
一种无先验地图的移动机器人导航方法
2023-05-05 03:01刘想德
重庆邮电大学学报(自然科学版) 2023年2期
刘想德,宋 泽,张 毅,郑 凯
(重庆邮电大学 先进制造工程学院,重庆 400065)
0 引 言
移动机器人在人类活动场景中广泛使用,其在未知复杂场景中的自主导航能力需要提高。随着人工智能、机器学习算法在机器人领域的应用,研究人员开始采用深度强化学习算法解决机器人在未知环境中的导航问题[1-2]。
文献[3]结合船舶在实际航行中的环境模型,提出了一种基于深度Q网络(deep Q network, DQN)算法的沿海船舶路径规划模型,然而,该模型规划出的路径存在较多路径角,且输出的动作为离散动作,在动态环境中容易与障碍物发生碰撞。文献[4]使用异步深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法,通过输入10维稀疏激光测量信息和目标的相对位置,使智能体能够学习连续控制动作,但由于该模型中的奖励函数较为“稀疏”,导致导航模型训练速度较慢,且当机器人处于障碍物较多的环境时,机器人导航鲁棒性较差。文献[5]提出的异步学习算法,通过增加好奇心驱动策略,训练后的机器人在未知环境中具有更好的泛化能力,但没有在复杂环境进行导航测试。文献[6]针对机器人在复杂场景的导航问题,将卷积神经网络与近端策略优化(proximal policy optimization,PPO)算法相结合,提高了机器人在复杂场景下的探索能力,但其输出为离散动作,在复杂场景中灵活性较低。
基于上述分析,本文采用DDPG算法,在奖励函数中引入人工势场,设计出高“密度”的奖励函数;并设计了基于Actor-Critic的网络结构,以提高模型的导航泛化能力。
1 算法框架
本文提出的导航算法框架如图1所示。算法将激光雷达的测距信息、机器人上一时刻的动作(包括角速度和线速度)和目标点的位置作为模型的输入,输出为连续动作。图1中,虚线部分表示导航模型根据机器人当前所处的状态计算奖励回报的过程。
为方便导航模型对输入信息进行处理,将模型输入信息进行预处理:①将激光雷达测距信息抽象为(-90°,+90°)范围的9个均匀间隔的扇形区域,可降低机器人周围环境噪声对模型训练和导航的影响,减少模型对环境信息处理的计算量;②将机器人线速度限制在0~1 m/s,角速度限制在-1~1 rad/s;③用距离和角度来表征导航目标点相对机器人的位置。
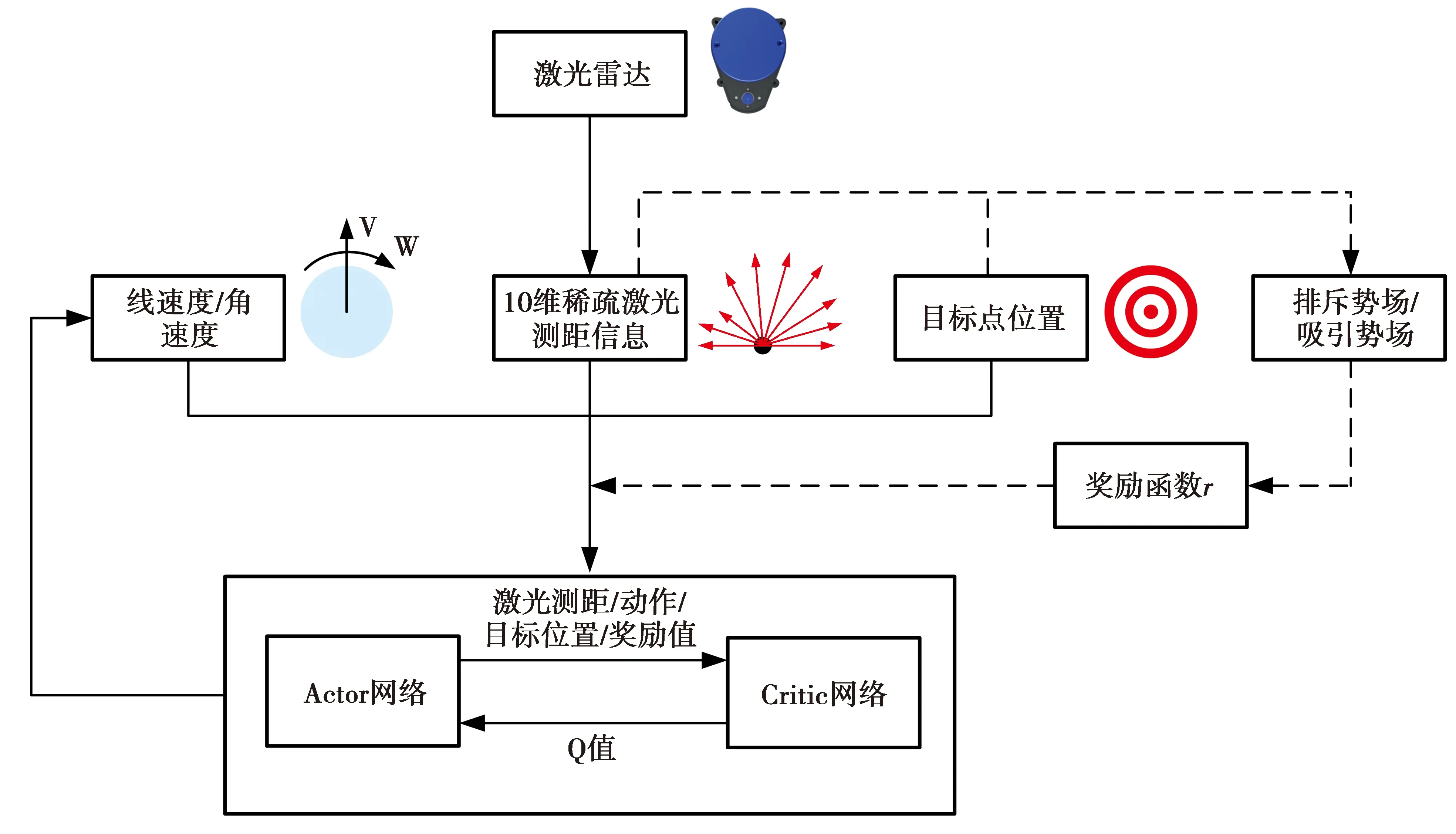
图1 算法框架结构Fig.1 Algorithm framework
2 无先验地图的导航模型
2.1 数学模型
由于移动机器人搭载的是2D激光雷达,该传感器只能感知到部分环境状态,因此,将移动机器人的无先验地图导航表述为部分可观察的马尔科夫决策过程。该过程描述的是在某一时间、处于某一状态的机器人执行一个动作达到下一个状态,并从模型中得到一个奖励回报的过程[7],其数学模型可以通过7元数组
(1)
策略π的随机性使得计算的累计折扣奖励也是随机的,而累计折扣奖励的期望是一个确定值。在强化学习中,常用动作-值函数预测当前状态下累计折扣奖励的期望,机器人的探索目标是将每个状态的动作-值函数最大化[8]。动作-值函数Qπ(s,a)表示根据策略π在环境状态st下采取动作a后的期望回报,表示为
(2)
当机器人的状态空间维数较大时,传统的强化学习算法难以估计动作-值函数。在深度强化学习中,可以利用深度学习对动作-值函数进行预测估计,进而学习Q值最大的行为策略。
2.2 奖励函数
奖励函数可分为4部分:到达奖励ra、碰撞奖励rc、时间奖励rt和势场奖励rp,前3部分皆设为固定值,到达奖励为正奖励,碰撞奖励和时间奖励均为负奖励。奖励函数可表示为
(3)
(3)式中,d为机器人移动距离。当机器人达到距离目标点dtarget范围内可视为达到目标点,获得+20的正奖励,将dtarget设为0.2 m;当机器人距离障碍物范围dcollision内则表示机器人与障碍物发生碰撞,碰撞获得-1的负奖励,将dcollision设置为0.1 m;step表示机器人在每一幕的探索步数,当机器人探索步数达到最大步数时,获得-1的负奖励。
机器人从初始位置到目标点的探索过程中,为了鼓励机器人向目标点靠近并且避开障碍物,在奖励函数中引入人工势场,设计出势场奖励函数,势场奖励函数受吸引势场和排斥势场的影响。吸引势场由目标点和机器人位置决定,机器人距离目标点位置越远,所受的吸引势场越大[9]。吸引势场Uatt定义为
Uatt=kρg=k||Pr-Pg||2
(4)
(4)式中:k为引力势场正比例增益系数,设置为0.5;ρg表示机器人当前位置与目标点的欧氏距离。
机器人距离障碍物越近,排斥势场越大。考虑到障碍物只在一定范围对机器人产生影响,为减轻计算量,超过该影响范围后障碍物对机器人的影响忽略不计。机器人在障碍物附近的感知示意图如图2所示。

图2 机器人在障碍物附近感知示意图Fig.2 Schematic diagram of robot perception near obstacles
图2中,中心的黑色圆形表示机器人,虚线表示障碍物对机器人的影响范围,边缘处的圆形和正方形代表不同的障碍物。
传统的排斥势场只考虑了障碍物对机器人的影响,当机器人的目标点附近存在障碍物时,机器人所受到的排斥影响将占主导地位,使得机器人靠近目标点会获得较大的负奖励值,导致算法难以收敛[10-12]。本文在排斥势场的设计中,引入目标距离因子,保证目标点附近引力势场占主导地位,当靠近目标点时获得正的奖励值,引导机器人向目标点靠近,同时避开周围障碍物。排斥势场定义为
(5)
(5)式中:m为斥力势场距离增益系数,设置为0.05;di为激光的测距距离;d0为常数,表示障碍物产生的排斥势场对机器人产生影响的距离界限,将d0设置为1 m;N为当前时刻在障碍物影响范围内激光雷达感知到的障碍物激光线束数量;n为(0,1)的系数。当机器人靠近障碍物附近的目标点时,排斥势场逐渐减小并趋近于0,保证了机器人靠近目标点时吸引势场影响的奖励函数占主导地位。当计算出吸引势场和排斥势场后,通过构造塑性奖励函数计算t时刻的势场奖励,计算式为
Ut=Uatt+Urep
(6)
rp=Ut-1-Ut
(7)
2.3 网络结构
本文DDPG算法的Actor网络和Critic网络采用全连接神经网络,每个神经网络有3个隐藏层,每一层具有512个节点,每个隐藏单元采用ReLU激活函数,网络结构如图3所示。Actor网络需要输出机器人的线速度和角速度,为了将线速度限制在0~1 m/s,线速度输出层采用Sigmoid激活函数,此外,为获得-1~1 rad/s的角速度,角速度的输出层激活函数采用Tanh函数。Actor网络结构见图3a。Critic网络输出对状态和动作预测的Q值,输出层通过线性激活函数激活,其网络结构见图3b。
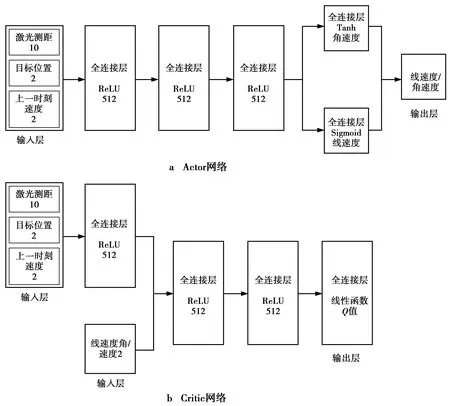
图3 网络结构Fig.3 Architecture of the network
3 试验与分析
机器人在真实环境中通过试错来探索最优策略代价大,因此,需要借助虚拟环境完成模型的训练。由于Gazebo平台具有强大的三维仿真环境且支持传感器数据,故选择Gazebo作为仿真试验平台,利用该试验平台创建虚拟环境,完成导航模型的训练和导航性能的评估。本文选择Turtlebot3 Burger作为机器人模型。试验所采用的服务器配置为:CPU为Intel的酷睿i7-10875H,GPU型号为GeForce RTX2080Ti,操作系统为ubuntu16.04。
3.1 在虚拟环境中的导航策略训练
在Gazebo仿真环境中,构建一个8 m×8 m的封闭室内环境作为导航模型的训练环境,并随机放置3个障碍物,模型训练的仿真室内环境如图4所示。图4中绿色部分为设置的障碍物,红色部分为导航目标点。在每一幕的训练过程中,机器人的初始点设置在封闭环境的中心位置,导航目标点随机分布。当机器人满足以下条件之一便结束一幕的训练过程:①到达目标点;②机器人与障碍物发生碰撞;③该过程探索步数达到最大探索步数。
机器人搭载的激光雷达型号为HLS-LFCD2,其最大测距范围为3.5 m,本文提取(-90°,+90°)等角度的10个激光测距数据作为模型的输入。在机器人定位方面,本文选择较为成熟的AMCL算法作为机器人的定位算法。考虑到机器人的活动能力以及过大的速度变化会对算法收敛性产生一定影响,训练过程中,将机器人最大线速度设为0.25 m/s,角速度限制在-0.5~0.5 rad/s,其余超参数如表1所示。

图4 模型训练时的虚拟环境Fig.4 Virtual environment during model training
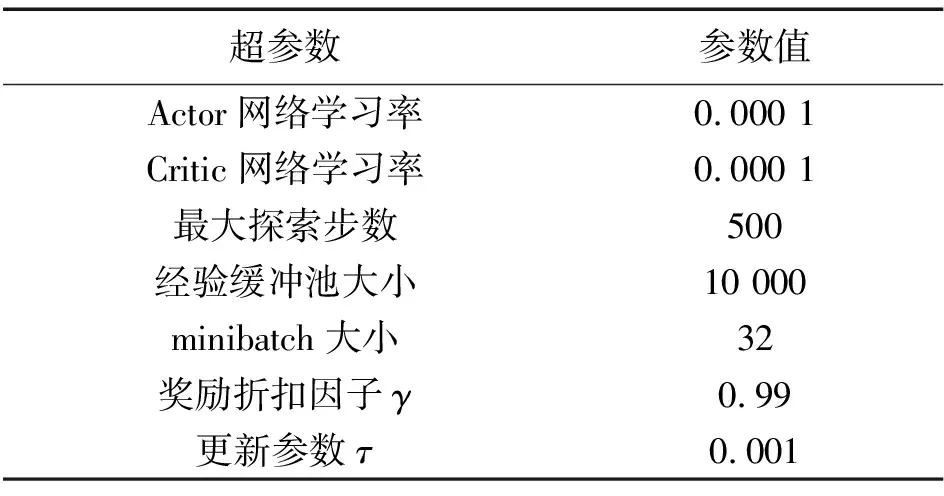
表1 参数设置表
3.2 试验评估
本文分别对模型的训练过程和模型训练完成后机器人的导航性能进行评估,将导航模型分别与文献[9]的导航模型(以下简称模型1)进行对比验证。同时,为验证排斥势场奖励函数中的目标距离因子在导航策略优化的有效性,设置一组在排斥势场奖励函数中不含目标距离因子的奖励函数导航模型(以下简称模型2)作为对比试验。模型1在设置奖励函数时只考虑了机器人与目标点距离的影响因素,没有考虑机器人靠近障碍物的情况,其探索过程的奖励函数类似于本文的吸引势场奖励函数,所使用的超参数和网络结构与本文的导航模型相同。模型2与本文提出的模型相比,在排斥势场奖励函数中,没有将目标距离因子包含在内。
3.2.1 算法训练过程的评估
在算法训练过程中,本文分别对机器人获得的奖励值和导航成功率进行对比。本文模型、模型1和模型2的奖励值和导航成功率如图5所示。由图5可以看出,本文模型奖励值曲线大约在800幕开始收敛,导航成功率超过80%且保持稳定;模型1约在1 050幕导航成功率达到80%;模型2大约在1 000幕奖励值开始收敛,导航成功率趋于稳定。由此可见,本文模型相对模型1和模型2训练速度更快,导航成功率更高。相比于本文模型和模型2,模型1在设计奖励函数时没有考虑障碍物对导航的影响,在模型训练过程中,机器人与障碍物发生碰撞的频率更高,导致模型的训练速度较慢、导航成功率更低。与模型2相比,本文设计的排斥势场奖励函数考虑了障碍物附近存在目标点的情况,引入了目标距离因子来降低障碍物对导航的影响,能够加快模型的训练速度。然而,由于导航目标点随机分布,可能导致目标点与障碍物位置冲突,造成机器人无法到达目标点,使训练过程的导航成功率受到一定限制。

图5 奖励值和导航成功率随幕数的变化曲线Fig.5 Curve of the reward value and success rate of navigation change with the number of episode
3.2.2 仿真实验
为了验证所提出的导航模型的泛化性,利用Gazebo分别创建一个障碍物密度相对较低的场景1和一个障碍物分布更密集的场景2,两个场景均为10 m×10 m的封闭室内环境,分别如图6所示。
在相同的训练环境条件下,取1 000幕作为算法训练的终止条件。导航初始点设置在左上角,右下角分别设置4个不同的目标点,且目标点靠近障碍物。两个场景的初始点位置和导航目标点位置均相同。根据起始点和目标点的位置分别对本文的导航模型、模型1与模型2在场景1和场景2进行测试,其路径规划结果示意图分别如图7和图8所示,其中,轨迹的黑色部分为人工干预导航段。

图6 实验验证的仿真环境Fig.6 Simulation environment of experimental verification

图7 机器人在场景1中的轨迹示意图Fig.7 Trajectory diagram of a robot in scenario 1
本文采用3个参数(成功达到目标点的次数,导航路径的平均长度,导航的平均时间)分别来衡量导航成功率、路径规划的性能以及导航时间,实验结果的评估数据如表2所示。
在场景1中,3种导航模型均能成功达到目标点,本文模型所规划的平均路径长度和平均导航时间分别为11.18 m和52 s,相比于另两种导航模型,其所规划的平均路径长度和导航时间更短,导航性能较好。本文模型和模型2的导航策略相对较为激进,而模型1的导航策略相对较为保守,更偏向远离障碍物,所规划的路径长度相对更远。在障碍物分布较密的场景2中,本文模型均能成功地完成导航任务;模型1在4次导航任务中,有3次出现碰撞的情况,需要人为干预完成导航任务,且规划的路径更为曲折;模型2虽然出现了一次碰撞的情况,但碰撞到障碍物的次数低于模型1。相比于模型1和模型2,本文模型规划的平均路径长度和导航时间更短,导航适应性能较好。实验表明,在设计奖励函数时考虑障碍物对导航的影响能够使模型具有更好的导航策略。同时,实验也验证了排斥势场奖励函数的目标距离因子在导航策略优化中的有效性。因此,在无先验地图的情况下, 本文模型在障碍物密度相对较低和障碍物分布密集的环境均有较好的导航性能,导航泛化性较好。

图8 机器人在场景2中的轨迹示意图Fig.8 Trajectory diagram of a robot in scenario 2

表2 仿真实验评估
4 结束语
本文提出了一种基于DDPG的移动机器人无先验地图导航模型,将2D激光雷达测距信息、机器人动作以及目标点位置作为模型的输入,经过训练后,可实现移动机器人的自主探索及导航;通过构造一种新的奖励函数优化机器人导航策略,克服了稀疏奖励函数导致的机器人“试错”次数增加的问题,能够更好地引导机器人避开障碍物,向目标点靠近。针对机器人在实际环境中的导航情况,设计出了一种基于Actor-Critic的网络结构,在模拟的简单场景和复杂场景中对模型的收敛速度和导航性能进行验证,并与主流的无先验地图导航模型进行比较。实验结果表明,本文提出的导航模型具有更快的训练速度、较好的导航性能和泛化性。
猜你喜欢
北京航空航天大学学报(2021年4期)2021-11-24
高技术通讯(2021年5期)2021-07-16
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
石油地球物理勘探(2017年4期)2017-12-18
系统工程与电子技术(2016年4期)2016-08-24
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
城市道桥与防洪(2014年5期)2014-02-27
