
基于SVM的流形正则堆叠胶囊自编码器优化算法
2023-12-14 00:46王鲁娜杜洪波朱立军
湖北民族大学学报(自然科学版) 2023年4期
王鲁娜,杜洪波*,朱立军
(1.沈阳工业大学 理学院,沈阳 110870;2.北方民族大学 信息与计算科学学院,银川 750021)
近年来,自编码器已成为深度学习模块无监督学习中的重要学习方法,被成功应用于图像分类[1-5]、图像识别[6-8]、异常检测[9-11]等诸多领域。自1986年传统自编码器被提出后[12],已被广泛研究并产生了各种改进。2008年Vincent等[13]人为地对干净的输入信号加入噪声进行破坏,提出了降噪自编码器,使得自编码器模型更具有鲁棒性。通过对传统自编码器增加一些稀疏性约束,研究人员提出了稀疏自编码器,极大地降低了数据维度,提升了模型性能[14]。因卷积神经网络发展快速且表现优异,卷积自编码器随之产生[15]。其通过对输入信号进行线性变换,实现了权重共享,很好地保留了图像特征信息中的空间信息。2014年提出的变分自编码器利用反向传播算法进行快速训练[16],自动生成与训练数据类似的输出,其主要用于数据生成领域。自编码器还有更多复杂的变种,袁非牛等[17]对传统自编码器及各种改进的自编码器进行了详细的理论和创新点分析,对其实际应用也进行了相关介绍。
堆叠胶囊自编码器(stacked capsule autoencoder,SCAE)是继Hinton团队的向量胶囊网络和矩阵胶囊网络后的第3个胶囊网络模型[18-20]。相比于有标签学习的向量胶囊和矩阵胶囊,堆叠胶囊自编码器属于无监督网络模型,其将图像中的部件先利用二维空间进行重建,再通过重构的方式将部件与整体的关系解释出来。Dai等[21]发现SCAE存在安全漏洞,因此先在编码器中加入扰动攻击,使得图像被错误分类,然后对该攻击进行评估,结果表明其具有较高的成功率和隐蔽性。Xiang等[22]针对SCAE中的固定模板,提出可以动态生成的模板——动态胶囊自编码器(capsule autoencoder based on dynamic part representation,DPR-CAE),极大提高了模型的鲁棒性。2022年赵祯[23]提出了孪生堆叠胶囊自编码器,采用先无监督训练、后微调的方法,提高了图像识别的准确率。王鲁娜等[24]针对SCAE模型对图像局部特征挖掘不充分、检测速度慢的问题,提出了基于流形正则的堆叠胶囊自编码器(stacked capsule autoencoder based on manifold regularization,MRSCAE)优化算法,将流形正则项引入损失函数中,极大提高了模型的训练速度和图像分类准确率。
另外,在将自编码器应用于图像分类的领域时,支持向量机(support vector machine,SVM)作为无监督编码器模型的分类器似乎更为优异[25-27]。因此,在前期MRSCAE模型研究基础上,进一步对模型进行改进,提出SVM-MRSCAE模型,主要研究内容如下:
1) 由于SCAE模型使用K均值(K-means)算法对图像数据集进行分类,但并不适合形状特征复杂的数据集,因此采用SVM对图像数据集进行分类,并采用不同核函数进行对比实验,以获得更精确的分类结果;
2) 对于SVM-MRSCAE模型,针对不同编码类型以及不同噪声类型进行对比实验,并利用MNIST和Fashion MNIST图像数据集来做分类任务,综合实验结果进行对比,验证该模型的有效性。
1 理论基础
1.1 SCAE模型介绍
SCAE模型由部件胶囊自编码器(part capsule autoencoder,PCAE)和目标胶囊自编码器(object capsule autoencoder,OCAE)组成。当图像被输入到该模型后,首先在PCAE阶段,模型提取构成图像中目标部分的姿态、存在、特征,并存储在部件胶囊中。然后在OCAE阶段,模型使用Set Transformer机制将这些提取出的部件组合成不同对象,计算每个对象的存在和姿态,并将它们存储在目标胶囊中,以进行自动编码操作。最后,使用K-means分类器预测图像的标签。

(1)

在PCAE阶段通过最大化式(1)的图像似然来训练,而在OCAE阶段利用Set Transformer机制作为这个阶段的编码器,从而实现模板的排列不变性和尺度不变性。在OCAE阶段,将所有不同的输入点均编码到K个目标胶囊中,每个目标胶囊k都由1个目标与观察者视角(object viewer,OV)矩阵、存在概率ak,m∈[0,1] 和1个胶囊特征向量ck组成,将每个输入部件建模为高斯混合模型,最终在OCAE阶段得到的部件损失Lpa可表示为
(2)

SCAE模型通过最大化式(1)和式(2)的对数概率进行训练,但仅通过上述损失训练无法得到更优秀的模型。为了训练鲁棒性更好的编码器,引入稀疏性损失。对于1个具有M个部件胶囊和K个目标胶囊的B尺寸的小批量集合,定义稀疏性损失Ls为
(3)

1.2 自编码器类型介绍
1.2.1 线性自编码器 线性自编码器(linear autoencoder)基于最优化方法与反向传播算法进行迭代学习。利用输入数据x本身作为监督,线性编码器可得到1个映射关系,并最终得到1个重构输出Y。其编码和解码过程可描述如下:
编码过程:h=σe(W1x+b1),
(4)
解码过程:Y=σd(W2h+b2),
(5)
其中,h为特征图,W1、b1、W2、b2分别为编码和解码阶段的权重和偏置,σ(·)表示非线性变换函数。文中所提模型采用线性编码器,因此令σ(·)=1。
1.2.2 卷积自编码器 卷积自编码器(convolutional autoencoder)利用卷积层和池化层替代了全连接层。设初始化k个卷积核(W),每个卷积核均加入1个偏置b,与输入数据x进行卷积后生成k个特征图h,则有公式如下:
hk=fconv(x·Wk+bk),
(6)
其中,fconv(·)表示卷积操作。解码层利用反卷积操作将输入特征进行上采样,对得到的hk特征图进行重构,可表示为
Y=fdeconv(hk·W-k+c),
(7)
其中,fdeconv(·)表示反卷积操作,c为偏置。
1.2.3 基于自注意力机制的卷积自编码器 由于自注意力机制可以重点关注图像的重要特征,从而提高模型精度,因此被广泛应用于图像特征提取和图像识别等机器学习任务中。在计算机视觉领域,自注意力机制可表示为
(8)
其中,dk为缩放因子,其取值表示K的维度,T表示转置。Q,K,V可分别由下式表示:
Q=fflatten(x·θ),
(9)
K=fflatten(x·φ),
(10)
V=fflatten(x·g),
(11)
其中,θ、φ、g均为神经网络中注意力模块的超参数,fflatten(·)表示全连接操作,x表示输入数据。
2 SVM-MRSCAE模型介绍
在自编码器进行图像分类领域中,SVM作为无监督模型的分类器,在对模型提取的图像特征分类方面表现更为优异。因此在前期建立的MRSCAE模型基础上进一步改进,提出SVM-MRSCAE模型。
2.1 SVM介绍
SVM在机器学习的图像分类领域中有着广泛应用,该模型将每个样本数据逐一映射到高维空间中,空间中每个点都代表1个样本数据,以此区分出不同的样本点类型。在线性不可分问题中,SVM决策边界的超平面表示如下所示:

表1 在不同数据集上不同类型编码器的最优分类准确率Tab.1 Optimal classification accuracy of different encoders on different datasets
ωTφ(X)+b=0,
(12)
其中,X为图像特征数据,T表示转置,b为偏置,ω为超平面的法向量,φ(·)表示映射函数。由于映射函数形式复杂且多种多样,内积公式难以计算,因此设计了通过核函数来回避内积的显式计算。
核函数的选择对SVM模型分类效果的影响异常重要,但迄今为止还没有公认较好的选择标准。为获得更精确的分类结果,文章将不同的核函数加入SVM中,并对其进行对比实验,以求选择出更适合所提模型的核函数。
2.1.1 线性核函数 线性(linear)核是基本的SVM线性可分核函数,其公式可表示为
(13)
其中,X1、X2表示图像特征数据。
2.1.2 多项式核函数 多项式(polynomial)核是线性核的更广义表示,适用于正交归一化数据,其公式可表示为
(14)
其中,n表示维度,且n≥1。
2.1.3 Sigmoid核函数 Sigmoid核的全局收敛性能较好,其公式可表示为
(15)
其中,a、b都为数值参数,且a,b>0。
2.1.4 高斯径向基核函数 基于高斯径向基(Gaussian radial basis function,RBF)核函数的SVM具有较强的学习能力,当没有数据的先验知识时,合适的参数往往会使得RBF核函数取得不错的效果,其公式可表示为
(16)
其中,γ代表1种数值参数,默认情况下一般取γ=1。
2.2 SVM-MRSCAE模型
在使用不同类型的编码器对图像特征进行提取时会产生不同的效果。文中采用3种不同的编码类型,即线性自编码器、卷积自编码器、基于自注意力机制的卷积自编码器进行对比,以探究更适合MRSCAE模型的编码器类型。
SCAE模型使用K-means聚类算法找到多个簇,然后使用二分图匹配找到分类误差的排列组合;然而K-means聚类算法并不适合形状特征太复杂的数据。在无监督图像分类领域,SVM的分类精度相比于K-means更高,因此选择SVM构建所提模型,该模型结构如图1所示。
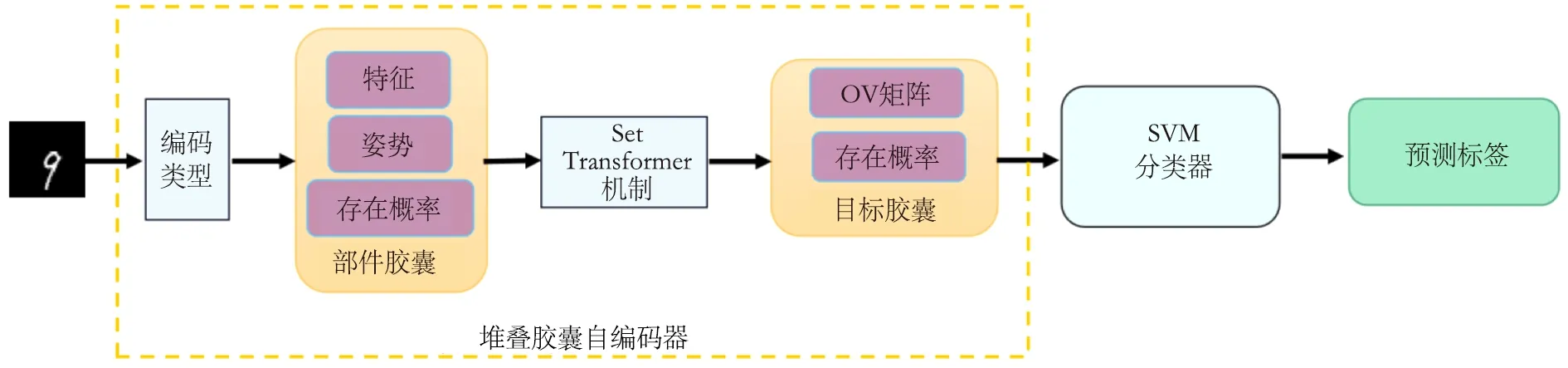
图1 SVM-MRSCAE模型的结构Fig.1 Structure of SVM-MRSCAE model
由图1可知,SVM-MRSCAE模型利用不同类型编码器对图像特征进行提取,而后将其送入PCAE阶段中的部件胶囊,再通过OCAE阶段重构出图像,之后利用SVM将图像进行分类,最终得到预测结果。
在图像特征提取阶段,不同类型编码器对图像进行特征提取时会产生不同的效果。采用1.2所述的3种编码器:线性自编码器、卷积自编码器、基于自注意力机制的卷积自编码器。其中,卷积自编码器中的卷积操作可以用来处理图像局部邻域中的特征信息,并将原始图像的固定特征向量传递给解码器,最终由解码器重构为具有原始图像特征的新图像。卷积自编码器在向量转化过程中可能会损失一些重要的图像特征信息,而基于自注意力机制的卷积自编码器可以保留更多重要的图像特征信息,增强模型的特征提取能力,并降低网络计算消耗,提高模型特征提取的精确度。将上述几种编码器进行对比实验,探究更适合所提模型的编码器类型。确定获得特征提取效果最好的编码器类型后,再经SCAE过程,使模型通过采用基于不同核函数的SVM对图像数据集进行分类对比实验,从而提升最终分类精度,确定更适合所提模型的分类器。
3 实验与结果分析
3.1 数据集及实验环境
分别利用MNIST和Fashion MNIST数据集对模型进行测试和评价。
MNIST数据集中样本图像为28像素×28像素的灰度图像,由250个不同的人手写的数字图片组成,其中包含了10000张验证集图像及其标签和60000张训练集图像及其标签。
与MINIST数据集类似,Fashion MINIST数据集中的样本图像也为28像素×28像素的灰度图像,涵盖了10种不同服饰类别,总计70000张图像。
实验硬件配置为DELL T640深度学习GPU运算塔式服务器主机,显卡为RTX3070,内存为64GB。仿真环境为Python3.6,学习框架为TensorFlow1.15。在训练过程中,设置迭代次数为25000次,批量大小设置为128。
3.2 结果与分析
为确定不同编码器类型对图像特征进行提取时产生的不同效果,在PCAE阶段,利用线性自编码器、卷积自编码器、基于自注意力机制的卷积自编码器进行对比实验。不同类型编码器对MNIST和Fashion MNIST数据集特征提取的准确率分别如图2、图3所示。

图2 MNIST数据集上编码器特征提取准确率
由图2可知,在MNIST数据集中,基于自注意力机制的卷积自编码器有更明显的优势,其分类准确率可达到0.9446,与线性自编码器和卷积自编码器相比有较大优势。由图3可知,在Fashion MNIST数据集中,基于自注意力机制的卷积自编码器与卷积自编码器分类效果相比,两者差距较小,前者效果略优。在迭代过程中,不同类型编码器的最优训练分类准确率如表1所示。由表1可知,无论是在MNIST数据集上,还是在Fashion MNIST数据集上,基于自注意力机制的卷积自编码器准确率都更高,相比于线性自编码器和卷积自编码器来说,提取效果更好。因此,选择采用基于自注意力机制的卷积自编码器对数据集中的图像进行特征提取,并利用SVM对图像数据集进行分类,之后采用不同核函数进行对比实验,以选取更适合的核函数来获得更精确的分类结果。
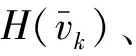
(17)
最终得到不同核函数训练集和验证集的对比分类准确率,如表2所示。在该实验中,为了更好地测试模型的鲁棒性,均加入了均匀噪声进行干扰。
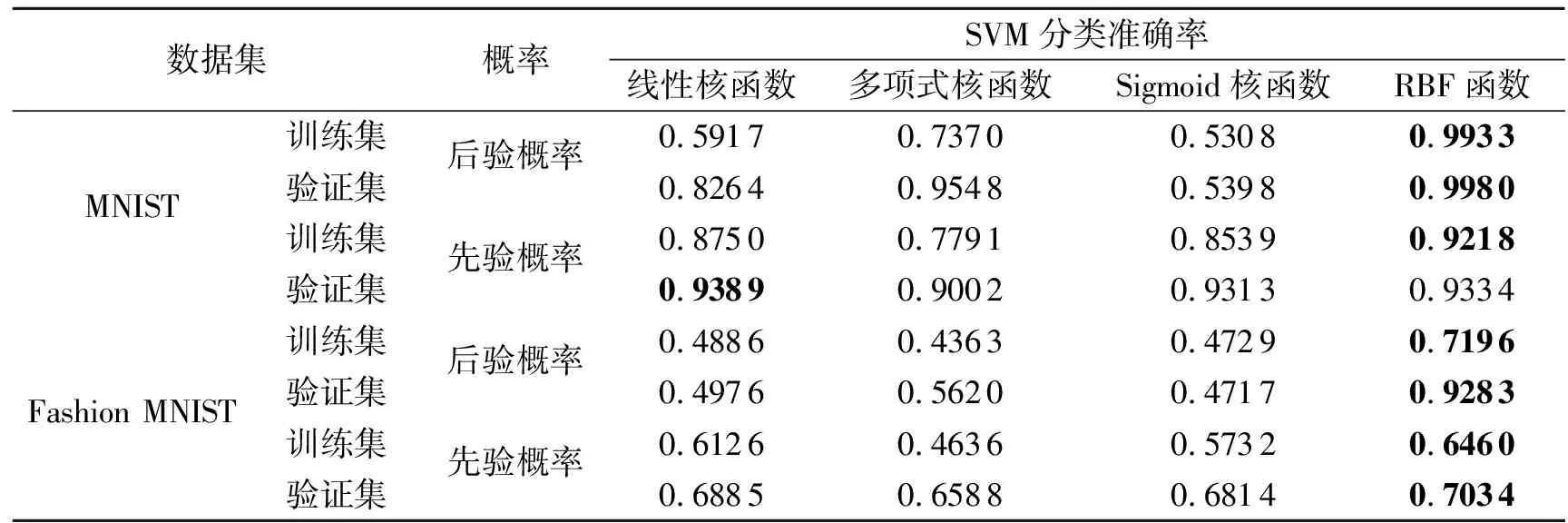
表2 不同核函数的SVM分类准确率Tab.2 Classification accuracy of SVM for different kernel functions
由表2可知,在MNIST数据集中,基于RBF核函数的SVM分类准确率高达0.9980,相比于其他核函数有一定程度的提高;在Fashion MNIST数据集中,也达到了0.9283的分类准确率,相比于其他核函数体现出很大的优势,有明显提高。
为了进一步对基于SVM的堆叠胶囊自编码器进行评价,对模型图像特征提取时,在OCAE阶段,实验中加入了不同类型噪声(随机均匀噪声、高斯噪声、logistic噪声)进行对比。在MNIST和Fashion MNIST数据集上的分类效果分别如图4、图5所示,其中,不同颜色代表不同数据类别。

图4 MNIST数据集上不同噪声分类效果Fig.4 Classification effect of MNIST dataset based on different noises
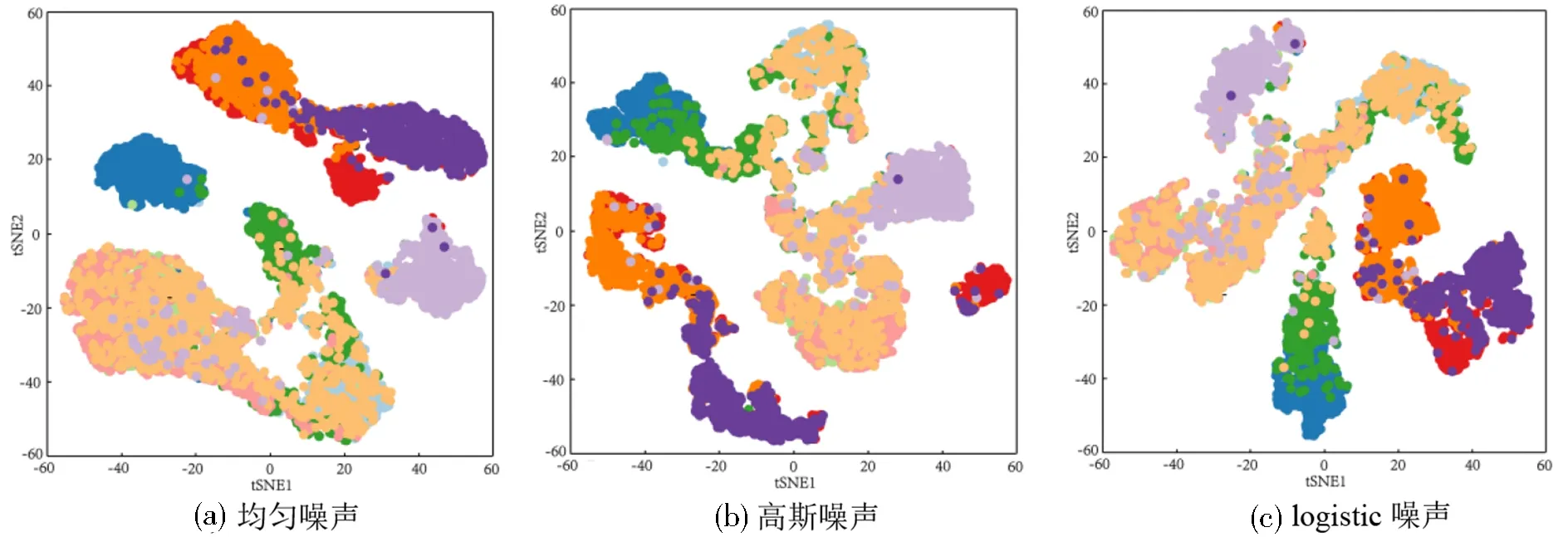
图5 Fashion MNIST数据集上不同噪声分类效果Fig.5 Classification effect of Fashion MNIST dataset based on different noises
由图4可知,在MNIST数据集中,加入均匀噪声和高斯噪声的图像,仅有几个异常点未被正常分类,而加入logistic噪声的分类异常点相对较多。由图5可知,在Fashion MNIST数据集中,加入均匀噪声、高斯噪声、logistic噪声的图像,分类效果并无太大差距。在不同噪声的影响下,基于RBF核函数的SVM对图像验证集的分类准确率如表3所示。由表3可知,加入噪声后的MNIST和Fashion MNIST数据集图像,所提模型对其分类准确率较为稳定,数据上下波动较小,表现出良好的鲁棒性。
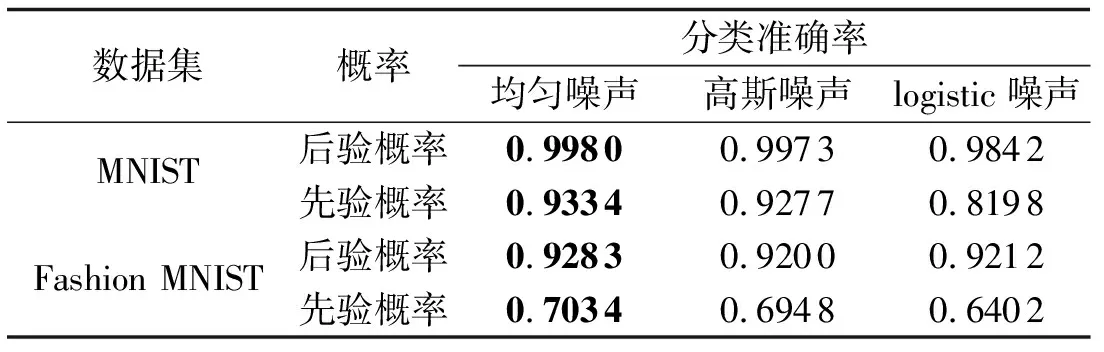
表3 SVM针对不同噪声影响的分类准确率Tab.3 Classification accuracy of SVM for different noise effects
所提SVM-MRSCAE模型先在PCAE阶段将图像解析成部件胶囊,而后在OCAE阶段利用目标胶囊自编码器对学习到的特征信息进行重构,最终利用SVM对图像数据集进行分类。K-means是无监督学习算法中传统的划分聚类算法[28],自编码器(autoencoder,AE)[29]也是无监督编码器的主要基础框架;另外,SWAE模型[30]将sliced-Wasserstein距离应用到无监督自编码网络框架中。因此,为进一步测试所提模型的性能,在相同实验环境下,将K-means、AE、SWAE、SCAE、MRSCAE与所提SVM-MRSCAE模型在MNIST和Fashion MNIST数据集上进行对比实验,分类准确率如表4所示。

表4 不同模型的图像分类准确率对比Tab.4 Image classification accuracy comparison of different models
由表4可知:1) 相比于传统的K-means、AE以及改进后的深度无监督模型,所提SVM-MRSCAE模型准确率有很大提升,说明采用基于SVM的堆叠胶囊自编码器可以得到更加精确的分类效果。2) 在MNIST数据集中,不同模型的分类准确率有很大的差距,相比于SCAE与MRSCAE模型,所提SVM-MRSCAE模型分类准确率提高了0.0099~0.0125。3) 在Fashion MNIST数据集中,所提SVM-MRSCAE模型分类准确率明显高于其他无监督分类模型,为0.9283,相比于SCAE与MRSCAE模型,提高了0.2026~0.2949,说明采用基于RBF核函数的SVM对数据集分类时,可达到更高的分类精度。
4 结论
SCAE模型利用K-means算法对提取出的图像信息进行分类,然而该方法对形状特征复杂的图像数据集分类效果差,因此,提出了SVM-MRSCAE模型。在前期建立的MRSCAE模型基础上进一步改进,在PCAE阶段采用不同类型编码器,对线性自编码器、卷积自编码器、基于自注意力机制的卷积自编码器进行对比,确定表现优异的编码器类型;并采用基于不同核函数的SVM对加入不同类型噪声的图像数据集进行分类,利用不同核函数的对比实验,获得更精确的分类结果。通过在MNIST和Fashion MNIST数据集上的实验结果发现,相比于MRSCAE模型,提出的SVM-MRSCAE模型分类准确率分别提高了0.0099和0.2026,所提模型获得了更好的分类精度。但与目前较为热门的有监督网络模型相比,采用堆叠胶囊自编码器的SVM-MRSCAE模型在更复杂、更现实的应用场景上使用效果并不理想,如何对其进行改进,使其在现实场景中也能获得优良效果还有待下一步的研究。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
成都信息工程大学学报(2018年3期)2018-08-29
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
