
基于BIGRU的轨迹数据发布隐私保护方案
2023-12-29 12:35申艳梅张玉阳申自浩刘沛骞
重庆邮电大学学报(自然科学版) 2023年6期
申艳梅,张玉阳,申自浩,王 辉,刘沛骞
(1.河南理工大学 软件学院, 河南 焦作 454000;2.河南理工大学 计算机科学与技术学院, 河南 焦作 454000)
0 引 言
近年来,随着通信技术和定位技术的发展,越来越多的设备具有位置数据搜集的能力。基于位置服务(location-based services, LBS)[1]已经广泛应用于各个领域,服务人民的生活。LBS技术可以分为两类:单点LBS与连续LBS。其中,单点LBS是指用户可以间断地获取位置信息,而连续LBS则需要用户周期地获取位置信息。尽管人们从LBS中获益良多,但使用LBS时被搜集的数据可能包含个人隐私,若不经处理直接进行发布,很可能引起隐私的泄露[2]。
目前位置隐私保护技术中,K-匿名是常用的方法之一。基于K-匿名及其延伸技术实现了对数据的泛化处理,使得每个用户的记录与多条错误信息相匹配,攻击者很难分辨出真正的用户,从而保证个人的隐私。Gupta等[3]在考虑最小等待时间的情况下,将用户的信息进行保护,提出了最佳移动感知缓存数据预取和替换策略,引入匿名器,通过使用K-匿名预取设施,使得移动用户输入形成一个掩蔽区域,提高了隐私保护程度。朱素霞等[4]认为位置会影响隐私预算与轨迹形状,进而影响数据的可用性,因此,利用相关熵和K-means技术,既保证了轨迹数据的隐私性,又增强了轨迹数据可用性。
差分隐私技术[5]因其具有精确的数学表达方式和个性化的隐私保护而备受关注。Guo等[6]为解决LBS中位置隐私的暴露问题,设计了一种构造匿名集的最佳辅助用户选择,并将差分隐私应用于匿名集的构建过程,添加自适应拉普拉斯噪声以满足用户的隐私要求,从而有效地保护了用户的隐私。田丰等[7]为满足不同用户的隐私保护需求,给出了一种基于个性化差分隐私的轨迹发布机制,提高数据可用性,更好地兼顾隐私和数据的可用性。
随着机器学习相关技术的发展,现如今越来越多的学者尝试将深度学习技术与差分隐私结合。晏燕等[8]提出基于深度学习的位置大数据划分结构预测方法和差分隐私发布方法。该方法构建基于时空序列的深度学习预测模型,通过提取历史位置大数据统计划分结构矩阵的时间和空间相关特性,实现对划分结构矩阵的有效预测,从而解决传统位置大数据统计划分发布结构不合理、划分发布方法效率低下的问题。Chen等[9]提出新的轨迹发布算法RNN-DP,将循环神经网络与差分隐私技术相结合应用于轨迹发布,提高了数据可用性。
针对循环神经网络(recurrent neural network,RNN)无法处理长距离数据以及大多数隐私保护方案无法抵御背景知识攻击的问题,本文利用差分隐私(differential privacy,DP)与循环神经网络技术,提出一种面向轨迹数据发布的双向门控循环神经网络差分隐私(bidirectional gated recurrent unit-differential privacy,BIGRU-DP)保护方案,以达到在抵御背景知识攻击的同时提高数据的可用性的目的。该方案能够更好地对长距离轨迹数据进行处理,降低梯度爆炸与梯度消失造成的影响,更好地适应不同类型的轨迹数据。
1 相关定义
定义1ε-DP[10]。给定随机算法M:D→Rn以及任意相邻数据集D和D′,其输入为一个数据集,输出为n维实数向量。若随机算法M对D和D′进行操作,得到的任意输出均使得结果S⊆Range(M),且满足
Pr[M(D)∈S]≤eε×Pr[M(D′)∈S]
(1)
则称算法M满足ε-DP。其中,ε为隐私预算,ε越接近于0,则算法M作用于D和D′输出的概率分布越相似,隐私保护效果越好。
定义2全局敏感度。设有查询函数f:D→R,以及任意的邻近数据集D和D′,函数f的敏感度定义为
Δf=maxD,D′‖f(D)-f(D′)‖1
(2)
差分隐私通过对数据加上噪声的方式来保证对数据隐私的保护。其中,全局敏感度Δf是一个十分重要的参数。通过控制全局敏感度,从而控制添加噪声的大小,实现满足差分隐私的隐私保护。
定义3轨迹数据集。轨迹是若干位置点依据其时间戳组成的位置序列。其中,位置Pi=(xi,yi,ti)为地图上离散点,xi和yi分别为位置点Pi的经度和维度,ti为记录该位置点的时间戳。轨迹可以表示为T=P1→P2→P3→…→Pn,其中,n为该轨迹的长度。由若干的轨迹组成的集合,称为轨迹数据集,表示为D=(T1,T2,T3,…,Tq),q为该轨迹数据集中轨迹数量。
定义4Laplace机制[11]。给定数据集D和隐私预算ε,查询函数q的全局敏感度为Δf,当查询函数q的输出满足
M(O)=q(O)+Lap(Δf/ε)
(3)
则称算法M满足ε-DP,且服从尺度参数为Δf/ε的Laplace分布。
拉普拉斯机制通过向查询函数加入符合拉普拉斯分布的噪声,使加噪后满足差分隐私,从而保护用户隐私。记位置参数μ为0,尺度参数为b。则所添加噪声的概率密度函数为
(4)
定义5指数机制。给定输入为数据集D以及输出为实体对象r∈Range,有可用性函数u:(D,r)→R,若算法M满足
(5)
则算法M满足ε-DP。其中,Δu为效用函数u:(D,r)全局敏感度,可通过(6)式计算得到。效用函数值越高,r被选择输出的概率越大。
Δu=maxr∈,D~D′|u(D,r)-u(D′,r)|
(6)
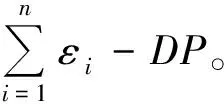
性质2并行组合原理。设有算法F1,F2,…,Fn,Fi(1<=i<=n)均满足εi-DP,那么对于不相交的输入数据集D1,D2,…,Dn,由这些算法构成的组合算法F(F1(D1),F2(D2),…,Fn(Dn))满足max(εi)-DP。
2 BIGRU-DP方案
2.1 系统架构
BIGRU-DP方案系统架构如图1所示,包含轨迹预测,轨迹泛化,轨迹合并,轨迹发布4个部分。
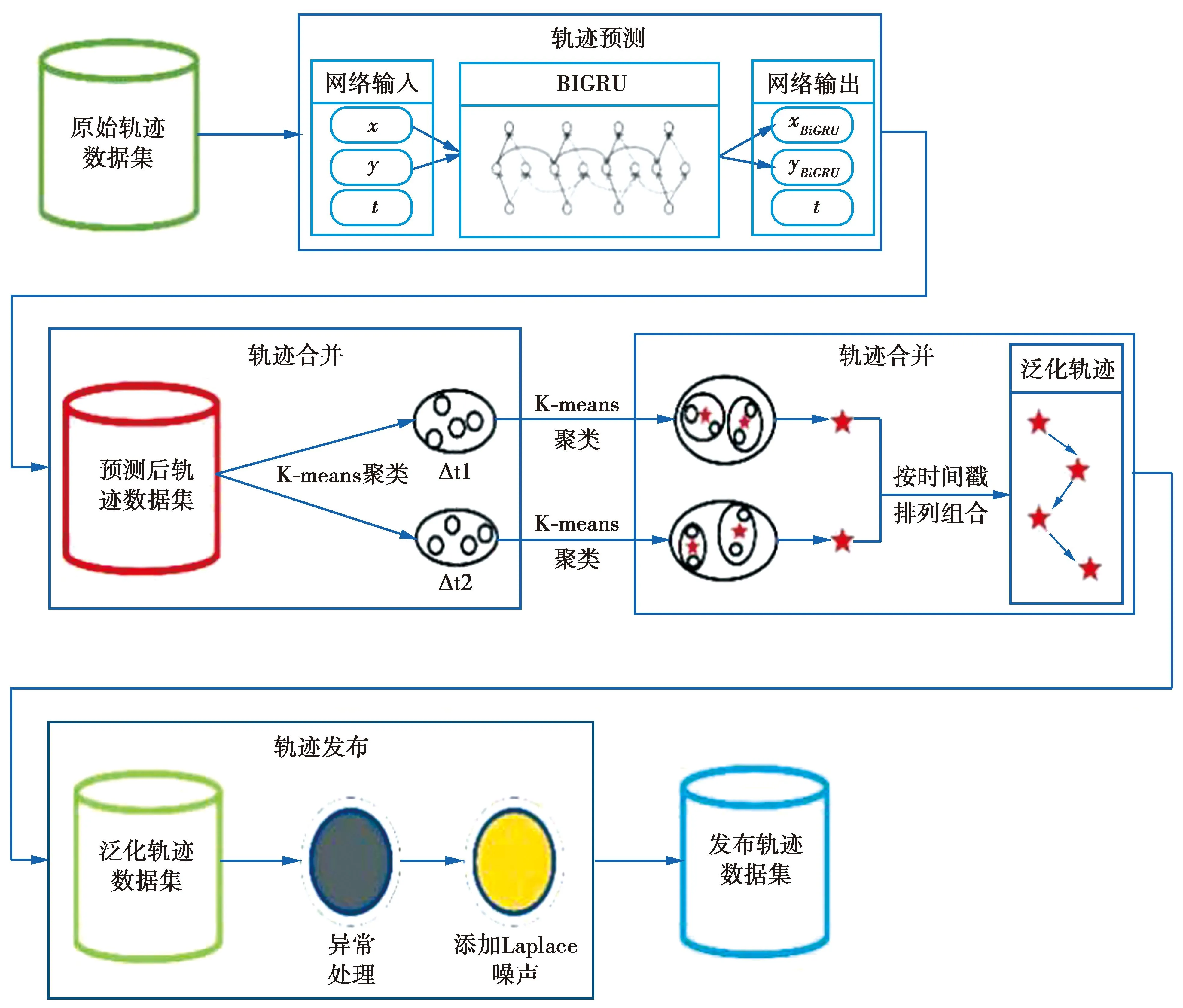
图1 系统架构Fig.1 System architecture
该方案实现隐私保护进行轨迹数据发布步骤如下。
步骤1轨迹预测模块应用BIGRU对轨迹进行预测。与一般的神经网络不同,BIGRU不仅适用于处理时序数据,相对于单向循环网络能够达到更精确的预测结果。
步骤2轨迹泛化模块使用K-means对时间属性进行泛化处理,降低时空相关性对于数据泄露的影响。
步骤3轨迹合并模块使用聚类技术与指数机制生成抽象轨迹数据集,并与原始轨迹进行比较合并。
步骤4轨迹发布模块采用异常处理机制删除异常轨迹,并对需要发布的轨迹数据集进行加噪处理,抵御背景知识攻击。
2.2 轨迹预测
鉴于RNN的梯度爆炸和梯度消失的缺陷,循环神经网络的发展催生出了门控循环网络(gated recurrent unit,GRU),它能有效地处理上述问题,并能捕获长距离依赖。BIGRU改进了GRU,其结构包含正反2个GRU层。时间步t处的输入提供正反双向隐藏状态信息来进行参考。在训练模型的过程中提供正向逆向2个隐藏信息,其中,参数根据公式(7)—(9)进行更新。
H′t=f(W1xt+W3H′t+b′t)
(7)
Ht=f(W2xt+W4Ht-1+bt)
(8)
Ht=H′t⊕Ht
(9)
使用BIGRU来进行轨迹的预测,生成新的轨迹,从而达到隐藏原始轨迹的效果。在模型训练的过程中,BIGRU同时参考预测点两侧的数据,因此,能够获得更加准确的轨迹数据。算法1给出了轨迹预测生成的过程。
算法1BIGRU-DP_prediction
输入:原始轨迹数据集D;
输出:预测后的轨迹数据集DBIGRU。
1.forTinD;
2.for eachPinT;
3.xBIGRU=BIGRU(D,x);
4.yBIGRU=BIGRU(D,y);
5.end for;
6.end for;
7.TBIGRU=(XBIGRU_1,YBIGRU_1,t1)→(XBIGRU_2,YBIGRU_2,t2)→…→(XBIGRU_n,YBIGRU_n,tn);
8.DBIGRU=(TBIGRU_1,TBIGRU_2,TBIGRU_3,…,TBIGRU_n);
9.returnDBIGRU。
2.3 轨迹泛化
在得到DBIGRU轨迹数据集后,对其时间属性进行泛化处理,避免因轨迹的时空相关性带来的隐私泄露。使用K-means聚类方法来实现所需的时间泛化。算法2描述了具体的泛化过程。
算法2BIGRU-DP_Generalization
输入:预测后的轨迹数据集DBIGRU,位置点集X={X1,X2,X3,…,Xm};
输出:泛化后的分区集Pset=(P1,P2,…,Pn)。
1.ifDBIGRU=∅ ;
2.return null;
3.end if;
4.初始化k个簇心μ1,…,μk;
5.repeat;
6.forjfrom 1 tom;
7.计算各位置点Xj与各聚类中心μi的距离;
8.将该位置点Xj划进与其最近的样本中心μi所在的簇中;
9.end for;
10.forifrom 1 tok;
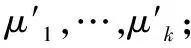
12.end for;
13.until所有的聚类中心不再变化;
14.记录泛化后的分区集Pset=(P1,P2,…,Pn);
15.returnPset。
轨迹泛化如图2所示。
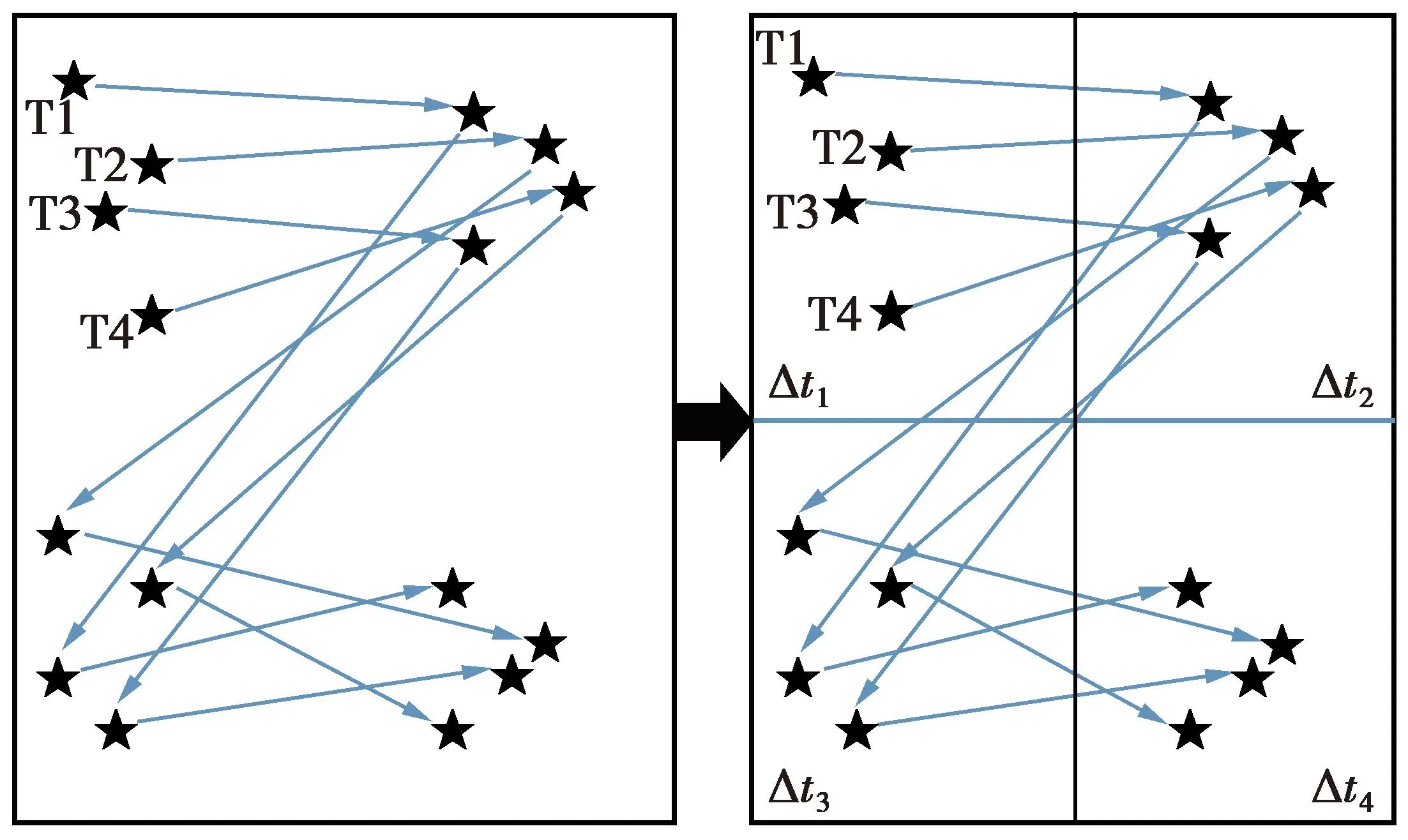
图2 轨迹泛化Fig.2 Trajectory generalization
2.4 轨迹合并
考虑到轨迹数据存在维数高,位置范围较大的问题,本方案通过对每个时间戳内的位置进行空间划分来解决。即通过使用K-means聚类将同一个时间戳内的位置划分为k组,k值越大,则每个位置将与其他轨迹上的较少位置进行合并,从而轨迹精度损失越小。划分后如图3所示。
通过合并每个时间戳的位置点,轨迹也会被合并,因此轨迹的计数就会增加。通过这种方式,使得即使添加小噪声也不会对数据可用性造成过大影响。
使用指数机制对在同一时间戳中的分区进行选择,并用候选分区的簇心代替该簇中的其他位置点。指数机制使用效用函数来对每一个候选分区进行打分赋值,分数较高的分区将会有更高的概率被输出。根据文献[14]中基于豪斯多夫距离设计的平均距离算法(mean distance,MeanDist),可以得到效用函数[13]为
(10)
(10)式中,
(11)
指数机制基于该效用函数,则每一个分区Pi的输出概率为
(12)
通过指数机制,能够建立一个划分区域内部位置点与簇心的映射关系,从而达到泛化的效果。
图3 空间划分Fig.3 Space division
2.5 轨迹发布
s个时间段与m个候选分区会有ms种划分策略。将所有的真实轨迹替换为泛化轨迹,从而保护用户的隐私。
然而,使用新生成的泛化轨迹代替原始轨迹的同时,会产生一些不存在的异常轨迹。针对这些异常轨迹,设计异常处理机制,将原始轨迹与泛化后的轨迹作对比并计数相对应的真实轨迹数(true count,TC),将tc=0的数据进行删除,不但减少了处理空轨迹的资源,同时增加了发布轨迹的有效性。
若直接将tc=1的轨迹进行发布,很容易遭到背景知识攻击。因此需要对其添加Laplace噪声。选择n条泛化轨迹,首先将具有原始轨迹的泛化轨迹纳入选择,将其数量记为n1,然后在剩余泛化轨迹中选择n-n1条轨迹。
然而,为了保证隐私性而添加噪声,将会导致牺牲部分的数据可用性。因此,根据文献[14]本文设计了一种后处理机制以保证数据的可用性。具体处理工作为将添加噪声前的轨迹集映射为图G,将泛化后的轨迹作为图G的边,其交叉点作为节点,这种映射更加符合现实的轨迹网络。为了降低添加噪声对数据可用性的影响,规定对于任意的两条边x,y,若x的轨迹比y更多,则其tc(x)>tc(y)。令Cmean[i,j]表示S的一条子轨迹Sij的平均数。
(13)
则经过约束性处理后的噪声Lm可以表示为
Lm=minj∈[m,n]maxi∈[1,j]Cmean[i,j]
(14)
排序处理后的序列S为
S=
(15)
经过处理后能提高数据的可用性。其处理过程如算法3所示。
算法3BIGRU-DP_release
输入:合并优化后的轨迹数据集Do,每条轨迹的真实计数{tc1,tc2,…,tcN};
输出:经过合并与异常机制处理后的轨迹数据集Dr。
1.ifDo=∅;
2.return null;
3.end if;
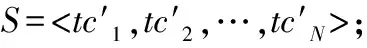
5.for allp,q∈[1,n1];
6.Δf=maxp,q{∣tcp-tcq∣};
7.μ=ComputeAverage(ε);
8.b=Δf/μ;
9.end for;
10.for alli∈[1,n1];
12.nci=tc′+noise(x);
13.end for;
14.NC={nc1,nc2,…,ncN};
16.S′=
17.forifrom 1 ton1;
19.end for;
21.returnDr。
3 隐私安全证明
结合差分隐私应用到方案的不同模块以满足隐私安全需求。在轨迹合并模块,首先在每个时间戳的位置区域上执行聚类,得到该时间戳的候选分区集,然后使用指数机制在候选分区集中选择一个区域。在轨迹发布模块中,为了提高隐私保护程度,对tc添加Laplace噪声。为了便于描述,分别将其称为轨迹合并(trajectory merging,TM)和轨迹发布(trajectory release,TR)。
定理1TM满足ε-DP。
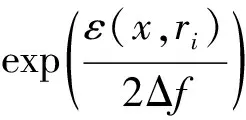
因此,只需将随机算法M的输出进行归一化处理,即可得到输出候选分区ri的概率密度。归一化处理为
(16)
根据差分隐私定义,在相邻数据集中通过随机化算法M得到相同的输出值ri的比值为
(17)
将(16)式代入(17)式,进行展开运算,则有
(18)
综上,TM满足ε-DP。
定理2TR满足ε-DP。
证明对tc的集合TC={tc1,tc2,…,tcN},Δf为敏感度。
M(D)=f(D)+Y
(19)
(19)式中:f为查询函数;Y为Laplace噪声;M(D)为加入噪声后的混淆返回结果。
px(z)和py(z)分别为ML(x,f,ε)与ML(y,f,ε)的概率密度函数。因此,对于某个输出z,有
(20)
对其进行运算推导可以得出
(21)
综上,TR满足ε-DP。
定理3BIGRU-DP满足ε-DP。
证明:由于TM与TR均为BIGRU-DP的子算法,且TM与TR都满足ε-DP,假设TM满足ε1-DP,TR满足ε2-DP,因此,BIGRU-DP满足ε-DP,其中,ε=ε1+ε2。
4 实验评估
实验仿真采用Pycharm开发平台,以Python语言实现。实验所使用的轨迹数据集为微软的T-Drive轨迹数据集。将BIGRU-DP与RNN-DP[9],NGTMA[14]进行比较以证明该方案在可用性和性能上的优势。
4.1 可用性评估
本文使用Hausdorff[15]距离作为轨迹数据可用性的度量指标。Hausdorff距离能够很好地计算两组集合之间的相似度。假设有2组集合A={a1,a2,…,ap},B={b1,b2,…,bq}则这2个点集合之间的Hausdorff距离定义为
H(A,B)=max(h(A,B),h(B,A))
(22)
(22)式中,
h(A,B)=max(a∈A)min(b∈B)‖a-b‖
(23)
h(B,A)=max(b∈B)min(a∈A)‖b-a‖
(24)
(23)—(24)式中,‖·‖是点集A和B点集间的距离范式。Hausdorff距离越小,代表数据的可用性越高。
本文使用Hausdorff距离计算原始轨迹数据集与进行轨迹发布算法处理后的轨迹数据集的相似性度量,并且记录在分配不同的隐私预算ε的情况下使用Hausdorff距离轨迹相似度的变化情况。
图4展示了隐私预算分别为0.1、0.2和0.5的情况下,随着每组测试数据的增加,BIGRU-DP,RNN-DP和NGTMA三种方案中Hausdorff距离的变化和对比情况。
从图4可以看出,根据分配不同的隐私预算ε实验结果可以得知,当实验数据量大小固定时,随着隐私预算ε的增大,不同算法的Hausdorff距离值均为下降趋势,数据可用性增加。这是因为,根据差分隐私的性质,增加隐私预算ε会导致隐私保护度的下降,从而导致数据可用性的提高。
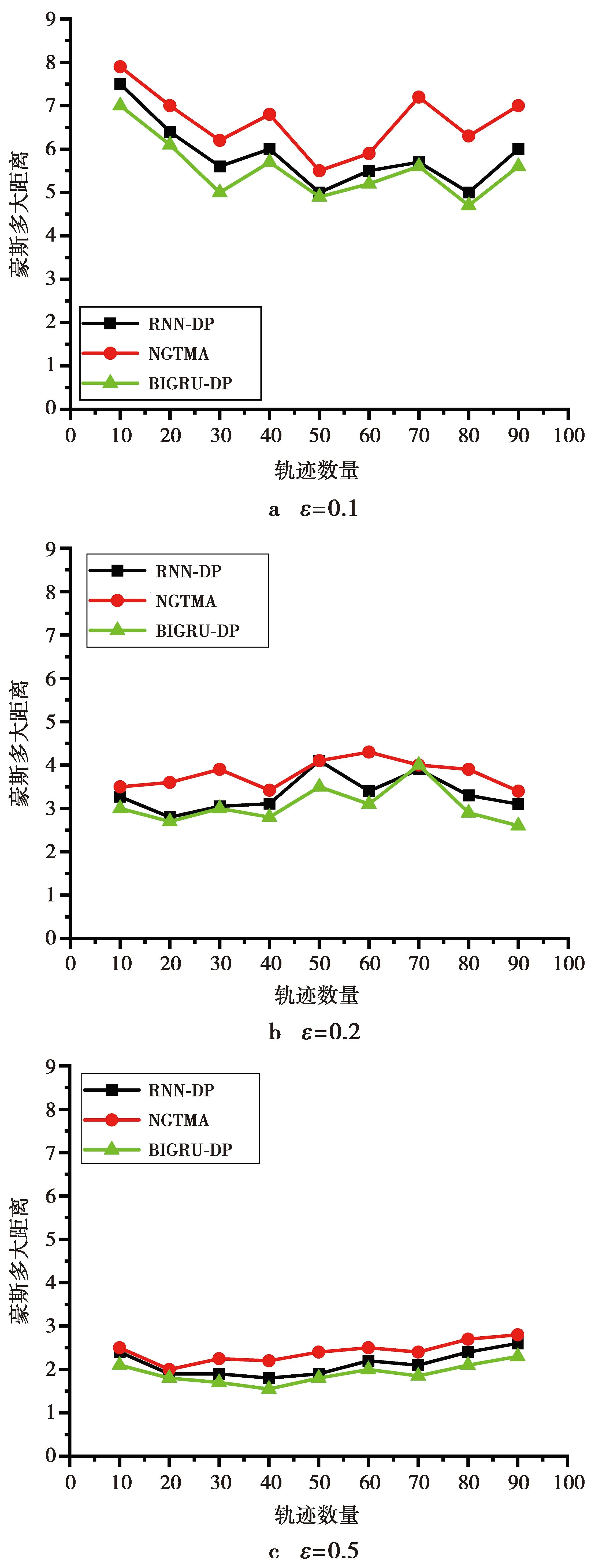
图4 可用性分析对比Fig.4 Availability analysis and comparison
在分配相同的隐私预算的情况下,可以观察到BIGRU-DP具有更好的数据可用性,这是因为在预测算法中,BIGRU在预测过程中引入了更多的信息,因此具有更高的数据可用性。
4.2 效率评估
观察不同的隐私预算与每组测试数据的大小对于消耗时间的影响。图5展示了隐私预算分别为0.1,0.2,0.5的情况下,随着每组测试数据的增加,BIGRU-DP,RNN-DP和NGTMA三种方案中所需时间的变化情况。

图5 性能效率对比Fig.5 Performance efficiency comparison
该实验结果表明,在对时间资源使用的过程中,隐私预算对于时间的影响不大。随着每一组实验数据的增加,所用时间也会随之增长。BIGRU-DP相较于其他2种方案具有时间优势。这是因为BIGRU-DP减少轨迹数据集的离群点,从而减少聚类时的迭代次数,进而减少了时间的消耗。
4.3 评估总结
本文主要贡献如下。
1)考虑到轨迹数据的多样性,利用GRU中门的特性,捕捉到轨迹数据中时间步距离较长的依赖关系,使该方案对于轨迹数据的处理更加具有普遍性。
2)为了提高轨迹发布数据的可用性,使用双向循环网络,同时参考预测点两侧的数据,使得到的轨迹更加准确。
3)使用BIGRU对轨迹数据集进行预处理,为k-means聚类减少了离群值,提升了效率。
4)采用微软公司发布的T-Drive轨迹数据集进行仿真实验。仿真实验结果表明,与同类方案相比,BIGRU-DP方案提高了轨迹数据可用性。同时与RNN-DP,NGTMA对比,实验结果表明BIGRU-DP具有时间效率优势。
5 结束语
本文提出了一种面向轨迹数据发布的BIGRU保护方案,使用BIGRU进行预测处理轨迹数据。由于BIGRU的双向性,BIGRU-DP对于轨迹数据具有更好的处理效果,从而增加了轨迹数据的可用性。同时在预测过程中能够处理离群值,使得BIGRU-DP在执行效率上优于RNN-DP与NGTMA,并且能够在不同样本数量下保持稳定。BIGRU能够利用过去和未来的数据来估计当前值,因此,其更加适合对一些静态轨迹数据进行处理。对于动态轨迹数据,该方案只能根据过去的数据进行处理,因此精度将会下降。如何在保证数据可用性的同时,提高数据的处理效率,选择与更好的聚类技术结合将会是下一步工作的重点。
猜你喜欢
包装工程(2023年24期)2023-12-27
环球时报(2022-03-29)2022-03-29
新世纪智能(数学备考)(2021年5期)2021-07-28
海洋信息技术与应用(2021年1期)2021-06-11
知识经济·中国直销(2018年7期)2018-07-27
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
河南科技(2015年7期)2015-03-11
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
