
固定效应部分线性单指标空间自回归面板模型的二次推断函数估计
2023-12-14 14:04丁飞鹏
高校应用数学学报A辑 2023年4期
丁飞鹏
(江西财经大学 统计学院,江西南昌 330013;江西师范大学 数学与统计学院,江西南昌 330022)
§1 引言
众多领域的数据呈现空间效应(即空间相依性和空间异质性)问题,这与经典计量理论的基础假设相违背,导致经典计量分析方法难以解释这种空间效应,为此,计量经济学家建立了空间计量模型.该模型自提出后,引起了学术界的高度重视.文[1-2]详细地描述了空间计量模型的理论方法及应用.在各种空间计量模型中,空间自回归模型(SAR)受到了极大关注,大量针对该模型的估计方法相继建立,例如,纠正普通最小二乘法(参见文[3]),矩估计法(参见文[4]),广义矩估计法(参见文[5-7]),准极大似然估计法(参见文[8-10]).这些模型的特点是通常假设回归函数为线性或已知的非线性形式.然而在实际应用中,变量间的空间计量经济关系往往存在高度非线性,而且事先也很难预知回归函数的形式,因此采用这些模型进行实证分析,容易出现模型误设现象,影响结论分析的准确性.
非参数计量方法的出现,为解决模型误设问题提供了新的途径.该方法降低了对回归函数形式的要求,能够提供更好的拟合效果,在计量理论和实证分析中得到了广泛研究和应用.目前,一些学者已将非参数计量技术引入空间计量模型中,建立了大量非参数空间计量模型及其估计方法.文[11]将边际积分法和局部线性法结合,研究了空间数据的非参数回归模型,并建立了渐近理论;与文[11]不同,文[12]在误差项存在空间相关性,条件异质性及非同分布的条件下,研究了空间数据的非参数回归模型,在给定一些充分条件下,推导了模型的大样本性质;文[13]为部分线性空间自回归模型建立了截面极大似然估计法;随后,文[14-15]将截面极大似然估计法分别应用于非参数空间动态模型和部分线性单指标空间自回归模型的研究中;然而,截面极大似然估计法无法获得解析表达式,因此在实际中不易实施,为此,文[16]建议采用广义矩法估计半参数空间自回归模型;根据文[16]的建议,文[17-18]采用广义矩估计法分别研究了部分线性单指标空间自回归模型和部分线性可加空间自回归模型;文[19]则考虑了随机场(random fields)下的非参数空间自回归模型,推导了估计量的大样本性质;文[20]为部分线性单指标空间自回归模型建立贝叶斯估计法.
最近,面板数据计量模型发展迅速.其主要原因是面板数据具有纯截面数据和时间序列数据无可比拟的优点:一是面板数据具有更多的自由度,可让研究人员估计更复杂的模型;二是面板数据可以消除异质性问题,估计结果更加有效;三是可减少共线性等问题的出现.基于此,一些学者将非参数空间计量模型与面板数据计量模型结合,建立了非参数空间面板模型.当前关于非参数空间面板模型的文献还较为有限,文[21]结合样条函数及半参数最小二乘法,研究了误差项具有空间异质和空间相关情形下的半参数空间面板固定效应模型;文[22]则考虑了半参数空间动态面板固定效应模型,为模型建立了两阶段最小二乘法,并证明了估计量的大样本性质;文[23]采用空间异质惩罚算法(algorithm based on spatial anisotropic penalties)研究了一种半参数空间自回归面板模型,该模型的特点是时空趋势具有非参数形式,时间序列方向存在自相关性.
与通常的非参数模型类似,非参数空间面板模型也存在“维数灾难”现象,即随着非参数部分协变量维数的增加,估计精度会不断降低.部分学者建立了具有降维功能的半参数空间面板模型以克服“维数灾难”现象,其中包括单指标空间自回归面板模型(见文[24]).与文[24]不同,本文将研究个体内存在相关性下部分线性单指标空间自回归固定效应面板模型,这主要基于以下几点考虑:一是所述模型具有显著的降维功能;二是所述模型不仅保留了非参数空间面板模型的灵活性,还通过加入线性部分,增加了模型的解释力,更具实用性;三是实际中的面板数据在个体内通常存在相关性,若忽略该相关性,将减少估计量的有效性,甚至影响估计量的一致性;四是固定效应模型应用范围更广.
本文其余部分安排如下:§2介绍相关的模型及其估计方法;§3说明在实际操作中的一些问题;§4给出了模型估计量的大样本性质,并提供了相关证明;§5采用Monte Carlo模拟和实际数据分析评价了模型及估计方法在有限样本下的表现;最后对全文进行了总结.
§2 模型及其估计方法
假设个体数N较大,时期数T固定.所述模型的数学形式为
其中γl为样条函数系数,l=1,···,q.将式(4)代入式(3)中,有
记B(·)=[B1(·),···,Bq(·)]′,γ=(γ1,···,γq)′.则式(5)可重写为
式(6)的矩阵形式为
式(7)的均衡表示形式为
其中S(ρ)=[(IN-ρW)⊗IT]-1.令uW=S(ρ)(Xβ+B(Zθ(ψ))γ),ϑ=(ρ,β′,ψ′,γ′)′.经过简单计算可得
其中Ω=IN ⊗V,V为ei=(ei,1,···,ei,T)′的协方差矩阵(本文假设误差项满足同分布假设),i=1,···,N.式(9)中,α为干扰参数,采用差分方法虽然可以消除该个体效应,但将导致部分信息损失,影响连接函数的估计.根据识别条件,本文采用LSDV法消除个体效应,即给定参数向量ϑ的值,α的值为
将式(10)代入式(9),于是有
其中LD=INT-D(D′D)-1D′.在式(11)中,协方差矩阵V是未知的,若用其估计值代替,将损失大量的自由度,损害估计量的有效性.按照文[25]的建议,采用已知对称基矩阵的线性组合近似V-1,
其中M1,···,Ms为已知对称矩阵,a1,···,as为未知常数.式(12)说明
将式(13)代入式(11)中有
为避免估计常数a1,···,as,构建扩展计分函数
显然E(gN(ϑ))=0,参数向量的估计值ϑ可由矩条件gN(ϑ)=0获得.事实上gN(ϑ)的方程个数为s(d+p+q) 大于未知参数的个数,因此矩估计法不可行,需诉诸于广义矩估计法,为此令
由于QN(ϑ)具有非线性形式,因此无法获得参数向量ϑ的解析表达式,需要运用迭代算法.本文中,采用Newton-Raphson迭代算法.
§3 一些实际操作问题
3.1 算法的实施步骤
设ϑ(0)为任意参数向量值,在ϑ(0)的邻域内利用Talor展式可知
第一步 利用两阶段最小二乘法获得参数估计的初始值ϑ(0);
第二步 给定第k步的迭代值ϑ(k),则第k+1步的迭代值为
第三步 不断重复第二步,直到满足给定收敛准则为止.
3.2 基矩阵的选择
对于常见的一些特殊相关结构,基矩阵M1,M2,···,Ms的选择并不困难.例如对于一阶自相关的结构,可以选择M1=IT,IT为T阶单位矩阵,M2为次对角线元素为1,其它为0的矩阵,M3为在(1,1)和(T,T)的位置为1,其它为0的矩阵,在实际应用中,M3通常省略;对于等相关结构,通常M1的选择与一阶自相关结构相同,的对角元素为0,非对角元素为1的矩阵;若相关结构不确定,则可同时使用矩阵M2和,或应用自适用估计法(具体参见文[26]).基矩阵选取方法的详细讨论可参考文[25].
3.3 节点数的选择
由于计算的复杂性,在模型估计时,无法做到同时确定样条函数的阶,节点的位置和节点的数量.一般的做法是,固定样条函数的阶,同时用等间距的方式选择节点,剩余的工作就只需选择合适的节点数.目前已有大量的节点数选择方法:近似选择法,AIC准则,BIC准则及广义交叉确证法(详细可参见文[27]).本文采用BIC准则选择节点数,其统计量为
实际操作中,通常采用网格搜素法寻找最优的节点数.
§4 渐近性质
4.1 渐近理论
A7.(i) 空间加权矩阵W的元素为已知常数,对任意空间相关系数ρ ∈(-1,1)有IN-ρW是非奇异的;(ii)W和(IN-ρW)-1的行与列元素的绝对值和均是一致有界的.
这是都是常用的假设条件,实际应用中很容易验证.假设条件A1是为了大概率保证处于分母的变量不为零;假设条件A2主要用于说明非参数估计量的收敛速度;假设条件A3表明误差项满足中心极限定理的条件;假设条件A4主要是保证可以选择到合适的样条函数,条件→0是定理证明的需要,在此条件下,函数的经验内积将足够接近其理论内积;假设条件A5为保证加权矩阵CN的特征值有界;假设条件A6 确保均值项有限,同时说明用非参数技术估计X的条件期望时的收敛速度,该条件可减弱为E(X|Z,Zθ)满足一阶连续可导,见文[28];假设条件A7是空间相关系数及空间加权矩阵的基本假设.
定理4.1在假设条件(A1)–(A7)下,连接函数的估计量实现了最优收敛速度,即
4.2 定理的证明
引理4.1在假设条件A2下,存在参数向量γ0和某个常数C,使得
证证明的细节请参见文[29].
再次由a的任意性可知‖ξ2k‖=Op((Nh)-1/2).定理结论得证.
引理4.3在假设条件A1-A7下,的特征值有界,进一步,对任意ϑ ∈ΘN(C)有
引理4.4在假设条件A1-A7下,有
证要证明式(28)中的结论成立,只要证明结论对每个分量成立即可.根据各表达式的定义可知,对k=1,···,s有
引理4.5在假设条件A1-A7下,存在常数C=C(ε),使得当N →∞时,
同理由假设条件A5,存在常数C2有
定理4.1的证明由引理4.4及4.5立即可得
式(37)说明定理4.1的结论成立.
定理4.2的证明首先类似于文[30],由引理4.4,不难证明
另一方面,根据Newton-Raphson算法,Talor展示及定理4.1的结论可知
式(39)表明
进一步由引理4.3知,存在存在系数矩阵Λ,使得
综上可得‖J2‖=Op(h2r)=op(N-1/2).
综合上述结论立即可得定理4.2的结论成立.
§5 数值研究
5.1 Monte Carlo模拟
表1为参数估计量在自相关结构下的表现.从表1可知,无论空间加权矩阵是Rook矩阵还是Queen矩阵,在ρ=0.3和ρ=0.8下,MAD值均随着个体数N的增大而下降,且数值大小逐渐接近于0,表明参数估计值与真实值的接近程度随个体数N的增加而增加,均符合大样本性质的表现;同样S.E.值也随着个体数N的增大而减少,且数值趋于0,表明估计方法的稳健性随N的增大而增大.进一步,Rook矩阵下的数值大小与Queen矩阵非常接近,说明估计方法的表现与空间加权矩阵的选择无关.表2为等相关结构下参数估计量的表现.与表1类似,可得出以下三个结论:一是估计方法的表现与空间加权矩阵的选择无关;二是参数估计量的表现符合大样本性质;三是随着N的增大,估计方法的表现越来越稳健.表3为独立结构下参数估计量的表现,与表1和表2的情况类似,参数估计量的表现符合大样本性质,估计方法的表现随N的增加而更加稳健,且与空间加权矩阵的选择无关.综上所述,所述方法在参数估计方面具有非常优越的表现,且不会因空间相关程度及空间加权矩阵的改变而改变.
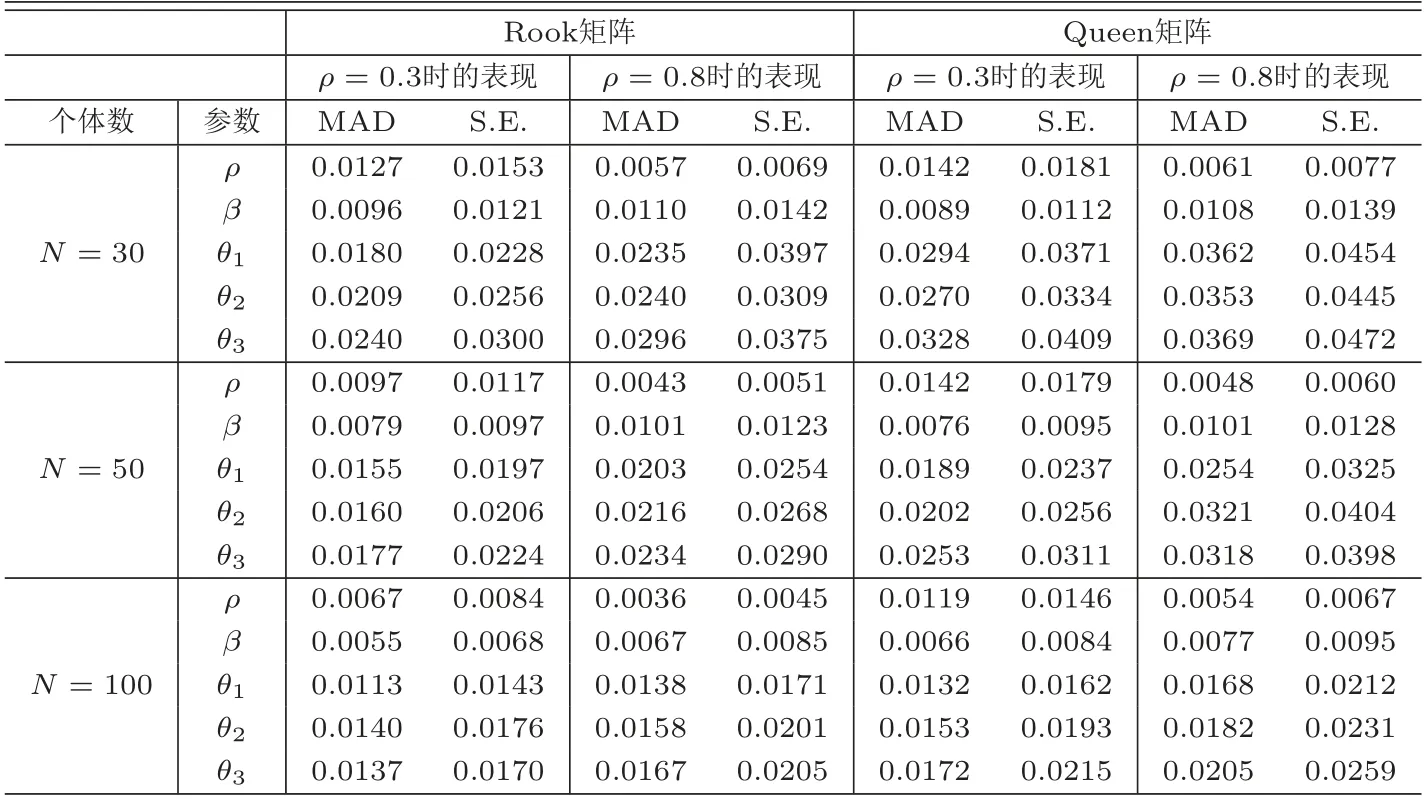
表1 自相关结构下参数估计量的表现
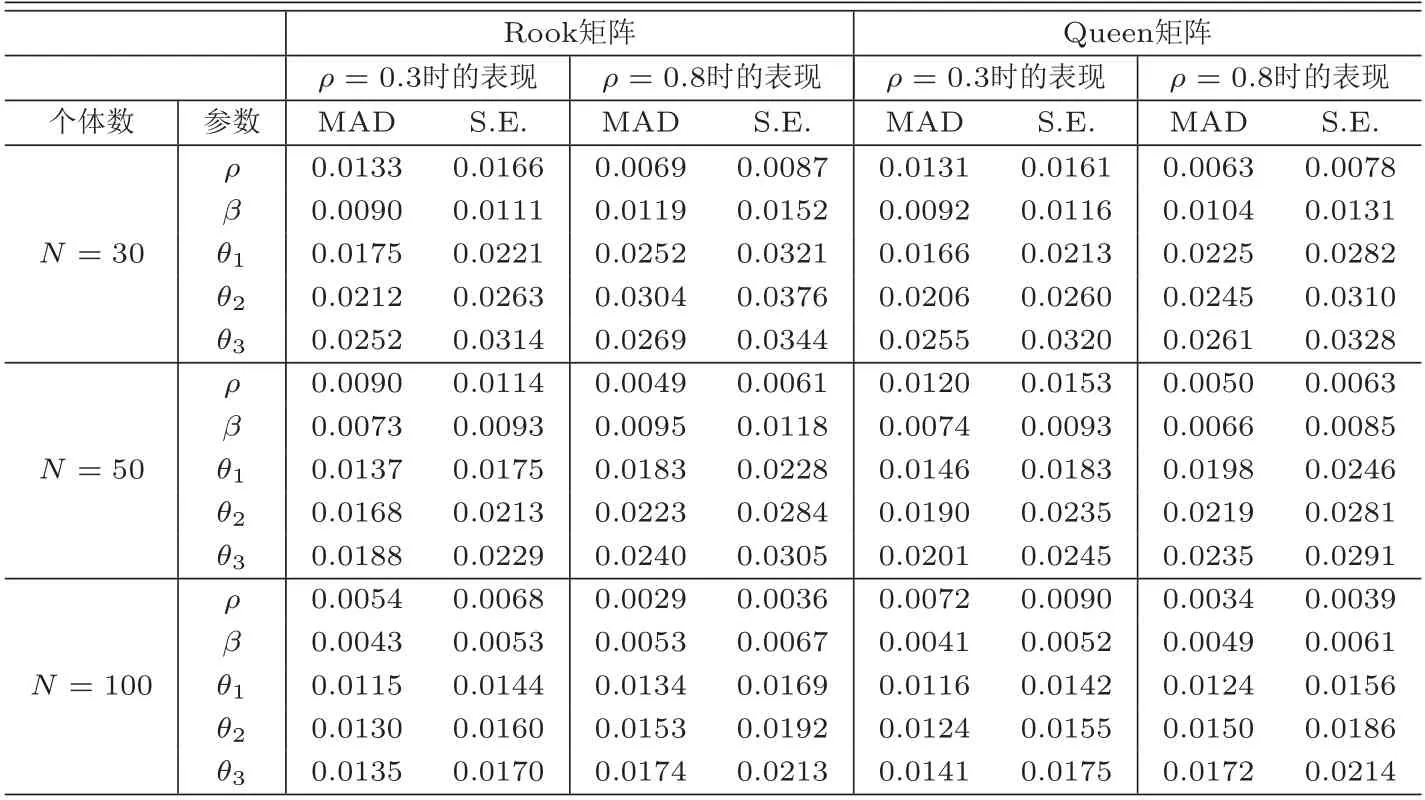
表2 等相关结构下参数估计量的表现

表3 独立结构下参数估计量的表现
表4为非参数估计量的表现.从表4的数值可以看到,在Rook矩阵和Queen矩阵下MAISE的数值相近,说明非参数估计量的表现与空间加权矩阵的选择无关.其次,在所有相关结构下,随着个体数N的增加,MAISE的数值逐渐减小,表明连接函数的估计值与真实的连接函数随着N的增加而不断接近,符合大样本性质的表现.最后,当ρ=0.3时MAISE的数值要小于ρ=0.8的数值,说明较强的空间相关性对非参数估计量具有一定的影响,但这种影响会随着N的增加而不断减少.

表4 非参数估计量的表现
例2 与两阶段最小二乘法(TLS)的比较为说明忽略个体内的相关性对估计量造成的影响,本文将所述方法与TSL法进行比较.数据产生过程与例1相同,个体数N=100,时期数T=5,zi,t的所有分量均独立来自于参数为0.2和0.5的beta分布,θ=(2/3,1/3,2/3)′,其他变量的设置与例1相同,模拟次数为500,模拟结果分别呈现在表5至表8中.
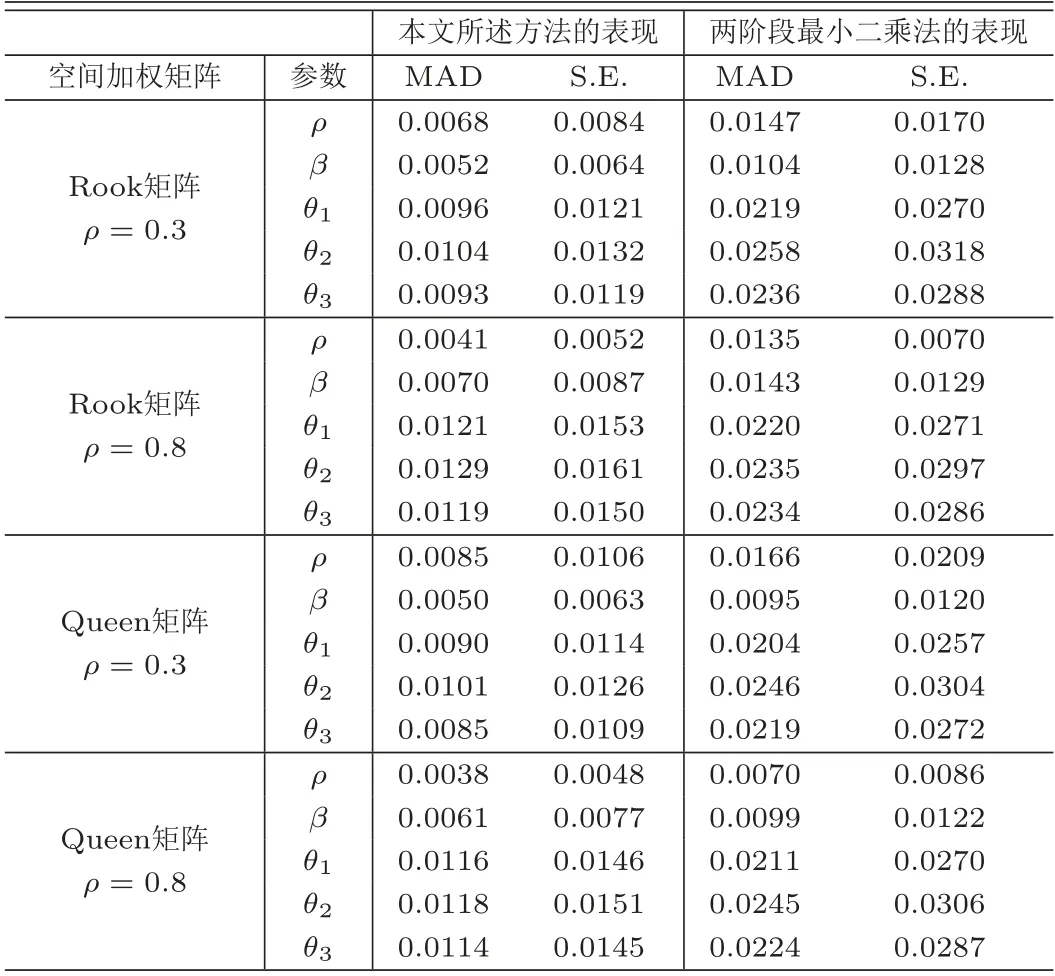
表5 估计方法在自相关结构下参数估计量的比较
表5为本文所述方法与TLS在自相关结构下参数估计量表现的比较,从表中的数值可以看到,在所有的空间加权矩阵下,对所有的空间相关系数ρ的值,本文所述方法下所有参数估计量的MAD值和S.E.值要远远小于TSL的相应数值,表明本文所述方法在参数估计方面的表现要大大优于TSL,且与空间加权矩阵的选择和空间相关系数的大小无关;表6为本文所述方法与TSL在等相关结构下参数估计量表现的比较,与表5的结果类似,在等相关结构下,本文所述方法的表现仍远远优于TSL;表7为本文所述方法与TSL在独立结构下参数估计量表现的比较;类似与自相关和等相关的情形,本文所述方法仍然要优于TSL;表8为各种情形下本文所述方法与TSL在非参数估计量表现的比较,各数值均清晰地表明,在所有情形下,本文所述方法的MAISE值要远远小于TSL,本文所述方法的表现要更优越.综上所述,当忽略个体内的相关性时,参数估计量的偏度和标准误会偏大,连接函数的估计量与真实函数的偏度增大,导致估计量的精确度降低,损害了统计的推断力.
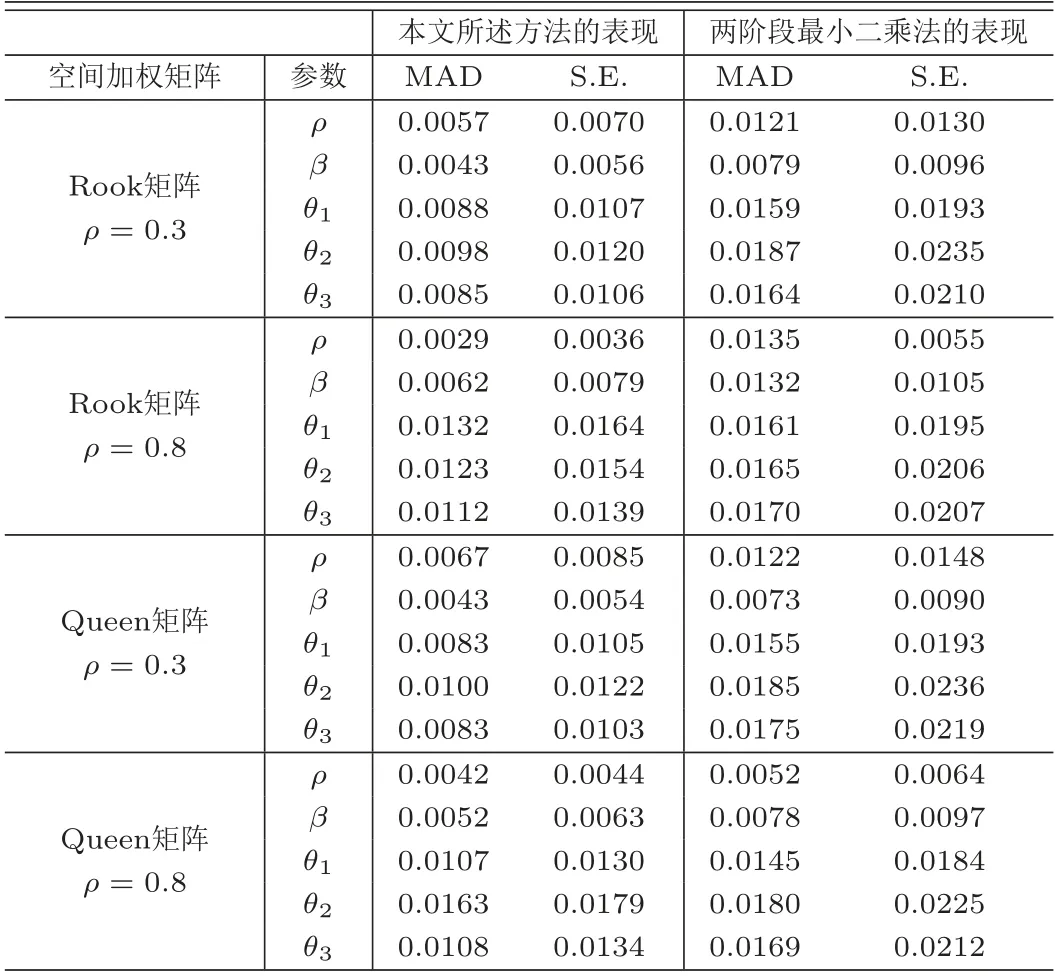
表6 估计方法在等相关结构下参数估计量的比较
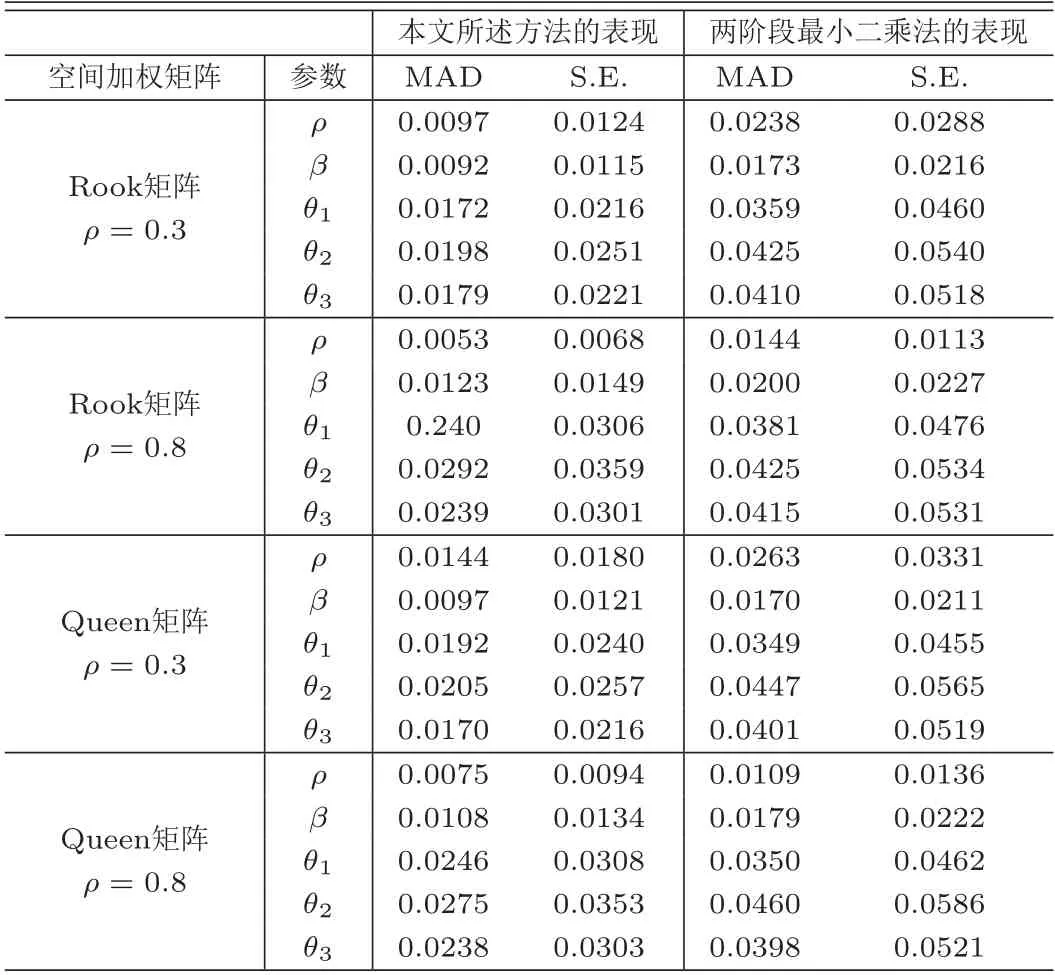
表7 估计方法在独立结构下参数估计量的比较
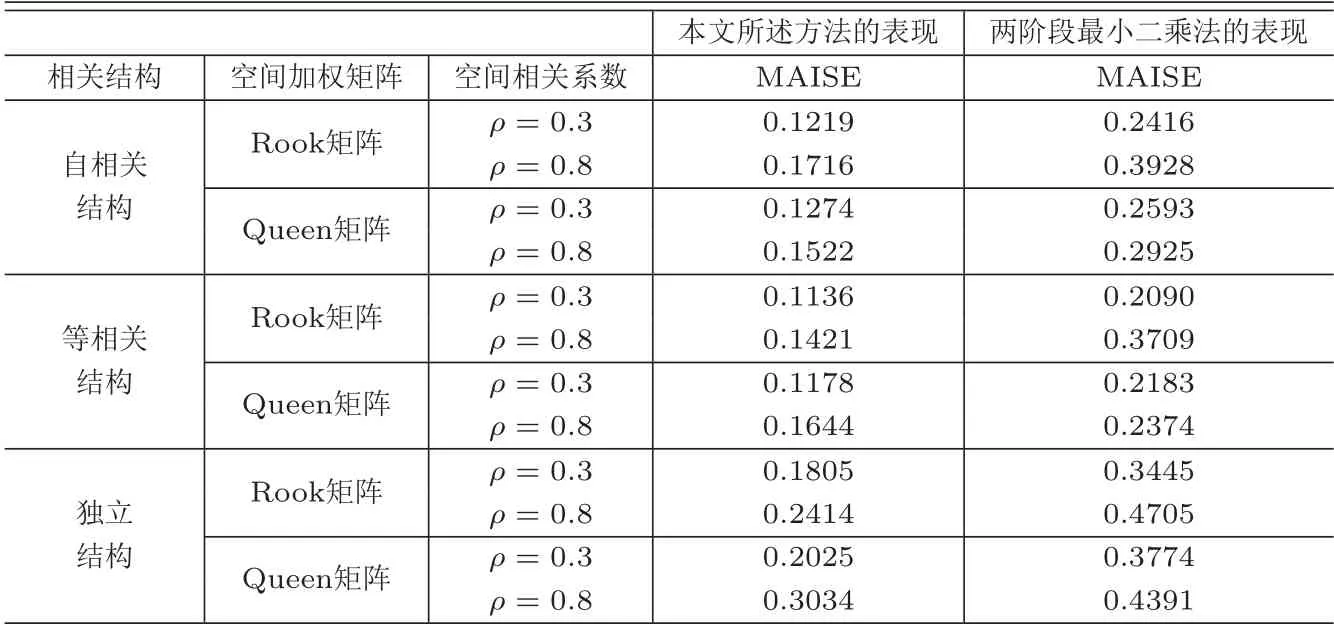
表8 非参数估计量表现的比较
5.2 真实数据应用
本节中,将本文所述模型和方法应用于分析美国各州生产力的影响因素.数据为美国48个州1970年至1986年的生产力数据,变量的选取和度量与Baltagi和Pinnoi(1995)中所使用的变量一致,因变量为各州总产值(用Y表示),影响因素有劳动输入(用L表示),私人资本(用PK表示),公共资本(用CK表示),失业率(用UNE表示),所有变量均为原始变量的对数值(除失业率外).由于主要关注本文所述模型和方法的应用,因此忽略数据测度的误差.为避免“虚假回归”,将针对差分后的变量进行分析.通过分析各变量差分与∆Y之间的散点图(限于篇幅,散点图没有在本文中报告)发现,∆L和∆UNE与变量∆Y具有非常明显的线性关系,其他变量差分与∆Y具有不同程度的非线性关系,鉴于此建立模型
其中wi,j为空间加权矩阵W中的相应元素,空间加权矩阵是根据美国48个州的地理位置,按照Queen矩阵方式计算而得;(ρ,β1,β2,θ1,θ2)′为未知参数向量;αi为第i个州的固定效应;ei,t为随机误差项;i=1,···,48;t=1,···,16.运用本文所述方法对模型进行估计,估计结果呈现在表9和图1中.
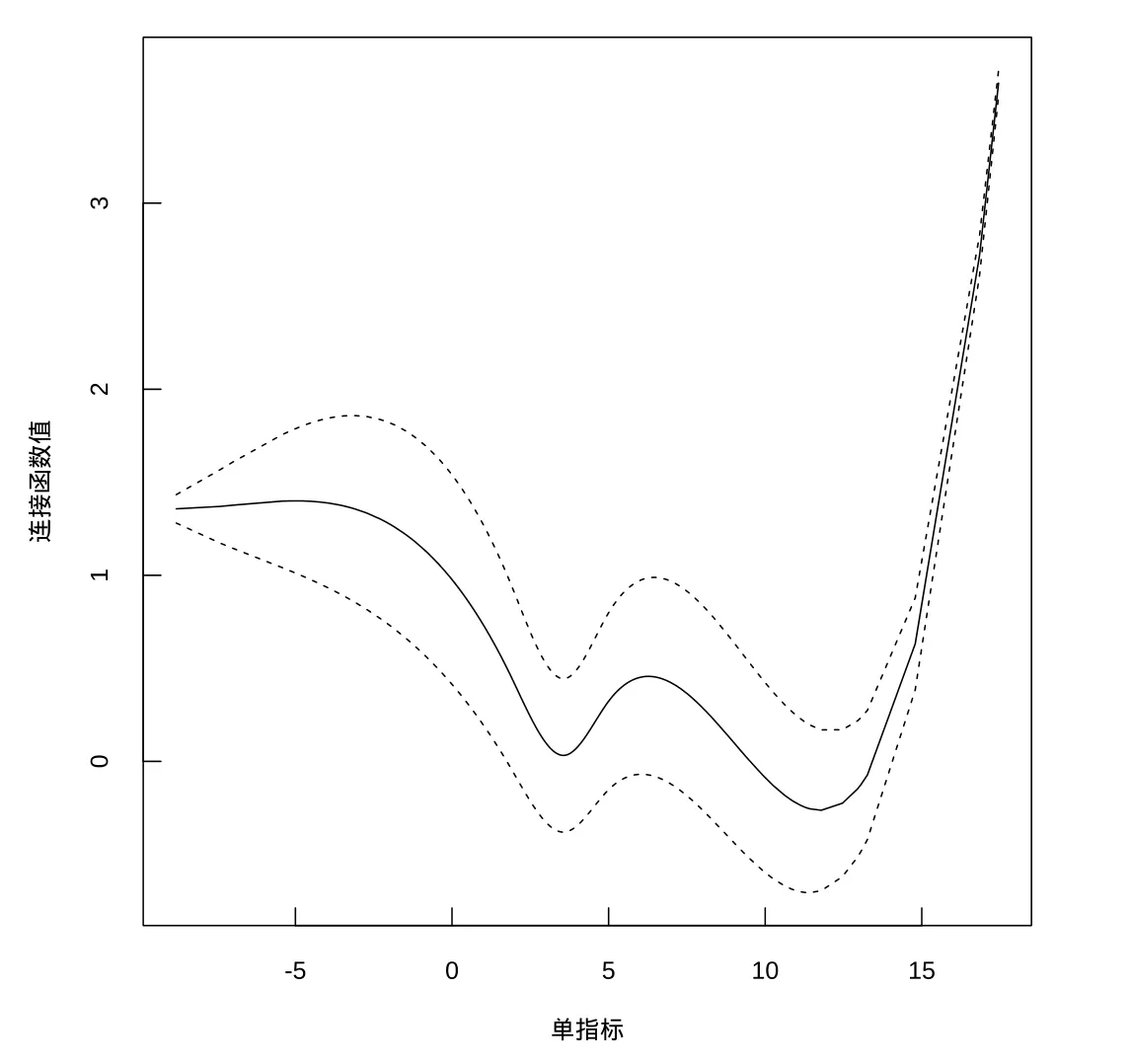
图1 连接函数估计图
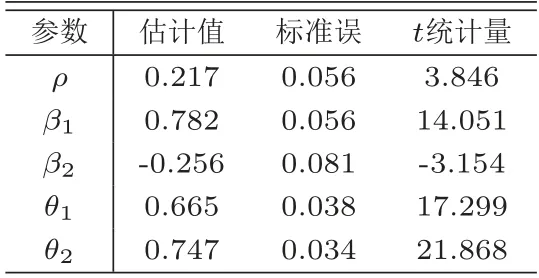
表9 各参数估计结果
根据表9中本文所述方法的估计结果,空间相关系数ρ=0.217,说明各州之间生产力的增长存在正向空间溢出效应,意味着周边地区的经济增长会带动本地区的经济增长;β1=0.782<1表明劳动输入对生产力具有正向影响作用,但生产力对劳动输入缺乏弹性,即大量的劳动输入并不能引起生产力的快速增长;β2=-0.256>-1表示失业率增长会阻碍生产力发展,但生产力对失业率同样缺乏弹性,即失业率的上升不会导致生产力的大幅下降.
图1为连接函数的估计图,图中虚线分别表示连接函数估计量的95%置信上下限(连接函数估计量置信上下限的获得方法为:首先获得样条系数估计量的置信上下限,然后类似于连接函数的估计,进而得到置信上下限的估计量).观察图1中纵坐标和横坐标数值发现,大多数情况下,资本增长率变化5个单位,生产力增长率变化不足一个单位,说明生产力对资本是缺乏弹性的;进一步用连接函数值除以单指标值作为生产力对资本弹性的度量,通过计算发现,当资本在0值附近时,生产力对资本的弹性非常大,接近于40,在其他地方的弹性均小于1,表明大部分情形下,生产力对资本缺乏弹性,只有在资本相当匮乏时,生产力对资本才富有弹性.此外,由θ1和θ2大于零表明,私人资本增长率和公共资本增长率对生产力增长率的影响均与单指标变量的影响方向一致,因而可推知,在大部分情形下,生产力对私人资本和公共资本是缺乏弹性的.
§6 结论及总结
本文研究了固定效应下个体内存在相关性的部分线性单指标空间自回归面板模型.该模型不仅存在空间内生性,个体内还具有某种相关性,而且受到固定效应的干扰.为有效地估计模型,首先采用B样条函数近似连接函数,采用LSDV法消除个体效应,再根据模型的特点,利用均衡模型的均值项与原模型的误差项不相关的事实,结合二次推断函数法,为模型构建了新的估计方法.该方法不仅消除了个体效应的干扰和空间内生性,还可以捕捉个体内的相关性,提高了估计量的有效性.进一步,在一些正则条件下,推导了连接函数估计量的收敛速度和参数估计量的渐近正态性.同时,采用Monte Carlo模拟评估了估计方法在有限样本下的表现,结果发现,本文所述方法在有限样本下的表现符合大数定律,且明显优于忽略个体内相关性下的估计方法.最后,利用本文所述方法分析了美国各州生产力增长率的影响因素,结论表明,劳动输入增长率对提高生产力增长率具有显著的正向线性影响,失业率增长量会阻碍生产力增长率的提高,私人资本增长率和公共资本增长率对生产力增长率具有不同程度的非线性影响.
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
统计与决策(2017年2期)2017-03-20
现代营销·学苑版(2016年12期)2017-01-23
红土地(2016年3期)2017-01-15
数学物理学报(2016年5期)2016-08-24
系统工程与电子技术(2016年2期)2016-04-16
电测与仪表(2015年6期)2015-04-09
海峡姐妹(2015年9期)2015-02-27
数学物理学报(2014年3期)2014-03-11
杭州科技(2014年3期)2014-02-27
