
一种基于多策略的改进黏菌算法
2023-01-19 04:04王喜敏寇巧媛
广西师范大学学报(自然科学版) 2022年6期
王喜敏,袁 杰,寇巧媛
(新疆大学 电气工程学院,新疆 乌鲁木齐 830017)
群智能优化算法包括2个搜索阶段: 勘探阶段和开发阶段[1]。勘探阶段是指尽可能广泛、随机和全局地搜索解空间的过程;开发阶段是指算法在勘探阶段获得区域内搜索更精确解的能力,随机性降低,精确度提高。当算法的勘探能力占优时,可以更好地搜索解空间,产生更多的差异化解集,从而快速收敛。当算法的开发能力占优时,更多地进行局部搜索,以提高解集的质量和精度。然而,当勘探能力得到改善时,会导致开发能力的降低,反之亦然。因此,对优化问题有效的2个阶段之间取得适当的平衡是具有挑战性的。典型群智能优化算法包括粒子群优化算法(PSO)[2]、灰狼优化算法(GWO)[3-4]、鲸鱼优化算法(WOA)[5]、萤火虫算法[6-7]、布谷鸟算法[8]等。黏菌算法(SMA)是由Li等[9]于2020年提出的一种基于种群的元启发式算法,黏菌的振荡行为类似于细菌觅食优化算法[10-11]。该算法相比其他群智能算法具有更优的搜索能力,应用于太阳能光伏电池参数优化[12-13]、电力系统稳定器参数优化[14]、路径规划[15]、任务调度[16-17]、旅行商问题[18]等领域。
SMA算法仍存在一些缺点,比如算法随着搜索增加会陷入局部最优、收敛性能下降,所以,研究人员对SMA算法进行了一定的改进。肖亚宁等[19]提出一种基于混沌精英黏菌算法(CESMA),提高了算法的搜索能力,用于优化PID控制参数;Chen等[20]提出混沌SMA(CSMA),集成Logistic混沌映射,提高搜索效率,提供了更好的开发模式;Zhao等[21]开发基于Levy飞行的改进SMA,引入Levy flight来代替均匀分布和高斯分布调用的随机权值,在探索开发阶段取得良好的性能;Zhao等[22]提出混合SMA和Harris hawk优化(HHO),利用更多的方式更新个体;Gao等[23]提出混合GWO算法与SMA算法,以改善原有SMA算法,的早熟收敛性能;Wu等[24]提出一种基于正交学习策略(OLS)和边界重启策略(BRS)的OBSMA算法,提高了算法的全局优化能力;Hu等[25]提出一种离散觅食策略的DFSMA算法,应用于生物医学数据的特征选择,提高了全局搜索能力,但是存在执行时间过长的问题;Wei等[26]提出一种基于领导者和跟随者机制的ISMA算法,较好地解决了无功优化调度(ORPD)问题中的精度和计算时间上的不足;Naik等[27]开发了一个领导者SMA(LSMA)以改善SMA的搜索过程,选择最优的候选解作为LSMA的领导者进行指导,应用于多光谱图像,取得了良好性能。虽然目前改进方法对算法全局勘探能力和开发能力有所优化,但在平衡算法的勘探和开发能力上还有待提高。
基于上述研究,为了均衡SMA算法的勘探能力和开发能力,本文在SMA中引入Tent混沌映射反向学习策略,生成反向种群,选择多样性好的种群作为初始种群来提高搜索效率,更好地利用解的局域性;引入自适应权值策略和扰动策略更新黏菌位置,平衡算法全局搜索能力和局部开发能力,避免算法早熟,快速获得全局最优位置。最后,对经典测试函数的寻优曲线进行分析,相较于其他算法,改进SMA算法收敛速度和收敛精度均得到提升。
1 基本黏菌算法
SMA算法是一种随机优化方法,模拟黏菌寻找食物过程的3个阶段:发现食物、接近食物和包围食物[28]。SMA算法利用适应性权值W来模拟基于生物振荡器的黏菌传播波的正负反馈系统结合产生的过程,该生物振荡器旨在展示连接食物的最优路径,权重发生变化,选择不同的更新策略。但是基于随机搜索的更新过程,导致种群多样性差问题;其次,2个随机个体的选择导致算法可能会陷入局部最优。
1.1 发现食物阶段
当食物浓度满足条件时,区域附近的权重较大;当食物浓度较低时,该区域的权重会降低,从而转向其他区域探索。
(1)
式中:
νb=[-a,a];
(2)
(3)
p=tanh|S(i)-FD|,i∈1,2,…,N。
(4)
W权重更新策略为
(5)
SmellIndex=sort(S)。
(6)
式(1)中:r表示[0,1]区间内的随机值;Xb(t)表示当前获得的最佳位置;W为权重;XA(t)和XB(t)是随机选择的2个个体;vb是控制参数;vc从1线性减小到0;t代表当前迭代次数;X(t)表示当前位置;p是选择开关。式(3)中:t表示当前迭代次数;tmax表示最大迭代次数。式(4)中:S(i)是进行排序后的种群;FD是所有迭代中最佳值。式(5)为权重W更新,其中:矢量Fb表示当前迭代过程中获得的最优适应值;Fω表示当前迭代过程中得到的最差适应值;condition表示S(i)是种群的前半部分,i=N/2。式(6)中SmellIndex对适应度值进行排序。
1.2 接近食物阶段
接近食物阶段是模拟黏菌静脉结构内的收缩方法,位置根据食物质量进行调整,也就是说,食物的浓度越高,该区域的权重就越大。否则,根据式(7)将该区域的权值转换为其他区域。位置更新策略为
(7)
式中:R表示[0,1]区间内的随机值;Bl和Bu表示搜索空间范围的下界和上界;z表示切换概率,决定SMA是探索其他食物源还是围绕最佳个体搜索;其他变量同公式(1)。
1.3 包围食物阶段
包围食物阶段是模拟vb的行为,vb在区间[-a,a]中以随机方式浮动,并随着迭代次数的增加逐渐减小到零。vc的值在[0,1]之间浮动,最终到达0。
2 多策略的改进黏菌算法
2.1 基于Tent映射反向学习的初始化种群策略
在SMA算法中,对初始种群使用了随机策略,通过一定范围的上下界实现随机取值,但这种随机策略使得最优解质量和收敛速度等方面不太理想。为了尽可能充分利用解的空间信息,提高最优解的质量和增强初始解搜索空间的勘探能力,本文针对SMA算法的缺点,采用Tent映射反向学习策略对种群进行重新初始化,以便获得更优的初始种群。
2.1.1 Tent映射
研究表明,利用混沌运动的随机性、规律性和遍历性的优势,能够产生丰富且多样性的初始种群。已知的混沌映射有Tent映射、Logistic映射等,Tent映射的遍历均匀性要明显强于Logistic映射[29],产生的初始值均匀分布在[0,1]区间,在提高算法的收敛速度方面有明显的效果。Tent混沌映射表达式为
(8)
当φ∈(0,1),且xk∈[0,1]时,系统(8)处于混沌状态。
2.1.2 反向学习策略
丰富的种群多样性能提高算法的搜索效率,减少计算时间,提高全局收敛能力。反向学习策略[30]是一种提高搜索效率的方法,采用对其初始种群求反向解的思想,增加搜索种群的多样性,进而提高最佳点的质量。其基本思路是:如果在D维度空间X=(X1,X2,…,XD)上存在一点,并且xi(i=1,2,…,D)分布在[c,d]区间内,反向点x′i=c+d-xi,i∈[0,D]。所以种群X′i为Xi的反向种群,反向种群的计算公式为
X′i=Li+Ui-Xi。
(9)
式中:Li和Ui分别为上下界;Xi为原初始种群;X′i为反向种群。
将原始种群和反向种群合并为一个新种群X=(Xi∪X′i),然后计算适应度值并进行排序,选取前N个点作为初始种群X。
2.2 自适应权值策略
受群智能优化算法的启发,黏菌算法在搜索过程中的随机分布限制了全局搜索范围。位置更新中加入一个随迭代次数变化的权值ω,ω的特点是迭代早期值较大,后期值较小。在算法迭代前期,选择较大搜索步长,以提高全局搜索能力,提高算法遍历全局的效果,避免出现早熟收敛;在迭代后期,选择较小搜索步长,以提高局部搜索,加快收敛速度。姜天华[31]提出非线性调整收敛因子,采用带有权重的个体位置更新和局部搜索算法,提高了算法的局部搜索能力。本文引入非线性变化的自适应权值策略,均衡算法勘探和开发能力,充分保证算法的有效性,自适应权值如式(10)[32],式中:ωinitial、ωfinal表示初始值和最终值,ω的范围为[0,1];t是当前的迭代次数;T是最大迭代次数。
(10)
改进后的位置更新公式为
(11)
本文引入自适应权值策略的位置更新,随着迭代次数增加,非线性动态改变权值。早期迭代中权值较大,能够获得较强的探索能力,快速向全局最优值靠拢,从而提高算法的收敛速度;后期迭代中选择较小权值,提高跳出局部最优值的能力。
2.3 扰动策略
黏菌更新位置的时候,一般选择当前最优位置进行更新,使得搜索范围变窄,迭代次数减少。为了提高全局搜索效率,选择对当前最优位置添加一个扰动,并对位置信息进行贪婪策略判断,判断当前位置是否最优。对当前位置进行随机扰动,公式为
(12)
采用贪婪机制策略进行判断是否保留扰动,公式为
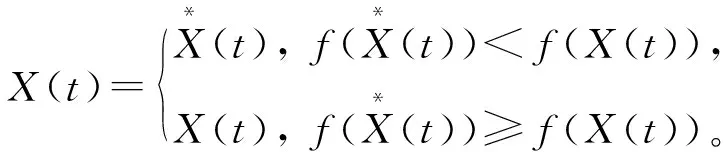
(13)
本文提出的改进SMA算法步骤如下:
Step1 初始化各参数,基于Tent混沌映射和反向学习策略生成初始种群X;
Step2 计算适应度值,进行排序;
Step3 根据迭代条件更新p、vb、vc;
Step4 每次迭代中通过式(5)、(7)、(11)更新位置、权重;
Step5 重新计算适应度值,同时选择适应的更新位置公式,选择最优位置;
Step6 利用式(12)和(13)对当前最优位置进行扰动更新;
Step7 判断是否满足设定的终止条件,如果是,输出全局最优值,算法结束,否则回到Step2。
3 仿真实验及分析
本文仿真实验的所有算法均在相同条件下进行,保证公平性。将PSO[2]、GWO[3]、WOA[5]、SMA[9]和本文多策略的改进SMA算法应用于选取的测试函数,并对结果进行对比分析。
3.1 测试函数
本文选取5个经典测试函数来验证算法的有效性,测试函数如表1所示。单峰函数f1和f2用来测试本文算法的局部开发能力,多峰函数f3、f4、f5用来测试本文算法的全局搜索能力。

表1 测试函数Tab. 1 Test function
算法的参数设置如表2所示,参数的选择是基于原文作者使用的参数或各种研究人员广泛使用的参数[6]。其中,设置种群的规模N=30,最大迭代次数T=1 000,维度D=30,为了减少算法运行随机因素的影响,将算法在测试函数中单独运行30次,取平均值作为最终运行结果。

表2 参数设置Tab. 2 Parameter settings
3.2 实验对比与分析
所有仿真实验在Windows10操作系统,Intel Core i5处理器上,基于MATLAB 2018b进行。通过结合算法迭代到最优值的迭代次数和寻到最优值所用时间来综合评价收敛速度,通过数据分析收敛精度,本文从收敛速度和收敛精度2个角度分析算法的搜索效率。
3.2.1 改进SMA算法与SMA、PSO、GWO、WOA的对比
为了直观清晰观察算法的收敛性,给出测试函数f1~f5收敛曲线,如图1所示。收敛曲线能直观看出收敛速度和陷入局部最优问题,横坐标为迭代次数,纵坐标为适应度值。记录最优函数值的标准差和平均值数据,如表3所示。

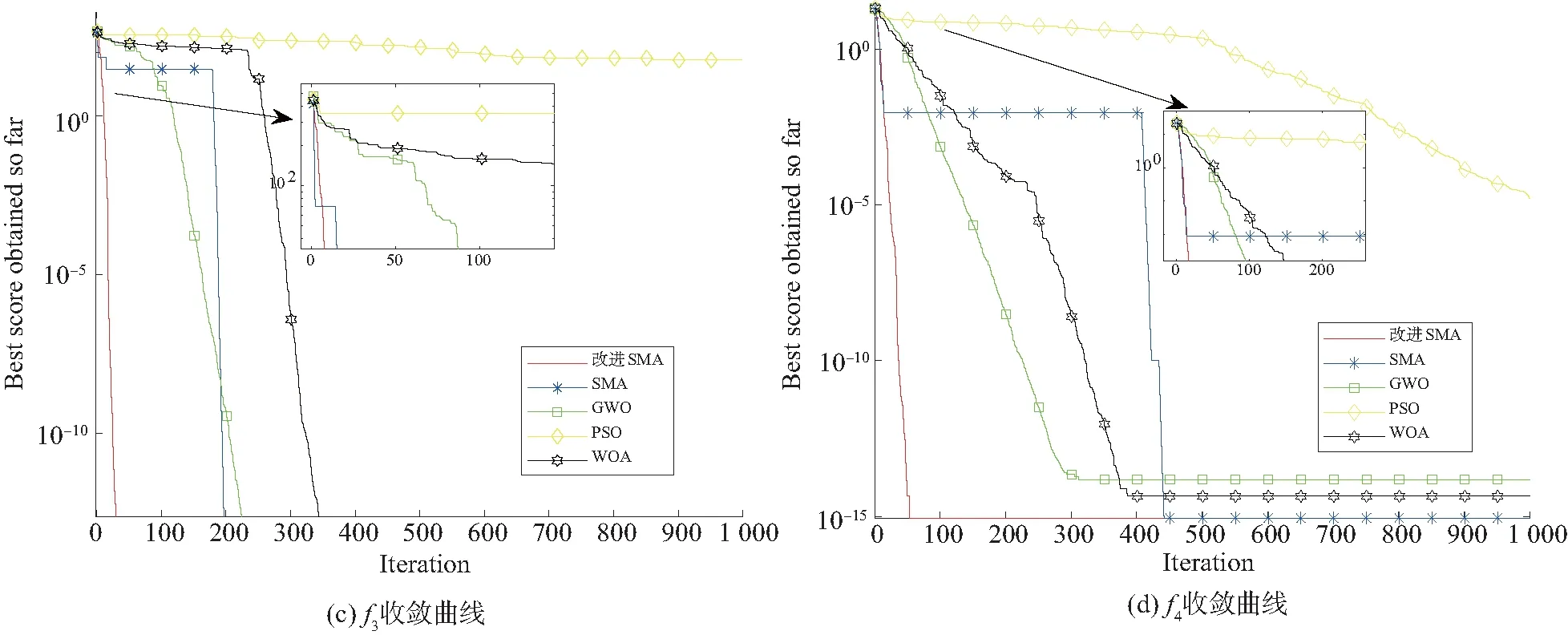
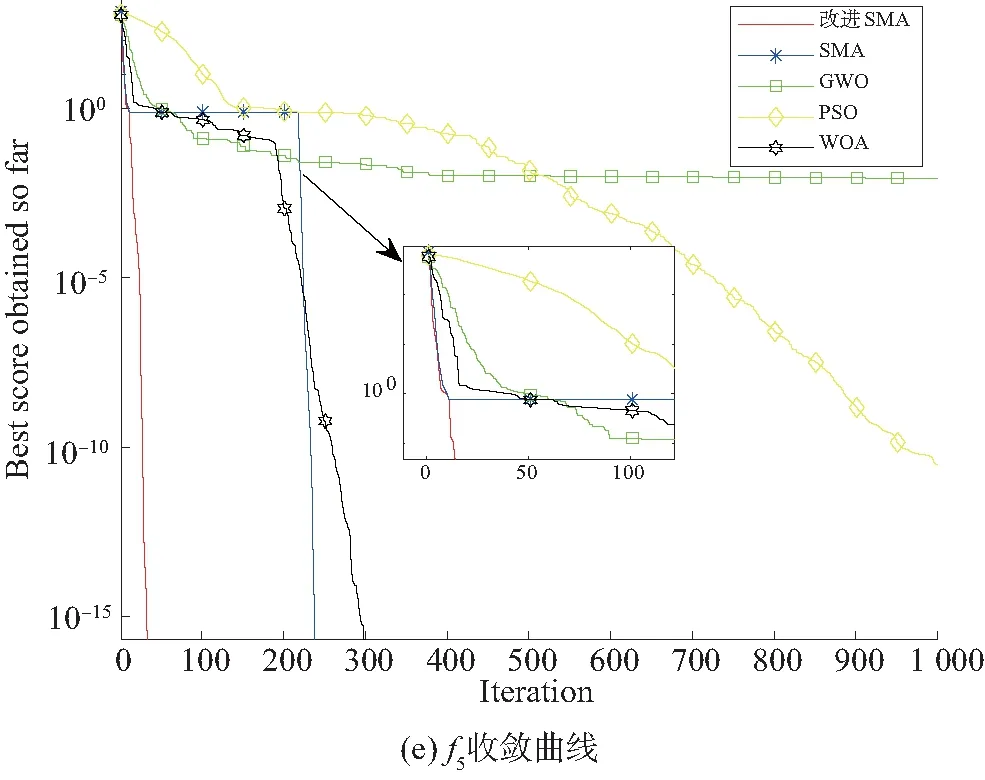
图1 与经典算法对比时函数f1 ~ f5寻优曲线Fig. 1 Optimization curve of functions f1 ~ f5 when the classicol algorithm compares
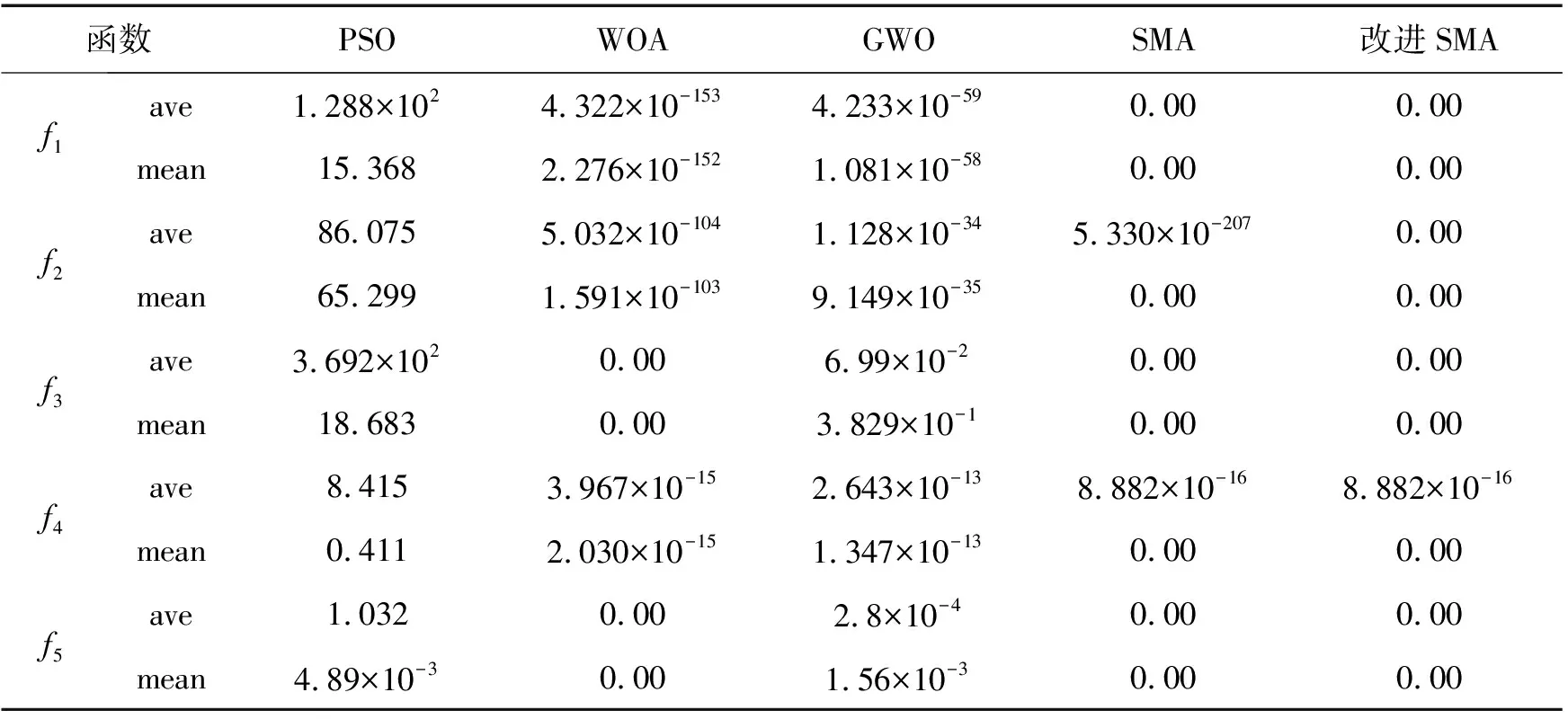
表3 改进的SMA算法与SMA、PSO、GWO、WOA算法实验结果对比Tab. 3 Comparison of test function results between improved SMA algorithm and SMA, PSO, GWO and WOA algorithms
图1给出各算法分别在30维度空间的寻优曲线。从收敛速度分析,图1(a)中,PSO、WOA、GWO在1 000次迭代过程中未搜索到极值点;SMA算法在迭代次数为50时出现陷入局部极值的情况,直到700次附近找到极值点0;而多策略的改进SMA算法的曲线平滑,没有出现陷入局部极值点现象,在迭代次数达到300附近已经寻得全局极值点0。
图1(b)中存在陷入局部极值现象,PSO、WOA、GWO陷入不同的局部极值中;SMA算法在迭代中多次陷入局部最优,到达1 000次迭代时出现平行于x轴的平行线,均未寻得极值点0;而改进的SMA算法由于策略的引入,避免陷入局部最优,在迭代次数为600左右时,寻得全局极值点0,使得算法的收敛速度优于其他算法。
观察图1(c)(多峰函数f3),PSO算法陷入局部最优值,WOA、GWO、SMA、改进的SMA算法找到全局最优极值点0。WOA和GWO快速跳出局部现象,当迭代次数达到300附近时找到全局最优极值点0,SMA算法在200次附近找到全局极值点,而改进SMA算法比SMA算法提前约150代找到全局极值点0,迭代次数相较SMA算法减少约170代。
在图1(d)中,PSO、WOA、GWO、SMA算法的收敛曲线均在多策略改进的SMA算法上方,已经出现局部问题,收敛速度慢,而改进的SMA算法在搜索过程中未出现陷入局部极值现象,迭代次数在50左右快速收敛寻得全局最优值8.882×10-16,改进的SMA算法相较于SMA算法收敛速度得到提高。
Griewank(f5)函数能够测试算法跳出局部能力,改进的SMA算法在迭代次数50之前已经找到全局极值点0,SMA算法出现陷入局部最优的现象。图1(e)说明引入多策略的改进SMA算法大幅度减少了算法收敛到全局最优值的迭代次数。
从收敛精度分析,表3数据显示,改进的SMA算法得到的平均值和标准差均优于比较算法,找到f2函数全局极值点0,而SMA算法的最优值为5.330×10-207,未找到全局极值点0,改进算法的收敛精度得到提高。
综上所述,图1(a)、(b)中表现出算法的局部开发能力明显提高,图1(c)、(d)、(e)在全局搜索方面表现较优,PSO、WOA、GWO、SMA算法存在陷入局部最优的现象,而多策略的改进SMA算法避免了局部极值问题,曲线的收敛速度优于其他算法,能较快找到全局最优值,收敛精度得到较大提高。
3.2.2 改进的SMA算法与SMA、CESMA的仿真实验分析
为进一步充分验证改进的SMA算法的有效性,选取SMA、CESMA与改进的SMA算法比较,结果如图2所示。给出相关算法在30维空间运行30次的数据,记录最优函数值的标准差和平均值,如表4所示。

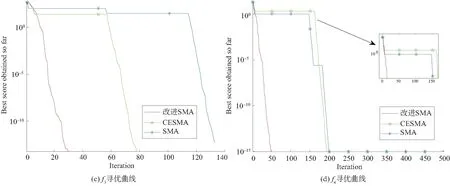
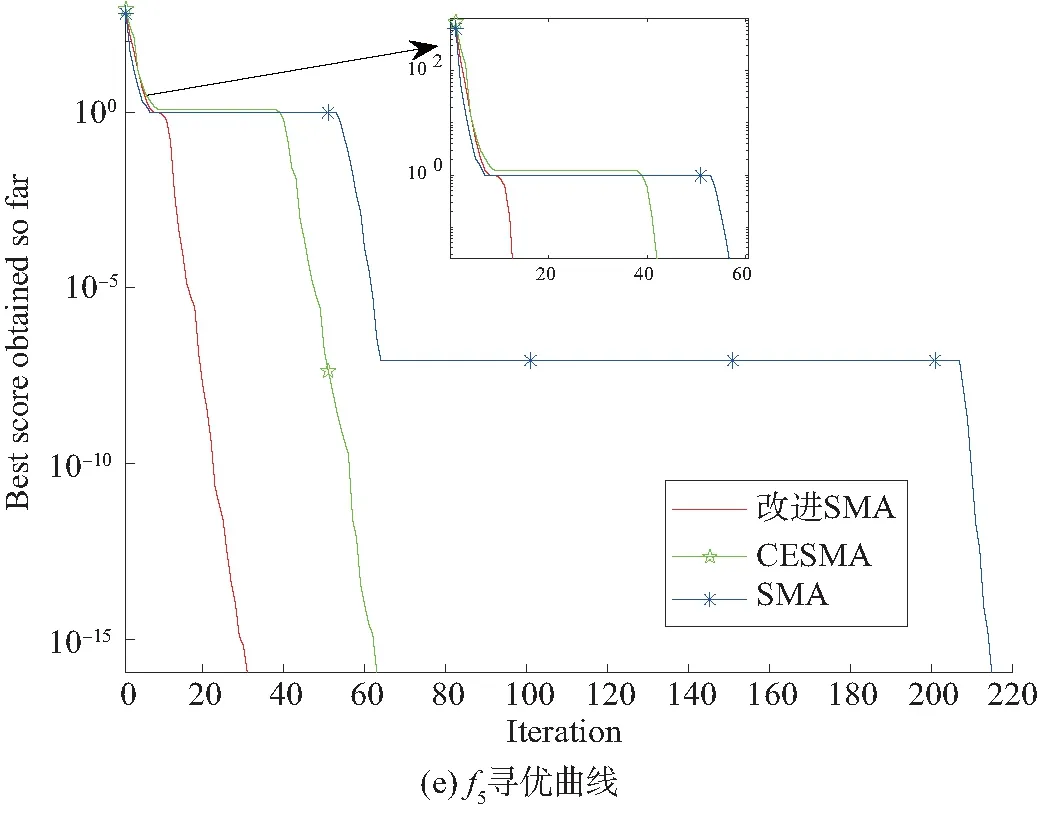
图2 与改进算法对比时f1 ~ f5函数寻优曲线Fig. 2 Optimization curve of function f1 ~ f5 when the improred algorithm compares
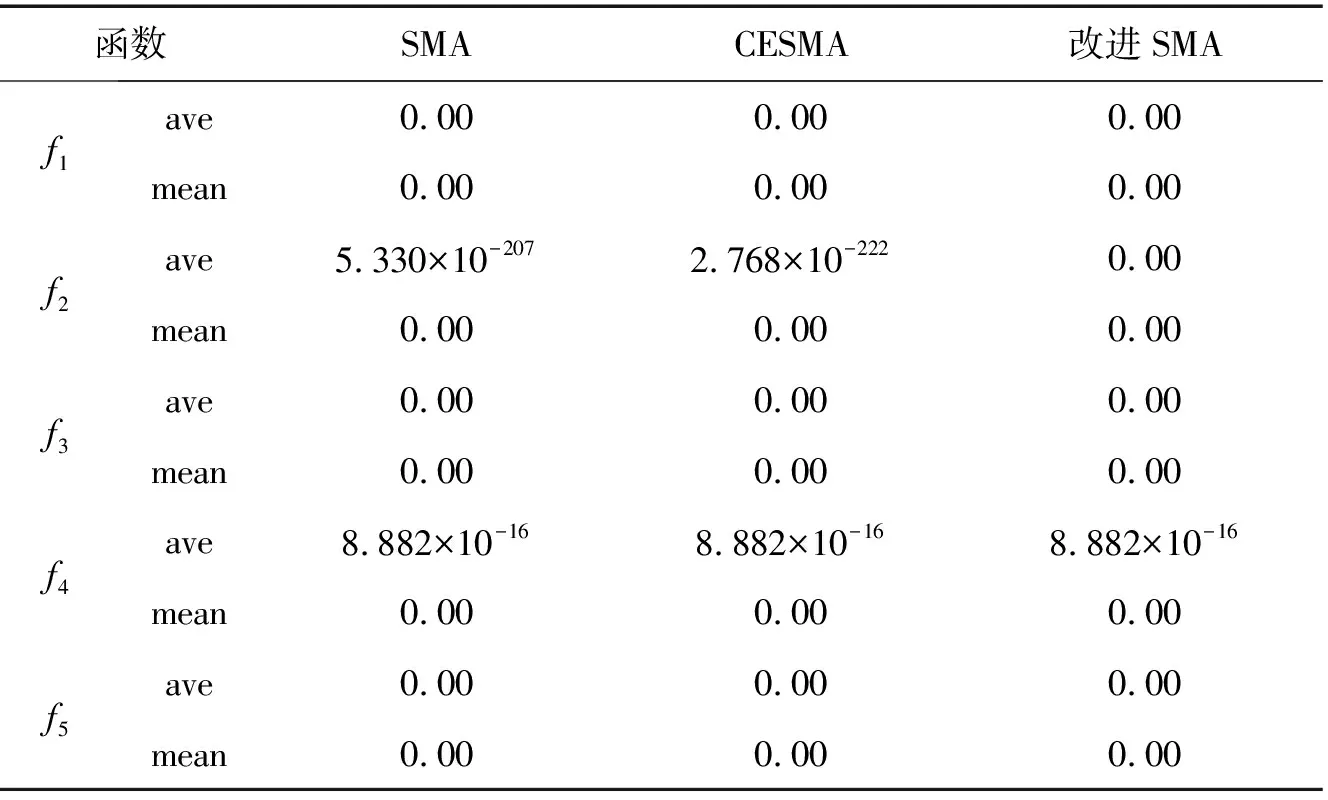
表4 改进的SMA算法与CESMA、SMA算法实验结果对比Tab. 4 Comparison of test function results between improved SMA algorithm, CESMA algorithm and SMA algorithm
图2给出测试函数在30维空间的寻优曲线。从收敛速度分析,图2(a)是Sphere(f1)函数仿真结果,改进的SMA算法的收敛曲线位于CESMA和SMA下方,迭代次数为300左右时寻得全局极值点0;而CESMA和SMA在搜索过程中出现较多的局部极值,由于CESMA算法引入Tent混沌映射反向学习策略,相较于SMA算法,更快找到全局最优值。改进的SMA算法引入自适应权值策略和扰动策略,明显提高了全局搜索能力,迅速朝着全局最优值搜索,避开了局部最优值,算法的收敛速度效果较佳,相较于CESMA算法,迭代次数减少约58%,收敛效果优于CESMA和SMA算法。
图2(b)是Schwefel 2.22函数仿真结果,改进的SMA在550次左右找到全局极值点0,此时CESMA和SMA陷入局部最优值,无法避免局部极值点,最终未寻到全局极值点0。相较于CESMA和SMA算法,改进的SMA算法寻得全局极值点0,收敛精度相对较高。
在图2(c)、图2(e)中,改进的SMA收敛速度优于CESMA和SMA算法,在迭代次数为30左右已经寻得极值点0。CESMA和SMA算法虽然找到全局最优值,但是SMA在迭代过程中经过更多的迭代次数才跳出局部极值现象,跳出局部能力较弱;CESMA算法在迭代次数为60左右时迅速跳出局部,寻得全局最优值0。引入Tent混沌反向学习策略的CESMA算法相较于SMA算法克服了陷入局部极值问题,引入自适应权值策略和扰动策略的改进SMA算法解决了早期容易陷入局部极值问题,同时算法的搜索效率相较于SMA算法和CESMA算法都有所提高。
图2(d)中改进的SMA相较于CESMA算法寻到全局最优值的迭代次数减少约75%,相较于SMA算法减少约76%。
从收敛精度分析,表4数据中,改进的SMA算法,除f4外均找到极值点0,而CESMA虽然精度高于SMA算法,但二者均未找到f2和f4函数极值点0,多策略的改进SMA算法收敛精度优于CESMA和SMA算法。
综上所述,图2(a)、(b)中表现出改进的SMA算法的局部开发能力明显提高,图2(c)、(d)、(e)表现出其在全局搜索方面较优。多策略的改进SMA算法通过引入映射反向学习策略提高了算法的收敛精度;引入自适应权值策略和扰动策略进一步提高算法的勘探能力,快速获得全局最优解。
本文还对算法的收敛速度通过该算法迭代到最优值的迭代次数和平均总运行时间进行综合评估。表5给出收敛精度较高的3种算法迭代到全局最优值的迭代次数、每代消耗时间、平均总运行时间数据。从表5数据分析可知,改进的SMA算法寻到全局最优值的迭代次数相对较少,在较短时间内找到全局最优值,平均总运行时间也相对较短,进一步说明改进的SMA算法在收敛速度上的优越性。
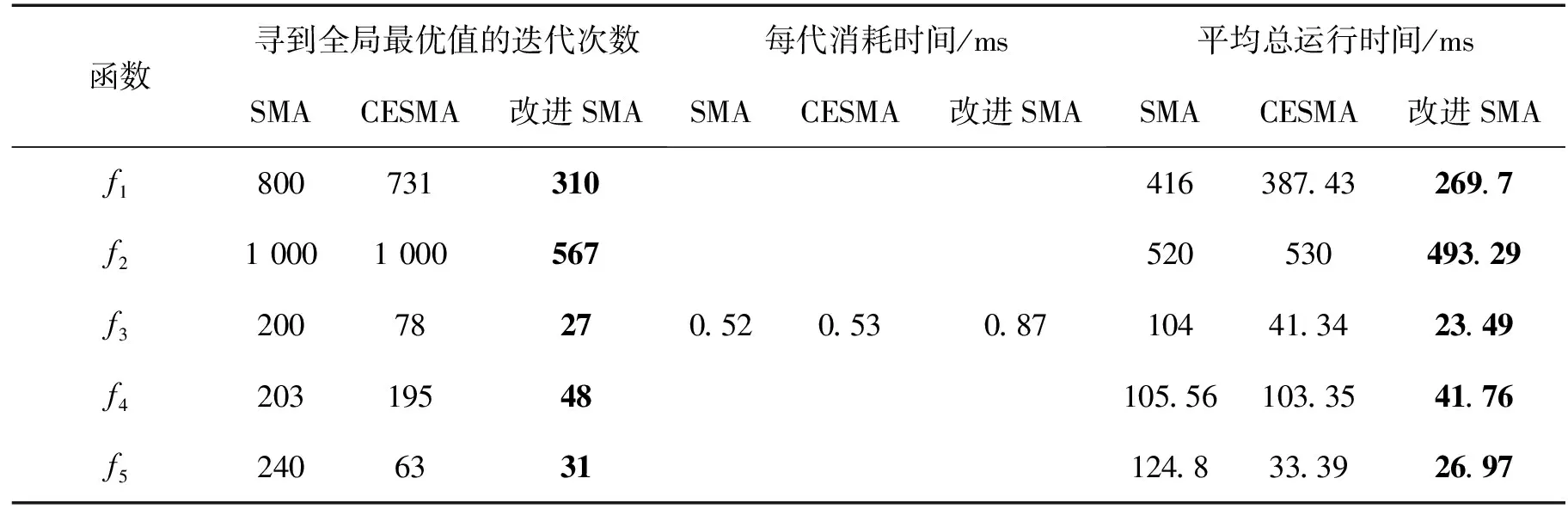
表5 平均总运行时间Tab. 5 Average total running time
4 结语
针对黏菌算法(SMA)搜索效率低和易陷入局部最优的问题,本文提出一种多策略的改进黏菌算法。通过Tent混沌映射反向学习策略优化初始种群,提高了算法收敛速度。自适应权值策略避免了算法局部极值现象,提高了黏菌靠近和获取食物的速度,算法的勘探能力和收敛精度得到较大提高。扰动策略对最优位置进行扰动更新,找到较佳的全局最优值,算法能够避免早熟现象。通过分析测试函数的寻优结果,表明多策略的改进SMA算法打破了早熟现象,获得较高的搜索效率,不仅收敛速度得到提高,较快地找到全局最优值,而且具有较高的收敛精度,寻得极值点。相较于对比算法,具有较好的全局搜索和跳出局部极值能力,充分验证了改进算法的有效性。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
成都信息工程大学学报(2022年3期)2022-07-21
数学物理学报(2022年2期)2022-04-26
新世纪智能(数学备考)(2021年10期)2021-12-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
河北理科教学研究(2020年3期)2021-01-04
语数外学习·高中版中旬(2020年10期)2020-09-10
中学数学杂志(2019年1期)2019-04-03
金桥(2018年4期)2018-09-26
计算机测量与控制(2018年3期)2018-03-27
