
基于LSTM和灰色模型的股价时间序列预测研究
2023-12-16 04:46韩金磊熊萍萍孙继红
南京信息工程大学学报 2023年6期
韩金磊 熊萍萍 孙继红
股价预测;综合预测;文本分析;误差修正;长短期记忆网络(LSTM);灰色模型
0 引言
股权融资是直接融资的一种重要渠道,能够将现实生活中多余的资金筹集起来,缓解融资约束.在一个成熟的市场上,股票的价格应当反映股票的内在价值.然而,内在价值的判定涉及折现率等一系列问题,很难做出精确的度量.在投资时,多数投资者所关注的仅是些常见的技术性指标和基本财务指标,但即使在资本市场发达的美国依然很难达到强有效或者半强有效市场,股票价格不免遭到国家政策、地缘政治、投资者情绪等突发性宏观或微观因素的影响.因此,在进行投资时,对股价做一个较为综合的考量,能帮助投资者降低投资风险,具有一定现实意义.
股价数据具有非线性、非平稳、高噪声、强时变性等非常显著的特征,对股价的预测具有一定挑战.纵观已有研究,早期的研究主要运用技术分析或经典时间序列模型.其中,技术分析是结合股票的成交量、成交价格等常见的市场指标来判定股价走势.研究者常结合时间序列模型来预测股价,常用的模型有差分整合移动平均自回归(ARIMA)模型[1]、针对金融数据波动聚集效应的广义自回归条件异方差(GARCH)模型[2]及ARIMA模型的变种——向量自回归(VAR)模型[3].除传统的计量模型外,灰色模型[4]、BP神经网络模型[5]以及模糊理论[6]在股价预测中也有较多应用,但这些模型存在一定的缺陷,即对非线性、长期时间序列的效果较差.
随后,学者们对各种模型进行了结合与改进.针对模型中存在的多重共线性问题,使用主成分分析(PCA)[7]或LASSO方法[8]进行变量的降维筛选.参数的优化也是其中的改进方向之一,智能优化算法借鉴自然中常见的现象设计算法,因原理简单、收敛速度快成为较常用的工具,其中,细菌群体趋药性、果蝇、遗传优化等算法在处理模型的最优权值结构中有广泛的应用,且多应用于超参数较多的BP、Elman神经网络以及非线性支持向量机等机器学习模型[9-12].鉴于模型各有针对性,有学者运用ARIMA、GM(1,1)、RBF神经网络等多个模型构成了一个集成预测结果[13].有研究提出一种联合卷积神经网络(CNN)和长短期记忆网络(LSTM)方法的预测模型,使用CNN提取股价的图像特征,使用LSTM提取股价的时序特征[14].针对股价非线性非平稳的特征,研究者使用小波分析对股价自身或者是股价的影响因素先进行分解,再建立ARIMA模型、BP神经网络或支持向量回归机(SVR)模型进行预测与重构,也获得了不错的效果[15-18].同小波分解一样,经验模态分解(EMD)原是工程领域用于分解复杂信号的一种方法,由于其对非线性非平稳序列更好的适用性广受研究者青睐,与长短期记忆网络(LSTM)、非线性孪生支持向量回归机(TSVR)等模型结合可以有效地预测股价[19-20].
随着人工智能和机器学习的发展,更多研究涉及深度学习[21].长短期神经网络(LSTM)能有效提取股价序列中的信息且在一定程度上缓解循环神经网络(RNN)梯度消失和梯度爆炸的问题[22],在股价时间序列中得到了广泛应用.有研究选取技术性、基本面指标基于LSTM、门控循环单元结构(GRU)模型构建混合神经网络,同时,多延迟嵌入张量处理技术(MDT)与注意力机制(CBAM)也被较好地与LSTM模型相结合[23-24].近年来,研究者开始关注一些投资者心理方面的因素.百度搜索指数、新浪微博情绪指数被证实对股价的短期预测具有一定的作用[25-27].机器学习为这种非结构化数据的处理提供了技术支持,媒体报道、公司新闻、微博评论等非结构化数据被用于提取情绪时间序列[28-30].随后,有研究在此基础上考虑了财务指标、技术性指标和网络舆情3种信息来源,使用支持向量分类器(SVM)对股价的涨跌进行预测[31].
结合已有文献,不难发现研究中还存在着值得改进的方面.首先在考虑特征变量时存在过于随意或考虑不足的问题.其次,结合文本对股价进行分析的文献相对较少,且对股价的文本分析往往只采用词典法,然而所用的金融词典并不完善,在反映投资者情绪时效果可能欠佳.另外,残差项作为预测值与真实值的误差往往包含了许多未被利用到的有用信息,但大多数研究者对此关注甚少.针对上述问题,本文提出了以下解决方案:1)考虑基本面和技术分析及投资者情绪等多层面指标作为特征对股价问题进行分析和预测,从多个层面选取特征变量;2)尝试创建股市语料库,并使用朴素贝叶斯的方法进行训练,对投资者的每日情绪指数进行较为精确的测算,以便更好地衡量投资者情绪;3)运用对小样本常用的灰色GM(1,1)模型对预测与真实值的残差项进行修正,更加充分地挖掘股价内在信息.
1 方法与原理
1.1 LSTM模型
步骤1:决定细胞中丢弃的信息,该操作由遗忘门来完成.首先读取当前输入xt和前神经元信息ht-1,由遗忘门ft来决定丢弃的信息,具体计算公式如下:
ft=σ(Wf[ht-1,xt]+bf).
(1)
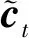
it=σ(Wi[ht-1,xt]+bi),
(2)
(3)
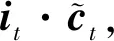
(4)
步骤4:确定输出,使用sigmoid层确定细胞状态中输出的部分,接着将细胞状态通过tanh进行处理,并将其和sigmoid层输出相乘,具体计算公式如下:
ot=σ(Wo[ht-1,xt]+bo),
(5)
ht=ot·tanh(ct).
(6)
1.2 GM(1,1)模型
灰色系统理论是一种针对小样本、贫信息的数据挖掘方法,在部分信息已知,部分信息未知的灰状态下,具有十分优良的性能.GM(1,1)是经典灰色模型,能够简单有效地挖掘出数据的内在信息[33],主要的建模步骤如下:
设:X(0)=(x(0)(1),x(0)(2),…,x(0)(n))为系统特征变量序列,其中:x(0)(k)≥0,k=1,2,…,n;X(1)为X(0)的一阶累加生成(1-AGO)序列;Z(1)为X(1)的紧邻均值生成序列,见式(7)—(8).
(7)
k=2,3,…,n.
(8)
(9)
k=1,2,…,n.
(10)
进一步,对式(10)进行累减还原,并求出对应X(0)的时间响应式,计算过程见式(11)—(12),其中α(1)表示一阶累减生成算子.
k=1,2,…,n,
(11)
k=1,2,…,n.
(12)
1.3 综合预测与残差修正的主要步骤
本文所采取的综合预测与残差修正的主要步骤如下:
1) 获取基本面指标;
2) 爬取东方财富网的股评、百度指数;
3) 使用SnowNLP模型进行情绪指数的计算;
4) 使用自适应提升法(AdaBoost)模型进行特征变量的提取,并参考方差膨胀因子(VIF)进行取舍;
5) 使用多变量LSTM模型对股价进行预测;
6) 对预测结果的残差项进行修正;
7)评估模型.
预测模型的技术路线如图2所示.
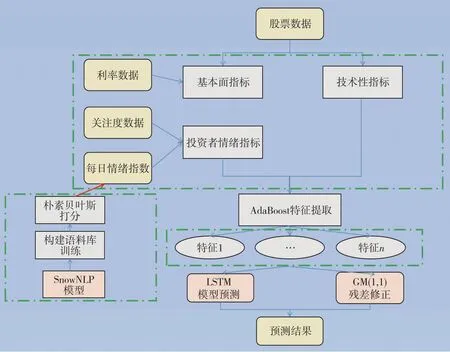
图2 预测模型的技术路线Fig.2 Technical route of stock price time series prediction model
2 模型构建
2.1 数据来源
本文所选的数据大致有3个来源,其中:股价用R语言中的pedquant包进行获取,计算相关技术性指标和基本的财务指标(财务指标如权益净利率等仅在年报、半年报、季报才能获得,而股价是日度数据,因此,仅选取市盈率等指标);利率选取了上海银行间同业拆放利率作为市场无风险利率,其对应的数据来源于官网(https://www.shibor.org/shibor/),汇率的数据来源于中国货币网(https://www.chinamoney.com.cn/),选取的是人民币兑美元的汇率;投资者情绪相关的数据源于东方财富网(http://guba.eastmoney.com/)及百度指数官网(https://index.baidu.com/),这些数据主要使用Python爬取及处理,将在下一部分进行详细描述.数据时间范围为2021年7月12日至2022年4月25日,剔除不交易的日期,共计191天.为验证模型的稳健性,选取上证指数(1A0001)以及格力电器(000651)两组数据,并着重对格力电器的股价进行分析及预测.
2.2 变量筛选
为防止过拟合、多重共线性等问题,按照以下步骤进行变量的筛选.首先进行相关性及显著性检验;接着,为防止多重共线性,使用计量中常用的方差膨胀因子(VIF)进行判断,进行变量的筛选;随后,使用AdaBoost模型观察变量的重要程度.限于篇幅,相关性及方差膨胀因子的相关数据这里不作展示.在图3中,按照变量的重要程度进行排序,发现对上证指数影响较大的特征变量分别为adx_adx、macd_signal、cci_20、emv_maemv、obv_、atr_atr、ex_rate、r_f.格力电器(图3)亦按照变量的重要性由小到大的顺序进行排列,发现影响较大的特征变量分别为pe_trailing、atr_atr、obv_、ex_rate、dpo_20、r_f.表1是变量的含义及描述性统计[34].对特征变量绘制变量的依赖关系,如图4所示.
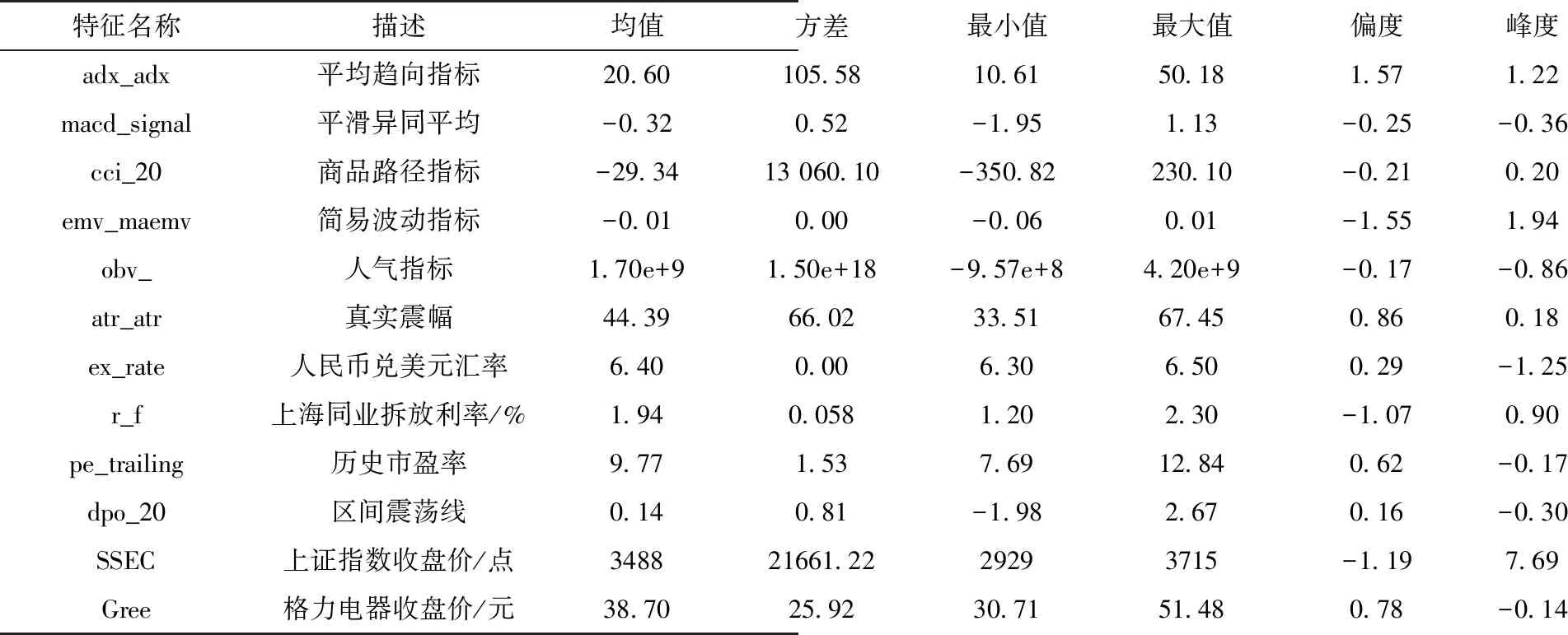
表1 重要特征变量以及响应变量的描述性统计[34]
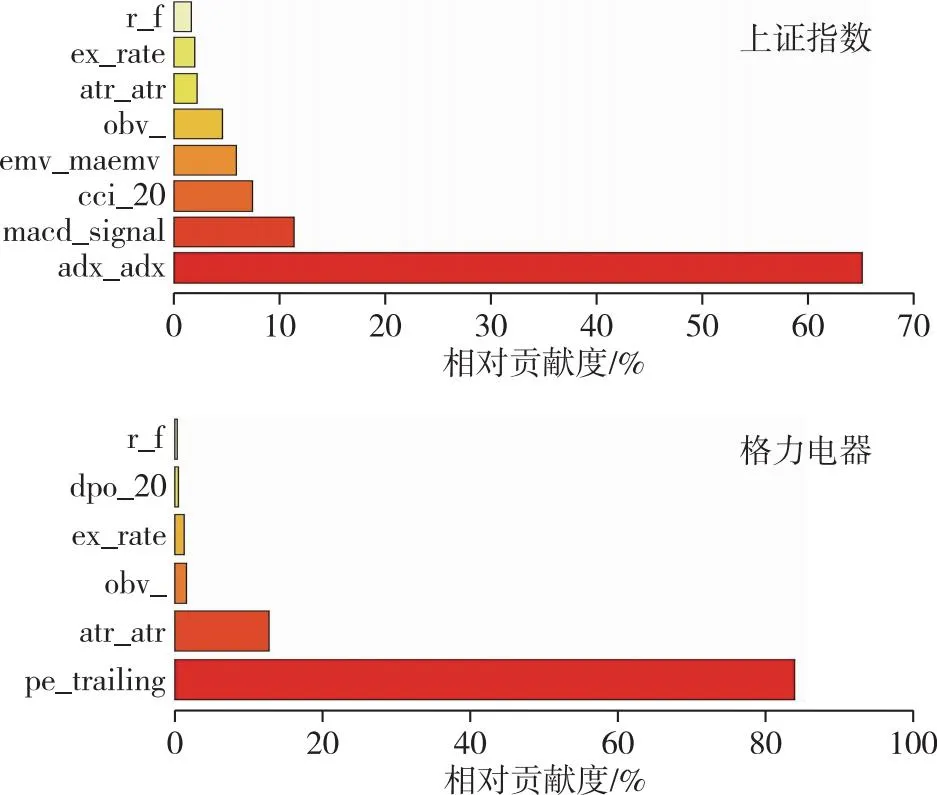
图3 上证指数及格力电器重要特征变量Fig.3 Key characteristic variables of SSE index and Gree Electric Appliances
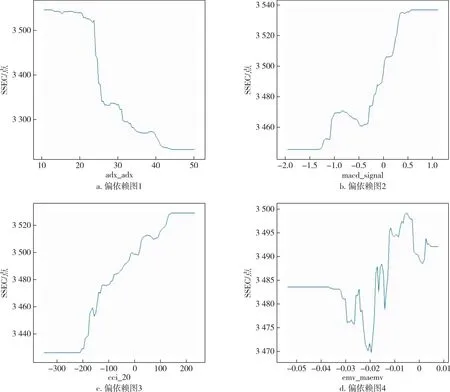
图4 上证指数重要特征变量偏相关依赖图Fig.4 Partial correlation dependence of key characteristic variables for SSE Index
从图4中可以看出反映超买超卖的cci_20以及趋势型指标macd_signal两个指标和上证指数SSEC大致呈现出正向相关的态势,而反映趋势强度的adx_adx指标与上证指数之间的关系大致是负向,其中,反映成交量与人气的emv_maemv指标和上证指数SSEC之间的关系存在显著的非线性关系.投资者在进行投资时可以着重关注这些影响较大的技术性指标.与此同时,在图5中也能看出反映公司价值的基本面指标pe_trailing与格力电器Gree的股价是正向的,因此投资者在进行投资时,不应该过于追求安全性,仅选市盈率较低的股票进行投资.反映震荡幅度的指标atr_atr、人气型指标obv_及汇率ex_rate与格力电器Gree的股价之间的关系比较复杂,在一定程度上反映了市场上不同投资者的态度以及产品的销售状况.
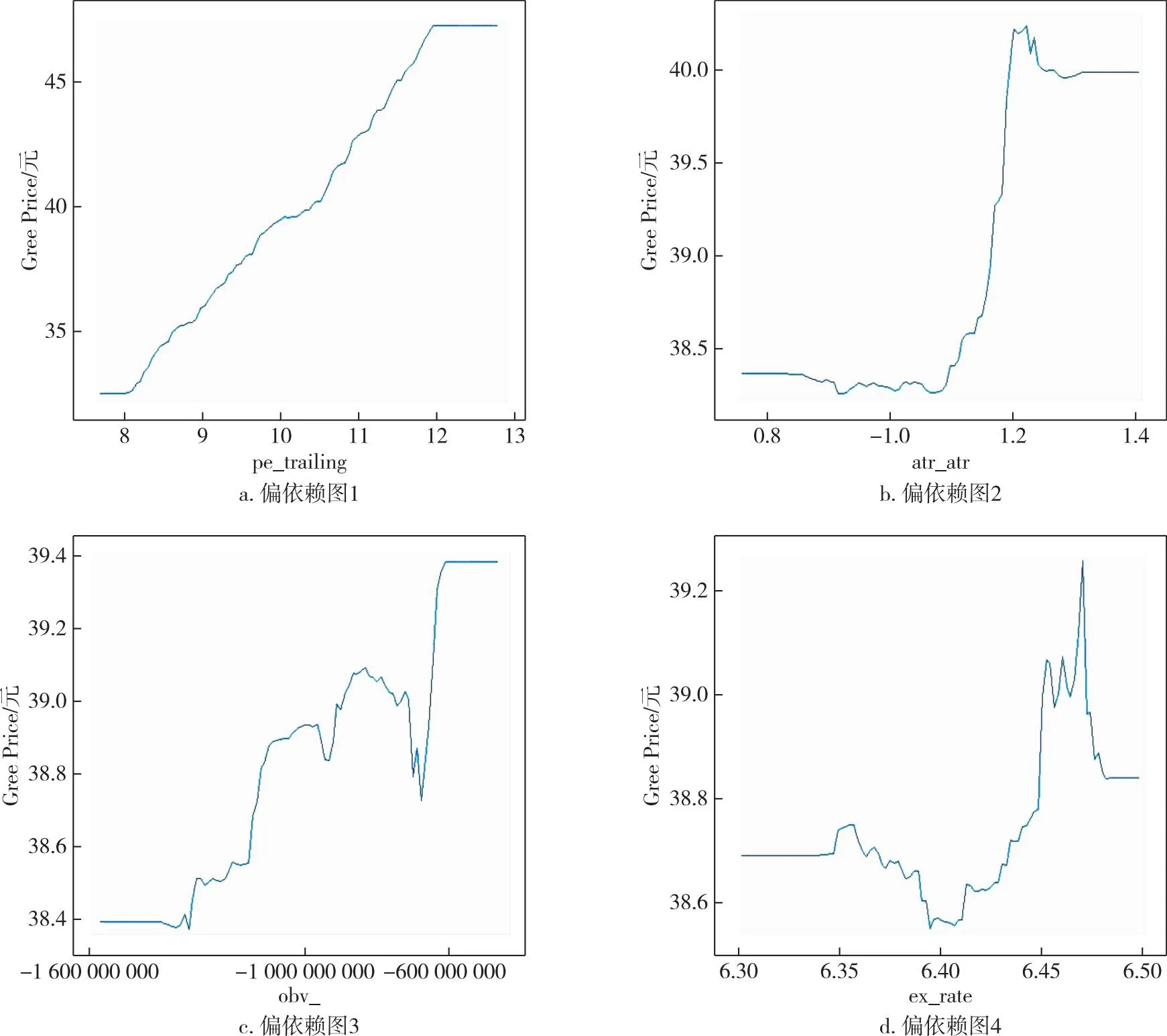
图5 格力电器重要特征变量偏相关依赖图Fig.5 Partial correlation dependence of key characteristic variables for Gree Electric Appliances
从表1能够看出:1)平滑异同平均(macd_signal)、简易波动指标(emv_maemv)、区间震荡线(dpo_20)与人气指标(obv_)、真实震幅(atr_atr)、上证指数(SSEC)在量纲上差距较大,后续在处理特征变量和响应变量时将进行归一化处理;2)数据都存在一定程度的左偏或者右偏,其中,上证指数相对正态分布呈现出“尖峰厚尾”的特征;3)量纲接近的指标中平均趋向指标(adx_adx)以及真实振幅(atr_atr)两个指标的方差较大,数据较为分散.
2.3 评价指标
本文采用如下的评估指标来评价模型预测效果:
1)均方根误差(RMSE):
(13)
2)平均绝对百分比误差(MAPE):
(14)
2.4 文本情绪指数计算
东方财富网股吧(https://guba.eastmoney.com/)是我国最大的股市投资者交流贴吧,本文选择其中的帖子来计算情绪指数.对爬取的文本进行预处理,去除一些没有意义的图片、数字及标点符号,通过整理每天的帖子计算每日的情绪指数.
常见的文本情绪指数计算有两种方法:一种是机器学习的方法,即先对文本进行分类选出积极消极的文本,通过支持向量机、朴素贝叶斯等模型进行训练,然后用训练完的模型进行应用,计算每天的情绪指数;另一种是运用词典的方法进行判定,构建情感词典,运用构建的情感词典筛选出每日的积极情感词和消极的情感词[35],其关键是情感词典的构建,构建一个详尽的中文金融情感词典十分重要.本文采用前一种方法,通过搜集一些已有文本,再加上作者标注的文本,构建积极和消极的语料并使用朴素贝叶斯进行分类,部分打标签的语料如表2所示.

表2 部分语料归类
本文抓取的上证指数以及格力电器的帖子时间跨度为2021年7月12日至2022年4月25日,除去其中没有交易的天数,共计191天,上证指数和格力电器帖子的条数分别为1万余条及12万余条,部分数据内容及打分如表3所示,效果较好,优于一般的情感词典法(情绪指数范围为0~1).

表3 部分帖子内容
通过计算整理得出每日的情绪指数.由于量纲的差异,先对变量进行标准化处理,并计算文本情绪指数em与响应变量(收盘价)之间的灰色关联度[36],经计算,得出上证指数与格力电器文本情绪指数与各自收盘价的灰色关联度分别为0.71和0.70,有较大关联性.股价关注度也是投资者情绪的一种体现[37],因此计算了投资者的关注度att,计算方式见式(15)[38],其中,AbbrSVL表示股票简称搜索量,CodeSVL表示股票代码搜索量.发现投资者关注度att与对应的收盘价也有较强的关联,因此将投资者情绪em以及投资者关注度att共同作为特征变量.
att=ln(AbbrSVL+CodeSVL).
(15)
2.5 LSTM模型参数设置
使用多变量LSTM模型在深度学习平台Tenorflow上搭建神经网络.构建3层的神经网络,其中2层为隐藏层,第3层为输出层,第1层包含80个神经元,第2层包含了100个神经元,用表1中选择的变量作为特征变量,使用默认的学习率0.01,使用Adam优化器,选择均方误差作为损失函数,迭代次数epoch以及每次喂入的数据batchsize分别为50和64.
2.6 误差修正
为进一步减小模型的误差,首先选出误差较小的基准模型,再使用滚动GM(1,1)模型进行修正,用前7天的误差预测第8天的误差,充分挖掘残差项的信息.对于其中出现的负的残差项,首先对数据加上一定的正数进行建模,再对残差进行相应的预测,预测出对应的数据后再减去原来加上的正数还原,得出最终预测的残差项.
3 实证分析
3.1 股价时间序列预测
本文选择格力电器的收盘价作为响应变量进行预测,因为格力电器作为A股市场的白马股具有一定的代表性.从191天的数据中,选取样本中前140天的数据作为训练集,后51天的数据作为测试集.采用滚动预测的方法,用前7天特征变量的数据预测第8天的标签,即收盘价的数据.根据前面的工作,选择的特征变量分别为pre_trailing、atr_atr、obv_、ex_rate、dpo_20、r_f以及后面加入的情绪相关变量att、em及其自身的收盘价共计9个特征变量.具体的预测结果如图6所示.为了说明模型的稳健性,本文加上了同为电器行业的飞科电器(603868)以及美的集团(000333)的股价,采用同样的方法在同一时间段内进行预测,预测结果分别如图7和图8所示,其中Gree、Flyco、Midea分别表示格力电器、飞科电器、美的集团三支股票.
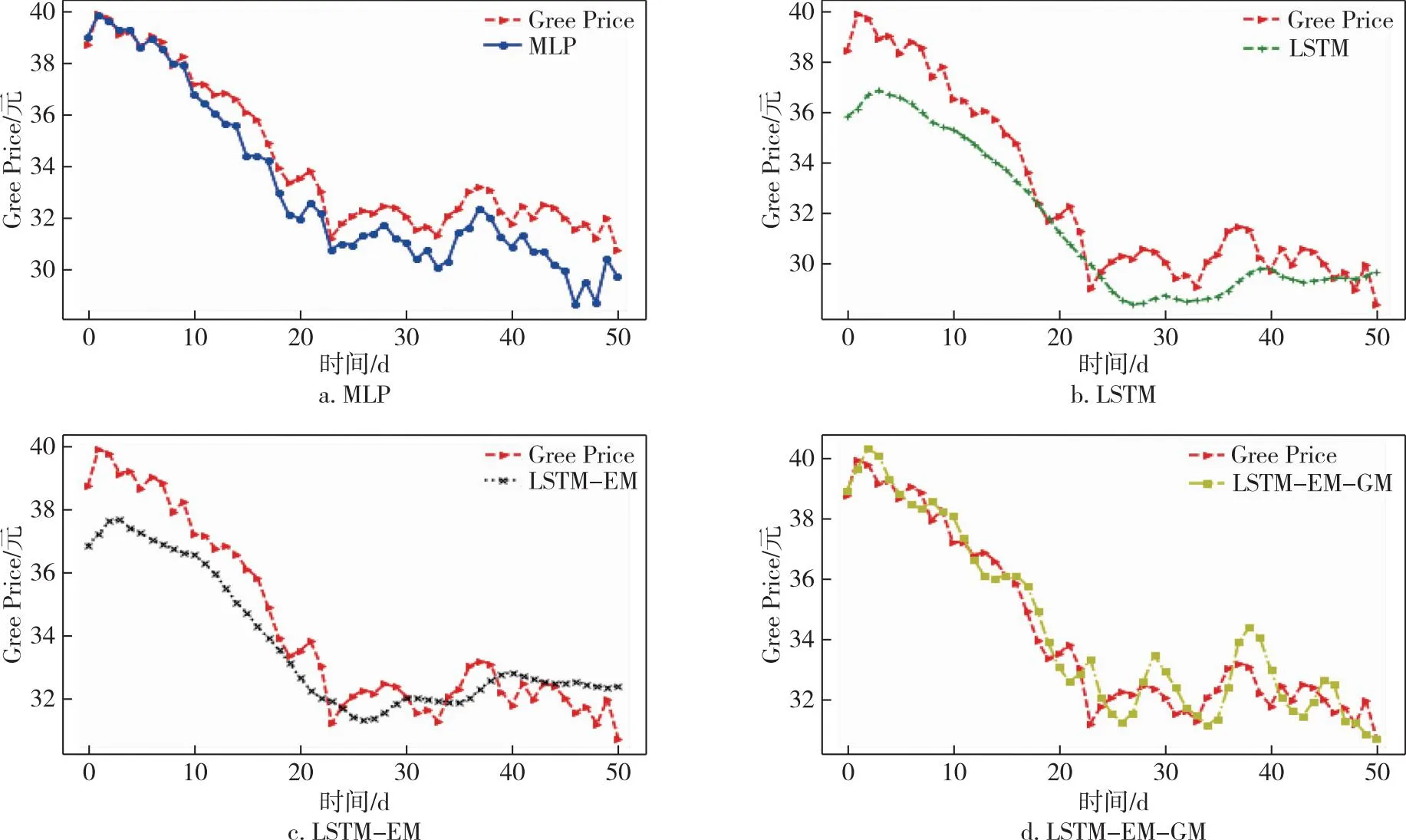
图6 不同模型格力电器股价预测比较Fig.6 Comparison of Gree Electric Appliances stock prices forecasted by different models
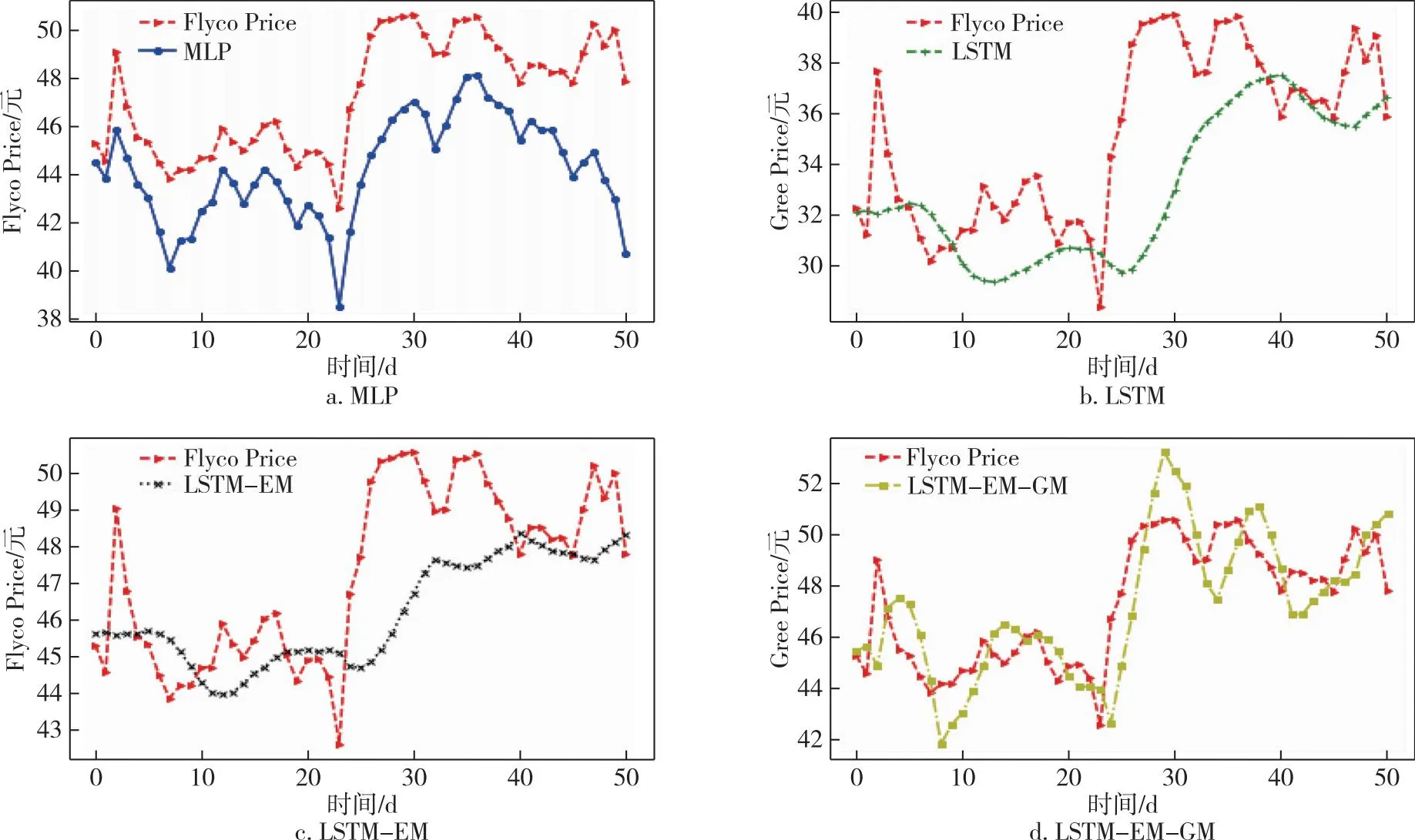
图7 不同模型飞科电器股价预测比较Fig.7 Comparison of Flyco Electric Appliance stock prices forecasted by different models
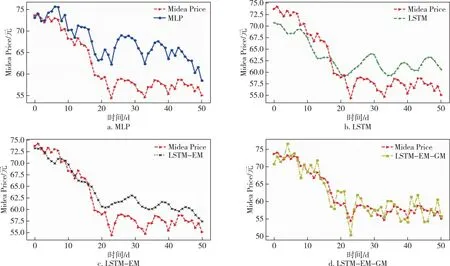
图8 不同模型美的集团股价预测比较Fig.8 Comparison of Midea Group stock prices forecasted by different models
本文首先选择的是MLP(Multilayer Perceptron)基础神经网络[39]与LSTM模型进行比较,发现即使没有添加情绪相关的指标,LSTM的预测效果也相对较好;接着分别对比加入情绪指数、投资者关注度的模型LSTM-EM以及在此基础上对误差修正的模型LSTM-EM-GM,具体评测指标的数值如表4所示.
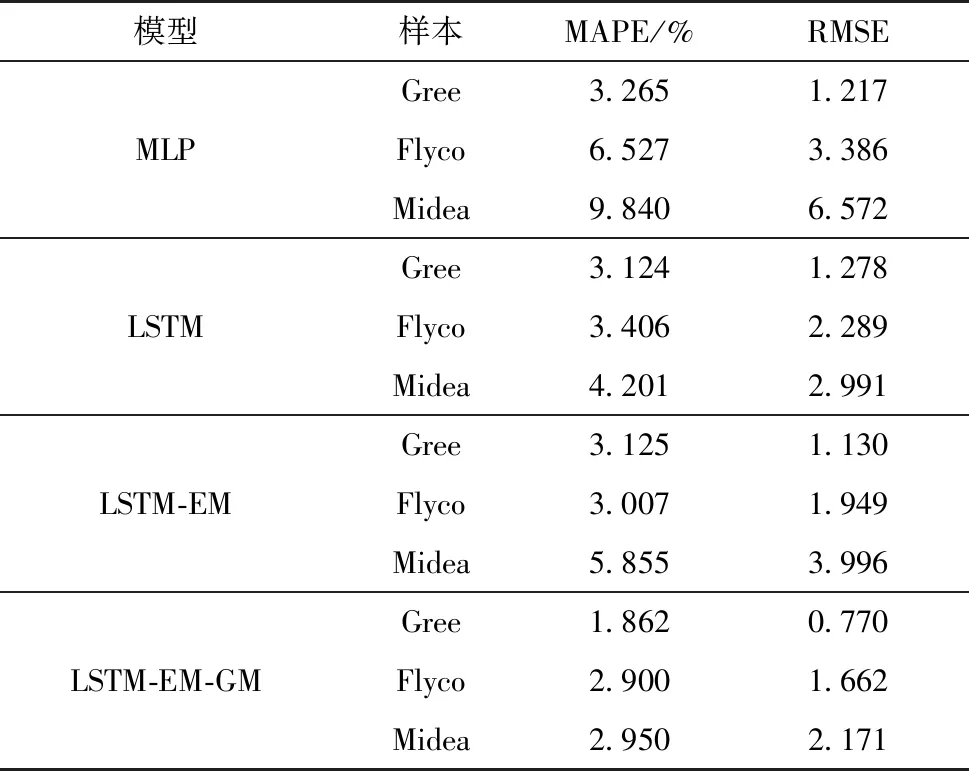
表4 不同模型预测结果对比
从表4中能够看出:在格力电器(Gree)的股价预测中,没有加入情绪指数的LSTM模型的MAPE、RMSE分别为3.124%、1.278,加入了情绪指数的MLP模型的MAPE、RMSE分别为3.265%、1.217.加入情绪指数em、投资者关注度att的模型LSTM-EM模型的MAPE以及RMSE分别为3.125%、1.130,相较于MLP模型,无论是MAPE还是RMSE指标都有了显著的提高,因此选用LSTM模型为基准模型.而相对于LSTM模型,LSTM-EM模型虽然MAPE没有显著变化,但RMSE有了较大下降.进一步,使用GM(1,1)模型对LSTM-EM进行修正后的模型LSTM-EM-GM模型的MAPE及RMSE分别为1.862%、0.770,都相对之前的模型有了更为显著的下降,为最优模型.在飞科电器(Flyco)及美的集团(Midea)的股价预测中,LSTM-EM-GM也是最优的预测模型,反映其预测误差大小的指标中MAPE分别为2.900%及2.950%,RMSE指标的值分别为1.662及2.171,相对于对比模型MLP以及原始模型LSTM,误差都有所下降.
从上述的对比中能够发现,相较于MLP,具有记忆性的LSTM模型能够对股价数据进行更好的预测,且投资者情绪与投资者关注度与格力电器的股价之间有较为明显的关联,将其作为特征变量加入到模型中能在一定程度上提高模型的预测精度.同时,由于选用灰色GM(1,1)模型,充分挖掘了残差项中的信息,使得模型的预测精确度有了较为显著的提高.结合所选取的电器行业的3个案例,发现模型对于波动剧烈且下降的格力电器股价、波动下降但降幅略小的美的集团以及波动上升的飞科电器股价,都能进行较好的预测,验证了模型的稳健性.
3.2 模型普适性研究
上述研究预测了近2个月的股票收盘价.为更好地说明模型的适用性,缩短预测时间,仅预测2天的数据量,选择上证指数SSEC作为响应变量进行验证.同样使用LSTM-EM-GM模型,除了迭代轮数epoch变为100,滚动窗口设置为5,其余参数同上.选择的特征变量分别为adx_adx、macd_signal、cci_20、emv_maemv、obv_、atr_atr、ex_rate、r_f以及投资者情绪指数em、投资者关注度att和自身收盘价共计11个特征变量.具体预测结果如表5所示.由于数据量较小,这里不再绘图展示.
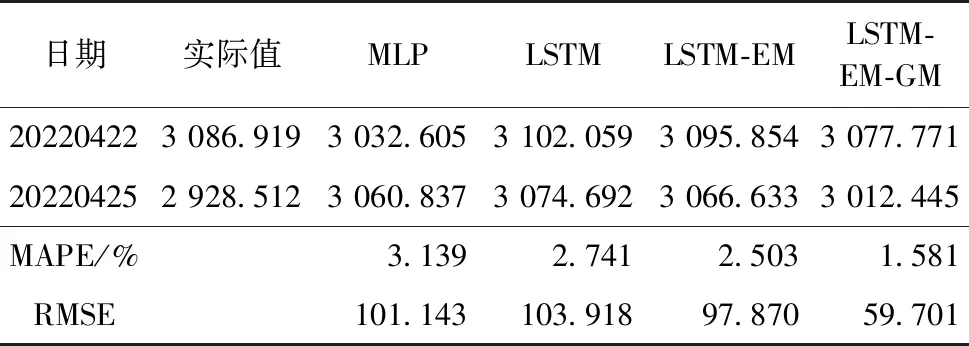
表5 不同模型短期预测结果对比
从表5中能够看出,对于上证指数的预测,由于量纲的问题导致RMSE的指标都相对较大.总的来说MLP模型的效果依然相对较差,其MAPE及RMSE指标的数值分别为3.139%及101.143,LSTM-EM-GM模型的效果依然最好,MAPE及RMSE的数值分别为1.581%及59.701.LSTM-EM-GM模型在更短期的预测中取得不错的表现,验证了模型的普适性.
4 结论
基于股票市场的技术性指标、基本面指标以及投资者情绪和投资者关注度对格力电器和上证指数进行了分析,并对变量筛选后的模型进行了残差项的修正.通过实证分析得出如下结论:
1)投资者在进行投资时除了关注市场行情、了解大盘指数,也可以关注与股指关联性较大的指标,如反映超买超卖的cci_20、反映趋势的macd_signal以及adx_adx等指标;在投资个股时除了关注汇率、市盈率等基本面的指标,也应适当关注对各股影响较大的技术性指标,如反映震幅的指标atr_atr、人气型指标obv_等.
2)情绪指数以及投资者关注度与股价之间存在较强的关系,将其作为特征变量能在一定程度上提高模型的预测精度,所以,在投资时应当时刻关注市场上的投资者情绪,适时操作.
3)通过对残差项进行修正,能显著地提高模型的预测效果,说明残差项中蕴含着丰富的信息,且使用GM(1,1)模型对于没有明确分布的时间序列具有较好的特征提取作用.
本文虽然在特征变量选取方面及情绪指数的计算方面具有一定的科学性,考虑了可能存在的多重共线性以及各个特征变量的贡献程度,整理了相对完善的语料库而未使用词典法计算情绪指数,但也存在一定的不足之处:首先,影响股市的因素错综复杂,可能还有许多影响重大的因素未得到体现;其次,文本分析及情绪指数的计算还缺乏成熟的体系.这是后续研究值得完善的方面.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
股市动态分析(2019年42期)2019-11-13
电脑报(2019年4期)2019-09-10
自动化学报(2019年6期)2019-07-23
现代营销(创富信息版)(2018年8期)2018-09-08
证券市场红周刊(2018年15期)2018-05-14
中国经济周刊(2017年39期)2017-10-20
股市动态分析(2016年2期)2016-09-27
证券市场周刊(2016年35期)2016-09-19
