
多尺度模态感知在文本指代实例分割中的研究与应用
2023-01-13 06:55胡永利刘秀平谭红臣尹宝才
图学学报 2022年6期
刘 静,胡永利,刘秀平,谭红臣,尹宝才
多尺度模态感知在文本指代实例分割中的研究与应用
刘 静1,胡永利1,刘秀平2,谭红臣1,尹宝才1
(1. 北京工业大学人工智能与自动化学院,北京 100124;2. 大连理工大学数学科学学院,辽宁 大连 116024)
文本指代实例分割(RIS)任务是解析文本描述所指代的实例,并在对应图像中分割出该实例,是计算机视觉与媒体领域中热门的研究课题。当前,大多数RIS方法基于单尺度文本/图像模态信息的融合,以感知指代实例的位置和语义信息。然而,单一尺度模态信息很难同时涵盖定位不同大小实例所需的语义和结构上下文信息,阻碍了模型对任意大小指代实例的感知,进而影响模型对不同大小指代实例的分割。对此,设计多尺度视觉-语言交互感知模块和多尺度掩膜预测模块:前者增强模型对不同尺度实例语义与文本语义之间的融合与感知;后者通过充分捕捉不同尺度实例的所需语义和结构信息提升指代实例分割的表现。由此,提出了多尺度模态感知的文本指代实例分割模型(MMPN-RIS)。实验结果表明,MMPN-RIS模型在RefCOCO, RefCOCO+和RefCOCOg 3个公开数据集的oIoU指标上均达到了前沿性能;针对文本指代不同尺度实例的分割,MMPN-RIS模型有着较好的表现。
视觉与语言;文本指代实例分割;异模态融合与感知;特征金字塔
文本指代实例分割(referring image segmentation,RIS)任务是一项热门的视觉媒体任务,广泛应用于人机交互[1]、视觉导航、交互式图像编辑[2]等智能领域。该任务目标是解析文本描述所指代的目标实例,并在对应图像中分割出该实例区域。不同于图像实例分割任务,RIS不仅需要处理抽象的文本语义,还需要搭建文本与图像之间语义桥梁,增强模型对模态语义的感知以定位和分割指代实例等。因此,RIS是一项极具挑战性的跨模态识别任务。近年来,随着深度学习的发展,一系列杰出方法被提出,大致分为:两阶段RIS方法[3-4]和单阶段RIS方法[5-13]。
两阶段RIS方法,首先利用目标检测或分割算法[14-18]捕获图像中所有实例,随后利用文本/图像间的语义对齐与感知策略定位或分割出指代实例。基于此思想,文献[3]提出了一个多阶段、多任务框架,利用Faster-RCNN[14]定位各目标区域,并选择与文本表达最接近的区域送入实例分割分支,以实现指代实例的定位和分割。基于捕获的候选目标实例,文献[4]构建文本语义解析树,通过反向广度优先搜索算法对树节点模态语义的更新,以提高模型对指代实例的推理和定位能力。该方法虽然可以获得较高的分割准确率,但分割结果受第一阶段的目标检测算法可识别类别的限制;此外,第一阶段不佳的检测结果直接影响后续分割效果。
为了改善两阶段RIS模型的不足,越来越多的学者试图移除目标检测阶段,直接驱动模型感知文本/图像模态以分割指代实例,即单阶段RIS方法。
当前,大部分单阶段RIS方法利用图像编码器和文本编码器分别提取图像和文本特征,然后设计不同的文本/图像模态融合与感知机制,进而分割指代实例。其中,在模态融合机制的设计中:文献[5]提出将2种模态特征与空间坐标特征图直接拼接,之后直接利用卷积层与反卷积层预测掩膜;文献[6]提出了循环多模态交互网络,在对文本中每个单词编码时引入视觉信息,进行多模态信息融合;文献[7]提出了跨模态自注意力网络,通过自注意力方法融合2种模态的特征,使网络模型自适应地聚焦于图像中的重要区域和语言描述中的关键词;文献[9]提出了双向跨模态关系推理网络,通过构建语言与视觉双向引导的注意力模块学习模态间的空间依赖关系。
尽管当前大部分方法在RIS任务中可以取得较好的分割结果,但依然不能很好地适应任意大小指代实例的分割。这是因为,当前大多数RIS方法基于单尺度文本/图像模态信息的融合来分割指代实例,其很难同时涵盖定位不同大小实例所需的语义和结构上下文信息;那么,能够融合或感知文本与图像的语义很难完全从单一尺度的模态特征中找到。使得:①模型对文本、图像模态的语义感知能力不足,文本特征和图像特征的对齐出现偏差;②模型对图像整体的理解能力不足,跨模态感知时不能有效利用前景特征。语义信息的缺失与错误对齐使多模态特征融合效果不佳,造成对指代物体错误地定位以及劣质地分割。而解决单尺特征不足的关键是引入多尺度特征,以扩大模态义融合与感知的特征选择范围。那么,对于不足①,本文第一个策略是探究不同尺度的文本-图像模态的融合与感知,提升模型对不同大小目标实例的感知能力,以及增强异模态语义的有效对齐;对于不足②,本文的第二策略则是基于策略一得到的多尺度模态融合信息,捕捉不同大小的指代实例在分割过程中所需的语义和结构信息,以提高分割的表现。
综上,本文提出了新的RIS模型,即多尺度模态感知的RIS模型(multi-scale modality perception network for RIS,MMPN-RIS)。在该模型中,本文提出多尺度视觉-语言交互感知模块(multi-scale vision-linguistic interaction perception module,MVLIPM),在不同尺度模态信息引导下增强模型对文本与图像语义的融合与感知。此外,本文还引入多尺度掩膜预测模块(multi-scale mask prediction module,MMPM),促使不同层次多模态信息的充分融合,进而提高模型对不同大小指代实例的分割表现。本文在RefCOCO[19],RefCOCO+[19]和RefCOCOg[20-21]3个基准数据集上进行模型的训练与测试。实验结果表明:在3个数据集上,本文提出的MMPN-RIS均获得了较高的指代图像分割性能。如:在RefCOCO数据集上,MMPN-RIS在oIoU指标上达到68.21%,相比基线模型提升7.04%。
1 MMPN-RIS模型的介绍
作为文本指代分割任务,其核心就是模型需要理解两模态的语义,以感知文本指代的实例。在模态语义的感知和理解过程中,不同大小的实例所需语义是不同的,如:小目标更需要浅层外表特征和上下文结构特征;较大目标则更需要高层语义特征。此外,实例分割阶段也需要捕获不同类型的语义特征以更加精准地定位不同大小尺寸的目标实例。正如引言所述,本文提出了MMPN-RIS来探索不同尺度模态融合与实例分割策略,以缓解上述问题。
MMPN-RIS网络框架如图1所示,主要包括:视觉和语言特征提取模块(feature extraction module,FEM),MVLIPM和MMPM。

图1 MMPN-RIS的网络框图
模型整体信息流:首先,利用视觉编码模型和文本编码模型分别提取图像特征和文本特征;接着,利用多尺度视觉-语言交互感知模块实现对文本与图像语义进行多尺度融合;最后,通过多尺度掩膜预测模块,将不同尺度的细节、结构和高层语义信息相结合,分割指代实例。
1.1 视觉和语言特征提取模块
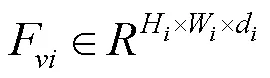

1.2 多尺度视觉-语言交互感知模块
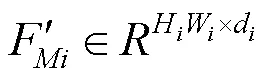
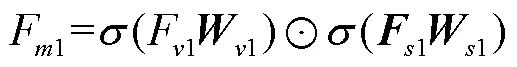
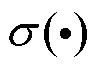
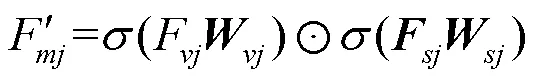
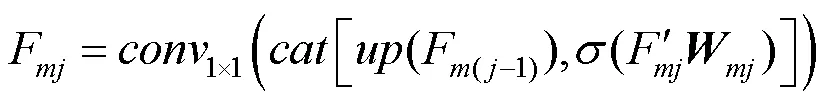
图2 多尺度视觉-语言交互感知模块
Fig. 2 Multi-scale vision-linguistic interaction perception module
此外,为了获得高质量的文本与图像模态融合信息,本文基于多头注意力机制[26]构建视觉-语言交互感知机制(visual-language interaction perception mechanism,VLIPM)。具体步骤如下:
(1) 多尺度图像与图像模态融合模式。为提升模型对图像整体的理解能力,本文借助图像上下文信息。通过计算不同尺度图像各区域间的相似度来求取图像各区域之间的相关性,找出图像中需要被关注的区域F。以多头注意力机制的一头为例,即
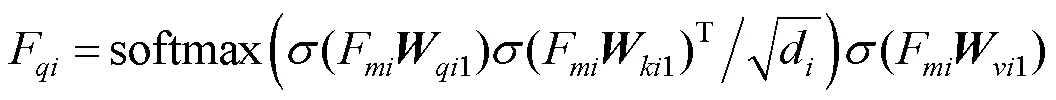
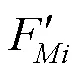
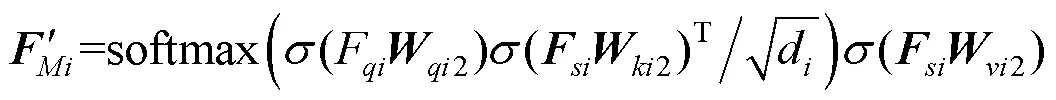
综上,本模块为提升模型对文本和图像模态语义感知能力,对不同尺度的视觉信息进行图像与图像、文本与图像的多尺度模态融合。这一设计有效利用了多尺度特征丰富的语义信息以及图像上下文信息。实现了对不同尺度目标物体的感知,以及对异模态间语义的融合。
1.3 多尺度掩膜预测模块
(1) 自下而上的信息融合。不同尺度视觉特征对文本的感知能力以及感知结果存在差异。为提升模型对浅层特征的利用,本模块对多尺度视觉-语言交互感知模块的结果进行自下而上的信息融合,获得更新的多模态融合特征,即
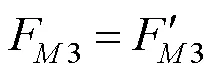
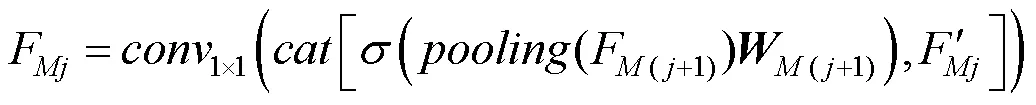
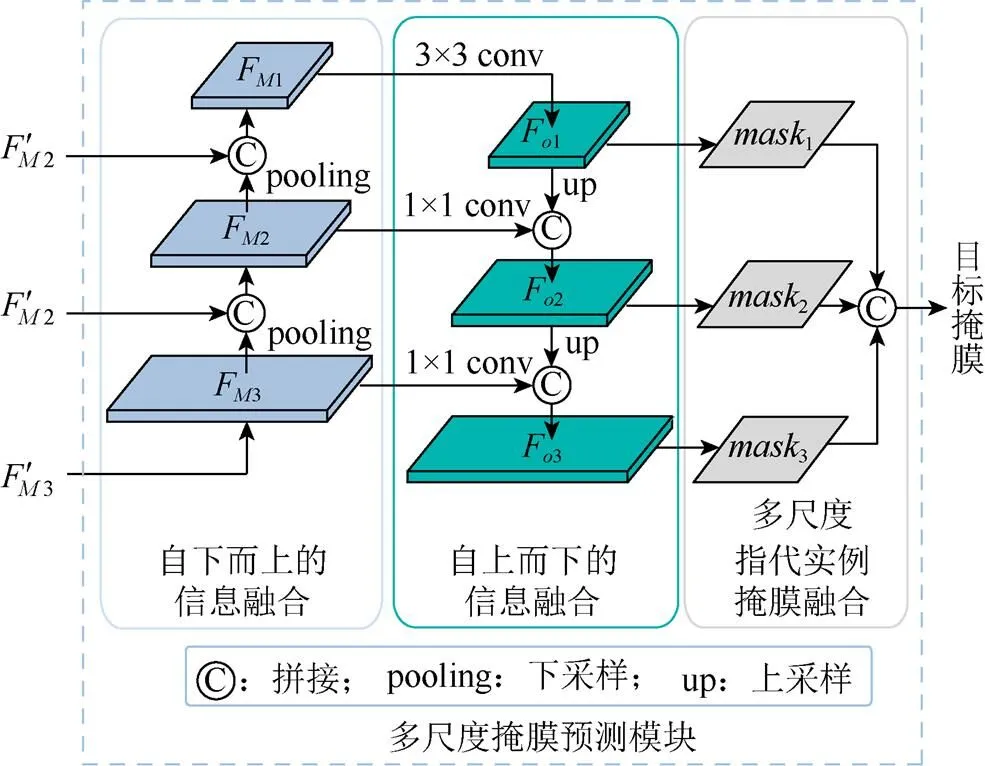
图3 多尺度掩膜预测模块
(2) 自上而下的信息融合。为保证最终用于掩膜预测的不同层次多模态特征F(=1,2,3)均具有丰富的语义信息,本文还通过自上而下的融合方式将来自高层的语义信息整合到底层的特征中,即
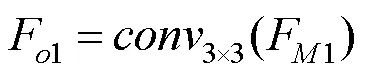
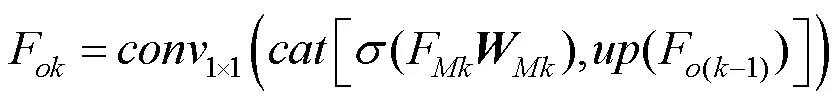
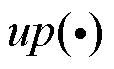
(3) 多尺度指代实例掩膜融合。不同尺度多模态融合特征包含的信息并不完全一致,为保证最终预测掩膜的准确性,在不需要其他复杂的后处理操作的情况下,本文设计了多尺度掩膜预测方案:1经4个堆叠的3×3卷积层和一个1×1的卷积层获得;2经3个堆叠的3×3卷积层和一个1×1的卷积层获得;3经2个堆叠的3×3卷积层和一个1×1的卷积层获得;三者尺寸一致。最后将多尺度指代实例掩膜:1,2和3进行拼接融合,并使用1×1卷积层将通道数降为1,作为最终分割结果mask。
综上,本模块为获得有助于准确分割的多模态融合表示,通过自下而上和自上而下的双向融合策略,逐步实现文本、图像异模态对指代实例信息表征的增强。本设计充分融合了多尺度信息,帮助模型获得适用于分割的高质量多模态特征,提高了对指代实例的分割表现。
本文使用真值掩膜mask与预测掩膜mask的二元交叉熵作为损失函数指导网络的训练,即
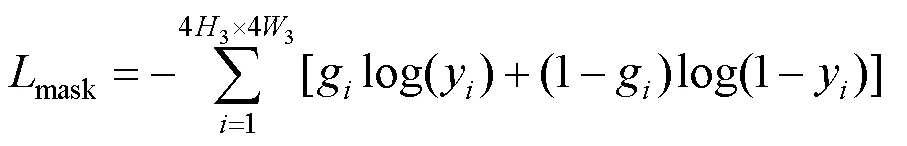
其中,g为真值掩膜mask下采样响应图的元素;为预测掩膜中的元素。
2 实验结果分析
本文实验从定量和定性的角度评价MMPN-RIS模型性能。定量评价:计算模型在RefCOCO,RefCOCO+和RefCOCOg等数据集上的oIoU等评价指标的数值结果;利用数值结果对模型进行客观的评价与分析。定性评价:可视化模型在RefCOCO测试集上的分割图像,主观评价MMPN-RIS与消融实验中对比方法分割图像的视觉效果。
遵循大部分前沿工作[3,22],本文以Darknet-53作为CNN主干网络,并在MS COCO[27]上进行预训练,此时的MS COCO数据集已去除与3个数据集重合的图像。输入图像的大小调整为416×416。对于RefCOCO和RefCOCO+,输入语言表达式的最大长度设置为15;对于RefCOCOg,最大长度设置为20。3个尺度的多头注意力机制均设置为4头,维度分别设置为1 024,512和256。本文使用Adam作为优化器来训练MMPN-RIS模型。初始学习速率为0.0005,在20个epoch时下降为0.0001。batch size和training epoch分别设置为8和35。
2.1 数据集及评价指标
本文在RefCOCO,RefCOCO+和RefCOCOg等3个标准基准数据集上对MMPN-RIS模型性能进行了评估。其图像均来自MS COCO数据集,并使用自然语言表达式进行标注。RefCOCO,RefCOCO+和RefCOCOg分别包含19 994,19 992和26 711张图像,标注对象分别为50 000,49 856和54 822个,标注表达式分别为142 209,141 564和104 560个。
RefCOCO和RefCOCO+中的表达式经交互式双人游戏获得,内容十分简洁(平均包含3.5个单词)。相比之下,RefCOCOg中的表达式更复杂(平均包含8.4个单词),更具有描述性,更具挑战性。另一方面,RefCOCOg的每张图像上平均有1.6个相同类别对象。相比之下,RefCOCO和RefCOCO+的每张图像上有平均3.9个相同类别的对象,因此后者可以更好地评估算法编码实例级细节的能力。同时,不同于RefCOCO,RefCOCO+在其表达式中禁用了位置词,这也使其成为一个更具挑战性的数据集。最后,RefCOCOg数据集有2个分区,即UMD[21]分区和谷歌[20]分区。本文在这2个分区上均进行了实验。
本文采用2个通用的度量指标来评估有效性:全局交并比(overall intersection over unio,oIoU)和精度百分比(简称Prec@X)。oIoU是对所有测试样本的预测掩膜与真实掩膜的总交集区域与总并集区域求比值,可以同时考虑每个类别的误检值和漏检值。Prec@X指标则是度量测试过程中预测掩膜与真实掩膜之间的IoU高于阈值的样本数目占全部测试样本数目的百分比。本文在实验中选择5种不同的阈值,其精度百分比分别表示为Prec@0.5,Prec@0.6,Prec@0.7,Prec@0.8和Prec@0.9。
2.2 消融实验
为了验证本文策略的有效性,将在RefCOCO数据集的val上进行消融实验的结果展示与分析。
遵循目前大部分深度网络模型消融实验的设计方案,本文首先设计基线模型,即:设计将句子级语言特征F与视觉特征F1进行单级融合获得多模态特征,随后在多模态特征上采样获得不同尺度的多模态特征,最后将不同尺度的多模态特征用于掩膜预测。并在此基础上讨论特征融合时采用多级融合以及模型中引入的视觉-语言感知模块和多尺度掩膜预测模块的有效性。
表1显示,6号本文模型及2~5号退化模型的性能皆优于1号基线模型。其中,经5,6号比较可知多级融合性能优于单级融合性能;3,4号比较可验证VLIPM模块的有效性,进而通过4,5号比较可证明对不同层次分别进行视觉-语言感知的可行性;通过对比1,2,3结果可知对不同层次特征通过双向融合进行信息增强可以进一步提高性能,且2个方向均具有增益。
除此之外,本文通过可视化方式将MMPN-RIS的预测掩膜与1号基线模型、4号模型进行定性比较。如图4所示,MMPN-RIS所生成的掩膜在定位准确性和分割完整度上均好于后者。进一步证明了提出的MVLIPM的有效性。同时在对干扰实体较多或目标实体尺寸较小的分割任务中,本文提出的MMPN-RIS依旧可以准确定位目标物体并对物体的细节及轮廓进行更有效的感知,从而获得更精准的分割结果。
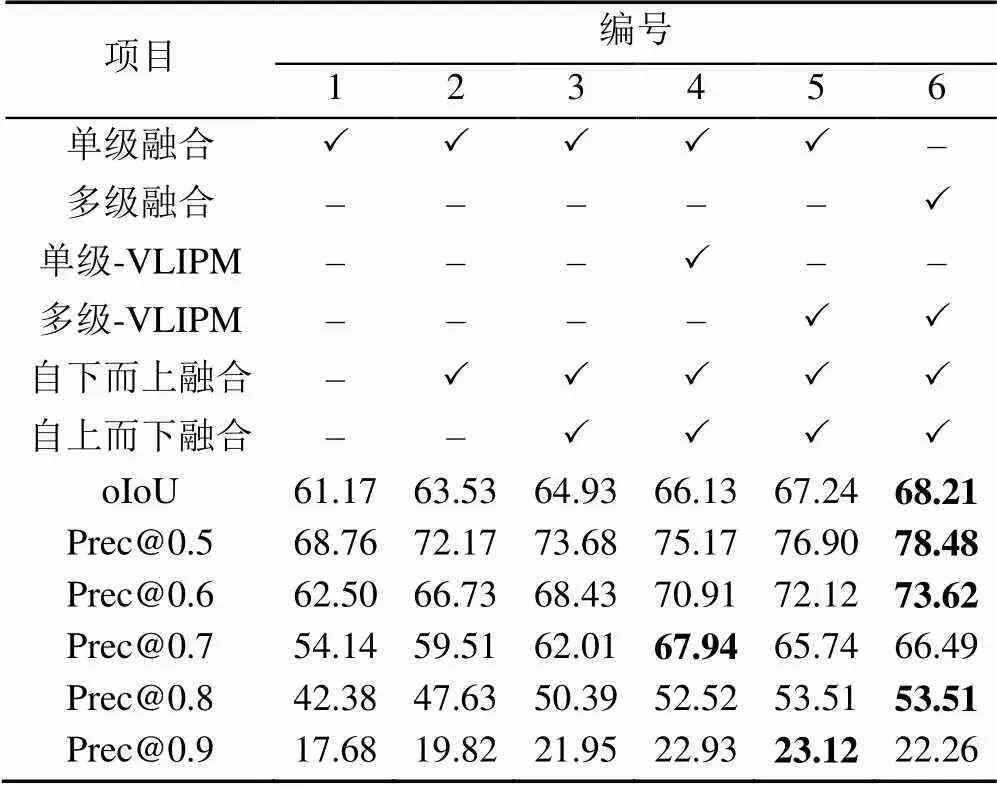
表1 消融实验
注:加粗数据为最优值

图4 消融结果可视化((a)输入图像;(b)基线模型;(c) 4号模型;(d)本文模型;(e)真值掩膜)
2.3 与前沿方法的比较与分析
为了评价模型的有效性与分割结果的准确性,表2展示了本文提出的MMPN-RIS和一系列前沿方法在RefCOCO,RefCOCO+和RefCOCOg3个数据集的验证与测试集上的oIoU指标评分。本文提出的MMPN-RIS的oIoU指标在3个数据集的实验结果均高于大部分前沿算法。在实例数较多的RefCOCO和RefCOCO+数据集上分别获得了2.56%~3.28%和1.19%~3.40%的增益,证明了本文模型MMPN-RIS对复杂场景具有较好理解能力;对于表达式长度较长的RefCOCOg数据集上,更是获得了2.00%~7.77%的增益,证明了MMPN-RIS对长文本-图像任务具有较好异模态对齐能力。分析原因包括:①对于实例较多的复杂场景,MVLIPM中的多头注意力机制可以从全局理解图像信息促进视觉语言的语义匹配;②进行多尺度视觉-语言感知有助于异模态间的融合与感知,可增强异模态语义的有效对齐。
本文还通过可视化方式将MMPN-RIS的预测掩膜与对比方法VLT进行定性比较。如图5所示,在处理颜色、前景/背景、位置以及尺寸等指代文本时,MMPN-RIS所生成的掩膜在面对定位准确性和分割完整度上均好于VLT。这体现了本文MMPN-RIS方法性能的优越性。
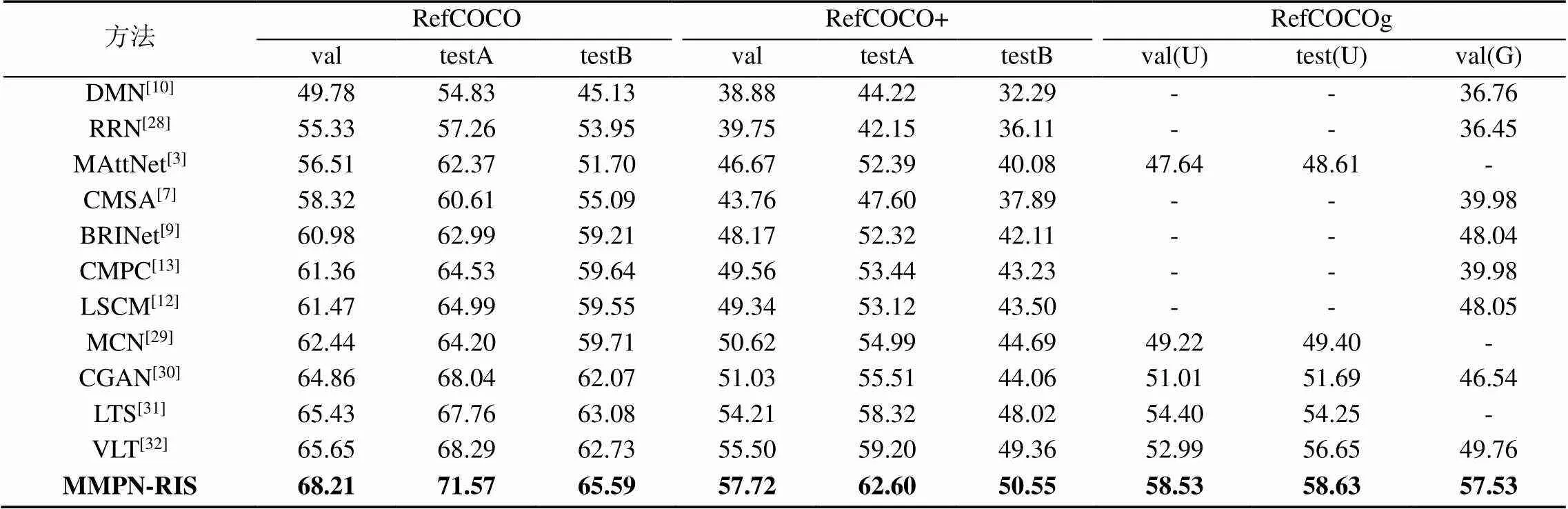
表2 MMPN-RIS在3个标准基准数据集上与对比方法进行比较(U:UMD分区. G:谷歌分区)
注:加粗数据为最优值

图5 实验结果可视化((a)输入图像;(b)真值掩膜;(c)对比方法(VLT);(d)本文模型)
3 模型局限性与讨论
本文提出的MMPN-RIS仍然存在着指代图像分割失败的案例。图6展示了可视化一些具有代表性的失败案例。失败原因包括:①真值掩膜标注错误;②文本描述指代不明;③本文模型在处理逻辑性强的任务时存在局限性。这是因为基于多模态融合的RIS模型虽然具有较强的模态感知能力,但处理异模态协同推理问题时存在不足。
未来的工作:①考虑对模态间实体关系的利用,提升模型的推理能力;②在进行特征提取阶段考虑模态间数据的相互作用。

图6 失败案例((a)输入图像;(b)真值掩膜;(c)本文模型)
4 结 论
本文提出了一种新的指代图像分割模型——多尺度模态感知的RIS模型(MMPN-RIS)。在MMPN-RIS中,本文引入多尺度视觉-语言交互感知模块,在有效利用不同层次视觉信息的同时提高模型对语言相关的图像区域的感知能力。此外,本文还引入双向融合多模态信息的多尺度掩膜预测模块,促使不同层次多模态信息的充分融合,进而驱动模型预测高质量分割掩膜。实验结果显示,本文提出的MMPN-RIS在3个基准数据集上,均获得了较高的指代图像分割性能。
[1] WANG X, HUANG Q Y, CELIKYILMAZ A, et al. Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 6622-6631.
[2] CHEN J B, SHEN Y L, GAO J F, et al. Language-based image editing with recurrent attentive models[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 8721-8729.
[3] YU L C, LIN Z, SHEN X H, et al. MAttNet: modular attention network for referring expression comprehension[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 1307-1315.
[4] LIU D Q, ZHANG H W, ZHA Z J, et al. Learning to assemble neural module tree networks for visual grounding[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 4672-4681.
[5] HU R H, ROHRBACH M, DARRELL T. Segmentation from natural language expressions[M]//Computer Vision - ECCV 2016. Cham: Springer International Publishing, 2016: 108-124.
[6] LIU C X, LIN Z, SHEN X H, et al. Recurrent multimodal interaction for referring image segmentation[C]//2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 1280-1289.
[7] YE L W, ROCHAN M, LIU Z, et al. Cross-modal self-attention network for referring image segmentation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 10494-10503.
[8] YE L W, ROCHAN M, LIU Z, et al. Referring segmentation in images and videos with cross-modal self-attention network[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3719-3732.
[9] HU Z W, FENG G, SUN J Y, et al. Bi-directional relationship inferring network for referring image segmentation[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 4423-4432.
[10] MARGFFOY-TUAY E, PÉREZ J C, BOTERO E, et al. Dynamic multimodal instance segmentation guided by natural language queries[M]//Computer Vision - ECCV 2018. Cham: Springer International Publishing, 2018: 656-672.
[11] YE L W, LIU Z, WANG Y. Dual convolutional LSTM network for referring image segmentation[J]. IEEE Transactions on Multimedia, 2020, 22(12): 3224-3235.
[12] HUI T R, LIU S, HUANG S F, et al. Linguistic structure guided context modeling for referring image segmentation[M]// Computer Vision - ECCV 2020. Cham: Springer International Publishing, 2020: 59-75.
[13] HUANG S F, HUI T R, LIU S, et al. Referring image segmentation via cross-modal progressive comprehension[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 10485-10494.
[14] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[15] 曹春键, 臧强, 王泽嘉, 等. 改进的YOLOv3目标检测算法[J]. 中国科技论文, 2021, 16(11): 1195-1201.
CAO C J, ZANG Q, WANG Z J, et al. Improved YOLOv3 object detection algorithm[J]. China Sciencepaper, 2021, 16(11): 1195-1201 (in Chinese).
[16] 周薇娜, 孙丽华, 徐志京. 复杂环境下多尺度行人实时检测方法[J]. 电子与信息学报, 2021, 43(7): 2063-2070.
ZHOU W N, SUN L H, XU Z J. A real-time detection method for multi-scale pedestrians in complex environment[J]. Journal of Electronics & Information Technology, 2021, 43(7): 2063-2070 (in Chinese).
[17] 郭智超, 丛林虎, 刘爱东, 等. 基于SK-YOLOV3的遥感图像目标检测方法[J]. 兵器装备工程学报, 2021, 42(7): 165-171.
GUO Z C, CONG L H, LIU A D, et al. Remote sensing image target detection method based on SK-YOLOV3[J]. Journal of Ordnance Equipment Engineering, 2021, 42(7): 165-171 (in Chinese).
[18] 李康康, 于振中, 范晓东, 等. 改进多层尺度特征融合的目标检测算法[J]. 计算机工程与设计, 2022, 43(1): 157-164.
LI K K, YU Z Z, FAN X D, et al. Improved multi-scale feature fusion target detection algorithm[J]. Computer Engineering and Design, 2022, 43(1): 157-164 (in Chinese).
[19] YU L C, POIRSON P, YANG S, et al. Modeling context in referring expressions[M]//Computer Vision - ECCV 2016. Cham: Springer International Publishing, 2016: 69-85.
[20] MAO J H, HUANG J, TOSHEV A, et al. Generation and comprehension of unambiguous object descriptions[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 11-20.
[21] NAGARAJA V K, MORARIU V I, DAVIS L S. Modeling context between objects for referring expression understanding[M]// Computer Vision - ECCV 2016. Cham: Springer International Publishing, 2016: 792-807.
[22] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2022-06-10]. https://arxiv.org/abs/1804. 02767.
[23] PENNINGTON J, SOCHER R, MANNING C. Glove: global vectors for word representation[C]//2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2014: 1532-1543.
[24] CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[EB/OL]. [2022-04-29]. https://arxiv.org/abs/1412.3555.
[25] YANG Z C, YANG D Y, DYER C, et al. Hierarchical attention networks for document classification[C]//2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: Association for Computational Linguistics, 2016: 1480-1489.
[26] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[C]//The 31st International Conference on Neural Information Processing Systems. New York: ACM Press, 2017: 6000-6010.
[27] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[M]//Computer Vision - ECCV 2014. Cham: Springer International Publishing, 2014: 740-755.
[28] LI R Y, LI K C, KUO Y C, et al. Referring image segmentation via recurrent refinement networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 5745-5753.
[29] LUO G, ZHOU Y Y, SUN X S, et al. Multi-task collaborative network for joint referring expression comprehension and segmentation[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 10031-10040.
[30] LUO G, ZHOU Y Y, JI R R, et al. Cascade grouped attention network for referring expression segmentation[C]//The 28th ACM International Conference on Multimedia. New York: ACM Press, 2020: 1274-1282.
[31] JING Y, KONG T, WANG W, et al. Locate then segment: a strong pipeline for referring image segmentation[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 9853-9862.
[32] DING H H, LIU C, WANG S C, et al. Vision-language transformer and query generation for referring segmentation[C]// 2021 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2021: 16301-16310.
Multi-scale modality perception network for referring image segmentation
LIU Jing1, HU Yong-li1, LIU Xiu-ping2, TAN Hong-chen1, YIN Bao-cai1
(1. School of Artificial Intelligence and Automation, Beijing University of Technology, Beijing 100124, China; 2. School of Mathematical Sciences, Dalian University of Technology, Dalian Liaoning 116024, China)
Referring image segmentation (RIS) is the task of parsing the instance referred to by the text description and segmenting the instance in the corresponding image. It is a popular research topic in computer vision and media. Currently, most RIS methods are based on the fusion of single-scale text/image modality information to perceive the location and semantic information of referential instances. However, it is difficult for single-scale modal information to simultaneously cover both the semantics and structural context information required to locate instances of different sizes. This defect hinders the model from perceiving referent instances of any size, which affects the model’s segmentation of referent instances of different sizes. This paper designed a Multi-scale Visual-Language Interaction Perception Module and a Multi-scale Mask Prediction Module to solve this problem. The former could enhance the model’s ability to perceive instances at different scales and promote effective alignment of semantics between different modalities. The latter could improve the performance of referring instance segmentation by fully capturing the required semantic and structural information of instances at different scales. Therefore, this paper proposed a multi-scale modality perception network for referring image segmentation (MMPN-RIS). The experimental results show that the MMPN-RIS model has achieved cutting-edge performance on the oIoU indicators of the three public datasets RefCOCO, RefCOCO+, and RefCOCOg. For the RIS of different scales, the MMPN-RIS model could also yield good performance.
visual and language; referring image segmentation; multi-modality fusion and perception; feature pyramid network
TP 391
10.11996/JG.j.2095-302X.2022061150
A
2095-302X(2022)06-1150-09
2022-08-02;
:2022-09-30
第7批全国博士后创新人才支持计划(BX20220025);第70批全国博士后面上资助(2021M700303)
刘 静(1994-),女,博士研究生。主要研究方向为目标检测、目标分割、指代分割、多模态学习等。E-mail:jingliu@emails.bjut.edu.cn
谭红臣(1992-),男,讲师,博士。主要研究方向为行人重识别、图像生成、及目标检测等。E-mail:tanhongchenphd@bjut.edu.cn
2 August,2022;
The 7th National Postdoctoral Innovative Talent Support Program (BX20220025); The 70th Batch of National Post-Doctoral Research Grants (2021M700303)
LIU Jing (1994-), PhD candidate. Her main research interests cover object detection, object segmentation, referring image segmentation and multimodal learning, etc. E-mail:jingliu@emails.bjut.edu.cn
TAN Hong-chen (1992-), lecturer, Ph.D. His main research interests cover person re-identification, image generation and object detection, etc. E-mail:tanhongchenphd@bjut.edu.cn
30 September,2022
猜你喜欢
科学咨询(2022年19期)2022-11-24
导航定位学报(2022年5期)2022-10-13
电子技术与软件工程(2021年5期)2021-06-16
考试与评价·八年级版(2020年1期)2020-10-26
电子技术与软件工程(2018年5期)2018-04-09
制造技术与机床(2017年10期)2017-11-28
东西南北(2016年19期)2016-11-01
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中学生天地·高中学习版(2008年5期)2008-03-20
