
一种新的平衡化谱聚类方法*
2023-03-08 03:12苏扬胡恩良
云南师范大学学报(自然科学版) 2023年1期
苏扬, 胡恩良
(云南师范大学 数学学院,云南 昆明 650500)
1 引言
谱聚类(Spectral Clustering,SPC)是一种基于图论的聚类方法,其本质是将聚类问题转化为求解Laplacian 矩阵或相似矩阵的谱分解问题.与传统聚类算法相比,谱聚类能够在任意形状样本分布上聚类且收敛于全局最优解[1].处理数据时,谱聚类仅需要构建样本点之间的相似度矩阵,这对处理高维数据聚类具有一定优势.近年来,谱聚类算法获得了持续改进和发展,例如:针对谱聚类中的相似度测量问题,Tasdemir等人[2]提出了一种基于测地线距离的混合相似性度量方法,应用不同类型的信息来表示数据点间的相似度;Wang等人[3]提出了一种谱多流形聚类算法(Spectral Multi-Manifold Clustering,SMMC);Zhang 等人[4]提出了基于随机游走来建立 Gaussian核相似矩阵.但要解决任意形状样本分布的数据聚类问题,迄今为止已提出的算法都是不完美的,谱聚类也不例外.
传统谱聚类隐含了各簇数据点数量分布较均衡的假设,即要求所选各簇之间的数据点数量差异不大.因此对各簇间样本点数相差悬殊的类不平衡问题,传统谱聚类将不再适用.针对类不平衡问题,刘富等人[5]提出了一种基于聚类体量约束的模糊c-harmonic均值算法,刘欢等人[6]改进了EM聚类算法,王舒梵等人[7]构建了高斯混合模型聚类的SMOTE过采样算法.然而,这些算法虽然提高了数据集类不平衡问题的聚类性能,但在处理高维数据集时容易产生“维数灾难”现象,导致聚类质量降低.为此,本文提出了一种新的平衡化谱聚类算法(Balanced Spectral Clustering,BSPC),该算法考虑谱聚类算法的基本特性融入了隶属度矩阵的近似正交约束,在克服“均匀效应”[8]问题的同时保证了结果的准确性.
2 平衡化谱聚类
2.1 谱聚类分析
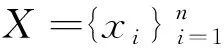
(1)
2.2 平衡化谱聚类
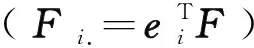
(2)
在模型(2)中:
i)约束“Fi.∈Δk,∀i∈[n]={1,…,n}”仅使得数据点对各个聚类中心的隶属度之和为1,而对各类样本点的隶属度总和没有限制,由此在处理非平衡数据时,极易使“大类”样本的隶属度总和过高,“小类”样本的隶属度总和过低,这便导致了“均匀效应”.因此需要对大类和小类的隶属度总和施加“平衡”约束;
ii)约束“FTF=I”对隶属度矩阵施加正交约束“平衡”大类和小类的隶属度总和[9].直观的,若约束隶属度矩阵F满足近似正交(FTF≈I),记F·p表示F的第P列,则
(3)
(4)
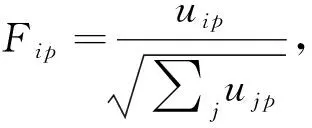
2.3 模型求解
为了求解问题(2),利用文献[10]中的迹惩罚函数,将问题(2)转化为
(5)
其中μ是罚参数.经过计算可知,(5)式等价于
(6)
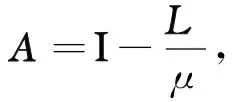
(7)
由于问题(7)中的目标函数是二次函数,所以可考虑利用Gauss-Newton(GN)法对其求解[11].记S(Ft)为g(F)在点Ft处的GN方向,则GN迭代格式为
Ft+1=Ft+αtS(Ft).
(8)
根据文献[10], 计算问题(7)的GN方向解析表达式,即
(9)
至此,平衡化谱聚类模型的近似问题(5)的求解算法可归纳为如下算法.
算法 平衡化谱聚类(BSPC)
输入:Laplacian矩阵L,期望的聚类数k,罚参数μ,最大迭代次数T,终止精度ε.
输出:聚类隶属度矩阵F*.
step1 :设置t=0,初始点F0;
step2 :根据(9)式计算GN方向
St=S(Ft);
step3 :利用线搜索求St方向的歩长αt,根据(8)式更新F为
Ft+1=Ft+αtSt;
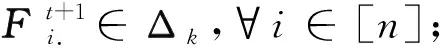
输出F*=Ft+1.
3 实验与分析
3.1 数据集选取
分别在模拟数据集和真实数据集上验证BSPC算法的有效性.模拟数据集共4个,分别由具有二维高斯分布的类不平衡数据点构建,每个数据集包含300个样本点,其中大尺寸类样本点和小尺寸类样本点的比例依次为9∶1(D1)、8∶2(D2)、7∶3(D3)和 6∶4(D4).真实数据集选用具有不同实际应用背景的UCI数据集,从中选取Chessboard、Spiral、Protein、Glass、 Heart、Cancer和CMC共7组数据作为测试集,所有数据集均经过类不平衡化处理,即各类的样本比例作了设置(如表1).
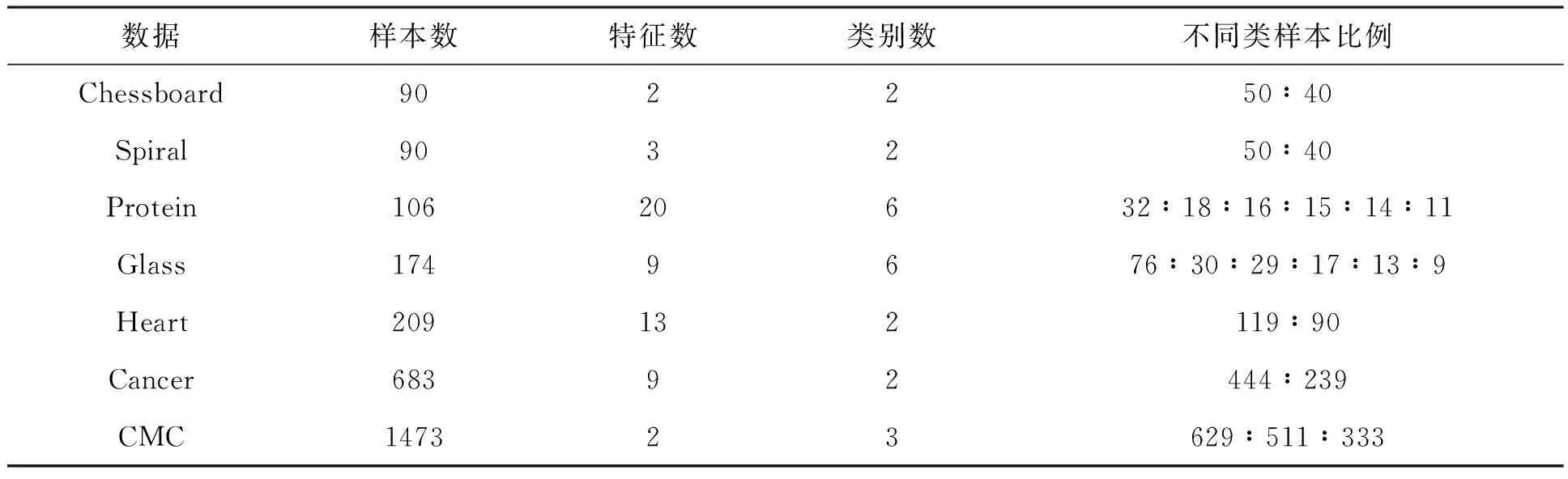
表1 实验所用数据集及其相关信息
3.2 性能评价指标
在实验中,设置期望聚类数等于数据集真实类别数.由于所选数据集都有真实的类标号,可将其作为聚类结果的基准.采用聚类纯度(Cluster Purity,CP)[11]来衡量聚类效果,CP定义如下:
(10)
其中,n为样本总数,njl为真实第j类中与聚类输出为第l中所含相同样本数.CP定义是将每个聚类标号对应于与其含有相同样本数最多的真实类标号,这k类中相同样本数之和与样本总数的占比,便是聚类纯度.聚类纯度越高且越接近1,表明聚类效果越好.
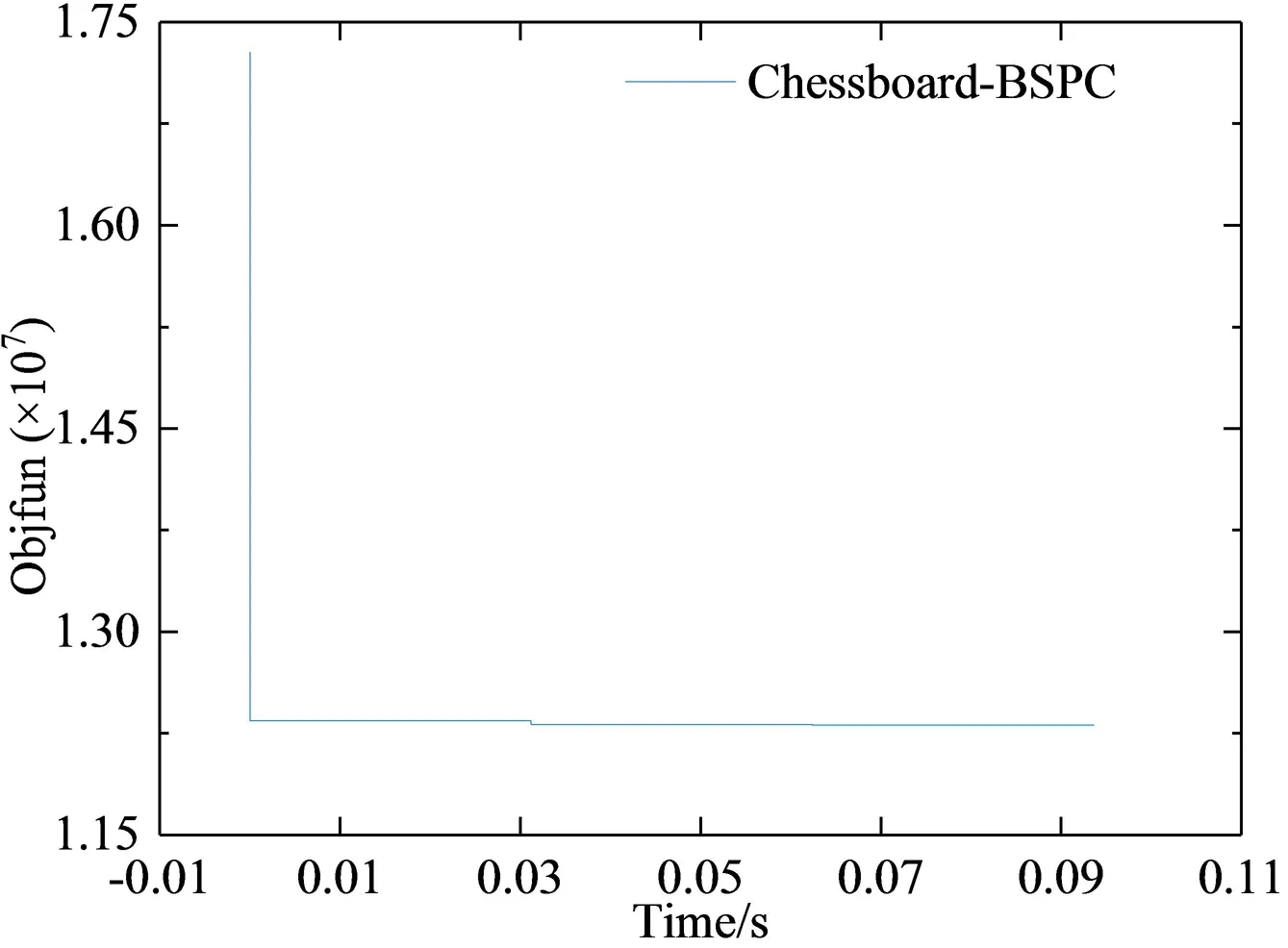
图1 在Chessboard数据集上的收敛性Fig.1 Convergence on the Chessboard dataset
3.3 实验结果及分析
在Chessboard数据集上运行BSPC算法,由图1的算法迭代图可知,BSPC算法的目标函数值具有迭代收敛性.
为了验证本文算法的聚类效果,使用SPC算法[1]与本文算法进行比较,在所有测试数据集上,分别以不同的初始点运行30次,并在表2中报告平均聚类纯度和标准差.可以看出,在多数情况下BSPC能获得更大的CP值.这是因为:① BSPC在SPC的基础上加入了正交约束项,使得大尺寸类的样本聚类隶属度降低,小尺寸类样本的聚类隶属度升高,从而缓解了聚类算法在不平衡数据上容易导致的均匀效应;②正交约束提高了类(簇)间的分离性.
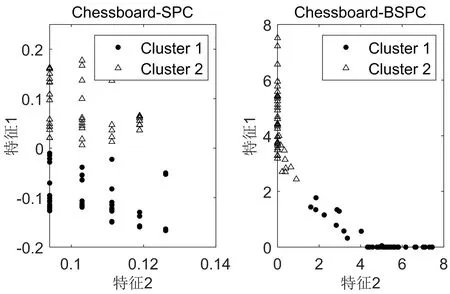
图2 在Chessboard数据集上的聚类效果Fig.2 Clustering effect on chessboard dataset
图2中显示SPC算法和BSPC算法在Chessboard数据集上的聚类结果,可看出BSPC更好地缓解了均匀效应,提高了各类(簇)间的分离性.
4 结语
在传统谱聚类的基础上提出了一种新的平衡化谱聚类模型,该模型在谱聚类的基础上加入了对聚类隶属度矩阵的正交约束,在11个不平衡数据集上的测试实验结果表明,提出的新算法相比于传统谱聚类具有更好的聚类效果.
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学年刊A辑(中文版)(2020年1期)2020-05-19
数学物理学报(2019年6期)2020-01-13
铁道通信信号(2019年6期)2019-10-08
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
雷达学报(2017年6期)2017-03-26
公民与法治(2016年8期)2016-05-17
人生十六七(2015年6期)2015-02-28
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
