
基于对比学习增强句子语义的事件检测方法①
2023-09-14 03:39谭文婷吕存驰赵晓芳
高技术通讯 2023年7期
梁 冬 张 程 史 骁③ 谭文婷 吕存驰 赵晓芳
(*中国科学院计算技术研究所 北京 100190)
(**中国科学院大学 北京 100049)
(***中科苏州智能计算技术研究院 苏州 215028)
0 引言
事件检测的目的是识别出文本中特定类型的事件[1-2],例如在句子“Liana Owen drove 10 hours from Pennsylvania to attend the rally in Manhattan with her parents.”中,需要识别出“Demonstrate”和“Transport”两种事件类型。基于触发词的识别和分类是当前常用的检测方法,这些方法将事件检测任务看成词的分类问题[3-8],通过对句子中每个词的分类,预测该词是否为一个事件触发词以及其触发的事件类型。比如上述句子要先识别出触发词“rally”和“drove”,然后检测出其分别触发了“Demonstrate”和“Transport”事件。
然而,基于触发词的事件检测方法存在2 个方面的问题:(1)构造训练数据比较耗时,标注人员不仅需要标注事件类型,还需要标注事件触发词。如上述句子需要标注{rally:Demonstrate,drove:Transport}。根据自动内容抽取(automatic context extraction,ACE)事件评估项目[9],触发词最能表述一个事件的发生。但是从已知的句子中挑选最能代表事件发生的词是需要专业的综合判断,往往会花费较多的精力,特别是对于一个很长的句子,尤其是文档级别的事件检测任务。(2)过度依赖触发词的事件检测,会丢失很多语义信息。先前的工作[10-11]表明文本所属的事件类型不仅依赖于触发词特征,还取决于文本的上下文语义特征。同类事件的发生可能是不同的触发词引起的,而相同的触发词根据其语义环境会触发不一致的事件。过度依赖触发词特征,容易导致事件类型的模糊性,难以正确识别已知事件类型未见过的触发词,从而使事件检测准确率下降。
针对上述问题,研究人员设计了无触发词的事件检测方法[12-14]。具有注意力机制的类型感知偏差神经网络(type-aware bias neural network with attention mechanisms,TBNNAM)[12]提出触发词的识别不是事件检测任务的必需步骤,并研究了无触发词的事件检测,利用基于事件类型的注意力机制来弥补触发词缺失造成的重要线索信息的丢失。Doc2EDAG[13]设计了一个无触发词的文档级别事件抽取方法,通过对整篇文档内容的分类来识别事件类型,以缓解事件标注的困难性。文献[14]实现了在无触发词条件下定位文档中的事件表述中心句并判断事件类型的方法。这些方法简化了事件检测的流程,能够降低数据标注的压力,但是由于监督学习需要大规模地标注数据才能学习到强健的语义表示,而目前可用的事件检测数据资源比较匮乏,这些模型在提取事件信息的语义特征方面还有待提高。最近兴起的对比学习是一种强大的表示提取方法,受到了越来越多的关注,在自然语言处理(natural language processing,NLP)领域也得到广泛应用[15]。对比学习为文本语义表示提供了一种新思路,在监督数据有限的情况下,可以有效地提取文本的语义信息。
本文提出了一种基于对比学习增强句子语义的事件检测方法。该方法在事件检测任务中忽略触发词识别这一中间步骤,降低了事件标注成本,简化了事件检测任务的流程,同时引入对比学习增强句子语义表示,提高事件检测结果的可靠性。本文的主要贡献总结为以下4 点。
(1)利用掩码(mask)操作和丢弃(dropout)操作构建自监督对比样例,增加监督对比样例,实现了自监督对比和监督对比2 种句子语义增强的方法,并进一步分析了不同对比学习方法的效果及收敛速度。
(2)在事件检测数据集上通过自监督学习对预训练的语言模型基于转换器的双向编码表示器(bidirectional encoder representations from transformers,BERT)调优,增强事件文本字符级别语义表示和提取,提高了模型在事件检测任务上的领域适应性。
(3)在训练过程中自动调整对比损失和事件检测的交叉熵损失的权重,能够更快地获得较优的结果。
(4)在ACE 项目[9]的中英文数据集上进行了详尽的实验分析,证实了本文方法的有效性。
本文的组织结构如下。第1 节介绍事件检测,预训练语言模型,对比学习相关研究工作;第2 节阐述基于对比学习增强句子语义的事件检测方法;第3 节通过实验对比验证上述方法的有效性;第4 节对全文进行总结。
1 相关工作
1.1 事件检测
事件检测是事件抽取的一个重要子任务,目的是识别出文本中提到的事件类型。这一问题受到了研究人员的广泛关注,现有的方法大多是基于触发词的识别和分类实现的,通常遵循监督学习范式,可以分为基于特征工程的方法和基于表示学习的方法。
基于特征工程的事件检测方法是通过人工设计的精巧特征将事件分类线索转化为特征向量,输入到随机森林(random forest,RF)或者支持向量机(support vector machine,SVM)之类的模型中进行事件识别。例如,文献[16]利用词汇、句法、额外知识等特征。文献[17]结合了相关文档的全局特征和局部决策特征。文献[18,19]提出了跨事件或跨实体的特征。文献[4]采用一个联合模型来捕获触发词和参数的组合特征。
随着深度学习技术的发展,近几年来的事件检测方法倾向于基于神经网络的表示学习方法。例如,文献[1,20]利用卷积神经网络(convolutional neural networks,CNNs)学习事件特征信息。文献[2,5,21,22]利用循环神经网络(recurrent neural networks,RNNs)学习词在事件中上下文语义信息。文献[23]结合CNNs 和RNNs 提取不同层面的事件特征。文献[24]利用注意力机制编码参数信息。文献[6,25]利用图神经网络探索了句法信息特征。文献[26,27,28]学习了文档级别的事件线索。
然而,上述的这些方法均需要额外注释触发词,增加了获取事件检测训练数据的成本,限制了数据驱动的深层网络应用。为了缓解事件标注的困难,受先前工作[12-14]的启发,本文开展了无触发词的事件检测研究工作。
1.2 预训练语言模型
近年来,预训练语言模型的发展将NLP 领域的研究带入到一个新阶段,从海量语料中学习的通用语言表示,能够显著提升下游任务。ELMo[29]、GPT[30]、BERT[31]、GPT2[32]等模型的相继提出,不断刷新了各大NLP 任务的排行榜,并表明采用更多的训练数据可以不断地提高模型性能。
预训练语言模型通过自监督学习,充分利用大量无监督的文本数据,编码语言知识,能够根据上下文动态捕捉单词的语义。本文使用大规模的预训练语言模型BERT[31]作为文本编码器,并在事件检测数据集上通过对随机掩码字符预测的调优训练,提高文本字符级别的事件语义表示,从而进一步提升模型在事件检测任务上的领域适应性。
1.3 对比学习
对比学习的主要思想是最小化给定样本(称为锚点)和正样例之间的距离,并最大化锚点和负样例之间的距离,从而更好地提取数据表示特征。如何构造正负样例是对比学习的关键问题。自监督对比学习没有标签信息,通过数据增强构造相似的样本,原数据和增强后的数据为正样例,和其他样本增强后的数据为负样例。图1 所示为自监督对比学习示意图,虚线圆圈为同一颜色(或同一形状)的实线圆圈增强后的相似样本。监督对比学习利用类别标签关系构造正负样例,同一类别的数据为正样例,不同类别的数据为负样例。图2 所示为监督对比学习示意图,不同颜色(或不同形状)属于不同的类别,本文利用数据增强操作提高同类别的样本数量,增加监督对比的正样例。

图1 自监督对比学习示意图

图2 监督对比学习示意图
最近的研究工作[15,33-34]将对比学习应用在NLP领域,通过对比学习训练文本的编码器。文献[15]通过dropout[35]操作设计了一个简单的对比学习框架,在文本语义相似度任务上取得先进的性能。文献[33]设计了一个监督对比损失函数,并对预训练语言模型微调。文献[34]通过2 种数据增强方式构建自监督对比样例:对原始文本随机删除或掩码操作,利用dropout 操作对特征层向量增强。
在事件检测任务中,对比学习的应用也有一定的研究。文献[36,37]采用三元组损失函数[38]将标签分类下的实例间的关系距离作为一个有效的监督信号,使得类别内部的样本距离小于不同类别样本的距离,但是没有探索无标签信息的句子语义距离关系。文献[39]利用文本中同一事件的参数比其他词更相近,事件相关的语义结构图比事件无关的语义结构距离更远的思想,构造自监督对比信号在大量的无监督数据上指导训练事件检测与抽取任务的预训练语言模型,没有关注对比学习在下游任务增强句子语义的能力。
本文在无触发词的事件检测研究中,为了增强句子的语义表示,实现了自监督对比和监督对比2种方式的表示学习方法,并实验分析了效果的差异性。
2 基于对比学习增强句子语义的事件检测方法
本文设计并实现了基于句子语义提取的事件检测框架。首先通过自监督学习对预训练的语言模型BERT 调优,提高模型在事件检测任务上的领域适应性。然后在此基础上提出了2 种增强句子语义的事件检测方法,分别是自监督对比学习和监督对比学习,通过对比信号提高句子语义的表达能力,从而提升事件检测方法的效果。
2.1 基于句子语义提取的事件检测基础架构
根据最近事件检测的研究进展,本文采用BERT编码器学习输入文本的向量表示。图3 所示为事件检测基础模型架构,该模型包括输入层、BERT 编码器、Dropout 层、线性分类器和输出层。对于给定的句子S,首先在句子S 的开始和结束位置添加特殊字符,构建扩展的序列“[CLS] S [SEP]”,利用BERT 编码器对序列进行编码,输出序列第一个字符的最后一层的隐含层向量作为整个句子的语义表示;然后将句子的语义表示向量进行dropout 操作,提高模型的鲁棒性,避免模型的过拟合;最后将dropout 操作后句子表示输入到一个线性分类器中,进行事件类型的识别。线性分类器输出一个数组,长度为事件类型总个数,每个索引位置分别对应一类事件,数组元素值为1 表示属于该索引位置对应的事件。图中表示句子“Liana Owen drove 10 hours from Pennsylvania to attend the rally in Manhattan with her parents.”预测为“Demonstrate”和“Transport”2种事件类型。
事件检测任务采用二进制交叉熵损失函数。首先将线性分类器的输出经过sigmoid 激活函数处理,归一化到(0,1)的范围,获取文本所属每一类事件的概率P(yj|xi),如式(1)所示,其中fθ(xi) 表示输入的文本序列xi经过BERT 编码器、Dropout 层、线性分类器输出的结果,θ为模型参数。然后在每个类别上计算负对数概率作为事件检测的损失函数Led,如式(2)所示,N为每次迭代训练批数据量大小,K为事件类型个数。
基于触发词的事件检测方法需要对每个字符的隐含层向量进行分类,本文在事件检测时忽略触发词,只需要对整个句子语义编码进行分类即可,相对更简单易于理解。为了满足句子可能描述多个事件的需求,本文通过判断句子预测为某类事件概率P(yj|xi) 是否大于阈值T来确定句子所属事件类型,若概率超过阈值则属于该事件类型,从而支持多标签事件检测。
2.2 面向事件检测的预训练语言模型调优
面向事件检测任务,本文采用自监督学习方法对预训练语言模型BERT 调优,提高模型的领域适应性。具体方式为:使用事件检测数据集,通过自监督预测随机掩码字符的方式,对预训练语言模型做调优训练。相比于直接将预训练模型应用在下游任务,本文的调优训练能够增强模型对事件文本字符级别语义的提取,有助于下游任务对比学习的句子语义表示。
自监督预测使用的掩码语言模型损失函数[33]如式(3)所示,其中,P(xm) 为句子中一个掩码字符的预测概率,M为一个批量数据中掩码字符的总个数。
算法1 为预训练语言模型调优算法的流程。首先(第2 和3 行)对批数据中每条样本进行随机掩码操作,构建掩码字符预测的训练数据;然后(第4~7 行)前向计算损失函数Lmlm,并利用损失函数的梯度更新BERT 编码器的参数。本文随机掩码字符操作参照文献[33]的操作,随机选取10%的字符,如果某个位置的字符被选择,则以80%的概率用“[MASK]”字符替换,10%的概率替换成随机字符,10%的概率保持原字符不变。

2.3 基于自监督对比的事件检测算法
在自监督对比学习中,由于没有标签信息,本文采用2 种数据增强方式构建自监督对比学习的正样例。如图4 所示,在BERT 编码器的输入端,通过句子的mask 操作增强样例;在BERT 编码器的输出端,通过句子特征层向量的dropout 操作增强样例。本文对原文本的mask 操作方法和上述预训练语言模型调优阶段的掩码方法相同。句子特征层向量的dropout 操作如下:对BERT 编码器输出的文本表示向量,以0.3 的概率丢弃。原文本和自身数据增强后的文本属于同源样本,用来构造对比学习的正样例,和其他文本增强的数据属于不同源样本,构造为负样例。

图4 自监督对比学习构建正样例的2 种方式
基于上述构造的正负样例,通过自监督方式对相近的语义进行理解和辨析[15,34],拉近同源样本在语义空间的距离,拉远不同源样本在语义空间的距离,从而提高样本语义表示能力。
通常情况下,基于自监督对比的事件检测的联合损失函数如式(5)所示,λ1为权重超参数。
但是需要大量的工作分析不同损失的量级、验证测试等才能设置合理的权重λ1。
为了降低手动设置联合学习损失函数权重的实验成本,文献[40]利用多任务内在的不确定性自动学习不同损失的权重。受此启发,本文在训练过程中自动调整损失函数的权重,减少了固定权重参数调优的过程,同时在事件检测的精度及模型收敛速度上都有所提升。
在动态调整损失函数权重的方式下,基于自监督对比的事件检测的联合损失函数如式(6)所示,其中σ1、σ2和β1在训练过程中动态变化,σ1和σ2决定损失函数的权重,β1为联合损失函数的正则项。
算法2 为基于自监督对比的事件检测算法的流程。首先(第3~7 行)对批数据中每条样本进行数据增强操作构建其正样例对,生成自监督对比学习的训练数据;然后(第8~13 行)对自监督对比任务和事件检测任务联合学习。

2.4 基于监督对比的事件检测方法
在监督对比学习中,可以通过事件类型标签信息构造监督对比学习的正负样例。属于同一个事件类型的文本的语义比较相似,其向量的距离也更近,相反属于不同事件类型的文本表示的向量距离更远。因此,属于同一类别的文本为正样例,属于不同类别的文本为负样例。由于事件检测数据的稀疏,事件类型的繁多,每个批量数据中正样例的数量比较少。为了增加监督对比学习的正样例,本文同样采用原始文本mask 操作和文本特征层dropout 操作来增强样例,并赋予增强的样例和原文本相同的事件类别标签。
基于上述构造的正负样例,通过监督对比区分不同事件类型的文本语义空间[33],拉近同类型文本在语义空间的距离,拉远不同类型文本在语义空间的距离,从而提高样本在事件语义空间表示能力。监督对比损失如式(7)所示。
其中,T为每次迭代训练批量数据中属于同一类样本对的个数,Ⅱyi=yj表示第i个样本和第j个样本属于同一类事件。
基于监督对比的事件检测的联合损失函数如式(8)所示,λ2为权重超参数。
同样地,动态地调整事件检测的二进制交叉熵损失和监督对比损失的权重,基于监督对比的事件检测的联合损失如式(9)所示,权重参数σ3、σ4和正则项β2在训练过程中自行调整。
算法3 所示为基于监督对比学习的事件检测算法的流程。首先(第3~7 行)对批数据中每条样本进行数据增强操作增加同类事件的样本数;然后(第8 行)利用事件标签信息生成监督对比学习的训练数据;最后(第9~14 行)对监督对比任务和事件检测任务联合学习。算法3 和算法2 的主要区别是数据增强的目的不同,算法2 中是为了构建样本的正样例对,而算法3 是为了增加同类事件的样本数。

3 实验与分析
本节将介绍实验数据集、评价指标、实验设置、实验结果等内容。
3.1 实验数据集
本文在ACE 2005 中英文数据集上进行了实验评估。中英文语料均包含8 大类、33 个子类的事件样本,本文分析了细粒度划分的子类事件检测的效果。根据之前的工作[4,12,20,24],对英文数据集划分方式如下:先从不同类型文档中随机选择30 篇文章作为验证集,然后随机选择40 篇作为测试集,剩余的529 篇文档作为训练集。同样方式对中文数据集划分:先从不同类型文档中随机选择64 篇文章作为验证集,再随机选择64 篇作为测试集,剩余的521篇文档作为训练集。表1 所示为实验数据集包含文档、句子、事件个数的情况。
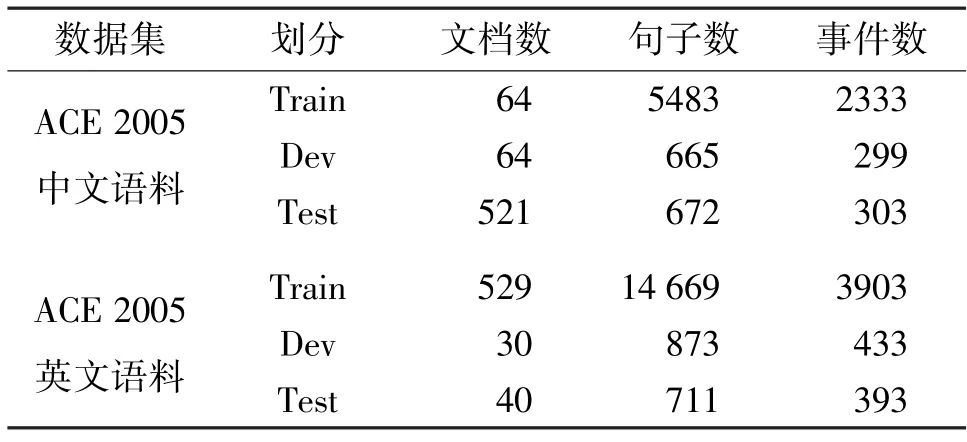
表1 ACE 2005 中英文语料的文档、句子、事件统计结果
利用Stanford CoreNLP 将每篇文档切分成句子,并根据ACE 2005 原始语料的注释为每条句子分配标签。如果一个句子不包括任何事件类型,则分配一个“Negative”的标签。如果一个句子中包含多个不同类型的事件,则保留每个类型的标签;如果句子中包含多个同一类型的事件,则针对同一事件类型,只保留一个标签。在ACE 语料中,这种情况占比不超过3%[12]。表2 所示为ACE 中英文语料中无触发词注释的几个样例。

表2 ACE 2005 中英文语料的无触发词注释的样例
3.2 评价指标
根据先前的工作[4,12,20,24],本文采用准确率P、召回率R和F1度量评估所提出事件检测算法的效果。
准确率P指在预测的事件中(不包括“Negative”类别)正确预测事件的概率,如式(10)所示。
召回率R指在所有真实的事件中(不包括“Negative”类别)正确预测出的概率,如式(11)所示。
F1度量计算如式(12)所示。
3.3 实验设置
本文采用BERT 模型的基础配置:隐含层的大小为768、层数为12。训练时采用Adam 优化器,模型的超参数设置为:序列最大长度为128、批量数据的大小为32、学习速率为3×10-5,对比学习的温度系数τ在{ 0.1,0.2,0.3,0.4,0.5}集合中取值。
在ACE 2005 英文语料的实验中,对比了同样无触发词的事件检测方法TBNNAMBias[12]、TBNNAM[12],以及传统需要标注触发词的基于BERT 编码器的事件检测方法DYGIE ++[26]、BERT-CRF。在ACE 2005 中文语料的实验中,对比了传统需要标注触发词的基于BERT 编码器的事件检测方法MCEE[41]、JMCEE[41]、BERT-CRF[8]。
TBNNAM:基于注意力机制的类型感知偏差神经网络,利用LSTM 编码字符的上下文,通过类型感知的注意力弥补触发词信息的缺失,并设计了偏差损失函数增强正样本的影响。TBNNAMBias 在计算损失函数时不使用偏差项。
DYGIE++:一个基于BERT 编码器的多任务学习框架,可以捕获句子内和跨句子的上下文语义。DYGIE++、BERTFinetune 是在事件检测任务上微调预训练BERT 模型。
BERT-CRF:传统的序列标注的事件检测方法,文本字符输入BERT 编码器输出的序列向量,通过CRF 层对序列字符所属事件触发词识别和分类。
MCEE、JMCEE:基于BERT 编码器的事件提取方法。MCEE 是管道式模型,先进行触发词的识别和分类,然后再进行事件元素的识别。JMCEE 是联合模型,同时预测文本的事件触发词和事件元素。本文对比了MCEE、JMCEE 事件检测(触发词的识别和分类)的结果。
3.4 实验结果
3.4.1 事件检测结果的量化分析
表3 和表4 分别展示了不同方法在ACE 2005中英文数据集上的实验结果。第1 组是对比的基准实验,第2 组是本文提出的方法,包括只使用交叉熵损失Led的基础方法,使用交叉熵损失和对比损失联合训练增强句子语义的方法,以及预训练语言模型调优的基础上利用对比学习增强句子语义的方法。

表3 在ACE 2005 中文语料上不同方法的实验对比

表4 在ACE 2005 英文语料上不同方法的实验对比
从表3 可以看出,在ACE 2005 中文语料上,本文只使用Led的基础方法,优于传统的MCEE(BERTPipeline)方法,F1值有2.3%的提升。在增加了对比损失后,和只使用Led的基础方法相比,F1值有1.8%~3.2%的提升,甚至最高的F1值超过了利用事件检测和事件元素提取多任务学习的方式增益事件识别效果的JMCEE(BERT-Joint)。和传统BERTCRF 的事件检测方法相比,本文提出的只使用Led的基础方法和增加了对比表示的方法没有优势,主要原因是BERT-CRF 将触发词识别和分类转化为序列标注任务,避免了触发词识别错误后传影响整体事件检测效果的问题。在预训练语言模型调优的基础上对比语义增强方法,和JMCEE(BERT-Joint)相比,F1值提升0.1%~3.5%,和只使用Led的基础方法相比,F1值提升3.1%~6.5%,并在监督对比学习方法中达到和传统方法BERT-CRF 相匹配的效果,甚至在利用mask 操作增强样例的情况下取得更优的F1值。分析其原因为:在无触发词的事件检测方法中,事件类型的识别主要依赖文本句子的语义表示;对比学习使不同语义的句子在向量空间具有更清晰的辨识度;预训练语言模型的调优,增强了句子字符级别事件信息的表示,提高了模型在下游任务的领域适应性。
从表4 可以看出,在ACE 2005 英文语料上,本文只使用Led的基础方法,优于同样无触发词的事件检测方法TBNNAMBias,F1值提升1.6%,但低于使用偏差损失函数增强正样本的TBNNAM 方法。这说明事件检测任务的正负样本(包含事件信息的样本为正样本,根据表1 占比不到50%)的偏差对事件识别的效果影响很大,而本文的重点在于文本语义的表示学习,没有针对这一问题做优化。在增加了对比损失后,和只使用Led的基础方法相比,F1值有2.0%~4.0%的提升,并达到了和TBNNAM 相匹配的效果,最高的F1值(基于mask 操作增强样例的监督对比学习)提升1.6%。和DYGIE ++、BERT Finetune 相比,本文只使用Led的基础方法略差,主要因为本文采用的方法缺失触发词信息,在增加了对比损失后,F1值提升0.0%~1.9%,表明增强句子语义的方法可以提高触发词缺失而下降的效果。在预训练语言模型调优的基础上使用对比语义增强的方法,和只使用Led的基础方法相比,F1值有4.2%~5.9% 的提升,并达到和传统方法BERTCRF 相匹配的效果,甚至在利用mask 操作增强样例的监督对比学习方法中取得更优的F1值。
从表3 和表4 还发现:同自监督对比学习相比,利用标签信息的监督对比学习的事件检测效果更好。一方面是因为监督对比将同一类别的样本作为正样例,相比于将同源样本作为正样例,更能在语义空间区分不同事件类型的语义距离。另一方面是因为监督对比采用数据增强的方式增加了每次迭代训练中的正样例数量。此外,不管是监督对比还是自监督对比,利用mask 操作的数据增强具有更好的检测效果,特别是基于mask 操作增强样例的监督对比学习在中英文语料上都取得了相对较优的F1值。
3.4.2 对比学习温度系数的影响分析
温度系数τ是对比损失中一个重要的参数,控制着模型对负样本的区分度,直接影响模型的效果。本文实验分析了在{ 0.1,0.2,0.3,0.4,0.5}中取不同的值对事件检测效果的影响。由于更小的值如0.07 在利用dropout 操作增强样例的自监督对比学习中收敛速度较慢,不在本文对比分析的范围。
图5 所示为在ACE 2005 中文语料上基于对比学习事件检测的F1值随温度系数τ变化情况,其中图5(a)和图(b)分别为温度系数取不同值时自监督对比学习和监督对比学习的事件检测方法的效果。同样,本文也测试了在ACE 2005 英文语料上基于对比学习事件检测的F1值随温度系数τ变化情况,如图6 所示。从图中可以看到,温度系数的选择受数据增强方式、对比学习方式、数据集特点等多种因素的影响。在中文语料上,利用dropout 操作增强样例的2 种对比学习方法的温度系数倾向于取值0.3,而利用mask 操作增强样例的2 种对比学习方法的最优温度系数分别为0.3、0.4。在英文语料上,利用dropout 操作增强样例的2 种对比学习方法的温度系数倾向于取值0.4(或0.3)、0.1,而利用mask 操作增强样例的2 种对比学习方法的最优温度系数分别为0.1、0.4。

图5 在ACE 2005 中文语料上事件检测F1 随温度系数变化情况

图6 在ACE 2005 英文语料上事件检测F1 随温度系数变化情况
本文进一步分析了不同取值的温度系数对模型收敛速度的影响。图7 所示为在ACE 2005 中文语料上温度系数对不同对比学习方法收敛速度的影响。从图中可以看到,不管是dropout 操作还是mask 操作的数据增强方式,相对于监督对比学习,自监督对比学习的收敛速度更容易受温度系数的影响,比如温度系数取值0.1 时和较大的取值(如0.3、0.5)相比,自监督对比学习的收敛速度明显慢很多。值得注意的是,和利用dropout 操作增强样例的对比学习方法相比,利用mask 操作增强样例的对比学习更容易收敛。以温度系数取值0.1 为例说明如下:在自监督对比学习中,利用dropout 操作增强样例的方式大概需要3000 多次迭代才能收敛,而利用mask 操作增强样例的方式大概需要迭代2500次;在监督对比学习中,利用dropout 操作增强样例的方式大概需要迭代2700 次才能收敛,而利用mask 操作增强样例的方式仅需要迭代1000 多次。
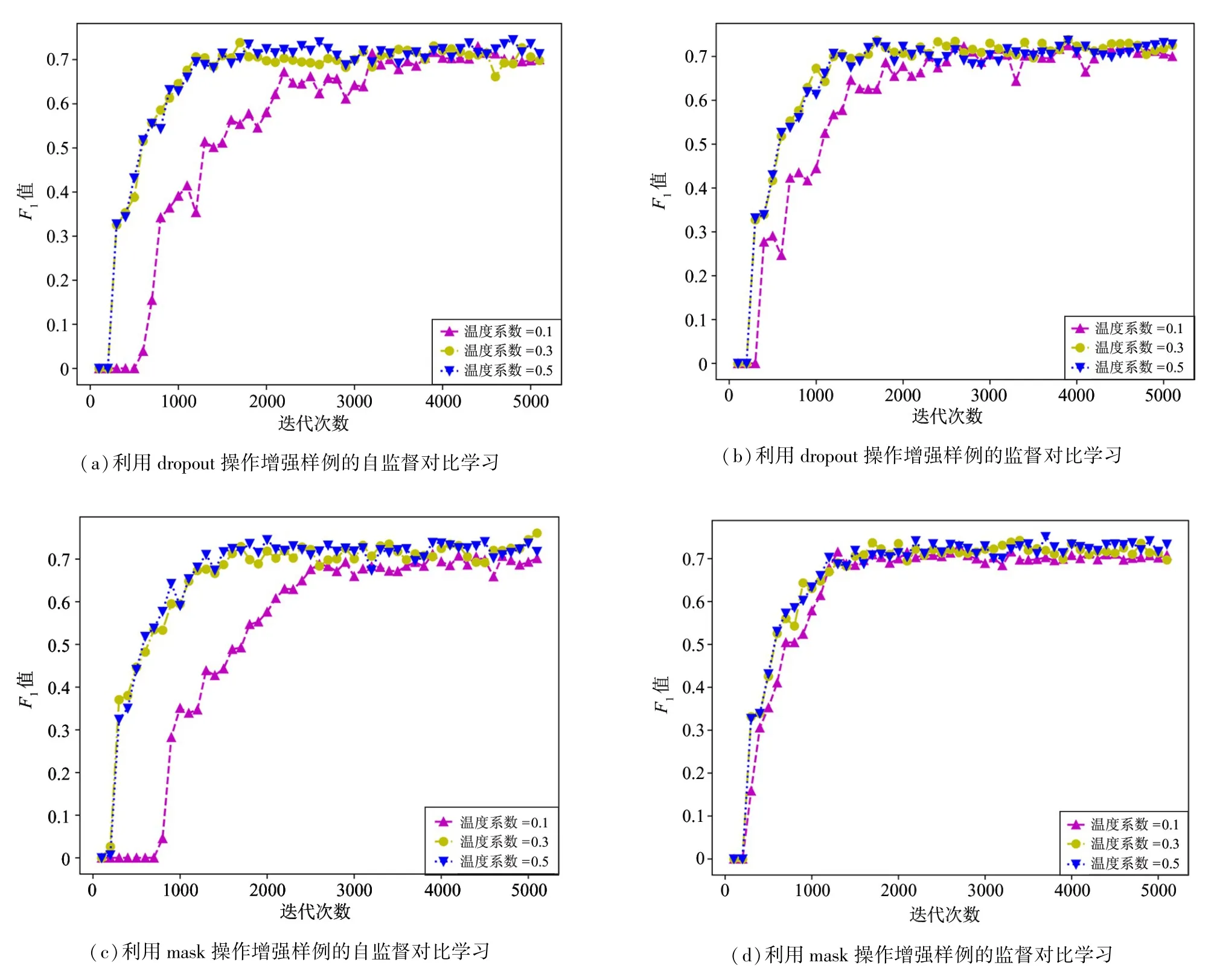
图7 在ACE 2005 中文语料上温度系数对不同对比学习方法收敛速度的影响
3.4.3 自动调整权重的效果分析
本文在训练过程中自动调整对比损失函数和事件检测的交叉熵损失函数的权重,和手动设置权重的方式相比,自动调整权重能够快速地达到较优的效果。
图8 所示为手动调整权重和自动调整权重的效果(F1值)对比,柱状形为使用式(5)或(6)手动调整损失函数权重的效果,虚线表示使用式(8)或(9)自动调整损失函数权重的效果。手动调整损失函数权重时,λ取值为{0.1,0.3,0.5,0.7,0.9,1.0}。测试方法是在ACE 2005 中文语料上利用dropout 操作增强样例的监督对比学习和利用mask 操作增强样例的自监督对比学习2 种方法,实验显示的结果是训练30 个epoch 在测试集上获得的F1值。从图中可以看到手动调整权重时λ取值0.1 最优,这对于有经验的专业人员,可能会快速地找到λ的最优值为0.1,但对于经验不足的调参人员可能需要多次的实验才能找到最优的权重分配,而动态调整权重的方式不需要如此繁琐的调参过程就能获得较优的F1值。

图8 手动调整权重和自动调整权重的效果(F1 值)对比
图9 对比了手动调整权重和自动调整权重的收敛速度。手动调整权重的λ取值0.1,曲线显示的是在验证集上F1值的变化情况。从图中可以看到,利用dropout 操作增强样例的监督对比学习,自动调整权重和手动调整权重收敛速度相差不大,经过3000多次的迭代训练均能收敛;利用mask 操作增强样例的自监督对比学习,自动调整权重的方式收敛速度更快,大概需要2000 多次迭代训练,而手动调整权重的方式经过8000 多次迭代训练还不能达到收敛状态。

图9 手动调整权重和自动调整权重的收敛速度对比
4 结论
面对事件检测数据稀疏、标注昂贵的问题,本文探索了无触发词事件检测的语义提取方法,介绍了基于对比学习增强句子语义的事件检测方法。该方法在事件检测数据集上通过自监督学习对预训练的语言模型BERT 调优,并利用mask 操作和dropout操作构建自监督对比样例,增加监督对比样例,实现了自监督对比和监督对比2 种句子语义增强的方法,同时在训练过程中自动调整对比损失和事件分类的交叉熵损失的权重。在ACE 2005 中英文语料上的实验结果表明,本文提出的方法和只使用交叉熵损失的方法相比,F1值在中文语料上有3.1%~6.5%的提升,在英文语料上有4.2%~5.9%的提升;相较于基准方法,F1值也具有明显的优势。在模型收敛速度方面,自监督对比学习比监督对比学习更容易受温度系数的影响,相同的对比学习方法中利用mask 操作增强样例的方式更容易收敛,特别是对于取值较低的温度系数。此外,本文采用的动态调整损失函数权重的方法,能够降低人工调参成本,同时更快地达到较优的结果。未来工作中,本研究将进一步探讨无触发词事件检测相关技术以及事件元素的提取。
猜你喜欢
心理学探新(2022年1期)2022-06-07
开放教育研究(2020年2期)2020-03-31
广东教学报·教育综合(2020年15期)2020-03-23
海外华文教育(2016年1期)2017-01-20
现代语文(2016年21期)2016-05-25
当代教育理论与实践(2015年9期)2015-12-16
大连民族大学学报(2015年2期)2015-02-27
社会心理科学(2015年6期)2015-02-07
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
