
基于CNN-ADABOOST的车载设备故障诊断
2023-12-29 12:23宋鹏飞陈永刚王海涌
重庆邮电大学学报(自然科学版) 2023年6期
宋鹏飞,陈永刚,王海涌
(1.兰州交通大学 自动化与电气工程学院,兰州 730070;2.兰州交通大学 电子与信息工程学院,兰州 730070)
0 引 言
列车运行控制系统(简称列控系统)是保证列车安全运行的重要设备,而车载设备更是列控系统的核心。车载设备的日志数据记录了车载设备各个模块的工作状况,技术人员可以通过日志来对车载设备进行故障诊断,但由于不同厂家对车载设备的运行记录不完全相同,且发生故障的原因是多方面的,所以这种严重依赖经验知识的故障诊断方法难度大、处理效率低。因此,进一步研究车载设备的诊断算法,实现车载设备故障的智能诊断,对保证列控系统可靠工作、列车安全运行具有重大意义。
文献[1]建立故障特征词库,采用改进的潜在狄利克雷发布模型(latent Dirichlet allocation,LDA)主题模型提取车载数据特征,通过粒子群优化算法优化的支持向量机方法实现故障信息的分类;文献[2]通过空间向量模型(vector space model,VSM)将车载日志数据转化为向量空间中的向量,利用主分量启发式算法进行特征选择,通过遗传算法优化的反馈传播(back propagation,BP)神经网络实现故障诊断;文献[3]首先利用粗糙集理论对应答器信息接收单元(balise transmission module,BTM)故障数据进行处理,实现故障的特征提取,再通过改进的布谷鸟算法优化BP神经网络的,最后利用优化后的BP神经网络实现故障诊断分类;文献[4]首先利用词向量模型(word to vecor, word2vec)对故障文本进行词向量转化,再通过卷积神经网络(convolutional neural networks,CNN)实现车载日志特征提取,采用结合代价敏感学习的随机森林算法对故障进行分类;文献[5]采用贝叶斯正则化算法优化BP神经网络,利用长短时记忆网络学习故障特征信息,建立长短时记忆网络(long short-team memory,LSTM)和优化BP神经网络的级联模型,实现车载设备的故障诊断。
自适应增强算法(adaptive boosting,Adaboost)作为一种自适应迭代算法,在机器学习上有广泛的应用。通过与神经网络相结合,常用于处理分类任务,其本质为将所有基分类器按照设定的方法组合成为强分类器,能显著改善弱分类器的分类性能。文献[6-7]将Adaboost算法与卷积神经网络结合,用于图像识别领域;文献[8]利用Adaboost改进CNN实现金属电镀领域的故障诊断;文献[9]将代价敏感算法与卷积神经网络结合形成代价敏感卷积神经网络(cost sentsitive convolutional neural networks,CSCNN),再将CSCNN与集成学习结合,提出了一种基于Adaboost-CSCNN的分类算法;文献[10]将CNN的特征提取能力与Adaboost的集成学习能力结合起来,提出了Adaboost-CNN模型,克服了训练CNN需要大量样本来调整参数的问题;文献[11]采用AlexNet模型作为基分类器,通过Adaboost算法更新迭代样本数据以及卷积神经网络的权重,形成AlexNet-Adaboost强分类器用作轴承故障诊断。
本文采用word2vec将车载设备运行日志转化为对应的词向量,用CNN卷积神经网络实现对故障文本数据的特征提取,将CNN作为基分类器,通过Adaboost算法迭代更新样本及CNN的权重生成强分类器,利用强分类器实现故障信息的分类。
1 列控车载设备及故障
CTCS-3级列控车载设备采用分布式结构,包括应答器接收单元(balise transmission module,BTM)、列车接口单元(train interface unit,TIU)[12]等,其总体结构图如图1所示。
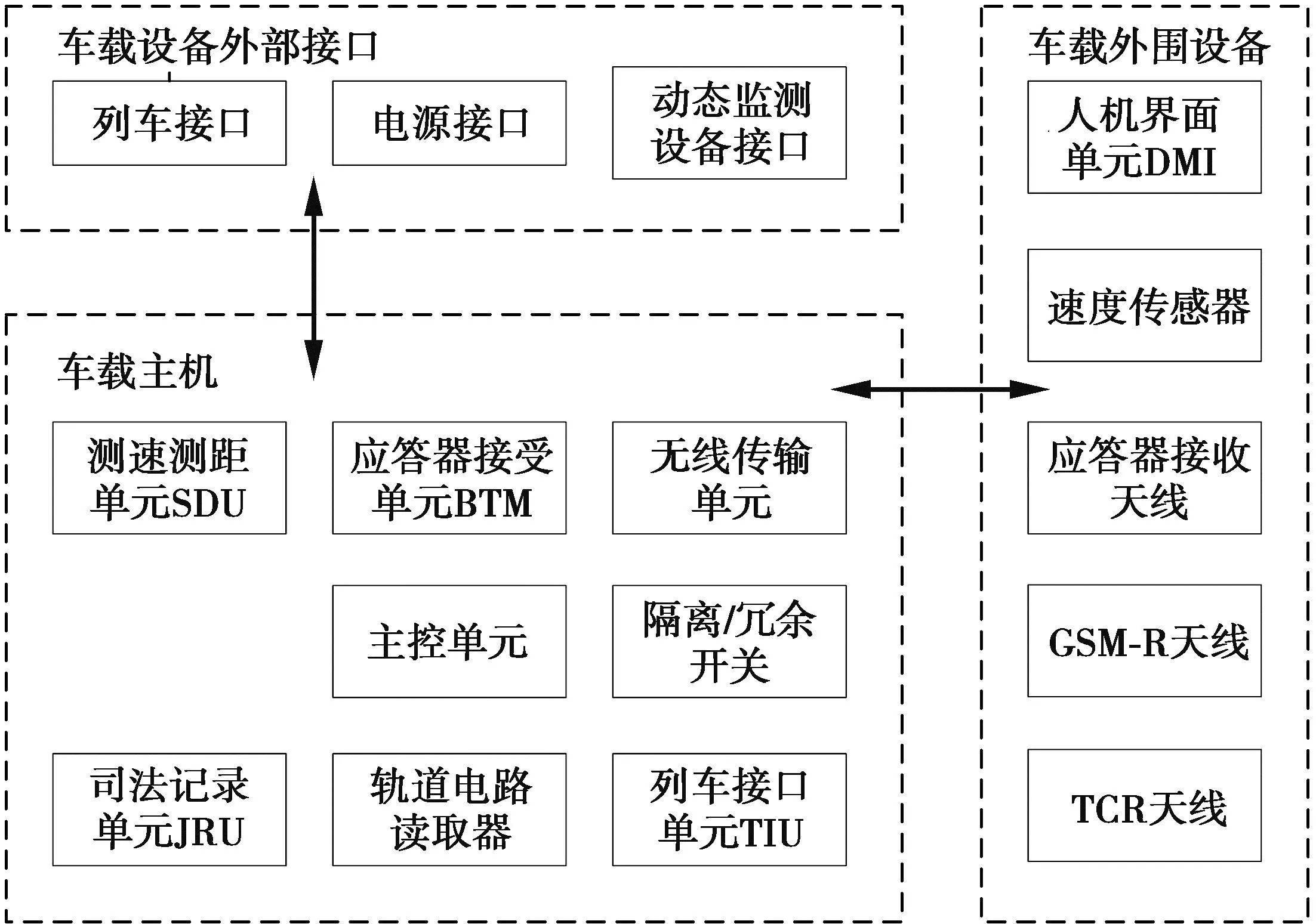
图1 CTCS-300T型列控车载设备组成Fig.1 Composition of CTCS-300T train control vehicle equipment
对300T型列控车载设备进行故障诊断的数据来源为应用事件日志(application event log, AElog),是一种半结构化文本,记录了车载设备某一时刻的运行信息,每个模块正常或故障的状态语句包含在内,由包含时间信息的英文短句来进行描述。共有4个模块保存车载日志,分别为ATPCU、C2CU、SDP和TSG4。本文的研究数据来源于ATPCU模块,根据故障案例库以及现场经验知识[13],对每种出现的故障语句进行分类,可将车载设备故障数据分为20类,如表1所示。

表11 车载设备故障类型及运行状态语句Tab.1 On-board equipment failure types and operating status statements
2 基于CNN-ADABOOST的列控车载设备故障诊断
2.1 模型整体流程
模型处理流程如图2所示,车载日志AElog文件经过数据处理转换为计算机可以识别的向量形式,再利用CNN对特征向量进行提取,通过Adaboost算法对样本及CNN迭代更新权重生成强分类器,最后利用强分类器在相应的数据集上实现故障诊断。
2.2 数据处理
原始车载设备应用事件日志是一种半结构化英文文本,需要将其转化为向量形式,神经网络才能对其进行特征提取。Word2vec是Mikolov等[14]提出的自然语言模型,其特点是能将文本快速转化为词向量,其维度与独热编码(one-hot)相比明显降低,且计算复杂度明显减少。本文采用word2vec中的跳跃文法(skip-gram)模型。
数据处理具体步骤如下。
1)文本预处理。以某局某段的车载日志为原始数据,提取运行状态等关键信息,去掉停用词和符号,建立故障信息语料库。去掉停用词和符号一方面可以提升分类器的分类能力,另一方面可以过滤掉无关的特征词,使结果更加精准。

图2 模型处理流程Fig.2 Model processing flow
2)词向量获得。该过程为用自然语言模型训练生成计算机可以识别的词向量形式。主要训练过程:模型扫描语料库,统计每个词出现的次数,根据每个词出现的次数建立哈夫曼树,模型依次读取每条语句中的词,利用梯度下降法算出梯度,更新词向量和非叶子节点处向量的词,当遍历完整个语料库时,训练终止,得到词向量结果。
简化目标函数为
(1)
(1)式中:C表示语料库;p为概率函数;Context(ω)表示上下文的集合。
2.3 CNN
CNN基本结构为输入层、卷积层、池化层、全连接层和输出层,作为整个神经网络的核心结构,卷积层和池化层可以交替多次使用[15]。本文所用卷积神经网络结构如图3所示。

图3 卷积神经网络结构Fig.3 Convolutional neural network architecture
输入层是一个向量矩阵,由词向量模型生成。为使向量长度一致,对原运行状态语句转化为向量时进行补零操作,即长度不足的用0补齐。
卷积层对输入层的词向量矩阵进行卷积操作,每进行一次卷积操作相当于提取一次相应的特征向量。卷积操作过程为
(2)
池化层作用为降低特征数量,缩减模型大小[16]。其数学模型为
(3)

一个CNN可以有多层全连接层,将特征向量作为全连接层的输入,连接所有的特征后输出给softmax函数,函数softmax将网络的输出转化为输出类别的概率,表示为
(4)
(4)式中:z是输出向量;α0是最后一个全连接层的权重系数;b0为输出层的偏差值。
CNN本身作为特征提取器,可以将word2vec生成的词向量矩阵进行特征提取,然后通过激活函数输出结果。具体流程为将由故障状态语句转化而来的词向量矩阵作为CNN的输入,通过定义卷积核大小及数量进行卷积与池化操作来提取特征向量,经过全连接层连接全部的特征后,通过softmax函数输出每一类故障的诊断结果。与常见的图像处理的区别在于,在处理图片时,卷积核依次提取图片的每一个像素点的特征,而在处理车载设备故障语句时,卷积核依次提取词向量矩阵的每一个元素的特征向量。
2.4 Adaboost算法生成强分类器
Adaboost是一种迭代算法,本质是通过迭代更新权重将一定数量的弱分类器集合形成强分类器,通过深挖弱分类器的性能从而减少误差率[17]。虽然CNN可做到分类效果,但由于车载设备故障数据存在不平衡性,即正常数据在全部数据中占据大多数,故障数据只占据少数,且不同故障数据类型包含的样本数目也存在不均衡,因此,只依靠CNN进行分类会造成对出现次数较少的故障类型及数据识别率低的问题。Adaboost算法的主要思想是更新训练样本权重和基分类器权重,更新样本权重会使模型的下一次训练集中在分类错误的样本上。基分类器权重的更新依赖于分类器在数据上的分类误差率,使分类性能较差的分类器所占权重较小,对最终分类结果的影响较小。通过对样本及基分类器权重的更新,能在很大程度上解决由于数据不平衡造成的漏分与错分问题。
将CNN作为基分类器,Adaboost训练基分类器具体步骤如下。
步骤1权重初始化,对每一个样本赋予相同的权重,表示为
(5)
步骤2计算分类误差率
(6)
(6)式中:em为分类误差率;ci为第i个样本的类别;Tm(xi)为训练i次的神经网络模型。
步骤3计算权重系数
(7)
步骤4更新权重
wm+1,i=wm,i·exp(αmciTm(xi))
(8)
步骤5构建强分类器。各弱分类器迭代训练好后组合为强分类器,表示为
(9)
(9)式中:M为训练的卷积神经网络的数量。
Adaboost对由车载设备故障状态语句转化生成的词向量矩阵中的每一行元素赋予相同的权重,将带有权重的向量矩阵作为CNN的输入,通过计算每一个CNN的分类误差率及权重系数来更新词向量矩阵的权重,在保留前一个CNN权重的前提下用更新权重后的词向量矩阵作为下一个CNN的输入,以此类推,依次更新不同CNN的权重,将各CNN作为基分类器按设定方式组合为强分类器,将词向量矩阵作为强分类器的输入来进行车载设备的故障诊断。
本研究的具体步骤如下。
步骤1获取大量的车载故障数据,对其进行数据清洗及分类,按20种故障类型和正常类型处理构建故障语料库;
步骤2将故障语料库中的数据样本按故障类别比例分为训练集、验证集和测试集;
步骤3通过skip-gram模型将样本转化为向量;
步骤4将产生的向量矩阵作为CNN的输入;
步骤6采用初始化的向量矩阵来训练第1个CNN;
步骤7计算基分类器在向量矩阵上的em和αm;
步骤8更新当前基分类器的权重与向量矩阵的权重;
步骤9保存当前基分类器,使用更新权重后的向量矩阵训练下一个基分类器,对于后续的基分类器,均采用之前迭代训练中CNN的学习参数;
步骤10对新的基分类器重复步骤7—9,直至达到目标要求;
步骤11将训练完成的基分类器按设定组合为新的强分类器;
步骤12采用强分类器对故障进行分类。
3 实验与分析
3.1 实验环境及数据
实验采用python3.6解释器,通过使用TensorFlow框架,gensim、Keras等库实现 word2vec、CNN以及Adaboost,硬件配置为i5 11400H、RTX3050。
本实验数据集采用某铁路局电务段的车载设备故障数据,通过数据预处理,产生6 180个数据样本,其中,5 275组正常样本和905组故障样本,故障样本分为F1—F20,其分布如图4所示。
905组故障样本按故障类别比例分为60%的训练集、20%的验证集和20%的测试集。
3.2 实验参数
本文模型的参数设置情况如表2和表3所示。

表2 word2vec模型参数设置Tab.2 Parameter settings of word2vec model

表3 CNN-Adaboost模型参数设置Tab.3 Parameter settings of CNN-Adaboost model
3.3 评价指标
车载设备故障诊断本质上是一个多分类问题,而且原始数据存在不平衡性,所以二分类指标,例如准确率等,要么无法正确地评价模型的性能,要么计算较为复杂。本文选择kappa系数作为模型性能的评价指标,kappa系数多用于多分类问题,其计算基于混淆矩阵[18],取值为[-1,1],通常为[0,1]。kappa的计算式为
(10)
(10)式中:p0为每一类正确分类的样本数量占总样本数的比例,即总体分类精度;pe表示为
(11)
可将kappa系数取值分为5组来表示不同级别的一致性,如表4所示。
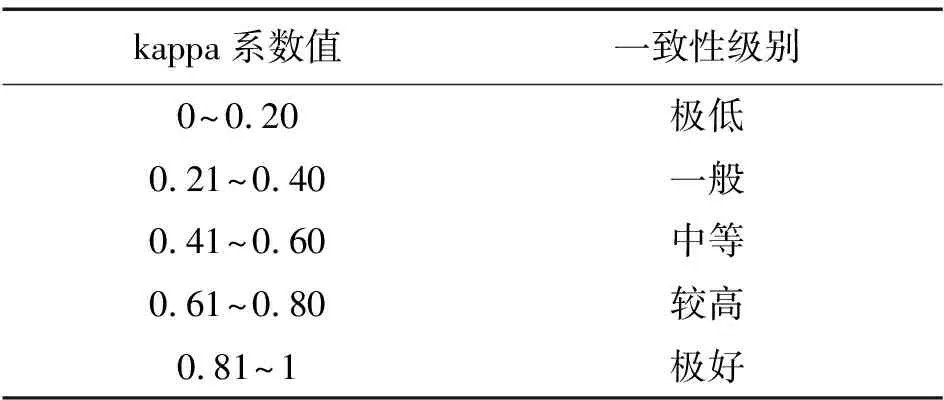
表4 kappa系数对应的一致性级别Tab.4 Coefficient of kappa corresponds to the consistency level
3.4 模型训练
实验采用第2节中的CNN模型作为基分类器,通过adaboost算法对训练数据及基分类器做迭代训并保存相应的基分类器,当达到满足要求的基分类器数目时训练终止,然后将保存的各分类器按(8)式结合成强分类器。
模型训练分为2部分:①第一部分目的是确定单个基分类器在何时拥有最优的性能。CNN迭代次数如图5所示,由图5可以看出,当训练到120步后模型性能趋于稳定,对训练集和测试集都有良好的分类能力,所以设定每个CNN迭代120次完成训练;②第二部分目的是确定最优基分类器数目。基分类器数目如图6所示,由图6可以看出,当基分类器数目为1时,kappa系数最低,即分类性能最低。随着迭代次数及基分类器的增加,模型的kappa系数也随之上升。当迭代次数为4次时,模型已经具有较好的诊断性能,且后续的kappa值曲线趋于平稳。当基分类器个数为7时,模型具有最好的性能,因为基分类器在数据上产生过拟合,所以当基分类器数目大于7时,模型的分类能力有一定下降。因此,采用7个基分类器,即迭代训练的CNN模型数量为7。
3.5 故障诊断结果及分析
为了证明本文提出的模型对车载设备故障诊断的有效性,分别用CNN、BP神经网络、SVM和本文提出的CNN-Adaboost模型在相同的训练集和测试集上实验分析,其收敛步数及时间如表5所示,CNN完成实验所需的收敛步数和时间是最低的。而CNN-Adaboost采用了7个CNN作为基分类器,所以其收敛步数为单个CNN的7倍,但由于后续的基分类器均采用前一个基分类器的参数,并且分类错误的数据的权重越来越高,因此,CNN-Adaboost能够快速收敛,完成整个实验所用时间较少。

图5 CNN迭代次数Fig.5 Nnumber of CNN iterations
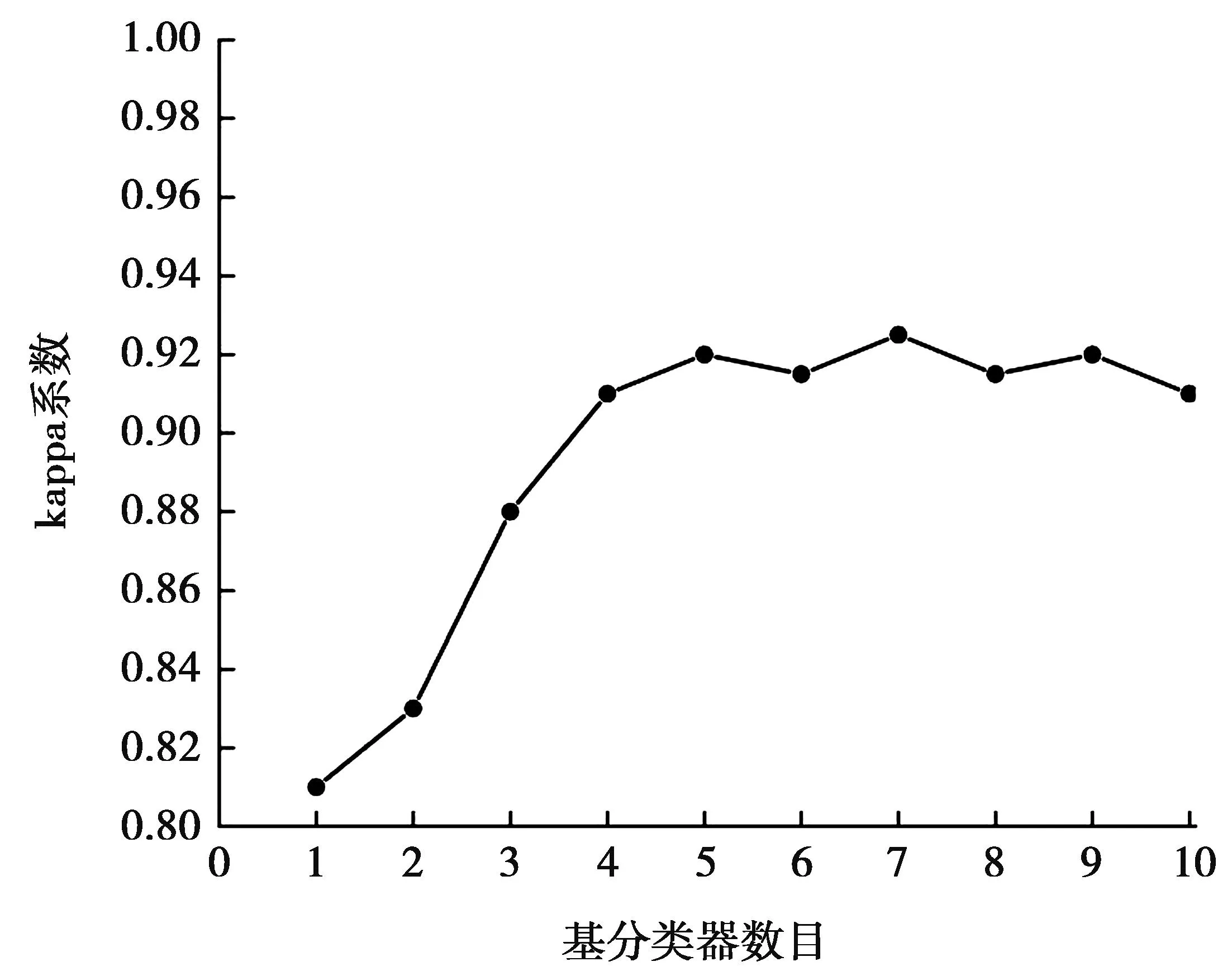
图6 基分类器数目Fig.6 Number of base classifiers

表5 不同模型收敛步数及时间比较
各模型实验得到的混淆矩阵如图7—图10所示,可以看出,由于Adaboost算法深挖分类器性能的能力,CNN-Adaboost模型的性能是最好的,对出现次数较少的类别也具有良好的分类能力。CNN、SVM、BP神经网络对不平衡数据较敏感,对一些样本数较少的故障类别识别能力欠佳,相较于本文设计的CNN模型,CNN-Adaboost模型的kappa系数提升了0.084,对不平衡数据的分类效果有一定的提升。不同模型的诊断性能如表6所示,本文提出的CNN-Adaboost模型的kappa系数高于其他模型,证明该研究的有效。

图7 卷积神经网络混淆矩阵Fig.7 Convolutional neural network confusion matrix

图8 BP神经网络混淆矩阵Fig.8 BP neural network confusion matrix

图9 SVM混淆矩阵Fig.9 SVM confusion matrix

图10 CNN-Adaboost模型混淆矩阵Fig.10 CNN-Adaboost model confusion matrix

表6 不同模型诊断性能比较
4 结束语
针对列控系统车载设备故障诊断依赖人工经验的问题,本文提出了一种卷积神经网络与Adaboost算法相结合的故障诊断模型。通过skip-gram模型对原始车载日志处理形成词向量,利用CNN卷积神经网络实现特征向量提取,采用Adaboost算法迭代训练生成的CNN-Adaboost模型对提取的特征向量进行分类输出,达到故障诊断的目的。
本文采用某铁路局车载日志作为原始数据进行实验,采用kappa系数作为模型性能的评价指标。实验结果表明,采用Adaboost算法训练的集成模型对训练分类错误的样本有较好的表现,能够降低分类性能不佳的弱分类器对最终诊断结果的影响,提升了模型的故障诊断能力。
CTCS-300T的车载日志记录在ATPCU、C2CU、SDP和TSG4个模块中,同一个故障类别可能由不同的模块或多个模块引起,本文只分析实验了ATPCU模块的故障信息,后续可以研究多模块数据混合的车载设备故障诊断。
猜你喜欢
铁道通信信号(2020年8期)2020-02-06
电子测试(2018年1期)2018-04-18
中国公共安全(2017年11期)2017-02-06
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
电源技术(2015年2期)2015-08-22
电测与仪表(2014年15期)2014-04-04
振动、测试与诊断(2014年5期)2014-03-01
机械与电子(2014年1期)2014-02-28
