
基于GloVe-CNN算法的英语在线考试主观题自动评分模型
2023-07-08 07:26黎秋艳刘佳祎
桂林理工大学学报 2023年1期
黎秋艳,刘佳祎,王 鹏,王 杰
(1.桂林电子科技大学 信息科技学院,广西 桂林 541004;2.桂林理工大学 网络与信息中心,广西 桂林 541006;3.广西师范大学 网络信息中心,广西 桂林 541006)
0 引 言
随着高校外语教育信息化的不断普及, 智能化在线考试正逐渐成为高校教学、 管理过程中的不可或缺的重要组成部分, 考试方式的改革也伴随着出现新的问题需要解决, 特别是英语在线考试主观题自动评分已经成为当前外语教育信息化比较关注的主题。相比选择题而言, 主观题或开放式考题答案相对复杂, 其具有形式多样性和灵活多变性, 如翻译和写作等主观题大多采用人工批改的方式, 由于多种因素的干扰, 使得评分不够公正、 准确[1]。
国外较为经典的自动评分系统有1966 年美国Ellis Page 等开发的Project Essay Grader(PEG)[2]、 皮尔逊公司1989 年开发的Intelligent Essay Assessor(IEA)[3]和Jill Burstein团队研究开发的Electronic Essay Rater(E-Rater)系统[4]等。国内梁茂成教授是最早涉足英文作文自动评分领域的, 他将PEG和 IEA 两个系统的优点相结合, 主持并开发“大规模考试英语作文自动评分系统”[5]。主观题的自动评分方法主要可以分为以下几类[6]: 一是参照标准答案利用规则匹配的方式建立评分规则[7], 通过词规则进行自动评分。二是将人工构建的特征和监督机器学习算法相结合, 这种方法称为传统机器学习的方法, 其优点是模型简单易懂, 但是需要手动构建特征向量, 且评分效果受特征选择的影响较大。2006 年, Hinton提出了深度学习的概念[8], 通过模拟人类大脑的神经连接方法, 构建深度神经网络模型, 从众多数据内容中自动学习、 提取特征, 且评分效果较好, 但是需要大量的训练数据和计算资源。三是基于深度神经网络的学习方法, 基于深度学习的文本特征表示技术受到很多学者青睐, 它可以更好地将文本语义表示出来, 主要用到Word2Vec[9]、 Doc2Vec[10]、 GloVe[11]等向量技术。徐庆婷等[12]提出了综合语义技术与 LSTM 神经网络方法, 龚云[13]提出将孪生神经网络和增强的顺序推理模型相结合的方法, 潘婷婷等[14]提出了基于混合语义空间的汉译英自动评分模型, 可以有效提高主观题智能评卷的灵活性和准确性。随着技术的不断创新, 学者们在自然语言处理领域有了新的发现。基于自然语言处理的评分模型是通过对文本进行语义分析来评分, 但是需要大量语料库和语言知识库的支持。除ETS公司的E-Rater[15]之外, 还有很多的主观题自动评估软件, 通常是采用自然语言处理常用的LSI[16]和LDA[17]方式提取语义等特征。钱升华等[18]则提出利用自然语言预处理BERT模型进而得到语句向量。
综上, 针对主观题自动评分模型的研究是非常丰富和多样化的, 不同的方法各有优缺点, 对于简答题、 名词解释等主观题的评阅取得了一定的研究成果。分数的高低主要取决于考生的答案与实际参考答案的文本语义相似度大小, 即两者的语义相似度的值越高, 获得的评分就会越高。由于大多数主观题答案无法用确定的语言来表达, 即答案并不唯一, 而主观题自动评分模型的评分标准往往是固定的, 无法根据不同的评分标准进行自适应调整, 导致主观题自动评分模型评分准确度受到部分影响。本文着重探索文本相似度的计算方法以及文本特征提取等内容, 通过global vector全局词频统计的词向量表示工具对文本语义进行词向量化, 结合卷积神经网络(CNN)提取文本表达式特征, 经过卷积层和池化层、 全连接层进行相似度计算, 提出基于GloVe-CNN算法的主观题自动评阅模型, 并以广西某高校英语考试主观题为例, 对模型进行实际测试, 验证模型准确性, 助力地方高校教育人工智能化和在线考试系统。
1 主观题自动评分模型的设计
1.1 主观题自动评分处理模型
基于GloVe-CNN算法的主观题自动评阅模型处理过程如图1所示。
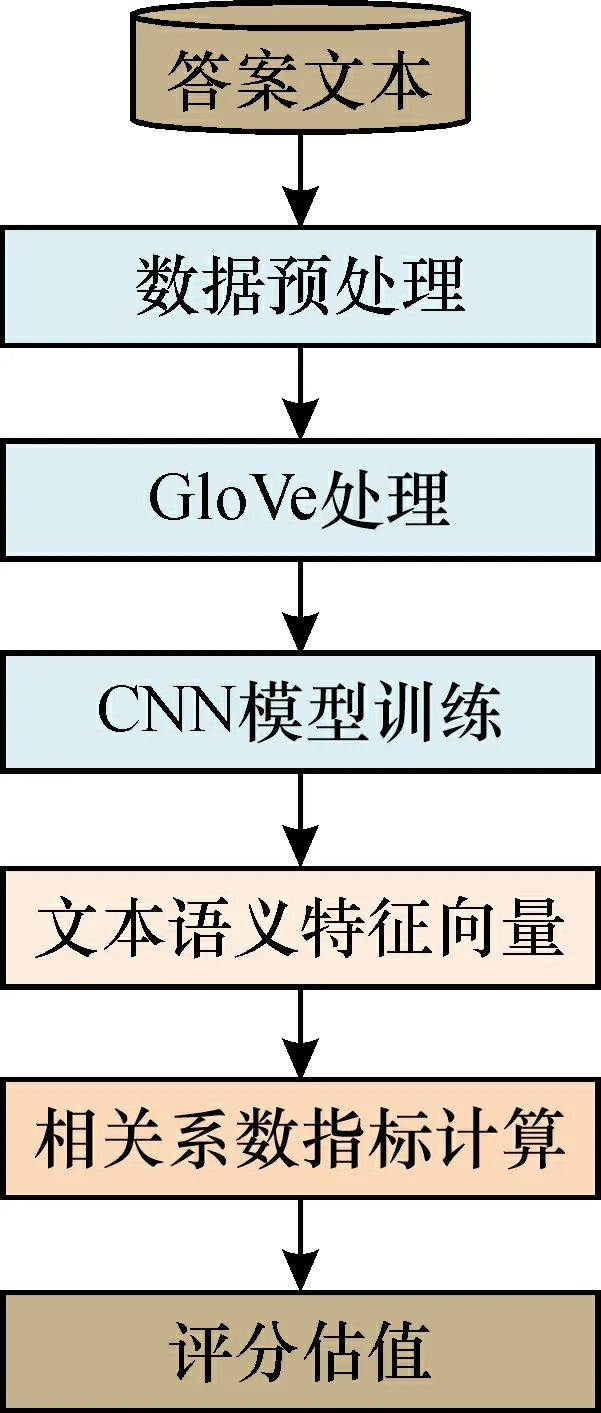
图1 GloVe-CNN模型处理过程Fig.1 Process of GloVe-CNN algorithm
① 数据预处理。首先对考生答案和参考答案原始文件资料分别进行手写文本识别及数据的预处理工作, 将文本的词特征最大化保留, 消除特殊符号、 乱码、 停用词等无关因素以及重复出现的词。
② 词向量构建。作为主流的词嵌入GloVe模型继承了Word2Vec的绝大部分优点, 是一种无监督技术, 使用全局统计信息、 全局先验信息以及共现窗口的优势, 使得在近义词、 多义词的处理上更具有优势, 能确保词向量之间尽可能多地蕴含语义、 语法等相关信息。因此, 本文采用GloVe变换词向量功能, 将一个单词表达成一个由实数组成的词向量矩阵, 分别对考生答案和参考答案作文本特征进行词向量化描述, 再利用所获得的词向量建立映射矩阵, 作为下一层的输入。
③ 文本语义特征提取。在完成词向量的矩阵映射后, 将其作为数据输入传送到CNN模型中进行语句特征的提取[19], 并作池化处理, 防止过拟合, 降低数据维度, 最后得到考生答案和参考答案的语义特征向量。通过深度学习训练, 得到含有上下文信息的词向量, 使得文本表示的层次更加丰富。
④ 相似性分析。将参考答案特性矢量和考生回答语义特性矢量进行拼接, 通过全连接层比较分析, 再传递相关系数给系统分析并测量其相似性值。
⑤ 结果输出。将第④步得到的相似性数值通过归一化计算, 确定答案文本的分数。
1.2 GloVe词向量构建
GloVe模型是由Pennington等在2014年提出[20], 是一个基于词共现矩阵理论的词向量模式, 它将单词表示为由实数组成的向量, 用于捕捉词与词之间的语义特性, 如相似性(similarity)、 类比性(analogy)等。在使用上下文信息的同时, 也采用矩阵分解方式, 实现词共现信息, 具体模型如图2所示[21]。
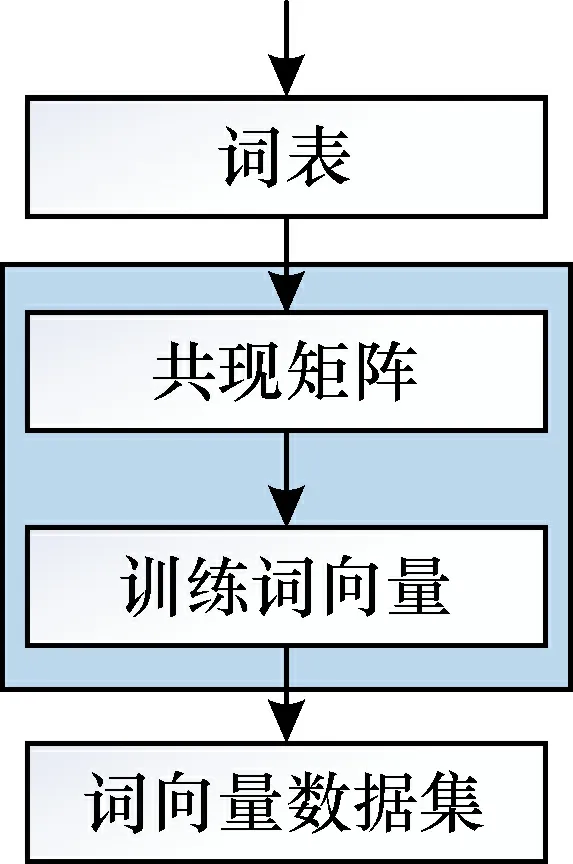
图2 GloVe模型Fig.2 GloVe model
GloVe模型主要是将每一个word向量作为参数, 词向量之间满足相关性。假设wi,wj,wk为词向量, 则通过F(wi,wj,wk)函数可以得到式(1), 即在单词i、j出现的两个语境范围内, 单词k出现概率的比值满足相关性, 其中Pk/i、Pk/j分别表示单词i、j出现语境范围内单词k出现的概率。
(1)
当F值很大时, 表明单词k与i相关, 与单词j不相关; 当F值很小时, 则表明单词k与i不相关, 与单词j相关; 当F值趋近1时, 且两个概率值都在较大时, 则表明单词k与单词i、j均相关; 当F值趋近1时, 且两个概率值都在较小时, 则表明单词k与单词i、j均不相关。
GloVe模型利用迭代法的梯度下降方式, 将文本中的单词进行向量表示, 损失函数J可表示为
(2)
其中:wi和wj是所要求的词向量;bi、bj分别为两个词向量的偏置项;V是词汇表的大小;X为共现矩阵;Xi, j表示词汇i、j共同出现在一起的次数;f(Xi, j)是一个权重函数, 其作用是降低高频词对模型的干扰, 可印证不同共现次数Xi, j对结果的影响[22-23]。如果i、j两个单词没有出现一起, 则Xi, j=0, 那么它们将不会参与计算,故f(0)=0。
1.3 语义特征提取
在完成词向量的矩阵映射后, 将其作为数据输入传送到具有多个卷积层和池化层的多层卷积神经网络[24]模型中以叠加的方式提取语义特征。通过卷积层中的卷积核的窗口大小进行卷积运算, 进而得到特征图, 具体公式为
(3)
其中: (a,b)表示特征图位置;Pt(a,b)表示输出第t个卷积运算结果;X表示输入矩阵;Kt(m,n)为第t个卷积核矩阵, 核矩阵形状为m×n;dim表示词向量的长度。
随后, 将输出结果传送到池化层, 为了降低信息冗余、 提高重要特征提取能力、 防止过拟合, 利用最大池化法在每个特征图中提取的最大值作为卷积层在该向量中提取到的最终的也是最重要的特征输出, 最大池化法公式为
Lt=max(Pt(a,b)),
(4)
其中,Lt表示第t个池化运算后的最终输出结果。
1.4 相似性分析
当GloVe-CNN模型分别提取到两个语义的特征后, 把两个句子的特征通过全连接层进行拼接, 传递相关系数, 通过分析比较、 测量其相似度。目前有多种计算距离的方法, 不同的方法对结果的准确性影响不同, 在自然语言处理领域中, 最常用的相似度计算模型是向量空间模型(VSM), 在向量空间模型中, 可以得到每个文本的词向量, 将词向量视为空间状态下的两条方向不同的线段, 两者会形成一个夹角, 通过计算夹角的余弦值衡量文本间的相似度, 即计算余弦相似度[25]。如两向量指向相同, 则余弦相似度越接近1, 表明两向量夹角越小, 也就意味着用词越相似。在不涉及上下文的情况下, 默认这两个文本的内容最相似。
采用余弦相似度来计算池化层输出的两个向量的夹角余弦值判断两个向量是否在相同方向, 进而评估两者的相似性。假设Ai和Bi分别代表向量A和向量B的各分量, 其余弦相似度为
(5)
1.5 模型训练
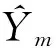
(6)
其中,n为样本总数。
2 主观题自动评分系统验证
2.1 实验环境
硬件方面: Windows 10专业版、 CPU Inter(R)Core(TM) i7、 内存16 GB; 软件方面: 依赖库Python 3.8、 Jupyter Notebook、 Tensorflow、 Sklearn 等。
2.2 数据来源
使用人工录入学生答卷、 参考答案和教师打分与试卷总分, 来完成数据集的收集工作。将预先训练好的GloVe词向量作为数据的输入端, 然后以GloVe-CNN模型基础再次进行训练, 模型训练共迭代 15 000 次, 每次训练大约25 min。实验数据为广西某大学英语考试卷简答题, 随机选取5 400个样本, 内容主要涉及学生答卷、 参考答案、 教师评分和所有试题的总分等方面。将其文字数据保存为*.csv格式, 并分成4列数据块进行存储, 依次为学生编号、 学生答卷和参考答案、 教师评分、 教师评分与系统评分的差值(文本相似度), 并以6∶2∶2的比例将数据分为用以训练模型参数的训练集、 选择表现最优参数的验证集和样本测试的检测集3个部分, 训练集和检测集详见表1。
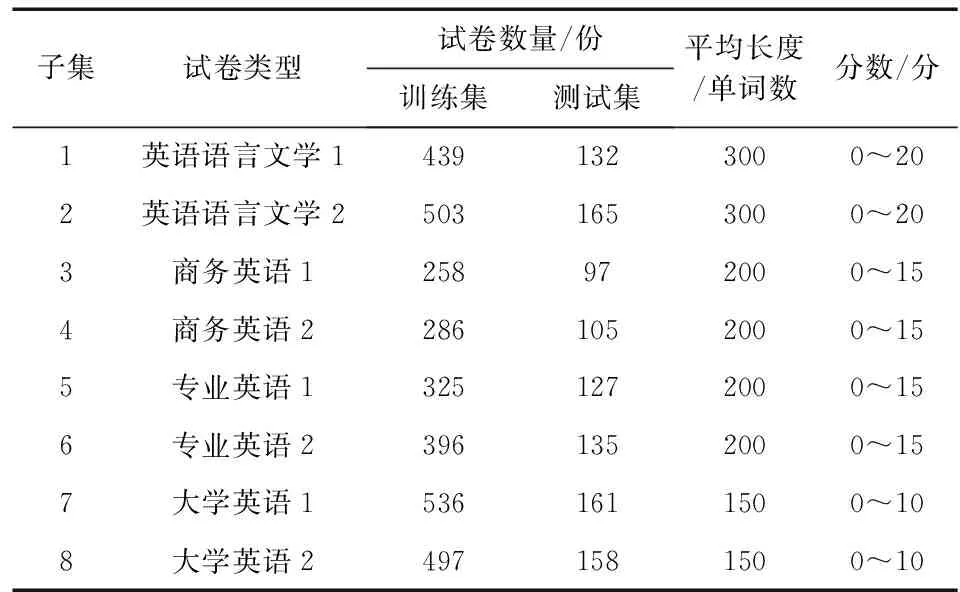
表1 数据集样本Table 1 Dataset samples
2.3 GloVe-CNN主观题自动评分模型效果
目前, 对英语主观题自动评分效果通常结合人工评分结果和系统评分结果间的相关系数来评价。本文通过平方加权Kappa评价指标[26]对实验结果进行评估, 从GloVe-CNN模型中调出预先训练好的8个子集汉译英译文的数据, 通过判断GloVe-CNN自动评分系统评分结果与人工评分结果的评估系数k的值来确定评分的一致性: 若k=1, 表明不同方式评分结果之间的一致性是完全相同的; 若k=0, 则说明不同评分结果之间的评分一致性完全随机的。本文将GloVe-CNN、 CNN(convolutional neural network)、 PV-DM(distributed memory version of paragraph vector)、 KNN(k-nearest neighbor)4种模型在使用相同数据集、 训练集和测试集的情况下, 对评估系数k进行对比分析, 结果详见图3。
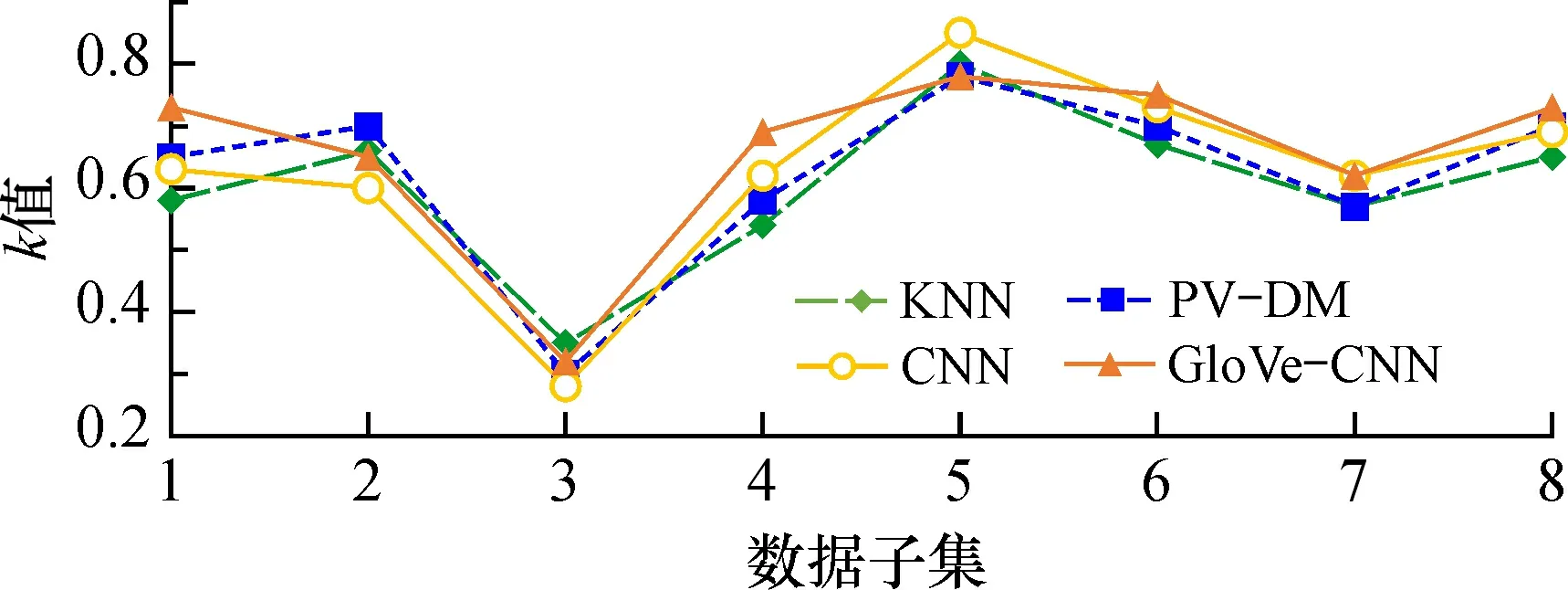
图3 不同模型k值对比Fig.3 Comparison of k values for different models
对比CNN、 PV-DM、 KNN模型的k值可发现, GloVe-CNN模型的k值平均值较高, 在子集1、 4、 6、 7、 8上的k值平均提升1%; 由于子集3为开放式问题, 大多数学生都是根据自身对题目的理解进行回答, 另外阅卷老师个人主观想法的差异会使分数出现偏差, 因此语义表现特征不够明显,k值最低, 在该段子集上人工阅卷的评分相比其他子集分数也略低。
为了验证评分效果, 设置以下评价指标对评分系统的可用性及大规模推广性进行评估, 主要包含: 评分系统和人工阅卷的相关系数, 与人工阅卷的完全一致率、 一致率系数等, 详见表2。

表2 人工阅卷和自动评分系统评估指标Table 2 Manual marking and automatic scoring system evaluation indicators
人工阅卷与计算机自动评分结果两者间相关系数在0.7以上, 方可应用在大规模考试评分系统中[27]。 本文设计的系统模型与人工阅卷相关系数r为0.79, 已达到要求, 完全一致率和一致率系数分别是0.66和0.36, 这两项评估指标也达到了国际研究报告中提出的指标(指标见参考文献[28])。
为了进一步对GloVe-CNN模型的预测性能进行评价, 在5 400份试卷中随机抽取300份, 并邀请2位阅卷老师对纸质版试卷分数进行复核, 将复核分数和原有试卷分数的平均评分作为最终分数, 结果保留两位小数, 分别将人工评阅平均分与CNN、 GloVe-CNN两模型评分作差绝对值运算对比, 结果见图4。
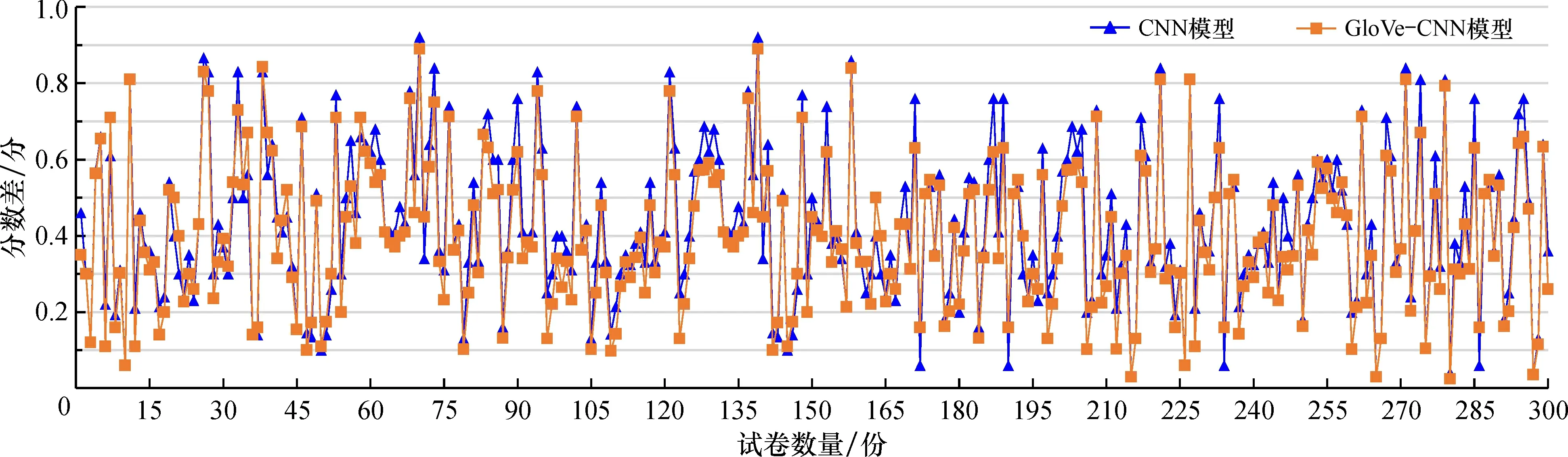
图4 分数差绝对值对比Fig.4 Comparison of absolute value of score difference
考虑人工阅卷评分结果受人为主观因素所影响, 因而部分样本的分数会存在一定的误差。可以看出, 两模型与人工阅卷分数差在可控范围内, 自动评分模型在一定程度上也达到了比较理想的结果。 但总体来说, 本文设计的主观题评分模型相对CNN模型误差波动幅度较小, 具有相对较高的准确性。
3 结束语
在大数据时代背景下, 主观题自动评分系统可以有效减少人力成本, 并减少因人工评价中只注重关键词匹配而导致的评价结果不正确、 不公正的问题。通过引入GloVe模型与卷积神经网络(CNN)构建文本表达式特征, 进而实现主观题自动评分, 通过平方加权Kappa评价指标对实验结果进行评估可以看出, GloVe-CNN模型整体性能较优。通过随机抽取300份样本验证系统阅卷的准确性, 对比系统评分数据和人工阅卷结果, 两者误差在合理范围内。
然而, 仅仅考虑到参考答案和学生答卷结果的接近程度, 没有考虑到学生作答句法的合理性。若学生作答的句式并不通顺或者回答文本只是由单词所构成, 此时简单对比相似度虽然可以进行自主打分, 但是在阅卷者眼中此情形无法得分。这些问题将是课题组继续研究的方向, 以期进一步完善该模型。
猜你喜欢
考试与招生(2022年10期)2022-11-17
井冈教育(2022年2期)2022-10-14
中学生数理化(高中版.高考数学)(2022年6期)2022-07-02
甘肃教育(2021年10期)2021-11-02
开放教育研究(2020年2期)2020-03-31
中学生英语·阅读与写作(2017年6期)2017-07-18
中学生英语·中考指导版(2017年6期)2017-07-18
现代语文(2016年21期)2016-05-25
时代英语·高二(2015年4期)2015-08-14
大连民族大学学报(2015年2期)2015-02-27
