
复杂纹理背景下的密集骨签文字检测算法
2023-09-14 06:40李健昱王慧琴
液晶与显示 2023年9期
李健昱,王慧琴*,刘 瑞,王 可,王 展
(1. 西安建筑科技大学 信息与控制工程学院,陕西 西安 710055;2. 中国社会科学院 考古研究所,北京 100101;3. 陕西省文物保护研究院,陕西 西安 710075)
1 引言
骨签出土于汉长安城未央宫遗址,数量巨大,记录了西汉王朝地方工官向皇室和中央上缴的各种产品,是西汉王朝中央政府备查的重要文字资料,同时也是秦汉考古方面不可多得的宝贵研究资料,对其内容的解读、性质的判定极其必要[1-2]。由于骨签年代久远,其表面不可避免地出现了裂痕、磨损等纹理背景干扰,骨签上所刻文字也存在部分粘连和缺失,因此提取骨签文字信息需依靠文物专家的经验。然而骨签数量庞大,人工检测并提取骨签文字信息的工作量巨大,因此使用数字图像处理等技术对骨签文字进行自动检测十分必要。
随着深度学习技术的发展,越来越多的目标检测技术[3]应用到文字检测中,代表算法有SSD[4]、R-CNN[5]、Faster-RCNN[6]、RetinaNet[7]和YOLO[8](You Only Look Once)等。其中,Redmon 等在2016 年提出的YOLO 系列性能更高,最具有代表性。YOLO 将目标检测问题视为回归问题,进而将目标和背景更好地进行区分。Redmon 等[9]在2017 年提出YOLOv2,使用darknet-19 网络作为主干网络,在简化网络结构的同时提高了目标检测的准确率。刘杰等[10]提出一种基于YOLOv2的改进方法,对目标候选框聚类分析,并将其应用于自然场景中文字符检测中。之后,Redmon[11]在2018 年提出YOLOv3,在保持高检测速度的同时提高了检测精度。殷航等[12]将YOLOv3 与最大极值稳定区域相结合,实现了倾斜文本行的检测。Alexey[13]在2020 年提出YOLOv4,使用CSPDarknet53 作为主干网络并采用FPN 和PAN融合特征图,进一步提高了检测准确率。同年,Ultralytics[14]提出了YOLOv5,模型检测准确率高于以往的目标检测模型且检测速度快,YOLOv5也因此成为目前目标检测表现最好的网络模型之一[15-18]。本文主要针对骨签文字检测。骨签存在大量与文字特征相似的裂痕,使用YOLOv5 等现有技术进行文字检测会受到裂痕等复杂纹理背景信息的干扰,产生误检问题。骨签文字具有密集、粘连的特点,现有技术检测骨签文字时会出现检测框冗余,造成一框多字的问题。
针对上述问题,本文基于YOLOv5 提出改进的骨签文字检测算法SAC-YOLOv5(Self-Attention Convolutional-YOLOv5)。该算法通过融合自注意力卷积关注骨签文字位置信息,扩展模型捕获特征图全局信息和丰富上下文信息的能力,并引入损失函数Focal-EIOU Loss 替换原网络的CIOU 计算定位损失,提高模型的精准定位能力。实验结果表明,本文算法在保持较快检测速度的同时提高了骨签文字的检测精度。
2 骨签文字检测算法
为了解决现有检测算法在骨签文字检测中的问题,本文基于YOLOv5 提出复杂纹理背景下的密集骨签文字检测算法,主要包括Input 输入端、Backbone 特征提取端、Neck 颈部端和Prediction 预测端。Input 端使用Mosaic 数据增强和自适应锚框(Anchors)计算方法。Backbone 部分由切片结构Focus、4 次卷积ConV、C3 模块、空间金字塔池化(Spatial pyramid pooling,SPP)模块和SAC 模块组成。SAC 模块加强网络对骨签文字深层特征的注意,同时扩展模型捕获特征图全局信息和丰富上下文信息的能力,抑制骨签图像上裂痕对文字检测的干扰;Neck 端采用FPN(Feature Pyramid Networks)[19]和PAN(Pyramid Attention Network)[20]结构融合特征图,经过下采样输出端生成3 个特征图用于检测不同尺寸的目标,同时引入损失函数Focal-EIOU Loss 替换原始网络的CIOU 计算定位损失。其中,EIOU 使用预测框和真实框的宽和高损失代替纵横比,从而使预测框与真实框的宽度和高度之差最小,生成预测框时能剔除大于真实框的预测框,解决了骨签文字检测框冗余的问题。本文提出的骨签文字检测算法SAC-YOLOv5 网络结构如图1所示。

图1 SAC-YOLOv5 网络结构Fig.1 SAC-YOLOv5 network architecture
2.1 SAC 模块
骨签由于年代久远,出现了与文字特征相似的裂痕、磨损等复杂纹理背景信息,在进行文字特征提取时困难较大。为了从裂痕等信息干扰的骨签图像中提取到更精确的骨签文字特征信息并使模型聚焦到这些文字信息上,本文提出自注意力卷积模块,具体结构如图2 所示。

图2 SAC 模块结构Fig.2 Self-attention convolutional module architecture
输入特征图F∈RH×W×C首先经过全局平均池化操作,然后进行卷积核大小为k的一维卷积操作,并经过Sigmoid 激活函数得到各个通道的权重,最后将权重与原始输入特征图对应元素相乘,得到的特征图输入到空间自注意力机制中,沿空间维度展开得到矩阵F∈RN×C,其中N=H·W,C表示不同图像区域的高维向量。然后通过可学习的权重矩阵Wq∈RC×C',Wk∈RC×C',Wv∈RC×C'分别计算得到Q、K、V3 个向量,其中C'=C/r,r>1,r是还原比,用于减少向量的维数,并计算注意权重和低维子空间中的值。
式中:α∈RN×N为自注意矩阵;aij是区域i对区域j的注意权重;V∈RC×C'是低维子空间中的权重矩阵,使用Wv∈RC×C'将其投射到原始子空间获得自注意特征图S∈RC×C',最后通过残差连接获得最终的输出。
其中,a是初始化为0 的可训练标量参数。SAC模型首先学习局部邻域周围的图像特征,然后逐渐继续学习全局依赖关系,为网络提供具有丰富内容和上下文信息的特征图,在关注骨签文字位置信息的同时扩展模型捕获特征图全局信息和丰富上下文信息的能力,优化特征提取时混淆裂痕特征与文字特征的问题。
2.2 改进损失函数
YOLOv5 的损失函数由分类损失、定位损失和置信度损失组成。其中定位损失使用CIOU[21]计算。CIOU 考虑了边界框回归的重叠面积、中心点距离、纵横比,其计算公式为:
其中:IOU 为交并比,b和bgt分别表示预测框和真实框的中心点,ρ(·)表示欧几里得距离,c表示包含预测框和真实框的最小外接矩的对角线长度,α是用于平衡比例的参数:
v用于衡量预测框和真实框宽和高之间的比例一致性:
式中:wgt、hgt代表真实框的宽和高,w和h代表预测框的宽和高。
由公式(7)可得,CIOU 使用的是预测框和真实框的宽和高的相对比例,并不是宽和高的值。根据纵横比v的定义,可以看出当预测框的宽和高和真实框的比例满足:
即预测框和真实框的宽高纵横比呈线性比例时,CIOU 中添加的相对比例的惩罚项便不再起作用。从预测框的宽和高的相对于v的公式:
可以推导出:
预测框w和h的梯度值和具有相反的符号。在预测框回归过程中w和h其中某一个值增大时,另外一个值必须减小,不能同增或者同减。由于骨签文字具有密集和粘连的特点,因此在骨签文字检测时使用CIOU 作为损失函数,纵横比v决定了预测框的宽和高不能同增或同减,总是会出现预测框大于真实框的情况,从而导致一框多字的问题。
为了解决这个问题,采用EIOU[22]替换原网络的CIOU 计算定位损失。EIOU 计算公式为:
其中,cw和ch分别是预测框和真实框最小外接矩形的宽和高。EIOU 将损失函数分成了3 个部分:预测框和真实框的重叠损失LIOU、预测框和真实框的中心距离损失Ldis以及预测框和真实框的宽高损失Lasp。
EIOU 损失的前两部分延续CIOU 中的方法,第三部分使用宽高损失代替纵横比。宽高损失使预测框与真实框的宽度和高度之差最小,生成预测框时能剔除大于真实框的预测框,解决检测框冗余问题。图3 是CIOU 和EIOU 损失预测框迭代过程对比图,橘色点线框是真实框,黑色实线框是预先设定的锚框,红色虚线框和蓝色虚线框是预测框的回归过程。

图3 预测框迭代过程对比图Fig.3 Prediction box iterative process comparison diagram
为了更好地提高模型性能,使用Focal L1 损失针对文字和裂痕内容失衡的样本将错误率大的地方设置更高梯度,如式(13)所示,降低低质量骨签样本对模型性能的影响。通过整合EIOU损失和Focal L1 损失,得到最终的Focal-EIOU 损失,如式(14)所示:
3 实验结果及分析
3.1 实验数据
骨签数据来源于中国社会科学院考古研究所。由于年代久远,表面不可避免地出现了裂痕。骨签文字具有密集、粘连的特点,骨签图像样本及标注结果如图4 所示。本文骨签文字数据集采用“LabelImg”标注工具进行人工标注,标注信息存储至txt 标签文件,共计标注2 500 张骨签数据,按照8∶2 的比例划分训练集和验证集。

图4 实验数据Fig.4 Experimental data
3.2 数据增强
YOLOv5 中使用了Mosaic 数据增强方法,主要思想是将4 张图片随机裁剪缩放后拼接成一张图片,在丰富数据集的同时增加小样本目标,提高网络的鲁棒性。一次性计算4 张骨签图片使模型对内存的需求降低。本文在Mosaic 思想的基础上,将8 张骨签图片随机裁剪、排列、缩放后拼接成一张图片,以此增加骨签图像中小文字样本,增加数据多样性并提升网络的训练速度。数据增强的流程如图5 所示。

图5 数据增强Fig.5 Data enhancement
3.3 实验环境及参数配置
本文使用Windows10 64 位系统,实验环境为python3.7、pytorch1.8.0、cuda11.1。所有的模型都在NVIDIA RTX 3090Ti GPU 运行,在相同超参数下进行训练、验证和测试。图片设置为640×640 JPG 格式,Batch size设置为8,训练200个epoch,选取准确率(Precision,P)、召回率(Recall,R)、平均精度均值(mAP0.5)、每秒10 亿次的浮点运算数(GFLOPs)、权重大小(Weight)和实际检测速度(FPS)作为评价指标。其中P和R的计算公式如(15)和(16)所示:
式中:TP(True Positive)表示真正例,即预测正确的文字数量;FP(False Positive)表示假正例,即非文字样本被预测为文字的数量;FN(False Negative)表示假负例,即文字样本被预测为非文字的数量。GFLOPs 用于衡量训练模型时的计算复杂度。mAP 为学习的类别精度均值。mAP0.5表示将交并比IOU 设为0.5 时,骨签图像文字数据集的AP 的平均值。精度均值AP 为以准确率(Precision)和召回率(Recall)所围成的曲线面积值。因本文检测目标为单类别目标,故mAP 值与AP 值相等。mAP 计算公式如式(17)所示:
3.4 YOLOv5 基础模型对比
YOLOv5 目标检测网络结构共有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 4 个模型,网络深度和宽度逐次递增。在自建骨签文字数据集上对YOLOv5 基础模型对比,结果如表1 所示。

表1 YOLOv5 基础模型结果对比Tab.1 Compared results of Yolov5 basic model
如表1 所示,随着网络深度和宽度的递增,mAP 值基本保持一致,而计算量和模型权重文件逐渐增大,导致训练时间变长,检测实时性下降明显。本文以检测精度和速度为侧重点。由于在检测精度基本保持一致时,模型实时性会因为网络规模的增大而降低,因此选择YOLOv5s作为基础网络进行改进,模型参数量和计算量较小,具有更好的实时性和检测精度,能更好地满足骨签文字检测的实际项目需求。
3.5 消融实验
为验证引入多头注意力机制及改进损失函数的有效性,本文进行消融实验评估不同模块在相同实验条件下对骨签文字检测算法性能的影响。在消融实验中选择YOLOv5s 作为基准模型,结果如表2 所示。

表2 消融实验结果Tab.2 Experimental results of ablation
消融实验中,模型B 表明在引入SAC 模块后,mAP0.5 在YOLOv5s 的基础上提升了1.88%,证明了SAC 模块的有效性,但检测速度降低,分析认为SAC 计算需要消耗较大的计算资源,且检测速度与计算复杂度呈负相关性。因此,为提高训练效率,本文只在特征提取网络中插入SAC 结构。模型C 验证了改进损失函数后的网络性能,mAP0.5 提高了1.05%,解决了骨签文字密集、粘连产生的一框多字问题。模型D 验证了最终改进模型的性能,mAP0.5 比原YOLOv5s 提高了3.08%,证明了本文改进方法对骨签文字检测的有效性。
为了进一步验证自注意力卷积模块的有效性,利用CAM[23]方法绘制增加SAC 模块前后的骨签图像的热力图,结果如图6 所示。

图6 热力图对比结果Fig.6 Thermodynamic diagram comparison results
由于骨签图像背景复杂,文字与裂痕纹理信息过于相近,未经过SAC 模块的骨签文字目标区域激活值较低且激活范围小,难以有效反映出真实文字目标位置;而经过SAC 模块后,相对更准确地在骨签文字目标区域形成聚焦产生了较高的激活值。由此可见,本文提出的SAC 模块有效增强了骨签文字的特征,抑制了检测中复杂纹理背景对文字检测的干扰。
为了验证改进损失函数的有效性,对改进前后的模型检测效果进行可视化,结果如图7 所示。
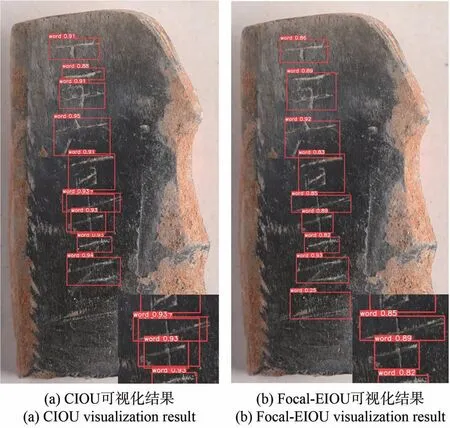
图7 Focal-EIOU 改进前后的对比结果Fig.7 Comparison results of Focal-EIOU before and after improvement
可以看出,使用CIOU 作为损失函数对粘连骨签文字进行检测时,出现了检测框冗余现象;而使用Focal-EIOU 作为损失函数时,完整地检测到每个文字,验证了Focal-EIOU 的有效性。
3.6 对比实验
为验证所提算法的先进性,在自建骨签数据集上与当前几种主流算法在相同训练环境下进行客观指标对比,结果如表3 所示,P-R曲线如图8所示。

表3 不同算法的对比实验Tab.3 Contrast experiment of different algorithms
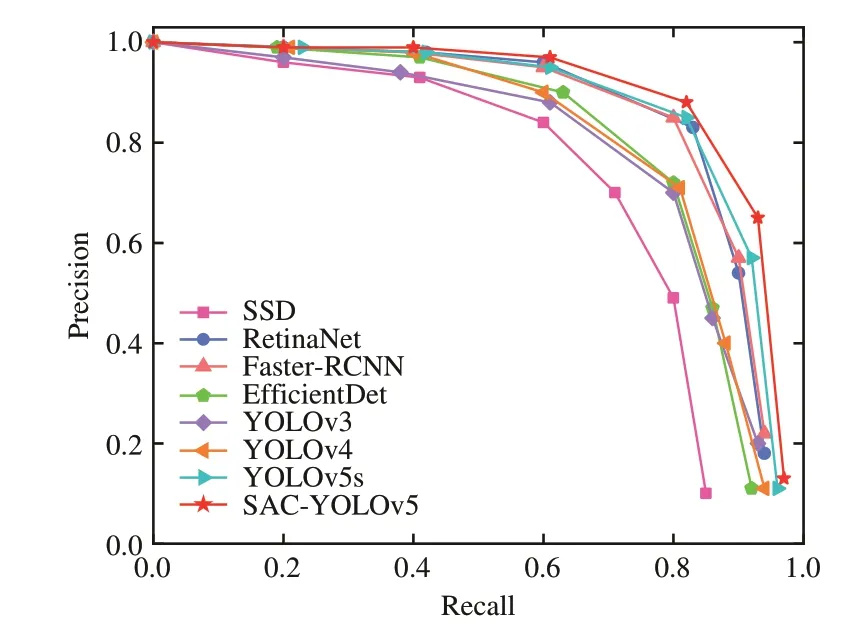
图8 对比实验的P-R 曲线图Fig.8 P-R curves of contrast experiments
由图8 实验结果可得,在相同实验条件下本文算法的精确率、召回率和平均精确率均优于对比算法,mAP0.5 比YOLOv4 提高了11.23%;检测速度相较于改进前的YOLOv5s略有下降,但仍优于其他对比算法。为进一步验证本文算法对骨签文字的检测效果,选取上述经典检测算法与本文算法针对含有裂痕干扰、粘连骨签文字以及密集骨签文字3 种典型问题进行测试验证,图9 展示了裂痕干扰样本。图10 展示了粘连骨签文字样本。图11 展示了密集骨签文字样本的检测结果。

图9 裂痕干扰样本的检测结果对比Fig.9 Comparison of detection results of crack interference samples
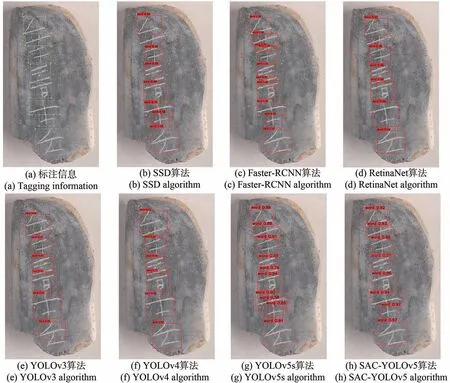
图10 粘连骨签文字样本的检测结果对比Fig.10 Comparison of test results of adhesive bone stick text samples
图9 中,骨签有严重的裂痕信息干扰,其他对比算法均产生了漏检,本文算法则完整地检测到裂痕干扰下的骨签文字。图10 为粘连骨签文字的检测结果,RetinaNet、YOLOv3、YOLOv4 将粘连文字检测为一个文字,SSD 存在漏检文字,Faster-RCNN、YOLOv5s产生了检测框冗余问题,本文算法则很好地检测出粘连文字。图11 所示为密集骨签文字的检测结果,SSD、YOLOv3、YOLOv4、YOLOv5s 等算法均产生了漏检问题,本文算法则完整地检测出每个文字,检测结果较理想。在实验中,发现本文算法检测的置信度较低,分析认为YOLOv5 加入了标签平滑,标签平滑是一种正则化技术,它扰动目标变量,如果出现错误标签,算法受到的影响就会更小。对比实验表明,本文算法相比其他对比算法能更有效地检测骨签文字。
4 结论
针对骨签存在裂痕等复杂纹理背景干扰、文字密集及粘连的问题,本文提出融合自注意力卷积和改进损失函数的骨签文字检测算法,建立了骨签文字数据集,基于此数据集进行训练和对比实验。首先,使用Mosaic 数据增强,增加小样本目标,提升网络的训练速度;其次,设计自注意力卷积模块加入特征提取网络中,通过为文字信息分配更大的权重增强网络对骨签文字特征的注意,同时综合利用各子空间的特征信息,缓解单纯使用自注意力机制产生的过度集中自身位置信息的问题,从全局提取出更多的有效特征,获得更丰富的上下文信息,抑制骨签图像上裂痕对文字检测的干扰;最后,采用Focal-EIOU 损失函数替换原网络的CIOU 进行优化,使用宽高损失使预测框与真实框的宽度和高度之差最小,提高模型的精准预测能力。实验结果表明,本文算法针对骨签文字检测的mAP0.5 达到了93.35%,在检测速度基本不变的情况下,有效增强了YOLOv5 的鲁棒性和骨签文字的检测能力,解决了大量检测框冗余、漏检和误检的问题,对复杂纹理背景下的密集粘连骨签文字检测任务更为适用。
猜你喜欢
公民与法治(2022年5期)2022-07-29
英语文摘(2021年11期)2021-12-31
小猕猴智力画刊(2021年9期)2021-10-11
小天使·一年级语数英综合(2021年9期)2021-09-22
数学小灵通·3-4年级(2021年5期)2021-07-16
小雪花·小学生快乐作文(2020年6期)2020-10-13
文苑(2020年12期)2020-04-13
今日农业(2019年15期)2019-01-03
海外星云(2016年15期)2016-12-01
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
