
基于深度强化学习的无人机自组网路由算法
2023-05-05 03:10乔冠华潘俊男张易新
重庆邮电大学学报(自然科学版) 2023年2期
乔冠华,吴 麒,王 翔,潘俊男,张易新,丁 建
(1.中国西南电子技术研究所 成都 610036;2.重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
无人机具有体积小、移动速度快、灵活性强等优点,在军事和公共管理等领域的应用十分广泛。在美军无人机[1]和无人机系统[2]规划中,无人机作为全球信息系统的一个重要节点,与地面无人机系统、海上无人机系统构成一体化的无人作战系统。无人机自组网不仅具有传统自组织网络的无中心化、动态网络拓扑、多跳路由、资源受限等共性,还具有能量受限、节点移动速度快、传输实时性高等特点。
目前,无线网络的路由协议主要有:基于路由表的主动路由协议,如DSDV[3]和OLSR[4]路由协议;按需响应协议,如AODV[5]、DSR[6]、TORA[7]路由协议;混合路由协议,如ZRP[8]协议;机会路由协议,如基于强化学习的路由算法[9];基于位置的路由协议,如GPSR路由协议[10]。基于强化学习的路由算法在复杂网络中显示出强大优势,得到了广泛的关注与研究。
传统方法当中,文献[11]提出了适用于无人机自组网的基于最短路径的改进路由算法。该算法可以实现多路径传输,并且从丢包率、端到端时延和抖动3个方面评估性能,但没有考虑动态场景的情况。文献[12]提出了一种具有负载感知和网络拓扑变动感知能力的多指标多径优化链路状态路由协议。该协议在成功率、端到端时延和吞吐量性能上均有明显提高,进而证明所提多径路由方案的合理性。
在现有的基于深度强化学习的研究成果中,文献[13]首次提出基于强化学习的Q-Learning算法[14]的逐跳路由算法。该算法实现自适应路由,并且在动态变化的网络中表现良好。当网络负载水平、流量模式和拓扑结构随时间变化时,其性能都优于传统的路由协议。
在Q-Routing算法的基础上,又出现了多种改进算法,如PQ-R[15],SQ-R[16]等。但是,Q-Routing算法及其扩展方案应用到复杂的无线网络中时存在明显缺陷。基于Q-Routing的路由算法要维护Q表,需要消耗大量的时间和空间成本,并且无法扩展到较大的动作和状态空间。
文献[17]提出的TQNGPSR是基于GPSR和Q网络的流量感知无人机ad-hoc网络路由协议。该协议利用邻居节点的拥塞信息实现流量平衡,并用Q网络算法评价当前节点每条无线链接的质量。基于对链接的评估,该协议可在多个选择中作出合理决定,降低网络时延和丢包率。
文献[18]提出一种基于深度强化学习的集中式无线多跳网络能量高效机会路由算法,通过机会路由的方式减少传输时间,同时平衡能耗、延长网络寿命。文献[19]提出了一种基于强化学习的分布式和能量高效无线物联网路由算法,通过仿真评估了算法的失效率、频谱和功率效率。文献[20]提出了基于演示的优先级记忆深度Q学习来加速收敛和减少内存占用。文献[21]针对现有智能路由算法收敛速度慢、平均时延高、带宽利用率低等问题,提出了一种基于深度强化学习的多路径智能路由算法RDPG-Route。该算法采用循环确定性策略梯度作为训练框架,引入长短期记忆网络作为神经网络,相比于其他智能路由算法降低了平均端到端时延,提高了吞吐量,减少了丢包率。
路由算法大多基于固定的路由规则,面对未来无人机自组网复杂多变的网络环境,难以根据实时的网络状态与实际的应用场景需要,自适应地作出智能化的路由决策。现有基于强化学习的无人机路由解决方案中,大部分基于集中式的深度强化学习方法,使用具有集中式的智能体学习整个网络环境的状态,给网络中的每个节点发送对应的动作。一旦整个网络路由决策的控制中心受到干扰甚至瘫痪,就会严重影响整个网络路由的性能,这在无人机对抗场景中是十分致命的。
为解决上述问题,本文使用深度强化学习技术研究并设计一种分布式的符合无人机网络路由特性的联合路由方案,将无人机网络的机会路由问题建模为强化学习问题,包括系统模型的定义、状态空间、动作空间,以及奖励函数的设计,使得智能体根据当前状态选择最佳的动作,不断与网络环境进行交互,最终学习到一个保证路由性能、延长网络寿命的路由策略,并解决多智能体深度强化学习中维度过大以及多智能体之间相互影响的问题。仿真结果验证了本文算法的有效性。
1 网络建模
1.1 无人机自组网建模
无人机自组网中的网络节点在部署之后将自动组网。本文将具有N个节点的无人机自组网建模成一个连通图G=(V,E),其中的每一个顶点v⊆V对应一个无人机节点,每一条边e⊆E对应两个无人机节点之间的通信链路。数据包可在网络节点之间的无线链路发送,网络中每个节点既可以是源节点,也可以是目的节点。当源节点s⊆V向目的节点d⊆V发送大小为L的数据包p到达中继节点j时,如果j=d,说明数据包已经到达目的节点,数据包的路由过程结束;否则,数据包将被转发到由当前智能体节点学习的路由策略选择的下一跳邻居节点上。
在路由的过程中,由节点i发往下一跳节点j的数据包传输时间ti,j定义为数据包在节点i的队列中的等待时间和无线链路的转发时间之和,即
(1)
(1)式中,数据包在节点队列的等待时间wi为数据包进入节点队列到离开节点队列的时间差,无线链路的转发时间通过数据包的大小L和链路的最大传输速率Bi,j的比值来衡量。每个无人机节点具备一定的初始能量,当一个节点有数据包要发送或者排队时,就视为工作状态消耗能量;否则,节点处于休眠状态,即不消耗能量。使用ei表示节点i的剩余能量,为初始能量与消耗能量之差。当节点能量低于给定的阈值时,该节点被视为不活跃节点,并不可到达。能量为0时,删除该节点。
1.2 智能体状态设定
将无人机自组网的分布式路由问题建模为马尔可夫决策过程(Markov decision process,MDP)。MDP基于一组交互对象,即智能体和环境进行构建,所具有的要素包括状态、动作、策略和奖励。在模拟过程中,智能体感知当前状态,按策略对环境实施动作,从而改变环境状态并得到奖励,奖励随时间的累积被记作回报。由于本次研究的是分布式路由协议,因而将网络中每个无人机节点视为一个智能体,智能体根据网络环境的状态智能地作出决策,选择动作。马尔可夫决策过程通常情况由四元组(S,A,P,R)来定义,其中S是状态的有限集合,A是动作的有限集合,P是智能体在t时刻执行动作at后从状态st转移到状态st+1的转移概率,R是智能体在执行动作at之后获得的即时奖励,代表当前动作在当前意义上的好坏程度。本文采用无模型的强化学习方法,在状态转移概率矩阵P未知的前提下,也可以优化改进策略。下面给出状态空间、动作空间和奖励函数的详细定义。


奖励函数:奖励函数rt(st,at)指智能体在t时刻执行动作at后由状态st转移到状态st+1时环境给予智能体的即时奖励。本文提出一种分布式的奖励策略。一方面,奖励函数包括描述个体之间相互作用的局部奖励,即关于两个相邻节点之间的信息。另一方面,引入全局奖励来反映执行动作的质量,即数据包的传输方向。具体地,使用所有的数据包最终路径计算奖励,之后将奖励分配给路径中的每个智能体节点计算每个节点的价值,最后计算全局奖励。本文将数据包i最后一跳动作的即时奖励定义为
(2)
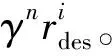
通过定义状态空间、动作空间以及奖励函数,可以将无人机自组网路由问题表述为MDP。智能体的目标是找到确定性的最佳策略π,使总累积奖励最大化。基于前述公式,可将基于深度强化学习的无人机组网路由问题定义为最大化未来累积奖励Gt=rdes+γrdes-1+γ2rdes-2+…,为了估计未来的累计奖励,将Q函数表示为累计未来奖励的期望,即
Qπ(st,at)=E[Gt|st=s,at=a]=
E[rdes+γrdes-1+γ2rdes-2+…|st=s,at=a],
∀st∈S
(3)
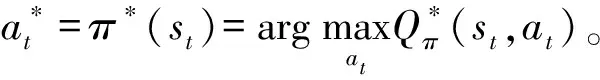
2 算法设计
2.1 方法选择
采用强化学习方法(Q-learning)需要把所有的Q值存放在Q表中,在大规模无人机协同网络中, Q表会异常庞大。无人机硬件的限制导致Q表进行数据存储和更新的效率低下,从而影响任务的执行效能。利用深度Q网络(deep Q-network, DQN)算法将基于强化学习的 Q-learning算法中的Q表更新过程转化为函数拟合问题,可以解决 Q-learning算法不适用于高维状态动作空间的问题。DQN算法如图1所示。
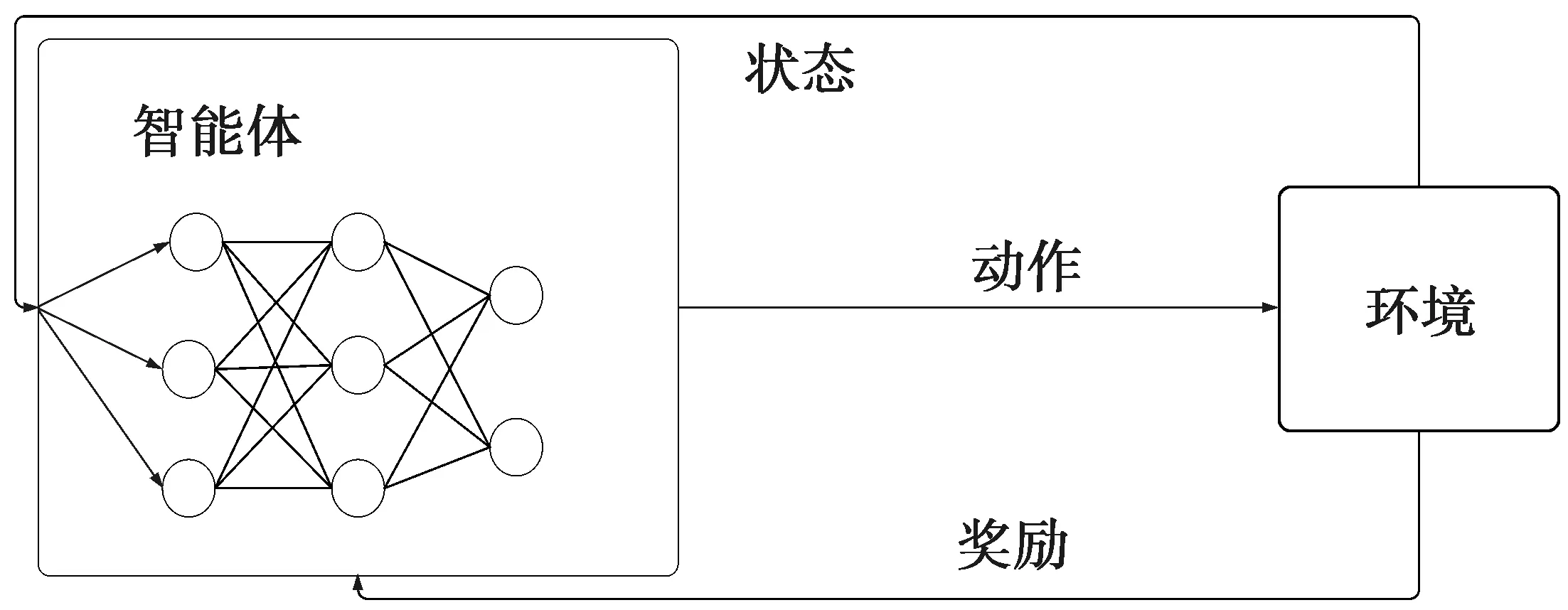
图1 DQN算法示意图Fig.1 DQN algorithm diagram
本文总体使用分布式设计,每一个无人机节点都可根据观测到的网络状态信息st,并根据ε-greedy原则选择动作at。以概率ε随机选择邻居节点作为下一跳,以概率1-ε选择Q值最大的邻居节点作为下一跳。之后智能体会获得奖励rt(st,at),并进入下一状态st+1。经验信息(st,at,rt,st+1)被存放在智能体的经验回放记忆单元。
2.2 方法结构描述
强化学习产生的数据样本之间是相互关联的,使智能体的训练难以收敛。随机采样经验回放记忆单元中的样本可以消除经验数据之间的相关性,还允许智能体使用新旧经验来进行训练,使得智能体的训练更加高效。在训练过程中,Q值将被改变,如果使用不断变化的值来更新Q网络,那么估计值会难以控制,导致算法不稳定。为了解决这个问题,使用一个目标神经网络来频繁但缓慢地更新训练神经网络的 Q值,显著降低目标值和估计值之间的相关性,从而稳定算法。智能体框架如图2所示。
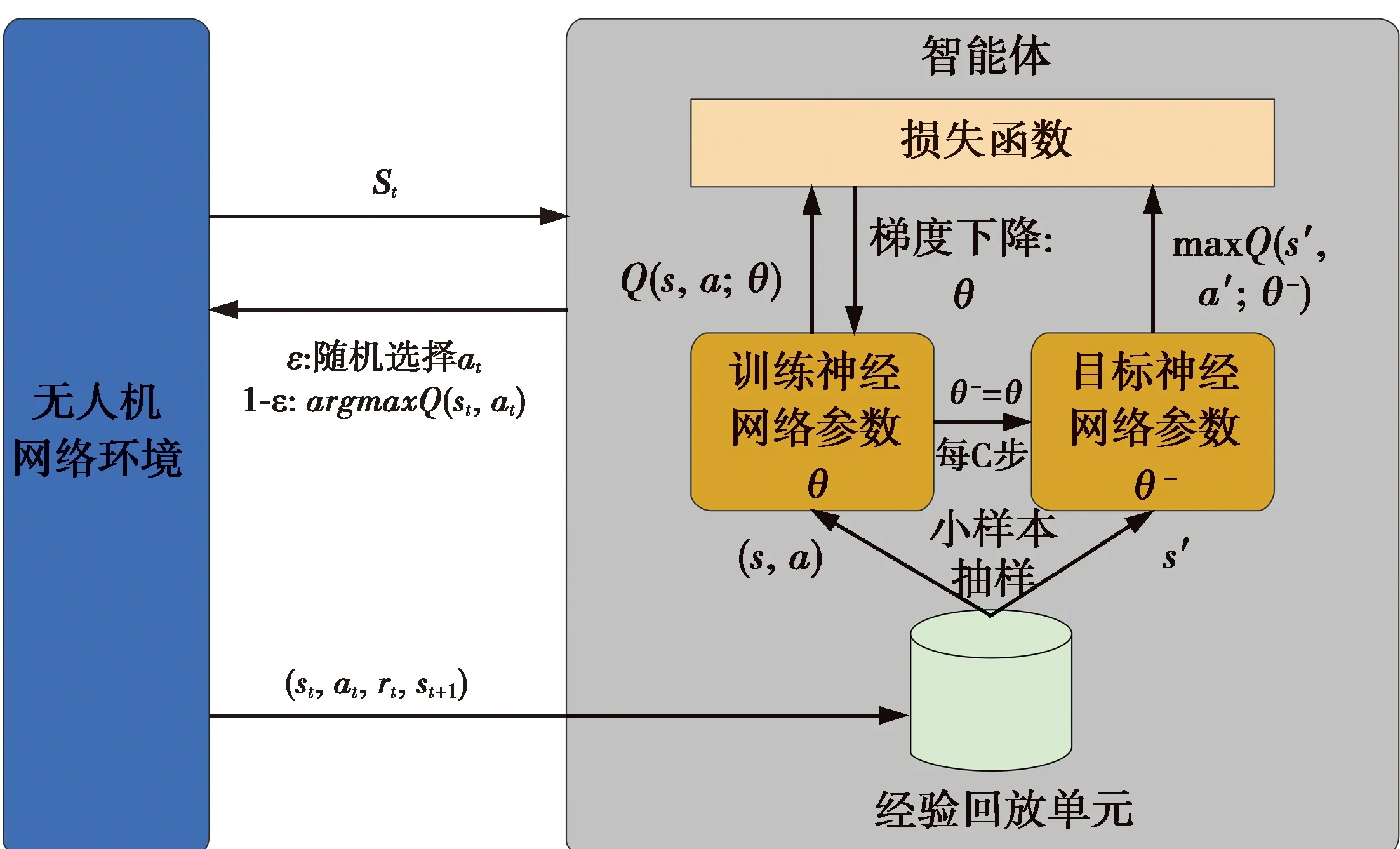
图2 智能体框架图Fig.2 Agent framework diagram
图3展示了DQN利用评估网络的Q估计值来近似真实Q值的模型形式。该模型包括:1个输入层、1个输出层和2个隐藏层。输入层由负责将信息发送到隐藏层的输入神经元组成。隐藏层负责将数据发送到输出层。每个神经元都有加权的输入、激活函数(在给定输入的前提下定义输出)和一个输出。

图3 智能体神经网络结构Fig.3 Agent neural network structure
令θ表示训练神经网络的参数,θ-表示目标神经网络的参数。神经网络的训练过程是最优化损失函数,即目标值和网络输出的估计值之间的偏差。DQN智能体最小化损失函数定义为
LDQN(θ)=E[(y-Q(s,a,θ))2]
(4)
y=r+γmaxQ(s′,a′,θ-)
(5)
(4)—(5)式中:Q(s,a,θ)是训练神经网络输出的估计值;y是目标神经网络计算的目标值。本文采用梯度下降法以学习率α更新训练神经网络的参数θ,即
∇LDQN(θ)=E[(y-Q(s,a,θ))∇Q(s,a,θ)]
(6)
θ←θ+α∇LDQN(θ)
(7)
通过将多步训练神经网络的参数复制到目标神经网络,以此更新目标神经网络的参数。该算法主要分为预训练和策略学习两个阶段。
算法初始化:初始化具有随机权重θ的训练神经网络和具有权重θ-的目标神经网络、经验回放记忆单元Dreplay、数据采样比例η和预训练的步骤k、收集数据并以(st,at,rt,st+1)的形式存储在演示数据缓冲区Ddemo中。
预训练阶段:首先,从演示数据缓冲区Ddemo中采样部分数据对智能体进行训练;其次,用目标神经网络计算损失函数LDQN;然后,用梯度下降法更新训练神经网络参数θ←θ+α∇LDQN(θ),每C步更新目标神经网络参数θ-=θ,循环k次。
策略学习阶段:智能体收集网络信息获得状态st,根据ε-greedy选择动作at,获得奖励rt,并进入下一状态st+1;将状态转移对(st,at,rt,st+1)作为经验数据被添加到经验回放记忆单元Dreplay中,再从演示数据Ddemo和回放记忆单元Dreplay随机采样训练智能体,之后使用目标神经网络计算损失函数;最后,使用梯度下降方法更新训练神网络参数,每C步更新目标神经网络参数θ-=θ,这个过程一直循环到训练结束。
3 仿真分析
3.1 仿真流程及参数设置
本文仿真使用Python3.6编写事件驱动模拟器的代码,以Pytorch作为深度学习框架来实现基于DQN的路由算法,并基于NetworkX来搭建无人机组网网络环境。
为评估算法在实际无人机组网下的性能,需要在具有自定义数量节点的无人机网络上重复进行训练。为了契合无人机集群作战的实际场景,设定每个节点都有随机数量的邻居节点,并且随时有可能脱离邻居节点的有效通信范围。初始化每个节点的队列长度、发送队列长度,以及节点之间的无线链路数据传输速率、数据包大小;设定最大寿命为节点总数的一半,每个数据包的源节点和目的节点随机生成。具体的参数设置如表1所示,仿真流程如图4所示。

表1 仿真参数设置

图4 仿真流程图Fig.4 Simulation flow chart
典型的无人机自组网场景如图5所示。假定任务区域内的无人机数量为50—110 架,每一架无人机被视为一个网络节点和智能体,都能够根据实时的网络状态和学习到的最优策略发送和接收数据包,且网络拓扑高度动态,链路会随机断裂与恢复。

图5 任务场景Fig.5 Task scenario
仿真开始后,系统创建一个模拟数据包路由的过程,在一系列时间步长上离散更新。在仿真的一个回合中,链路随机断裂,并在每个时间步长随机恢复。此外,链路权重以近似正弦方式波动。回合开始时,网络上会生成许多数据包,每个数据包都有一个随机的源节点和目标节点。每发送完成一个数据包,即有一个新的数据包在若干时间步长后初始化。一旦在网络上生成并成功传递了一定数量的数据包,当前回合就结束了。仿真要求路由过程根据一种路由算法确定每个数据包的路径。本文通过Dijkstra算法探索最短路径,采用各种奖励函数探索分布式Q学习以及深度Q学习。
3.2 仿真结果
图6给出了在50个节点、训练个回合下数据包传输时间的收敛性能情况,该场景考虑了每一个回合下的传输性能。从图6可以看出,随着训练的进行,数据包平均传输时间在0—500 个回合中快速下降,在1 000个回合后逐渐平稳趋于收敛,从而验证了本文算法具有很好的收敛性能。

图6 传输时间收敛性能Fig.6 Transmission time convergence performance
图7展示了端到端传输时延对比情况。由图7可见,本文算法随着节点数量的增加时延缓慢上升,与AODV协议以及Q-Routing的时延差距显著,表明本文算法更适用于大规模无人机集群场景。
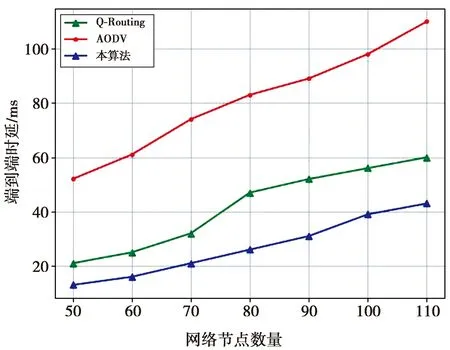
图7 不同算法端到端时延对比Fig.7 Algorithm end-to-end delay comparison
图8为控制开销对比。从图8可以看出,基于本文算法的路由协议具有较小的控制开销,而AODV路由协议控制开销较大,从而使得网络中发送的控制消息较多。本文算法能在相同情况下减少控制消息发送的大小,从而提升了网络的性能。

图8 控制开销对比Fig.8 Control overhead comparison
图9给出了在50个节点、不同算法最大队列长度对比。从图9可以看出,AODV协议的最大队列长度在140左右浮动,而本算法的最大队列长度随着数据包数量的增大,从40逐步上升到140。网络数据包排队长度越大,说明网络拥塞程度越高。当数据包数量越来越多,算法性能也会逐渐下降。在数据包4 000—5 000区域内,各算法波动较小,已达到各算法的较大性能。
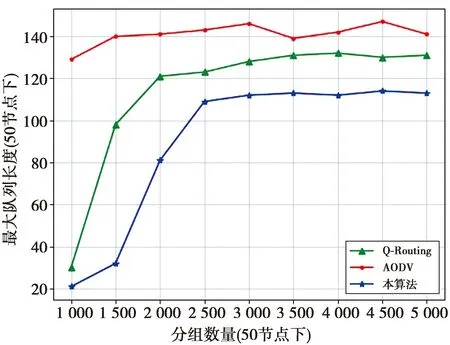
图9 最大队列长度对比Fig.9 Maximum queue length comparison
图10给出了不同算法的平均传输时间对比。从图10可以看出,本文的算法具有较低的平均传输时间,并且增长幅度较为平稳;最短路径算法的传输时间较长,并且随着数据包数量的增多,传输时间的增长幅度也会变大。这印证了本文算法具有更优异传输性能的结论。

图10 平均传输时间(步)对比Fig.10 Average delivery time(step) comparison
图11展示了不同业务量大小的满负载节点占比大小的对比。从图11可以看出,本文算法在相同业务量下满负载节点(拥塞节点)所占比例明显更低。拥塞节点比例越高,说明网络的拥塞程度越高,从而导致网络更易拥塞降低用户服务质量。因此,也证明了本文算法拥有较好的网络传输性能。

图11 拥塞节点比例对比Fig.11 Percent of working nodes at capacity comparison
综上所述,本文算法在端到端传输时延、控制开销、拥塞性能方面均优于AODV路由协议以及Q-Routing。这是因为本文算法利用深度强化学习感知学习无人机节点移动性、链路连接特性、网络拓扑动态变化,无人机节点通过不断地与环境进行交互,探索学习最优行动(路由)策略,根据学习结果找到满足要求的路由,并能通过存储的经验知识,维护端到端路由,赋予无人机网络智能化重构和快速修复的能力,提高路径的稳定度,降低路由建立和维护开销,增强网络的鲁棒性。
4 结 论
国内外关于无人机自组网路由协议的研究表明,深度强化学习是提高无线网络性能的一个很有前途的方式。目前关于无人机自组网和深度强化学习的研究大多是独立进行的,无法充分利用强化学习技术的学习能力来自适应地优化网络路由,这极大地限制了深度强化学习技术改善无人机网络性能的潜力。为了体现深度强化学习技术在无人机自组织网络中的优势,进一步提高无人机网络的智能化程度,满足未来无人机网络发展与实战化的需求,本文提出了一种基于深度强化学习的分布式无人机自组网高效路由算法。该算法能够通过训练网络中每一个网络节点来学习路由策略,使用了更适用于大规模无人机组网的DQN算法,摒弃了传统集中式训练的思想,可显著增强网络的鲁棒性,减少数据包的传输时间与跳数,减少丢包率,同时有效地平衡能耗与网络负载以延长网络寿命。此外,本文算法解决了多智能体强化学习的学习速度慢、多智能体间相互影响及动作维度爆炸等问题,更加适用于未来无人机集群作战的场景。
猜你喜欢
电子制作(2019年19期)2019-11-23
网络安全和信息化(2018年4期)2018-11-09
网络安全和信息化(2018年3期)2018-11-07
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
电测与仪表(2014年16期)2014-04-22
计算机工程(2014年6期)2014-02-28
河南科技(2014年5期)2014-02-27
深圳信息职业技术学院学报(2013年3期)2013-08-22
