
ChatGPT来了,我们离AI生成电影还有多远?
2023-04-11 12:19张雪
现代电影技术 2023年3期
如果你还没有和ChatGPT (Chat Generative Pre-trained Transformer)对话,都不好意思聊人工智能(AI)。
Chat GPT 是美国人工智能实验室Open AI发布的一种生成式大型语言模型,采用Transformer深度神经网络架构,基于人类反馈的监督学习和强化学习,在GPT-3.5模型之上进行训练微调形成,能够通过学习人类语言和理解上下文来实现对话互动,敢于质疑与承认错误,大幅提升了对用户意图的理解能力。
ChatGPT 上线2个月,月活跃用户就已成功过亿,并于近日宣布开放API,允许第三方开发者将其集成至应用程序和服务中。
那么,“神通广大”的Chat-GPT可以生成一部电影吗?
1 ChatGPT生成剧本
菲律宾28 Squared工作室和Moon Ventures工作室运用Chat GPT帮助剧本创作,7天制作完成6 分半短片 《安全地带》(The Safe Zone)。团队首先使用ChatGPT 筛选出大量故事创意,并挑选前五名,让ChatGPT为这五个创意生成剧本。但在这一过程中,团队发现ChatGPT 会很快偏离关键主题,为此制片人只能不断提醒其注意情节的发展逻辑。最后,团队通过主动要求ChatGPT 对故事的某些部分提供更多细节来充实剧本。剧本生成后,ChatGPT 可以根据剧本内容设计具体的镜头清单,还可以回答机位、演员位置、灯光位置、角色情绪、服装道具等完整细节,以辅助分镜设计。
2 AI生成电影
采用Chat GPT 生成剧本已完成了电影制作的第一步,后续电影制作仍能由AI完成吗?Chat GPT认为“如果结合多个AI模型,可能可以实现一些电影制作方面的任务。”下面让我们看看在电影制作过程中,AI都能完成哪些制作任务。
电影主要由图像和声音两大要素组成,在图像和声音生成领域近年来发展形成了较多国内外AI模型,从图1可以窥见一斑。它们 “可能可以”接力ChatGPT 生成的剧本,完成相应的电影制作。
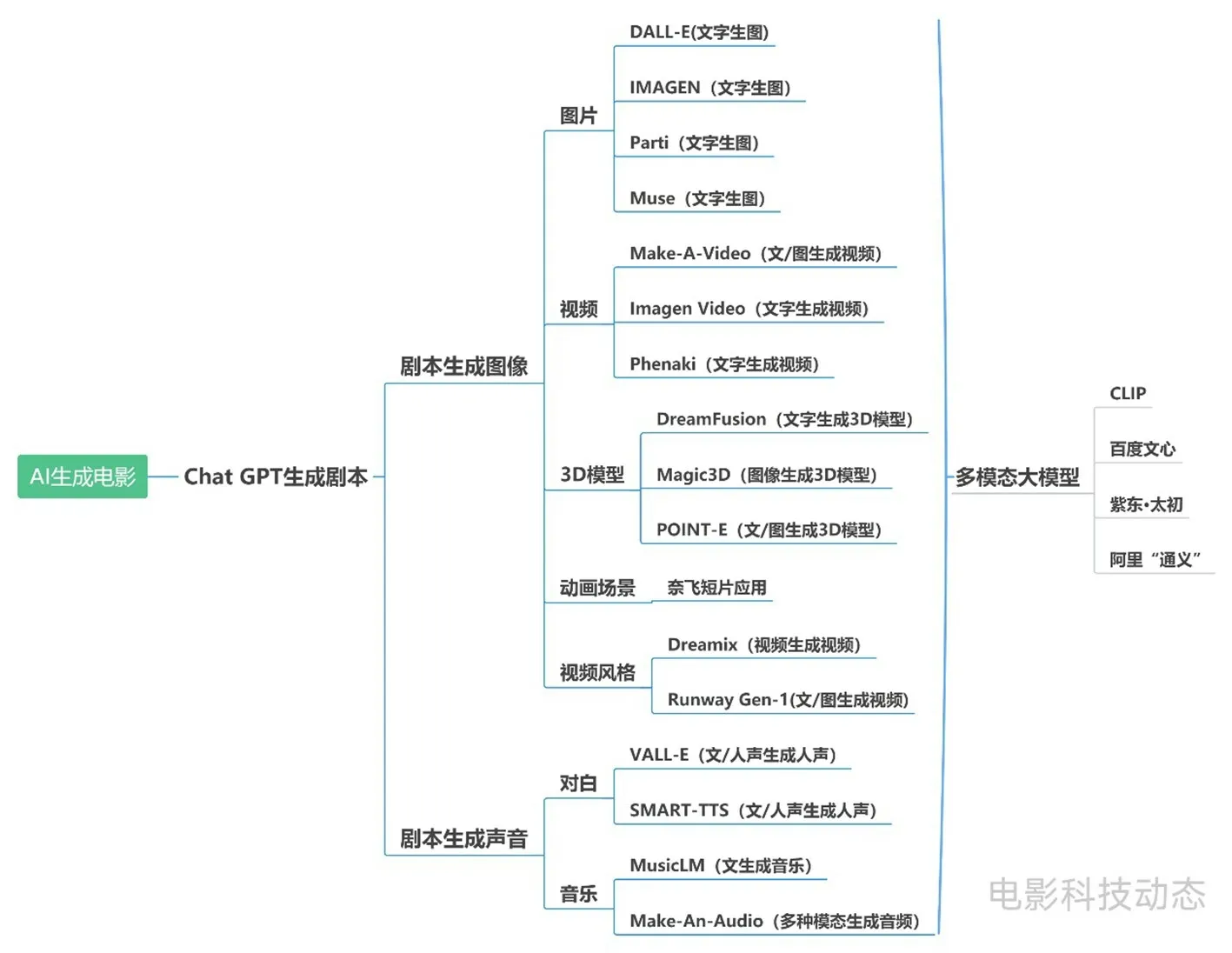
图1 电影制作过程中AI能够完成的制作任务
3 图像生成
目前各类图像AIGC (人工智能生成内容)模型发展迅速,如文字生图片、文字生视频、3D 模型生成、动画场景生成、视频风格迁移等。
3.1 图片生成
当前文字生图片AI模型发展较快,其中较为常见的大模型包括Open AI的DALL-E 2和谷歌的IMAGEN、Parti、Muse。
DALL-E 2虽能生成较为逼真的图片,但无法辨识上下左右等方位信息,当文本中存在对物体颜色或场景内文字的描述时会出现错误,生成复杂场景时还会出现严重的细节缺失。IMAGEN 使用大量纯文本语料训练,得益于强大的编码器,IMAGEN在为物体分配颜色和生成场景内文字时更加准确。Parti具有可扩展的模型规模,最高可扩展至200亿参数,参数越多、模型规模越大,生成图像的细节越丰富,错误信息也明显降低。Muse在给输入图片加入掩码进行重构学习的基础上,利用动态遮蔽率实现推理阶段的迭代并行编码,在不损失图片生成效果的同时,极大地提高了模型推理效率。
3.2 视频生成
视频可以认为是多张 “图片”有逻辑、连贯的组成,AI生成视频是AI生成图片的深度延伸。现有AI生成视频模型可一定程度满足提升效率与契合脚本内容的需求,但由于模型本身能力和训练素材质量的限制,此类模型目前处于非常初级的阶段,存在动作过渡不自然、理解角度诡异、视频分辨率不高等问题,所生成的视频还不够完善。
Meta的“Make-A-Video”AI影片生成工具可通过文字和图片识别,生成一段时长5秒、16FPS的无声片段,分辨率为768×768。除文本输入外,还可根据其他视频或图片制作新视频,或是生成连接图像的关键帧,让静态图片动起来。
谷歌的Imagen Video与Phenaki,前者主打视频品质,后者主要挑战视频长度。其中Imagen Video可根据文本提示以24FPS生成分辨率为1280×768的视频,长度不超过5 秒;Phenaki可根据200 词左右的提示语生成2分钟以上长镜头,且具备相对完整的故事情节。
3.3 3D 模型生成
若需要制作更为复杂的3D 模型,也有相应的AI生成模型,但渲染环节暂无专门的AI模型支持。谷歌DreamFusion可由文本生成具有密度和颜色的3D 模型,还可进一步导出为网格体,以便进一步加工。英伟达Magic3D 使用两阶段生成法,首先使用低分辨率扩散先验获得模型的粗略表示,并使用稀疏3D 哈希网格结构进行加速;再以粗略表示作为初始,进一步优化具有纹理的3D 网格模型。Open AI的POINT-E由文本-图像模型和图像-3D模型组成,其首先根据文本生成2D 图像,再将2D图像依次转换为包含1024个点的粗略点云,最后在粗略点云的基础上生成包含4096个点的精细点云。
3.4 动画场景生成
AI在动画场景绘制方面已有短片应用。此前奈飞(Netflix)与微软小冰、WIT STUDIO 共同创作首支AIGC动画短片《犬与少年》,其中部分动画场景由AI辅助生成。其采用类似Stable Diffusion中以图生图的方式,由制作人提供设计图,AI生成细节并优化,形成一张完成度较高的场景图,制作方只需对这张图进行适当修改,即可直接使用。
3.5 视频风格迁移
如果对现有视频风格不满意,还可使用AI工具生成其他定制风格的新视频。谷歌Dreamix可通过应用特定的风格从现有视频中创建新的视频。曾在2022年创建“文本-图像”模型Stable Diffusion的技术公司Runway推出模型Gen-1,可通过文本提示或参考图像指定的任何风格,将现有视频转换为全新风格、时长更长的视频。
4 声音生成
声音作为电影的另一项要素,主要包括对白、音效、音乐,共同起着情节推进、氛围营造和情感共鸣等重要作用。目前也有不少AI模型可以完成相关内容的生成制作。
4.1 对白
微软的语音合成AI模型VALL-E 经过6万小时英语语音数据的训练,使用特定语音的3秒剪辑来生成内容,可复制说话者的情绪和语气,即使说话者本人从未说过的单词也可以模仿。
科大讯飞的多风格多情感合成系统SMARTTTS充分利用文本和语音的无监督预训练,实现了从文本到声学特征,再到语音的端到端建模,可提供11 种情感、每种情感20 档强弱度的调节能力,也可根据自己喜好调节停顿、重音、语速等。
4.2 音乐
谷歌的Music LM 可从文本描述中生成频率为24k Hz的高保真音乐,还可以基于已有旋律转换为其他乐器,甚至可以设置AI“音乐家”的经验水平,系统可以根据地点、时代或音乐风格 (例如锻炼的励志音乐)进行创作。
浙江大学与北京大学联合火山语音提出的文本到音频的生成系统Make-An-Audio,可将自然语言描述作为输入,而且是任意模态(例如文本、音频、图像、视频等)均可,同时输出符合描述的音频音效,具有强可控性、泛化性。
4.3 多模态大模型
多模态大模型能够在计算机视觉 (CV)、自然语言处理(NLP)、语音识别等不同的模态间构建关联,单个模型可支持,以音生图、以文生图、以图生音以及声音转文字等功能。OpenAI的CLIP、国内百度文心、紫东·太初、阿里“通义”等多模态大模型近年来持续发展,在电影制作领域也具备一定的潜在应用价值。
5 结语
在上述各类模型的共同参与下,AI生成电影的基本链条已具雏形。但正如ChatGPT 所言,目前AI技术仍然存在一些局限:
第一,AI模型仍然需要人工干预,语言类模型给出的文本指导需经过专业技术人员的审核确认才能实际应用;
第二,用于生成视频和音频的AI模型由于训练数据的限制,生成结果较为简单,质量还远远达不到电影要求;
第三,由于AI生成内容是由机器使用现有数据和内容产生,AI生成作品的版权问题仍存在较大争议,法律对AI生成内容的版权保护仍处于“缺位”状态。
猜你喜欢
制造技术与机床(2019年10期)2019-10-26
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
电子制作(2018年18期)2018-11-14
小学教学参考(2015年20期)2016-01-15
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
