
基于数据平稳化和BiLSTM的短期风电功率预测方法
2023-12-29 12:23唐贤伦张家瑞郭祥麟
重庆邮电大学学报(自然科学版) 2023年6期
唐贤伦,张家瑞,郭祥麟,邹 密
(重庆邮电大学 自动化学院,重庆 400065)
0 引 言
风能作为一种成本低、发电过程无污染的清洁可再生能源,逐渐成为能源与环境可持续发展的主力军。然而,风电具有的随机性和不可控性会直接影响风电场甚至整个电力系统的安全性和稳定性。因此,提高风电功率预测的准确性对提高电力系统运行的安全性、经济性和稳定性具有重要意义。
常见风电功率预测的方法可以分为物理方法、统计方法和人工智能的方法[1]。近年来,基于人工智能技术的飞速发展以及其强大的并行处理非线性序列的能力,研究人员已将人工智能广泛应用于风电功率预测研究中。文献[2]提出一种基于新型隐马尔可夫模型的风速校正方法,通过引入模糊C均值聚类对隐马尔可夫模型的隐状态空间进行合理划分,并通过核密度估计将隐马尔可夫的发射频率转变为连续的,通过风速修正,从确定性预测和概率预测2个方面提高了风电功率预测的精度。文献[3]通过改变预测时刻前时间段的数量来对人工神经网络(artificial neural network,ANN)模型在效率和稳定性方面进行改进,并在预测时改变输入层参数的选择,改善了模型性能,降低了预测误差。文献[4]提出了一种基于长短期记忆网络( long short term memory,LSTM)的区间预测模型,并引入竞争学习机制,对LSTM参数进行优化,提高了预测精度。
以上预测方法主要通过改进和优化预测模型来提高预测精度,忽略了风电功率数据序列本身存在的非平稳性和非线性的问题。对此,有研究人员提出利用小波变换(wavelet transform,WT)、经验模态分解(empirical mode decomposition,EMD)、变分模态分解(variational mode decomposition,VMD)等分解算法将原始风电功率数据序列分解成子序列后再进行预测,以此实现对原始序列的平稳化处理,提高预测精度。文献[5]采用VMD与集合经验模态分解(ensemble empirical mode decomposition,EEMD)相结合的二次分解方法依次对原始时间序列进行分解,从而最大程度保留数据中的有用信息,并通过在LSTM模型中融合因子分解机,整体上提高了预测精度。文献[6]利用改进的小波变换将原始信号分解为子信号,并基于最大相关性等特征选择方法来选择最佳输入,而后通过基于粒子群优化后的二维卷积神经网络对数据集进行训练和预测,并在短期预测范围内分析验证了其方法的高性能和优势。文献[7]提出一种利用离散小波变换(discrete wavelet transformation,DWT)、季节性自回归综合移动平均(seasonal autoregressive integrated moving average model,SARIMA)和LSTM的混合模型完成了对海上风电功率数据的预测。文献[8]通过EEMD将数据分解为本征模态分量(intrinsic mode function,IMF),再经过由遗传算法(genetic algorithm,GA)方法优化后的卷积双向长短期记忆网络(convolutional neural network-bidirectional long short term memory,CNN-BiLSTM)对各IMF进行训练及预测,最后对各IMF的预测结果进行重构,得到最终预测值。为了使VMD能产生合适数量的IMF分量,文献[9]提出一种基于元启发式种群的正弦余弦集成水循环算法(sine cosine integrated water cycle algorithm,SCWCA)对VMD的参数(α,K)进行优化,并通过混合核(mixed kernel ELM,MKELM)自动编码器进行短期多步风电功率预测。
然而,以上分解后再预测的方法大多是将分解后的子序列直接进行预测,忽略了输入变量序列对时间序列预测模型的影响。本文充分考虑上述预测方法的优缺点,针对原始数据序列曲线的非平稳性和非线性,合理有效地选取输入变量序列,提出了一种基于结合自适应噪声完备集合经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)、偏自相关函数(partial autocorrelation function,PACF)和双向长短期记忆网络(bidirectional long short term memory,BiLSTM)的组合短期风电功率预测模型。
1 基于CEEMDAN和BiLSTM的短期风电功率预测方法和流程
在风电功率预测过程中,由于风能本身具有的随机性、波动性、不可控性以及会对风电场发电机组产生影响的环境因素,比如温度、湿度、风向等,使得功率数据曲线表现出强烈的波动性和随机性,增加了风电功率预测的难度。在现有的风电功率预测研究中,大多数是直接将其放进预测模型中进行训练和预测[10-12],很少针对原始功率数据曲线和相关时间序列信息进行分析和处理。因此,为了提高短期风电功率预测的精确度,以及改善因为存在大量峰值而致的原始功率数据曲线图的不平稳性,本文提出了一种CEEMDAN结合BiLSTM网络的组合预测模型,其结构如图1所示。

图1 本文所提预测方法的结构Fig.1 Structure of the prediction method proposed in this paper
1.1 CEEMDAN分解算法
CEEMDAN通过加入经EMD分解后含辅助噪声的IMF分量以及对EMD分解后的第1阶IMF分量进行集合平均计算,解决了EMD算法存在模态混叠以及EEMD算法分解后会残留一定的白噪声等问题。本文使用CEEMDAN对信号进行分解及平稳化处理[13],具体分解步骤如下。
1)将高斯白噪声δj(t)加入到原始信号x(t),得到新信号s(t),即
s(t)=x(t)+δj(t)
(1)
(1)式中,j=1,2,…,N表示加入白噪声的次数。
2)对已添加噪声信号的s(t)进行EMD分解,得到第1阶本征模态分量imf1,表示为
(2)
(2)式中:Ei表示EMD分解得到的第i个模态分量,j=1,2,…,n表示EMD分解得到模态分量的个数,r1为EMD分解得到的残差分量。

(3)
去除第1个模态分量后得到余量R1(t)为

(4)

(5)
去除第2个模态分量后得到余量R2(t)为
(6)
5)重复上述步骤,直到获得的余量为单调函数,不能再继续分解。最终原始信号x(t)被分解为
(7)
(7)式中:k=1,2,…,K表示得到的本征模态分量的数量;R(t)表示最终剩余的残差信号。
1.2 BiLSTM网络
通过在隐藏层中加入遗忘门、输入门和输出门的门结构,LSTM实现了对历史信息合理的保留和遗忘,从而解决了RNN不能有效记忆时间跨度较长的信息以及在处理长序列训练过程中产生的梯度爆炸和梯度消失等问题[14]。LSTM隐藏层内部结构如图2所示。
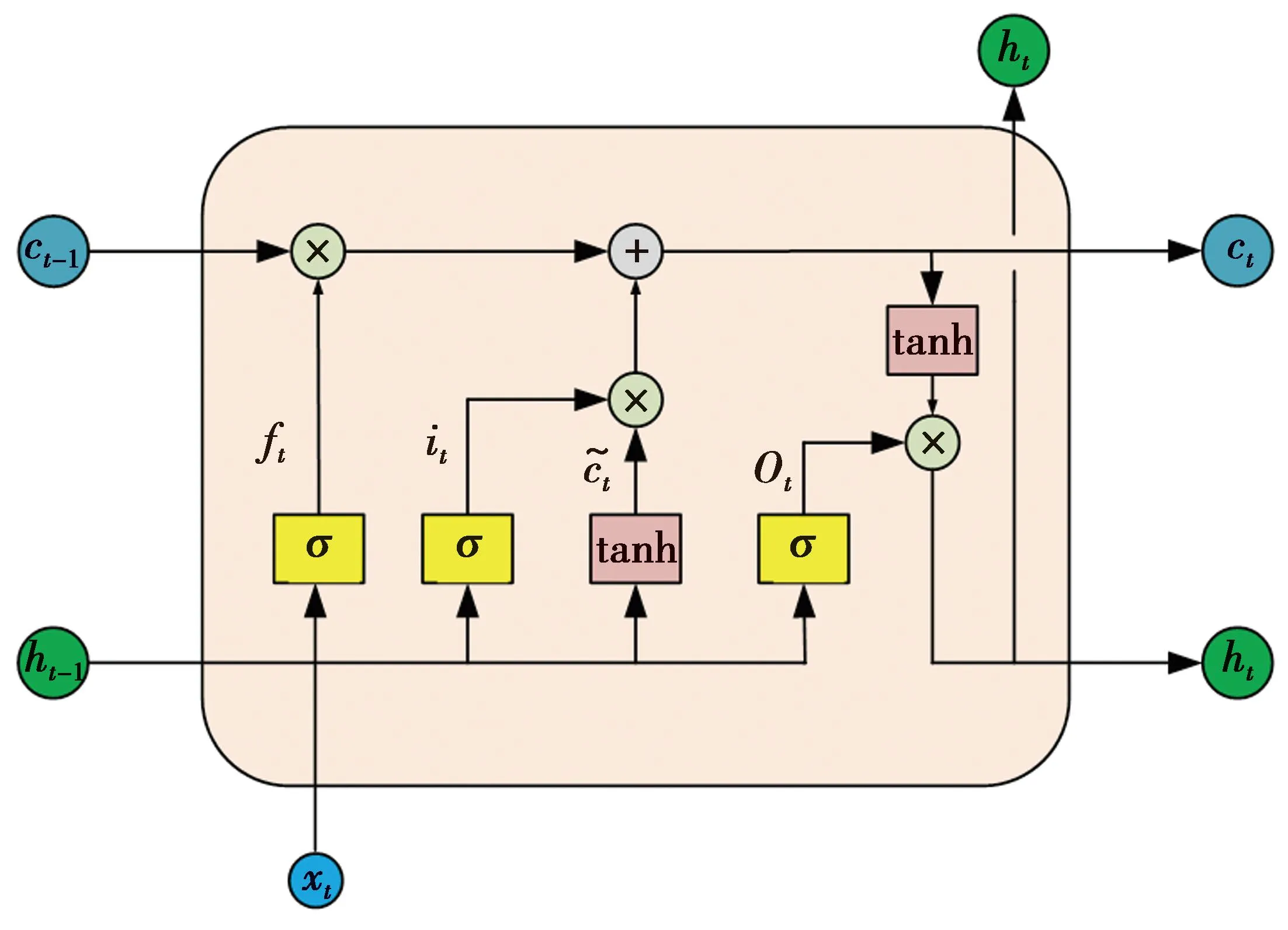
图2 LSTM结构图Fig.2 LSTM structure diagram
图2中,xt表示输入数据,ht和ct分别表示输出数据和LSTM特有的细胞状态。LSTM内部结构的核心处理单元遗忘门、输入门、输出门分别由ft、it和ot表示,其中涉及的公式如下。
ft=σ(Wf·[ht-1,xt]+bf)
(8)
it=σ(Wi·[ht-1,xt]+bi)
(9)
(10)
(11)
ot=σ(Wo·[ht-1,xt]+bo)
(12)
ht=ot*tanh(ct)
(13)

BiLSTM由2层方向相反的LSTM层叠加而成,因此,输入会同时提供给前向层和反向层的LSTM,输出即由这2个LSTM层共同决定[15]。其结构如图3所示。

图3 BiLSTM结构图Fig.3 BiLSTM structure diagram
图3中,x为模型输入,y为输出,中间2层方向相反的LSTM网络组成隐藏层,h表示隐藏层状态。
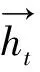
(14)

(15)
(16)
1.3 基于CEEMDAN和BiLSTM的功率预测流程
本文采用CEEMDAN分解算法对功率时序信号进行平稳化处理,将功率序列分解成若干个更为平稳的模态分量。在预测模型方面,采取可以同时处理正反2个时间流向的BiLSTM模型,有利于更好地发掘数据的时序特征,提升短期风电功率预测的精确度。图4为本文提出的短期风电功率预测方法流程图。

图4 本文预测方法流程图Fig.4 Flow chart of the prediction method in this paper
本文方法具体实现步骤如下。
1)对原始数据集进行预处理。采集设备故障、通信故障以及人为误操作等不可预料的因素,可能会导致保存的历史功率数据出现突变和缺失等问题。本文采用横向法来填补、删除或修正历史数据集中出现的不良数据。
2)使用CEEMDAN分解算法将预处理后的功率数据集进行分解得到多个本征模态函数分量和一个残差分量。
3)利用样本熵(sample entropy,SE)计算每个分量的SE值,并将SE值相近的分量归为一类,得到新的重构分量,从而减少需要训练和预测的分量数量,提高预测效率。
4)采用偏自相关函数PACF计算相关程度,确定每个重构分量序列的输入变量,减少人为设置预测模型输入变量的主观性,提高预测精度。
5)对每个重构分量采用min-max方法进行归一化处理,从而消除数据量纲,加速训练网络的收敛。用xnorm表示归一化后的值,其计算公式为
(17)
(17)式中,xmax和xmin分别表示功率数据序列中功率的最大值和最小值。
6)根据由PACF确定的输入变量,建立BiLS-TM预测模型。利用训练集样本对模型进行训练,模型中隐藏层状态的维度为64,输入形状参数为(l,m),其中l为输入变量长度,m为功率数据和天气数据总数。网络训练采用Adam优化算法,对权重进行更新,得到预测模型。以输入变量长度作为滑动窗口长度,采用单步滚动预测方法输出各个重构分量的预测值,并对预测值进行反归一化处理,得到预测的功率值。以均方误差(MSE)值VMSE作为损失函数,表示为
(18)

7)通过叠加各分量的功率预测值得到最终功率预测值,并对其进行综合评价。
2 案例分析
2.1 数据集
本文通过2个不同数据集的实验来分析验证所提预测方法的有效性和优越性。案例1数据集来源于重庆某风电场2012年的全年历史功率数据,数据采样间隔为5 min。同时,数据集还包括每个采集点对应时刻的100 m高度处的自然风向、100 m高度处的自然风速、2 m处的空气温度、地表大气压强、轮毂高度处大气密度5种气象特征。案例2数据集来源于数据科学竞赛平台Kaggle,该数据采集于土耳其某地工作的风力涡轮机,数据包括2018年全年的输出功率,以及对应时刻的风速和风向数据,采样间隔为10 min。
短期风电功率预测的任务和需求是通过预测得到未来1~3天的风电功率,用于规划和调整风电场每天的发电和调度任务[17]。本文实验选取每小时功率峰值以及对应时刻的气象数据值作为被测数据集,目的是预测出未来一天中每小时的功率峰值,共24个数据点。本文实验将数据集按8∶1∶1的比例分布形成训练集,验证集和测试集,分别用于构建及训练预测模型、确定模型参数以及输出预测结果并评估模型的预测性能。
2.2 评价指标
为了评估衡量模型的预测能力,本文选用均方根误差(root mean square error,RMSE)VRMSE和平均绝对百分比误差(mean absolute percentage error,MAPE)VMAPE作为所提出模型的评价指标,其计算公式为
(19)
(20)

2.3 案例1
2.3.1 CEEMDAN分解及重构
选取原始功率数据集前1 000个采样点数据绘制曲线如图5所示。由于风能自身存在的突变性和随机性,数据集存在大量功率峰值和谷点,导致数据集曲线呈现出强烈的非平稳非线性特点。因此,对选取的数据集进行数据清洗处理后,利用CEEMDAN分解算法对原始功率数据序列进行分解,获得分解结果如图6所示。

图5 部分原始功率数据Fig.5 Partial raw power data
图6中,CEEMDAN分解结果包括9个本征模态分量(IMF)和1个残差分量(Res)。为了减少实验重复步骤,提高预测效率,本文将利用样本熵对各个分量序列进行复杂度评估,并将样本熵值相近的分量重构为一组。各分量样本熵计算结果如图7所示。根据图7显示的各分量样本熵值,将分量IMF1、IMF2、IMF3合并重构为新的分量RIMF1;IMF4、IMF5、IMF6重构为RIMF2;IMF7、IMF8、IMF9、Res重构为RIMF3。
2.3.2 确定输入变量
对于依赖历史数据的时间序列预测,输入变量的选取能直接影响预测结果的准确性。目前的时间序列预测研究大多根据实验数据的现实意义及其体现出的周期性来确定预测模型的输入变量,比如电力负荷预测[18-21]等研究。然而对于具有强随机性和波动性的风电功率数据,通常只能依据研究人员的历史经验、相关参考文献以及大量对比实验等方法来确定输入变量[22-24]。为了准确且快速地确定预测模型的输入变量,本文将利用PACF测量当前序列值和过去序列值之间的相关性,并指示预测将来值时最有用的过去序列值,即确定每个预测模型的最优输入变量序列。

图6 CEEMDAN分解结果Fig.6 CEEMDAN decomposition results
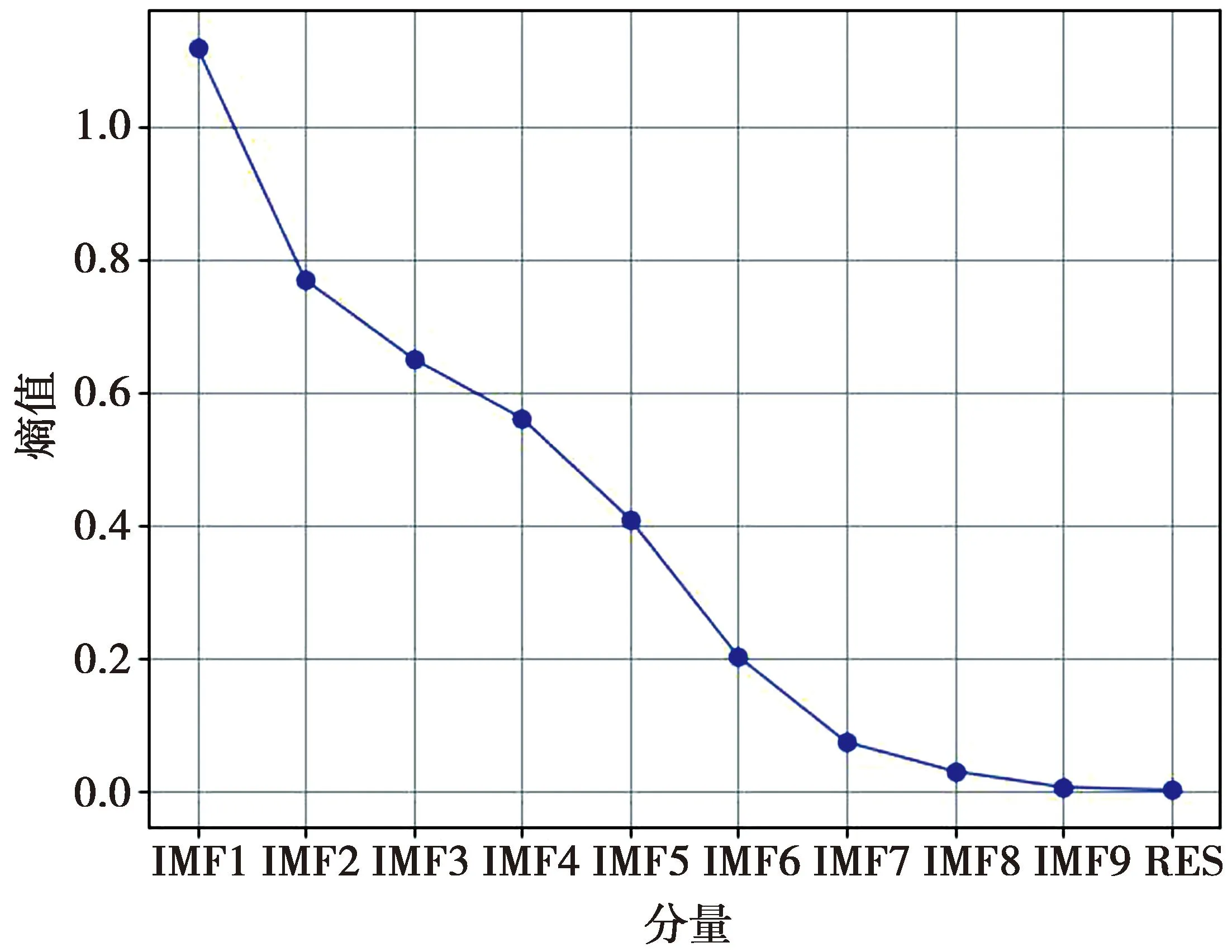
图7 各分量的样本熵值Fig.7 Sample entropy value of each component
分别计算原始风电功率数据序列和各重构分量序列的偏自相关函数,结果如图8所示。根据偏自相关函数定义以及计算得到的滞后阶数图,若在第n个滞后阶数后骤降到相关性置信区间内,则该序列可以做n阶滞后自回归,即可将xt-1,xt-2,…,xt-n作为输入变量序列。案例1输入变量的选取如表1所示。

图8 不同分量偏自相关函数图Fig.8 Partial autocorrelation function diagram of different components
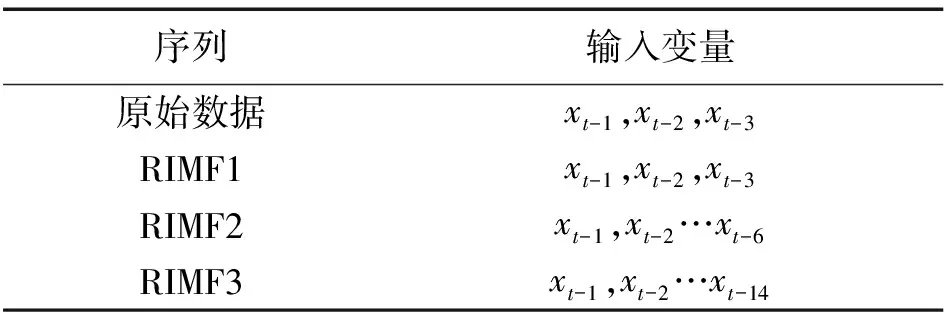
表1 各分量输入变量选择结果
在预测模型训练过程中,本文选用单步滚动预测的方法,即以确定的输入变量个数作为滑动窗口的长度,训练过程中将重构分量用滑动窗口切片后作为输入,输出得到下一时刻的功率预测值后,输入的滑动窗口继续向后滑动一步以得到再下一时刻的功率预测值,其中输出得到的功率预测值将作为下一时刻的输入窗口中最后一位输入变量,对应时刻的真实功率值将作为标签,以采用有监督的学习方式进行训练。
对原始功率数据集在经典时间序列预测模型LSTM上进行不同滑动窗口长度的对比实验,实验结果如表2所示,误差对比如图9所示。

表2 不同滑动窗口长度在LSTM中的实验结果Tab.2 Experimental results of different sliding window lengths in LSTM

图9 不同滑动窗口长度在LSTM中的误差对比Fig.9 Error contrast of different sliding window lengths in LSTM
由表2和图9可以看出,以偏自相关函数计算得到的滞后阶数确定的输入变量在预测模型中表现最佳,具有最低的预测误差,其评价指标VRMSE和VMAPE值分别为0.839 86和4.45%。证明了利用偏自相关函数确定预测模型输入变量能有效提高预测精度的结论。
2.3.3 预测结果及分析
为了验证所提预测方法的有效性及优越性,本文分别选取了支持向量回归(SVR)、长短期记忆网络(LSTM)、双向长短期记忆网络(BiLSTM)和3种单一预测模型以及EMD+BiLSTM和CEE-MDAN+LSTM这2种组合预测模型进行对比分析。各模型在测试集上的实验误差结果如表3所示。
从表3可以看出,相比于循环神经网络模型LSTM和BiLSTM,SVR模型的预测能力较差,其VRMSE和VMAPE值分别为1.442 13和20.55%,均高于其他模型。这是因为SVR模型对其参数的调整和核函数的选取较为敏感,并且大多适用于数据量较小的数据集,对于数据庞大且复杂的风电功率数据,则会表现出较差的拟合能力。BiLSTM在传统LSTM的结构基础上增加了一层反向LSTM层,使其能同时处理来自下一时刻的信息,因此,在短期风电功率预测中,BiLSTM模型性能相较于LSTM有较小的提升。同时,由CEEMDAN+LSTM组合模型的预测结果可以看出,利用CEEMDAN分解算法将原始数据序列处理后的VRMSE和VMAPE均小于单一LSTM模型,证明了CEEMDAN算法在风电功率预测中对预测模型具有优化效果。

表3 实验结果误差对比Tab.3 Error comparison of experimental results
此外,为了更具体形象地展示和分析模型的预测能力,本文绘制了风电功率真实值与各预测模型得到预测值的对比曲线,其结果如图10所示。图10中,红色曲线表示真实功率数据,黑色曲线表示本文方法预测得到的功率值。从图10可以看出,在功率发生升降变化的时候,本文方法能准确预测出其变化趋势,能确定功率变化的拐点,在功率稳定时段能保持稳定且保持与真实值较为贴合的状态。相比于其他预测模型的拟合曲线,本文方法的预测结果更为准确,整体误差更小,与真实值曲线更为贴合,具有更强的功率时序信息拟合能力。

图10 各模型预测结果对比图Fig.10 Comparison of prediction results of each model
2.4 案例2
2.4.1 实验过程
采取与案例1相同的实验流程,具体步骤如下。
1)对案例2数据集进行数据清洗处理后,利用-CEEMDAN进行分解,得到各模态分量。
2)对各分量进行复杂度分析,同时考虑各分量的频率以及样本熵值的大小,对各分量进行合并重构,得到合并结果如表4所示。

表4 重构分量结果Tab.4 Reconstructed component results
3)分别计算原始数据序列和各重构分量序列的偏自相关函数,并根据偏自相关函数确定的滞后阶数,选取各序列在预测模型中的输入变量序列位置,选取结果如表5所示。

表5 各分量输入变量选取结果Tab.5 Selection results of input variables for each component
4)以确定的输入变量长度作为预测模型训练预测过程中的滑动窗口长度,对各分量序列进行单步滚动预测,并对各分量预测结果进行求和,得到最终预测结果。
2.4.2 实验结果及分析
在以SVR、LSTM、BiLSTM这3种单一预测模型以及EMD+BiLSTM、CEEMDAN+LSTM这2种组合模型作为对比实验的基础上,增加Transformer网络[25]和VMD+BiLSTM组合模型进行对比分析,得到各预测模型的实验误差结果,如表6所示。
根据表6可知,相比于所选取的其他7种预测模型,本文所提出的方法具有最低的预测误差,其VRMSE和VMAPE分别为236.627 9和5.08%。同时,上述几种对比实验的预测结果也证实了案例1中实验结论的真实性,即在风电功率预测研究中,BiLSTM的预测效果优于LSTM;尽管Transformer的预测精度优于传统LSTM,但其表现仍稍逊于BiLSTM和其他组合模型;相比于直接进行预测的单一预测模型,对原始功率数据序列进行分解和平稳化处理后,再进行预测能够有效提高预测精度;相比于BiLSTM,EMD+BiLSTM和VMD+BiLSTM模型,本文所提出CEEMDAN+Bi-LSTM模型得到最优预测结果,证明了CEEMDAN算法能够有效改善BiLSTM模型的预测效果。

表6 实验结果误差对比Tab.6 Error comparison of experimental results
选取并绘制测试集中某日24 h功率真实值与各模型预测得到预测值的对比曲线,如图11所示。图11中,红色曲线表示真实功率数据,黑色曲线为本文方法得到的预测数据曲线。

图11 各模型预测结果对比Fig.11 Comparison of prediction results of each model
从图11可以看出,本文所提方法相比其他模型具有更高的拟合程度,并且在拐点处与真实值曲线更为贴合,如15时至20时区间中黑色曲线与红色曲线最为贴合,说明了本文所提方法能够准确预测出功率曲线的升降变化趋势,证明了该方法在预测波动性强的风电功率数据中的优越性。
3 结束语
针对风电功率数据序列非平稳性和非线性的特点以及输入变量选取的不确定性,本文提出了一种结合CEEMDAN和PACF-BiLSTM的组合预测方法,并根据风电场实际的历史功率数据集,完成了对未来24 h的每小时峰值的短期风电功率预测。经过以上实验分析,可得出以下结论。
1)利用CEEMDAN对风电功率数据序列进行分解能够有效改善原始序列的非平稳性和非线性,以分解得到的模态分量作为数据集进行预测能够有效提高预测精度。
2)对于相同的网络模型,不同的输入变量可能导致不同的预测结果和预测精度。依据偏自相关函数计算得到的滞后阶数能够为风电功率预测中输入变量的选择提供依据,减少人为判断的主观性。不同输入变量在经典预测模型LSTM中的对比预测实验结果表明,偏自相关函数实验选取的输入变量表现最佳,具有最低的预测误差。预测模型对比实验结果表明,加入偏自相关函数实验能有效提高预测精度。
3)BiLSTM具有2层反向的LSTM层,使其能够兼顾历史信息和未来信息。根据BiLSTM预测模型和传统LSTM模型实验结果对比表明,BiLSTM在风电功率预测研究中更具优越性。
4)CEEMDAN、PACF和BiLSTM均在风电功率预测研究中表现出其适用性和优越性,本文通过结合三者形成一种新的风电功率组合预测模型,分别从数据预处理、预测模型参数调整以及预测模型入手,优化了短期风电功率预测模型,提高了预测精度。与4种单一预测模型SVR、LSTM、BiLSTM、Transformer和3种组合预测模型VMD+BiLSTM、EMD+BiLSTM、CEEMDAN+LSTM进行实验结果对比表明,本文所提方法在2个数据集案例中均有最低的误差结果和最优的预测表现,表明了该方法在短期风电功率预测中的有效性和优越性。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
基层中医药(2021年12期)2021-06-05
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2018年12期)2019-01-31
英美文学研究论丛(2018年1期)2018-08-16
纺织科学研究(2017年6期)2017-07-03
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
电测与仪表(2014年23期)2014-04-04
