
自注意力加权半脸的人脸表情识别算法
2023-12-29 12:22汪榕涛刘泽圣
重庆邮电大学学报(自然科学版) 2023年6期
汪榕涛,黎 勇,刘 锐,刘泽圣
(重庆大学 计算机学院,重庆 400044)
0 引 言
人脸表情识别作为情感计算重要的组成部分,在公共安全、智慧交通和医疗康复等领域有着良好的应用前景。在过去的几年里,数据驱动的深度神经网络虽然为人脸表情识别算法注入了新的活力,但是仍面临以下2个关键性难点:①头部的偏转造成了面部遮挡和配准误差,导致识别精度再向上提升变得异常困难,因此难以运用到实际场景中;②现有数据集中存在一些不确定性表情样本,这些样本造成提取出的特征有害。
头部偏转造成的非正面表情识别会引入以下困难:①人脸中五官等面部要素被遮挡,造成表情信息缺失;②头部偏转造成人脸图像发生不同程度的“形变”,使得人脸模型复杂化;③打破光照的均衡分布,改变了图像中部分区域灰度值的大小[1]。这些因素使得人脸图像中的表情属性变得模糊,导致了表情识别模型提取不到鲁棒的表情特征。现有减小头部偏转对于表情识别精度影响的方法主要分为4类:①扩大非正面的人脸表情数据规模;②依靠几何模型搜索图像中的人脸关键点,通过关键点获取表情线索,从而回避头部偏转的干扰;③建立不同偏转角度样本之间的联系,从而借助一种偏转的表情识别出另一种偏转的表情类别;④获取人脸图像的全局和局部表情特征,以局部信息增强模型的抗干扰性[1]。基于人脸关键点的方法是缓解头部偏转干扰的有力工具,Pantic等[2]列举了分布在额头、眉毛、鼻子和嘴唇等周围的10个特征点,这些特征点围成了与表情相关的侧面轮廓,在提取这些关键点特征以后,采用分类方法实现非正面人脸表情识别;Sung等[3]采取了基于视图的2D+3D主动外观模型实现人脸跟踪与表情识别双任务,该模型通过拟合人脸图像中的关键点坐标位置,进而实现对头部姿态的估计,最后将这些信息送入双层广义表情判别分类器中,实现人脸表情的识别。对于建立非正面样本之间的联系,Lai等[4]借鉴了人脸识别中的正则化方法,建立正面人脸与非正面人脸之间的联系,对于不同的非正面图像先利用生成对抗网络(generative adversial network,GAN)生成正面表情图像,再将学习到的头部姿势特征用于后续的表情分类任务;Zhang等[5]利用不同的头部偏转和表情,进行人脸图像合成和非正面表情识别的双任务,首先利用GAN学习人脸图像的生成性和区分性表征特征,合成不同头部偏转下的表情图像,再将表情分类器置于GAN模型后,该方法不仅有效扩充了数据集,而且利用了生成器中的鲁棒特征,可以有效提升识别精度。利用局部特征也可以有效地提升非正面表情识别精度;Liu等[6]用训练好的多通道卷积神经网络对人脸图像、眼部图像和嘴巴图像分别进行特征提取,然后将特征输入到联合多尺度融合网络获得表情特征并判断头部偏转角度,再根据所得头部偏转角度将特征输入到对应的姿势感知表情网络中,最后送入分类网络中得到表情识别结果;Wang等[7]提出区域注意力网络(region attention networks,RAN)模型来应对头部偏转与面部遮挡问题,对于给定的一张图片,首先按照一定的规则选取图片中的局部区域,然后将原始图片与局部区域送入主干网中提取出表情特征,最后将原始图像的全局特征、局部区域的特征及其权重送入分类器得到表情类别。
Wang等[8]首次指出表情数据集中存在不确定性问题。模糊的表情、低像素的图像以及标注者的主观性,这些都导致现有的面部表情数据中存在一些不确定性样本。针对这种情况,Wang提出了自治愈网络(self-cure network,SCN)模型,它将同一批次中的每张输入图像分配不同的权重,其中,不确定性的图片会被分配低权重,并通过排序正则化损失函数将同一批次的图片分为高注意力和低注意力两组,最后设置重标签模块为那些被判定为错误标签的样本重新分配合适的伪标签。
1 基于自注意力加权半脸的人脸表情识别模型
不同于上述方法,本文从以下角度来缓解头部姿势与不确定性样本的干扰。
1)对于头部偏转,自注意力加权半脸辅助模块首先将人脸区域划分为左右半脸局部区域,为其分配不同的权重,使左右半脸局部区域的预测对最终结果的影响不同,从而有效缓解头部偏转的影响。相较于上述的局部特征方法,半脸结构不仅减少了计算量,而且包含了部分五官信息,可以提供更丰富的局部特征。
2)对于数据集中的不确定性图片,自适应重标签模块提供2个维度帮助模型定位。①利用全局和辅助预测之和判断与原标签是否不一致;②判断全局预测和辅助预测是否相符。当2个判定条件都满足时,才允许为图片分配伪标签。相较于其他方法,该模块更加严谨精确。
3)部分表情信息只占据了图像中很小的区域,而这些信息会在卷积、池化堆叠的过程中简化甚至消失。为了抑制特征丢失,本文研究了一种多特征融合主干网。该主干网首先取消了全局池化的设置,利用上采样和大核卷积达到参数降维、防止分类器过拟合的目的;其次保留了浅层的低级特征,利用上采样和大核卷积抵消特征图中的噪声干扰。此外,为了增强主干网的表情特征学习能力,把表情特征划分为人脸共享特征和表情差异特征,前者是从数据集中所有的表情图像经过计算提取得到的,因此,主干网不用从头学习表情特征,只需要学习后者,从而简化了学习过程。
基于自注意力加权半脸的人脸表情识别模型的框架如图1所示。本方法主要由5个小模块构成,即图片切割、多特征融合主干网、自注意力权重、双线预测融合和自适应重标签。其中,图片切割、自注意力权重和双线预测融合构成自注意力加权半脸辅助模块用以对抗非正面表情识别,自适应重标签帮助模型定位数据集中不确定性表情图片并为它们分配合适的伪标签。

图1 自注意力加权半脸的人脸表情识别算法框架Fig.1 Facial expression recognition method based on self-attention weighted half-face
1.1 图片切割
给定一幅正面或非正面的表情图像,首先使用多任务级联卷积神经网络(multi-task cascaded convolutional neural networks,MTCNN)[9]检测出人脸框和5个人脸关键点(两只眼睛的中间点,鼻尖和嘴角),按照人脸框坐标首先裁剪出人脸区域Iori,并选择鼻子的坐标点作为分界点,将人脸区域Iori竖直切割成左右人脸区域Ileft和Iright,然后将原始图像Iori和相应的左右脸图像Ileft和Iright缩放至相同的大小(224×224),送入多特征融合主干网提取特征。
MTCNN可以很好地在头部多姿势下准确预测鼻子位置的坐标点。相比于文献[6]的方法,本文仅需鼻尖的坐标位置,发生偏移的概率较小。但是在某些极端偏转中(如90°的偏转),会出现鼻尖点检测失效的现象,由于面部的左右脸存在一定程度的关联性和对称性。因此,直接将原图片沿水平方向翻转后设定为左脸Ileft,原图片设定为右脸Iright,通过这些操作,所有输入图片均获得Ileft和Iright。
1.2 多特征融合主干网
基于深度学习的人脸表情识别方法大都将卷积神经网络作为主干网提取特征,其中包含了大量的卷积、池化操作。随着模型的卷积层和池化层的不断叠加,虽然可以检测到更多关于表情的高级语义信息,但是也丢失了大量的空间信息。由于面部中有关表情的信息本身可能只占图像很少的像素(嘴角、皮肤皱纹等),这些信息在连续卷积、池化的过程中极易丢失,导致在高层特征图中缺少关键性线索,造成表情分类困难。
针对以上问题,本文提出一种基于ResNet18的多特征融合的主干网。为了保留ResNet18的特征提取能力,该主干网并没有更改其内部结构,仅在提取出的特征图上进行融合修改,其框架结构如图2所示。该主干网主要由2个模块构成:特征金字塔和共享特征。特征金字塔的作用有2点:①取消全局池化,充分利用高级语义特征;②保留浅层网络中高分辨率、低级纹理信息的低层特征。下面介绍主干网的详细设置。
1.2.1 特征金字塔


图2 多特征融合主干网Fig.2 Multi feature fusion backbone

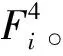
1.2.2 共享特征

(1)
VG=VG+λVbatch
(2)
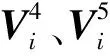
(3)
1.3 自注意力权重
Vori、Vleft和Vright是多特征融合主干网分别从输入Iori、Ileft和Iright中提取的3个特征向量。当头部发生偏转时,左右脸中包含的信息量不同且表情信息会出现不同程度的“形变”,因此它们对最终预测结果的影响也会不同。为了从模型中体现出这种差异,本文采用了自注意力机制。自注意力权重模块由一个全连接层(FC)和一个Sigmoid激活函数组成,它从半脸局部特征向量Vleft和Vright中捕获表情信息的丰富程度和“形变”程度,并以权值的形式数字化,在分类过程中体现了半脸局部特征对最终预测的贡献度。每个局部特征向量Vi相应的贡献度,即自注意力模块中的权重wi,计算过程为
wi=σ(WTVi),i∈{left,right}
(4)
(4)式中:Vi∈R(121×1)表示半脸的局部特征向量;W∈R(121×1)是全连接层的参数;σ(·)是Sigmoid激活函数。经过Sigmoid函数计算后,权重wi落在(0,1)。相比之下,原始图像Iori拥有较丰富的全局信息,所以它的贡献度得分应该固定为1,不需要自注意力权重模块的处理。此外,半脸区域作为表情判断的辅助线索,其权重总和应小于等于原始图像的权重。因此,设计了自我注意力权重损失函数来约束这种关系,其表达式为

(5)
(5)式中,L1(·)是一个平滑的1损失函数[11],数字1来限制左右脸对于最终预测结果的权重接近完整人脸对于最终预测结果的权重,通过该损失函数可以帮助模块有限制地分配权重。
1.4 双线预测融合
对于主干网提取出来的特征,双线预测融合模块的结构可以分为2行来处理:①根据提取的原始特征Vori作出全局预测Pori;②基于左右脸区域的局部特征做出局部预测,即
(6)
(6)式中:Wfc∈R(121×n)为全连接层的参数矩阵;n为表情类别数。特别地,将半脸区域的预测结果Pleft和Pright分别乘以它们相应的权重wleft和wright来构成辅助预测Paux;随后,将Paux与原始图像的预测Pori相结合,得出最终输出P,计算过程为
Paux=Pleft×wleft+Pright×wright
(7)
P=Paux+Pori
(8)
(8)式中,P∈R(n×1)表示模型最终的预测输出,取概率最大的表情类别作为最终的预测结果。为了帮助主干网在非正面条件下提取强表征力的特征,使用平滑的L1损失函数迫使模型在学习局部特征和学习全局特征之间达到良好的平衡。因此,特征平衡损失函数计算过程为
(9)
通过损失函数的反向传播,模型被迫加深对权重更大的局部特征的偏好。此外,为了保证模型学习的特征与表情相关,直接利用模型的输出P与真实标签构成的one-hot向量Pgt构造交叉熵损失函数为
(10)
最终模型的总损失函数为
(11)
(11)式中,α、β和γ是折中比。由于局部信息缺乏全局感受野,急切地迫使模型逼近辅助预测可能会损害模型学习特征的能力。因此,需要仔细调整特征平衡损失函数与交叉熵损失函数之间的比例。
1.5 自适应重标签
人眼进行面部表情识别时,无论面部是正面还是侧面,都可以很好地判断出面部表情。利用这一特性本文重新设计了文献[8]中的重标签模块,利用图像的固有信息就可以帮助模型鉴别出不确定性的图像。因此,在所提的双线预测融合模块后添加了一个自适应重标签模块。具体而言,当P中预测类别与真实标签不匹配时,自适应重标签模块会检查辅助预测Paux是否等于原始图像的预测Pori(图1中的“=?”),如果这2个预测相等,则意味着无论从局部信息或是从全局信息的角度来看,图像均被认为属于另一种表情,之后本模块将概率最大的表情作为伪标签分配给原始图像。在其他情况下,不执行任何处理。本模块通过增加辅助预测和全局预测的关系,使得定位不确定性图片更加严谨、精确。本模块仅在训练过程中帮助模型定位不确定性图片,在预测时本模块被遮蔽。
2 实验结果与分析
2.1 实验设置
本文使用的ResNet18网络在ImageNet数据集上进行了预训练,同时将预训练好的ResNet18作为实验的基准方法,用于对比实验。根据实践经验,本文中的超参数设置如下:batch_size大小为128;学习率为0.001;λ为可更新参数;总损失函数中的折中比率α、β和γ分别设置为3、1和2;模型的训练次数为70,并在第10个epoch后,让重标签模块参与训练、优化。此外,由于RaFD数据集没有划分训练集和测试集,所以本文采用5折交叉实验最后取平均值为最终结果。本文所有实验结果均为10次实验后的平均值。
2.2 消融实验
为了评估自注意力加权半脸模型中每个小模块的有效性,本节在RAF-DB上设计了消融实验来研究模型中的后4个模块对识别精度的影响,实验结果如表1所示。

表1 消融实验Tab.1 Ablation experiment %
为了便于比较,自注意力权重模块与双线预测融合同时被遮蔽、参与训练优化。由表1可知,仅将自适应重新标记模块(第2行)添加到基准方法(第1行)会略微降低精度,这说明只依靠ResNet18不能提取强表征力的特征,此时模型还未“掌握”识别表情的知识,这时的重标签模块将是有害的。之后添加了其他几个模块,明显地提高了模型的性能(第6行和第7行),这表明多特征融合主干网、自注意力权重和双线预测融合模块能有效学习提取表情特征。本文所提出的模块均在一定程度上提升了识别精度,其中多特征融合主干网的贡献度最大,约提升3.23%(第4行)。
2.3 非正面表情识别性能分析
为了验证所提方法是否能提升非正面表情识别精度,本节在RAF-DB测试集上选取了不同姿势的表情图片进行验证,实验结果如图3所示。可以看出,这些图片存在着一定的信息缺失与人脸模型“变形”,基准模型在面对头部姿势偏移时,分类结果性能较差;而本文提出的模型可以很好地克服这一点,可以在多种偏重角度下有效识别图像中的表情类别。

图3 基准方法与自注意力加权半脸方法的实验对比Fig.3 Experimental comparison between baseline and self-attention weighted half-face method
此外,根据文献[7]提供的头部姿势数据(30°偏转和45°偏转),本文所述模型还与其他模型对比了非正面表情识别能力,结果如表2所示。表2显示,在RAF-DB、FERPlus和AffectNet数据集上,RAN模型与本文所述方法的识别精度均远高于基准模型,并且相比于RAN取得的收益,本文方法更能克服头部偏转带来的负面影响。
2.4 定位不确定性图片性能分析
为了验证本文所提的自适应重标签模块比SCN中带阈值的重标签方法更有效,将设计的自适应重标签模块替换为SCN中带阈值的重标签方法来进行对比,具体设置:对于模型最终预测向量P,将向量中的最大值减去向量中标签对应的概率值,若差值大于给定阈值就为该图像重新分配伪标签,相应的对比结果绘制在图4中。由图4可知,SCN中僵硬的阈值重标签方法在不同阈值下识别精度有所不同,这是因为在不同的阈值情况下,不确定性图片被误判漏判的可能性被放大或缩小;而本文提出的自适应重新标记方法总是具有更高的精度(90.76%)。

表2 多姿势识别准确率对比表Tab.2 Comparison table of recognition accuracy with multi-pose %

图4 重标签方法的对比Fig.4 Comparison of relabeling methods
除了验证自适应重标签模块的有效性以外,本文还深入训练过程中探究分配伪标签的合理性,结果如图5所示。

图5 训练过程中样本标签的变化情况Fig.5 Changes of image labels during training
图5a—5c中的第一列图像被精确标记,因此,自适应重标签模块从始至终没有更改过图片标签。图5a—5c中的第二列和第三列表明自适应重标签模块认为其特征分类结果和标签值不一致,因此,在训练过程中为图片重新分配合适的伪标签。图5a—5c中的最后一列原图片被误分类为另一种表情,但在模型训练一定次数后,这个错误最终得到了纠正。
2.5 实验结果比较
为了评估自注意力加权半脸模型中每个小模块的有效性,将所述方法与最近的表情识别方法在RAF-DB、FERPlus和RaFD上进行了比较,对比结果如表3—表5所示。

表3 与其他方法在RAF-DB上的对比Tab.3 Comparison with other methods on RAF-DB

表4 与其他方法在FERPlus上的对比Tab.4 Comparison with other methods on FERPlus

表5 与其他方法在RaFD上的对比Tab.5 Comparison with other methods on RaFD
实验结果表明,本文所提模型均获得了较高的识别精度,在RAF-DB、FERPlus和RaFD上分别获得了90.76%、91.08%和98.66%的识别精度。
由于表3—表5中仅使用了单一的识别准确率评价指标,这不能体现数据集中不同表情类别之间的识别精度差异。因此,除了上述表格外,还绘制了混淆矩阵来展示不同表情的识别精度分布,如图6所示。矩阵中对角线上的元素表示相应表情的识别精度,其余位置为误分类的情况。在RAF-DB数据集中样本数较小的表情类别(恐惧和厌恶)均有明显的提升;对于中性表情,本文所提模型可以达到99%的识别准确率。在RaFD数据集中,多个表情类别的识别精度可以达到100%。而在FERPlus中,轻蔑表情识别精度最低,只有25%,这可能是因为FERPlus是对FER2013重新标注,且轻蔑表情为新添加的标签,新标签与原数据存在一定差异,导致模型分类效果较差。
3 结束语
本文提出的自注意力加权半脸的人脸表情识别方法,在一定程度上缓解了头部偏转与不确定性的干扰,在多个数据集上均有一定的性能提升。与其他非正面表情识别方法相比,本文所述方法以增加一定复杂度为代价,有效提升了非正面表情识别精度;与其他重标签方法相比,本文提供2个维度从而更加严谨地判断图片是否应被重标签,这为以后的数据清洗工作提供了自动化方法。此外,本文将表情识别任务与其他分类任务相区分,不仅利用了低级特征,还将表情特征划分为人脸共享特征与表情差异特征,这不仅丰富了表情特征,而且简化了模型的学习过程。

图6 模型在不同数据集的混淆矩阵Fig.6 Confusion matrix of model in different datasets
猜你喜欢
中国教育网络(2022年1期)2022-04-12
小雪花·成长指南(2022年1期)2022-04-09
少儿美术·书法版(2021年9期)2021-10-20
海洋信息技术与应用(2020年2期)2020-07-27
中国教育网络(2019年10期)2019-12-13
动漫星空(2018年9期)2018-10-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国交通信息化(2016年10期)2016-06-08
发明与创新(2015年33期)2015-02-27
