
基于Mask R-CNN的遥感影像滑坡检测方法研究
2023-12-19 08:32徐玲刘晓慧张金雨刘震
山东建筑大学学报 2023年6期
徐玲,刘晓慧,张金雨,刘震
(山东建筑大学测绘地理信息学院,山东 济南 250101)
0 引言
我国是地质灾害频发的大国,由于山区众多、地形结构较为复杂,地质灾害隐患广泛分布。国务院办公厅于2020年5月印发《关于开展第一次全国自然灾害综合风险普查的通知》,定于2020—2022 年间开展第一次全国自然灾害综合风险普查工作[1]。根据自然资源部地质灾害数据统计,2020 年我国共发生地质灾害7 840 起,其中有滑坡4 810 起、崩塌1 797起、泥石流899起,造成了139人死亡(失踪)、58人受伤,直接经济损失可达50.2 亿元[2]。因此,对大范围的滑坡开展自动检测,快速获取滑坡的区域分布、数量、规模等灾害信息,对地质灾害普查工作、地质灾害管理以及风险评估具有重要意义[3]。然而,传统的滑坡提取方法大多基于现场调查[4-5],调查范围有限、耗时长、工作量大、效率低,难以满足救援部门的效率需求。由于遥感技术具有快速、宏观的优势,使其飞速发展并在灾害应急救援中得到广泛应用[6-9]。因此,利用遥感技术初步掌握灾害分布情况,对于地质灾害普查工作具有重要意义。
深度学习方法在计算机视觉领域得到广泛应用,如影像分割、目标检测和影像分类,并为自动提取滑坡提供了有效的框架[10-13]。与传统方法相比,深度学习方法可以借助深度学习框架通过卷积运算自动学习特征,并用分层特征提取代替人工特征识别。MANFRÉ等[14]使用支持向量机、决策树、二进制编码等多种机器学习方法实现了对巴西圣保罗州地区的滑坡识别工作;陈天博等[15]基于模糊分类与支持向量机相结合的决策树方法实现了对北京市西南部的霞云岭乡滑坡识别;HU 等[16]使用支持向量机、人工神经网络和随机森林3 种方法实现了对九寨沟地区的滑坡识别工作。在上述研究中,采用了比较基础的网络结构,由一系列卷积层、池化层和全连接层组成,网络结构比较简单,对滑坡提取有一定的限制。张倩荧[17]将3 种深度学习算法应用于滑坡提取,在边界上取得了很好的效果,但无法得到滑坡形状。掩膜区域卷积神经网络(Mask Region-Based Convolutional Neural Networks,Mask R-CNN)是一个结构完善、目标特征提取能力强的实例分割模型,能够在定位目标的同时检测不规则目标的边界,在滑坡检测过程中可以同步提取滑坡的位置和形状。
在将深度学习应用于滑坡检测的现有研究中,滑坡检测所使用的影像主要是无人机实测影像数据、高分卫星数据以及地球眼卫星数据,这些数据往往无法公开获取。对于滑坡检测而言,低分辨率遥感影像往往会造成很多目标的漏检,而谷歌地球(Google Earth)影像分辨率高、易于获取,可以满足检测影像的需求。
基于以上分析,文章以四川省中西部的丹巴县以及甘肃省西南部的永靖县为研究区,以开源的Google Earth光学遥感影像为研究数据,分别建立了历史山体滑坡和黄土滑坡样本数据库,利用Mask R-CNN目标检测算法并结合迁移学习机制训练滑坡数据集,探索使用Mask R-CNN深度学习方法检测Google Earth 影像中大范围的滑坡可行性。同时,结合影响滑坡发生的因子,使用多层感知器模型预测研究区内各个区域的滑坡发生概率,通过对比基于Mask R-CNN检测的滑坡灾害点在研究区滑坡发生概率分区图中的分布情况验证滑坡识别结果的准确性。
1 Mask R-CNN滑坡检测方法
文章使用Mask R-CNN目标检测算法来实现滑坡的自动识别。Mask R-CNN是由HE等[13]开发的一种目标检测算法,该算法在图像分类与识别中取得了很好的效果。如图1 所示,Mask R-CNN 算法是在更快的区域卷积神经网络(Faster Region-Based Convolutional Neural Networks,Faster R-CNN)的基础上将感兴趣区域(Region of Interest,RoI)特征提取算法RoI Pooling替换成RoI Align,并且在目标检测的基础上添加分支全卷积网络层(Fully Convolutional Network,FCN),用于语义分割识别。Mask R-CNN是一个两阶段的目标检测算法,第一阶段是特征图通过区域候选网络(Region Proposal Network,RPN)生成候选框,再对每个候选框分类和边界框回归;第二阶段则是在第一阶段生成的候选框的基础上,再次进行分类和边界框回归,从而达到提高检测精度的目的。
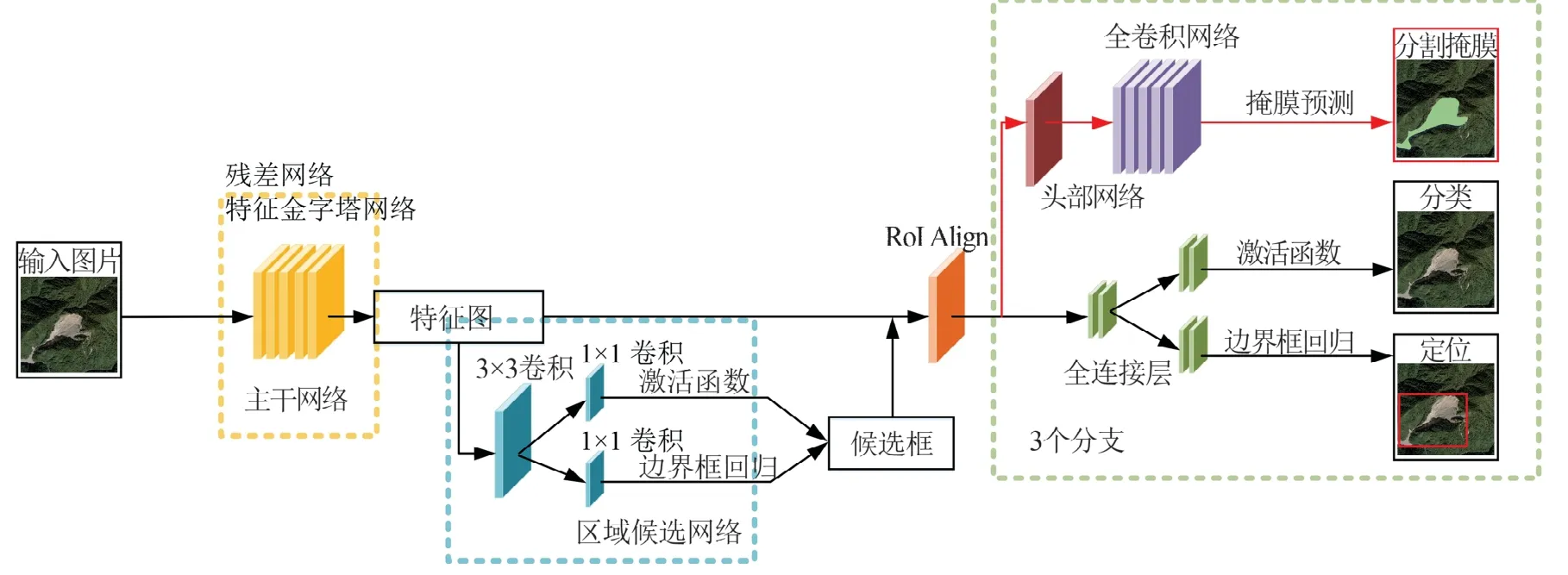
图1 Mask R-CNN模型结构图
1.1 主干特征提取网络结构
文章使用经典的残差网络ResNet101(Residual Neural Network,ResNet)[11]和特征金字塔网络[18](Feature Pyramid Network,FPN)作为主干特征提取网络,如图2 所示。使用ResNet101 网络通过跨层连接提取图像特征,图像经过ResNet101网络5次卷积运算(C1—C5)提取目标特征,得到5个不同大小的特征图(P2—P6),在不降低特征提取性能的情况下加深神经网络的深度,使训练更容易。为了使定位目标更为准确,通常使用高分辨率图像输入,其包含更多细节信息,从而可以提升目标检测的性能。
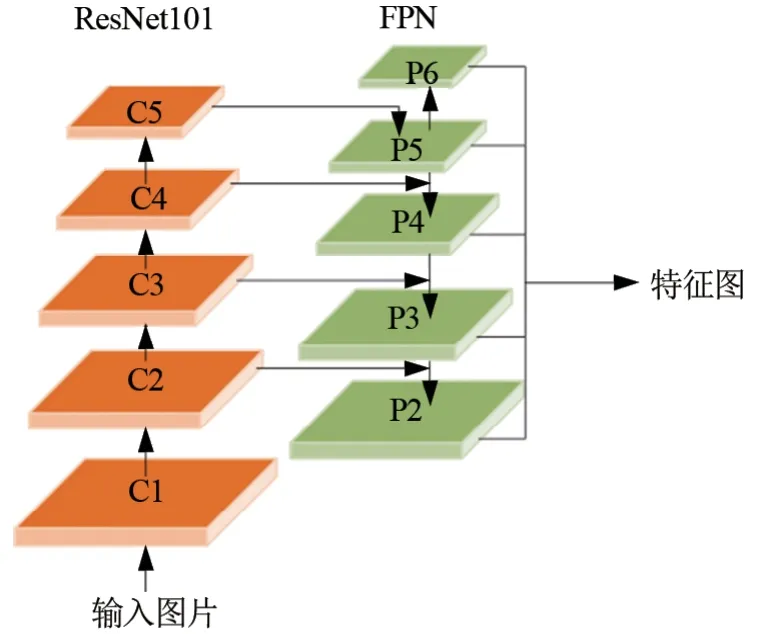
图2 主干特征提取网络结构图
FPN通过引入自上而下的路径,充分利用了不同层提取的特征,对高层特征图上采样到和下一层同样的尺寸,并将其和下面的一层进行相加,进而得到一个融合高低层特征的新特征图层。将低分辨率、大感受野特征(语义信息)与高分辨率、小感受野特征(细节信息)相结合,以检测不同尺度的物体,一定程度上缓解了特征图分辨率与感受野大小之间的矛盾。
1.2 区域候选网络结构
采用滑动窗口的方法将图像划分为大小不同且不重叠的图像块,然后对所有图像块进行分类和回归计算,得到图像中得分最高的RoI。通过这种方式,将RoI输入到RoI特征提取算法RoI Align 以提取感兴趣区域的特征。
1.3 RoI Align
RoI Align 是Mask R-CNN 区别于Faster RCNN中RoI特征提取算法RoI Pooling的一大创新。RoI Pooling的作用是把候选框在特征图上对应的位置池化为固定大小的特征图[12],并进行后续的分类、回归、掩膜生成。该过程需要对RoI的边界量化取整、裁剪,将裁剪好的区域平均分割为k×k个单元,同时对每个单元的边界进行第2次取整[13]。两次量化使得候选框与回归的边界框之间存在偏移,从而造成区域不匹配的问题。
RoI Align则是在遍历候选区域的时候保持浮点数边界不量化,同时采用双线性插值和最大池化计算每个单元中的4 个坐标位置。RoI Align 过程[13]如图3所示。
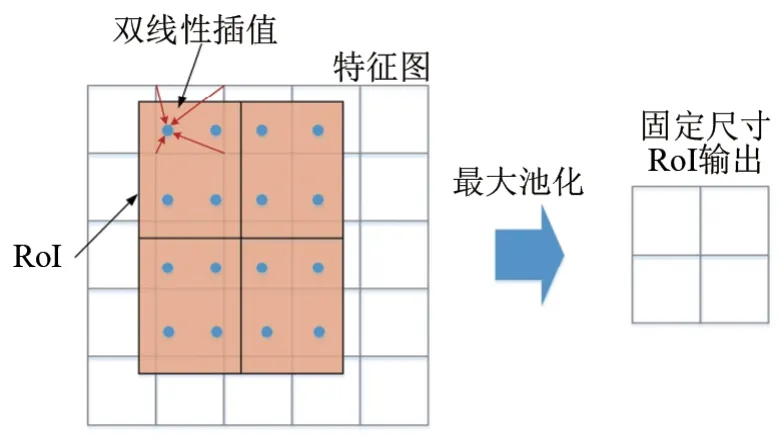
图3 RoI Align 过程
1.4 头部网络结构
头部网络由3个分支构成,分别实现目标分类、定位(边界框回归)以及生成掩码。因此,整个网络的损失函数L被定义为分类、回归、分割掩码分支损失之和,由式(1)表示为
式中Lcls为分类损失;Lbox为回归损失;Lmask为分割掩码损失。
1.5 精度评价
在目标检测的训练过程中,通常根据预测框与真实框的交并比来判断识别的准确性[19]。重叠度(Intersection over Union,IoU)可以作为目标检测算法中预测框与真实框相似度的度量,IoU 的值IU由式(2)表示为
式中I为预测框和真实框的交集面积;U为预测框和真实框的并集面积。
对模型精度评价之前要确定预测结果是否正确,通过设定置信度阈值和IoU 阈值判断预测框是否能准确预测到了位置信息。在文章中,将IU>0.5、置信度>0.9的结果作为正确预测结果。
文章使用精确率P、召回率R、F1 值作为定量评估模型检测结果精度评价指标。精确率是正确识别的滑坡数与识别滑坡总数的比值;召回率是正确识别的滑坡数与测试样本集滑坡数量的比值;F1 值用于评估模型的整体性能,定义为精确率和召回率的调和平均数,且F1 值越大,模型的性能越好。精确率、召回率以及F1值分别由式(3)~(5)表示为
式中tp为正确识别的滑坡数量;fp为错误识别的滑坡数量;fn为尚未识别的滑坡数量。预测结果和实际结果的混淆矩阵见表1。

表1 预测结果和实际结果的混淆矩阵表
2 案例研究
案例研究过程的技术流程如图4 所示,主要步骤包括:(1)数据收集选择开源的Google Earth 遥感影像作为研究数据;(2)制作滑坡样本集包括影像裁剪和样本标记;(3)滑坡信息提取训练模型得到最优的滑坡检测模型;(4)精度评价与检测结果分析验证。
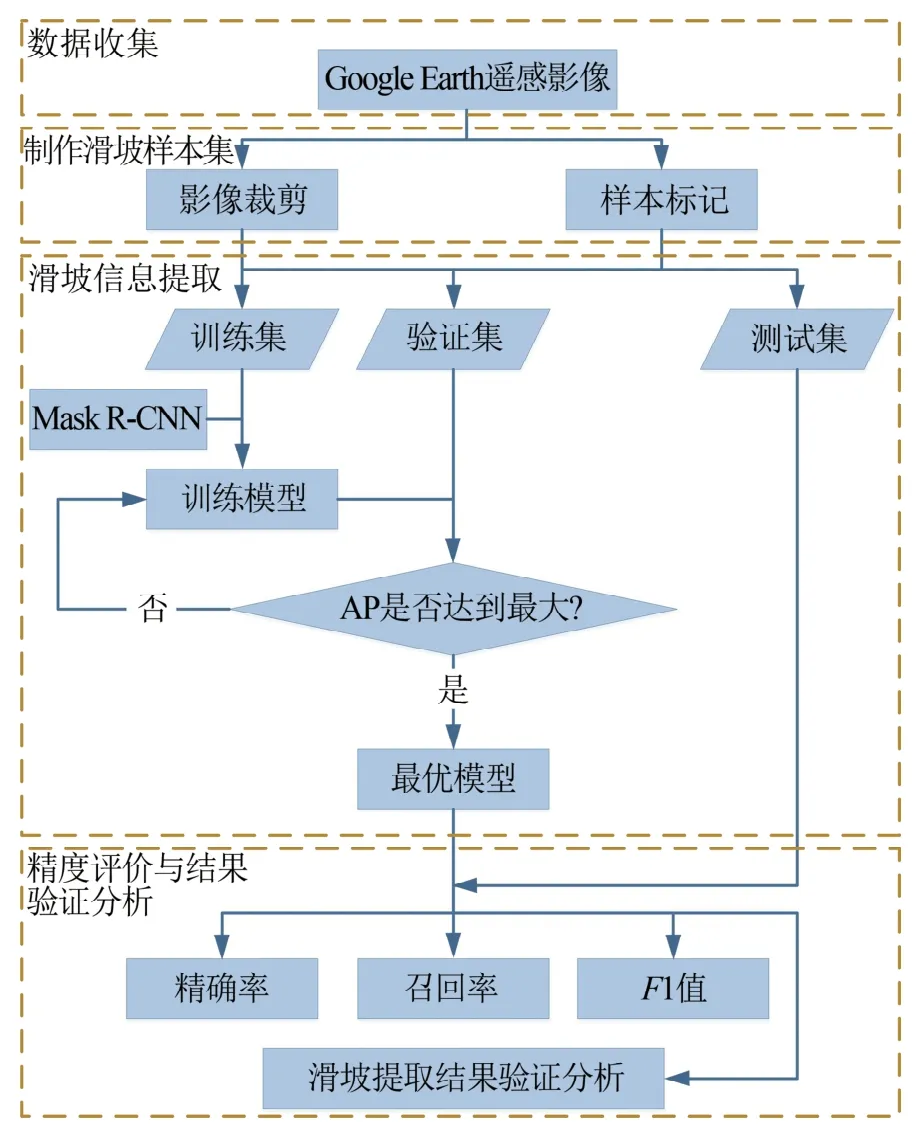
图4 滑坡检测技术流程图
2.1 实验数据与样本集制作
滑坡多数发生在我国的西北部和南部山区,文章选取101°17′—102°12′E、30°29′—31°29′N 和102°53′—103°13′E、35°59′—36°16′N的地理范围作为研究区。两个地区分别位于四川省中西部的丹巴县以及甘肃省西南部的永靖县,丹巴县以山体滑坡为主,而永靖县以黄土滑坡为主,如图5所示。两个研究区都是地质灾害多发地区,区内地质灾害以滑坡、崩塌和泥石流为主。
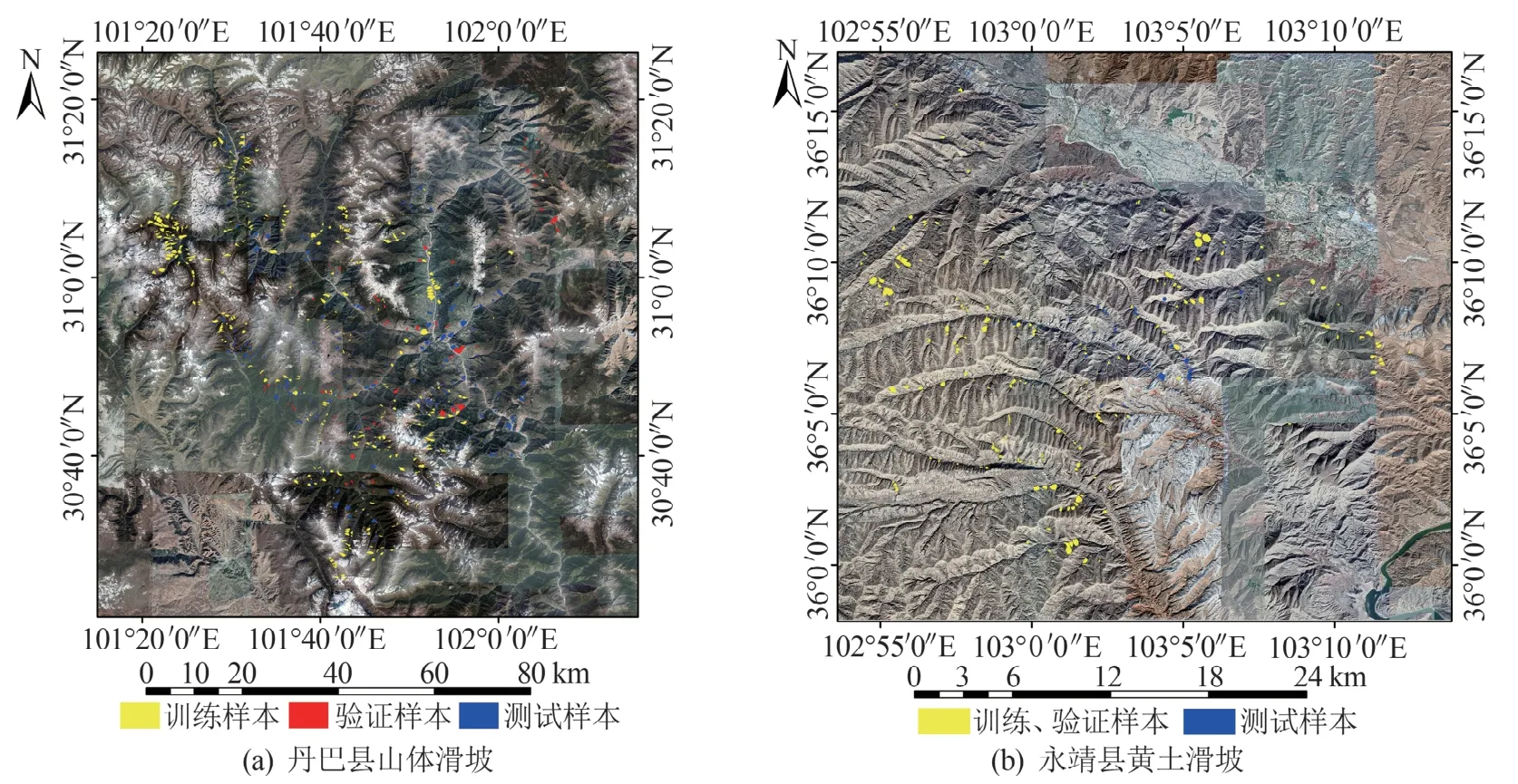
图5 研究区滑坡样本分布图
滑坡的尺寸、形状各异,识别时有一定的难度。常见的滑坡特点可以总结为:(1)滑坡在空间分布上表现为多发生在道路两侧、山谷与河流相交的地区以及一些土壤较为松软的边坡与斜坡;(2)大部分山体滑坡的边界较为明显,在形状上呈现为U形且与周围的植被有明显的界限,新发生的滑坡在颜色上呈现为暗灰色或灰白色,部分发生在没有植被地区的滑坡以及发生时间较久的老滑坡,由于光谱信息与周围相似识别难度较大,但仍然可以通过与周围环境的颜色差异进行识别;(3)发生滑坡的地区表层的植被遭到破坏,深层的土壤裸露出来,在纹理特征上表现为地表环境破碎,纹理粗糙且色块分布不均。
文章使用Google Earth 数据作为数据源构建用于深度学习的滑坡样本集。Google Earth 的卫星影像是由多传感器融合而成的。选择2021 年9 月24日、2019年11 月5 日以及2018 年4 月16 日三期Pléiades 1A和SPOT 7卫星融合而成的遥感影像作为实验数据,其最高分辨率分别为0.5 和1.5 m。从Google Earth Pro虚拟地球应用软件下载了1 400 幅遥感影像,其分辨率为2.15 m,为了使每个训练批次可以训练多张影像,将所有影像设置为相同的512 pixel×512 pixel,每张影像都只有RGB3个通道。
参考中科院地理所资源环境科学与数据中心(https:/ /www.resdc.cn/)公开的滑坡点,结合滑坡特点,对照遥感影像使用“VGG Image Annotator”Web工具对已经发生的滑坡进行样本标记,对一些不确定是否为滑坡的地区,可以在Google Earth Pro中反复旋转角度,从多角度查看三维影像,辨认是否为滑坡。将注释了用于对象实例分割的训练样本保存为JavaScript Object Notation 的格式,手动注释中使用的影像子集示例如图6 所示。注释的山体滑坡样本共有1 466个,可随机分为3个子数据集,包括训练数据样本集(1 047 个滑坡样本),用于最小化过度拟合的验证样本集(100 个滑坡样本),以及用于评估经过训练的深度学习算法的性能的测试样本集(319个滑坡样本);黄土滑坡样本共有757个,其中训练样本599个、验证样本96 个、测试样本62个,样本统计情况见表2。
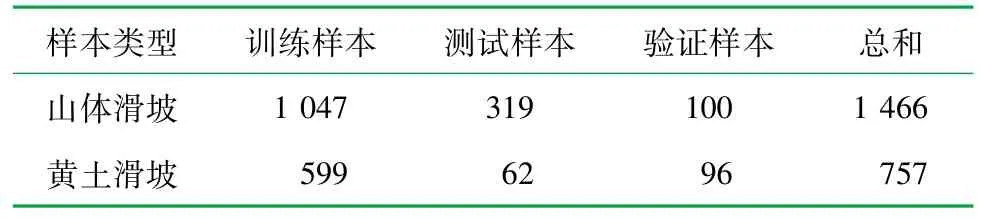
表2 滑坡样本统计表

图6 手动注释中使用的影像子集示例
2.2 实验环境与参数设置
模型训练和测试所使用的硬件设备为AMD Ryzen Threadripper 2970WX 24 - Core Processor、NVIDIA GeForce RTX 2080 Ti。实验环境配置的tensorflow-gpu版本为1.8.0,cuda 版本为9.0。在训练过程中,图形处理单元用于训练包装中采用的网络为ResNet101,共训练100 个批次,每个批次迭代运算200 次,实验中使用的图形处理器显存为11 GB,可以容纳两张图片,因此将批量大小设置为2。HE[13]将学习率设置为0.02,但是在实际训练时发现较高的学习率容易造成权重爆炸,尤其是训练小批量的数据时,而较小的学习率收敛的更快,因此文章实验中将学习率设置为0.001、学习动量设置为0.9、权重正则化系数设置为0.000 1。
为了降低训练成本,有效提高模型性能和整体检测精度,使用matterport 团队在COCO 2014 数据集上训练Mask R-CNN 得到的mask_rcnn_coco.h5(https:/ /github.com/matterport/Mask_RCNN)作为文章滑坡检测算法的预训练权重。在预训练权重的基础上,对文章的训练样本集进行迁移学习,保存训练得到的权重结果。在训练过程中,为了减少过度拟合,使用验证样本集来验证模型的精度,载入训练得到的权重结果进行模型测试,将精度最高的模型作为测试模型,并将其应用于测试样本集的滑坡检测。
2.3 实验结果与分析
2.3.1 滑坡检测结果
Mask R-CNN 模型的训练结果显示,山体滑坡检测模型训练到第55个训练批次时,验证样本集的平均精度(Average Precision,AP)达到最大值0.96(如图7所示),此时损失也下降至平缓,因此将第55个模型参数用于后面测试样本集的山体滑坡识别及精度评价。黄土滑坡检测模型训练到第7个批次时,AP 达到最大值0.82(如图8 所示),同时损失达到0.41并趋于平缓,因此选择第7个模型参数用于测试样本集的黄土滑坡识别与精度评价。
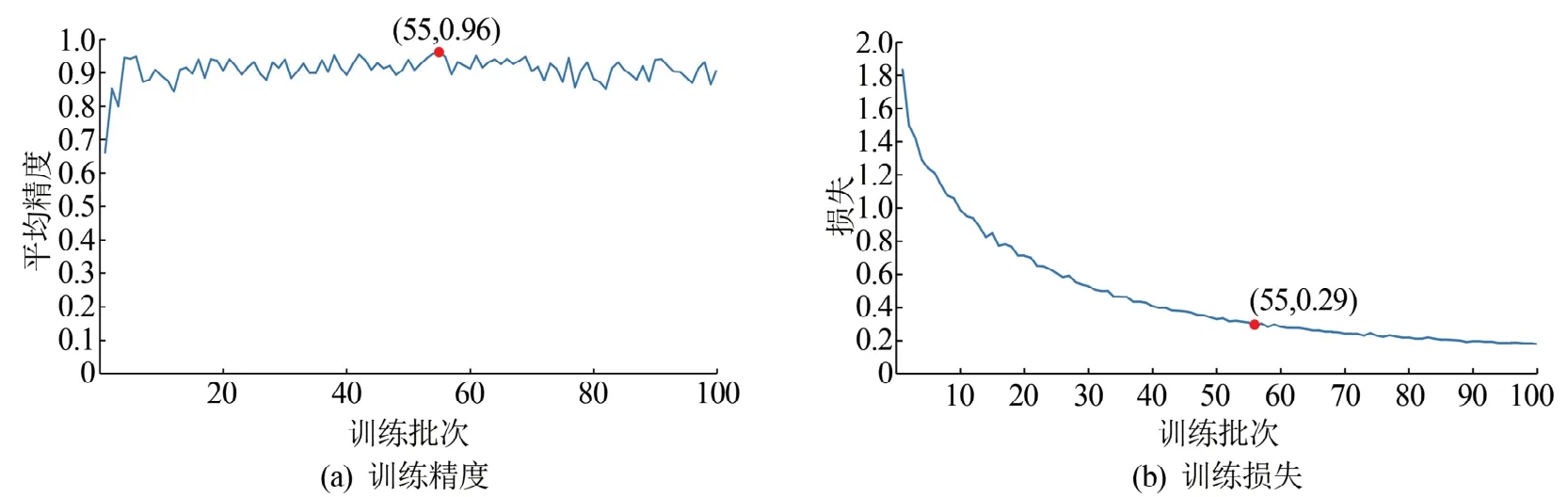
图7 山体滑坡训练精度与损失
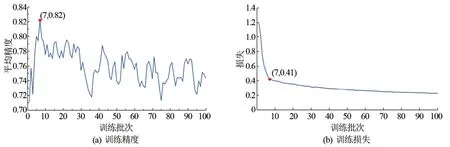
图8 黄土滑坡训练精度与损失
测试样本集的精度见表3,共有319 个山体滑坡样本和62个黄土滑坡样本,分别使用文章实验获得的最优模型进行检测,其结果如下:正确识别的山体滑坡个数为273 个、错误识别的山体滑坡个数为11个、未识别的山体滑坡个数为46 个。训练模型对于山体滑坡识别的精确率为96%、召回率为85%、F1值为0.90。正确识别的黄土滑坡个数为40个、错误识别的黄土滑坡个数为1 个、未识别的黄土滑坡个数为22 个。训练模型对于黄土滑坡识别的精确率为98%、召回率为65%、F1值为0.78。

表3 测试样本集精度统计表
2.3.2 滑坡检测结果分析
部分正确的滑坡识别结果如图9所示。为了便于展示识别效果,图9(a)和(c)使用手动注释的多边形边界来表示滑坡的真实值,图9(b)和(d)为滑坡识别的结果。尽管Google Earth 影像是由不同传感器的影像融合而成,光谱特征不统一,但从滑坡检测的结果来看,Mask R-CNN 模型可以自动识别Google Earth影像中的历史滑坡。

图9 正确检测结果图
图10~12 显示了部分错检和漏检的滑坡识别结果。通过识别结果对比发现,主要有3 种错误类型。第1种错误的识别结果多发生在生态环境遭到破坏、地表纹理较为复杂的地区,如河流阶地、土壤侵蚀和地表裸露的地区(如图10 所示)。这些地区复杂的地表纹理可能会形成类似于滑坡的光谱特征,因此这些区域很容易被错误地识别为滑坡。第2种遗漏的识别结果大多出现在有阴影(如图11 所示)、山脊或斜坡顶部的影像中,在空间分布上集中分布在山体背斜的阴影区域。由于山体的阴影,滑坡信息模糊,无法正确识别这些地区的滑坡。第3种是多尺度目标检测时,易出现遗漏的识别结果。由于精度和计算资源之间通常难以达到平衡,因此在识别大目标时容易遗漏一些小目标(如图12所示)。
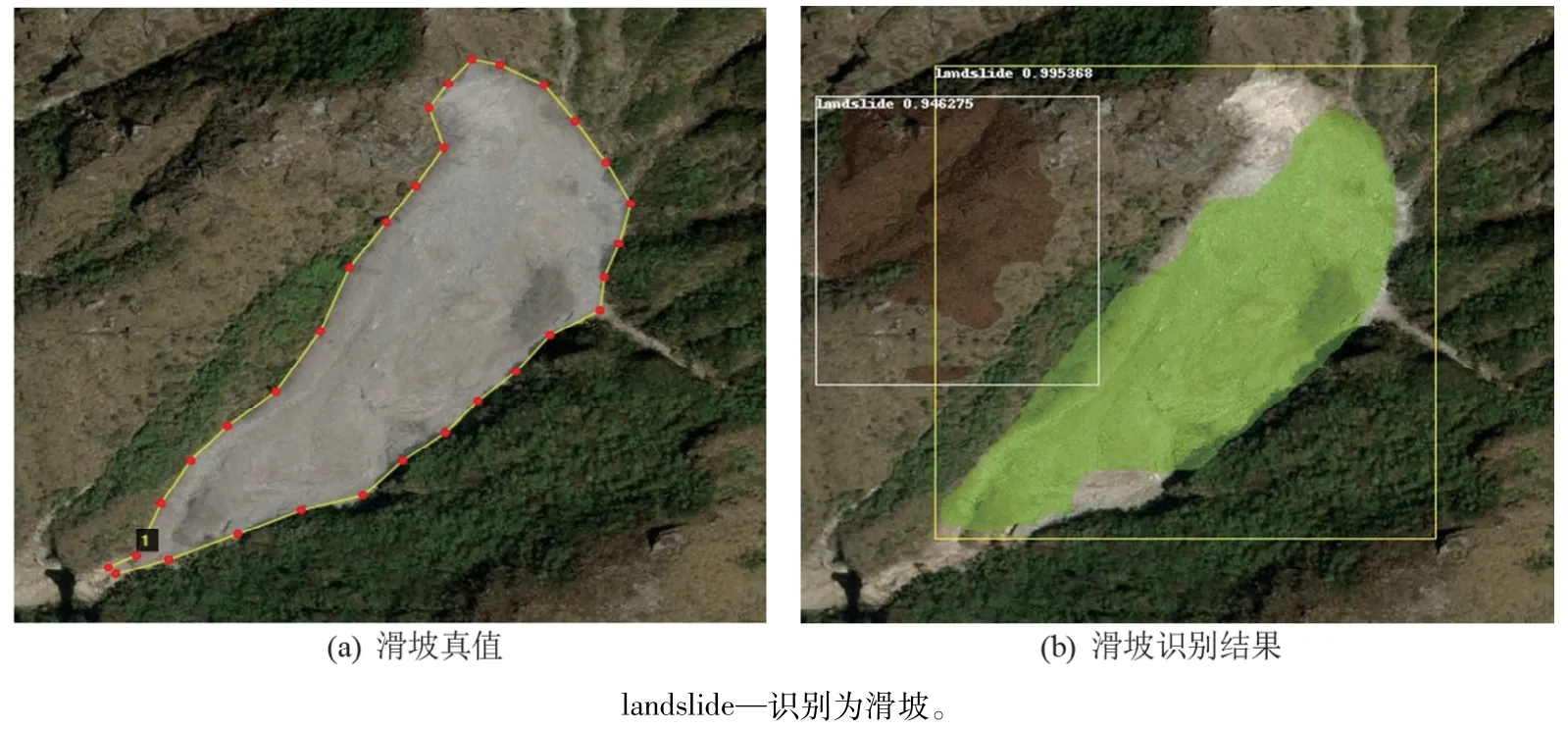
图10 错误检测结果图

图11 遗漏检测结果图

图12 遗漏检测结果图
2.3.3 滑坡检测结果验证分析
导致滑坡发生的影响因素有很多,如地形地貌、植被覆盖、断层岩性以及人类活动等。为了进一步验证基于Mask R-CNN模型检测滑坡的准确性,文章以丹巴县为例,通过分析研究区概况及历史滑坡灾害情况,选择高程、坡度、坡向、岩性、归一化植被指数以及断层等6 个评价因子,构建了丹巴县滑坡灾害影响因子体系,并采用多层感知器(Multilayer Perceptron Model,MLP)模型预测研究区内各个区域的滑坡灾害发生的概率。通过对比基于Mask RCNN模型检测的滑坡灾害点在滑坡发生概率分区中的分布情况,来验证滑坡检测结果的准确性。
使用MLP 模型对丹巴县滑坡灾害发生概率进行预测的具体流程如图13所示,历史滑坡样本点与随机生成的非滑坡样本点按照1∶1 的比例构建样本数据集,获取每个样本数据所对应的影响因子值,并将获取多源数据信息的样本数据集输入到数据挖掘软件SPSS Modeler 中进行模型的训练、验证与测试。将样本数据集的70%设置为训练数据集、15%设置为验证数据集、15%设置为测试数据集,得到最优模型的测试数据集精度为82.1%。用训练好的最优模型预测整个研究区发生滑坡灾害的概率,得到研究区滑坡灾害发生概率图。统计滑坡检测点在研究区滑坡灾害发生概率图中的分布情况,发现79%滑坡检测点分布于滑坡发生概率>80%的区域(如图14所示),验证了基于Mask R-CNN 的滑坡检测方法的可行性以及准确性。发生概率<80%的区域也有滑坡发生的可能性,所以有21%的点落在该区域。
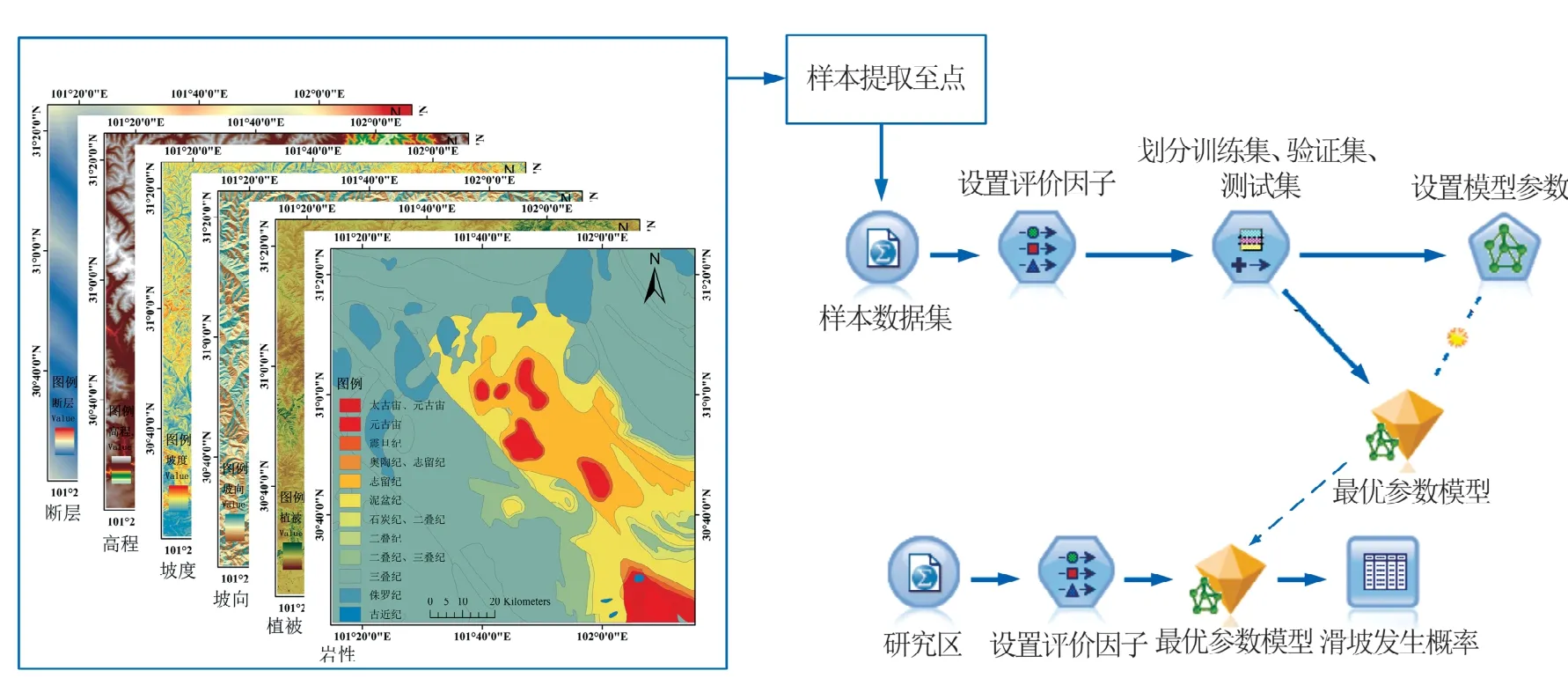
图13 多层感知器模型滑坡发生概率流程图

图14 滑坡灾害点在研究区滑坡灾害发生概率图中的分布图
4 结论
针对传统滑坡检测方法自动化程度低、检测精度不高的问题,文章将深度学习、迁移学习与遥感技术相结合,以Google Earth 遥感影像为数据源构建了历史滑坡样本集,使用Mask R-CNN 目标检测算法实现大范围滑坡信息的自动检测。经过分析得到以下结论:
(1)以丹巴县为研究区的山体滑坡案例研究结果显示,山体滑坡识别精确率为96%、召回率为85%、F1 值为0.90,且有79%的滑坡检测点分布于滑坡发生概率>80%的区域,表明Mask R-CNN 目标检测算法训练的模型能够快速准确地识别大范围的山体滑坡。
(2)以永靖县为研究区的黄土滑坡案例研究结果显示,黄土滑坡识别的精确率为98%、召回率为65%、F1 值为0.78,表明Mask R-CNN 目标检测算法对黄土滑坡的检测精度较高,但由于黄土滑坡的光谱信息与背景一致,检测结果存在较多漏检现象。
(3)文章综合考虑地形特征和纹理特征,有效地提高了地质灾害信息获取的自动化程度以及滑坡检测的精度,为从高分辨率遥感影像中快速准确地提取滑坡信息提供了一种方法,同时对地质灾害普查工作也具有重要意义。
猜你喜欢
河北地质(2021年1期)2021-07-21
中学生数理化·高一版(2021年2期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
电子制作(2018年11期)2018-08-04
数学学习与研究(2017年3期)2017-03-09
北方交通(2016年12期)2017-01-15
水利科技与经济(2016年6期)2016-04-22
测绘科学与工程(2016年5期)2016-04-17
山东青年(2016年3期)2016-02-28
中国老区建设(2016年1期)2016-02-28
