷积层进行激活,Relu函数提供了更加高效的梯度下降以及反向传播,避免了梯度爆炸和梯度消失问题;省去了其他复杂激活函数中诸如指数函数的影响,简化了计算过程;同时活跃度的分散性使得神经网络整体计算成本下降。输出层包含2个神经元,分别代表光照参数和。将实际图像作为输入,网络回归二维向量(,)。
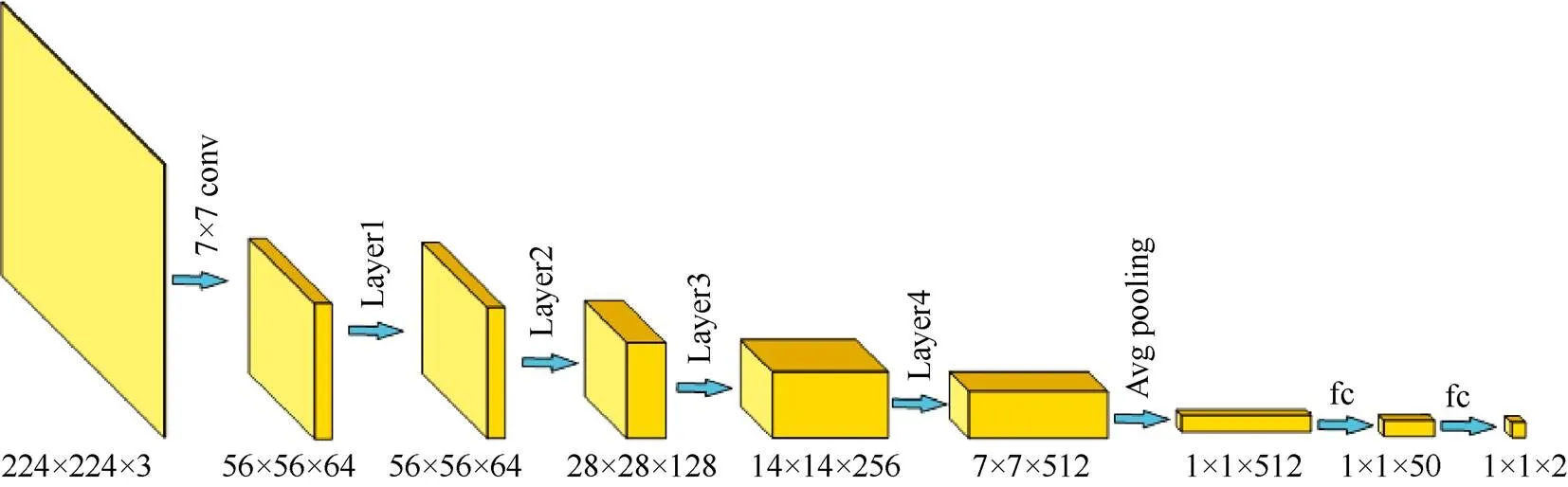
图8 光源估计网络
2.3 网络优化
在光源估计网络中,网络根据原子模型的渲染情况对光照进行估计。在图像中,原子模型根据不同光照位置所反映的情况是网络更值得关注的内容。注意力机制[25]主要包括2个方面:决定需部分;有限的信息处理资源分配给重要的部分。对于原子模型渲染图像来说,需要关注的点在于图像中受不同位置所反映的原子模型情况。基于此,本文考虑在光源估计网络中引入注意力机制。
注意力机制可划分为空间注意力和通道注意力,空间注意力[26]涉及一个空间转化器模块,可找出图片信息中需要被关注的区域,同时该模块具有旋转、缩放、变换的功能,图片局部的重要信息能够通过变换被提取出来。在本文中,可旋转的空间转化器会对光照位置的估计产生误判,故不适用,在实验部分对此进行了论证。SENet[27]是最经典的通道注意力机制之一,其所设的SE模块核心思想是通过网络根据损失函数去学习特征权重,放大有效特征图权重,减少无效或效果差的特征图权重,通过此方式训练模型使其达到更好的结果。按照图9的方式调整残差块,首先对空间维度进行挤压,然后通过2个全连接层学习到通道注意力,再经过Sigmoid归一化得到权重矩阵;将其与原矩阵相乘得到空间维度加权之后的特征。
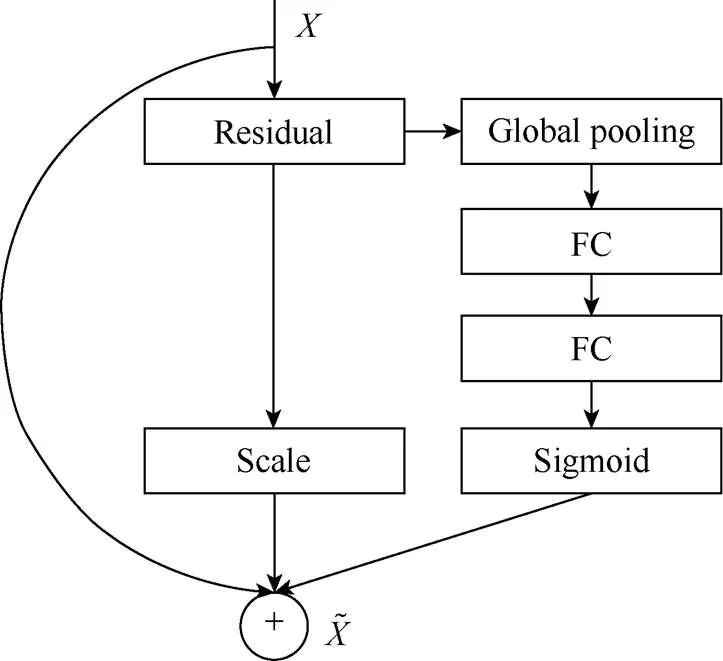
图9 SE-Net模块架构
2.4 损失函数设置
均方误差(mean square error,MSE)与平均绝对误差(mean absolute error,MAE)是最常用的回归损失函数。MSE是目标变量与预测值之间距离平方之和;MAE是目标变量和预测变量之间差异绝对值之和。具体为


为了使回归模型更快收敛,在图像集预处理时需要将参数标签和渲染图像做归一化处理。由于参数范围是范围的2倍,如果使用上述2种回归损失函数,会导致倾角参数的回归误差比偏角参数的回归误差大一倍。基于此,本文使用平衡量纲的方式对均方误差损失函数进行了改进,即


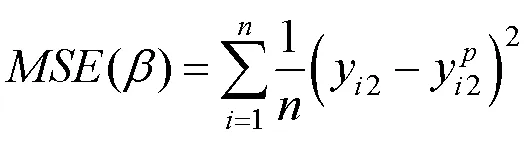
3 实 验
3.1 网络训练细节
实验在CPU为酷睿i7-7700K/4.2 GHz、内存16 GB的计算机上运行,使用开源深度学习框架Pytorch进行网络训练,训练时间和测试时间分别为49 482 s和36 s。初始学习率设置为0.001,批尺寸设置为32,训练次数epoch设置为100。实验使用的图像数据集是25 920幅原子模型光照渲染图像以及每幅图像对应的2个光源位置参数。其中随机抽取数据集中90%图像作为训练集,其余作为测试集。光源位置估计网络为回归型网络,在训练开始之前,需要对数据集的图像和标签统一做归一化处理。
3.2 网络性能评估
实验选取了4种经典深度学习网络模型作为实验对照,分别将原子模型渲染图像数据集在LeNet[28],AlexNet[29],VggNet[30]和GhostNet[31]网络框架下进行训练,以验证本文所采用的光照估计网络的性能。图10显示了原子模型渲染图像数据集在4种卷积神经网络框架下训练时损失函数随网络迭代的变化曲线。可以明显看出本文所采用的网络收敛速度显著优于其他网络。
表1显示了渲染数据集在本文与4种经典卷积神经网络框架下进行训练后的预测效果。表格中数值分别表示光照参数与经预测的准确率,实验设置以10°大小为误差范围,即预测值与真实值之差在10°以内,认为预测结果正确。通过相同的训练集与测试集计算网络的准确率可以看到本文选用的网络预测准确率达到最高。
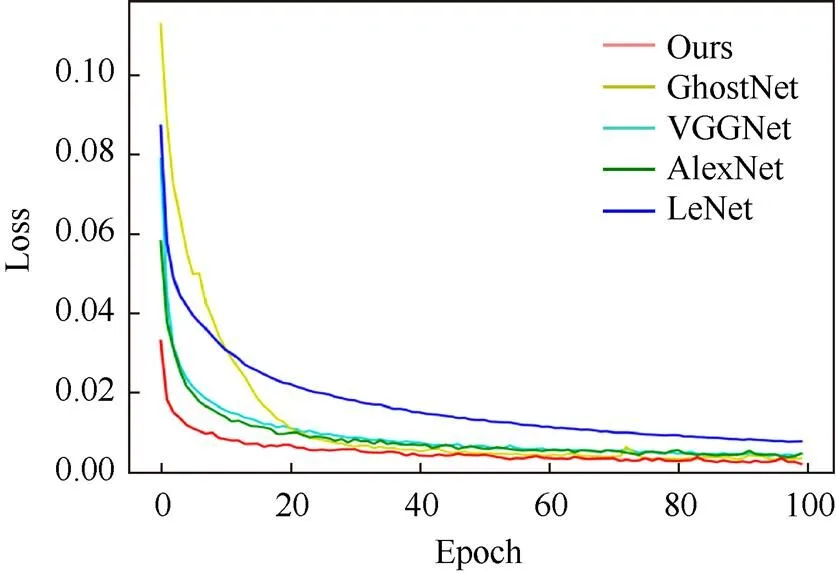
图10 不同网络框架下损失函数变化曲线对比

表1 不同网络框架下渲染参数预测效果对比
3.3 网络优化分析
实验对光源估计网络中的注意力机制的选取进行了消融实验。针对光源估计网络,设置对比项:添加空间注意力与通道注意力。实验结果见表2,引入通道注意力后的光源估计网络对渲染参数预测结果在误差小于2˚范围内有显著的提升,验证了2.3节的观点。实验结果证明:在引入通道注意力机制后,网络对于渲染参数的预测性能有了显著提升。

表2 不同注意力机制下光源估计网络效果对比
3.4 误差分析
为了更好地显示光照网络预测结果,本文统计测试了误差数据并以直方图的形式展示,结果如图11所示。其中,图11(a)和图11(b)分别为参数和的测试误差分布直方图;横纵坐标分别代表误差区间与测试图像数量,由图11可知,绝大多数测试图像的误差小于10°。通过观察分析预测角度与实际角度,发现和误差相对较大的图像聚集在渲染参数为0,360和0,180附近,这是由于在空间坐标系中,0°和360°为同一位置,导致在其附近的误差较大。经统计测试误差均值为4°。实验数据充分证明本文网络对参考图像的渲染参数预测效果良好,提出的方法稳定可靠。
3.5 渲染效果分析
为了更好地展示效果,从纳米技术领域国际著名期刊杂志[32-34]上找到若干张渲染效果较好的图像作为参考图像,送入训练好的网络,预测得到每张图像的光源参数,再将该参数作为渲染软件的输入,对原始模型进行渲染,最终得到渲染图像,并对比了3.2节中不同回归网络的渲染效果,结果见表3。本文列举了不同类别的原子模型各2种。实验结果显示,即便使用与原作者不同的绘制软件,本文方法也可以产生较好的渲染效果,并且同其他回归方法相比,渲染效果与稳定性能都达最优。

图11 误差分布直方图((a) α误差分布;(b) β误差分布)

表3 基于参考图像的原子模型渲染效果
4 结束语
本文提出一种基于参考图像的原子模型渲染方法。通过卷积神经网络估计理想图像的光源参数,快速渲染目标模型。首先阐述该方法的总体思路,其次介绍神经网络的架构和数据集的获取方式,以及其他实验细节设置。最后对训练结果进行分析对比。实验结果表明,训练的光源预测网络具有高度的可靠性,通过网络预测的参数与真实照明参数误差极小,可应用于渲染系统中。主要贡献包括:
(1) 一个原子模型渲染图像数据集;
(2) 一个光照参数估计网络;
(3) 一种基于参考图像的原子模型渲染方法。
由于数据集来源于有限的三维模型,所以该方法适用范围存在局限。对于复杂模型或包含多个光源的渲染图像,可能会存在较大的误差,为了解决这些问题,未来需要扩展三维模型,增加数据集的复杂性,使得该方法具有足够的通用性,以应对各种三维模型的渲染。
[1] JACOBS K, LOSCOS C. Classification of illumination methods for mixed reality[J]. Computer Graphics Forum, 2006, 25(1): 29-51.
[2] 刘万奎, 刘越. 用于增强现实的光照估计研究综述[J]. 计算机辅助设计与图形学学报, 2016, 28(2): 197-207.
LIU W K, LIU Y. Review on illumination estimation in augmented reality[J]. Journal of Computer-Aided Design & Computer Graphics, 2016, 28(2): 197-207 (in Chinese).
[3] FU X Y, ZENG D L, HUANG Y, et al. A fusion-based enhancing method for weakly illuminated images[J]. Signal Processing, 2016, 129: 82-96.
[4] GUO X J, LI Y, LING H B. LIME: low-light image enhancement via illumination map estimation[J]. IEEE Transactions on Image Processing, 2017, 26(2): 982-993.
[5] SHI W, LOY C C, TANG X O. Deep specialized network for illuminant estimation[M]//Computer Vision - ECCV 2016. Cham: Springer International Publishing, 2016: 371-387.
[6] LORE K G, AKINTAYO A, SARKAR S. LLNet: a deep autoencoder approach to natural low-light image enhancement[J]. Pattern Recognition, 2017, 61: 650-662.
[7] MARQUES B A D, DRUMOND R R, VASCONCELOS C N, et al. Deep light source estimation for mixed reality[C]//The 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications. Setúbal: SCITEPRESS - Science and Technology Publications, 2018: 873-883.
[8] KÁN P, KAUFMANN H. Correction to: DeepLight: light source estimation for augmented reality using deep learning[J]. The Visual Computer, 2020, 36(1): 229.
[9] CUI S, ZHANG J AND GAO J. Illuminant estimation via deep residual learning[J]. Journal of Image and Graphics, 2019, 24(12): 2111-2125.
[10] GAO Y Y, HU H M, LI B, et al. Naturalness preserved nonuniform illumination estimation for image enhancement based on retinex[J]. IEEE Transactions on Multimedia, 2018, 20(2): 335-344.
[11] LI Z Q, SHAFIEI M, RAMAMOORTHI R, et al. Inverse rendering for complex indoor scenes: shape, spatially-varying lighting and SVBRDF from a single image[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 2472-2481.
[12] BERGER M, LI J X, LEVINE J A. A generative model for volume rendering[J]. IEEE Transactions on Visualization and Computer Graphics, 2019, 25(4): 1636-1650.
[13] LI L, QIAO X Q, LU Q, et al. Rendering optimization for mobile web 3D based on animation data separation and on-demand loading[J]. IEEE Access, 2020. 8: 88474-88486.
[14] 王贝贝, 樊家辉. 均匀参与介质的渲染方法研究[J]. 中国图象图形学报, 2021, 26(5): 961-969.
WANG B B, FAN J H. Survey of rendering methods for homogeneous participating media[J]. Journal of Image and Graphics, 2021, 26(5): 961-969 (in Chinese).
[15] 姜胜利, 张蕾, 赵寒月, 等. 含能材料第一性原件计算软件HASEM的简介与展望[C]//2014’(第六届)含能材料与钝感弹药技术学术研讨会论文集. 成都: 国防工业出版社, 2014: 107-110.
JIANG S L, ZHANG L, ZHAO H Y, et al. Introduction and perspectives of HASEM, the software for calculating first principles of energy-containing materials[C]//2014’ 6th Symposium on Energetic Materials and Insensitive Munitions. Chendu: National Defence Industry Press, 2014:107-110 (in Chinese).
[16] HIREL P. Atomsk: a tool for manipulating and converting atomic data files[J]. Computer Physics Communications, 2015, 197: 212-219.
[17] 曹力, 顾兆光, 孙健, 等. 界面预制: 一种高效生成原子模型的方法[J]. 计算机辅助设计与图形学学报, 2016, 28(10): 1622-1629.
CAO L, GU Z G, SUN J, et al. Pre-constructed interface: an easy approach for generating nano-scale-device atomistic models[J]. Journal of Computer-Aided Design & Computer Graphics, 2016, 28(10): 1622-1629 (in Chinese).
[18] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 770-778.
[19] BANSAL A, RUSSELL B, GUPTA A. Marr revisited: 2D-3D alignment via surface normal prediction[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 5965-5974.
[20] REMATAS K, RITSCHEL T, FRITZ M, et al. Deep reflectance maps[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 4508-4516.
[21] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]//Computer Vision - ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
[22] TAN M X, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks[EB/OL]. [2022-04-22]. https:// arxiv.org/abs/1905.11946v4.
[23] ZHANG H Y, SHA Z L, CUI S H, et al. Application of POV-ray software in the molecular symmetry[J]. University Chemistry, 2015, 30(2): 78-82.
[24] GLOROT X, BORDES A, BENGIO Y. Deep sparse rectifier neural networks[C]//The 14th International Conference on Artificial Intelligence and Statistics. Chicago: Medical Library Association, 2011:315-323.
[25] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[EB/OL]. [2022-06-10]. https://arxiv.org/abs/1706.03762.
[26] WANG H R, FAN Y, WANG Z X, et al. Parameter-free spatial attention network for person re-identification[EB/OL]. [2022-05-02]. https://arxiv.org/abs/1811.12150.
[27] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// The IEEE conference on computer vision and pattern recognition. New York: IEEE Press, 2018: 7132-7141.
[28] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[29] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[30] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2022-04-30]. https://arxiv.org/abs/1409.1556v5.
[31] HAN K, WANG Y H, TIAN Q, et al. GhostNet: more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 1577-1586.
[32] TANG J B, LAMBIE S, MEFTAHI N, et al. Unique surface patterns emerging during solidification of liquid metal alloys[J]. Nature Nanotechnology, 2021, 16(4): 431-439.
[33] DANOWSKI W, VAN LEEUWEN T, ABDOLAHZADEH S, et al. Unidirectional rotary motion in a metal–organic framework[J]. Nature Nanotechnology, 2019, 14(5): 488-494.
[34] ZHANG Y, KERSELL H, STEFAK R, et al. Simultaneous and coordinated rotational switching of all molecular rotors in a network[J]. Nature Nanotechnology, 2016, 11(8): 706-712.
Atomic model rendering method based on reference images
WU Chen1, CAO Li1, QIN Yu1, WU Miao-miao1, Koo SiuKong2
(1. School of Computer and Information, Hefei University of Technology, Hefei Anhui 230601, China; 2. Hong Kong Quantum AI Lab, Hong Kong 999077, China)
Along with advances in biology and the simulation of nano electronic devices, atomic structures play a crucial role in modern science and technology. The complex details of the atomic structure result in the far-reaching impact of the position of the light source on the rendering effect, incurring difficulties in rendering atomic models. On this basis, an atomic model rendering method based on a reference image was proposed, in which the lighting parameters of the reference image were calculated for the rendering of the atomic model. First, a POV-Ray script was used to render a batch of models at different light angles by changing the light source positions, and the light source position parameters and rendered images were collected to obtain a dataset of rendered images corresponding to the light source positions. Then, the light source estimation network was designed with the residual neural network as the backbone, and the attention mechanism was embedded in the network to enhance the network accuracy. The optimized light source estimation network was employed to train the dataset and regress the light source location parameters. Finally, the trained convolutional neural network was used to estimate the rendering parameters of the reference image, and the target model was rendered using the rendering parameters. The experimental results show that the parameters predicted by the network are highly reliable with minimal error compared with the real lighting parameters.
atomic structure; model rendering; light source position; reference image; light source estimation network
TP 391
10.11996/JG.j.2095-302X.2022061080
A
2095-302X(2022)06-1080-08
2022-07-29;
:2022-10-17
国家自然科学基金项目(61602146)
吴 晨(2000-),男,硕士研究生。主要研究方向为计算机图形学。E-mail:chen124@mail.hfut.edu.cn
曹 力(1982-),男,副教授,博士。主要研究方向为计算机辅助设计、几何分析等。E-mail:lcao@hfut.edu.cn
29 July,2022;
17 October,2022
s:National Natural Science Foundation of China (61602146)
WU Chen (2000-), master student. His main research interests cover model rendering and model reconstruction. E-mail:chen124@mail.hfut.edu.cn
CAO Li (1982-), associate professor, Ph.D. His main research interests cover computer aided design, computer vision, etc. E-mail:lcao@hfut.edu.cn
猜你喜欢
中国机械工程(2022年8期)2022-05-09
少儿科学周刊·儿童版(2021年22期)2021-12-11
少儿科学周刊·儿童版(2021年22期)2021-12-11
少儿科学周刊·儿童版(2021年22期)2021-12-11
上海工艺美术(2021年4期)2021-04-24
家庭影院技术(2021年2期)2021-03-29
儿童时代·幸福宝宝(2021年1期)2021-03-29
小资CHIC!ELEGANCE(2019年40期)2019-12-10
家庭影院技术(2018年10期)2018-11-02
电子制作(2018年2期)2018-04-18
