
基于“推荐-学习”的两阶段数据布局策略
2023-12-19 09:21丁长松胡志刚
南京师大学报(自然科学版) 2023年4期
梁 杨,丁长松,胡志刚
(1.湖南中医药大学信息科学与工程学院,湖南 长沙 410208)(2.湖南省中医药大数据分析实验室,湖南 长沙 410208)(3.中南大学计算机学院,湖南 长沙 410083)
近年来,智能手机、联网汽车、AR/VR等智能设备快速普及,各类移动终端产生的数据量呈爆炸式增长[1]. 多接入边缘计算(multi-access edge computing,MEC)作为一种邻近计算范式,其本质是云计算向边缘网络的延伸. MEC允许边缘服务器分布在不同的地理位置,将计算和存储资源部署在移动用户附近,因此可以提供比云计算服务更低延迟[2]. MEC框架在满足访问时延的前提下,在节省网络带宽、提高服务质量(quality of service,QoS)、缓解数据中心压力等方面具有天然的优势. 然而,在数据密集型应用场景下因资源受限所带来的一系列问题正引起研究者们的广泛关注[3]. 由于边缘节点存储资源有限,数据密集型应用会频繁地进行远程数据访问,从而导致较高的往返延迟,甚至完全抵消MEC的优势[4].
在MEC环境中,大量移动边缘设备将不断产生和消费各类数据,不恰当的副本管理策略极易导致网络资源浪费和通信延迟过高[5]. 一方面,当处理本地用户任务的数据访问请求时,由于边缘节点存在严重自治,通常需要分别创建副本以减少远程数据访问的次数,很容易出现副本的高冗余存储和高频次更新,导致“副本泛滥”、资源浪费等问题[6];另一方面,云边网络用户对数据副本的多边高并发请求具有随机性和区域性,增加了“副本管理失控”的风险[7]. 因此对数据副本进行全局部署时,需要综合权衡局部和全局的资源互补与冲突,进而确定最佳副本布局.
一般,不合理的副本部署不仅会增加任务响应延迟,还会增加网络和存储开销[8]. 为解决上述问题,本文提出一种基于“推荐-学习”的两阶段数据布局策略(two-stage data placement strategy,TDPS),通过“推荐”阶段和“学习”阶段对副本放置规则进行深度优化. TDPS综合考虑了副本流行度和用户移动性,旨在实现访问延迟和成本开销的权衡优化. 综上所述,本文的主要贡献包括4个方面:
(1)提出了一种基于“推荐-学习”的两阶段副本管理框架,通过将MEC环境下副本决策过程分解为“边缘推荐”和“整体学习”两个阶段,有效整合了边缘端的局部信息和云端的全局信息,优化了副本管理机制;
(2)对目标问题进行形式化描述并构建了数学模型,将MEC中的副本放置决策问题描述为具有延迟和成本约束的双目标优化问题;
(3)在“推荐”阶段,提出一个基于移动预测和反馈优化的副本推荐引擎,一定程度上解决了盲目创建副本的问题;在“学习”阶段,提出一个基于A3C强化学习的副本放置规则学习模型,从全局视角下进一步保证了云边系统的数据服务性能最优;
(4)实验结果表明,本文基于“推荐-学习”的两阶段数据布局策略可以有效降低数据管理成本并改善用户QoS满意度.
1 相关工作
随着云计算和边缘计算逐步融合,如何提高云边系统的副本管理效率成为一个新兴的研究热点,引起国内外研究者的广泛关注[9]. 一些研究学者提出了基于数据流行度的静态副本策略[10],在指定的存储节点上设置固定的副本数量;而另外一些研究人员则提出了动态副本策略[11-12],允许根据用户的行为特征动态地调整副本数量和位置. Jin等[13]提出了一种边端协作存储框架,在边缘计算环境中协作存储必要的数据,以提高边缘层的性能,减少将任务转移到云数据中心的可能性. Vales等[14]提出一个将移动设备的存储资源和雾节点集中起来的解决方案,有效解决了用户访问远程云时面临的访问延迟、带宽受限、通信开销和位置盲目性等问题. Chang等[15]通过分析边缘服务器的数据副本收入、成本和利润,提出了面向MEC的自适应副本机制,有效地缩短了任务平均响应时间,提高了数据分组的服务质量.
由于边缘端存储资源和通信带宽都存在一定限制,副本优化机制需要充分考虑资源受限条件下的副本管理. Teranishi等[16]提出了一种面向边缘环境下物联网应用的动态数据流平台,不仅能够使物联网应用实现较小的延迟,而且可以避免物联网应用对网络和计算资源造成过载;研究者还提出了一个具有多因素最少使用算法的分布式多级存储模型[17],为处理海量物联网数据时可能面临的存储受限和网络拥塞等问题提供了有效的解决方案;Aral等[18]提出了一种智能分布式数据部署方案,解决了数据访问延迟和副本放置成本等问题.
以上早期研究虽然考虑了边缘端资源的有限性,但主要不足之处在于没有充分利用云端已有的高性能资源. 对此,一些研究者针对云边系统的副本管理优化提出了若干新方法,其中最为突出的是基于机器学习的副本管理. Wang等[19]提出了一种基于强化学习的副本缓存框架,用于激励边缘设备为周边用户提供副本存储服务;为了能够自适应地利用网络资源并降低任务响应时间,研究者还提出了一种基于深度强化学习的智能资源分配方案[20]. 以上研究显示,机器学习技术在实现“在线副本服务”方面具有较好的自适应性和鲁棒性.
综上所述,优化数据布局既需要考虑边缘资源的受限性,还需要考虑网络传输速度的差异性. 本文从以上两个方面来分析现有系统数据服务的性能瓶颈,并提出基于“推荐-学习”的两阶段数据布局策略来动态协调云端和边缘端的存储资源分配,以期充分利用云端的高性能来弥补边缘端的资源短缺.
2 系统框架和数学模型
根据云边环境下面向移动用户的典型应用场景,本节提出了一个两阶段副本管理框架,并对目标问题进行模型构建.
2.1 基于“推荐-学习”的两阶段副本管理框架
在云边协同系统中,一个有效的数据布局策略必须充分考虑云端和边缘端资源性能的差异. 针对由此导致的一系列性能瓶颈问题,本文提出了一种基于“推荐-学习”的两阶段副本管理机制TDPS,其整体架构如图1所示.
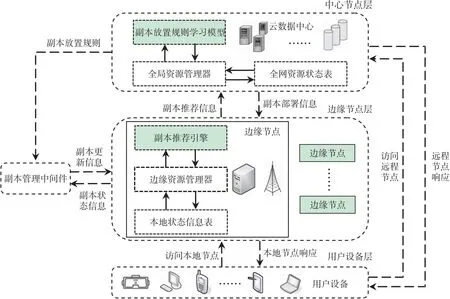
图1 基于“推荐-学习”的两阶段副本管理架构
在图1中,TDPS架构从逻辑上自下而上主要包含3层:用户设备层、边缘节点层和中心节点层.
(1)用户设备层:主要包含各种具有移动性的用户设备,需要向边缘云或中心云请求数据服务.
(2)边缘节点层:主要由分布式边缘节点组成,各边缘节点部署有副本推荐引擎、边缘资源管理器和本地状态信息表,负责向中心节点层推荐热点副本.
(3)中心节点层:云数据中心是本层的重要组件,主要包括副本放置规则学习模型、全局资源管理器和全网资源状态表,负责对全网数据布局进行决策.
2.2 问题描述与系统建模
假设E={e1,e2,…,en}表示所有边缘节点的集合,n为边缘节点的总数;F={f1,f2,…,fm}表示所有可访问的文件全集,m为文件总数;SZfi表示文件fi的大小.用户所感知的访问延迟主要依赖于用户和待访问文件之间的距离,则用户和其对应边缘节点之间的平均等待延迟如式(1)所示.
(1)
式中,VE表示边缘节点的数据传输速率;NRfi表示用户请求访问文件fi的总次数.Xfi,ej是一个二进制变量,用以表示fi的副本是否位于ej上,如果fi的副本位于ej上,则Xfi,ej=1;否则Xfi,ej=0.
简化起见,假设云数据中心存储了所有文件的副本,如果用户对fi的访问请求没有在本地得到满足,则必须向远程云请求fi,用户与云数据中心之间的平均等待延迟可以表示为式(2).
(2)
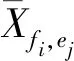
此外,资源开销同样制约着数据布局问题的决策.本文主要考虑副本放置过程中网络传输成本和边缘存储成本对总成本的影响.网络传输成本是指文件从云数据中心传输到边缘节点所产生的网络传输开销,如式(3)所示.
(3)
式中,Tunit表示从云数据中心到边缘节点的单位数据传输成本,Ctx表示总传输开销.
此外,因副本放置造成的存储开销亦不容忽视,则边缘节点的副本存储成本可以表示为式(4)所示.
(4)
式中,Sunit表示边缘节点上单位数据的存储成本,Csto表示总存储开销.
目标问题进一步转化为式(5)所示.
Ψ=μ(ALE+ALC)+η(Ctx+Csto),
(5)
式中,μ+η=1,0<μ,η<1.
基于上述分析,为表示延迟和成本敏感的数据布局问题,构建了如式(6)所示的双目标优化函数.
(6)
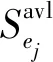
3 基于“推荐-学习”的两阶段副本管理机制
本节提出一种基于“推荐-学习”的两阶段副本管理机制,综合权衡全网的QoS和资源开销,进而确定当前工作周期内最优的全局副本放置规则. 在副本推荐阶段,通过在边缘节点上构建副本推荐引擎快速、准确地量化边缘层副本访问价值,缩小存在副本需求的局部文件规模,避免云端/边缘端盲目创建副本,使服务提供商在保证QoS的同时减少不必要的资源开销;在副本放置阶段,云数据中心基于强化学习构建全局副本放置规则学习模型,优化数据布局,以期指导副本管理中间件进行副本放置和替换,在QoS和成本开销间达到最佳折中,从整体上改进云边环境下副本服务的各类性能指标.
3.1 基于移动预测和反馈优化的副本推荐引擎
为了快速、准确地量化边缘端副本价值,最大程度减小副本规模,本文首先在边缘节点上构建副本推荐引擎,从局部层面上避免副本的盲目创建.
一方面,推荐引擎必须充分考虑用户移动性和文件访问特性,从而准确评估文件访问概率;另一方面,引入反馈机制及时修正误差,提高推荐引擎自适应性. 基于此,副本推荐引擎的框架如图2所示.
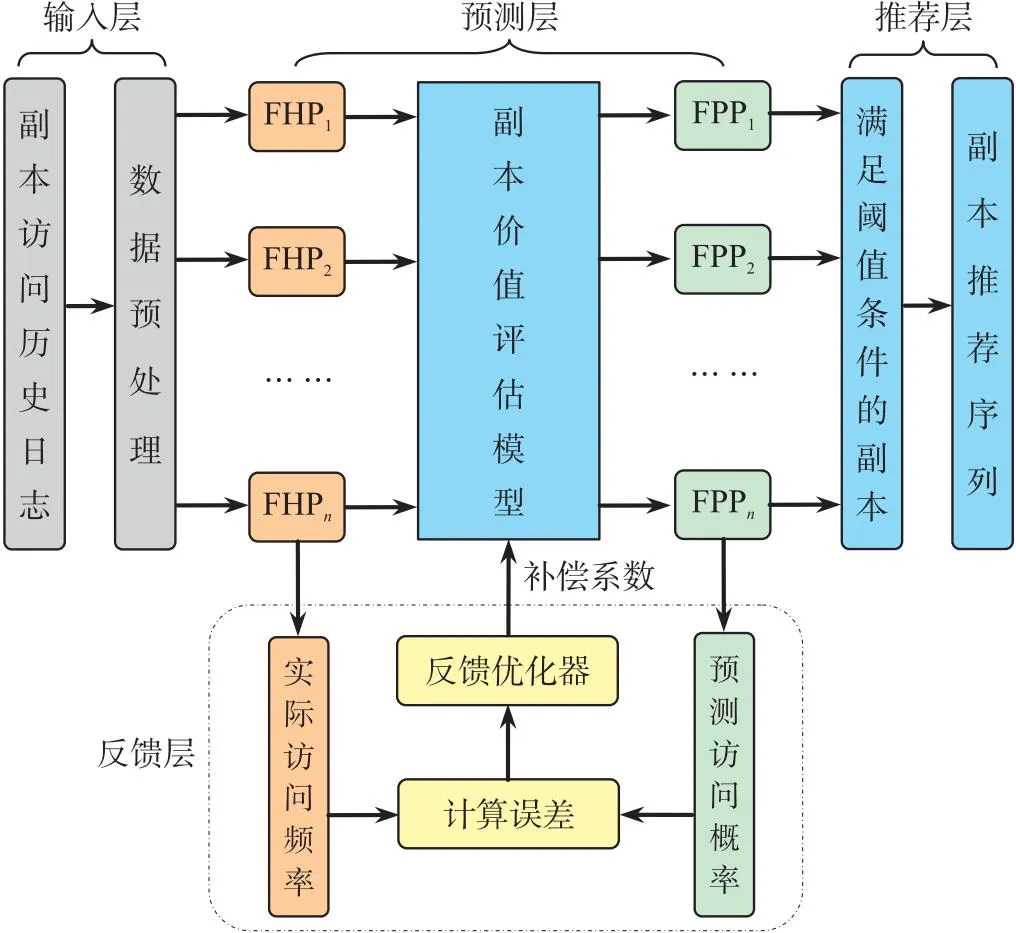
图2 基于移动预测和反馈优化的副本推荐引擎
由图2可以看出,副本推荐引擎主要由输入层、预测层、反馈层和推荐层组成. 其中,输入层负责对数据进行预处理以满足模型输入的要求;预测层根据文件历史流行度和用户移动性来预测本地节点上不同副本的期望访问概率;反馈层负责将副本的预测误差输入到反馈优化器,计算误差期望并确定补偿系数,及时反馈给预测层优化预测精度;推荐层负责筛选满足条件的副本,从中选择价值排名靠前的若干副本,构成副本推荐序列.
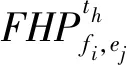
(7)
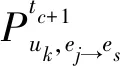
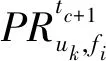
(8)
由此可见,副本推荐引擎同时考虑了边缘节点上的文件历史访问流行度和用户移动性的影响.
为改善价值评估模型性能,提高模型自适应能力,本文在推荐引擎中引入反馈层,对预测层结果进行误差分析,通过补偿系数进一步对模型进行修正,则式(8)进一步改进为式(9)所示.
(9)
式中,λtc表示在时段tc时的模型补偿系数,且λtc>0.
最后,推荐引擎将根据副本期望访问概率进行推荐,具体推荐过程如算法1所示.
首先,将tc时段边缘节点es上的所有文件的期望访问概率集作为推荐层的输入;其次,根据价值阈值筛选出期望访问概率不低于该阈值的文件;最后,如果存在满足阈值要求的文件,则返回期望访问概率中排名前K(K>0)的副本标识符列表.

算法1 副本推荐算法
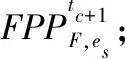


② fori=1 tomdo
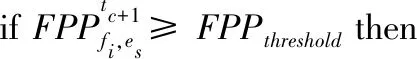
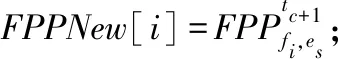
⑤ else
⑥FPPNew[i]=0;
⑦ end if
⑧ end for
⑨ ifFPPNew!=NULL then
⑩FPPTopK[·]=TopK(FPPNew);
3.2 基于A3C强化学习的副本放置规则学习模型
边缘端推荐的副本序列存在一定的局部性限制,为保证全局层面的QoS和系统性能最优,本文提出一种基于异步优势行动者-评论家算法(asynchronous advantage actor-critic,A3C)的副本放置规则学习模型,采用基于多线程机制的异步训练框架,引入优势函数对策略网络(Actor)和价值网络(Critic)进行更新,使模型在训练速度、收敛性能和预测精度等方面具有更好的表现. 该模型由多个并行子线程和一个全局网络组成,每个子线程由一个Actor和一个Critic组成,负责独立运行Actor-Critic算法和并行进行参数探索,既独立更新全局网络参数,又从全局网络获取参数指导;全局网络主要包括一个全局Actor和一个全局Critic,负责汇总子线程与环境交互的结果,异步更新全局网络参数.
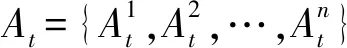
(10)
式中,T表示矩阵转置,πj表示ej上的副本放置模式,πj,i表示fi的副本放置在ej上的概率,πj,i∈[0,1].πj,i=0表示fi的副本不能放置在ej上;反之,πj,i=1.
为有效度量智能体所选动作策略的优劣,本文提出一个延迟-成本组合奖励函数,如式(11)所示.
(11)
式中,Lt(St,At)和Ct(St,At)分别表示在状态-动作对(St,At)下的访问延迟和成本开销,LCt(St,At)表示组合奖励.基于此,长期累计奖励如式(12)所示.

(12)
式中,γ∈(0,1]为折扣因子,表示从环境状态St开始,未来环境奖励对累计奖励的影响权重.显然,模型训练目标可以表示为最大化长期累计奖励的期望,如式(13)所示.
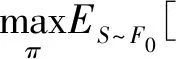
(13)
式中,环境状态S服从先验分布F0,π表示在环境状态St下选择的副本放置策略,则此时状态价值函数如式(14)所示.
Vπ(St)=Eπ[Rt|St=S],
(14)
类似地,智能体的动作价值函数如式(15)所示.
Qπ(St,At)=LCt(St,At)+γVπ(St+1),
(15)
为寻找使长期累计奖励期望最大化的副本放置策略π,需要不断更新策略参数θ,对此,智能体采用优势函数来评价某一策略动作所产生的增益大小,如式(16)所示.
Aπ(St,At)=Qπ(St,At)-Vπ(St),
(16)
式中,Vπ(S)的值由Critic网络训练获得,若Aπ(S,A)>0,则表示在状态St下执行的动作有利于奖励的增加,策略参数可以朝梯度方向更新以改进副本放置策略;反之,则不建议更新策略参数.为加快长期累计奖励期望收敛,通过梯度上升法更新Actor策略网络参数θ,如式(17)所示.
θ=θ+μθlogπ(At|St;θ)Aπ(St,At),
(17)
式中,π(At|St;θ)∈[0,1]表示在St和θ条件下执行At的概率,logπ(At|St;θ)∈[0,+∞)避免了梯度消失.μ为学习率,μ∈[10e-6,1].另外,为避免过早陷入局部收敛,在策略函数的损失函数中需增加π的交叉熵项,则式(17)可改进为式(18)所示.
θ=θ+μθlogπ(At|St;θ)Aπ(St,At)+ηθH[π(St;θ)],
(18)
式中,η为交叉熵权重因子,η∈[0,1].基于时间差分方法进行Critic价值网络参数更新,其价值函数的损失函数如式(19)所示.
LOSS=(Qπ(St,At)-Vπ(St))2,
(19)
为加快式(19)所示损失函数收敛,通过梯度下降法更新Critic策略网络参数θv,如式(20)所示.
(20)
式中,ε为学习率,ε∈[10e-6,1].对此,副本放置规则的A3C子线程学习算法伪代码如算法2所示.
算法2 A3C子线程学习算法
输入:环境状态集合S,智能体动作集合A,A3C全局网络的全局Actor参数θ和全局Critic参数θv,A3C子线程的Actor参数θ′和Critic参数θ′v,全局最大迭代次数Tmax和全局迭代计数器T,子线程单次迭代最大时间序列tmax和本地线程时间序列计数器t,折扣因子γ,学习率μ、ε,交叉熵权重因子η;
输出:A3C全局神经网络参数θ、θv.
①T=0 andt=1
② repeat
③ dθ←0 and dθv←0;
④θ′←θandθ′v←θv;
⑤tstart=tandSt=getState(t);
⑥ repeat
⑦ 基于π(At|St;θ′)执行动作At;
⑧ 获得LCt(St,At) andSt+1;
⑨t←t+1 andT←T+1;
⑩ untilt-tstart==tmaxorSt==ST
4 结果与讨论
为评价和分析所提出算法的性能,本文引入副本命中率、平均访问延迟和成本节约率等[22]3项测试指标作为评估标准,将TDPS策略与其他基准算法进行比较,验证所提算法在副本决策方面的有效性.
4.1 实验环境设置
本文采用EdgecloudSim[23]平台进行仿真实验,模拟云边环境. 边缘节点的位置分布由BRITE[24]拓扑生成器给出,中心节点设置为距离各边缘较远的数据中心. 为了便于比较和分析,假定所有待访问文件的大小相等,用户提交的作业请求近似服从泊松分布,初始数据位置近似服从齐夫分布,用户优先向附近边缘节点提出访问请求,实验参数的详细设置如表1所示.

表1 实验设置
4.2 实验结果与分析
本实验将TDPS分别与D-ReP[18]、RPME[25]和HRS[26]3种基准算法在副本命中率、平均访问延迟和成本节约率等方面进行对比,每次对比实验采用同一性能指标,分别进行10组独立重复实验,以评估TDPS策略的性能,具体实验结果与分析如下:
(1)副本命中率
副本命中率(replica hit rate,RHR)表示本地副本访问次数占本地用户请求总数的比例,用以衡量该策略的本地化水平,如式(21)所示.
(21)
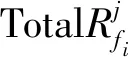

图3 不同副本部署策略的副本命中率比较
图3表明,当并发请求规模较小时,TDPS的副本命中率与其他算法差距不大,甚至略低于某些算法;随着并发请求数的增加,副本命中率总体呈上升趋势,而TDPS的增长幅度明显高于其他算法,说明其具有更好的副本放置决策能力. 主要原因是TDPS同时考虑了文件历史流行度和用户移动性带来的影响,通过预测用户位置并提前放置数据副本,有效提高了副本命中率;当并发请求规模较大时,各算法副本命中率的变化幅度不明显,原因在于边缘节点存储空间有限,当副本数增加到一定程度后,仅进行必要的副本替换,副本命中率趋于稳定.
(2)平均访问延迟
平均访问延迟(average access latency,AAL)表示从作业提交数据访问请求到作业执行完成的平均持续时间,如式(22)所示.
(22)
式中,ti(end)和ti(start)分别表示作业i的完成时间和开始时间,Q表示用户提交的作业总数. 图4对比了TDPS与基准算法在平均访问延迟方面的表现.
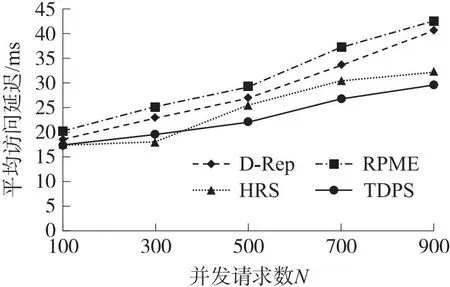
图4 不同副本部署策略的平均访问延迟比较
由图4可以看出,当并发请求数较少时,不同方法的平均访问延迟差别不大,TDPS的平均访问延迟甚至高于HRS,这是因为不同策略创建的副本数量均处于较低水平,使得服务响应时间较为接近;当并发请求数达到500左右时,TDPS的平均访问延迟比D-ReP减少约17.9%,比RPME减少约24.6%,原因在于TRMM具有更高的副本命中率;随着并发请求的增加,TDPS平均访问延迟的增长率明显低于其他算法,进一步说明TDPS能够有效增加用户就近访问数据的机会.
(3)成本节约率
成本节约率(cost saving rate,CSR)表示在所有作业请求中边缘节点完成的作业总费用与中心节点完成的作业总费用之比,如式(23)所示.
(23)
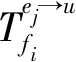
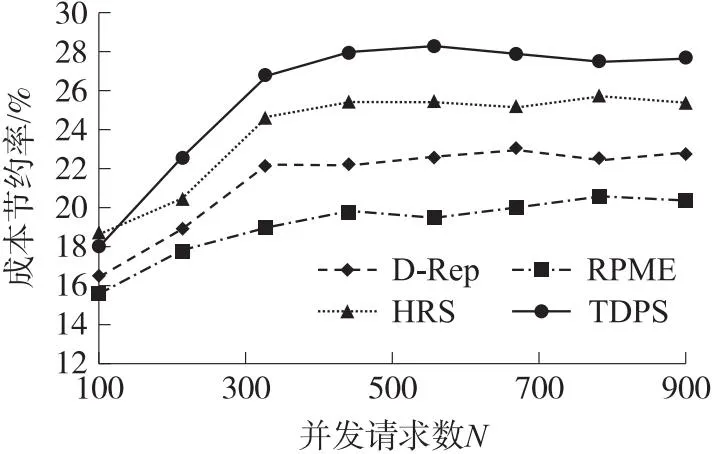
图5 不同副本部署策略的成本节约率比较
在图5中,当并发请求规模较小时,TDPS与其他基准算法的成本节约率差距不大,各策略的成本节约率随着并发请求数的增加而增加;当并发请求数达到500时,与HRS、D-ReP和RPME 3个基准算法相比,TDPS分别能够节约2.68%、5.57%和8.43%的成本开销;之后,随着并发请求规模继续增大,不同算法的成本节约率虽时有波动,但变化幅度始终处于一个较小范围,总体维持动态平衡. 总体而言,TDPS能够更显著地提高成本节约率,原因在于:一方面,TDPS通过分布式副本推荐引擎为各边缘节点推荐个性化副本序列,控制了局部副本规模;另一方面,TDPS基于副本放置规则学习模型优化面向全网的副本放置决策,控制了全局副本规模. 因此,TDPS采用“推荐-学习”的两级副本管理机制在成本控制方面的表现更优.
5 结论
本文提出一种基于“推荐-学习”的两阶段数据布局策略TDPS,解决云边环境下面向数据密集型应用如何改善用户QoS满意度并降低云边协同集群的管理和维护成本等核心问题. 采用基于移动预测和反馈优化的副本推荐引擎挖掘局部热点副本,通过基于A3C强化学习的副本放置规则学习模型有机整合边缘推荐信息,优化全网数据布局. 将TDPS与其他基准算法对比,实验结果表明,所提出策略在不同测试指标下都明显优于其他算法,验证了所提出方法的有效性. 下一步工作将考虑如何根据大规模分布式节点异构性调整数据布局策略,并在真实场景下对研究问题进行实验验证.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
计算机系统应用(2019年2期)2019-04-10
金桥(2018年4期)2018-09-26
通信产业报(2016年44期)2017-03-13
计算机与生活(2016年11期)2016-11-22
中国卫生(2014年5期)2014-11-10
电子竞技(2009年14期)2009-09-07
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
