
BP神经网络模型在流量资料插补中的应用
2023-11-15 01:42刘丽
水资源开发与管理 2023年10期
刘 丽
(辽宁省水利事务服务中心,辽宁 沈阳 110003)
水文原始资料的完整性对水文水利计算起着不可或缺的重要作用,而对于洪峰流量观测缺失部分的插补工作又是原始资料整编的一个关键环节。在实际观测中,水文原始数据的缺失是一种比较常见的现象,导致原始数据缺测丢失的原因有很多,如观测站的性质变化、监测器的错误、断电和人为因素等[1]。而数据的缺失将直接影响水文数据的一致性,进而影响水资源量的统计与水利工程防洪标准的制定。方红远等[2]将BP神经网络算法应用于苏南宁溧山丘区的当地水文过程预测,通过对预测值与实际值的对比发现拟合系数R2均超过0.90;蒋懿[3]基于BP神经网络原理建立了洪水反向演算模型,用于提高河道内洪水反向演算结果的精度。刘平等[4]结合典型潮位站的潮位单位线形状,利用临近站点完整潮位资料对沿海潮位缺失低潮位的测站点实现了潮位资料的插补延长;张志萍等[5]对大理河流域降水缺失资料的插补延长采用了“系列化处理”的计算方法;刘恒[6]基于BP神经网络原理建立了多因子洪水分类模型,对洪水实现了在线分类。水文数据的缺失问题是水文计算的一个关键的基础问题,水文数据的插补还原精度则是目前亟需解决的一个难题。本文以南沙河千山水文站的缺失流量资料插补为例,对BP神经网络在水文数据插补中的应用进行探究。
1 流域概况
南沙河为太子河支流,属辽河水系,发源于辽宁省鞍山市千山风景区庙尔台村,经过辽宁省鞍山市的陈家台、立山和城昂堡村以及辽阳市的刘二堡镇,至唐马寨南坨子村流入太子河。南沙河集水面积为426km2,河道总长为58km,流域内植被茂盛,水量丰富,降水主要集中在6—9月[7]。
千山水文站位于辽宁省鞍山市千山风景区庙尔台村,建于1983年,控制流域面积为14.3km2,从1988年开始有流量观测资料,2016—2020年因水文站功能的改变而缺少观测数据。温泉水文站位于辽宁省鞍山市千山风景区倪家台村,处于千山水文站下游,设立于1984年,控制集水面积为45.3km2,水文观测资料较完整。
2 研究方法
2.1 BP神经网络法
人工神经网络是由具有适应性的简单单元组成的广泛并行连接的网络[8]。BP神经网络是基于人工神经网络而改进的一种,也是所有人工神经网络中应用范围最广的一种[9]。BP神经网络利用误差逆传播算法对多层前馈网络进行训练,核心是梯度下降,其权值的调整采用反向传播,具有并行分步处理、非线性映射、通过训练进行学习、强适应和信息融合等多种特性,特别对复杂的、大规模的和多变量的系统具有相当好的适用性。BP神经网络结构是“输入层—隐藏层—输出层”的分层网络,其学习过程就是不断调整网络的连接权,以获得期望的输出的过程。单隐层结构是BP神经网络模型中最基本的结构。当所有神经元的激活函数均采用S型函数时,单隐层结构的BP神经网络模型就可以解决大部分判定类型的问题[10]。所以,选用单隐层结构作为本次研究的BP神经网络模型的结构,见图1。

图1 单隐层BP神经网络
BP神经网络计算过程如下:
步骤一:选定网络的神经元节点个数,对权值赋值。
步骤二:输入训练集的样本,并获得实际值和理想值两者之间的误差。
步骤三:调整模型中节点的阈值以及连接权值。
步骤四:重新输入样本数据,判断已校正后的模型实际输出结果与理想输出结果两者的误差是否符合本次训练要求,如未符合,需返回步骤二继续校正,直至符合训练要求[11]。
本次网络模型搭建的激活函数选用sigmoid函数,其把神经元的输入信号和输出信号两者之间的关系描述为在(0,1)内的单调可微函数,公式如下:
(1)
式中:β>0,通常β=1;x为输入层的特征值。
2.2 传统计算方法——水文比拟法
两个具有相似的降水条件、下垫面条件、地质条件等的流域,其水文现象会具有较为类似的发生、发展规律[12]。水文比拟法应用的前提就是两个流域间各种自然条件的相似性,如此才能将参证流域的水文观测资料移置到设计流域。主要内容是选择恰当的参证流域,参证流域应与待研究流域的水文条件和主要影响因素具有共同性,并且具有较长的水文数据观测系列。
3 实例分析
3.1 模型搭建
洪峰流量是水利工程建设不可忽视的一个重要因素,根据洪水成因分析,洪水主要由集水面积内的降雨形成,降雨量则是影响洪峰流量的重要因素,千山水文站集水面积较小,将该站的点降雨量认作降雨量。同一流域不同水文站的洪峰流量变化有一定的相关性,因此,本次将千山水文站的降雨量与温泉水文站的洪峰流量选作BP神经网络输入层的两个特征因素。模型的隐含层选用10个节点,选用sigmoid函数作为激活函数,千山水文站的洪峰流量作为输出层的期望值。
将千山水文站与温泉水文站1988—2007年共20年的水文数据作为训练集,用作模型拟合的数据样本。将2008—2011年共4年的数据选作测试集,用来评估最终模型的泛化能力。将2012—2015年共4年的数据作为验证集,用于调整BP神经网络模型的超参数以及对模型预测能力的初步评估。神经网络各层单元数见表1。
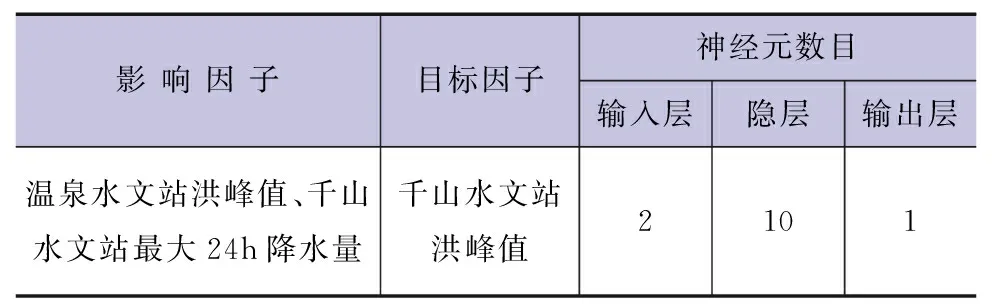
表1 神经网络各层单元数
均方误差代表预测输出和目标输出之差的期望值,该值越接近0越好,图2为BP神经网络的训练过程曲线,图中横坐标表示模型训练迭代次数,纵坐标表征了模型的均方误差值。图中的绿色圆圈显示了验证集在最佳均方误差时网络的迭代次数为8,均方误差值为2.667。

图2 BP神经网络的训练过程曲线
回归值R代表预测输出和目标输出之间的相关性,R的数值越接近1说明预测和输出数据之间的关系越密切,R的数值越接近0说明预测值与输出值两者之间的关系随机性越大。
图3所示为训练集、验证集、测试集与总体模型的数据相关性关系,图中横坐标表示目标输出,纵坐标表示预测输出和目标输出之间的拟合函数。图中R值均大于0.9,说明预测输出与目标输出误差较小,模型搭建合理。

图3 训练集、验证集、测试集与总体模型的数据相关性关系
选取千山水文站丰枯相差较大的年份2010—2015年进行流量结果验证对比。图4为总模型估值与真实值的对比图,横坐标为年份,纵坐标为洪峰流量值。可以看出,总模型估值与真实值之间误差较小,数值相近,具有一定合理性。该模型可以用来预测千山水文站2016—2020年的洪峰流量值。

图4 总模型估值与真实值的对比
3.2 水文数据插补分析
本节分别采用较为成熟的水文比拟法与3.1节中已经搭建好的BP神经网络模型对千山水文站2016—2020年缺失的洪峰流量值进行插补展延分析,对比结果见表2。其中水文比拟法中参证站选用的是温泉水文站,温泉水文站与千山水文站均处于南沙河流域,两站相距3.4km,下垫面条件、降水条件、地质条件等都极为相似,完全适合水文比拟法在两站的应用。由温泉水文站2016—2020年洪峰流量值通过面积比法得到千山水文站洪峰流量值。对这两种计算方法得到的结果列表比较,并通过差值百分比进行分析。差值百分比计算公式为

表2 BP神经网络法与水文比拟法计算的洪峰流量对比分析
(2)
式中:Δ为差值百分比;QBP为BP神经网络模型计算得到的洪峰流量,m3/s;Q比拟为水文比拟法计算得到的洪峰流量,m3/s。
从表2可以看出,BP神经网络模型与水文比拟法计算结果相差范围为0.2~1m3/s,其中,以2020年的误差值最小,为0.208m3/s;2016年的误差值最大,为1m3/s。BP神经网络法与水文比拟法计算结果的差值百分比范围为1%~16%,其中,以2020年的误差值最小,为1.71%;2017年的误差值最大,为15.41%。BP神经网络法与水文比拟法计算结果差值百分比超过10%出现在2017年,该年的洪峰流量值小于2m3/s,故差值百分比会相对被放大,但仍在合理范围之内。除2017年以外,其他年份差值百分比为1.5%~6.5%,说明BP神经网络模型预测结果较为合理。从表2可以看出,BP神经网络模型计算的流量结果均大于水文比拟法计算的流量结果。千山水文站在温泉水文站上游,千山水文站所处位置的比降大于温泉水文站所处位置处的比降,所以千山水文站处的洪峰流量应略大于由温泉水文站数据通过水文比拟法得到的洪峰流量,所以无论是从数据合理性还是从工程安全考虑,在水文计算时采用BP神经网络模型计算的洪峰值更有利于得到较为真实的水文数据,更好地保护人民生命财产安全。
4 结 语
本文以千山水文站与温泉水文站为例,通过采用BP神经网络模型计算值与实际数值的测验对比,可以发现BP神经网络模型能较好地插补出洪峰流量值,对千山水文站2016—2020年的水文数据插补分析发现,BP神经网络模型插补值相比于水文比拟法的插补值,差值百分比为1%~16%,BP神经网络模型计算出的结果精度较高,从工程角度来看也偏安全,说明BP神经网络模型在水文数据插补展延方面具有一定的应用价值。目前仅对南沙河流域作了验证,其他地区的模型适应度仍需要进一步探究。
猜你喜欢
关东学刊(2022年2期)2022-08-25
国画家(2022年1期)2022-03-29
中华建设(2020年5期)2020-07-24
水利规划与设计(2017年9期)2017-12-20
水利科技与经济(2017年5期)2017-04-22
岷峨诗稿(2017年4期)2017-04-20
水利技术监督(2016年6期)2017-01-15
水利规划与设计(2016年10期)2017-01-15
水利科技与经济(2016年10期)2016-04-26
水利科技与经济(2016年8期)2016-04-22
